《硅基之盾》番外篇二:算力底座的暗战------智算中心 VXLAN/EVPN 架构下的多租户隔离与防御
你好,我是陈涉川,这是我特别为你写的番外,欢迎来到专栏《硅基之盾》。在上一篇番外里,我们带着大家钻进了布满铁锈与尘埃的工业控制网络,体验了一把在物理隔离的边缘废土中进行数字博弈的快感。不知道大家看得过不过瘾?今天,我们不搞那些"复古"的把戏了。既然是《硅基之盾》的番外篇,咱们必须去目前世界上最烧钱、最前沿、也最核心的战场走一遭。系好安全带,这期内容非常硬核,我们将直接潜入大模型时代的心脏,看看那些被各大科技巨头当成最高机密的智算中心,其底层究竟暗藏着怎样的血雨腥风。
引言:跃迁风暴眼------算力霸权下的隐秘绞肉机
在《硅基之盾》的正传以及上一篇关于工控物理隔离的探讨中,我们将视野投向了广袤的边缘战场与陈旧的数字废土。但今天,在这篇番外中,我们必须将目光强势拉回现代科技的绝对风暴眼------智算中心(AI Data Center, AIDC)。
随着千亿乃至万亿参数级大语言模型(LLM)的狂飙突进,算力已然成为这个时代最为昂贵、也最具战略意义的霸权资源。当我们站在那些动辄由数万张顶级 GPU 组成、日夜轰鸣的庞大算力集群面前时,往往只会被其恐怖的浮点运算能力(FLOPS)和诸如 SK 海力士 HBM 内存的极速带宽所震撼。然而,在这些耀眼的光环与动辄数亿美元的投资之下,真正决定一个智算中心生死存亡、主宰模型训练成败的,其实是一张极其复杂、肉眼不可见的网络互联底座。
大模型的分布式训练(如张量并行、流水线并行、数据并行)对网络底层协议的依赖,已经达到了近乎偏执的苛刻程度。一次极其微小的网络拥塞,一个数据包的微秒级延迟,甚至万分之一的瞬间丢包,都可能让数万个节点参与的集合通信(Collective Communication,如 All-Reduce 过程)瞬间陷入停滞。这种停滞,会让每分每秒都在燃烧真金白银的算力成本化为乌有。为了支撑这股恐怖的"东西向"流量洪流,现代智算中心彻底抛弃了传统的网络架构,全面拥抱了基于 Spine-Leaf(叶脊)的无损以太网,并以 VXLAN(虚拟可扩展局域网)与 BGP EVPN(以太网虚拟专用网)作为构建多租户算力池的绝对基石。
但是,请想象一个极度危险的场景:当我们将不同的租户------他们可能是相互倾轧的科技巨头,也可能是暗藏杀机、蓄谋已久的国家级 APT 组织------共同塞进同一个庞大的物理算力集群,并仅仅依靠虚拟化网络协议的"逻辑高墙"来维持和平时,一场极其隐蔽、极其凶险的"底座暗战"便悄然打响。
本篇番外,我们将彻底屏住呼吸,如解剖精密钟表般切入网络架构师与协议专家的深水区。去探寻当恶意租户试图撕裂 VNI(VXLAN Network Identifier)隔离墙,窃取百亿参数权重,或利用 RoCEv2 无损网络的物理机制缺陷发动"降维打击"时,这套维系着全球顶尖 AI 算力的网络底座,究竟藏着怎样致命的阿喀琉斯之踵。
一、 算力孤岛的终结:智算中心网络的极致演进
要深刻理解 VXLAN/EVPN 架构在安全上的阿喀琉斯之踵,我们必须首先理清一个核心脉络:现代智算中心的网络是如何一步步演进成今天这种高度复杂、高度耦合的形态的。
1.1 从传统大二层到 Clos 架构的必然
早期的云计算数据中心大多采用传统的接入(Access)、汇聚(Aggregation)、核心(Core)三层架构,并依赖生成树协议(STP, Spanning Tree Protocol)来防环。这种架构在处理以南北向(客户端到服务器)为主的 Web 流量时游刃有余。
然而,到了 AI 时代,大模型训练的流量特征发生了极其暴烈的突变。在进行反向传播计算梯度时,服务器之间需要极其频繁地交换庞大的参数矩阵。这种横向跨越服务器的流量(东西向流量)占据了智算中心 90% 以上的带宽。传统三层架构下,STP 为了防环会阻塞大量冗余链路,导致网络截面带宽(Bisection Bandwidth)极低,根本无法承受 AI 训练的洪流。
因此,智算中心全面转向了 Clos 架构(Spine-Leaf 叶脊架构)。
在 Spine-Leaf 架构中,每一个 Leaf 交换机(通常作为 ToR,柜顶交换机)都与所有的 Spine 交换机(脊交换机)全互联。这种架构极其优美地解决了两个问题:
- 任意两台服务器之间的跳数(Hop Count)严格固定,确保了网络延迟的绝对确定性。
- 配合等价多路径路由(ECMP, Equal-Cost Multi-Path),网络可以横向无限扩展,实现真正的无阻塞(Non-blocking)全交换。
1.2 RDMA 与 RoCEv2:绕过操作系统的极速狂飙
即使有了完美的 Spine-Leaf 拓扑,传统的 TCP/IP 协议栈依然是 AI 训练的噩梦。
在传统的以太网通信中,当 GPU 想要发送数据时,数据必须从 GPU 显存拷贝到系统内存,然后由 CPU 介入,经过操作系统内核的 TCP/IP 协议栈层层封装(加上 TCP 头、IP 头、以太网帧头),最后才交由网卡发送。接收端则要经历同样繁琐的反向过程。这种"多次上下文切换"和"数据拷贝"带来了极大的延迟(通常在几十到上百微秒级别),且消耗了大量宝贵的 CPU 资源。
为了榨干网络的最后一点性能,RDMA(Remote Direct Memory Access,远程直接内存访问) 技术被引入。RDMA 允许一台服务器的网卡直接读写另一台服务器的内存(甚至直接读写 GPU 显存,即 GPUDirect RDMA),彻底绕过了操作系统的内核态,实现了零拷贝(Zero-copy)和 Kernel Bypass。 延迟被恐怖地压缩到了 1-2 微秒。
起初,RDMA 主要运行在昂贵且封闭的 InfiniBand(IB)网络上。为了打破供应商锁定,业界极客们开发出了 RoCEv2(RDMA over Converged Ethernet v2)。它极其聪明地将 RDMA 的操作码封装在 UDP/IP 报文中,使其能够跑在通用的商用以太网交换机上。
然而,命运的所有馈赠都在暗中标好了价格。RoCEv2 虽然拥有了以太网的通用性,但它继承了 RDMA 的一个致命弱点:对丢包的极度"零容忍"。
