
Typora图片上云折腾了好久,最后终于成功了
文章目录
ctype.h
1.字符判断
判断是否是对应内容,如果是就返回非0,不是就返回0
- iscntrl:控制字符:https://c.biancheng.net/c/ascii/中的黄色的(码值为0\~31和127)
- 常见的有\n ,\0
- isspace:
- 空格
' '(ASCII 32) - 换页
\f(12) - 换行
\n(10) - 回车
\r(13) - 制表符
\t(9) - 垂直制表符
\v(11)
- 空格
- isdigit:数字字符
- isxdigit:16进制数字所包含的字符:09,az、A~Z
- islower:小写字母
- isupper:大写字母
- isalpha:字母
- isalnum:字母+数字
- ispunct:标点符号:! " # $ % & ' ( ) * + , - . / : ; < = > ? @ \\ ^ _ { | } ~`
- isgraph:能看见的:ASCII 33 ~ 126(所有可打印字符,排除空格
' ') - isprint:能打印的:ASCII 32 ~ 126(所有可打印字符,加上空格
' ')
2.字符转换
- tolower:小写转大写,其他不变
- toupper:大写转小写,其他不变
具体实践:将商标中的小写转化成大写
- 通过字符判断函数
cpp
//将商标中的小写字母转为大写
#include<stdio.h>
#include<string.h>
#include<ctype.h>
char* atoA(char* s,int size)
{
char* ret = s;
for (int i = 0; i < size; i++)
{
