摘要 :本文在 Decoder Only Transformer、LLaMA 架构 与 Gemma 1 架构 的统一框架下,系统介绍 Gemma 2(2B / 9B / 27B) 的架构与每一步的矩阵维度与运算 。相对 Gemma 1,Gemma 2 在保持 Decoder-only、RoPE、近似 GeGLU 等家族基因的同时,引入 交替的局部滑动窗口注意力与全局注意力 、注意力与最终层的 Logit soft-capping 、子层输入与输出双侧的 RMSNorm(含 FFN 前后各一对 Norm) ,以及全系 GQA(分组查询注意力) ;2B / 9B 在预训练阶段采用 自回归知识蒸馏 (以 27B 等为教师),27B 则 从头训练 。全文按「Tokenizer → 嵌入 → 单层 Decoder(注意力子层 + 前馈子层)→ lm_head」拆解,并给出与 Gemma 2 技术报告 一致的规模表与关键超参。
关键词:Gemma 2;Decoder-only;RMSNorm;Pre-Norm;Post-Norm;GeGLU;RoPE;GQA;局部注意力;滑动窗口;全局注意力;Logit soft-capping;知识蒸馏
参考与引用:
- Decoder Only Transformer
- LLaMA 架构
- Gemma 1 架构详解
- Gemma explained: What's new in Gemma 2(Google Developers Blog)
- Gemma 2: Improving Open Language Models at a Practical Size(技术报告 PDF)
- Gemma explained: An overview of Gemma model family architectures
- 位置编码深化:Transformer 21. 从 LLaMA 到 Qwen:Rotary Position Embedding(RoPE)与 YaRN 一文读懂
- 权重与实现可在 Hugging Face
google/gemma-2-*系列与上游transformers的Gemma2实现中核对(config.json以公开发布为准)。
💡 理解要点 :Gemma 2 仍是 仅 Decoder 的因果语言模型,但 每一大层 内在 注意力子层 与 FFN 子层 上都采用 「进入子层前 Norm + 子层输出后再 Norm」 的 RMSNorm 双包夹 ;相邻层交替 使用 全局 8192 span 的自注意力与 局部 4096 滑动窗口 自注意力。注意力 logits 与 最终语言模型头 logits 经过 tanh 式 soft-cap 限制幅度。全系 GQA :查询头数为 KV 头数的 2 倍 (
num_kv_heads = num_heads / 2)。与 Gemma 1 不同,不再 采用「7B=MHA、2B=MQA」的分工,而是 2B / 9B / 27B 统一 GQA。
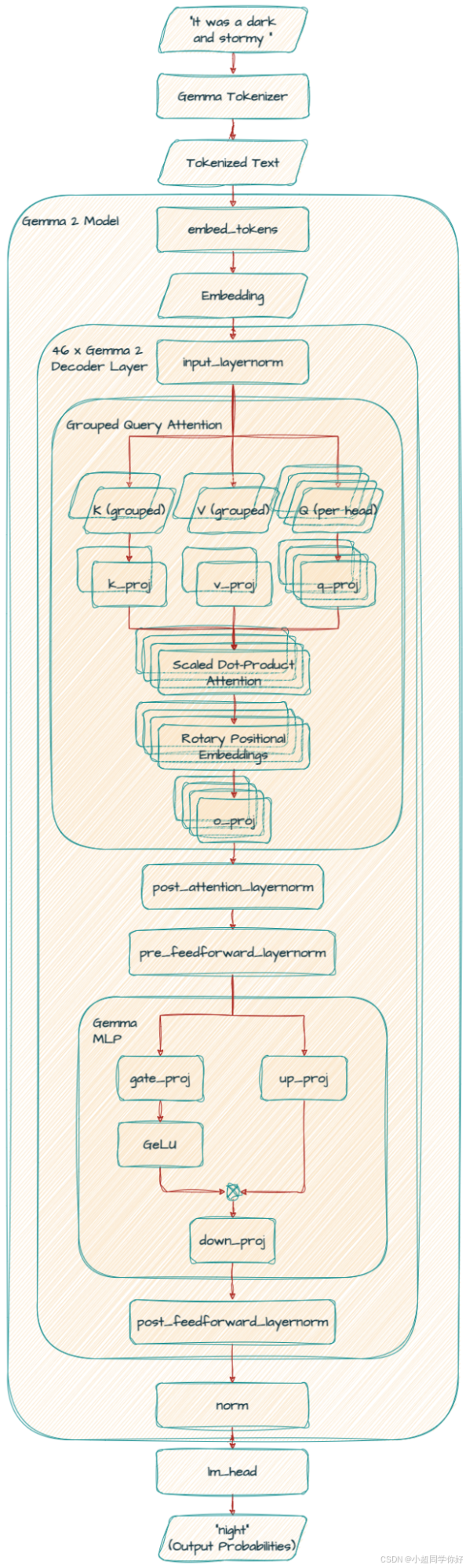
1. 概述:Gemma 2 在模型家族中的位置
1.1 Decoder-only 与自回归目标(与 Gemma 1 相同骨架)
与 Decoder Only Transformer 及 Gemma 1 一致,Gemma 2 的训练目标仍是:给定前缀 token 序列,预测下一 token 分布 。训练时对长度为 L L L 的序列施加 因果掩码 ,可对每个合法位置并行计算交叉熵;推理时 自回归 逐步延长序列。
Gemma 2 的发布范围 :公开权重包含 2B、9B、27B 等规模的 纯文本 Decoder-only 模型系列;多模态与更长上下文的代际演进见同系列其他博文与仓库(例如后续 RecurrentGemma 、PaliGemma 等,不在本文展开)。用户-facing 的 指令微调(IT) 模型与对话格式在技术报告「Post-Training」中有概述。
1.2 核心规模对照表(与技术报告 Table 1 对齐)
下列 主超参 摘自 Gemma 2 技术报告 Table 1,便于后文引用。词嵌入与 lm_head 绑权(tied embedding) 在三个规模上均为 yes。
| 属性 | Gemma 2 2B | Gemma 2 9B | Gemma 2 27B |
|---|---|---|---|
| 层数 N N N | 26 | 42 | 46 |
| d model d_{\text{model}} dmodel | 2304 | 3584 | 4608 |
| 注意力类型 | GQA | GQA | GQA |
| 查询头数 h q h_q hq | 8 | 16 | 32 |
| KV 头数 h kv h_{\text{kv}} hkv | 4 | 8 | 16 |
| 每头维度 d k d_k dk | 256 | 256 | 128 |
