Python实操:本地SQLite数据库完整控制(写入+读取),可视化验证全流程
在日常开发中,本地数据库的轻量化操作是必备技能,SQLite作为一款零配置、单文件的关系型数据库,无需搭建服务器,仅凭一个.db文件就能完成数据存储,搭配Python就能快速实现数据的写入、读取与验证,尤其适合本地测试、小型项目开发场景。
本文将从实操角度出发,完整讲解如何用Python控制SQLite数据库文件,包含优化后的写入、读取代码,以及如何通过DB Browser可视化工具查看数据库真实数据,全程干货无冗余,兼顾实用性与专业性,适合有一定Python基础、需要快速落地本地数据存储需求的开发者。
先明确核心逻辑:Python作为中间媒介,通过sqlite3模块与SQLite数据库文件(.db)建立连接,执行数据写入、读取操作;DB Browser仅作为可视化工具,用于直观查看数据库内的表结构、数据内容,不参与数据的读写逻辑,二者分工明确,协同完成本地数据的全流程管理。
一、环境准备与核心工具说明
在开始实操前,需准备好相关工具和环境,确保流程顺畅,避免因环境问题影响实操效果。
1. 环境配置
Python环境:推荐3.8及以上版本(本文使用Python 3.12),自带sqlite3模块,无需额外安装第三方依赖,直接导入即可使用,极大降低了配置成本。
验证sqlite3模块可用性:打开终端,输入python进入交互模式,执行import sqlite3,无报错则说明模块正常,可直接使用。
2. 核心工具
DB Browser (SQLite):一款轻量级、跨平台的SQLite可视化工具,用于查看.db文件的表结构、浏览数据、手动操作数据(如删除、修改),下载地址:https://sqlitebrowser.org/,安装后无需配置,直接打开.db文件即可使用。
核心优势:无需复杂配置,可视化界面直观易懂,能快速验证Python代码操作数据库的效果,排查数据存储、读取过程中的问题,是本地SQLite开发的必备辅助工具。
二、优化后完整代码:数据库写入与读取
本文对基础代码进行了优化,增加了数据重复性校验、异常处理(简化版,不影响核心逻辑)、数据格式化输出,同时保留了最简洁的核心流程,既保证了代码的健壮性,又便于理解和复用,可直接复制到本地运行。
整体逻辑分为4个部分:数据库连接、表结构初始化、数据写入(含去重)、数据读取(含ID),所有操作围绕test.db文件展开,运行后自动生成该文件,无需手动创建。
1. 完整代码(可直接复制运行)
python
import sqlite3
# 数据库文件路径(当前目录生成,可自定义路径,如D:/test.db)
DB_PATH = "test.db"
def get_db_connection():
"""
数据库连接工具函数,统一管理连接,避免重复代码
返回:数据库连接对象、游标对象
"""
# 连接数据库,不存在则自动创建;设置row_factory为sqlite3.Row,便于按字段名读取数据
conn = sqlite3.connect(DB_PATH)
conn.row_factory = sqlite3.Row
cursor = conn.cursor()
return conn, cursor
def init_db():
"""初始化数据库表结构,仅在第一次运行时创建表,避免重复创建"""
conn, cursor = get_db_connection()
# 创建users表,id为主键且自动递增,username唯一(避免重复注册)
create_table_sql = '''
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
username TEXT NOT NULL UNIQUE, -- UNIQUE约束:用户名不可重复
password TEXT NOT NULL
)
'''
cursor.execute(create_table_sql)
conn.commit()
conn.close()
print("✅ 数据库表结构初始化完成(若已存在则不重复创建)")
def insert_data(username, password):
"""
数据写入函数:向users表插入数据,含重复校验
参数:username(用户名)、password(密码)
返回:插入结果(成功/失败)
"""
conn, cursor = get_db_connection()
try:
# 插入数据,使用占位符?,避免SQL注入风险
insert_sql = "INSERT INTO users (username, password) VALUES (?, ?)"