if (islower(s[i]))
s[i] = s[i] - 32;
}
return ret;
}
int main()
{
char s[] = "12310Tag";
int size = strlen(s) / sizeof(s[0]);
printf("%s\n", atoA(s, size));
return 0;
}- 通过字符转换函数
cpp
char* atoA(char* s, int size)
{
char* ret = s;
for (int i = 0; i < size; i++)
{
s[i] = toupper(s[i]);
}
return ret;
}string.h
strlen
基本功能和条件:
- 计算字符串长度
- 传参是char*,返回值是size_t
- 字符串要有\0(使用双引号初始化),strlen只读到\0
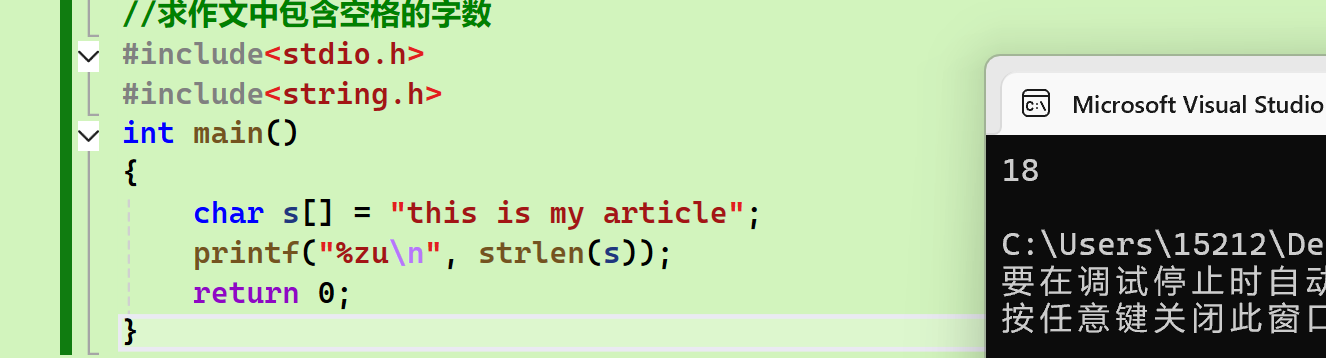
一般示例(求学生英文作文中包含空格的字数):
cpp
//求作文中包含空格的字数
#include<stdio.h>
#include<string.h>
int main()
{
char s[] = "this is my article";
printf("%zu\n", strlen(s));
return 0;
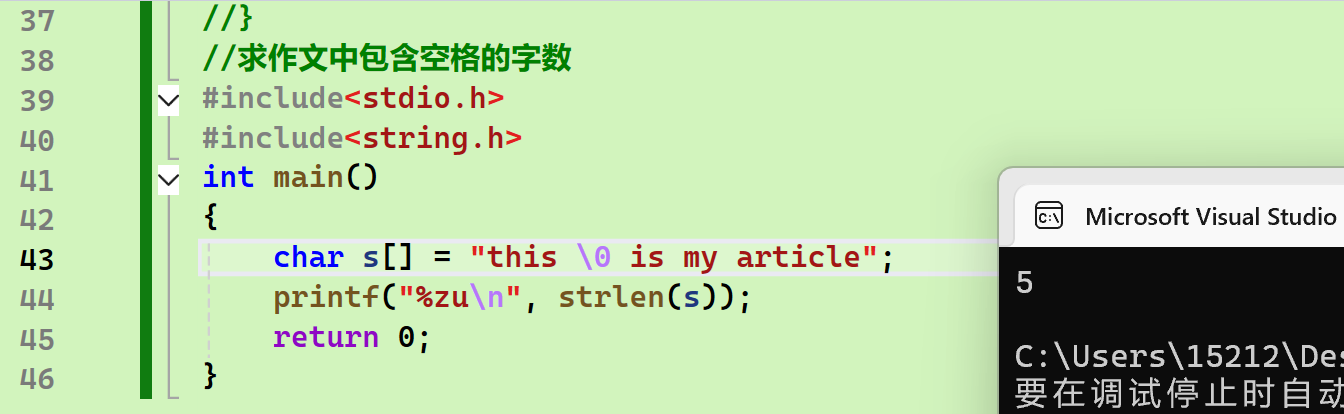
}- 特殊事例(字符串中有'\0'的情况):
cpp
#include<stdio.h>
#include<string.h>
int main()
{
char s[] = "this \0 is my article";
printf("%zu\n", strlen(s));
