目录
实验报告

代码:
Matlab
[data, txt] = xlsread('第13次-聚类分析和判别分析.xlsx');
cityNames = txt(2:end, 1);
data = zscore(data);
Y_euclidean = pdist(data, 'euclidean');
Z_euclidean = linkage(Y_euclidean, 'ward');
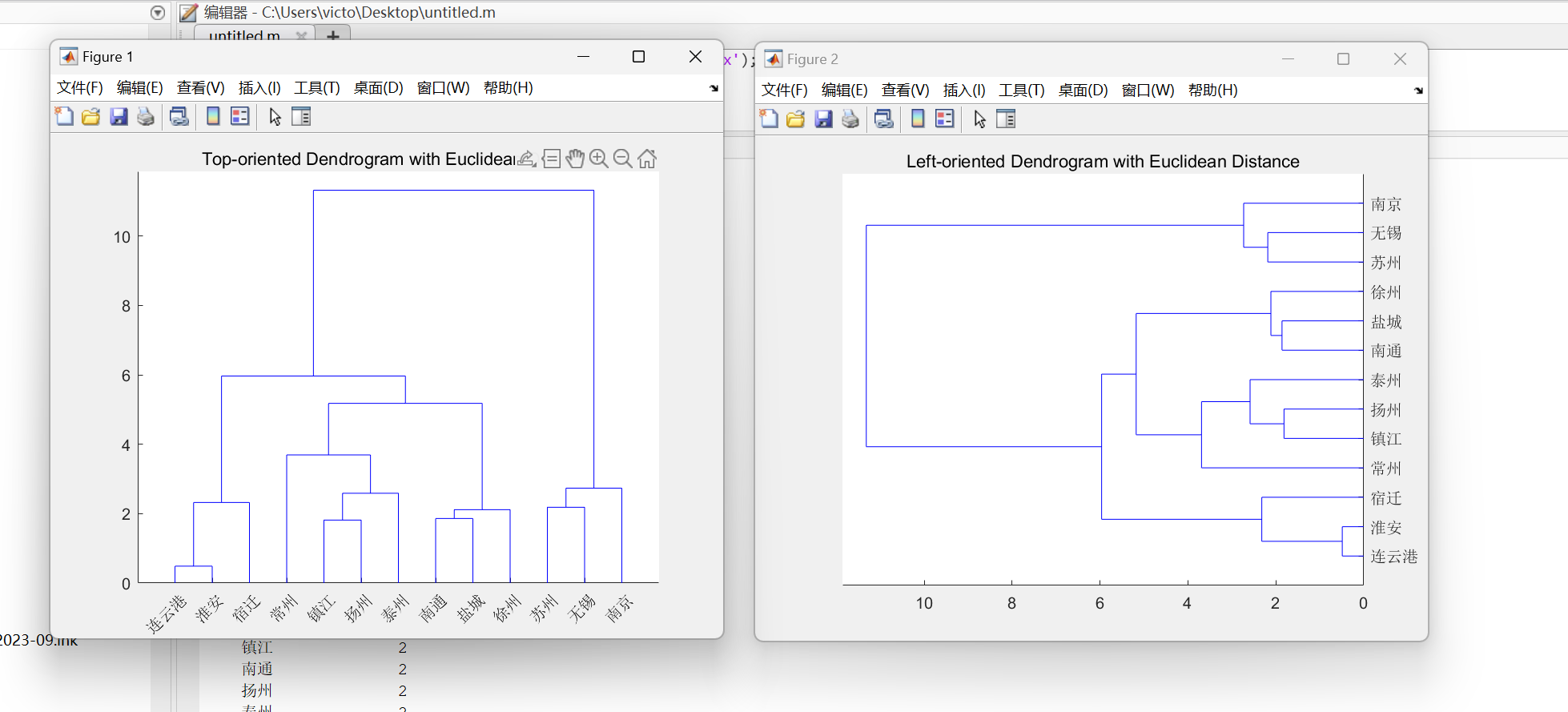
figure;
dendrogram(Z_euclidean, 'Orientation', 'top', 'Labels', cityNames);
title('Top-oriented Dendrogram with Euclidean Distance');
figure;
dendrogram(Z_euclidean, 'Orientation', 'left', 'Labels', cityNames);
title('Left-oriented Dendrogram with Euclidean Distance');
cluster2_euclidean = cluster(Z_euclidean, 'maxclust', 2);
cluster3_euclidean = cluster(Z_euclidean, 'maxclust', 3);
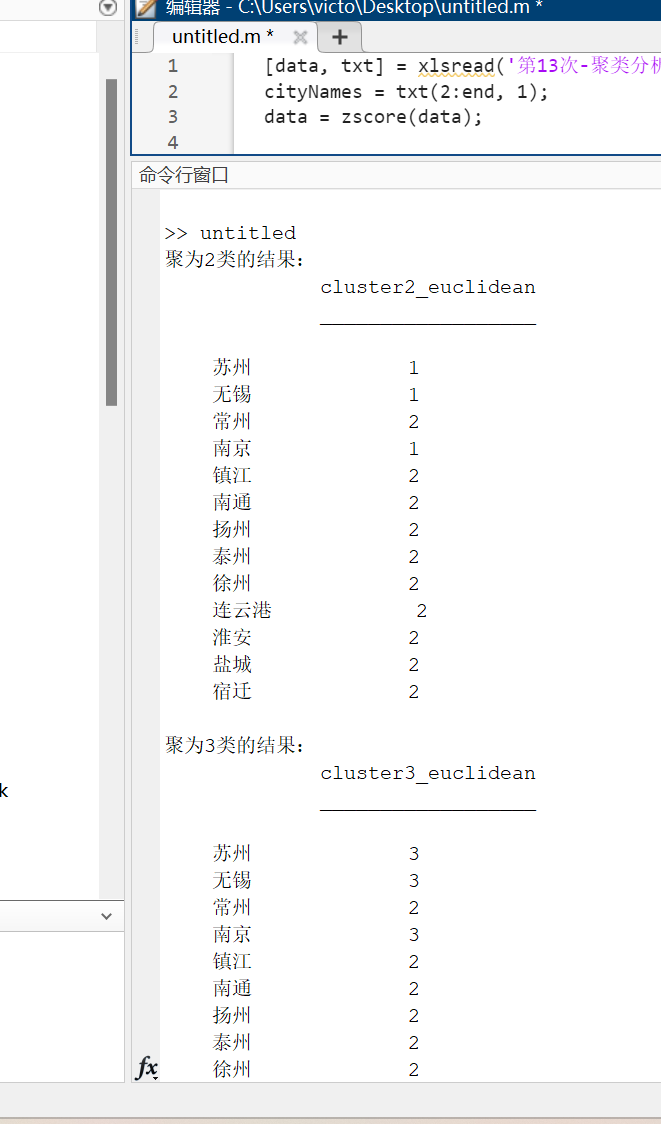
disp('聚为2类的结果:');
disp(array2table(cluster2_euclidean, 'RowNames', cityNames));
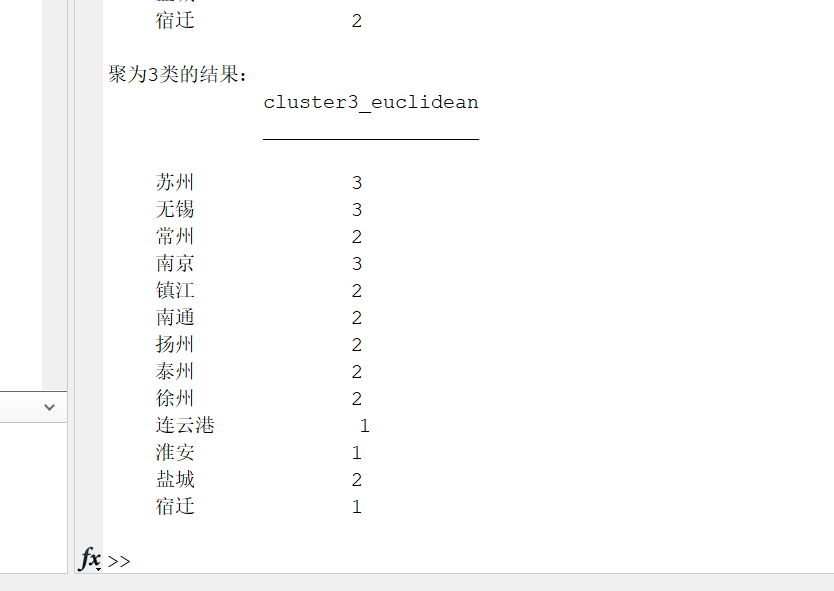
disp('聚为3类的结果:');
disp(array2table(cluster3_euclidean, 'RowNames', cityNames));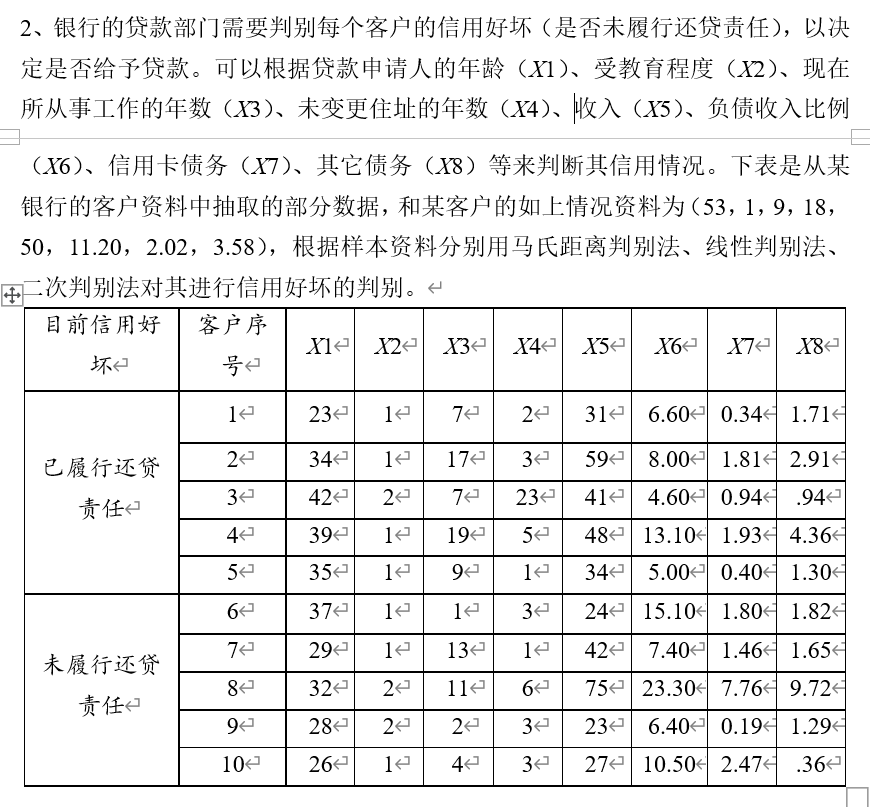