| 校验 h q ⋅ d k h_q \cdot d_k hq⋅dk | 8 × 256 = 2048 8\times256=2048 8×256=2048(经 o_proj 映至 d model = 2304 d_{\text{model}}=2304 dmodel=2304) |
16 × 256 = 4096 16\times256=4096 16×256=4096(经 o_proj 映至 d model = 3584 d_{\text{model}}=3584 dmodel=3584) |
32 × 128 = 4096 32\times128=4096 32×128=4096(经 o_proj 映至 d model = 4608 d_{\text{model}}=4608 dmodel=4608,见第 3 节) |
| GeGLU 每路中间维(报告中的 Feedforward dim 为两路合计量级) | 18432 | 28672 | 73728 |
| 全局注意力 span | 8192 | 8192 | 8192 |
| 局部层滑动窗口 | 4096 | 4096 | 4096 |
| 词表 V V V | 256128 | 256128 | 256128 |
| Pre-norm | yes | yes | yes |
| Post-norm(子层输出侧 RMSNorm) | yes | yes | yes |
注意,层数 N N N 指的是:堆叠的 Decoder 块(Transformer Layer)有多少个------也就是模型里有多少个 GemmaDecoderLayer(或同类的 DecoderLayer) 从输入到输出依次重复。
如何阅读「Feedforward dim」 :Gemma 族 GeGLU 块中有 gate_proj 与 up_proj 两路并列升到中间维,再逐元素门控;报告中 73728(27B) 可与实现里两路各 36864 对齐理解(2×36864 )。具体以checkpoint 与 config.json 的 intermediate_size 为准。Hugging Face 对 Gemma 2 的模块打印 中 27B 示例为 gate_proj/up_proj: Linear(4608 → 36864),down_proj: Linear(36864 → 4608)。
1.3 与 Gemma 1 比对
| 维度 | Gemma 1 | Gemma 2 |
|---|---|---|
| 规模 | 2B、7B | 2B、9B、27B |
| 多头方案 | 7B MHA ;2B MQA | 全系 GQA ,且 h q = 2 h kv h_q = 2\,h_{\text{kv}} hq=2hkv |
| 注意力模式 | 全程 全局 因果自注意力 | 隔层交替 :局部滑动窗口 (4096)与 全局(8192) |
| Norm 布局 | 标准 Pre-Norm(每层 2 处 RMSNorm:注意力前、FFN 前) | Pre-Norm + Post-Norm :注意力前后各 1 次 ,FFN 前后再各 1 次 (每层共 4 个 RMSNorm) |
| 输出与注意力 logits | 常规模型(Gemma 1 文未强调 cap) | Soft-capping :自注意力中 50.0 ,最终层 30.0(见下) |
| 2B/9B 训练目标 | 以标准 下一词预测 为主(见 Gemma 1 报告) | 2B/9B :预训练阶段 知识蒸馏(最小化与教师分布的交叉熵,见技术报告第 3.2 节) |
🔍 实际例子(27B,全局层, L = 8192 L=8192 L=8192) :若当前层为 全局注意力 ,则因果掩码下每个 token 可关注的前缀上限为 8192 (不超过序列实际长度);若为 局部层 ,有效感受野在实现上收缩为 长度 4096 的滑动窗口 (详见第 3.7 节)。批处理 时形状为 B × L × 4608 B \times L \times 4608 B×L×4608 (此处 d model = 4608 d_{\text{model}}=4608 dmodel=4608)。
2. 从输入到 Decoder:Token、嵌入与位置信息
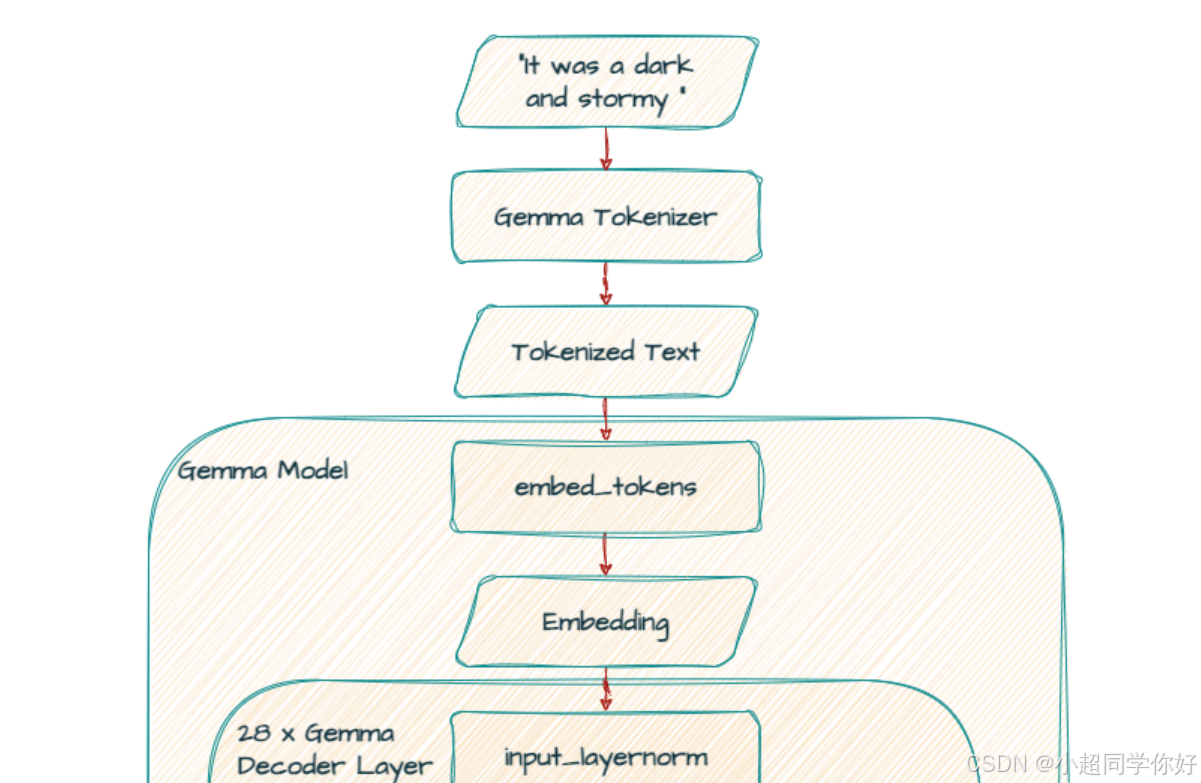
2.1 Tokenization:与 Gemma 1 / Gemini 同源的 SentencePiece
Gemma 2 使用 与 Gemma 1 和 Gemini 相同 的 SentencePiece 流程------含 拆分数字(split digits) 、保留空白(preserved whitespace) 、字节级编码 等设计(技术报告第 3.1 节)。词表仍为 V = 256128 V=256128 V=256128:
w = ( w 0 , ... , w L − 1 ) , 0 ≤ w i < V . \mathbf{w} = (w_0,\ldots,w_{L-1}),\quad 0\le w_i < V. w=(w0,...,wL−1),0≤wi<V.