return 0;
}
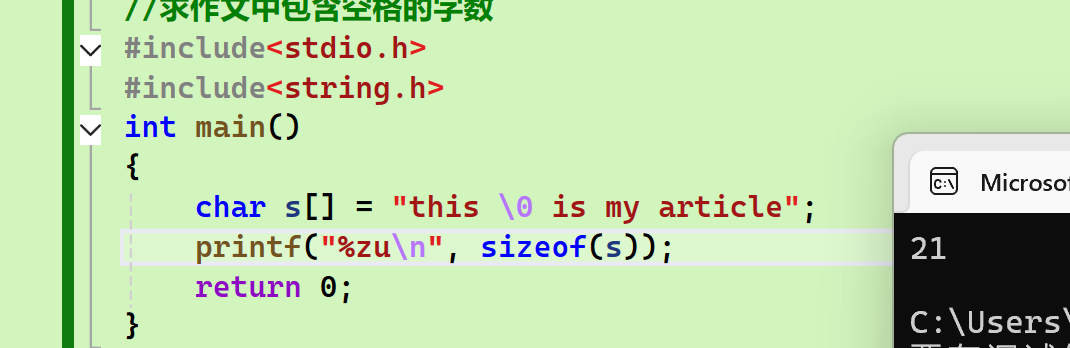
和sizeof的比较:
- 二者返回值都是size_t类型
- strlen只计算字符数组的长度,sizeof计算任意数组的字节长度
- strlen计算到\0截止,sizeof不会截止(计算含\0的字符串,后者会计算\0,不能用于遍历)

三种方法模拟实现strlen
- 直接进行计数
cpp
#include<stdio.h>
size_t mystrlen(char* s)
{
size_t len = 0;
while (*s != '\0')
{
len++;
s++;
}
return len;
}
int main()
{
char s[] = "hello i am 12310";
printf("%zu\n", mystrlen(s));
return 0;
}- 使用递归的方式
cpp
#include<stdio.h>
size_t mystrlen(char* s)
{
size_t len = 0;
if (*s == '\0')
return 0;
return (mystrlen(s+1) + 1);
}
int main()
{
char s[] = "hello i am 12310";
printf("%zu\n", mystrlen(s));
return 0;
}- 两个指针相减的方式
cpp
size_t mystrlen(char* s)
{
char* tmp = s;
while (*s)
{
s++;
}
return (s - tmp);
}strcpy/strncpy
-
功能:将source中的内容复制到destination中
-
条件:
- 传参
- 前者传两个参数