截图:
代码:
Matlab
X = [23 1 7 2 31 6.60 0.34 1.71;
34 1 17 3 59 8.00 1.81 2.91;
42 2 7 23 41 4.60 0.94 0.94;
39 1 19 5 48 13.10 1.93 4.36;
35 1 9 1 34 5.00 0.40 1.30;
37 1 1 3 24 15.10 1.80 1.82;
29 1 13 1 42 7.40 1.46 1.65;
32 2 11 6 75 23.30 7.76 9.72;
28 2 2 3 23 6.40 0.19 1.29;
26 1 4 3 27 10.50 2.47 0.36];
Y = [1; 1; 1; 1; 1; -1; -1; -1; -1; -1];
new_customer = [53 1 9 18 50 11.20 2.02 3.58];
mu1 = mean(X(Y==1, :));
mu2 = mean(X(Y==-1, :));
sigma1 = cov(X(Y==1, :));
sigma2 = cov(X(Y==-1, :));
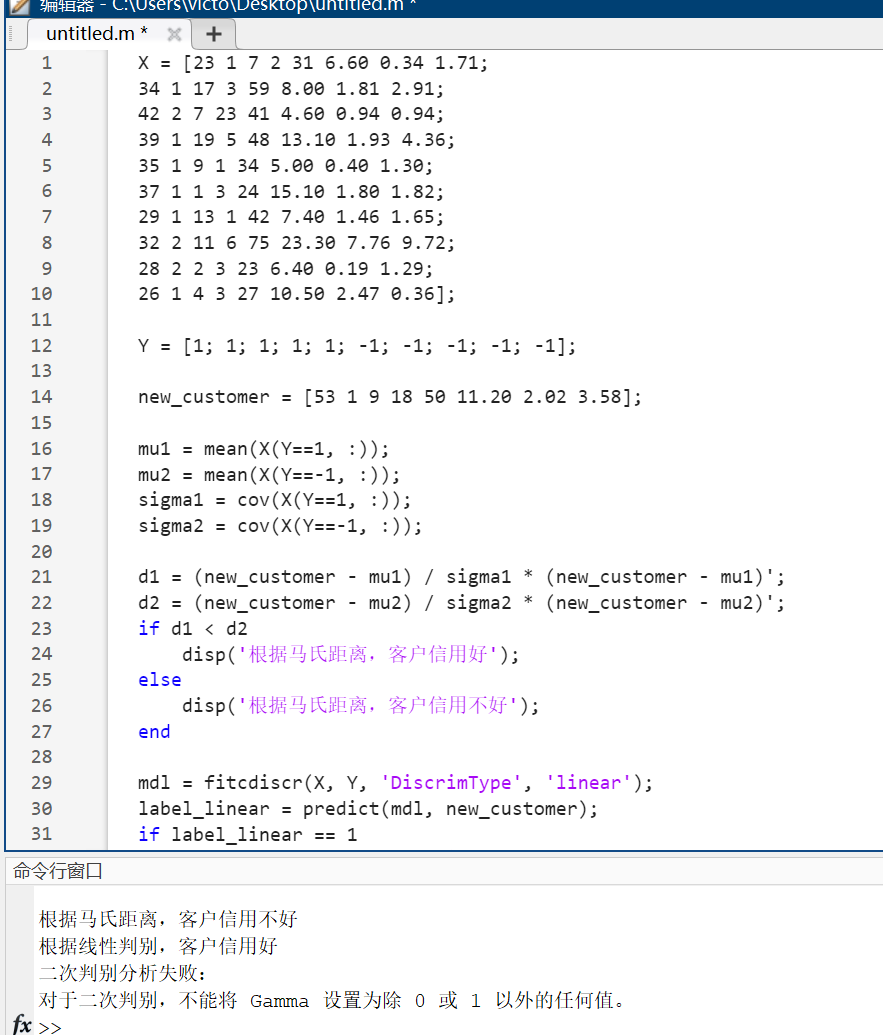
d1 = (new_customer - mu1) / sigma1 * (new_customer - mu1)';
d2 = (new_customer - mu2) / sigma2 * (new_customer - mu2)';
if d1 < d2
disp('根据马氏距离,客户信用好');
else
disp('根据马氏距离,客户信用不好');
end
mdl = fitcdiscr(X, Y, 'DiscrimType', 'linear');
label_linear = predict(mdl, new_customer);
