RAG与Agent性能调优:4.切片语义割裂怎么办?
Gitee地址:https://gitee.com/agiforgagaplus/OptiRAGAgent
文章详情目录:RAG与Agent性能调优
上一节:第3节:领域术语种混淆?构建精准数语库,提升检索一致性
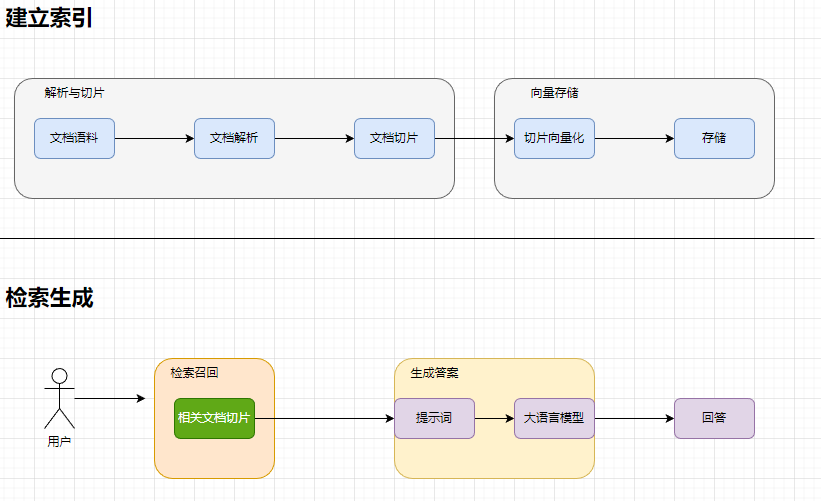
什么是滑动窗口?
我们可以把文档想象成一条连绵不断的河流,而滑动窗口就像是一个移动观察框。它每次只关注一小段,然后逐步向前滑动,依次扫描整个文档
- 避免切片过短,确保每个片段都有一定的信息量
- 同时,合理设置窗口大小和布长,实现对全文覆盖式处理
关键词如何发挥作用?
- 关键词通常是文档中的核心概念、专业术语或高频语义单元,它们承载着文本的主要信息特点
- 如果某个窗口的边界恰好切断了一个关键词,或者打断了一个完整的语义单元
- 我们就可以根据关键词位置动态调整切片的起始或结束位置,从而保证语语义的完整性
滑动窗口+关键词=智能切片
将两者结合,我们可以构建一套更加智能的切片流程
- 初步切片:使用滑动窗口,对文档进行基础分段
- 关键词检测:分析每个切片的边界,是否存在关键词或语义单元中断
- 动态调整:根据关键词的位置和上下文语义,微调切片边缘,确保语义完整且不冗余
实战演练(均为伪代码,详细代码进仓库查看)
Token切片
优点:控制输出长度,适用于小模型,实现简单
缺点:容易造成语义割裂;依赖overlap补偿效果有限,不适合复杂语义任务
import os
from llama_index.core import VectorStoreIndex, Settings, Document
from llama_index.core.node_parser import SentenceWindowNodeParser, SemanticSplitterNodeParser, TokenTextSplitter
from llama_index.core.postprocessor import MetadataReplacementPostProcessor
# 导入 OpenAILike LLM (用于 DashScope 兼容模式,Qwen 模型)
from llama_index.llms.openai_like import OpenAILike
# 导入 DashScopeEmbedding (用于阿里云 DashScope 嵌入模型)
from llama_index.embeddings.dashscope import DashScopeEmbedding
# 1. 配置 LLM (使用 DashScope 的 qwen-plus 模型,通过 OpenAILike 调用)
# 2. 配置嵌入模型 (使用 DashScopeEmbedding 类)
def evaluate_splitter(splitter, documents, question, splitter_name):
"""
评测不同文档切片方法的效果
手动打印召回结果,方便直接对比切分效果。
"""
print(f"\n{'='*50}")
print(f"正在使用 {splitter_name} 方法进行测试...")