实现上仍常见 padding_idx=0 ;应用侧须以 tokenizer_config.json 为准核对 BOS/EOS/对话控制符(技术报告 Table 4 列出 user、model、对话轮次等控制 token;Gemma 2 的 对话格式 schema 相对 Gemma 1 有更新,见报告第 4 节 Formatting)。
2.2 Embedding: L × d model L \times d_{\text{model}} L×dmodel 与 绑权(tied embeddings)
嵌入查表与 Gemma 1 相同:
E ∈ R V × d model , X = E \[ w 0 ⊤ ⋮ E w L − 1 ⊤ ] ∈ R L × d model . E \in \mathbb{R}^{V \times d_{\text{model}}},\quad X = \begin{bmatrix} Ew_0^\top \\ \vdots \\ Ew_{L-1}^\top \end{bmatrix} \in \mathbb{R}^{L \times d_{\text{model}}}. E∈RV×dmodel,X= Ew0⊤⋮EwL−1⊤ ∈RL×dmodel.
Gemma 2 各规模的嵌入矩阵形状:
| 型号 | d model d_{\text{model}} dmodel | E E E 形状 |
|---|---|---|
| 2B | 2304 | R 256128 × 2304 \mathbb{R}^{256128 \times 2304} R256128×2304 |
| 9B | 3584 | R 256128 × 3584 \mathbb{R}^{256128 \times 3584} R256128×3584 |
| 27B | 4608 | R 256128 × 4608 \mathbb{R}^{256128 \times 4608} R256128×4608 |
2.2.1 输出层 lm_head 与绑权
从 h \mathbf{h} h 到 logits(预测下一词)
设最后一层 Decoder 输出 H ∈ R L × d model H \in \mathbb{R}^{L \times d_{\text{model}}} H∈RL×dmodel,自回归里常取某一位置 (训练时多为「当前词位置」、推理时常为最后一个有效 token )对应的行,记为列向量
h = H i , : ⊤ ∈ R d model . \mathbf{h} = Hi,\\,:^\top \in \mathbb{R}^{d_{\text{model}}}. h=Hi,:⊤∈Rdmodel.
语言模型头要把 d model d_{\text{model}} dmodel 维映到 词表维 V V V ,得到进入 softmax 之前 的原始 logits 向量 s raw ∈ R V \mathbf{s}_{\text{raw}} \in \mathbb{R}^V sraw∈RV。下面写的是 cap 之前 的线性部分;随后对词表维做 final logit soft-capping(见第 5 节)。
绑权(weight tying / tied embedding) :技术报告 Table 1 写明 tied embedding: yes ,公开发布以绑权为准 。输出权重与嵌入表转置共用存储:
W out = E ⊤ ( 即 W out ∈ R d model × V 与 E ⊤ 为同一块参数 ) . W_{\text{out}} = E^\top \quad (\text{即 } W_{\text{out}} \in \mathbb{R}^{d_{\text{model}} \times V} \text{ 与 } E^\top \text{ 为同一块参数}). Wout=E⊤(即 Wout∈Rdmodel×V 与 E⊤ 为同一块参数).
于是第 w w w 个词元的线性部分 logit(无偏置时)为
( s raw ) w = h ⊤ e w , (s_{\text{raw}})_w = \mathbf{h}^\top \mathbf{e}_w, (sraw)w=h⊤ew,
其中 e w = E w , : ⊤ \mathbf{e}w = Ew,\\,:^\top ew=Ew,:⊤ 是 输入端对 token w w w 查表得到的那一行嵌入 (列向量)。含义是:预测分 = h \mathbf{h} h 与各词 嵌入方向 的内积 ------「词表 ↔ \leftrightarrow ↔ 隐空间」在 V V V 个词上共用同一组 d model d{\text{model}} dmodel 维向量。若有输出偏置(依实现而定),则 ( s raw ) w = h ⊤ e w + ( b out ) w (s_{\text{raw}})_w = \mathbf{h}^\top \mathbf{e}w + (b{\text{out}})w (sraw)w=h⊤ew+(bout)w。
参数量 :词表--隐层映射在总参数里只计 一份 V × d model V \times d{\text{model}} V×dmodel(与报告 Table 2 嵌入 列一致),不再 单独增加同等大小的 lm_head。
行向量与 PyTorch :与 hidden @ lm_head.weight.T 一致时可写 s raw ⊤ = h ⊤ W out \mathbf{s}{\text{raw}}^\top = \mathbf{h}^\top W{\text{out}} sraw⊤=h⊤Wout,其中 W out = E ⊤ W_{\text{out}}=E^\top Wout=E⊤。
如何在 checkpoint / 代码里核对
- 配置 :官方权重常见
tie_word_embeddings: true;微调若改为false,以实际权重为准。 - 实现 :
get_input_embeddings().weight与lm_head所用权重应 同一底层存储 (可用data_ptr()或is判断)。print(model)可能并列打印两处模块,不要按两个满矩阵重复计数。 - 形状 :