if label_linear == 1
disp('根据线性判别,客户信用好');
else
disp('根据线性判别,客户信用不好');
end
try
mdl2 = fitcdiscr(X, Y, 'DiscrimType', 'quadratic', 'Gamma', 0.5);
label_quadratic = predict(mdl2, new_customer);
if label_quadratic == 1
disp('根据二次判别,客户信用好');
else
disp('根据二次判别,客户信用不好');
end
catch ME
disp('二次判别分析失败:');
disp(ME.message);
end3、(选做题)利用k均值(kmeans)聚类方法完成第1题的聚类任务。
截图:

代码:
Matlab
[data, txt] = xlsread('第13次-聚类分析和判别分析.xlsx');
cityNames = txt(2:end, 1);
data = zscore(data);
Y_euclidean = pdist(data, 'euclidean');
Z_euclidean = linkage(Y_euclidean, 'ward');
cluster2_euclidean = cluster(Z_euclidean, 'maxclust', 2);
cluster3_euclidean = cluster(Z_euclidean, 'maxclust', 3);
disp('聚为2类的结果:');
disp(array2table(cluster2_euclidean, 'RowNames', cityNames));
disp('聚为3类的结果:');
disp(array2table(cluster3_euclidean, 'RowNames', cityNames));
idx2 = kmeans(data, 2);
idx3 = kmeans(data, 3);