TCP 协议生来就有优秀的拥塞控制和丢包重传机制;但在 RDMA 的世界里,哪怕出现万分之一的丢包,都会触发 Go-Back-N 的全局重传机制,导致网络吞吐量断崖式暴跌(这就是业界常说的"网络吞吐量随丢包率呈悬崖式衰减"现象)。
为了保证绝对的零丢包,智算中心的底层交换机被迫启用了极其底层的硬件流控技术:PFC(Priority-based Flow Control,基于优先级的流量控制,IEEE 802.1Qbb) 和 ECN(Explicit Congestion Notification,显式拥塞通知)。
请记住 PFC 这个机制,它将成为我们后续论述中,恶意租户发起"降维瘫痪攻击"的最核心武器。
二、 虚拟化的迷宫:VXLAN 与 BGP EVPN 的双重世界
在构建了 Spine-Leaf 物理拓扑并打通了 RoCEv2 无损网络之后,数据中心架构师们面临着最后一个,也是与网络安全息息相关的问题:多租户隔离与虚拟化。
智算中心的算力极其昂贵,往往需要作为云服务(AIaaS, AI as a Service)租借给不同的企业或研究机构。租户 A 和租户 B 的物理服务器可能插在同一个机架上,连接着同一台 Leaf 交换机。他们可能需要使用相同的 IP 网段(例如 10.0.0.0/8),并且都要求自己感觉像是独占了一个庞大的二层局域网,可以在其中自由地进行虚拟机(VM)或容器的动态热迁移(Live Migration)。
传统的 VLAN(IEEE 802.1Q)技术在这里彻底破产。VLAN Tag 只有 12 bit,最多只能支持 4094 个租户,这在动辄数万节点的超大规模云数据中心面前简直是杯水车薪。此外,VLAN 无法跨越三层(IP)网络,根本无法在庞大的 Spine-Leaf 架构中实现端到端的大二层延伸。
于是,VXLAN(Virtual eXtensible LAN,RFC 7348) 作为救世主应运而生。
2.1 数据面的幻术:VXLAN 的 MAC-in-UDP 封装
VXLAN 的本质是一种 NVO3(Network Virtualization over Layer 3)隧道技术。它实施了一套极其精妙的"障眼法":将原始的二层以太网帧(MAC 帧),强制封装进一个 UDP 数据包中,然后在这个 UDP 数据包外面套上物理网络的三层 IP 头,通过底层的 IP 网络进行路由转发。
对于租户的虚拟机或容器来说,它们依然认为自己在与同一个网段的机器进行二层通信;但实际上,它们发出的数据包被悄悄地"塞进"了 UDP 隧道,跨越了无数的 Spine 路由器,到达目的地后再被"解包"。
执行这种封装和解封动作的实体被称为 VTEP(VXLAN Tunnel End Point,VXLAN 隧道端点)。在典型的硬件 SDN(软件定义网络)方案中,VTEP 通常由 ToR(柜顶)Leaf 交换机担任。
VXLAN 协议最核心的安全与隔离机制,是其头部包含的 24 bit 的 VNI(VXLAN Network Identifier)。
24 bit 的空间意味着它可以支持多达 2^{24} \approx 1677 万个独立的租户网络。在这个架构下,VNI 就是租户绝对的物理边界。只要两个虚拟机的 VNI 不同,即使它们的 IP 地址完全一样,即使它们连接在同一台物理交换机上,它们的数据包也绝对无法互通。
2.2 控制面的大脑:BGP EVPN 的降维统治
早期的 VXLAN 存在一个致命的缺陷:它没有一个专门的控制面协议。
当一台虚拟机想要寻找同网段的另一台未知虚拟机时,它会发出 ARP 广播请求。早期的 VXLAN 会将这个 ARP 广播封装进底层的 IP 组播(Multicast)报文中,在整个数据中心内进行泛洪(Flooding)。这种"数据面泛洪学习"机制在小规模网络中勉强可用,但在数万节点的智算中心里,无处不在的广播风暴会瞬间瘫痪整个网络的 CPU。
我们需要一个"大脑"来统一管理数千万个 MAC 地址和 IP 地址与 VTEP 之间的映射关系。最终,网络极客们找到了最强大的武器:BGP(边界网关协议)。
是的,就是那个支撑着全球互联网(Internet)运转的、以极其稳定和可扩展著称的 BGP。经过扩展后,它演变成了 MP-BGP EVPN(RFC 7432 / 8365)。
EVPN 的核心思想是颠覆性的:将二层的 MAC 地址学习,从"数据面的广播泛洪"升级为"控制面的 BGP 路由传递"。
这意味着,当一台 Leaf 交换机(VTEP)下接入了一台新的 GPU 服务器时,它不会去发广播,而是立刻生成一条 BGP 路由更新报文,将这台服务器的 MAC 地址 + IP 地址 + 所在的 VNI,作为路由前缀宣告给全网。
在极其复杂的 Cisco Nexus、Huawei CloudEngine 或 H3C S 系列数据中心交换机的 CLI 配置中,工程师们利用 NETCONF/RESTCONF 接口或高级的 IBN(基于意图的网络)控制器,向交换机下发错综复杂的 EVPN 策略。为了实现这一切,EVPN 定义了多种极其晦涩但功能强大的路由类型(Route Types):
- Type 2 (MAC/IP Advertisement Route): 这是 EVPN 的绝对核心。它同时宣告了租户的 MAC 地址和主机的 /32(IPv4)或 /128(IPv6)主机路由。正是通过 Type 2 路由,EVPN 实现了 ARP 抑制(ARP Suppression),并在 Spine-Leaf 架构中完美支持了分布式 Anycast 网关(所有 Leaf 交换机的租户网关 IP 和 MAC 完全一样,虚拟机热迁移时网关永远在身边)。
- Type 3 (Inclusive Multicast Ethernet Tag Route): 用于自动化发现其他的 VTEP 节点,并构建头端复制(Head-End Replication)列表,彻底取代了底层的 IP 组播树,处理必须的 BUM 流量(Broadcast, Unknown unicast, Multicast)。在智算环境中,虽然大部分是点对点的高速单播,但在集群初始化、节点发现和特定同步信号下,BUM 流量依然是不可或缺的基础机制.
