一、内存泄漏
新生代:绝大多数对象(比如方法里new出来的一个临时变量)都活不过 1 秒钟。它们在新生代被创建,用完马上就被当垃圾回收了。
老年代:如果一个对象在新生代里经历了多次清理都还没死(比如static静态变量、Spring 里的@Service 单例,或者是内存泄漏导致的幽灵对象),它就会被晋升到老年代。
GC (Garbage Collection)垃圾回收:内存不够用了,JVM 就会触发 GC 去清理死掉的对象
**Minor GC:**只清理新生代,速度极快,感觉不到
**Full GC大扫除:**大扫除时,整个项目必须暂停营业(Stop The World,简称 STW),所有的用户请求都会卡住,如果频繁发生 Full GC,系统就会一直卡顿。
**锯齿波:**随着用户不断访问,对象不断创建,内存占用直线上升(锯齿的上升沿);突然,触发了 GC,垃圾被瞬间清空,内存占用直线下降(锯齿的下降沿)。连在一起看,就是一个漂亮的锯齿状。如果发生内存泄漏(有进程占着位置不走),你会发现锯齿波的"谷底"越来越高。每次 GC 完,释放的内存越来越少。
①VisualVM监控
确保项目在 IDEA 里正跑着,按下电脑的Win+R 键,输入jvisualvm回车。弹出的界面左侧,双击项目,右边切到监视(Monitor)标签。
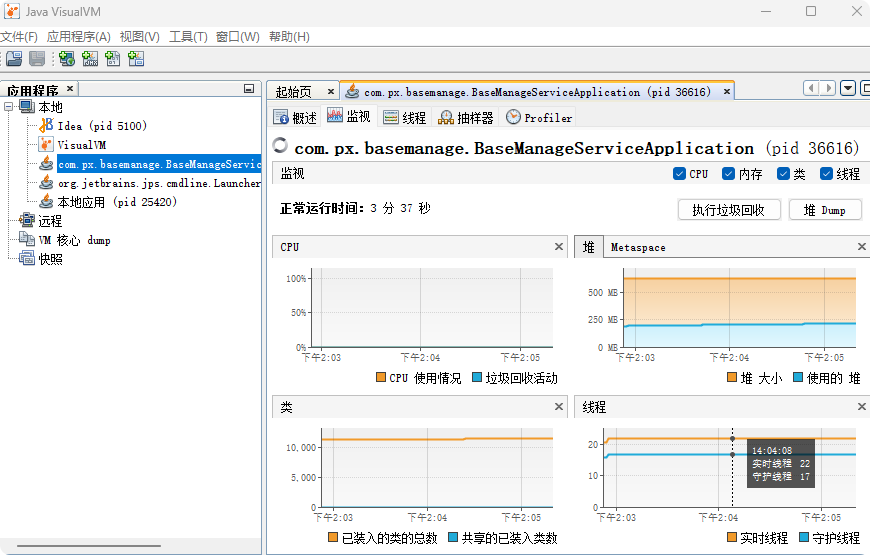
四个参数:
1、cpu蓝线代表 Java 程序(JVM)占用的 CPU,黄线代表整个服务器所有软件加起来占用的 CPU。
2、**堆 (Heap)**橙色区域表示总共分配给内存大小,蓝色区域表示当前实际使用的内存大小。若每次断崖式下跌后,掉到的最低点一次比一次高。说明有很多垃圾清理不掉没执行 remove。
3、类 展示了 JVM 当前加载了多少个**. class**文件,若系统运行了几天,这根线还在呈现 45 度角往上涨,通常发生了类加载器泄漏,可能程序在疯狂地动态生成代理类。
4、线程 :大面积出现红色,并且长时间不退。如果你写的代码里有两把锁互相锁住了对方(比如 A 等 B 放手,B 等 A 放手),VisualVM 的线程页面顶部弹出**"检测到死锁 (Deadlock detected)"**。
堆 Dump和线程 Dump可以查看到问题所在位置
②Arthas(阿尔萨斯)监控(流行)
不重启项目的情况下,动态潜入你的 Java 进程,适用于Linux 服务器
