开篇介绍:
hello 大家,nice to meet you,老掉牙的开场白了已经,那么我们也是话不多说其实,在上一篇博客中,我们总算是对进程这个难题进行了一个结束,那么接下来,我们要开始学习另一个重点,文件,这个也是很重要的一部分内容,毕竟计算机肯定离不开文件,更别谈我们的Linux系统是"一切皆文件",所以,接下来的几篇博客里,我们就将对文件发起进攻。
OK大家,那么话不多说,我们直接开始。
文件基本操作:
一、什么是 "文件"?
1. 狭义说:硬盘里的 "永久存储物"
你电脑里的文档、图片、视频,甚至安装的程序,都是 "文件"。它们有两个核心特点:
- 存在硬盘(磁盘)里:硬盘是 "永久存储" 设备,就像家里的抽屉,东西放进去断电也不会丢;而内存(电脑临时工作的地方)像桌面草稿纸,断电就清空。
- 操作文件就是 "搬东西" :硬盘是电脑的 "外部设备",不属于核心计算部件。所以 "打开文件看内容",本质是把硬盘里的数据 "搬到内存"(输入,I);"编辑后保存",是把内存里的新数据 "搬回硬盘"(输出,O)。这种 "搬数据" 的过程,就叫IO 操作。
2. 广义说:Linux 里 "啥都算文件"
在 Linux 系统中(比如服务器常用的系统),不仅硬盘里的文档是文件,键盘、显示器、网线接口这些硬件,也被当成 "文件" 对待。
- 为啥这么设计?为了 "简单"。比如:
- 从键盘打字(输入)和从硬盘读文件,用类似的方法处理;
- 往显示器显示(输出)和往硬盘写文件,也用类似的方法处理。不用记一堆规则,统一叫 "操作文件" 就行。
3. 文件的 "两部分":属性 + 内容
任何文件都由两部分组成:
- 内容:你能直接看到的部分,比如文档里的文字、图片的像素数据。
- 属性(元数据):描述文件的 "标签",比如文件名("笔记.txt")、大小(10KB)、创建时间(2023-10-01)、谁能查看(权限)等。哪怕是 0KB 的空文件(没内容),也得存这些属性,所以空文件也会占一点硬盘空间(存属性用)。
4. 谁在 "操作" 文件?
文件自己不会动,必须靠 "程序"(正在运行的程序叫 "进程")操作。比如用记事本打开 "笔记.txt",记事本就是一个进程,它负责从硬盘读内容、显示到屏幕、保存时再写回硬盘。
但进程不能直接 "碰" 硬盘,得靠 "操作系统"(比如 Windows、Linux)帮忙。操作系统是硬盘的 "管理员",进程要操作文件,只需告诉操作系统 "我要读 XXX 文件",操作系统会实际操作硬盘。
C 语言里的fopen、fwrite等函数,是 "简化工具"------ 它们帮你把需求告诉操作系统,不用你直接和操作系统打交道,本质上其实是调用系统的接口,比如open函数,这个我们后面会学到
二、C 语言如何操作文件?
C 语言操作文件的核心流程是:打开文件→读写文件→判断状态→关闭文件 ,涉及的关键函数有fopen、fwrite/fread/fprintf/fscanf、feof/ferror、fclose。
1. 打开文件:fopen函数(拿 "钥匙")
作用:告诉操作系统 "我要操作 XXX 文件了",返回一个 "文件指针"(类似一把 "钥匙",后续操作都靠它)。
函数原型:
FILE *fopen(const char *filename, const char *mode);(1)参数说明
-
filename(文件名):要操作的文件名(可带路径)。若只写文件名(比如"笔记.txt"),文件会存在程序 "当前所在的文件夹" 里。怎么看 "当前文件夹"?比如双击a.exe运行,当前文件夹就是a.exe所在的文件夹;用命令行./myprog运行,当前文件夹就是命令行所在的文件夹。 -
mode(打开方式):决定操作权限(读 / 写)、文件不存在时的行为,以及是否影响原有内容。详细如下表:
| 打开方式 | 全称含义 | 读写权限 | 文件不存在时 | 对已有文件的影响 | 适用场景 |
|---|---|---|---|---|---|
"r" |
read(只读) | 只能读,不能写 | 打开失败(返回NULL) |
不修改内容 | 读已存在的文本 / 二进制文件(如配置文件) |
"w" |
write(只写) | 只能写,不能读 | 新建空文件 | 清空原有内容(截断为 0 字节),类似之前讲的重定向操作的> | 新建或覆盖文件(如写日志) |
"a" |
append(追加写) | 只能写,不能读 | 新建空文件 | 写内容自动加在末尾,不影响原有内容,类似之前讲的重定向操作的>> | 追加数据(如日志追加) |
"r+" |
read+write(读写) | 既能读也能写 | 打开失败(返回NULL) |
不截断内容,可修改任意位置,即以r为主 | 编辑已存在的文件(如改文档) |
"w+" |
write+read(读写) | 既能读也能写 | 新建空文件 | 清空原有内容,即以w为主 | 新建可读写文件,或覆盖后读写 |
"a+" |
append+read(追加读写) | 既能读也能写 | 新建空文件 | 写内容加在末尾,读可从开头开始 | 边读边追加(如边看日志边加新内容) |
关键补充:文本模式与二进制模式
上述模式默认是 "文本模式"(适合.txt等文本文件)。若操作图片(.jpg)、视频(.mp4)等二进制文件,需在模式后加"b"(binary),避免数据损坏。
| 二进制模式 | 对应文本模式 | 区别 | 适用场景 |
|---|---|---|---|
"rb" |
"r" |
读时不转换换行符(如 Windows 的\r\n不变为\n) |
读图片、视频等二进制文件 |
"wb" |
"w" |
写时不转换换行符(\n不变为\r\n) |
写二进制文件 |
"ab" |
"a" |
追加时不转换换行符 | 追加二进制数据 |
"r+b" |
"r+" |
读写时不转换换行符 | 读写二进制文件 |
"w+b" |
"w+" |
读写时不转换换行符,且截断内容 | 新建并读写二进制文件 |
"a+b" |
"a+" |
读写时不转换换行符,写内容追加到末尾 | 追加并读二进制文件 |
为什么要区分?
- 文本文件中,换行符在不同系统中表示不同:Windows 用
\r\n,Linux/macOS 用\n。文本模式下,C 语言会自动转换(如写\n时,Windows 会转为\r\n),保证文本显示正常。 - 二进制文件(如图片)的字节是 "原样存储" 的,若自动转换换行符,会破坏数据(比如图片里的
\n被转为\r\n,图片会损坏)。
(2)返回值:必须检查是否成功
fopen成功时返回FILE*类型的文件指针("钥匙");失败时返回NULL(比如用"r"打开不存在的文件)。
如果不管失败直接用NULL操作,程序会崩溃,所以必须检查:
FILE *fp = fopen("笔记.txt", "r"); // 尝试打开文件
if (fp == NULL) { // 打开失败
printf("打不开文件!可能文件不存在\n");
return 1; // 直接退出,别往下执行
}2. 读写文件:4 个核心函数
C 语言提供两类读写函数:二进制读写 (适合所有文件)和格式化读写(适合文本文件)。
(1)二进制写:fwrite(内存→文件,适合所有文件)
作用:把内存中的数据(无论文本还是二进制,比如图片、视频)"原样搬到" 文件里,意思就是说,你是二进制,你也得给我输入到文件里,你不是二进制,那你也给我滚进去,没错,又是一个霸道总裁。
函数原型:
size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream);参数说明
| 参数 | 含义(通俗解释) | 例子 |
|---|---|---|
ptr |
要写入的内存数据的起始地址("源头"),字符数组的变量名 | 写字符串"hello",ptr就是"hello"的首地址。 |
size |
单个数据元素的字节大小(每个 "小单位" 的大小),一般是直接sizeof(数组名0) | 写char(字符)时size=1(1 字节 / 字符);写int时size=4(假设 int 占 4 字节)。 |
nmemb |
计划写入的元素个数(要写多少个 "小单位"),一般是直接sizeof(数组名) | 写 5 个int,nmemb=5;写"hello"(5 个字符),size=1时nmemb=5。 |
stream |
文件指针(fopen返回的 "钥匙") |
如fp(目标文件)、stdout(写到显示器)。 |
返回值:实际成功写入的 "元素个数"
返回size_t类型(无符号整数),表示实际写入的元素个数(不是字节数)。
- 正常:返回值 = 计划写入的
nmemb(如写 5 个字符返回 5) - 异常:返回值 <
nmemb(如磁盘满,只写了 3 个)。
总写入字节数:返回值 × size
例如:fwrite("hello\n", 6, 1, fp)中,size=6("hello\n"共 6 字节),nmemb=1,若返回 1,则总写入1×6=6字节。
例子:
cpp
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
FILE* f=fopen("test_fwrite.txt","w");//以w方式打开文件,要是我们没有指定目录的话,默认就是在本目录下
//在以w方式打开的时候,要是没有这个文件,那么系统会自己创建这个文件
if(f==NULL)
{
perror("fopen failed:");
}
char str[]="hello win!";
fwrite(str,sizeof(str[0]),strlen(str),f);//第一个参数是要传入数据的数组,数组名就行,第二个参数是数组内每个元素的字节大小
//第三个参数是要传入多少个元素进去,第四个参数是要将数据传入到哪个文件里面去
//那么这里我们要注意,我们传入字符串的话,是不用把字符串结尾的\0也输入到文件里面去
//这会导致乱码,为什么呢?因为\0是针对C语言的,关文件什么事
//所以我们对fwrite的第三个参数只需要strlen就行(统计字符串中\0前面的字符个数)
//这一点需要注意,不难很容易有问题
int count=5;
while(count)
{
//可不要忘记了还有fprintf函数哦
fprintf(f,"%d:%s\n",count,str);//换行符也可以传入的哦
--count;
}
fclose(f);
return 0;
}(2)二进制读:fread(文件→内存,适合所有文件)
作用:把文件中的数据 "原样搬到" 内存的缓冲区(比如数组)里,适合读任何文件(文本、图片、视频等),和fwrite差不多,也是霸道,只不过是把数据从文件搬到代码内部。
函数原型:
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);参数说明
| 参数 | 含义(通俗解释) | 例子 |
|---|---|---|
ptr |