nn.Embedding(V, d_model)与nn.Linear(d_model, V)的weight均为 ( V , d model ) (V, d_{\text{model}}) (V,dmodel),便于 逐元素共享。
🔍 实际例子(9B) : L = 4096 L=4096 L=4096 时,嵌入输出 4096×3584 。取末位 h ∈ R 3584 \mathbf{h} \in \mathbb{R}^{3584} h∈R3584,绑权下先得到 s raw ∈ R 256128 \mathbf{s}{\text{raw}} \in \mathbb{R}^{256128} sraw∈R256128,再经 soft-cap(30) 与 softmax 得下一词分布。与 Gemma 1 相比,同序列长度下每 token 更宽 ,FLOPs 与显存上升,GQA 会部分抵消推理期 KV 缓存带宽压力(相对同宽 MHA)。
💡 理解要点 :Gemma 2 固定 **W out = E ⊤ W{\text{out}}=E^\top Wout=E⊤** ,未 cap 前 ( s raw ) w = h ⊤ e w (s_{\text{raw}})_w=\mathbf{h}^\top \mathbf{e}_w (sraw)w=h⊤ew ;另对注意力与最终词表 logits 做 soft-cap,见第 3、5 节。
注意 :部分工具链打印 Embedding(256000, ...) 而报告写 256128 ,属于 词表口径/实现显示 差异,以官方 config.json 与权重行为为准。
2.3 位置编码:仍是 RoPE;上下文长度与局部/全局 span
- RoPE 仍施加在 Q , K Q,K Q,K 上,不在嵌入上相加正弦 PE ------几何直觉与公式同 Gemma 1 第 2.3 节 与 Transformer 21. 从 LLaMA 到 Qwen:Rotary Position Embedding(RoPE)与 YaRN 一文读懂。
- 预训练上下文 :报告与 Table 1 一致,全局注意力层 的 attention span 为 8192 tokens(Gemma 1 亦常为 8192)。
- 新增 :在 局部层 ,有效邻域被 滑动窗口 截断为 4096 (报告第 2 节 Local Sliding Window and Global Attention )。RoPE 的频率与缩放 (
rope_theta等) 以各config为准;更长序列外推 依赖推理框架与可能的位置插值策略,此处不代替官方部署说明。
💡 理解要点 :位置编码机制未换 ;换的是 某些层的注意力邻接矩阵「谁能看见谁」 ------从「下三角全校」改为「下三角 ∩ 滑动窗」。
2.4 小结:进入堆叠层之前的张量
- 输入 : X ∈ R L × d model X \in \mathbb{R}^{L \times d_{\text{model}}} X∈RL×dmodel,仅来自
embed_tokens(无经典绝对 PE 相加)。 - 随后 :进入第一层
Gemma2DecoderLayer的input_layernorm(第 3 节)。
3. Decoder 单层 · 第一子层:交替掩码自注意力(GQA + 可选局部窗 + Pre/Post RMSNorm)
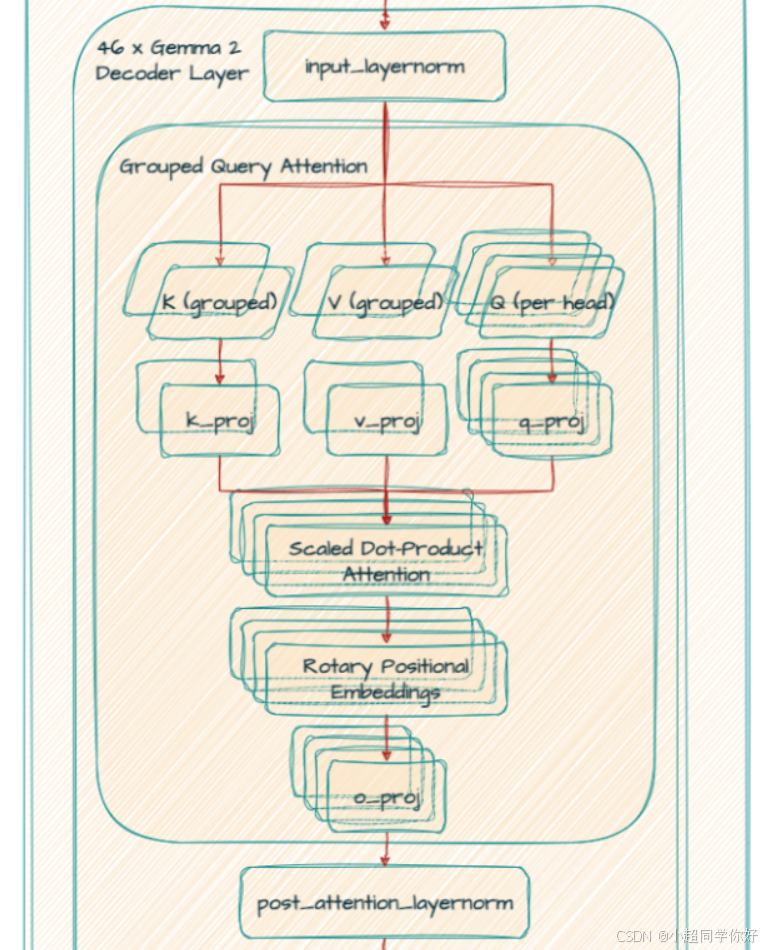
3.1 整层骨架(Gemma 2:四个 RMSNorm + 两子层残差)
与 Gemma 1「每层 2 个 RMSNorm」不同,Gemma 2 在实现与报告中体现为 注意力子层 与 FFN 子层 各有一对 Pre/Post RMSNorm 。用与 Gemma 1 第 3 节 兼容的记号,注意力块 可写为:
X mid = X + P o s t A t t n N o r m ( A t t n ( P r e A t t n N o r m ( X ) ) ) , X_{\text{mid}} = X + \mathrm{PostAttnNorm}\Bigl(\mathrm{Attn}\bigl(\mathrm{PreAttnNorm}(X)\bigr)\Bigr), Xmid=X+PostAttnNorm(Attn(PreAttnNorm(X))),
其中 P r e A t t n N o r m \mathrm{PreAttnNorm} PreAttnNorm 对应模块 input_layernorm , P o s t A t t n N o r m \mathrm{PostAttnNorm} PostAttnNorm 对应 post_attention_layernorm。
不要混淆 :Gemma 1 的 post_attention_layernorm 是 FFN 前 的 Norm;在 Gemma 2 里,post_attention_layernorm 是注意力 输出端的 Norm,FFN 另有 pre_feedforward_layernorm / post_feedforward_layernorm。
3.2 第一步:input_layernorm(RMSNorm)
对子层入口 X ∈ R L × d model X \in \mathbb{R}^{L \times d_{\text{model}}} X∈RL×dmodel 逐行 RMSNorm(与 LLaMA / Gemma 1 同式):
R M S N o r m ( x ) = x ε + 1 d model ∑ j x j 2 ⊙ γ . \mathrm{RMSNorm}(\mathbf{x}) = \frac{\mathbf{x}}{\sqrt{\varepsilon + \frac{1}{d_{\text{model}}}\sum_j x_j^2}} \odot \boldsymbol{\gamma}. RMSNorm(x)=ε+dmodel1∑jxj2 x⊙γ.
