1:基础知识点
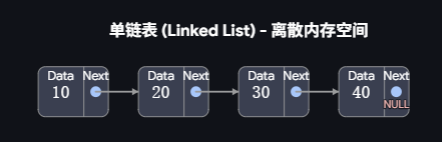
a:链表是由一系列独立的节点串联组成的线性数据结构,每个节点固定包含两个核心域:数据域与指针域。
数据域:专门用来存放节点要存储的实际数据
指针域:一个和节点同类型的指针变量,专门存放下一个节点的内存地址
在内存中是非连续存储的。和数组完全不同,数组的所有元素在内存中是一块连续、相邻的地址空间;而链表的每个节点可以分散在内存的不同位置,节点之间没有地址上的相邻要求,全靠指针域的地址来维系关联。
b:链表在指定位置插入、删除元素,不需要移动其他元素,仅需修改对应节点的指针指向即可。如果在数组中间插入 / 删除元素,需要移动插入位置之后的所有元素,数据量越大效率越低。
c:链表随机查找,访问速度远低于数组
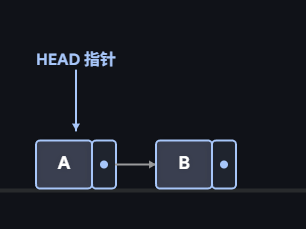
d:没头结点的链表:头指针直接指向第一个存数据的节点。
头指针 -> 第1个数据节点 -> 第2个数据节点 -> ... -> NULL当你插入新节点时,由于它是新的"第一名",你必须强制修改头指针的指向,否则你找不到新的链表开头。
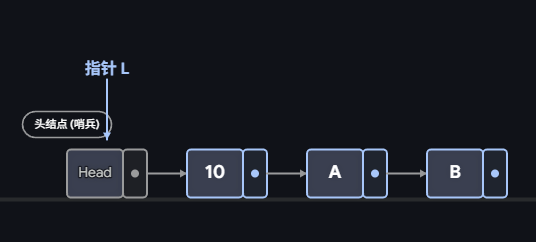
第一步:新节点的 next 指向当前的第一个节点。
第二步:头指针指向新节点。
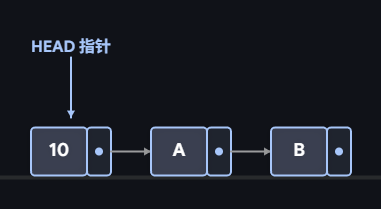
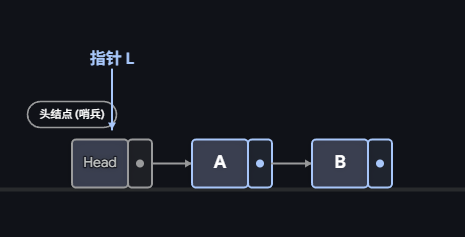
有头结点链表:头指针指向头结点。
头指针 -> 头结点 -> 第1个数据节点 -> 第2个数据节点 -> ... -> NULL这是最推荐的做法。此时,头指针永远指向那个不动的"头结点"。在第一个位置插入,其实就是在头结点后面加塞。
插入数据10演示:
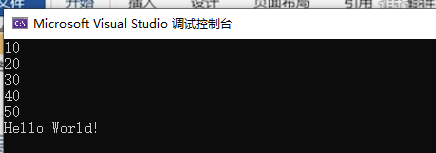
具体例子:静态链表
cs
#include <iostream>
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
struct linknode
{
int data;
struct linknode* next;
};
void test()
{
//创建结构体
struct linknode node1 = { 10,NULL };
struct linknode node2 = { 20,NULL };
struct linknode node3 = { 30,NULL };
struct linknode node4 = { 40,NULL };
struct linknode node5 = { 50,NULL };
//链表连接
node1.next = &node2;
node2.next = &node3;
node3.next = &node4;
node4.next = &node5;
node5.next = NULL;
struct linknode* pcurrent = &node1;
while (pcurrent != NULL)
{
printf("%d\n", pcurrent->data);
pcurrent = pcurrent->next;
}
}
int main()
{
test();
std::cout << "Hello World!\n";
}