接收数据的内存缓冲区地址("目的地") | 字符数组buf[1024]的首地址buf,数据存在这里。 |
size |
单个数据元素的字节大小(和fwrite一致) |
读字符时size=1,读int时size=4。 |
nmemb |
计划读取的最大元素个数(最多读多少 "小单位"),一般还是sizeof(数组名) | 缓冲区buf[1024]存字符(size=1),则nmemb=1024(最多读 1024 个字符)。 |
stream |
文件指针,指定要读取的源文件 | 如fp(源文件)、stdin(从键盘读)。 |
返回值:实际成功读取的 "元素个数"
返回size_t类型,表示实际读取的元素个数(不是字节数)。
- 正常 1:读到数据,返回值 > 0 且≤
nmemb(如计划读 1024 字符,实际读 500(因为文件内只有500个数据),返回 500) - 正常 2:文件读完,返回 0,且
feof(stream)为真(用feof判断)。 - 异常:读取错误,返回 0,且
ferror(stream)为真(用ferror判断)。
总读取字节数:返回值 × size
例如:fread(buf, 1, 1024, fp)中,size=1,若返回 500,则总读取500×1=500字节(存在buf中)。
例子:读文件内容并显示到屏幕
char buf[1024]; // 缓冲区(一次最多存1024个字符)
while (1) { // 循环读,直到文件读完
// 读文件:最多读1024个字符到buf
size_t s = fread(buf, 1, sizeof(buf), fp); // s是实际读到的字符数
if (s > 0) { // 读到数据了
// 用printf("%s")显示需要字符串结尾的'\0',手动加一个
buf[s] = '\0'; // 注意:s不能超过1023,否则越界
printf("%s", buf); // 显示到屏幕
}
// 检查是否读完(后面讲feof的用法)
if (feof(fp)) {
break; // 读完了,退出循环
}
}(3)格式化写:fprintf(按格式写文本,适合文本文件)
作用:按指定格式把内存中的数据(如整数、字符串)写成 "人类能看懂的文本" 并写入文件(或显示器),类似printf,但可指定目标,这个就不嫩把二进制也给写入,换言之就是没那么霸道了
函数原型:
int fprintf(FILE *stream, const char *format, ...);参数说明
stream:目标文件流(文件指针),如fp(写入文件)、stdout(写入显示器,和printf一样)。format:格式字符串,含格式占位符(如%d(整数)、%s(字符串)),指定写入格式。- 后面的参数:要写入的数据,对应格式占位符(如整数、字符串),这个其实就是与printf里面的一样,大家看下面的代码示例就知道了
返回值:成功写入的字符数(失败返回负数)
- 正常:返回写入的总字符数(包括格式符中的字符)。例如:
fprintf(fp, "姓名:%s,年龄:%d\n", "张三", 20)中,写入的文本是"姓名:张三,年龄:20\n",共 15 个字符,返回 15。 - 异常:返回负数(如文件关闭、写入错误)。
例子:往文件写格式化信息
FILE *fp = fopen("info.txt", "w");
if (fp == NULL) {
perror("fopen failed"); // 打印错误原因
return 1;
}
// 往文件写3条用户信息(姓名+年龄)
fprintf(fp, "用户1:%s,%d岁\n", "张三", 20);
fprintf(fp, "用户2:%s,%d岁\n", "李四", 22);
fprintf(fp, "用户3:%s,%d岁\n", "王五", 25);
fclose(fp); // 关闭文件运行后,info.txt的内容为:
用户1:张三,20岁
用户2:李四,22岁
用户3:王五,25岁(4)格式化读:fscanf(按格式读文本,适合文本文件)
作用:按指定格式从文件(或键盘)读取 "人类能看懂的文本",解析成对应的数据类型(如整数、字符串)存到内存,类似scanf,但可指定来源。
函数原型:
int fscanf(FILE *stream, const char *format, ...);参数说明
stream:源文件流(文件指针),如fp(从文件读)、stdin(从键盘读,和scanf一样)。format:格式字符串,含格式占位符(如%d、%s),需和写入时的格式匹配。- 后面的参数:接收数据的变量地址(需加
&,字符串数组除外,没错,也是和scanf函数里面的参数一样,大家依旧是可以看下面的代码就知道了。
返回值:成功读取的 "数据项数"(失败返回EOF)
- 正常:返回成功读取的数据项数(和格式占位符数量一致)。例如:
fscanf(fp, "%s %d", name, &age)中,若成功读 1 个字符串和 1 个整数,返回 2。 - 异常:返回
EOF(表示读取错误或文件尾)。
例子:从文件读格式化信息
FILE *fp = fopen("info.txt", "r");
if (fp == NULL) {
perror("fopen failed");
return 1;
}
int id;
char name[20];
int age;
// 循环读文件中的"id+姓名+年龄"(格式需和写入时一致)
while (fscanf(fp, "用户%d:%s,%d岁\n", &id, name, &age) == 3) {
// 若成功读3项数据(id、name、age),则输出
printf("读到:id=%d,姓名=%s,年龄=%d\n", id, name, age);
}
fclose(fp);运行后,会输出文件中存储的 3 条用户信息。
3. 判断文件状态:feof和ferror(区分正常结束与错误)
当fread返回 0(或fscanf返回EOF)时,需要判断是 "文件读完了" 还是 "读出错了",这就需要feof和ferror。
(1)feof:判断是否到达文件尾
作用:检查文件流是否到达 "文件末尾"(正常结束)。
函数原型:
int feof(FILE *stream);返回值
- 已到达文件尾:返回非 0 值(真);
- 未到达:返回0(假)。
(2)ferror:判断是否发生读取错误
作用:检查文件流是否发生 "读取 / 写入错误"(如文件损坏、权限不足)。
函数原型:
int ferror(FILE *stream);返回值
- 发生错误:返回非 0 值(真);
- 未发生错误:返回0(假)。
(3)用法:结合fread/fscanf的返回值
当fread返回 0(或fscanf返回EOF)时,用这两个函数区分原因:
char buf[1024];
size_t s = fread(buf, 1, sizeof(buf), fp);
if (s == 0) { // 没读到数据
if (feof(fp)) { // 先判断是否到文件尾
printf("文件已读完\n");
} else if (ferror(fp)) { // 再判断是否出错
printf("读文件出错\n");
}
}4. 关闭文件:fclose函数(还 "钥匙")
作用:告诉操作系统 "我用完这个文件了",释放资源。
用法:fclose(fp);
为什么必须关?
- 数据可能存在临时缓存中,关文件时才真正写入硬盘;
- 操作系统限制同时打开的文件数量(比如最多 1024 个),不关闭会占名额。
5. 程序自带的 3 个 "特殊文件"
C 语言程序一启动,会自动打开 3 个 "文件",不用手动fopen:
stdin:对应键盘(输入设备),scanf就是从这读数据。stdout:对应显示器(输出设备),printf默认往这写数据。stderr:对应显示器,专门输出错误信息(比如程序崩溃提示)。
往显示器写内容的 3 种方式
cpp
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
//我们来实现几个能够把数据输出到显示器上
int main()
{
//第一个,毋庸置疑,最经典的printf函数
printf("hello win!\n");
//第二个,我们自己指定文件的fprintf函数
fprintf(stdout,"hello win!\n");
//第三个,也是我们自己指定文件的函数,fwrite函数
char str[]="hello win!\n";
fwrite(str,sizeof(str[0]),sizeof(str),stdout);
//使用方法不必多说
}6. 实战案例
(1)模拟cat命令(读文件并显示)
cat是 Linux 的命令,功能是 "读指定文件,把内容显示到屏幕"。核心逻辑:
cpp
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <stdlib.h>
int main(int argc,char* argv[])
{
//因为要我们自己模拟实现cat指令
//所以我们肯定就得知道用户要打开的是哪个文件
//而那个文件名字其实就存储在argv【1】里面 eg:cat test.txt
//很明显,这个main函数需要用变量,获取所输入的
if(argc==2)
{
FILE* f=fopen(argv[1],"r");//以只读方式打开
if(f==NULL)
{
perror("fopen failed:");
exit(2);
}
char str[1024]={0};//创建存储字符的数组
while(1)//不断将文件内的内容读取到str数组里面
{
size_t ret=fread(str,sizeof(str[0]),1024,f);//和fwrite函数的参数一样,意思也一样
//第二个参数依旧是数组内的一个元素的字节大小
//因为我们压根不知道文件内有多少数据,但是我们又想全部输入到数组内
//所以我们就得借助死循环,去直接1024个1024个的输入数据
//从文件 f 中读取 1024 个 "大小为 sizeof(str[0]) 字节" 的元素,存储到 str 中,
//并用 ret 记录实际读取的元素个数(成功时 ret=1024或者小于1024的,失败或文件尾时 ret=0)。
//还有一点需要知道的是,fread函数是会覆盖掉原本的str内的内容的
//所以不用担心文件内数据个数大于1024的情况
//那么每当我们读取一个字符,就可以输出一个字符来,不用等将文件内容全部读取完了再去输出
//这就需要fread函数的返回值,它会返回每次读取成功的数据的个数,这个很重要
//那么因为我们是读取字符类型的数据
//所以其实都是一个字节
//又因为我们是用%s进行输出,这就要求字符数组(字符串)最后一个元素得是\0
//但是文件内是肯定没有的,所以就得我们自己手动去增加
//那么我们怎么知道要在哪里加呢?