输出记为 X ~ ∈ R L × d model \tilde{X} \in \mathbb{R}^{L \times d_{\text{model}}} X~∈RL×dmodel。可学习参数 仅为 γ ∈ R d model \boldsymbol{\gamma}\in\mathbb{R}^{d_{\text{model}}} γ∈Rdmodel,无 LayerNorm 式平移 β \boldsymbol{\beta} β。
3.3 第二步:GQA 下的 Q , K , V Q,K,V Q,K,V 线性投影
GQA(Grouped-Query Attention) 将 h q h_q hq 个查询头 划分为 h kv h_{\text{kv}} hkv 组 ,每组 共享 同一套 K , V K,V K,V。Gemma 2 取 h q = 2 ∗ h kv h_q = 2*h_{\text{kv}} hq=2∗hkv (报告:GQA with num_groups = 2)。
以 9B 为例: d model = 3584 d_{\text{model}}=3584 dmodel=3584, h q = 16 h_q=16 hq=16, h kv = 8 h_{\text{kv}}=8 hkv=8, d k = 256 d_k=256 dk=256。
q_proj:3584 → 16×256 = 4096k_proj/v_proj:3584 → 8×256 = 2048(K、V 仅 8 个头)。- 计算注意力时,每个 KV 头服务 2 个连续的 Q 头(分组数 2)。
27B 特例: d model = 4608 d_{\text{model}}=4608 dmodel=4608,d k = 128 d_k=128 dk=128 , h q = 32 h_q=32 hq=32, h kv = 16 h_{\text{kv}}=16 hkv=16,故 q_proj : d model → h q d k d_{\text{model}}\to h_q d_k dmodel→hqdk 即 4608 → 4096 4608\to 4096 4608→4096,k_proj/v_proj : 4608 → 2048 4608\to 2048 4608→2048,与博文打印一致;o_proj 再映回 d model = 4608 d_{\text{model}}=4608 dmodel=4608。
2B : h q = 8 h_q=8 hq=8, h kv = 4 h_{\text{kv}}=4 hkv=4, d k = 256 d_k=256 dk=256, d model = 2304 d_{\text{model}}=2304 dmodel=2304。
三型号 GQA 投影对照 (与技术报告 Table 1 及上文一致;h q : h kv = 2 : 1 h_q:h_{\text{kv}}=2:1 hq:hkv=2:1):
| 型号 | d model d_{\text{model}} dmodel | h q h_q hq | h kv h_{\text{kv}} hkv | d k d_k dk | h q d k h_q d_k hqdk | h kv d k h_{\text{kv}} d_k hkvdk | q_proj |
k_proj/v_proj |
o_proj |
|---|---|---|---|---|---|---|---|---|---|
| 2B | 2304 | 8 | 4 | 256 | 2048 | 1024 | 2304 → 2048 2304\to 2048 2304→2048 | 2304 → 1024 2304\to 1024 2304→1024 | 2048 → 2304 2048\to 2304 2048→2304 |
| 9B | 3584 | 16 | 8 | 256 | 4096 | 2048 | 3584 → 4096 3584\to 4096 3584→4096 | 3584 → 2048 3584\to 2048 3584→2048 | 4096 → 3584 4096\to 3584 4096→3584 |
| 27B | 4608 | 32 | 16 | 128 | 4096 | 2048 | 4608 → 4096 4608\to 4096 4608→4096 | 4608 → 2048 4608\to 2048 4608→2048 | 4096 → 4608 4096\to 4608 4096→4608 |
批量形状(单条序列):
- Q ∈ R L × ( h q d k ) Q \in \mathbb{R}^{L \times (h_q d_k)} Q∈RL×(hqdk);reshape 为 R L × h q × d k \mathbb{R}^{L \times h_q \times d_k} RL×hq×dk。
- K , V ∈ R L × ( h kv d k ) K,V \in \mathbb{R}^{L \times (h_{\text{kv}} d_k)} K,V∈RL×(hkvdk);reshape 为 R L × h kv × d k \mathbb{R}^{L \times h_{\text{kv}} \times d_k} RL×hkv×dk。
- 在分组广播后,每个头内仍算缩放点积,** logits 形状** 主项仍是 L × L L\times L L×L (局部层中大量位置对被 掩码为 − ∞ -\infty −∞,见 3.7)。
3.4 第三步:RoPE 作用于 Q , K Q,K Q,K
与 Gemma 1 相同:对 Q , K Q,K Q,K 施 RoPE , V V V 一般不做 RoPE。每个头内:
S i j ( t ) = ⟨ R o P E ( Q i ⋅ ( t ) ) , R o P E ( K j ⋅ ( t ) ) ⟩ d k . S^{(t)}{ij} = \frac{\langle \mathrm{RoPE}(Q{i\cdot}^{(t)}), \mathrm{RoPE}(K_{j\cdot}^{(t)})\rangle}{\sqrt{d_k}}. Sij(t)=dk ⟨RoPE(Qi⋅(t)),RoPE(Kj⋅(t))⟩.