cmd输入 **curl -O https://arthas.aliyun.com/arthas-boot.jar**下载
接着在命令行启动 java -jar arthas-boot.jar
选择进程数字序号
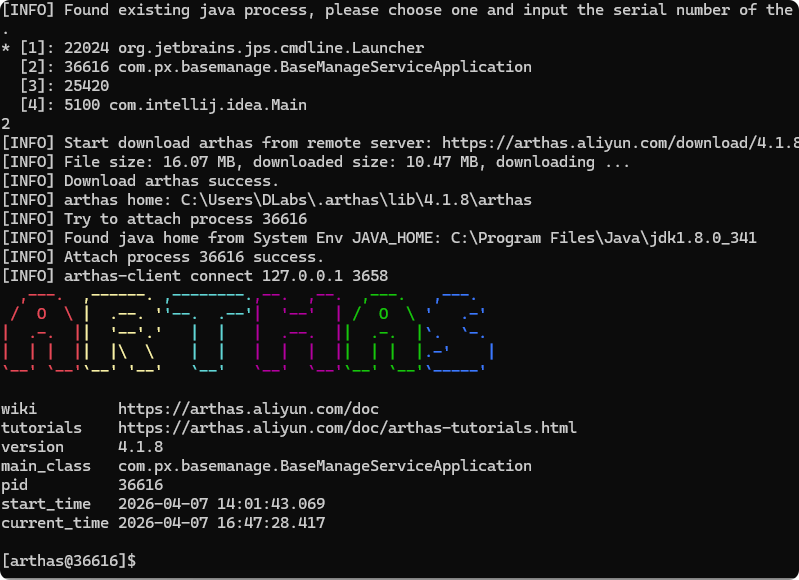
输入dashboard 看大盘,Ctrl+C退出面板
thread -n 3这会瞬间帮你找出当前系统里最耗费 CPU 的前 3 个线程
测性能:trace com.basemanage.platform.main.workflow.WorkflowEngineService pass
③Prometheus + Grafana监控(流行)
先安装探针
XML
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
bash
# 暴露所有的监控端点
management.endpoints.web.exposure.include=*
# 允许 Prometheus 抓取数据
management.endpoint.prometheus.enabled=true
# 给你的应用打个标签,方便在 Grafana 里区分
management.metrics.tags.application=BaseManageSys访问 http://localhost:8185/control/actuator
安装Prometheus时序数据库
下载 | Prometheus - Prometheus 监控系统
编辑prometheus.yml文件为以下
bash
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
# The label name is added as a label `label_name=<label_value>` to any timeseries scraped from this config.
labels:
app: "prometheus"
# 这是为你项目新增的抓取任务
- job_name: "spring-boot-basemanage"
metrics_path: "/control/actuator/prometheus"
scrape_interval: 10s # 每10秒去你的项目拉一次数据
static_configs:
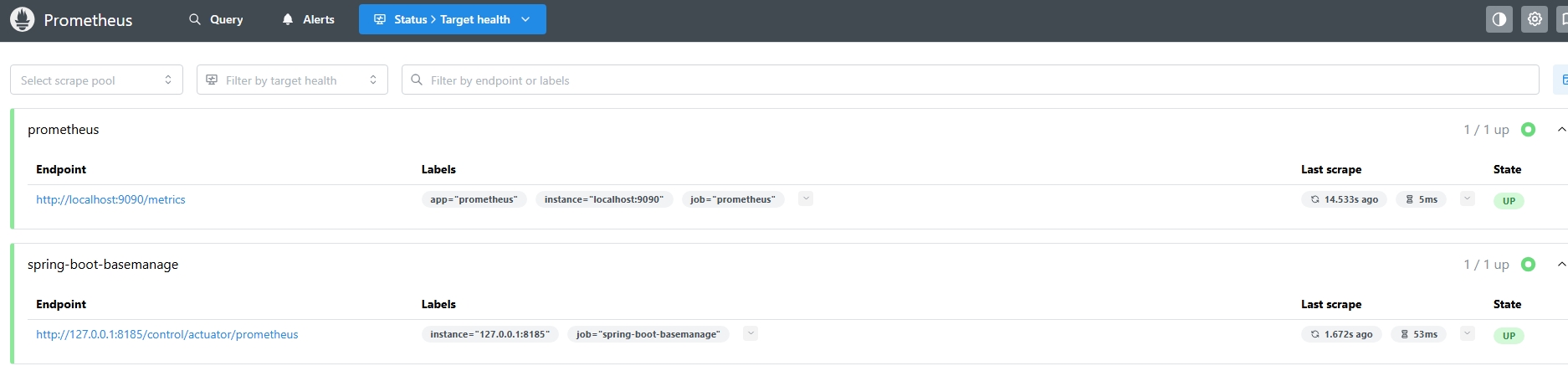