//其实就是在字符数组的下标为ret的位置加\0,
//因为我们知道ret是每次成功读取的数据的个数,那么由于数组是从0开始存储的
//所以第ret个就是为空,而ret-1个就是有数据
//所以我们要把ret那个位置赋值为\0
if(ret>0)
{
str[ret]='\0';
printf("%s",str);
}
//最后怎么知道文件是否读取结束呢?
//用feof函数,这个会判断文件是否读取完
if(feof(f))
{
break;//终止循环
}
//那么feof只是判断文件数据是否读取结束
//要是文件数据读取过程中出错了呢?
//这就需要ferror函数去帮我们判断了
else if(ferror(f))
{
printf("文件读取出错");
fclose(f);
exit(2);
}
//那么其实还有fscanf函数,这个的话,就自行熟练了,没多难
}
fclose(f);
}
return 0;
}(2)用fprintf和fscanf读写学生信息
需求:往文件写 3 个学生的 "姓名 + 成绩",再读出来显示。
#include <stdio.h>
int main() {
// 步骤1:往文件写学生信息(用fprintf)
FILE *fp = fopen("students.txt", "w");
if (fp == NULL) {
perror("fopen write failed");
return 1;
}
fprintf(fp, "张三 90\n");
fprintf(fp, "李四 85\n");
fprintf(fp, "王五 95\n");
fclose(fp); // 写完关闭
// 步骤2:从文件读学生信息(用fscanf)
fp = fopen("students.txt", "r");
if (fp == NULL) {
perror("fopen read failed");
return 1;
}
char name[20];
int score;
printf("读取的学生信息:\n");
// 循环读,直到fscanf返回非2(表示没读到2项数据)
while (fscanf(fp, "%s %d", name, &score) == 2) {
printf("%s:%d分\n", name, score);
}
// 步骤3:判断结束原因
if (feof(fp)) {
printf("读完所有学生信息\n");
} else if (ferror(fp)) {
printf("读文件出错\n");
}
fclose(fp);
return 0;
}三、总结
- 文件的本质:硬盘里的 "属性 + 内容" 集合,操作文件就是 IO 操作(内存和硬盘间搬数据)。
- Linux 的设计:"一切皆文件",统一设备和文件的操作方式,简化使用。
- C 语言操作流程 :
fopen:打开文件,拿 "钥匙"(文件指针),必须检查是否成功;- 读写:
fwrite/fread(二进制,适合所有文件)、fprintf/fscanf(格式化,适合文本文件); - 判断状态:
feof(文件尾)、ferror(错误),在读写返回 0(或EOF)时使用; fclose:关闭文件,还 "钥匙",避免资源泄漏。
- 关键原则:打开必检查、读写必判断状态、用完必关闭,确保操作正确。
这一部分的内容,其实应该在我们之前学习C语言文件操作的时候,就要知道了,当然,我们也确实是知道,只不过现在忘记了~~~,那么大家现在就是要当作复习,巩固记忆。
文件IO:
一、核心数据结构:进程与文件的 "关联桥梁"
操作系统靠三个关键结构体打通进程与文件的交互通道:
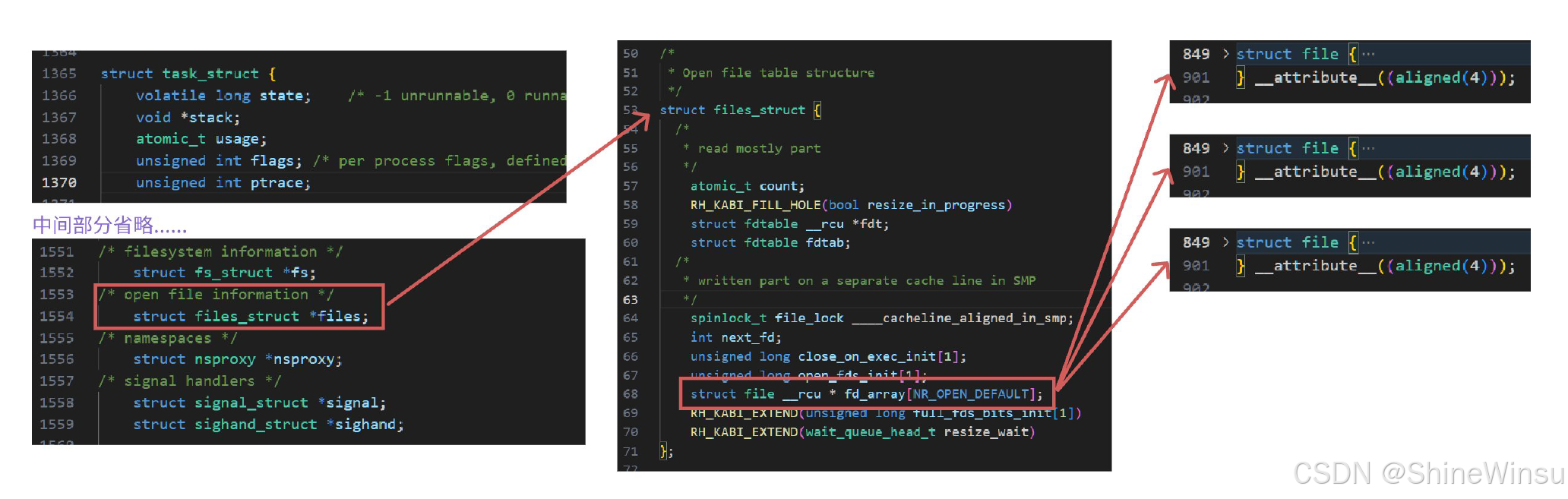
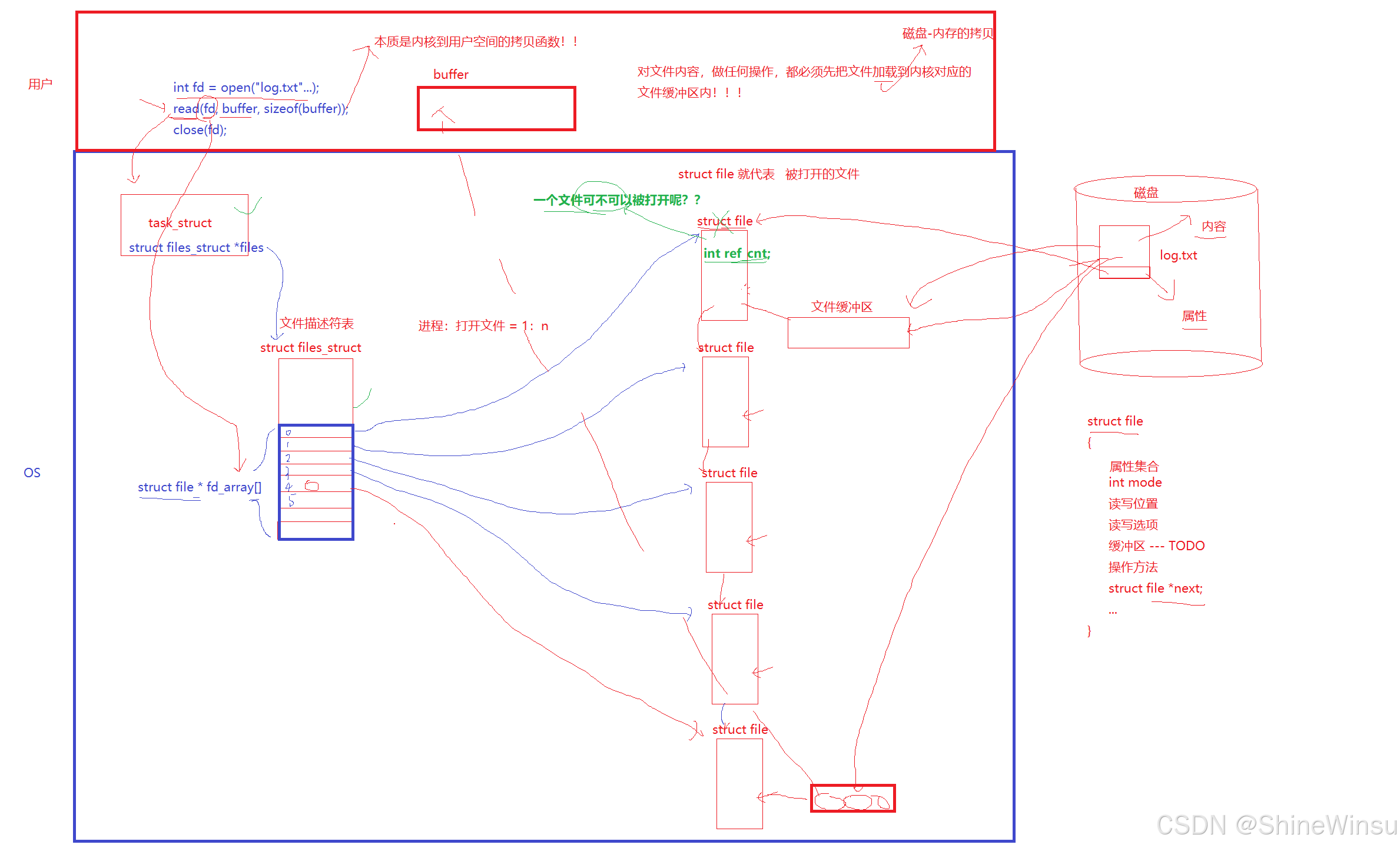
1. struct file:文件的 "详细档案"
- 作用:只要文件被打开,操作系统就会为它创建唯一的
struct file结构体,相当于给文件建了一份永久存档,后续所有操作都基于这份档案记录,这个结构体内就存储着这个文件的信息,是文件的身份证 - 核心内容(通俗拆解) :
- 基础属性:文件的完整路径(比如 "/home/user/ 笔记.txt")、访问权限(只读 / 可写 / 可执行),就像档案里记录的文件 "存放地址" 和 "使用规则";
- 操作状态:当前读写位置(比如读到了第 100 字节,下次自动从 101 字节开始),类似档案标注 "上次读到哪一页",避免重复或遗漏;
- 存储信息:文件存在哪个物理设备(比如硬盘的 C 盘、D 盘分区),相当于档案记录 "文件存放在公司哪个柜子";
- 安全机制:引用计数(记录有多少个进程正在用这个文件),比如两个进程同时读一份日志文件,引用计数就是 2,只有计数变为 0 时,系统才会删除这份 "档案",避免一个进程误关闭文件导致其他进程出错。
- 关键特点:同一文件被多个进程同时打开时,操作系统只会创建一份
struct file结构体。就像公司的《员工手册》,多个部门共用同一份原件,不会重复打印,节省系统资源。
2. struct files_struct:进程的 "文件管理部门"
- 作用:每个进程都有专属的
files_struct结构体,相当于进程内部的 "文件管理部门",专门负责登记该进程打开的所有文件。 - 核心内容 :
- 核心组件:一个叫
fd_array的指针数组,数组里的每个元素都是指向struct file的指针。比如数组下标 3 指向 "笔记.txt" 的struct file,这个指针就像 "档案索引",告诉管理部门 "这份文件的档案在哪个柜子",其实就是fd,叫作文件描述符,这个我们会在下面的内容中讲到,是文件操作的关键所在。 - 管理信息:记录该进程已打开的文件总数、最多能打开多少个文件(默认 1024 个),相当于管理部门的 "文件登记上限"。
- 核心组件:一个叫
3. struct task_struct:进程的 "身份信息卡"
- 作用 :每个运行的进程都有一张 "身份证"------
task_struct结构体,里面记录了进程的所有关键信息:进程 ID(相当于员工工号)、运行状态(正在工作 / 等待资源)、占用的内存大小等。 - 与文件管理的关联 :这张 "身份证" 上专门标注了 "文件管理部门" 的位置 ------ 一个叫
*files的指针,通过这个指针能直接找到该进程的files_struct,就像员工身份证上标注了所属部门地址,方便快速对接工作。
这个我们之前说过了,相信大家都不陌生。
三者关联关系(类比总结)
进程(员工)→ task_struct(身份证)→ *files指针(指向文件管理部门)→ files_struct(文件管理部门)→ fd_array数组(文件登记表)→ 指针(档案索引)→ file结构体(文件档案)简单说:员工(进程)凭身份证(task_struct)找到文件管理部门(files_struct),再通过登记表(fd_array)的索引,找到对应文件的档案(struct file),最终操作文件。
二、标志位传递:用 "二进制开关" 精准控制功能
标志位是系统接口的 "功能开关",核心是用二进制位表示单个功能,通过简单的位运算组合或判断功能状态,是 Linux 的经典高效设计。
1. 为什么用二进制?
一个 32 位整数有 32 个二进制位,每个位都能当一个 "独立开关":
- 位值为 1 → 开关打开(功能启用);
- 位值为 0 → 开关关闭(功能禁用)。比如用一个整数就能控制 "只读、创建、追加" 等多个功能,不用传多个参数,既高效又节省系统资源。就像手机的快捷设置面板,一个面板能控制 Wi-Fi、蓝牙、手电筒等多个功能,不用单独打开每个设置页。
2. 标志位的表示方式:八进制与二进制的对应
代码里常用八进制定义标志位,因为 1 个八进制位刚好对应 3 个二进制位,书写更简洁(比如二进制00000001用八进制0001表示)。核心对应关系如下:
| 八进制 | 二进制 | 位位置(从 0 开始数) | 通俗理解 |
|---|---|---|---|
| 0001 | 00000001 | 第 0 位 | 第一个功能开关 |
| 0002 | 00000010 | 第 1 位 | 第二个功能开关 |
| 0004 | 00000100 | 第 2 位 | 第三个功能开关 |
| 0010 | 00001000 | 第 3 位 | 第四个功能开关 |
3. 核心运算:组合与判断功能
(1)或运算(|):同时开启多个功能
- 类比:同时按下电器的 "照明" 和 "吹风" 开关,两个功能一起工作;就像同时打开手机的 Wi-Fi 和蓝牙。
- 运算规则:两个二进制位只要有一个是 1,结果就是 1。
- 实例:定义
ONE=0001(功能 1)、TWO=0002(功能 2),执行ONE | TWO:二进制计算:0001 | 0002 == 0011 = 0003,最终这个结果就代表 "同时开启功能 1 和功能 2"。
(2)与运算(&):检查某个功能是否开启