disp('k均值聚为2类的结果:');
disp(array2table(idx2, 'RowNames', cityNames));
disp('k均值聚为3类的结果:');
disp(array2table(idx3, 'RowNames', cityNames));4、(选做题)请利用Matlab自带的鸢尾花数据集完成以下任务:
(1)导入数据(以下2种方法均可);(1.1)load fisheriris(1.2)X,T = iris_dataset
(2)将每类鸢尾花的数据按8:2随机划分为训练集和测试集;
(3)利用线性判别法对测试集中的样本进行预测,并计算预测的准确率;
(4)利用朴素贝叶斯分类算法对测试集中的样本进行预测,并计算预测的准确率;
(5)利用k近邻算法对测试集中的样本进行预测,并计算预测的准确率。
截图:
代码:
Matlab
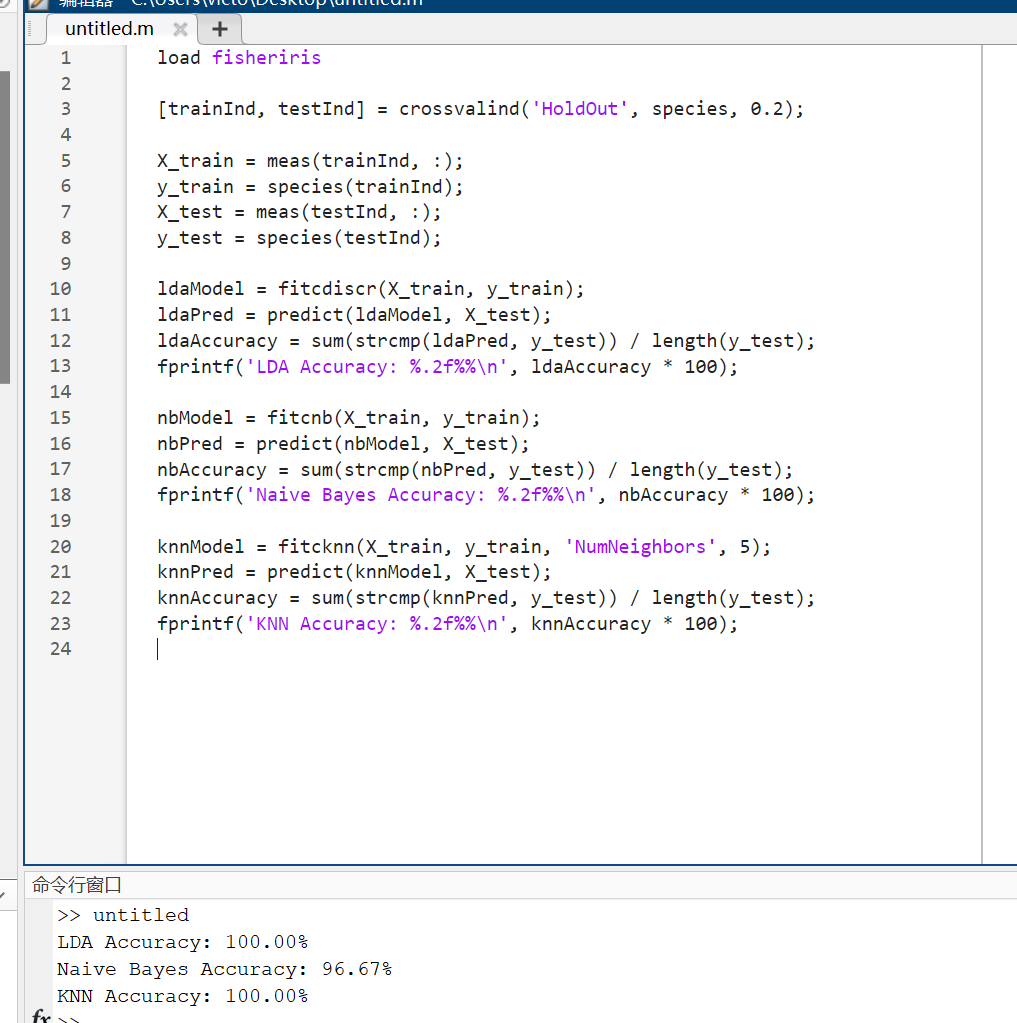
load fisheriris
[trainInd, testInd] = crossvalind('HoldOut', species, 0.2);
X_train = meas(trainInd, :);
y_train = species(trainInd);
X_test = meas(testInd, :);
y_test = species(testInd);
ldaModel = fitcdiscr(X_train, y_train);
ldaPred = predict(ldaModel, X_test);
ldaAccuracy = sum(strcmp(ldaPred, y_test)) / length(y_test);
fprintf('LDA Accuracy: %.2f%%\n', ldaAccuracy * 100);
nbModel = fitcnb(X_train, y_train);
nbPred = predict(nbModel, X_test);