print(f"{'='*50}\n")
# 显示 raw chunks generated by the splitter
print(f"【{splitter_name}】生成的原始文档切片 (Nodes):")
raw_nodes = splitter.get_nodes_from_documents(documents)
for i, node in enumerate(raw_nodes, 1):
print(f"\n 切片 {i}:")
if isinstance(splitter, SentenceWindowNodeParser):
original_text = node.metadata.get("original_text", node.get_content())
window_context = node.metadata.get("window", "N/A - 窗口内容未生成")
print(f" 核心内容: \"{original_text}\"")
print(f" 完整窗口上下文(供LLM用): \"{window_context}\"")
else:
print(f" 内容: \"{node.get_content()}\"")
# Add metadata for debugging if needed
# print(f" 元数据: {node.metadata}")
print(" " + "-" * 40)
print("\n" + "="*50)
# --- 开始测试不同的切片策略 ---
# Token 切片 (Character/Token-based)
token_splitter = TokenTextSplitter(
chunk_size=30, # Small chunk size to demonstrate forced breaks
chunk_overlap=0 # No overlap for clear distinct chunks
)
evaluate_splitter(token_splitter, documents, question, "Token 切片 (chunk_size=30)")
token_splitter = TokenTextSplitter(
chunk_size=30, # Small chunk size to demonstrate forced breaks
chunk_overlap=10 # No overlap for clear distinct chunks
)
evaluate_splitter(token_splitter, documents, question, "Token 切片 (chunk_size=30,chunk_overlap=10 )")句子切片
|---------------|-----------------------|----------------------|
| 特性 | TokenTextSplitter | SentenceSplitter |
| 切分单位 | Token | 句子 |
| chunk_size | 硬性上限,强制截断 | 软性目标,优先保持句子完整 |
| chunk_overlap | Token 级别重叠,可能包含不完整句子 | 句子级别重叠,确保上下文自然衔接 |
sentence_splitter = SentenceSplitter(
chunk_size=512,
chunk_overlap=50
)
evaluate_splitter(sentence_splitter, documents, question, "Sentence")句子窗口切片
-
切分单元:句子
-
核心机制:为每个句子附加上下文窗口
-
检索方式:基于句子的精准召回
-
生成方式:使用上下文窗口提升语义完整性
-
适用场景:精准问答,摘要生成,解释型问答等对上下文敏感的任务
句子窗口切片 (Sentence Window)
sentence_window_splitter = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text"
)
evaluate_splitter(sentence_window_splitter, documents, question, "Sentence Window")
句子的滑动窗口切片
|---------|----------|------------|---------------|
| 特性 | 句子切片 | 句子窗口切片 | 基于句子的滑动窗口 |
| 保持句子完整性 | ✅ | ✅ | ✅ |
| 切块之间重叠 | ❌ | ❌ | ✅ |
| 上下文丰富程度 | 一般 | 强(需后处理) | 强(天然包含) |
| 检索准确性 | 一般 | 一般 | 强 |
| 适用场景 | 基础文本处理 | 精准问答、解释型任务 | 复杂语义匹配、长文本检索 |
def demonstrate_sliding_window_splitter(documents, chunk_size, chunk_overlap):
"""
演示 LlamaIndex 中保持句子完整性的滑动窗口切片。
Args:
documents (list[Document]): 待切分的文档列表。
chunk_size (int): 每个切块的目标 Token 数量。
chunk_overlap (int): 相邻切块之间重叠的 Token 数量。
"""
print(f"\n{'='*50}")
print(f"正在演示【滑动窗口切片】...")
print(f"切块大小 (chunk_size): {chunk_size}")
print(f"重叠大小 (chunk_overlap): {chunk_overlap}")
print(f"{'='*50}\n")
# --- 第一步:创建切分器 ---
# SentenceSplitter 优先保持句子完整性,再考虑大小
splitter = SentenceSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
# --- 第二步:执行切分 ---
# 获取切分后的节点(切块)
nodes = splitter.get_nodes_from_documents(documents)
# --- 第三步:打印切分结果,展示重叠效果 ---
print("\n--- 切分后生成的原始切块:---")
print(f"文档被切分为 {len(nodes)} 个切块。")
for i, node in enumerate(nodes, 1):
content = node.get_content().strip()
print(f"\n【切块 {i}】 (长度: {len(content)} 字符):")
print("-" * 50)
print(f"内容:\n\"{content}\"")
print("-" * 50)
# --- 简单的切分效果分析:观察相邻切块的重叠部分 ---
print("\n--- 关键点:观察相邻切块的重叠部分 ---")