- Type 5 (IP Prefix Route): 用于宣告租户的网段路由(如 10.1.1.0/24),实现跨子网的三层路由(对称 IRB 或非对称 IRB 架构下的分布式三层互通)。
通过将 VXLAN(数据面封装)与 BGP EVPN(控制面路由)强强联合,智算中心构建了一张看似无懈可击的多租户算力大网。不同的租户被封印在不同的 VNI 和 MAC-VRF(虚拟路由转发实例)中,他们的路由表通过极其严格的 Route Target (RT) 机制进行导入(Import)和导出(Export)隔离。
在这个完美的数学与协议模型中,租户 A 绝无可能窥探到租户 B 的大模型训练数据。网络架构师们安稳地睡去了,确信这套底座坚不可摧。
然而,网络安全的第一定律永远是:任何协议的极度复杂化,必然伴随着攻击面的极度扩张。
三、 算力底座的破窗效应:VXLAN/EVPN 架构下的原生脆弱性
当这套极其复杂的 SDN 底座从图纸走向物理机架,特别是在追求极致性能的 AI 算力场景下,一些深藏于协议基因中的脆弱性开始暴露。对于一个深谙网络底层协议的国家级 APT 组织或内部的恶意租户来说,看似坚不可摧的 VXLAN/EVPN 隔离墙,实际上到处都是"破窗"。
3.1 VNI 欺骗与流量越权(VNI Spoofing and Hopping)
在理论模型中,VTEP 位于 ToR 交换机上,租户虚拟机发出的裸以太网帧在进入交换机端口时,由交换机硬件 ASIC 强制打上对应的 VNI 标签。这种基于物理端口的划分是相对安全的。
然而,智算中心的架构正在发生剧变。为了进一步释放 CPU 算力并实现更细粒度的网络控制,DPU(Data Processing Unit)或 SmartNIC(智能网卡) 开始被大规模部署。VTEP 的功能正在从柜顶交换机"下沉"到插在服务器 PCIe 插槽上的智能网卡中。
这就意味着,VXLAN 隧道的起点,从网络设备延伸到了计算设备的边界。
如果一个极其高端的攻击者(租户 A)通过某个 0-day 漏洞,获取了其租用的 GPU 服务器上的 Root 权限,并进一步渗透、攻破了该服务器上的 DPU 操作系统(DPU 通常运行着一个裁剪版的 Linux,且极少被安全软件扫描),这就等同于攻击者接管了 VTEP 的数据面封装引擎。
在这个极其恐怖的场景下,租户 A 可以编写自定义的 eBPF 程序或直接调用 DPDK 接口,在其发出的网络数据包的 VXLAN 头部中,强制注入租户 B 的 VNI。
底层物理网络(Spine-Leaf 交换机)对于 UDP 数据负载内部的内容是完全不检查的(为了保证线速转发,硬件 ASIC 只看外层的物理 IP 和 UDP 端口)。当这个带有伪造 VNI 的恶意数据包到达目标宿主机时,目标端 VTEP 会正常解封装,并根据那个被伪造的、属于租户 B 的 VNI,将这个含有恶意 payload(例如针对数据库的 RCE 攻击代码)的数据包,精准地投入到租户 B 戒备森严的虚拟网络内部。
这种攻击彻底绕过了所有的上层防火墙和微分段策略,实现了真正意义上的"降维越权穿越"。
3.2 控制面中毒:BGP EVPN 路由的隐秘污染
如果说修改数据面的 VNI 是"蛮力强突",那么针对控制面 BGP EVPN 的攻击,则是网络世界中最高阶的"精神控制"。
BGP 协议最初是为互信的运营商设计的,其默认的安全机制极度薄弱。在 EVPN 架构中,如果攻击者能够以某种方式(例如利用自动化运维平台的配置漏洞,或者攻陷了负责下发配置的 IBN 控制器/SDN 控制器集群中的某个微服务)向控制面注入恶意的 EVPN 路由更新,整个算力底座的隔离逻辑将瞬间崩溃。
1. Type 2 路由黑洞与中间人拦截(MITM)
假设租户 B 正在分布式训练节点 Worker-1 (IP: 10.0.0.1) 和 Worker-2 (IP: 10.0.0.2) 之间高频同步梯度数据。攻击者利用被攻陷的控制面权限,向 BGP 反射器(Route Reflector, RR)伪造并发送了一条针对 Worker-2 IP/MAC 地址的 Type 2 路由更新,但将该路由的 Next-Hop(下一跳 VTEP IP)指向了攻击者控制的节点 Hacker-VTEP。
由于 BGP 的路由优选原则,所有发往 Worker-2 的大模型参数数据包,都会在底层的物理 Spine 交换机上发生重定向,被源源不断地送入黑客的服务器。黑客可以记录这些极其昂贵的专有模型权重(Model Weights),然后再通过另一个隧道悄悄转发给真正的 Worker-2。在受害者看来,训练依然在进行,损失的仅仅是几微秒的延迟,而他们耗资数千万美元训练出的千亿大模型参数,已经在暗网的硬盘中被完美镜像。
2. Type 3 路由爆炸与算力瘫痪
更具破坏性的是针对 EVPN Type 3 路由(用于处理 BUM 组播流量)的攻击。攻击者可以通过自动化脚本,极其疯狂地向控制面宣告海量的、虚假的 VTEP 节点信息和 Type 3 路由。
BGP 协议本身对状态机的处理非常消耗 CPU。当全网数以百计的 Leaf 交换机在极短时间内收到数百万条恶意的 EVPN 路由前缀时,交换机的控制面 CPU(通常只是性能孱弱的嵌入式处理器,如 ARM Cortex 或老旧的 MIPS)会被瞬间打满(100% 占用率)。