- 类比:看电器的 "照明" 开关是否打开;就像检查手机蓝牙是否处于开启状态。
- 运算规则:两个二进制位必须都是 1,结果才是 1;只要有一个是 0,结果就是 0。
- 实例:
- 若
flags=0003(已开启功能 1 和 2),判断是否开启功能 1:0003 & 0001 = 0001(结果非 0,说明功能 1 已开启); - 若
flags=0002(只开启功能 2),判断是否开启功能 1:0002 & 0001 = 0000(结果为 0,说明功能 1 未开启)。
- 若
4. 代码实例
// 定义3个独立功能的标志位(每个占1个二进制位,互不冲突)
#define ONE 0001 // 功能1:第0位为1(比如"打印日志")
#define TWO 0002 // 功能2:第1位为1(比如"保存数据")
#define THREE 0004 // 功能3:第2位为1(比如"发送通知")
// 接收组合后的功能开关,判断开启了哪些功能
void func(int flags) {
if (flags & ONE) printf("flags包含ONE! "); // 检查"打印日志"功能
if (flags & TWO) printf("flags包含TWO! "); // 检查"保存数据"功能
if (flags & THREE) printf("flags包含THREE! "); // 检查"发送通知"功能
printf("\n");
}
int main() {
func(ONE); // 只开"打印日志"→ 输出:flags包含ONE!
func(THREE); // 只开"发送通知"→ 输出:flags包含THREE!
func(ONE | TWO); // 开"打印日志+保存数据"→ 输出:flags包含ONE! flags包含TWO!
func(ONE | THREE | TWO); // 开所有功能→ 输出:flags包含ONE! flags包含TWO! flags包含THREE!
return 0;
}- 编译运行步骤 :把代码保存为
flag_demo.c,用gcc flag_demo.c -o flag_demo编译,执行./flag_demo就能看到对应输出。
5. 常见疑问:为什么不用普通整数表示功能?
如果用ONE=1、TWO=2、THREE=3,会出现严重冲突:比如TWO | THREE = 2 | 3 = 3,程序无法区分是 "只开 THREE" 还是 "同时开 TWO+THREE";而用二进制位独立表示时,每个功能的位互不重叠(比如 ONE 占第 0 位、TWO 占第 1 位),组合后的结果唯一,不会混淆。
三、系统文件 I/O 接口:直接与操作系统 "对接"
系统调用接口绕开了 C 库的 "中间环节",直接和操作系统内核通信,是文件操作的 "底层快车道",核心有open、write、read、close四个接口,掌握它们就能实现基础的文件读写。
1. 核心接口:open(打开 / 创建文件)
作为文件操作的 "第一步",负责打开已存在的文件,或创建新文件。
(1)函数原型与头文件
// 必须包含的头文件(相当于"系统调用的准入凭证",少了就会编译报错)
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
// 用法1:打开已存在的文件(不用创建)
int open(const char *pathname, int flags);
// 用法2:创建新文件(文件不存在时)
int open(const char *pathname, int flags, mode_t mode);- 头文件作用 :这些头文件里定义了函数的参数类型、返回值类型和相关常量(比如
O_RDONLY),编译器需要靠它们识别函数。
(2)参数深度解析
① pathname:文件路径(告诉系统文件在哪)
- 相对路径:以当前工作目录为起点,比如
"myfile.txt"(表示当前文件夹下的myfile.txt);- 适用场景:操作当前项目内的文件,比如编写日志程序时,把日志存到项目的
log文件夹。
- 适用场景:操作当前项目内的文件,比如编写日志程序时,把日志存到项目的
- 绝对路径:从根目录(
/)开始的完整路径,比如"/home/user/myfile.txt";- 适用场景:操作系统中固定位置的文件,比如读取系统配置文件
/etc/profile。
- 适用场景:操作系统中固定位置的文件,比如读取系统配置文件
② flags:打开方式(核心参数,控制文件操作模式)
- 基础选项(三选一,必须指定):
O_RDONLY:只读模式(只能读,不能写),比如打开系统配置文件/etc/passwd,避免误修改;O_WRONLY:只写模式(只能写,不能读),比如写日志文件,防止程序误读日志内容;O_RDWR:可读可写模式,比如编辑文档时,既能看内容又能修改。
- 扩展选项(可多选,用
|组合):O_CREAT:文件不存在就创建(没有这个选项的话,文件不存在会直接报错);- 例子:
open("newfile.txt", O_WRONLY | O_CREAT, 0644),如果newfile.txt不存在,就创建它。
- 例子:
O_APPEND:追加写模式(新内容加在文件末尾),比如往日志文件里添加新的日志记录,不会覆盖旧内容;O_TRUNC:清空写模式(打开文件时,把原有内容全部删除),比如重新写配置文件时,先清空旧配置。
③ mode:创建文件的权限(仅flags带O_CREAT时需要)
- 权限规则:用八进制数字表示,总共 4 位(第 1 位是前缀 0,后 3 位分别对应 "文件所有者、同组用户、其他用户" 的权限);
- 权限数值对应:
r(读权限)=4,w(写权限)=2,x(执行权限)=1;- 权限组合:比如 "可读可写" 就是 4+2=6,"可读可执行" 就是 4+1=5。
- 实例解析:
0644(最常用的文件权限)- 第 1 位 0:八进制前缀,告诉编译器这是八进制数;
- 第 2 位 6:文件所有者权限(4+2 = 可读可写);
- 第 3 位 4:同组用户权限(仅可读);
- 第 4 位 4:其他用户权限(仅可读)。
- 注意:权限掩码(umask)的影响:系统默认有
umask(比如默认umask=0022),会屏蔽部分权限。计算方式是 "文件权限 & ~umask":- 例子:创建文件时指定
mode=0644,默认umask=0022,实际权限是0644 & ~0022 = 0622(其他用户的写权限被屏蔽了); - 解决办法:用
umask(0)取消权限掩码,确保创建的文件权限和指定的mode一致。
- 例子:创建文件时指定
(3)返回值说明
- 成功:返回一个非负整数,这个数就是 "文件描述符(fd)",相当于文件的 "操作身份证",后续读写文件都靠它;
- 失败:返回
-1,用perror("open")能打印具体错误原因(比如 "权限不足""路径不存在""文件已被占用")。- 例子:如果用普通用户身份打开
/root/secret.txt,会返回-1,perror("open")输出open: Permission denied(权限被拒绝)。
- 例子:如果用普通用户身份打开
2. 核心接口:write(写文件)
负责把进程缓冲区里的数据,写入到文件中。
(1)函数原型与参数
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);- 参数拆解:
fd:文件描述符(open函数返回的 "操作身份证",告诉系统要写哪个文件);buf:数据缓冲区(要写入的内容存放在这里,比如字符串的地址);count:期望写入的字节数(比如字符串的长度,不能超过缓冲区的大小,否则会导致数据溢出)。
- 返回值说明:
- 成功 :返回实际写入的字节数(正常情况下和
count相等); - 失败 :返回
-1(比如文件已被关闭,或磁盘空间满了)。
- 成功 :返回实际写入的字节数(正常情况下和
- 类型说明:
ssize_t:带符号整数,能表示负数(用来表示错误);size_t:无符号整数,只能表示非负数(用来表示数据长度)。
(2)代码实例拆解(带细节说明)
const char *msg = "hello bit!\n"; // 要写入的字符串
int len = strlen(msg); // 计算字符串长度(结果是9字节)
write(fd, msg, len); // 往fd对应的文件写入9字节- 为什么用
strlen而不用sizeof? :- 字符串末尾有一个隐藏的
\0(C 语言的字符串结束符),这个字符不用写入文件,因为\0只是针对C语言的,关文件什么事情呢,所以我们不用把\0也传进文件内,这个大家要注意 strlen(msg)会计算\0之前的有效字符长度("hello bit!\n" 共 9 个字符);- 如果用
sizeof(msg),会把\0也算进去(长度为 10 字节),导致文件里多一个无用字符。
- 字符串末尾有一个隐藏的
3. 核心接口:read(读文件)
