目录
[3.1 系统模型](#3.1 系统模型)
[3.2 分层Stackelberg博弈模型](#3.2 分层Stackelberg博弈模型)
[3.3 效用函数定义](#3.3 效用函数定义)
[3.4 分层Q学习原理](#3.4 分层Q学习原理)
[3.5 干扰机策略执行](#3.5 干扰机策略执行)
[3.6 计算即时奖励](#3.6 计算即时奖励)
1.引言
在智能干扰威胁环境下,通信系统面临的干扰不再是简单的固定频率干扰,而是具有学习能力的智能干扰机能够根据用户的通信行为自适应地调整干扰策略。传统的单层抗干扰方法(如仅在物理层进行跳频或仅在网络层进行路由选择)已难以有效应对此类智能干扰。因此,需要一种跨层联合抗干扰策略,同时在网络层进行路由选择和在物理层进行信道选择,从而提高通信系统的抗干扰能力。
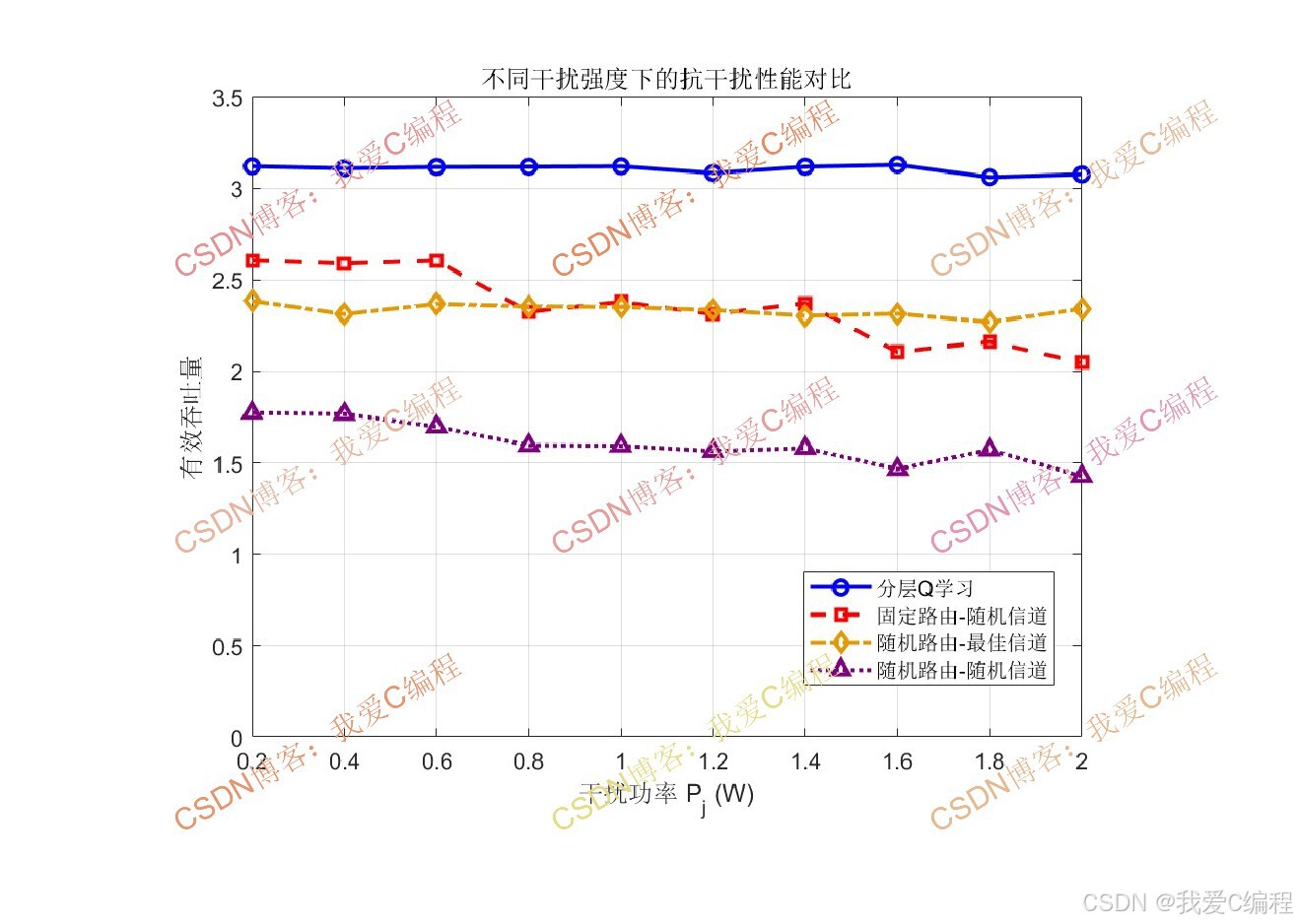
2.算法测试效果
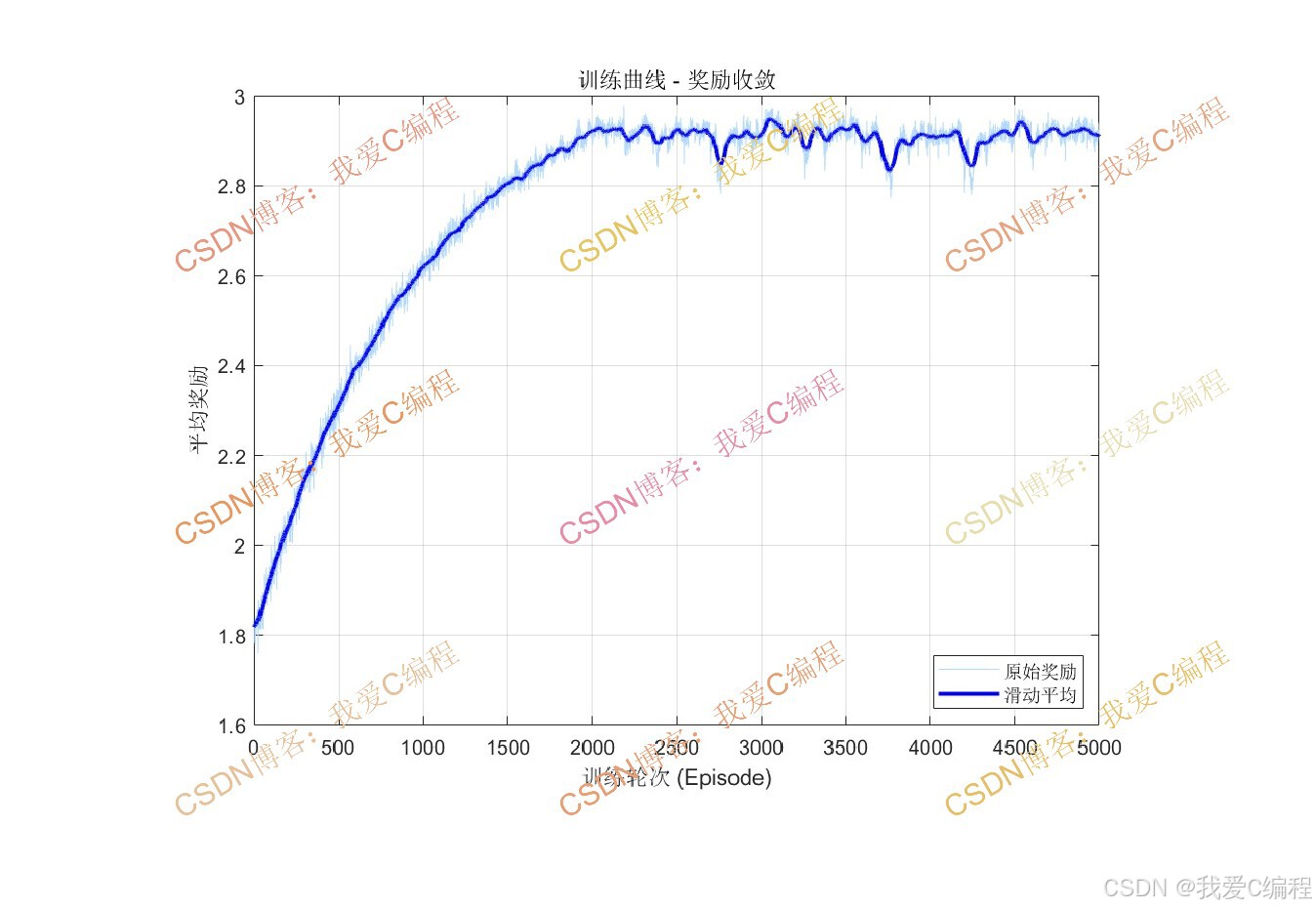
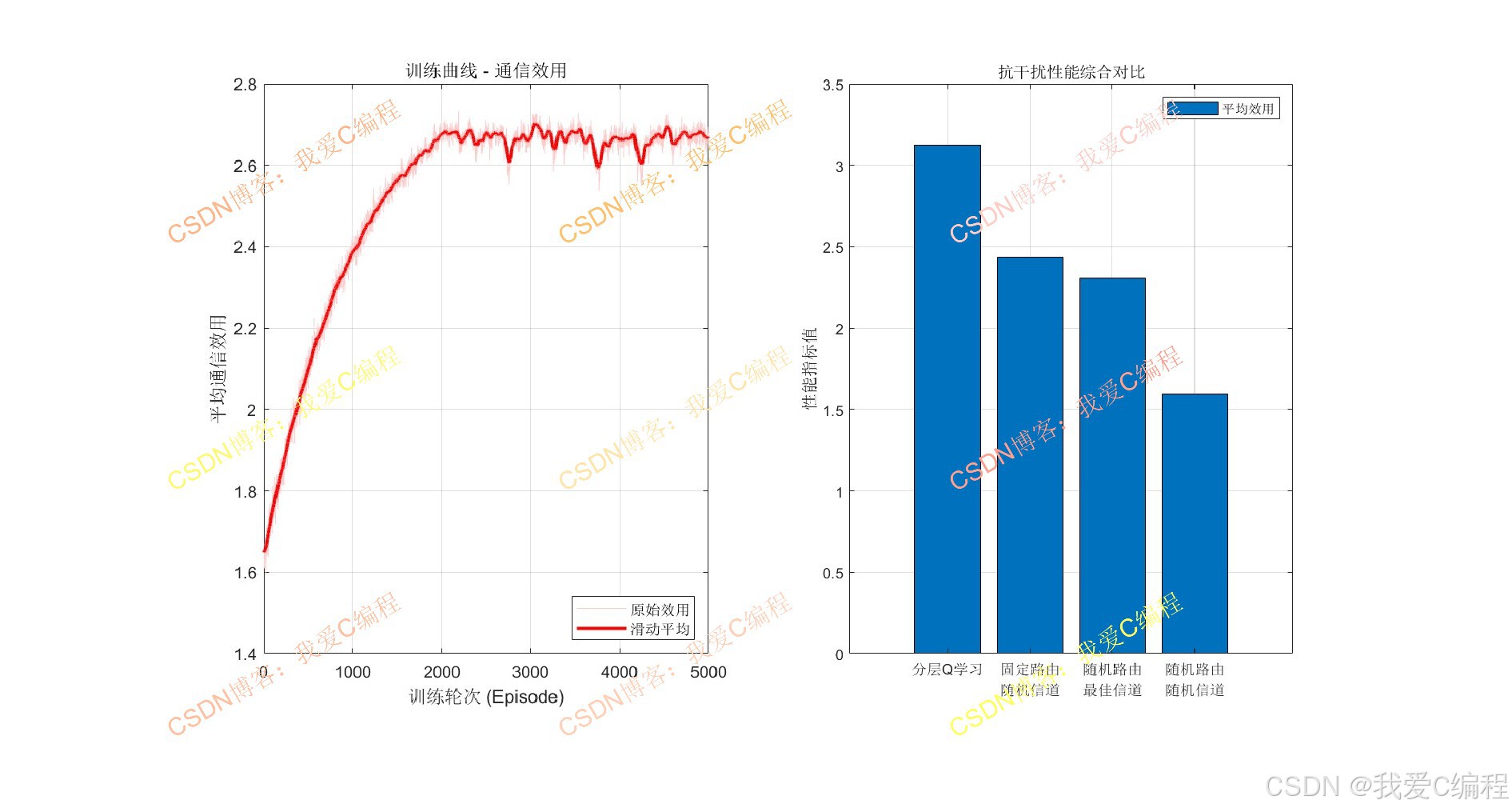
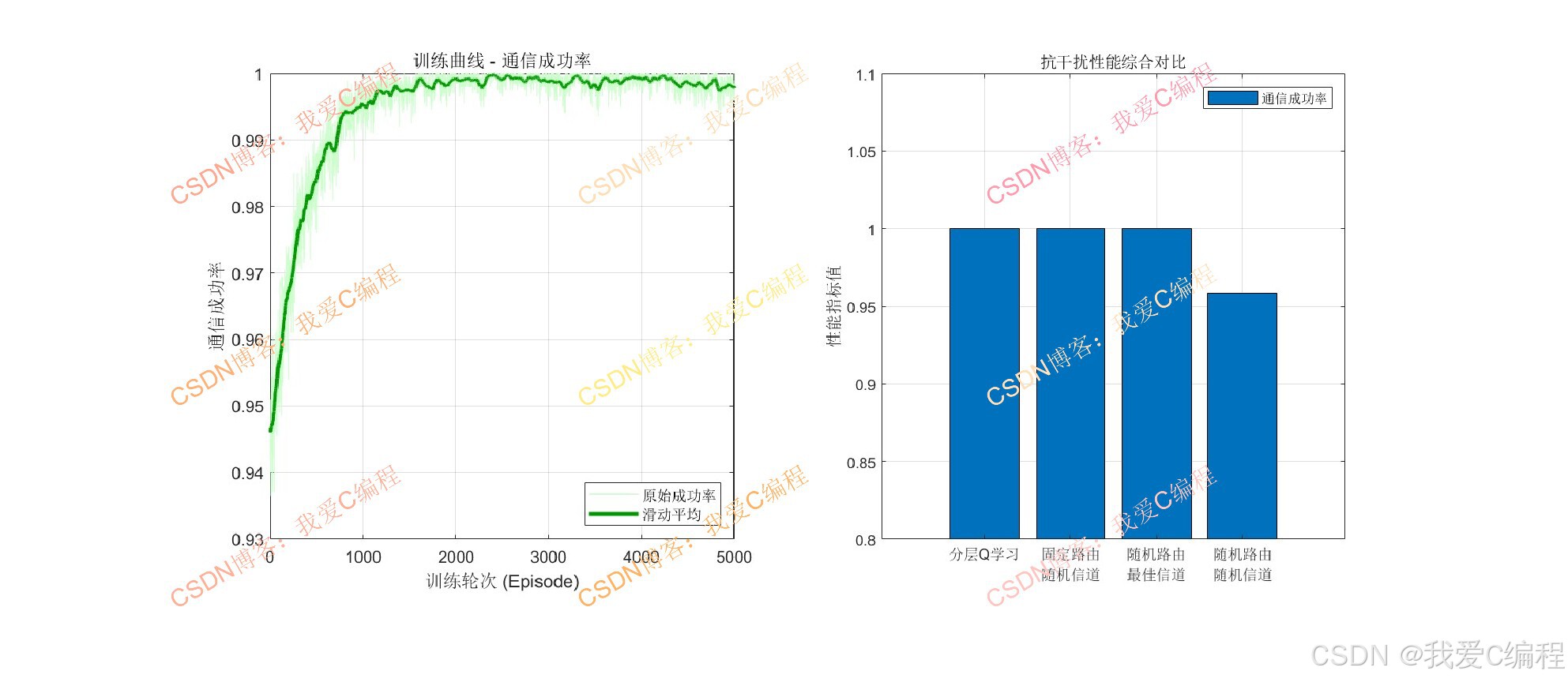
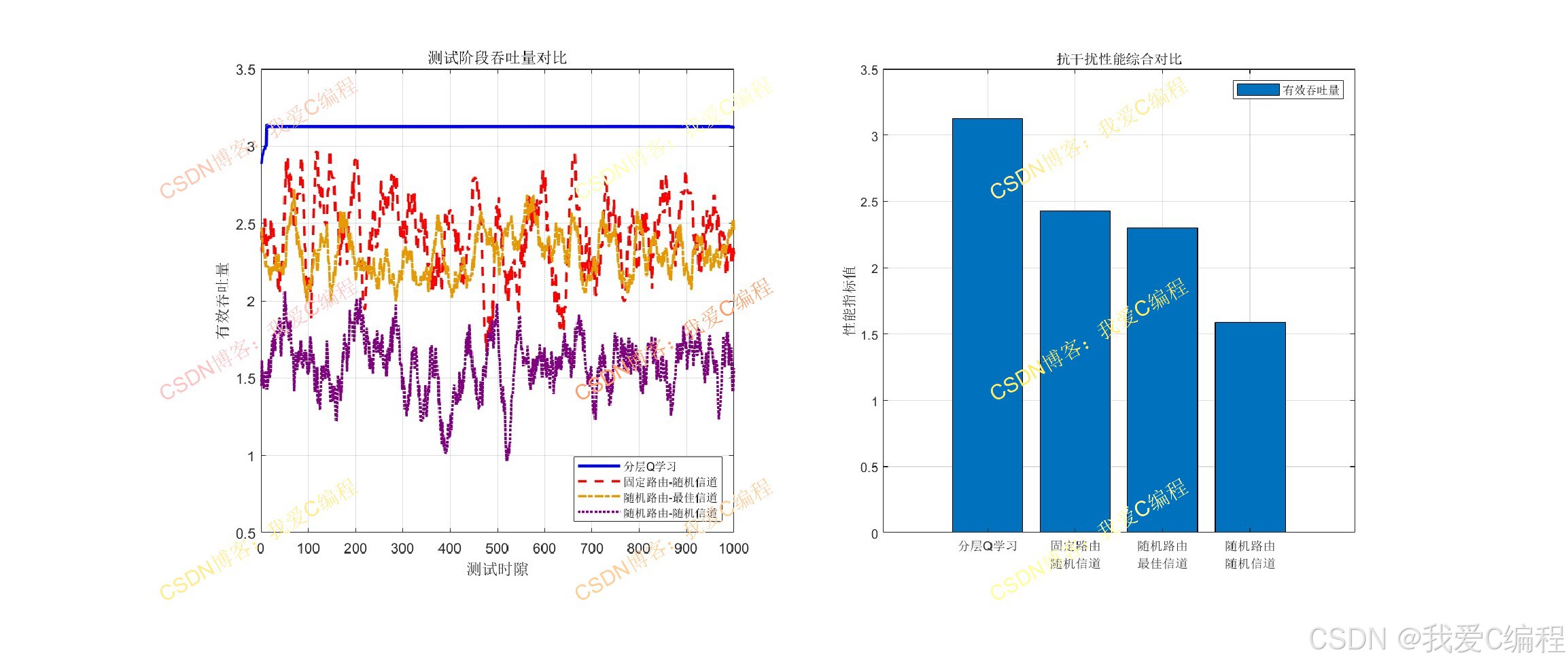
3.算法涉及理论知识概要
3.1 系统模型
考虑一个由多个节点组成的无线网络,源节点需要通过中继节点向目的节点传输数据。系统中存在一个智能干扰机,能够对特定信道实施干扰。用户需要联合选择传输路由和通信信道来规避干扰。假设网络中有𝑁𝑟条可用路由,𝑁𝑐个可用信道,干扰机可以同时干扰𝑁𝑗个信道。用户的策略空间为路由和信道的联合选择,干扰机的策略空间为干扰信道的选择。