这种 BGP 路由表溢出攻击(Route Table Exhaustion) 会导致合法的路由无法收敛。更糟糕的是,底层的 ASIC 硬件转发表(FIB, Forwarding Information Base)/TCAM 空间是极其有限的。当 TCAM 被恶意虚假条目塞满后,智算中心的交换机只能无奈地将后续合法的 AI 训练流量"上送(Punt)"给 CPU 进行慢速软件转发。原本微秒级的延迟瞬间暴涨到几百毫秒,整个几万张 GPU 的 All-Reduce 通信彻底超时,一场极度昂贵的训练任务就此崩溃。
3.3 无损网络的阿喀琉斯之踵:PFC 死锁与拒绝服务风暴
我们前面提到,为了让 RDMA(RoCEv2)在以太网上跑出极致性能,智算中心启用了 PFC(基于优先级的流量控制)。PFC 的原理极其简单粗暴:当一台交换机的某个端口缓冲队列(Buffer Queue)即将满了的时候,它会向上一跳设备发送一个 PFC Pause 帧(暂停帧),强制要求上一跳停止发送该优先级的所有流量,直到本地队列腾出空间。
这个机制在理想状况下能保证零丢包,但在存在恶意攻击者的多租户环境中,它却变成了一个足以瘫痪全网的超级武器。
假设攻击者(租户 A)租用了一批服务器。他不需要攻破任何加密协议,也不需要寻找任何软件漏洞,他只需要利用极其深厚的网络底层知识,发动一场**"PFC 风暴(PFC Storm)"**。
在排队论(Queueing Theory)模型中,网络节点的缓冲区状态 Q(t) 受数据到达率 \lambda 和服务率 \mu 影响。当攻击者恶意构造特定的微突发流量(Microbursts),使得 \lambda \gg \mu 时,攻击端连接的 ToR 交换机队列会被瞬间打满。
更阴险的是,攻击者可以在自己的服务器上,恶意修改网卡驱动,使其无视上游交换机发来的 PFC Pause 帧,继续疯狂注入数据。
这将导致极其恐怖的连锁反应:
- 第一跳 Leaf 交换机的队列彻底耗尽,它被迫向上游的 Spine 交换机发送 PFC Pause 帧。
- Spine 交换机收到暂停帧后,停止向该 Leaf 交换机转发数据,导致 Spine 交换机自身的队列也迅速积压。
- Spine 交换机被迫向连接它的所有其他 Leaf 交换机发送 PFC Pause 帧。
这种现象被称为 "拥塞树蔓延(Congestion Tree Spreading)"。
最致命的问题在于,虽然 VXLAN/EVPN 可以在逻辑上将租户 A 和租户 B 的 IP 网段死死隔离,但物理交换机的缓冲队列和底层光纤的带宽是整个智算中心共享的资源。
当租户 A 故意制造的 PFC Pause 风暴席卷整个 Spine 层时,由于底层的物理排队机制发生了线头阻塞(Head-of-Line Blocking, HoL),即使是属于租户 B 的、完全合法且极其重要的 AI 训练流量,也会因为底层物理端口的阻塞而被无限期暂停。
在这场不需要任何一行恶意代码、纯粹利用物理网络协议机制发动的"拒绝服务(DoS)"攻击面前,高高在上的大模型算法工程师们只会看到控制台上的 GPU 算力利用率(MFU)诡异地跌向 0%。他们会绝望地检查自己的 Python 代码、检查 PyTorch DDP 框架的集合通信接口,却永远无法想到,在他们不可触及的网络底层真空地带,一场利用以太网流控机制发起的物理降维绞杀,已经彻底摧毁了整个智算中心的算力基石。
3.4 梯度篡改与模型投毒(微秒级的"基因编辑")
如果说拒绝服务(DoS)是极其喧闹的破坏,那么最高阶的 APT 攻击往往是静默的。在分布式训练的 All-Reduce 过程中,各个 GPU 节点会通过无损网络极其频繁地同步模型权重(Weights)和梯度(Gradients)。
假设恶意租户通过 DPU 提权或中间人劫持(如前面提到的 BGP 路由重定向),并没有选择阻断流量,而是利用 eBPF 或可编程交换机在数据面上进行"微秒级的位翻转(Bit-flipping)"。攻击者通过精准解析以太网帧内的 RoCEv2 负载,在梯度数据包飞越 Spine 交换机的瞬间,极其微小地修改某些参数的浮点数值。
底层的物理校验(FCS)可以被硬件重新计算并掩盖,而上层的训练框架(如 PyTorch)只会将这些被篡改的脏数据当成正常的计算结果吸收进模型中。这场攻击不会引发任何网络告警,甚至连吞吐量都没有下降,但经过数周耗资上千万美元的训练后,受害者得到的将是一个逻辑错乱、甚至潜伏着预设后门(Backdoor)的废品模型。这种直接从网络底层对 AI 模型进行"基因编辑"的降维打击,是当前智算中心最令人毛骨悚然的隐患之一。
四、 零信任数据面:从 DPU 到智能网卡的硬核微隔离
面对上述四大致命的"降维打击"(VNI 欺骗、BGP 投毒、PFC 风暴以及静默的模型投毒),传统的边界防火墙已经完全失效。防守方必须展开针对性的"三维反击":在数据面实现硬件级微隔离(第四章),在控制面引入闭环验证(第五章),并在物理链路层彻底重构拥塞控制算法(第六章)。
首当其冲的,便是数据面的改造。在动辄几十 Tbps 吞吐量的 Spine-Leaf 架构中,任何试图将东西向流量牵引到集中式安全网关(Service Chaining)进行清洗的做法,都会瞬间引爆网络延迟,彻底摧毁大模型分布式训练(如 Megatron-LM 的张量并行)所需的微秒级同步节拍。
因此,智算中心安全架构的第一次大迁徙,是安全边界的"绝对下沉"------从柜顶交换机(ToR)下沉到每一台物理服务器的 PCIe 插槽上。在这个过程中,DPU(Data Processing Unit,数据处理单元)与 SmartNIC(智能网卡)成为了捍卫算力底座零信任数据面的核心物理锚点。
4.1 VTEP 的物理剥离与 DPU 隔离域
在上一代的云原生架构中,VTEP(VXLAN 隧道端点)要么实现在 ToR 交换机的硬件 ASIC 中,要么实现在宿主机操作系统的虚拟交换机(如 Open vSwitch, OVS)中。这两种方式在 AI 智算场景下都存在致命缺陷:
- ToR 硬件 VTEP: 粒度太粗。一旦攻击者攻陷了服务器,就可以在物理端口内伪造任何 MAC 和 VNI,ToR 交换机难以察觉。
- 宿主机 OVS VTEP: 安全性极度依赖于宿主机 OS 的内核。如果租户通过容器逃逸或 KVM 漏洞提权获得了宿主机 Root 权限,他们就能直接修改 OVS 的流表(Flow Table),随意篡改 VXLAN 封装的头部。
DPU 的引入,在物理层面上彻底切断了这种信任链的崩塌。
现代 DPU(如 NVIDIA BlueField、华为芯擎或基于 ARM 架构的自研芯片)本质上是一台插在服务器内部的"独立微型计算机"。它拥有独立的带外管理网口、独立的多核 ARM 处理器(运行隔离的嵌入式 Linux 操作环境,如 Ubuntu-DPU)、以及极其强大的网络硬加速 ASIC/FPGA。
在安全架构上,我们将所有的网络控制面(BGP EVPN 代理)、数据面封装(VXLAN Encap/Decap)、以及 RoCEv2 的拥塞控制状态机,全部从宿主机的 CPU 剥离,"硬卸载(Hardware Offload)" 到 DPU 中运行。
对于宿主机(也就是租户正在运行 AI 训练的计算环境)来说,DPU 呈现的只是一个极其简单的、标准的以太网网卡(VF, Virtual Function)或者是一个裸金属的 RDMA 设备。租户的 Root 权限被物理锁定在宿主机 OS 内部,他们对插在 PCIe 插槽上的 DPU 操作系统完全没有访问权限。
即使恶意租户编写了最底层的 C 代码试图伪造带有其他租户 VNI 的数据包,当这个裸数据帧通过 PCIe 总线到达 DPU 时,DPU 内部的硬件查表引擎(基于精确匹配的 eBPF 或可编程 P4 管道)会进行强制的身份校验:
- "端口 VF-3 发来的数据包,其分配的合法 VNI 只能是 50001。"
- "如果检测到负载中企图注入其他 VNI,或者源 MAC 地址与管控平台下发的表项不符,直接在硬件流水线的第 0 纳秒执行 DROP 操作。"
这种架构实现了真正意义上的**"物理级微隔离(Micro-segmentation)"**。攻击者的权限被死死钉在了计算域,永远无法触碰网络封装的上帝之手。
4.2 信任的终极锚点:硬件信任根(RoT)与安全启动
物理隔离固然美好,但如果 DPU 自身的固件在出厂或升级时被植入了后门呢?面对国家级 APT 组织,防御必须深入到芯片的硅晶层面。 现代高级 DPU 强制引入了硬件信任根(Hardware Root of Trust, RoT)。在 DPU 每次上电时,集成在不可篡改的 ROM 中的微代码会首先启动,验证第一级 Bootloader 的数字签名;随后 Bootloader 验证 DPU 操作系统的内核;内核再验证加载的 eBPF 程序。这条牢不可破的信任链(Chain of Trust)确保了,即使攻击者拥有宿主机的所有权限,甚至试图通过刷写固件的方式永久控制 DPU,也会因为缺乏厂商的私钥签名而在启动的第 0 秒被直接变砖,从物理上斩断了高级持续性威胁(APT)的生存土壤。
4.3 极速密码学:硬件 MACsec 与 IPsec over VXLAN
解决了身份伪造问题后,我们必须面对 VXLAN 协议的原生缺陷:明文传输。
在极其敏感的智算中心(例如多个国家级研究机构共享算力池,或者处理涉及金融、医疗隐私数据的多模态大模型),仅仅通过 VNI 隔离是不够的。底层的光纤分光器窃听、Spine 交换机端口镜像的恶意配置,都有可能导致大模型参数的直接泄露。
加密是唯一的出路。但在以 Tbps 计的无损以太网中,传统的 CPU 软件加密(如 OpenSSL)会成为整个算力集群的性能黑洞。
为了在不增加任何肉眼可见延迟的前提下实现数据面加密,智算中心启用了基于物理层/链路层的 MACsec(IEEE 802.1AE) 以及由 DPU 硬件加速的 IPsec over VXLAN。
- MACsec(逐跳加密): 在 Leaf 到 Spine 的每一段物理光纤上,交换机底层的 PHY 芯片或 MAC 芯片利用 AES-256-GCM 算法对整个以太网帧(包括 VXLAN 头部)进行线速(Line-rate)加密。这种加密是在极低层进行的,延迟增加通常在几十纳秒(ns)级别,对 RoCEv2 的无损特性几乎没有影响。它防御的是物理光纤被搭线窃听的风险。
- IPsec over VXLAN(端到端加密): 这是更高维度的租户级防护。DPU 内部集成了强大的密码学协处理器(Crypto Accelerator)。当宿主机发出数据时,DPU 先将其封装成 VXLAN 报文,随后立即在硬件流水线中套上 IPsec ESP 头部,完成端到端的硬件加密。只有目标端 DPU 拥有对应的解密密钥。这意味着,即使底层的网络管理员被买通,他们通过交换机抓取到的,也只是一堆毫无意义的高熵随机乱码,彻底斩断了"内鬼"窥探模型权重的可能。
五、 控制面的绝对净化:BGP EVPN 的安全加固与意图网络(IBN)
如果说 DPU 守住了数据面的大门,那么控制面(BGP EVPN)就是整个智算中心网络的大脑。在上篇中我们分析了,通过注入恶意的 Type 2(MAC/IP)或 Type 3(组播)路由,攻击者可以轻易制造路由黑洞、流量劫持甚至导致交换机 TCAM 表项溢出的拒绝服务攻击。
要净化 BGP EVPN 的控制面,我们需要将零信任原则引入路由协议的交互中,并利用自动化技术实现协议状态的实时校验。