nbAccuracy = sum(strcmp(nbPred, y_test)) / length(y_test);
fprintf('Naive Bayes Accuracy: %.2f%%\n', nbAccuracy * 100);
knnModel = fitcknn(X_train, y_train, 'NumNeighbors', 5);
knnPred = predict(knnModel, X_test);
knnAccuracy = sum(strcmp(knnPred, y_test)) / length(y_test);
fprintf('KNN Accuracy: %.2f%%\n', knnAccuracy * 100);实验心得
通过本次聚类分析和判别分析的 MATLAB 实验,我系统掌握了多元统计分析中无监督学习与有监督学习的核心方法,深入理解了聚类分析与判别分析的原理、应用场景及实操技巧,在数据处理、算法应用和结果分析等方面均收获颇丰,对统计分析在经济、金融等实际领域的应用价值有了更深刻的认知。
实验第一部分围绕江苏省 13 个地市国民经济数据展开聚类分析,让我熟练掌握了层次聚类的完整流程。从使用xlsread函数读取 Excel 数据、提取城市名称标签,到利用zscore函数完成数据标准化处理,我认识到数据预处理是保证分析结果准确的关键 ------ 不同经济指标量纲差异极大,不进行标准化会直接导致聚类结果失真。实验中采用欧氏距离衡量样本相似度、内平方距离法(Ward 法)进行聚类,并绘制上下两种方向的谱系图,直观呈现了城市间的经济相似性与层级关系。通过对比聚为 2 类和 3 类的结果,我清晰看到江苏省各地市经济发展的分层规律,发达城市、中等发展城市与发展相对滞后城市的划分符合实际情况,深刻理解了层次聚类在区域经济分析、分类评估中的实用价值。选做题中的 K-Means 聚类,让我对比了层次聚类与划分式聚类的差异,前者适合小样本、可展示层级结构,后者运算高效、适合大数据量,两种方法的互补性让我对聚类算法的选择有了更清晰的判断。