负责把文件里的数据,读取到进程的缓冲区中。
(1)函数原型与参数
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);- 参数拆解:
fd:文件描述符(指定要读哪个文件);buf:数据缓冲区(读取到的数据会存到这里,通常是字符数组);count:期望读取的字节数(建议设为缓冲区大小,避免数据溢出)。
- 返回值说明:
- 成功 :返回实际读取的字节数(可能小于
count,比如文件剩余内容不足count字节); - 0:读到文件末尾(比如文件共 100 字节,已经读了 100 字节,再读就返回 0);
- 失败 :返回
-1(比如文件已关闭,或设备断开连接)。
- 成功 :返回实际读取的字节数(可能小于
(2)代码实例:循环读逻辑(带场景说明)
char buf[1024]; // 定义1024字节的缓冲区(能存1024个字符)
while(1) {
ssize_t s = read(fd, buf, strlen(msg)); // 每次读9字节(和之前写入的长度一致)
if(s > 0) { // 读到了数据,打印出来
printf("%s", buf);
} else { // s=0(读完了)或s=-1(读失败),退出循环
break;
}
}- 为什么要循环读?:
- 如果文件很大(比如 10MB),而缓冲区只有 1024 字节,
read一次只能读 1024 字节,无法读完整个文件; - 循环读能反复调用
read,直到返回 0(文件读完)或-1(读失败),确保能读取完整文件。
- 如果文件很大(比如 10MB),而缓冲区只有 1024 字节,
- 场景例子 :读一个 2000 字节的文件,缓冲区 1024 字节,第一次
read读 1024 字节,第二次读 976 字节,第三次读返回 0,循环退出。
4. 核心接口:close(关闭文件)
作为文件操作的 "最后一步",负责释放资源,断开进程与文件的关联。
(1)函数原型与功能
#include <unistd.h>
int close(int fd);- 核心功能 :释放文件描述符
fd,让系统回收这个fd(后续进程能重新使用),同时减少对应struct file的引用计数。 - 为什么必须调用? :
- 系统给每个进程分配的文件描述符数量有限(默认 1024 个);
- 如果不调用
close,fd会一直被占用,引用计数也不会归零,struct file无法被释放,导致 "资源泄漏"; - 后果:进程打开的文件越来越多,最终
open会返回-1,报错 "打开的文件过多",程序无法正常工作。
- 返回值说明 :
- 成功:返回 0;
- 失败 :返回
-1(比如fd已经被关闭,或fd是无效值)。
5. 实战:写文件 + 读文件完整流程
(1)写文件程序(test_write.c)
cpp
#include <stdio.h>
#include <fcntl.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/types.h>
#include <errno.h>
int main()
{
//我们之前使用的fopen函数,其实底层是调用open函数
//这是个系统接口,底层函数
int fd=open("test_openwrite.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
//OK,接下来得好好知道这个函数的三个参数的含义,很重要
//那么第一个参数其实毋庸置疑,就是要打开的文件的路径,没有的话就默认在本目录下进行寻找
//重点是第二个参数,那么这个参数其实是告诉系统,你要怎么打开这个文件,诶,感觉和fopen很像
//但是呢,open函数不传w或者r什么什么的
//要转标志位,本质上是宏定义的一些数字
//那么如果我们想要以写文件的方式打开的话,那么我们就得给第二个参数写O_WRONLY,表示只写
//但是这还不够,我们知道我们之前的fopen函数以w方式打开的话,
//要是没有指定路径下的文件的话,那么系统是会创建出一个对应的文件去的
//还有就是以w方式打开的话,那么指定文件已有的话,系统就会把那个文件的内容清空
//但是在我们open函数的话,我们想要达到这个功能仅仅使用O_WRONLY是不够的
//还要给O_WRONLY|上W_CREAT,W_CREAT表示要是没有指定的文件的话,就创建出这个指定文件来
//然后还要一起|W_TRUNC,这个就是表示要把已有指定文件里的内容进行清空
//所以,我们要是想达到fopen,w的功能的话,我们第二个参数就得传O_WRONLY|W_CREAT|W_TRUNC,顺序可以随意调换
//那么其实还有一个很重要的点,就是如果open函数创建指定文件的话
//那么是要求我们传入第三个参数,所创建的指定文件的权限码,这个我们之前说过
//那么一般就是直接传入0666,然后系统就会0666&umask,使用最终的结果作为权限
//如果我们想在代码内部修改的话
//可以使用umask函数,即可
//还有就是使用O_TRUNC是会把打开的文件的内容清空再进行写入数据的
//那么要是我们是想追加内容呢,即以fopen函数的'a'方式打开
//那么我们只需要把O_TRUNC换为O_APPEND即可,简简单单
//打开了文件之后,我们就可以对文件写入内容
//那么我们之前是使用包装好的fwrite函数,那么在这里,我们就直接使用系统函数write函数
char str[]="hello win!\nyou are so handsome\n";
int ret=write(fd,str,sizeof(str[0])*strlen(str));
//那么对于write函数的参数其实是比较简单的,和fwrite函数的参数差不多,比较类似
//但是也有不同,write只需要三个参数,第一个参数是文件标识符
//其实它就是我们open函数的返回值,那么它其实是在系统中管理文件结构体的其中的管理和统计本进程打开文件的数组下标
//具体会再博客里讲,这里我们需要知道其实系统对于本进程用open打开的文件是用open函数的返回值记录起来的
//那么write函数的另外两个参数就比较简单了
//第二个是我们要要把哪个数组的数据传入文件的数组名,指针类型,即类似fwrite函数的第一个参数
//第三个则是一共要传入多少个字节的数据,这个就要注意了
//其实它相当于是fwrite函数的第二个第三个参数的乘积
//因为我们知道,fwrite函数的第二个参数一个数据的字节数,第三个参数则是一共要传入多少个字节的数据
//那么write函数的第三个参数就是总字节个数
//即我们要传入(一个数据的字节数*一共要传入多少个数据)作为write函数的第三个参数
//对于write函数的返回值,则是返回成功写入文件的数据的总字节数
//注意:是总字节数,而不是fwrite函数的数据个数(数据个数不一定等于总字节数)
//因为总字节数==数据个数*一个数据所占的字节数
//还是比较简单的
//将返回值打印到显示器上
write(stdout,ret,sizeof(ret)*1);
//对文件操作完之后,我们就要关闭文件
//那么依旧是不用fclose函数,我们就直接使用系统函数close函数
close(fd);
//只需要传入文件标识符就行,也就是open函数的返回值。
return 0;
}(2)读文件程序(test_read.c)
cpp
#include <stdio.h>
#include <fcntl.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/types.h>
int main()
{
//同样的,来测试一下系统函数read函数
//那么会了write函数之后,还有open函数、close函数的操作
//其实针对只读的open,改变也比较简单
int fd=open("test_openwrite.txt",O_RDONLY);
//那么依旧是要有返回值,记录我们打开的文件
//然后第一个参数依旧是指定文件路径,
//而后面一个参数就简单多了,因为我们只读是不用没有指定文件就创建的
//所以我们只传一个O_RDONLY就行
//就这么简单
char str[1024]={0};
//接下来就是使用read函数
while(1)
{
int ret=read(fd,str,1*sizeof(str));
//那么对于read函数,其实还是有点说法的
//那么它的第一个参数依旧是打开文件的文件标识符,即open函数的返回值
//然后它的第二个参数,我们就得传入要将文件数据放在哪个数组里的数组名,指针类型
//最后它的第三个参数,其实是和write函数的第三个参数差不多
//也是fread函数第二个第三个参数的乘积
//即要将文件内的多少个数据传入数组的数据的总字节数
//注意,是总字节数
//那么依旧是我们不知道文件内有多少个数据
//所以我们依旧是借助死循环
//每次读取数组总容量的总字节数
//那么我们要怎么知道是否读取完了呢?