5.1 控制面多维防御:从 CoPP 到严格的 Route-Target 过滤
传统的网络设备默认对所有 BGP 邻居发来的路由更新照单全收。在多租户智算环境中,第一道防线必须是极其苛刻的控制面监管(Control Plane Policing, CoPP)与路由过滤策略。
- 控制面限速(Rate Limiting): 针对 EVPN Type 3 路由爆炸攻击,工程师必须在所有的 Leaf 和 Spine 交换机上配置严格的 CoPP 策略。系统会监控发往 CPU 处理的 BGP Update 报文速率。如果某个 VTEP 节点(或 DPU)在短时间内发送了超过基线阈值的 MAC 地址漂移(MAC Mobility)更新或路由通告,硬件 QOS 队列会立即执行尾部丢弃(Tail Drop),从而保护核心交换机 CPU 不被恶意请求打挂。
- 严格的 RT(Route Target)导入/导出验证: BGP EVPN 依赖扩展团体属性(Extended Community)中的 Route Target 来控制路由的泄漏。智算中心的 SDN 控制器必须对每一台设备的 BGP 配置进行数字签名和基线锁定。任何租户 VTEP 只允许宣告携带其自身分配 RT 的路由。如果在 Spine 交换机的 Route Reflector(反射器)上检测到非法的跨租户 RT 注入尝试,该路由更新会被立刻阻断,并通过 Syslog 触发最高级别的安全告警。
- BGPsec 与 EVPN 路由源验证: 借鉴互联网骨干网的 RPKI(资源公钥基础设施)机制,高阶的智算中心网络正在引入局域网级别的路由签名。每一个合法的 VTEP 节点在宣告 EVPN 路由时,必须附带基于数字证书的加密签名。接收端设备通过校验签名链,确保该路由(例如 "10.0.0.1/32 属于 VNI 50001 且位于 VTEP-A")确实是由拥有该网段合法授权的节点发出的,从根本上杜绝了中间人欺骗和路由黑洞。
5.2 意图驱动网络(IBN):控制面状态的"闭环验证"
面对极其庞大且复杂的 EVPN 状态机,仅仅依靠静态的安全策略配置是不够的。网络的物理状态随时在变化,微小的配置漂移(Configuration Drift)都可能引发连锁的安全灾难。
基于意图的网络(Intent-Based Networking, IBN) 架构,成为了智算中心控制面防御的终极大脑。
传统的网络运维是"命令式"的(例如通过 CLI 输入 router bgp 65000)。而 IBN 是"声明式"的。网络架构师在顶层控制器中输入的是高阶的业务意图(Intent):
- "租户 A 的大模型训练集群必须与外部互联网绝对物理隔离,且内部各节点间必须保证 400Gbps 的无阻塞互通。"
IBN 控制器(如 Cisco Nexus Dashboard 或自研系统)会将这些意图自动编译成底层设备的 NETCONF/YANG 模型,并通过 gRPC 协议并发推送到成千上万台交换机和 DPU 上。
但这仅仅是开始,IBN 在安全上的核心价值在于连续状态验证(Continuous Validation)。
控制器会通过 Telemetry(网络遥测) 技术,以毫秒级的频率,源源不断地从所有交换机的 ASIC 芯片和 CPU 中拉取当前的实际运行状态(包括 BGP 邻居状态、EVPN 路由表、MAC-VRF 实例详情)。
在后台,IBN 维持着一个巨大的图数据库(Graph Database)。它将"网络当前应有的逻辑状态(意图)"与"通过 Telemetry 采集到的物理真实状态"进行极其严密的数学比对计算。
假设一个潜伏的攻击者利用某个 0-day 漏洞,在某台 Leaf 交换机内部偷偷篡改了一条静态的 VXLAN 隧道指向,或者修改了 MAC 表项。在传统的 SNMP 监控体系下,只要端口没断,这种逻辑层面的恶意篡改可能潜伏数月都无法被发现。
但在 IBN 架构下,状态的校验是闭环的、实时的。只要控制器发现"实际收集到的 EVPN 路由拓扑图"与"系统意图库中的白名单模型"产生了哪怕一个节点的偏差,它就会立即判定控制面被污染。系统可以瞬间触发自动化 Remediation(修复)脚本,利用 NETCONF RPC 重置该交换机的 BGP 进程,或者直接在物理层 Down 掉受污染的端口,将威胁锁定在极小的爆炸半径内。
5.3 全息流量透视:突破传统镜像的监控盲区
你无法防御你看不见的东西。在传统的企业网中,我们通过端口镜像(SPAN)或 NetFlow 采样来监控异常流量。但在智算中心,这套机制彻底破产了。
面对几万张 GPU 产生的数百 Tbps 洪流,任何物理探针都无法全量接收镜像流量;而传统的 1:1000 NetFlow 采样率,对于持续时间只有几百微秒的 RoCEv2 微突发(Microburst)来说,无异于盲人摸象,根本抓不到 PFC 风暴的源头。
为了在不牺牲线速的前提下获得可见性,智算中心启用了基于 DPU 硬件卸载的全息流遥测(Hardware-Accelerated Flow Telemetry)。DPU 内部的 ASIC 引流引擎不再对数据包进行采样,而是为途经的每一条"微流(Micro-flow)"在硬件内存中实时维护状态表。它可以精确记录每一条会话的五元组、建立时间、字节数、甚至 TCP/RoCEv2 的拥塞窗口变化。一旦探测到异常的短时高频发包(如潜在的 DDoS 或流量越权试探),DPU 会直接在本地将警报元数据(Metadata)通过带外网络(OOB)发送给控制中枢,从而在不占用任何业务带宽的情况下,实现了对算力底座零死角的全息透视。