if len(nodes) > 1:
# 为了更好地展示重叠,我们只截取重叠部分的内容
# 由于是句子级别的切分,重叠部分是完整的句子
overlap_content_end_of_chunk1 = nodes[0].get_content()[-chunk_overlap:].strip()
overlap_content_start_of_chunk2 = nodes[1].get_content()[:chunk_overlap].strip()
print(f"切块 1 的末尾 ({chunk_overlap} 字符): \"...{overlap_content_end_of_chunk1}\"")
print(f"切块 2 的开头 ({chunk_overlap} 字符): \"{overlap_content_start_of_chunk2}...\"")
print(f"\n你可以看到,切块 1 的末尾与切块 2 的开头存在重叠,这就是 chunk_overlap 的作用。")
else:
print("文档太短,未能生成多个切块。请使用更长的文档以观察效果。")
print(f"\n滑动窗口切片测试完成。")
print(f"{'='*50}\n")
# --- 调用滑动窗口切片演示函数 ---
# 调整 chunk_size 和 chunk_overlap 观察不同效果
demonstrate_sliding_window_splitter(documents, chunk_size=150, chunk_overlap=50)语义切片
# --- 3. 定义一个能处理中文的自定义分句函数 ---
# 这个函数本身就是 SemanticSplitterNodeParser 所需要的"句子切分器"
def chinese_sentence_tokenizer(text: str) -> list[str]:
sentences = re.findall(r'[^。!?...\n]+[。!?...\n]?', text)
return [s.strip() for s in sentences if s.strip()]
def plot_similarity_and_chunks(splitter: SemanticSplitterNodeParser, title: str):
# 使用我们自己的函数进行可视化部分的句子切分,这部分逻辑是正确的
sentences = chinese_sentence_tokenizer(document.get_content())
if len(sentences) < 2:
print(f"错误:只找到了 {len(sentences)} 个句子,无法计算句子间的相似度。")
return
print(f"正在为 {len(sentences)} 个句子生成嵌入向量...")
embeddings = Settings.embed_model.get_text_embedding_batch(sentences, show_progress=True)
def cosine_similarity(v1, v2):
return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2))
similarities = [cosine_similarity(embeddings[i], embeddings[i+1]) for i in range(len(embeddings) - 1)]
breakpoint_threshold_val = np.percentile(similarities, splitter.breakpoint_percentile_threshold)
print(f"计算出的相似度阈值为: {breakpoint_threshold_val:.4f}")
# --- 可视化 ---
plt.figure(figsize=(12, 6))
plt.plot(similarities, marker='o', linestyle='-', label='相邻句子相似度')
plt.axhline(y=breakpoint_threshold_val, color='r', linestyle='--', label=f'切分阈值 ({splitter.breakpoint_percentile_threshold}百分位)')
plt.title(title, fontsize=16)
plt.xlabel("句子连接处索引")
plt.ylabel("余弦相似度")
plt.legend()
try:
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
except Exception:
print("无法设置中文字体 'SimHei',图表中的中文可能显示为乱码。")
plt.grid(True)
plt.show()
# --- 实际切分 ---
# 这部分现在应该可以正常工作了
nodes = splitter.get_nodes_from_documents([document])
print("\n--- 切分结果 ---")
for i, node in enumerate(nodes):
print(f"====== 节点 {i+1} (长度: {len(llama_tokenizer(node.get_content()))} tokens) ======")
print(node.get_content().strip())
print("-" * 20)
# --- 5. 直接将我们编写的函数传递给 SemanticSplitterNodeParser
# 实验一:使用保守阈值 (95)
print("="*20 + " 实验一:使用保守阈值 (95) " + "="*20)
conservative_splitter = SemanticSplitterNodeParser(
buffer_size=1,
breakpoint_percentile_threshold=95,
embed_model=Settings.embed_model,
sentence_splitter=chinese_sentence_tokenizer
)
plot_similarity_and_chunks(conservative_splitter, "相似度与切分点 (阈值=95%)")
# 实验二:使用激进阈值 (5)
print("\n" + "="*20 + " 实验二:使用激进阈值 (5) " + "="*20)
aggressive_splitter = SemanticSplitterNodeParser(
buffer_size=1,
breakpoint_percentile_threshold=5,
embed_model=Settings.embed_model,
sentence_splitter=chinese_sentence_tokenizer
)