//在之前我们是直接使用feof函数和ferror函数
//那么在这里,我们使用read函数就不需要了
//因为read函数的返回值会进行判断
//如果返回值为0,就代表读取结束
//如果返回值为<0,那么就代表读取文件过程中出错
//排除这两种情况的话,就会返回每次读取成功的总字节数
//是的,依旧是总字节数,fread函数是返回数据个数,两个可不一样哦
//所以我们就可以借助read函数的返回值进行判断
if(ret==0)
{
printf("文件读取结束!\n");
break;
}
else if(ret<0)
{
printf("文件读取过程出错!\n");
close(fd);
exit(2);
}
else if(ret>0)
{
str[ret]=='\0';
printf("%s",str);
//因为我们依旧是读取完一次就直接表达数据一下,而且是使用%s
//所以我们依旧得手动在最后一个有效数据的后一个位置赋值为'\0'
//那么因为read函数返回值大于0时是返回每次读取成功的总字节数
//所以我们就可以在返回值那个下标的位置进行赋值,毕竟数组是从0开始计数
//还有最重要的一点就是,我们是统一按照字符来进行读取和存入字符数组中
//而一个字符是一个字节,所以,read函数的返回值(总字节数)==读取成功的数据个数
//这个是很关键的
}
}
close(fd);
return 0;
}6. 常见问题排查
(1)写文件后看不到内容?
- 原因:如果混用 C 库函数(比如
printf)和系统调用(比如write),C 库函数有缓冲区,数据可能没及时写入文件; - 解决:用
fflush(stdout)强制刷新缓冲区,或改用write函数写内容。
(2)文件创建成功但权限不对?
- 原因:忘记调用
umask(0),系统默认的umask屏蔽了部分权限; - 解决:在
open之前调用umask(0),确保权限和mode参数一致。
(3)open返回-1?
- 排查步骤:
- 检查路径是否正确:比如把 "myfile.txt" 写成了 "myfile1.txt";
- 检查权限是否足够:比如普通用户往
/root目录写文件,会因权限不足失败; - 检查文件是否被占用:比如其他程序正在写这个文件,导致当前程序无法打开。
四、文件描述符(fd):进程的 "文件编号牌"
文件描述符是系统给打开的文件分配的 "编号",本质是进程files_struct中fd_array数组的下标,通过这个编号能快速找到对应的文件。
1. 底层原理(生活类比 + 细节拆解)
- 生活类比:学校的 "学生登记表" 是一个数组,每个学生的学号是数组下标,老师通过学号能快速找到学生的信息;
- 底层逻辑:
- 文件被打开后,操作系统创建
struct file(文件信息块); - 进程的
files_struct里有fd_array指针数组,数组下标就是fd; - 数组元素是指向
struct file的指针,相当于 "学生信息的地址"; - 进程操作文件时,只需传入
fd,系统用fd当下标访问fd_array,就能找到struct file,进而操作文件。
- 文件被打开后,操作系统创建
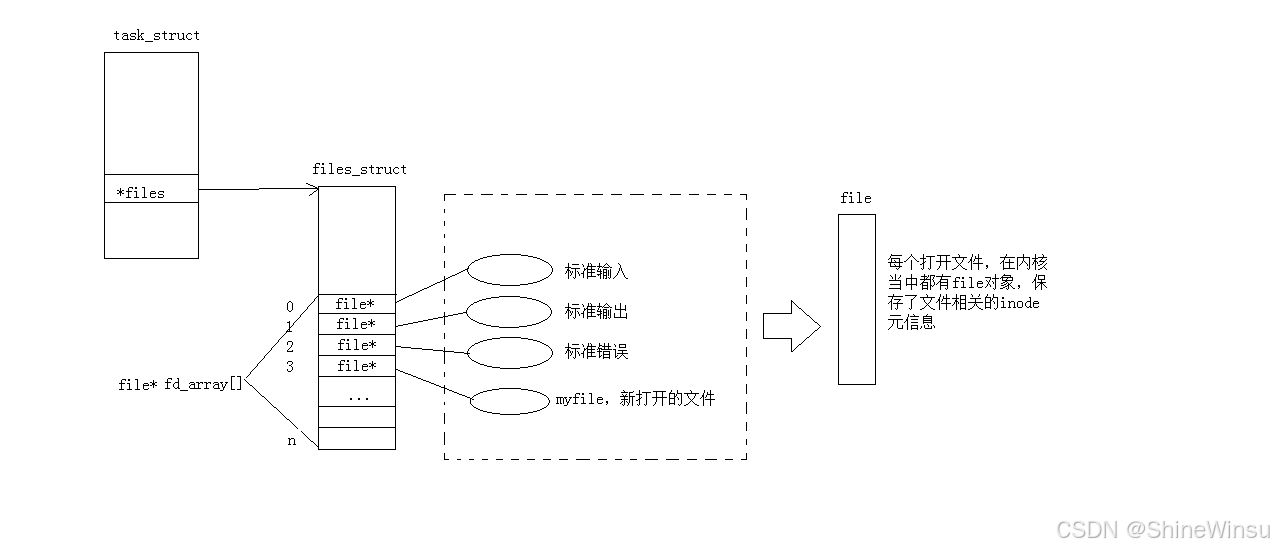
2. 进程默认的 3 个文件描述符
Linux 进程启动时,操作系统会自动完成 3 件事,所以进程一启动就有 3 个默认fd:
- 打开 3 个默认文件:标准输入(键盘)、标准输出(显示器)、标准错误(显示器);
- 为这 3 个文件创建
struct file结构体; - 让
fd_array的下标 0、1、2 分别指向这 3 个结构体。
这 3 个默认fd的详细信息如下表:
| fd | 名称 | 对应设备 | 作用 | 常用场景 |
|---|---|---|---|---|
| 0 | 标准输入 | 键盘 | 进程默认读数据的来源 | scanf、read(0, ...) |
| 1 | 标准输出 | 显示器 | 进程默认写数据的目标 | printf、write(1, ...) |
| 2 | 标准错误 | 显示器 | 进程默认写错误信息的目标 | 程序报错信息输出 |
验证实验:直接读写 fd=0 和 fd=1(带运行效果)
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main() {
char buf[1024]; // 缓冲区,存读取到的数据
// 从fd=0(键盘)读数据,最多读1024字节
ssize_t s = read(0, buf, sizeof(buf));
if(s > 0) {
buf[s] = 0; // 给字符串加结束符,避免打印乱码
write(1, buf, strlen(buf)); // 往fd=1(显示器)写数据
write(2, buf, strlen(buf)); // 往fd=2(显示器)写数据
}
return 0;
}- 运行步骤 :
- 编译代码:
gcc fd_demo.c -o fd_demo; - 执行程序:
./fd_demo; - 输入内容:比如输入 "abc" 并回车;
- 运行结果:屏幕会打印两次 "abc",因为
fd=1和fd=2都指向显示器。
- 编译代码:
3. 文件描述符的分配规则:"抢最小的空闲编号"
当用open打开新文件时,系统会在fd_array中找 "当前未使用的最小整数" 作为新fd,就像停车场找 "最近的空车位"。
实验 1:关闭 fd=0 后打开新文件
cpp
#include <stdio.h>
#include <fcntl.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/types.h>
#include <errno.h>
//我们来研究一下文件标识符的规则
//我们知道,系统为了管理一个进程打开的文件
//会在PCB里面创建一个指针,然后这个指针指向管理文件的结构体
//而在那个管理文件的结构体中,有个数组
//数组下标就是记录本进程打开的文件,它的名字是文件描述符
//那么0是stdin,1是stdout,2是stderror
//从3开始才是我们在进程中打开的其他文件,以此递增
//然后在我们运行进程的时候
//系统默认把stdin、stdout、strerror这三个文件打开
//那么,要是我们把这三个随意一关,那么我们再打开一个文件
//这个文件的文件描述符是会在3及3之后,还是占据前面的位置呢?
int main()
{
close(0);
//把stdin给关了
int fd=open("test_fdrule.txt",O_CREAT|O_TRUNC|O_WRONLY,0666);
printf("fd=%d\n",fd);
//输出结果就会发现,fd是0,不是3或者3之后的数字,这就表明:
//文件描述符的分配规则:在files_struct数组当中,找到
//当前没有被使用的最小的一个下标,作为新的文件描述符。
close(fd);
return 0;
}- 注意 :关闭
fd=0后,键盘输入会失效,因为fd=0不再指向键盘。
实验 2:关闭 fd=1 后打开新文件
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main() {
close(1); // 关闭fd=1(标准输出,此时fd=1变成空闲)
int fd = open("myfile.txt", O_WRONLY | O_CREAT, 0644);
printf("新fd:%d\n", fd); // 输出:1(fd=1是最小空闲编号)
close(fd);
return 0;
}- 注意 :关闭
fd=1后,printf的内容不会显示在屏幕上,因为fd=1现在指向myfile.txt,内容会写入文件。
4. 常见疑问:fd 的最大值是多少?