索引 ( t ) (t) (t) 在 Q 侧遍历 h q h_q hq ;K/V 侧按 KV 头索引 广播到对应的两个 Q 头。
3.5 第四步:注意力 Logit Soft-Capping
在 自注意力 内部,对 注意力 logits(标量层面「打分」)施加:
S ~ = s attn ⋅ tanh ( S s attn ) , s attn = 50.0 \tilde{S} = s_{\text{attn}} \cdot \tanh\!\left(\frac{S}{s_{\text{attn}}}\right),\quad s_{\text{attn}} = 50.0 S~=sattn⋅tanh(sattnS),sattn=50.0
(报告第 2 节 Logit soft-capping )。再 加因果掩码(及局部掩码),做 softmax,与 V V V 相乘得到上下文向量。
直觉 :极端大的 logits 会把 softmax 推向 近似 one-hot ,梯度与环境 数值 更不稳定;tanh 将 logits 饱和 在 ( − s , s ) (-s,s) (−s,s) ,抑制「过度自信」的注意力尖峰,起到与 logit clipping 类似的正则化效果 Bello et al., 2016 引用见报告。实现细节(在 softmax 前或分头 cap 等)以 modeling_gemma2 为准。
3.6 第五步:拼接多头与 o_proj
将各 Q 头输出拼回:
C o n c a t ∈ R L × h q d k . \mathrm{Concat}\in\mathbb{R}^{L \times h_q d_k}. Concat∈RL×hqdk.
注意 : h q d k h_q d_k hqdk 不一定等于 d model d_{\text{model}} dmodel(27B : 32 × 128 = 4098 32\times128=4098 32×128=4098?实为 4096 ,即 设计上令 h q d k = 4096 h_q d_k=4096 hqdk=4096 );因此需要 o_proj : R h q d k → R d model \mathbb{R}^{h_q d_k}\to\mathbb{R}^{d_{\text{model}}} Rhqdk→Rdmodel(27B 为 4096→4608),得到 A t t n O u t ∈ R L × d model \mathrm{AttnOut}\in\mathbb{R}^{L\times d_{\text{model}}} AttnOut∈RL×dmodel。
9B / 2B :o_proj 将拼接维度 h q d k h_q d_k hqdk 映回 d model d_{\text{model}} dmodel(9B:4096 → 3584;2B:2048 → 2304)。
3.7 第六步:交替局部与全局掩码
报告第 2 节:每隔一层 在 局部滑动窗口注意力(Beltagy et al., 2020) 与 全局注意力 间切换:
- 全局层 :因果掩码下,若序列长度 ≤ 8192 \le 8192 ≤8192,位置 i i i 可见所有 j ≤ i j\le i j≤i(在 L L L 增长时仍受 8192 span 约束的实现细节以代码为准)。
- 局部层 :在因果约束之外再加 带状稀疏 :距离超过 4096 的 ( i , j ) (i,j) (i,j) 对被屏蔽(sliding window size = 4096)。
局部滑动窗口在算什么 。普通 因果自注意力 里,位置 i i i 的查询可以与所有 过去 位置 j ≤ i j\le i j≤i 算相似度, logits 主项仍是 稠密 的 L × L L\times L L×L(再靠掩码去掉非法的 j > i j>i j>i)。滑动窗口 是在因果掩码 之上 再裁一刀:只允许「离 i i i 不太远的 j j j」参与注意力 ,更远的过去 token 对应的 logits 被置为 − ∞ -\infty −∞ (与 3.3 一致:掩码后 softmax 为 0)。因此 带状稀疏 :有效注意力模式在 ( i , j ) (i,j) (i,j) 平面上落在主对角附近的一条带内。
在 因果 + 仅看过去 的前提下,「距离超过 4096」可以理解为:对每个 i i i,最多再往回看约 4096 个 token (形如仅允许 j ∈ max ( 0 , i − 4096 ) , i j\in\\max(0,i-4096),\\,i j∈max(0,i−4096),i 一类的区间。它 不是 「整个模型上下文只有 4096」:序列仍可更长;限制的是这一层、这一次注意力里「单步能直接引用多远的历史」。
为什么要与全局层交替 。纯局部层算子便宜(大量 ( i , j ) (i,j) (i,j) 不算),但单层内长距离信息 不能一步直达 ;全局层 保留「远距一次性相连」的能力。堆叠上 一层局部、一层全局 交错后,邻近结构主要由局部层刻画,跨块依赖由全局层与深层传播共同承担,与 Longformer 等「局部 + 稀疏/全局」思路同族。
报告 Table 10 展示:在 推理时改小 滑动窗口(2048、1024)对 perplexity 影响温和 ,可当作 推理加速旋钮 ------因为此时主要 少算 了远距离注意力项,而 其余层(尤其全局层) 仍能传递信息,故质量下降往往不如「一刀切缩短上下文」那样剧烈。
3.8 第七步:post_attention_layernorm + 残差
A t t n B l o c k O u t = R M S N o r m post-attn ( A t t n O u t ) , X mid = X + A t t n B l o c k O u t . \mathrm{AttnBlockOut} = \mathrm{RMSNorm}{\text{post-attn}}(\mathrm{AttnOut}),\quad X{\text{mid}} = X + \mathrm{AttnBlockOut}. AttnBlockOut=RMSNormpost-attn(AttnOut),Xmid=X+AttnBlockOut.