- targets: ["127.0.0.1:8185"]启动prometheus.exe 访问**http://localhost:9090/targets**,项目状态绿色up即为启动成功
安装Grafana
启动bin里的grafana-server.exe

配置数据源
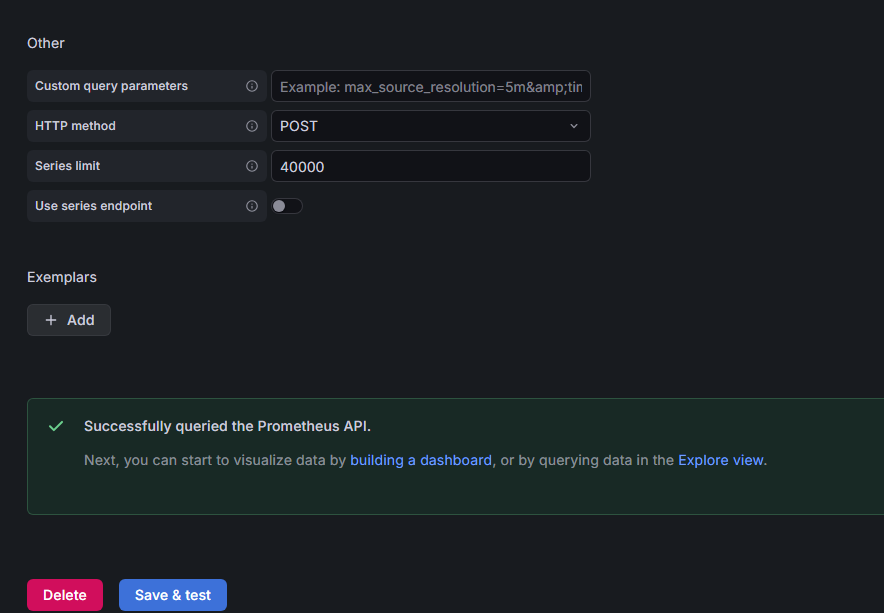
在左侧菜单栏点击齿轮图标(Configuration) 选择 Data sources。
点击蓝色的 Add data source 按钮。
选择 Prometheus, 在 HTTP 的 URL 框里,填入:localhost:9090
滑到最下面,点击 Save & test。如果提示绿色打勾,说明连接成功
点击加号图标(+)选择 Import(导入)。
在Import via grafana.com的输入框里,填入一个神奇的数字:4701 ,然后点击右侧的 Load。
在下一步页面最下方,Prometheus 下拉框里选择你刚才建好的数据源。
点击 Import 按钮
二、垃圾回收
java指北大佬总结JVM垃圾回收详解(重点)
1、判断垃圾 :采用可达性分析算法, JVM 会在内存里设立GC Roots ,顺着他们的引用一直找下去,相关的对象就是存活对象,找不到的就叫垃圾。内存泄漏的情况之一,不小心让某个GC Roots一直引用,永远认为那个对象还是活的,死活不回收。
2、**确认垃圾后清理:**不同区采用不同回收方法,下图三层为 新生代、老年代、永久代
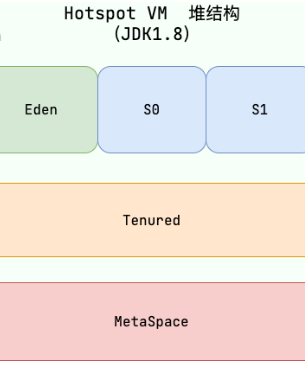
新生代
新生代是所有新对象出生的地方,对象多、死得快、存活率极低。
Minor GC采用复制算法, 被切分成了三个部分,比例通常是 **8 : 1 : 1。**Eden 区、Survivor 0 区、Survivor 1 区。先找Eden 区和Survivor 0 区活对象,移至Survivor 1 区,清空。下一轮找Eden 区和Survivor 1 区活对象,移至Survivor 0 区,清空。依次循环。
老年代
这里的对象存活率极高。包含了 Spring 的单例 Bean、常驻缓存、或者占用内存极大的长字符串/大数组。
Full GC采用**标记-整理算法,**找出所有活着对象和死掉的垃圾。把所有活着的对象,全部往内存的一端移动、靠拢,把活对象边界之外的所有内存,一刀切全部清空。保证内存的绝对连续和规整。