- 默认限制 :每个进程能打开的
fd数量默认是 1024 个; - 查看方式 :在终端输入
ulimit -n,就能看到当前的fd上限; - 修改方式 :临时修改用
ulimit -n 2048(把上限改为 2048,重启终端后失效),永久修改需要修改系统配置文件(新手不建议操作); - 超限后果 :
open会返回-1,报错 "Too many open files"(打开的文件过多)。
5. 打开文件的完整流程:从 open 到 fd 的生成
以open("myfile.txt", O_RDONLY)为例,一步步看fd是怎么来的:
- 用户调用 open 系统调用:进程执行
open函数,这个请求会从用户态切换到内核态,让操作系统处理; - 内核检查文件并创建 struct file:
- 内核根据
pathname找文件,检查文件是否存在; - 检查进程是否有访问权限(比如读权限);
- 检查通过后,创建
myfile.txt的struct file,填写路径、权限、初始读写位置(0 字节)等信息;
- 内核根据
- 内核找到进程的 files_struct:
- 内核通过进程的
task_struct(身份卡)找到files_struct(文件管理部门); - 遍历
fd_array,找到最小的空闲下标(比如默认 3 个fd已占用,最小空闲下标是 3);
- 内核通过进程的
- 关联文件与进程,返回 fd:
- 把
struct file的地址存入fd_array[3]; - 内核把下标 3 作为
open的返回值,这个返回值就是fd。
- 把
最终,进程拿到fd=3,后续读写myfile.txt时,只要传入fd=3,系统就能找到对应的文件。
6. 通过 fd 操作文件的链路:从 read/write 到文件
以read(fd=3, buf, 1024)为例,看进程如何通过fd读文件:
- 进程传入 fd,请求操作系统操作:进程执行
read函数,传入fd=3、缓冲区buf、期望读取的 1024 字节; - 内核通过 fd 找到 struct file:
- 内核通过进程的
task_struct找到files_struct; - 用
fd=3当下标,访问fd_array[3],得到指向myfile.txt的struct file指针;
- 内核通过进程的
- 执行读写操作,更新文件信息:
- 内核根据
struct file里的 "当前读写位置"(比如 0 字节),从硬盘读取 0~1024 字节的数据; - 把数据存入
buf; - 更新
struct file的 "当前读写位置" 为 1024 字节,下次读就从这里开始;
- 内核根据
- 返回操作结果:内核把实际读取的字节数作为
read的返回值,返回给进程,完成一次读取。
7. 关键补充:为什么关闭文件要调用 close (fd)?
执行close(fd)时,内核会做这些事:
- 找到
fd_array[fd]对应的struct file; - 把
struct file的引用计数减 1; - 如果引用计数变为 0:
- 释放
struct file(删除文件档案); - 把
fd_array[fd]设为NULL,标记这个下标为空闲;
- 释放
- 如果引用计数不为 0:只释放
fd,struct file保留(其他进程还在使用)。
如果不调用close(fd),fd会一直被占用,struct file的引用计数也不会归零,导致资源泄漏,进程可用的fd会越来越少。
8. 核心逻辑链总结
open系统调用 → 操作系统创建file结构体(文件档案)→ 找到进程files_struct的空闲数组下标 → 数组元素指向file结构体 → 返回下标作为fd
↓
read/write系统调用 → 传入fd → 以fd为下标找到file结构体 → 操作文件并更新档案信息
↓
close系统调用 → 释放file结构体(引用计数为0时)→ 清空数组元素 → 释放fd本质上,fd就是进程 "文件登记表" 的下标,复用数组下标的计数规则,让设计既简洁又高效,这也是fd从 0 开始的原因。
五、重定向:改变 "数据流向" 的本质
重定向(>/>>/<)是 Linux 里常用的功能,核心是修改fd对应的文件,让数据的 "来源" 或 "去向" 改变,比如把显示器输出改成文件输出。
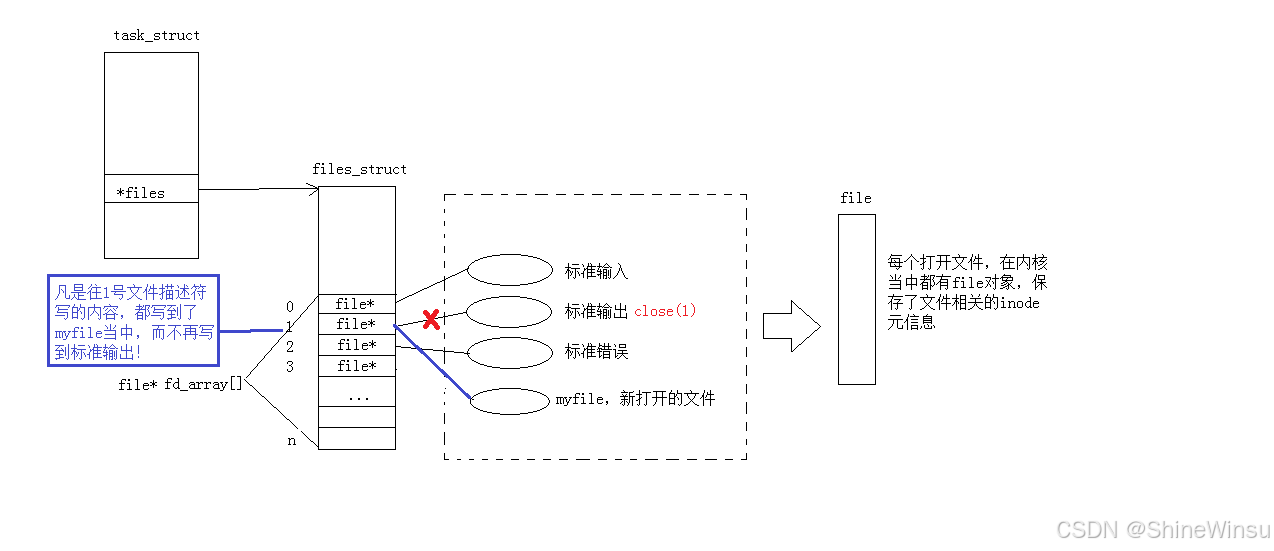
1. 输出重定向(>):把显示器输出改成文件输出
- 原理 :让
fd=1(标准输出)从指向显示器,改成指向目标文件; - 生活类比:把家里的电视信号线从电视拔掉,插到投影仪上,画面就从电视转到投影仪。
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
int main()
{
//那么我们前面是只把0关闭,即把stdin关闭
//那么要是我们把1,即stdout关闭呢?
//我们知道,stdout是把内容输出到显示器上的
//而平时使用的printf函数就是默认将数据输出到stdout文件
//而我们把它给关闭了,再去使用printf函数,会怎么样呢?
//因为我们知道,文件描述符的规则,所以当我们把stdout------1关闭之后
//再打开一个新的文件,那么这个文件就会占据1那个位置
//即以1为新打开的文件的文件描述符
close(1);
int fd=open("test_fd-1.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
if(fd==-1)//打开文件失败时,会返回-1
{
perror("open failed:");
exit(1);
}
char str[]="win";
printf("now fd is %d\n",fd);
printf("hello %s\n you are my idor\n",str);
fflush(stdout);//我们要把stdout文件缓冲区强制刷新一下,不难会没效果
close(fd);
return 0;
}- 关键疑问:为什么需要 fflush?:
- C 库的缓冲区分三种:行缓冲、全缓冲、无缓冲;
- 默认情况下,
printf是行缓冲,输出到终端时,遇到\n或缓冲区满了就刷新; - 重定向到文件后,
printf变成全缓冲,只有缓冲区满了(比如 4096 字节)才会写入文件; - 用
fflush(stdout)能强制把缓冲区的内容写入文件,避免程序退出前没刷新,导致内容丢失。
2. 追加重定向(>>):在文件末尾添加内容
只需在open时加O_APPEND选项,新内容就会追加到文件末尾,不会覆盖旧内容:
// 打开文件时加O_APPEND,实现追加
int fd = open("myfile.txt", O_WRONLY | O_CREAT | O_APPEND, 0644);- 对比 O_TRUNC :
O_TRUNC:打开文件时清空旧内容,新内容从文件开头写;O_APPEND:保留旧内容,新内容从文件末尾写。
3. 输入重定向(<):把键盘输入改成文件输入
- 原理 :让
fd=0(标准输入)从指向键盘,改成指向目标文件; - 生活类比:把麦克风拔掉,换成录音笔,声音来源就从现场变成录音笔。
代码实战(带运行效果)
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main() {
close(0); // 1. 关闭原fd=0(指向键盘)
// 2. 打开文件,fd=0指向myfile.txt
int fd = open("myfile.txt", O_RDONLY);
if(fd < 0) {
perror("open");
return 1;
}
char buf[1024];
// 3. 从fd=0读数据,实际是从myfile.txt读
ssize_t s = read(0, buf, sizeof(buf));
if(s > 0) {
buf[s] = 0;
printf("读到的内容:%s\n", buf);
}
close(fd);
return 0;
}- 运行效果 :执行程序后,会把
myfile.txt里的内容读取到缓冲区,然后打印到屏幕上,不用手动输入到屏幕上,最经典的就是cat指令
4. 重定向的本质总结
- 重定向不会改变命令的行为:比如
printf还是往fd=1写数据,只是fd=1对应的文件变了; - 核心是 "修改 fd 对应的 struct file":数据流向由
fd的指向决定,指向显示器就输出到屏幕,指向文件就写入文件; - 所有重定向工具(
>/>>/<)的底层,都是这套 "修改 fd 指向" 的逻辑。
六、dup2 函数:更便捷的 "重定向工具"
手动关闭旧fd再打开新文件的重定向方式,步骤繁琐还容易出错。dup2函数能一步完成重定向,是实际开发中常用的工具。
1. 函数原型与核心功能
#include <unistd.h>
int dup2(int oldfd, int newfd);- 核心功能 :让
newfd指向oldfd对应的文件,相当于 "复制oldfd的文件通道,接到newfd上"; - 自动处理 :如果
newfd原本指向某个文件,dup2会先自动关闭newfd,再建立新关联; - 返回值:
- 成功:返回
newfd; - 失败:返回
-1。
- 成功:返回
2. 生活类比
比如oldfd=3指向log.txt,newfd=1指向显示器。调用dup2(3,1)后,相当于把log.txt的 "文件通道" 复制一份,接到newfd=1上,后续往fd=1写数据,都会写入log.txt。
3. 代码实战 1:用 dup2 实现输出重定向
cpp
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
int main()
{
//那么前面我们知道了
//当我们把本进程打开的文件描述符2(stdout)给关了之后
//我们再使用printf函数,就会变为将其内的数据传进
//新的占据文件描述符2位置的文件里面
//而不再是stdout(显示器文件)
//因为printf函数虽然是往stdout输出数据
//但是他本质上其实是找本进程的2的文件描述符代表的文件
//那么我们前面是打开一个新的文件
//然后这个文件会占据2的位置
//但那只是打开一个文件的时候
//要是我们打开多个文件,然后是想在把后面一点的文件设置到文件描述符2那里呢?