3.2 分层Stackelberg博弈模型
将用户与干扰机之间的对抗建模为分层Stackelberg博弈。该博弈分为两层:
上层博弈(路由选择层):用户作为领导者选择传输路由,目标是最大化端到端的通信效用。路由选择影响传输路径上的节点数量、链路质量和被干扰的概率。
下层博弈(信道选择层):在给定路由的条件下,用户与干扰机进行信道选择博弈。干扰机作为跟随者,根据观察到的用户行为选择最佳干扰信道;用户则根据干扰机的策略选择最佳通信信道。
博弈的参与方定义如下:

3.3 效用函数定义
用户信干噪比(SINR):当用户选择路由 𝑟和信道 𝑐,干扰机选择干扰信道集合 𝑐𝑗时,用户在各跳链路上的信干噪比为:
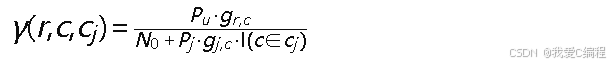
其中𝑃𝑢为用户发射功率,𝑔𝑟,𝑐为路由 𝑟上信道 𝑐的信道增益,𝑁0为噪声功率,𝑃𝑗为干扰功率,𝑔𝑗,𝑐为干扰信道增益,𝐼(⋅)为指示函数。

3.4 分层Q学习原理
分层Q学习将联合决策问题分解为两个层次的子问题,每个层次使用独立的Q表进行学习。
上层Q学习(路由选择):维护Q表𝑄route(𝑠,𝑟),其中状态𝑠包含网络负载、历史干扰信息等,动作𝑟为路由选择。其更新规则为:
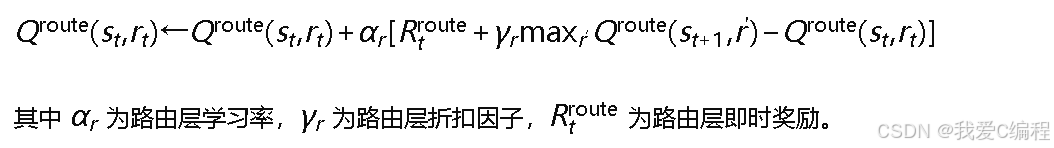
下层Q学习(信道选择):在选定路由𝑟后,维护Q表𝑄𝑟channel(𝑠,𝑐),动作𝑐为信道选择。更新规则为:
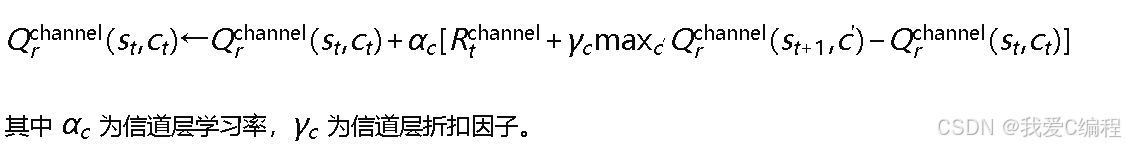
干扰机Q学习:干扰机独立进行学习,维护Q表𝑄jam(𝑠,𝑐𝑗),更新规则为:
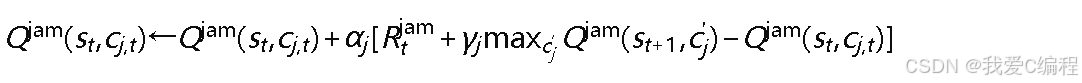
3.5 干扰机策略执行
干扰机根据自身Q表选择干扰信道:

3.6 计算即时奖励
根据通信结果计算各方奖励。用户奖励为:

4.MATLAB核心程序
% 网络参数
N_routes = 4; % 可用路由数
N_channels = 6; % 可用信道数
N_jam = 2; % 干扰机同时干扰信道数
hops = 2, 3, 4, 3; % 各路由跳数
% 信道参数
Pu = 1.0; % 用户发射功率(W)
Pj = 0.8; % 干扰功率(W)
N0 = 0.01; % 噪声功率(W)
BW = 1.0; % 归一化带宽
% 各路由各信道的信道增益(预设,路由x信道)
G_user = 0.3 + 0.7*rand(N_routes, N_channels);
G_jam = 0.2 + 0.6*rand(1, N_channels);
% Q学习参数
alpha_r = 0.05; % 路由层学习率
alpha_c = 0.20; % 信道层学习率
alpha_j = 0.05; % 干扰机学习率
gamma_r = 0.90; % 路由层折扣因子
gamma_c = 0.90; % 信道层折扣因子
gamma_j = 0.90; % 干扰机折扣因子
eps_init = 1.0; % 初始探索率
eps_min = 0.05; % 最小探索率
eps_decay = 0.9985; % 探索率衰减
beta = 0.05; % 跳数惩罚因子
eta = 0.1; % 路由层额外奖励权重
0Z_029m
5.完整算法代码文件获得
完整程序见博客首页左侧或者打开本文底部GZH名片
(V关注后回复码:X129)
V