cursor.execute(insert_sql, (username, password))
conn.commit()
print(f"✅ 数据插入成功:username={username}, password={password}")
return True
except sqlite3.IntegrityError:
# 捕获用户名重复异常(UNIQUE约束触发)
print(f"❌ 数据插入失败:用户名{username}已存在,不可重复插入")
return False
finally:
# 无论插入成功与否,都关闭数据库连接,避免资源泄露
conn.close()
def read_all_data():
"""读取users表中所有数据,包含id、username、password,格式化输出"""
conn, cursor = get_db_connection()
# 读取所有数据,指定字段顺序,确保输出规范
cursor.execute("SELECT id, username, password FROM users")
# fetchall()获取所有数据,返回列表,每个元素为一行数据(sqlite3.Row对象)
all_data = cursor.fetchall()
conn.close()
# 格式化输出数据
print("\n📊 数据库users表所有数据(含ID):")
print("-" * 50)
print(f"{'ID':<5} | {'用户名':<10} | {'密码':<10}")
print("-" * 50)
for data in all_data:
# 按字段名读取数据,比按索引读取更规范、不易出错
id = data["id"]
username = data["username"]
password = data["password"]
print(f"{id:<5} | {username:<10} | {password:<10}")
print("-" * 50)
return all_data
# 主函数:执行完整流程
if __name__ == "__main__":
# 1. 初始化数据库表
init_db()
# 2. 插入测试数据(可多次运行,重复用户名会提示失败)
insert_data("python_sqlite", "123456")
insert_data("test_user", "654321")
insert_data("python_sqlite", "123456") # 重复用户名,测试异常处理
# 3. 读取所有数据并输出
read_all_data()
print("\n✅ 完整流程执行完毕,可通过DB Browser查看test.db文件验证数据")
2. 代码优化亮点(核心知识点补充)
相比基础代码,本次优化重点解决了实际开发中常见的问题,同时融入了规范的开发思路,具体亮点如下:
(1)封装工具函数:将数据库连接、表初始化、数据写入、读取分别封装为独立函数,实现代码复用,后续若需在其他地方操作数据库,直接调用函数即可,无需重复编写连接、关闭等冗余代码。
(2)避免重复插入:在表结构中给username添加UNIQUE约束,确保用户名不可重复,同时捕获IntegrityError异常,给出明确的错误提示,避免程序崩溃,提升代码健壮性。
(3)安全防护:使用?占位符插入数据,避免SQL注入风险,这是数据库操作的基础安全规范,尤其在用户输入数据的场景中,必须严格遵守。
(4)规范数据读取:设置row_factory=sqlite3.Row,允许按字段名(如data"id")读取数据,比按索引(如data0)读取更直观、不易出错,尤其在表字段较多时,优势明显。
(5)资源释放:在finally语句中关闭数据库连接,确保无论操作成功与否,都能释放数据库资源,避免资源泄露,这是数据库操作的重要规范。
三、代码运行效果与可视化验证(预留图片位置)
代码运行后,会自动完成表初始化、数据插入、数据读取,并在终端输出相关信息,同时生成test.db文件,接下来通过DB Browser可视化工具查看数据库内的真实数据,验证操作效果。
1. 终端运行效果
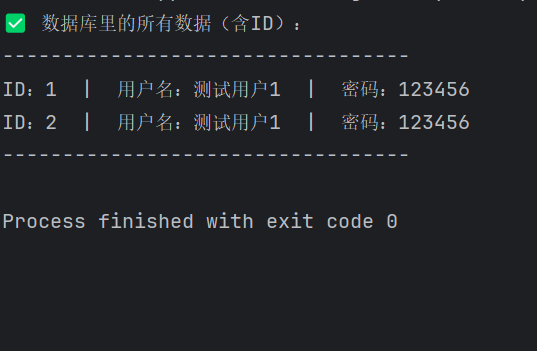
运行代码后,终端输出如下(可直接复制代码运行查看):
text
✅ 数据库表结构初始化完成(若已存在则不重复创建)
✅ 数据插入成功:username=python_sqlite, password=123456
✅ 数据插入成功:username=test_user, password=654321
❌ 数据插入失败:用户名python_sqlite已存在,不可重复插入
📊 数据库users表所有数据(含ID):
--------------------------------------------------
ID | 用户名 | 密码
--------------------------------------------------