实验第二部分的银行客户信用判别分析,是我首次系统学习判别分析这一有监督统计方法。基于客户年龄、收入、债务等多项指标,我分别运用马氏距离判别法、线性判别法和二次判别法完成信用好坏的分类预测。实验过程中,我掌握了各类判别方法的核心原理:马氏距离消除了量纲和指标相关性的影响,线性判别假设各类协方差矩阵相同,运算简洁,二次判别则适用于协方差矩阵不同的场景。通过对新客户信用的判别,我切实体会到判别分析在金融风控、信贷审批中的重要作用,它能依托历史数据建立判别规则,为实际决策提供科学依据,有效降低信贷风险。同时,我也学会了根据数据特征选择合适的判别方法,提升了解决实际分类问题的能力。
实验第四部分基于鸢尾花数据集的分类实验,进一步巩固了我的分类算法应用能力。通过数据随机划分、线性判别、朴素贝叶斯、K 近邻算法的建模与准确率计算,我对比了不同有监督分类算法的性能,理解了模型训练、预测与评估的完整流程。鸢尾花数据集作为经典测试数据,让我快速掌握了分类算法的实操逻辑,也明白了数据集划分、模型评价指标在机器学习中的核心地位。
本次实验不仅提升了我的 MATLAB 编程能力,让我熟练运用数据读取、标准化、聚类、判别、模型评估等函数,更培养了我的统计思维和数据分析逻辑。我认识到,聚类分析是探索数据内在结构 的工具,适用于无标签数据的分类探索;判别分析是基于已知标签构建分类规则的工具,适用于有监督的预测场景,二者相辅相成,广泛应用于经济、金融、医学、生物等多个领域。同时,我也深刻体会到数据预处理、算法选择、结果验证的重要性,任何统计分析都必须立足数据实际,结合业务场景解读结果,才能发挥其真正价值。
此次实验让我夯实了多元统计分析的理论与实操基础,提升了解决实际数据分析问题的能力。在今后的学习和工作中,我将把本次实验所学的聚类与判别方法灵活运用到更多场景中,持续深化对统计分析算法的理解,不断提升数据分析与数据挖掘的综合能力,用科学的数据分析方法为决策提供支撑。