此处 RMSNorm 再次 逐行 缩放,参数与 input_layernorm 独立 。残差锚点 仍是 子层最开始的 X X X(Pre-Norm 族的残差语义)。
💡 理解要点 :Gemma 2 的注意力子层 = RMSNorm → GQA+RoPE →(注意力 logits soft-cap)→ softmax → 拼头 → o_proj → RMSNorm → 残差 ;掩码(因果 + 每层的全局 / 局部窗口)在 softmax 前与 logits 相加 。局部层「往过去能看多远」的直观含义见 3.7 小节。
4. Decoder 单层 · 第二子层:GeGLU 前馈(外加 Pre/Post FFN RMSNorm)
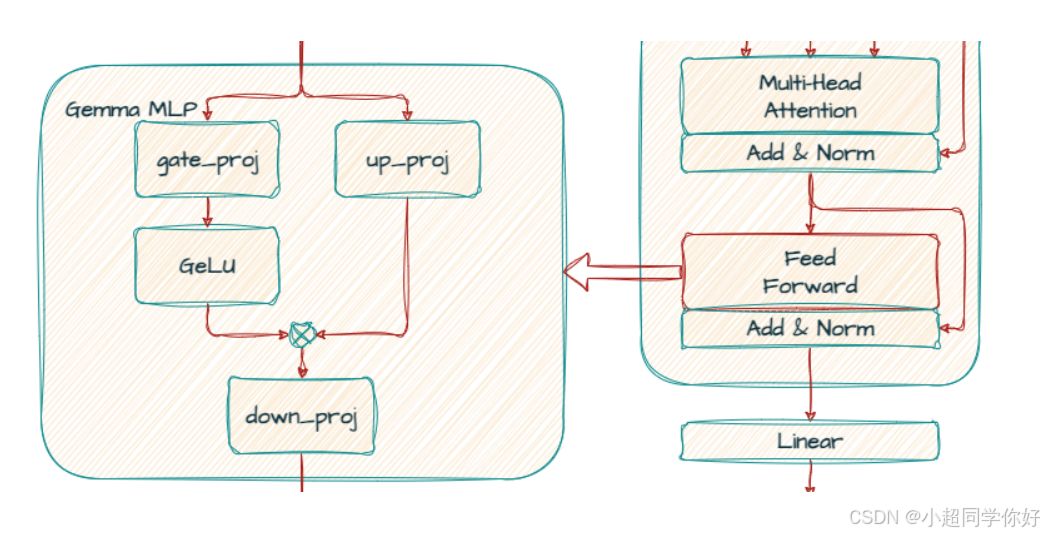
第二子层 入口为 X mid X_{\text{mid}} Xmid。与 Gemma 1 仅 post_attention_layernorm 一次 不同,Gemma 2 使用:
pre_feedforward_layernormmlp(Gemma2MLP:gate_proj、up_proj、PytorchGELUTanh/GELU门控 、down_proj)post_feedforward_layernorm- 残差连回 X mid X_{\text{mid}} Xmid
数学草图:
X out = X mid + P o s t F F N o r m ( F F N ( P r e F F N o r m ( X mid ) ) ) . X_{\text{out}} = X_{\text{mid}} + \mathrm{PostFFNorm}\Bigl(\mathrm{FFN}\bigl(\mathrm{PreFFNorm}(X_{\text{mid}})\bigr)\Bigr). Xout=Xmid+PostFFNorm(FFN(PreFFNorm(Xmid))).
4.1 pre_feedforward_layernorm
X ~ ff = R M S N o r m pre-ff ( X mid ) ∈ R L × d model . \tilde{X}{\text{ff}} = \mathrm{RMSNorm}{\text{pre-ff}}(X_{\text{mid}}) \in \mathbb{R}^{L\times d_{\text{model}}}. X~ff=RMSNormpre-ff(Xmid)∈RL×dmodel.
4.2 GeGLU:门控与前馈(与 Gemma 1 同族,维数随规模变)
记中间宽 d ff d_{\text{ff}} dff 为 intermediate_size(单路):与 Gemma 1 相同:
U = X ~ ff W up , G = X ~ ff W gate , H = G E L U ( G ) ⊙ U , F F N O u t = H W down . U = \tilde{X}{\text{ff}} W{\text{up}},\quad G = \tilde{X}{\text{ff}} W{\text{gate}},\quad H = \mathrm{GELU}(G)\odot U,\quad \mathrm{FFNOut} = H W_{\text{down}}. U=X~ffWup,G=X~ffWgate,H=GELU(G)⊙U,FFNOut=HWdown.
规模示例(与报告/博文对齐):
| 型号 | d model d_{\text{model}} dmodel | 单路 intermediate_size(典型) |
down |
|---|---|---|---|
| 27B | 4608 | 36864 | 36864 → 4608 |
| 9B | 3584 | 14336(28672/2) | 14336 → 3584 |
| 2B | 2304 | 9216(18432/2) | 9216 → 2304 |
Google 博文 27B 打印为 36864,与上表一致。
4.3 post_feedforward_layernorm + 残差
F F N B l o c k O u t = R M S N o r m post-ff ( F F N O u t ) , X out = X mid + F F N B l o c k O u t . \mathrm{FFNBlockOut} = \mathrm{RMSNorm}{\text{post-ff}}(\mathrm{FFNOut}),\quad X{\text{out}} = X_{\text{mid}} + \mathrm{FFNBlockOut}. FFNBlockOut=RMSNormpost-ff(FFNOut),Xout=Xmid+FFNBlockOut.
X out X_{\text{out}} Xout 送入 下一层 ;共重复 N N N 次。
4.4 与 LLaMA(SwiGLU)及 Gemma 1 的对照
| 项目 | LLaMA | Gemma 1 | Gemma 2 |
|---|---|---|---|
| 门控非线性 | SwiGLU | GeGLU | GeGLU |
| 注意力 | 多为 MHA(依规模) | 7B MHA / 2B MQA | GQA( h q = 2 h kv h_q=2h_{\text{kv}} hq=2hkv) |
| FFN Norm | 通常 Pre-Norm 一次 | Pre-Norm 一次 | Pre + Post 各一次 |
| 局部注意力 | 依模型 | 无 | 4096 窗与全局交替 |
5. 输出层:lm_head、最终 Logit Soft-Capping 与 Softmax
最后一层堆叠输出 H ∈ R L × d model H \in \mathbb{R}^{L\times d_{\text{model}}} H∈RL×dmodel。取位置 i i i 的隐向量 h ∈ R d model \mathbf{h}\in\mathbb{R}^{d_{\text{model}}} h∈Rdmodel(训练时常对 所有 非末 token 并行预测下一词)。
绑权 时:
z raw = E h ( 或等价矩阵乘 h ⊤ W lm ) . \mathbf{z}{\text{raw}} = E\,\mathbf{h} \quad (\text{或等价矩阵乘 } \mathbf{h}^\top W{\text{lm}}). zraw=Eh(或等价矩阵乘 h⊤Wlm).
最终层 soft-cap (报告: s final = 30.0 s_{\text{final}}=30.0 sfinal=30.0):
z = s final ⋅ tanh ( z raw s final ) . \mathbf{z} = s_{\text{final}} \cdot \tanh\!\left(\frac{\mathbf{z}{\text{raw}}}{s{\text{final}}}\right). z=sfinal⋅tanh(sfinalzraw).
P ( ⋅ ∣ context ) = s o f t m a x ( z ) . P(\cdot\mid \text{context}) = \mathrm{softmax}(\mathbf{z}). P(⋅∣context)=softmax(z).