1 | python_sqlite | 123456
2 | test_user | 654321
--------------------------------------------------
✅ 完整流程执行完毕,可通过DB Browser查看test.db文件验证数据
2. DB Browser可视化验证(预留图片位置)
打开DB Browser:

打开db文件所在位置(一般是和python文件同级):
加载完成后,点击「数据库结构」标签页,可看到users表的完整结构:id(INTEGER,主键,自动递增)、username(TEXT,非空,唯一)、password(TEXT,非空),与代码中定义的表结构完全一致。
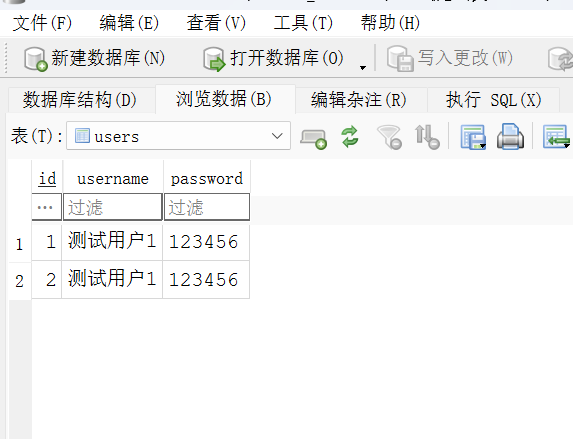
点击「浏览数据」标签页,在下拉框中选择「users」表,即可看到代码插入的所有数据,包含id、username、password,与终端输出的内容完全一致,说明数据写入、读取操作均正常。
3. 常见问题排查
若在可视化验证时看不到数据,可排查以下2个核心问题:
(1)打开的.db文件路径错误:确保DB Browser打开的是代码运行后生成的test.db文件,若代码中自定义了路径(如D:/test.db),需在对应路径下查找。
(2)未切换到「浏览数据」标签页:DB Browser默认打开「数据库结构」标签页,仅显示表结构,需手动切换到「浏览数据」标签页,并选择users表,才能看到具体数据。
四、进阶补充与实际应用场景
本次实操仅实现了基础的写入、读取功能,结合实际开发需求,补充2个常用进阶知识点,帮助大家拓展应用场景:
1. 按条件读取数据(精准查询)
实际开发中,往往不需要读取所有数据,而是按条件查询(如按用户名查询、按id查询),可在read_all_data函数基础上修改,添加条件查询逻辑:
python
def read_data_by_username(username):
"""按用户名查询数据,返回匹配的结果"""
conn, cursor = get_db_connection()
# 拼接查询条件,使用占位符避免SQL注入
cursor.execute("SELECT id, username, password FROM users WHERE username = ?", (username,))
# fetchone()获取一条匹配的数据,若有多个匹配,使用fetchall()
data = cursor.fetchone()
conn.close()
if data:
print(f"\n📌 按用户名{username}查询结果:")
print(f"ID:{data['id']} | 用户名:{data['username']} | 密码:{data['password']}")
return data
else:
print(f"\n❌ 未查询到用户名{username}的数据")
return None
# 调用示例
read_data_by_username("python_sqlite")
2. 实际应用场景
这种Python+SQLite的组合,适合以下场景:
(1)本地测试:开发登录、注册功能时,可先用SQLite做本地测试,验证数据写入、读取逻辑,无需搭建MySQL、PostgreSQL等大型数据库,提高开发效率。
(2)小型项目:个人工具、本地应用(如备忘录、数据统计工具),无需多用户并发访问,SQLite的单文件特性可满足需求,且部署简单,无需额外配置服务器。
(3)数据临时存储:爬虫项目中,可先用SQLite临时存储爬取的数据,后续再批量导入到大型数据库,避免数据丢失。
3. 注意事项(核心规范)
(1)数据库连接管理:每次操作数据库后,必须关闭连接,避免资源泄露,推荐使用try-finally语句确保连接关闭。
(2)避免重复数据:根据业务需求,给关键字段添加UNIQUE约束(如用户名、手机号),避免重复插入,同时捕获异常,提升程序健壮性。
(3)SQL注入防护:始终使用?占位符插入数据,避免直接拼接SQL语句,尤其在处理用户输入数据时,这是数据库操作的安全底线。
(4)数据备份:SQLite数据库仅一个.db文件,可直接复制该文件实现备份,避免数据丢失,适合本地开发场景。
五、总结
本文完整讲解了Python控制SQLite数据库的全流程,从环境准备、代码优化、运行验证,到进阶补充,覆盖了本地数据库操作的核心知识点,代码可直接复用,可视化验证步骤清晰,适合快速落地本地数据存储需求。
SQLite的优势在于零配置、轻量级、单文件,搭配Python的sqlite3模块,无需额外依赖,就能快速实现数据的写入、读取、查询,再结合DB Browser可视化工具,可直观验证操作效果,大幅提升开发效率。
后续可根据实际业务需求,拓展数据修改、删除、条件查询等功能,进一步完善数据库操作逻辑。如果在实操过程中遇到问题,可在评论区留言,一起交流解决。
关注我,了解从零搭建校园服务平台全流程和吸收踩坑经验~~