六、 无损网络的护城河:驯服 PFC 风暴与拥塞控制革命
上篇中提到的 PFC 死锁(PFC Deadlock)和 PFC 风暴,是由于 RoCEv2 协议过度依赖链路层被动流控机制而产生的物理级降维打击。当攻击者恶意构造微突发流量,导致整个 Spine-Leaf 架构的缓冲队列发生雪崩式的级联阻塞时,再强大的加密和隔离也无济于事,因为高速公路本身已经彻底堵死了。
为了保卫大模型训练不可或缺的无损网络(Lossless Network)底座,架构师们必须从被动的"堵塞反馈"走向主动的"精细化拥塞控制"。
6.1 物理交换机的最后防线:PFC Watchdog 机制
首先,必须在物理交换机层面建立针对 PFC 级联效应的熔断机制。现代数据中心级交换机(如采用 Broadcom Tomahawk 系列芯片的设备)硬件支持一种名为 PFC Watchdog(PFC 看门狗) 的防死锁技术。
PFC Watchdog 的原理是监控每一个端口和每一个优先级队列接收 PFC Pause 帧的持续时间。
- 检测阶段(Detection): 当 Watchdog 探测到某个端口在极度反常的时间内(例如持续几百毫秒,远超正常的网络拥塞周期)一直处于接收 Pause 帧的暂停状态,系统就会判定该队列已经陷入了由恶意攻击或软件 Bug 引发的"PFC 死锁(Deadlock)"。
- 熔断阶段(Recovery/Drop): 在死锁被确认的瞬间,为了防止拥塞树向全网蔓延,交换机硬件 ASIC 会做出极其果断的决定------无视收到的 PFC Pause 帧,强行恢复该端口的报文转发,或者更彻底地,直接清空并丢弃(Drop)该队列中堆积的所有数据包。
对于 RoCEv2 来说,丢弃报文是极度痛苦的,它会导致上层应用的高延迟重传。但这就像是在森林大火中砍伐出一条隔离带,通过牺牲局部的一小部分恶意或异常流量,保全了整个智算中心核心 Spine 网络的畅通,防止了全网算力的休克。
6.2 从被动到主动:拥塞控制算法的进化(DCQCN 与 HPCC)
然而,PFC Watchdog 仅仅是最后的兜底手段。要从根本上免疫 PFC 攻击,智算中心必须抛弃粗放的链路级暂停,转而拥抱基于端到端(End-to-End)的高级网络拥塞控制(Congestion Control, CC)算法。
1. 经典的妥协:DCQCN(Data Center Quantized Congestion Notification)
这是目前应用最广泛的 RoCEv2 拥塞控制算法。它结合了 ECN(显式拥塞通知)和 PFC 的特性。
当中间交换机的队列深度超过设定阈值(但还没满)时,交换机不会发送粗暴的 PFC 暂停帧,而是会在转发数据包的 IP 头部中打上 ECN 标记。目标端网卡收到带有 ECN 标记的包后,会向源端网卡发送一个 CNP(Congestion Notification Packet,拥塞通知报文)。
源端网卡(如 DPU)收到 CNP 后,会主动在硬件层面降低发送速率(Rate Limiting)。其速率更新遵循 AIMD(加性增乘性减)的数学模型,例如目标速率 R_t 的更新公式:
如果网络健康,未收到拥塞通知,速率进行加性增加:
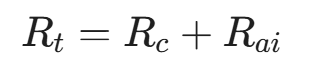
如果收到拥塞通知(CNP),速率进行乘性急剧下降(其中 α 是动态更新的拥塞因子):
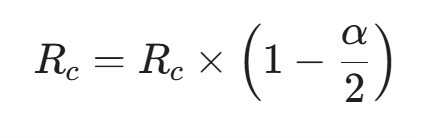
通过 DCQCN,网络将原本会触发 PFC 风暴的微突发流量,在源头就被平滑地压制了下去,使得物理队列始终保持在健康水位以下。
2. 极客的狂欢:HPCC(High Precision Congestion Control)与 INT 技术
尽管 DCQCN 很优秀,但它依赖于单一维度的 ECN 标记,反应依然不够快。在追求极致的大模型训练集群中,任何试探性的发包都会浪费宝贵的带宽。
于是,业界推出了革命性的 HPCC(高精度拥塞控制) ,其核心武器是 INT(In-band Network Telemetry,带内网络遥测)。
INT 是一种令人惊叹的硬件技术。当一个数据包穿过智算中心的网络拓扑(Leaf -> Spine -> Leaf)时,沿途的每一台物理交换机都会利用其 ASIC 芯片的强大能力,在数据包内部的专用 INT 头部空间中,线速地插入自身的精确遥测数据。
这些数据包括:该交换机的 ID、数据包到达该交换机端口时的精确纳秒级时间戳(Timestamp)、以及当前该端口队列被占用了多少字节(Queue Depth)。
当数据包最终抵达目标端 DPU 时,它已经变成了一个携带了沿途完整"网络气象数据"的探测器。
接收端根据这些极其精确的链路级数据,可以利用精准的数学公式直接计算出链路上的可用带宽和积压情况,并将指令迅速反馈给源端。
利用 HPCC 和 INT,我们彻底剥夺了恶意租户利用黑箱网络机制制造队列雪崩的土壤。因为源端的 DPU 完全掌握了全网的微秒级状态,它可以以极高的精度控制注入网络的流量速率。任何企图制造微突发拥塞的恶意发包器,其速率都会被底层的 HPCC 算法在纳秒级时间内死死钳制,无法在物理光纤上掀起一丝波澜。
七、 AI 守望 AI:算力底座的认知免疫系统
在拆解了从数据面微隔离(DPU)、控制面净化(IBN)到物理拥塞控制(HPCC)的复杂防御机制后,我们发现,维系智算中心底层安全的协议栈已经庞大到了人类工程师无法单纯依靠大脑去理解和运维的地步。
当我们在用成千上万张 GPU 去训练世界上最聪明的大模型时,为什么不利用这些 AI 自身的算力,来保护孕育它们的网络底座呢?