与 Gemma 1 相比,Gemma 1 文仅备注「若启用 attention logits soft-capping 以代码为准」;Gemma 2 则在报告层面 明确 了 注意力 50 与 最终 30 两套标量。
🔍 实际例子 :若某维 z raw \mathbf{z}_{\text{raw}} zraw 达 10 2 10^2 102 量级,经 tanh 压缩后绝对值 不超过 30 ,softmax 更平滑;蒸馏训练 中教师分布若很尖锐,学生 logits cap 也有助于 数值对齐。
6. 训练与推理流程(预训练 / 蒸馏 / 后训练纲要)
6.1 数据与 token 预算(报告第 3.1 节)
- 27B :13T tokens 预训练,主要英语 ,数据来源含网页、代码、科学文章等(非多模态 ;多语能力 非 SOTA 目标)。
- 9B :8T tokens。
- 2B :2T tokens。
过滤与去污染流程与 Gemma 1 同族(PII、安全、评测集去污染、复读风险等)。
6.2 知识蒸馏(2B / 9B)
报告第 3.2 节:对学生 P S P_S PS、教师 P T P_T PT,最小化
L = − ∑ x P T ( x ∣ x c ) log P S ( x ∣ x c ) . \mathcal{L} = -\sum_x P_T(x\mid x_c)\log P_S(x\mid x_c). L=−x∑PT(x∣xc)logPS(x∣xc).
教师 为 大模型 (发布管线中以 27B 为更高容量教师;报告叙述 2B/9B 用蒸馏替换纯下一词 one-hot 目标 )。27B 从头训练 (非蒸馏学生)。直觉与小模型 加长训练 的边际收益递减相对,蒸馏 用 更「厚」的标签分布 换 同等 token 下的更强梯度信号。
6.3 后训练(报告第 4 节,简述)
- SFT :合成 + 人类数据混合;可用 更大模型作教师 生成回复;亦提及对学生分布再蒸馏。
- RLHF :相对 Gemma 1.1 换用 更大、更偏好多轮对话 的 reward model;模型融合(averaging) 提升鲁棒性。
- 控制 token 表延续 Gemma 1,格式 schema 更新(多轮示例见报告 Table 5)。
6.4 推理要点
- KV Cache :GQA 下 K/V 头数减半 (相对同宽 MHA),缓存体积 近似按 h kv / h q h_{\text{kv}}/h_q hkv/hq 比例节省(实现与 MQA 类似思想,但 表达能力通常优于纯单头 KV)。
- 局部层 :算子可使用 带状稀疏 / 滑动窗核 降低 O ( L 2 ) O(L^2) O(L2) 常数;全局层 仍为全长因果注意力(上限 span 8192)。
- 改窗宽 :报告 Table 10 暗示 推理侧缩放窗口 的 速度--质量 折中。
7. 参数量量级(与 Gemma 1 文第 7 节对照)
7.1 技术报告 Table 2(总参数拆分)
| 模型 | 嵌入参数量(约) | 非嵌入参数量(约) |
|---|---|---|
| 2B | 590,118,912 | 2,024,517,888 |
| 9B | 917,962,752 | 8,324,201,984 |
| 27B | 1,180,237,824 | 26,047,480,320 |
非嵌入 主体来自 N N N 层 ×(注意力 + GeGLU + 4 组 RMSNorm) ;GeGLU 仍占 2 d model ⋅ d ff + d ff ⋅ d model 2d_{\text{model}}\cdot d_{\text{ff}} + d_{\text{ff}}\cdot d_{\text{model}} 2dmodel⋅dff+dff⋅dmodel 量级(与 Gemma 1 第 7 节 公式同型,d ff d_{\text{ff}} dff 取单路宽)。
7.2 GQA 相对 MHA 的注意力参数(直觉)
记 Query 拼接宽度 d q = h q d k d_q = h_q d_k dq=hqdk,则 KV 侧总宽为 h kv d k = d q / 2 h_{\text{kv}} d_k = d_q/2 hkvdk=dq/2(Gemma 2 固定 h q : h kv = 2 : 1 h_q:h_{\text{kv}}=2:1 hq:hkv=2:1 )。W K , W V W_K,W_V WK,WV 的参数量相对「满 MHA」大致 减半 ;W Q W_Q WQ 仍映至满 d q d_q dq;o_proj 负责 d q → d model d_q \to d_{\text{model}} dq→dmodel (三规模均非「跳过」,见第 3.6 节 27B :4096→4608)。
7.3 额外 RMSNorm
每层 +2 个 γ \boldsymbol{\gamma} γ(各 d model d_{\text{model}} dmodel 维),相对 亿级 线性层可忽略,但对 训练动力学 有意义(报告强调 稳定训练)。
8. 总览对照表:Gemma 2 vs Gemma 1 vs 经典 Decoder / LLaMA
| 维度 | 经典 Decoder-only | LLaMA | Gemma 1 | Gemma 2 |
|---|---|---|---|---|
| 位置 | 嵌入 + PE | RoPE(Q,K) | 同左 | 同左 |
| 归一化 | Post-LN 常见 | Pre-RMSNorm | Pre-RMSNorm | Pre + Post RMSNorm(双包夹) |
| FFN | ReLU MLP | SwiGLU | GeGLU | GeGLU |
| 注意力 | MHA | MHA 为主 | 7B MHA / 2B MQA | GQA(全系,2:1) |
| 邻域 | 全局因果 | 全局因果 | 全局因果 | 局部 4096 与全局 8192 交替 |
| Logits | 无 cap(通常) | 无 cap(通常) | 未强调 | 注意力 50 / 最终 30 soft-cap |
| 小模型训练 | --- | --- | 下一词为主 | 2B/9B 大规模蒸馏 |
9. 小结
- Gemma 2 在 Gemma 1 的现代 Decoder 栈上,用 更深网络 + GQA + 交替局部/全局注意力 + 双边 RMSNorm + logit soft-capping +(小模型)蒸馏 换 同量级下的更强能力 与 更可用的推理效率。
- 单层流水线 :Attn :
input_layernorm→ GQA+RoPE → 注意力 logits cap(50) → softmax → concat →o_proj→post_attention_layernorm→ 残差;FFN :pre_feedforward_layernorm→ GeGLU →post_feedforward_layernorm→ 残差。 - 数据流 :256128 SentencePiece → 嵌入 → N N N 层 上述块 → 绑权 logits → 最终 cap(30) → softmax。
- 读文献时 :规模与窗宽以 技术报告 Table 1 为准;模块名与维度以 Hugging Face 打印 与
config.json实测锁定。