//那么我们就得使用系统函数:dup2
close(1);//依旧是要先把1(stdout)给关了
int fd1=open("tset_dup.txt",O_WRONLY);//实验,我们就不写太认真
int fd2=open("test_dup2.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
if(fd2<0)
{
perror("open failed:");
exit(2);
}
dup2(fd2,2);
//这个dup2函数就是可以实现将指定文件描述符换为另一个指定文件描述符
//通俗易懂一点来说就是狸猫换太子,偷天换日
//相当于就是把文件描述符2那个位置的文件换为我们指定的文件
//即原本2那个位置是指向stdout,而我们dup2一下之后,2那个位置就改为指向我们传过去的文件
//那么对于dup2的两个参数,还是有些许说法的
//第一个参数是叫做oldfd,第二个参数叫做newfd
//那么是什么意思呢,其实就如参数的名字一样
//dup2函数会把oldfd指向的文件拷贝给newfd,使newfd也指向那一个文件
//所以我们一下就知道了,我们是把2传给newfd,把1传给oldfd
//此时我们再使用printf函数就是把数据都丢进2指向的新文件里了
printf("hello world!\n");
char str[]="this win speanking!\n";
for(int i=0;i<6;++i)
{
printf("%d:%s",i,str);
}
fflush(stdout);
close(fd2);
return 0;
}- 优势 :不用手动关闭
fd=1,dup2会自动处理,逻辑更简洁,还能避免忘记关闭旧fd导致的错误。
4. 代码实战 2:用 dup2 实现标准错误重定向
让fd=2(标准错误)也指向log.txt,程序的错误信息会写入文件,而不是显示器:
// 在dup2(oldfd, 1)后添加一行
dup2(oldfd, 2);- 效果测试 :比如在代码中故意写一个错误(比如
open一个不存在的文件),perror的错误信息会写入log.txt,屏幕上看不到错误提示。
5. 常见错误场景
- oldfd 无效 :比如
oldfd=5但没打开,调用dup2(5,1)会返回-1,fd=1还是指向原来的文件; - newfd == oldfd :比如
oldfd=3、newfd=3,dup2不做任何操作,直接返回3; - 权限不足 :比如
oldfd指向的文件是只读的,newfd=1要写数据,会返回-1。
七、整体总结:核心要点速记
- 标志位:二进制位当 "独立开关",
|是 "同时开多个开关",&是 "检查某个开关是否打开"; - 系统 I/O 接口:打开文件用
open,写数据用write,读数据用read,用完关闭用close,一步都不能少; - 文件描述符:进程的 "文件编号",默认 0(键盘)、1(显示器)、2(显示器),新编号抢 "最小空闲位",本质是数组下标;
- 重定向:不改命令改
fd指向,数据流向跟着变,比如把fd=1指向文件,输出就写入文件; - dup2 函数:重定向 "快捷键",一步复制
fd指向,开发中常用,避免手动操作出错。
OK大家,那么这篇博客我们就先到这里,在下篇博客中,我将带着把我们之前的shell的功能再完善一点,即加入重定向操作,然后会给大家详细讲讲Linux中一切皆文件,以及缓冲区,最后实现自己封装glibc库。
结语:以文件为舟,渡 Linux 学习之河
各位小伙伴,当你读到这里时,我们关于 Linux 文件操作的核心知识之旅已走过大半。从 C 语言封装的文件函数到操作系统底层的系统调用,从抽象的数据结构到具象的代码实战,从简单的读写操作到灵活的重定向技巧,我们一步步揭开了 Linux "一切皆文件" 的神秘面纱,在字符与字节的流转中,触摸到了操作系统的底层脉搏。此刻,想先对每一位坚持下来的你说一声:辛苦了,但你真的很棒!
回顾这段学习历程,我们从最基础的 "文件是什么" 出发,明白了文件是硬盘中 "属性与内容" 的统一体,是内存与外设之间数据流转的载体。在 C 语言文件操作的章节里,我们重温了fopen、fwrite、fscanf这些老朋友,理清了 "打开 - 读写 - 判断 - 关闭" 的核心流程,更理解了这些封装函数背后对系统接口的调用逻辑 ------ 它们就像贴心的向导,帮我们避开了直接与操作系统对话的复杂细节。而当我们深入到系统文件 I/O 接口时,open、write、read、close这四个核心函数,让我们真正站在了用户态与内核态的交界处,体验了直接与操作系统 "对话" 的纯粹与高效。
在这段旅程中,最具挑战性也最迷人的,莫过于对底层逻辑的探索。三个核心数据结构struct file、struct files_struct、struct task_struct,如同搭建起进程与文件交互的 "桥梁",我们用 "公司办公" 的类比将抽象的结构体具象化,终于明白:进程操作文件的本质,是通过文件描述符这个 "编号牌",在 "文件管理部门" 的登记表中找到对应文件的 "详细档案"。而文件描述符的分配规则 ------"抢最小的空闲编号",以及默认的 0、1、2 三个特殊描述符,更让我们看到了 Linux 系统设计的简洁与高效。
标志位的 "二进制开关" 设计,让我们惊叹于操作系统对资源的极致利用;重定向通过修改文件描述符的指向改变数据流向,展现了 Linux 系统的灵活与统一;dup2函数则像一把 "快捷键",简化了重定向的实现流程,让我们体会到实用工具对开发效率的提升。每一个知识点的突破,每一段代码的调试成功,都是我们对抗知识壁垒的胜利,都是从 "知其然" 到 "知其所以然" 的跨越。
我深知,学习底层知识的过程从不轻松。或许你曾为open函数的权限参数困惑不已,对着0644与umask的计算关系反复推演;或许你曾在调试重定向代码时,因忘记刷新缓冲区而看不到预期结果,陷入莫名的卡顿;或许你曾对文件描述符的底层链路一头雾水,对着三个核心结构体的关联关系画了无数张示意图。但请相信,这些困惑与挣扎都是学习路上的必经之路,它们不是用来打击你的,而是用来帮你夯实基础、锤炼思维的。就像我们在代码中必须检查fopen的返回值、判断read的状态、确保close的调用,学习的过程也需要我们 "步步为营",在发现问题、解决问题中不断成长。
当你成功运行起自己编写的写文件程序,看到 "hello bit!" 被精准写入文件;当你通过重定向将 printf 的输出存入日志文件,体验到数据流向改变的奇妙;当你用dup2函数简化了重定向逻辑,感受到工具带来的便捷 ------ 这些瞬间的喜悦与成就感,正是学习的魅力所在。它们会成为你继续前行的动力,让你在面对更复杂的知识点时,多一份从容与自信。
接下来的旅程,我们将带着本次学到的文件操作知识,去完善 shell 的重定向功能,让我们亲手编写的 shell 更具实用价值;我们还将深入探索 Linux "一切皆文件" 的深层内涵,剖析缓冲区的工作机制,甚至挑战自己封装 glibc 库中的文件操作函数。这无疑会是一段更具挑战性的旅程,但请记住,你已经打下了坚实的基础,那些曾经让你头疼的知识点,如今都已成为你武器库中的 "装备"。
学习 Linux 就像航海,文件操作只是我们遇到的第一片重要海域。前方还有管道、进程通信、网络编程等更广阔的领域等待我们探索,还有无数的底层原理等待我们揭开。在这个过程中,你可能会遇到风浪,可能会迷失方向,但请不要轻易放弃。多动手敲代码,多调试程序,多思考 "为什么",把每一个知识点嚼碎、消化、吸收,让它们真正成为你能力的一部分。
请相信,每一次对底层逻辑的探索,都是在提升你的核心竞争力。在这个技术迭代迅速的时代,底层知识就像一棵大树的根基,根基越牢固,树干才能长得越高、枝叶才能越繁茂。无论你是为了提升职场竞争力,还是出于对技术的热爱,这段学习经历都会成为你人生中宝贵的财富。
最后,感谢你一路的陪伴与坚持。学习的道路从来没有捷径,但每一步努力都不会白费。下一篇博客,让我们带着本次的收获,继续扬帆起航,去攻克更多的技术难关,探索更广阔的 Linux 世界。愿你在技术的海洋中,保持好奇、保持执着,不断突破自我,最终抵达自己心中的彼岸。我们下篇再见!