智算中心的终极防御形态,是演化出一个基于 AI 驱动的"网络认知免疫系统"。
7.1 图神经网络(GNN)重构网络空间
传统的异常检测往往将网络流量看作是一维的时间序列数据(比如单纯监控某个端口的吞吐量曲线)。但在 Spine-Leaf 架构中,VXLAN/EVPN 构成的是一个极其复杂的多维拓扑图。
现代安全架构正在引入图神经网络(Graph Neural Networks, GNN) 来监控底层的状态。
网络控制平台将物理的 Spine-Leaf 拓扑、逻辑的 VXLAN 隧道(VNI 映射)、BGP EVPN 的对等体关系、以及海量虚拟机的通信矩阵,全部抽象为一个庞大的知识图谱(Knowledge Graph)。图中的节点(Nodes)是交换机、DPU、虚拟机;边(Edges)是物理链路、隧道连接和业务流量。
随着时间推移,GNN 能够在海量正常 AI 训练周期的打磨下,学习到这个庞大拓扑图的"拓扑嵌入(Topological Embeddings)"基线。它不仅"理解"每个端口该有多少流量,它甚至理解在大规模 All-Reduce 集合通信发生时,整个网络矩阵的连通状态应当呈现出何种对称性的美感。
7.2 微爆发与"蝴蝶效应"的毫秒级猎杀
当一个隐藏极深的高级攻击者(APT),试图通过微调几台边缘服务器的发包频率,以期利用底层协议的某个 0-day 漏洞在几十跳之外的核心 Spine 交换机上引发一场拒绝服务拥塞(也就是网络空间中的蝴蝶效应)时。
传统的阈值告警系统根本不会报警,因为边缘节点的微小变化完全在合法范围内。
然而,在 AI 驱动的免疫系统中:
- 底层的 INT(带内遥测)以每秒数百万次的频率将全网微观状态输入给 GNN 模型。
- GNN 强大的空间聚合能力(Spatial Aggregation)能够在极短的时间内,敏锐地捕捉到这股微小扰动在多维图结构中的异常传播路径。
- 它会发现,虽然单点的行为看似合法,但在全局视图下,这几股离散的流量正在向同一个极易引发 PFC 死锁的薄弱节点汇聚。
在灾难发生前的一百毫秒,AI 免疫系统直接输出防御决策,联动 DPU 的 eBPF 引擎或交换机的可编程 ASIC,将那几台被黑客控制的边缘服务器瞬间打入隔离 VNI 域,彻底切断物理连接。
这是一场没有硝烟的秒级对决。AI 算法在暗网中猎杀着恶意的探针,而它们保护的,正是另一批正在改变人类历史进程的 AI 大模型。
结语:黑暗森林的破晓------以彼之矛,铸造底座之盾
至此,这场发生在地底深处、光纤之间与硅片之上的智算中心网络暗战,我们已经完成了深度的解剖。
在这座由数以万计的复杂协议、顶级硬件与海量数据交织而成的迷宫中,多租户隔离与安全防御早已超越了传统意义上"部署一台防火墙"或"划分几个 VLAN"的古典范畴。它是计算机科学中最硬核、也最残酷的交叉领域:从数据面与控制面编织的虚拟幻境,到 DPU 劫持、BGP 路由投毒带来的致命危机;从纯粹网络协议逻辑的攻防,一路厮杀到基于硬件流水线、芯片级极速密码学,乃至深入排队论数学模型的拥塞控制革命。
在这个算力为王的时代,智算中心的底层网络不仅是一条信息高速公路,它本身就是一台极度精密且随时处于临战状态的战争机器。作为数字世界的架构师,我们必须时刻铭记网络安全的第一性原理:没有任何一种纯虚拟化的技术是绝对隔离的。只要计算单元依旧运行在同一个物理底座、共享同一根光纤之上,微观的物理反馈法则(延迟、拥塞、热量)就永远是悬在逻辑隔离墙上方的达摩克利斯之剑。
然而,技术亦在极致的攻防对抗中涅槃。从传统的手工 CLI 路由走向意图网络(IBN)的闭环验证,从被动粗暴的 PFC 丢包走向高精度主动流控(HPCC),直至最终引入图神经网络(GNN)觉醒出"认知免疫系统"。这套名为"硅基之盾"的防御体系,正在与它所孕育的 AI 智能一同疯狂进化。在这片算力争夺的黑暗森林中,只有将冷酷的物理规则、坚不可摧的密码学与最顶尖的人工智能深度融合,我们才能为人类文明驶向通用人工智能(AGI)的彼岸,铸就一块不可撼动的底层基石。
陈涉川
2026年04月10日