plot_similarity_and_chunks(aggressive_splitter, "相似度与切分点 (阈值=5%)")滑动窗口+关键词语义切片
|-------------------------|-----------------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------|
| 策略类型 | 优点 | 缺点 |
| 滑动窗口 (SentenceSplitter) | 1.上下文保留:通过chunk_overlap确保切块边界的信息不会丢失,有效缓解了"答案在切块边缘"的问题。 2.大小可控:可以大致控制切块的chunk_size,对LLM的上下文窗口友好。 3.速度快:不依赖昂贵的Embedding模型调用,计算成本低。 | 1.语义盲目:完全不理解文本内容,可能在逻辑最紧密的地方强行切分,导致"语义割裂"。 2.冗余度高:产生大量重叠内容,增加了索引的存储成本和检索时的计算量。 |
| 语义切分 (SemanticSplitter) | 1.语义完整性:切块的边界就是语义的边界,每个块都是一个高度内聚的、完整的逻辑单元。 2.信噪比高:提供给LLM的上下文非常"干净",几乎没有无关信息。 3.动态大小:切块大小自适应文本的逻辑结构。 | 1.边界上下文丢失:如果用户的答案恰好需要结合两个语义块边界的信息,可能会因为没有重叠而检索不全。 2.大小不可控:可能产生非常大的语义块,超出LLM能处理的上下文长度限制。 3.成本高:需要为每个句子计算嵌入向量,速度慢且有API调用成本。 |
DASHSCOPE_API_KEY = os.getenv("DASHSCOPE_API_KEY")
# --- 自定义混合解析器类 (已更新为带详细打印的版本) ---
class HybridNodeParser(NodeParser):
primary_parser: NodeParser
secondary_parser: NodeParser
max_chunk_size: int = 1024
tokenizer: Callable = Field(default_factory=get_tokenizer, exclude=True)
def _parse_nodes(self, documents: List[Document], **kwargs) -> List[Document]:
print("--- 开始执行【混合切分】... ---")
primary_nodes = self.primary_parser.get_nodes_from_documents(documents)
print(f"\n{'='*25} 第一步(语义切分)结果 {'='*25}")
print(f"初步切分出 {len(primary_nodes)} 个语义段落。")
for i, p_node in enumerate(primary_nodes, 1):
print(f"\n【原始语义段落 {i}】 (大小: {len(self.tokenizer(p_node.get_content()))} tokens)")
print("-" * 60)
print(textwrap.indent(p_node.get_content().strip(), ' '))
print("-" * 60)
print(f"\n{'='*25} 第二步(检查与二次切分)过程 {'='*25}")
final_nodes = []
for i, node in enumerate(primary_nodes, 1):
node_size = len(self.tokenizer(node.get_content()))
print(f"\n>>> 正在检查【原始语义段落 {i}】 (大小: {node_size} tokens)...")
if node_size <= self.max_chunk_size:
print(f" └── 结果: 大小合适 (<= {self.max_chunk_size} tokens),直接采纳。")
final_nodes.append(node)
else:
print(f" └── 结果: 段落过大 (> {self.max_chunk_size} tokens),将使用滑动窗口进行二次切分。")
print("\n 【即将被切分的原始内容】")
print(" " + "-"*50)
print(textwrap.indent(node.get_content().strip(), ' | '))
print(" " + "-"*50)
sub_nodes = self.secondary_parser.get_nodes_from_documents([Document(text=node.get_content())])
print(f"\n 【二次切分结果】: 被切分成了 {len(sub_nodes)} 个重叠的子切块。")
for j, s_node in enumerate(sub_nodes, 1):
print(f"\n 【子切块 {i}.{j}】 (大小: {len(self.tokenizer(s_node.get_content()))} tokens)")
print(" " + "-"*40)
print(textwrap.indent(s_node.get_content().strip(), ' | '))
print(" " + "-"*40)
final_nodes.extend(sub_nodes)
print("\n--- 【混合切分】完成!---")
return final_nodes
@classmethod
def from_defaults(cls, **kwargs):
raise NotImplementedError("请直接实例化此类,不要使用 from_defaults")
# --- 实例化两个基础的解析器 ---
semantic_parser = SemanticSplitterNodeParser(
buffer_size=1,
breakpoint_percentile_threshold=95,
sentence_splitter=chinese_sentence_tokenizer,
embed_model=Settings.embed_model
)
window_parser = SentenceSplitter(
chunk_size=256,
chunk_overlap=50
)
# --- 实例化并使用我们的混合解析器 ---
hybrid_parser = HybridNodeParser(
primary_parser=semantic_parser,
secondary_parser=window_parser,
max_chunk_size=300,
tokenizer=get_tokenizer()
)
# 执行混合切分
final_nodes = hybrid_parser.get_nodes_from_documents([long_document])