第一个是目标地址
第二个是source的地址 - 后者传3个参数,前两个参数和前者一样, 多了一个长度的参数
- 前者传两个参数
- 传参
-
一般示例:
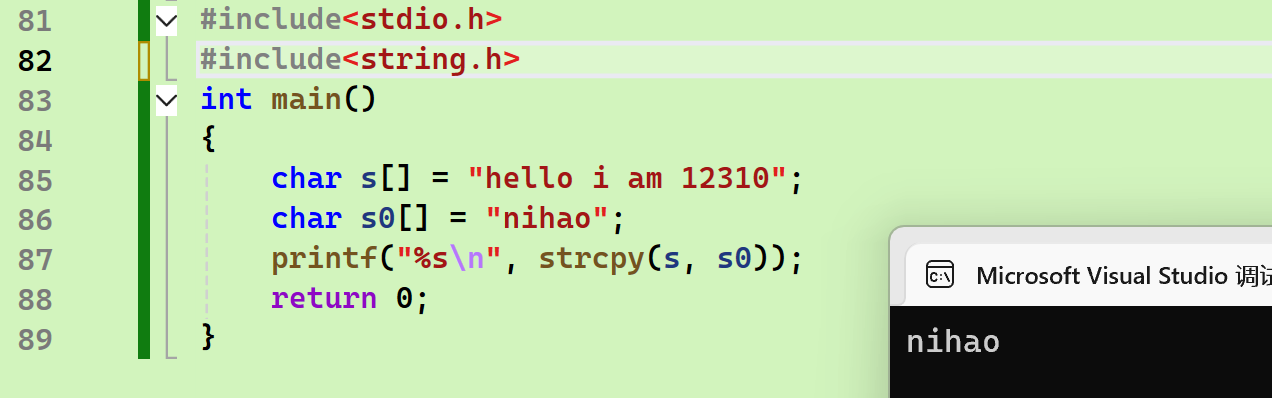
- strcpy(将nihao复制到hello的位置):
- strcpy会将后面的斜杠零也复制进去,导致使用printf的时候打印到第一个\0就会停
- strcpy(将nihao复制到hello的位置):
cpp
#include<stdio.h>
#include<string.h>
int main()
{
char s[] = "hello i am 12310";
char s0[] = "nihao";
printf("%s\n", strcpy(s, s0));
return 0;
}
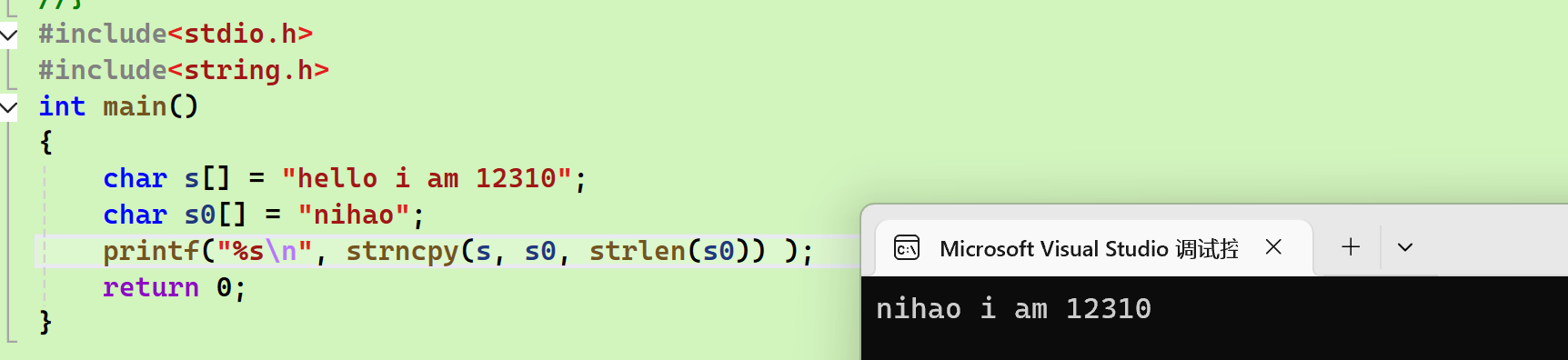
- strncpy:
- 这里只将你好的长度作为第3个参数传进去了,所以不会复制结尾的斜杠0,使用printf自然也不会出问题
cpp
#include<stdio.h>
#include<string.h>
int main()
{
char s[] = "hello i am 12310";
char s0[] = "nihao";
printf("%s\n", strncpy(s, s0, strlen(s0)) );
return 0;
}
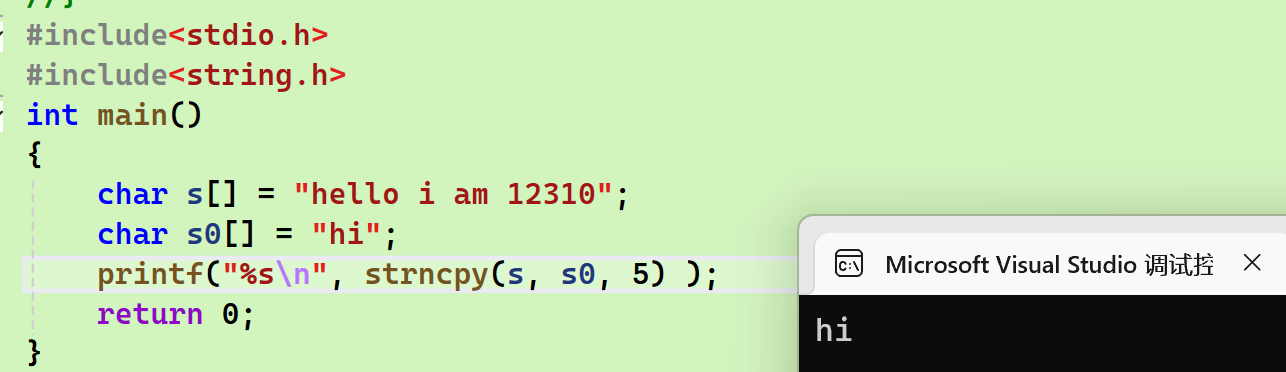
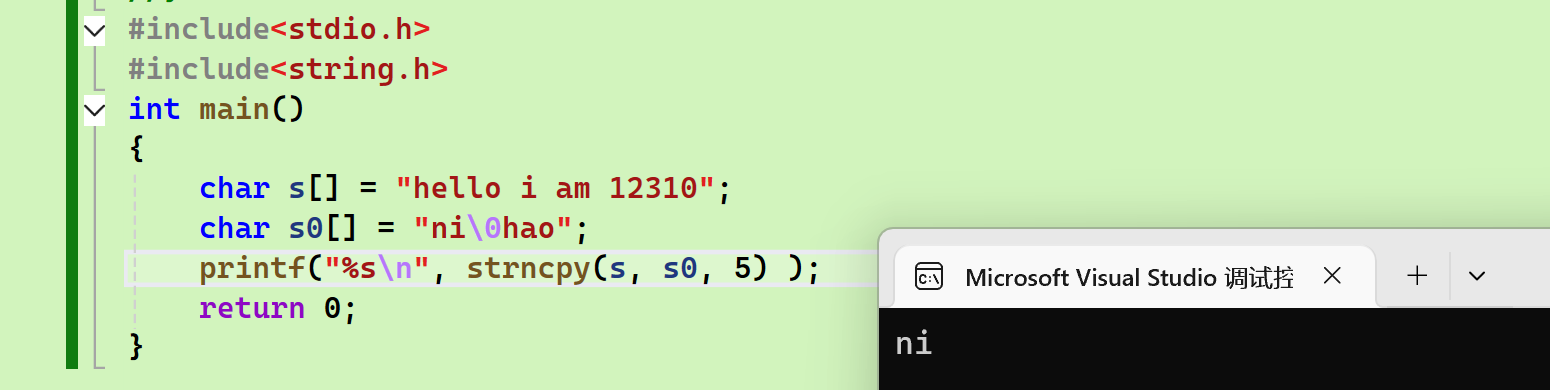
特殊情况
- Source未满 \ Source中(第N个字符前)有\0
内存情况:
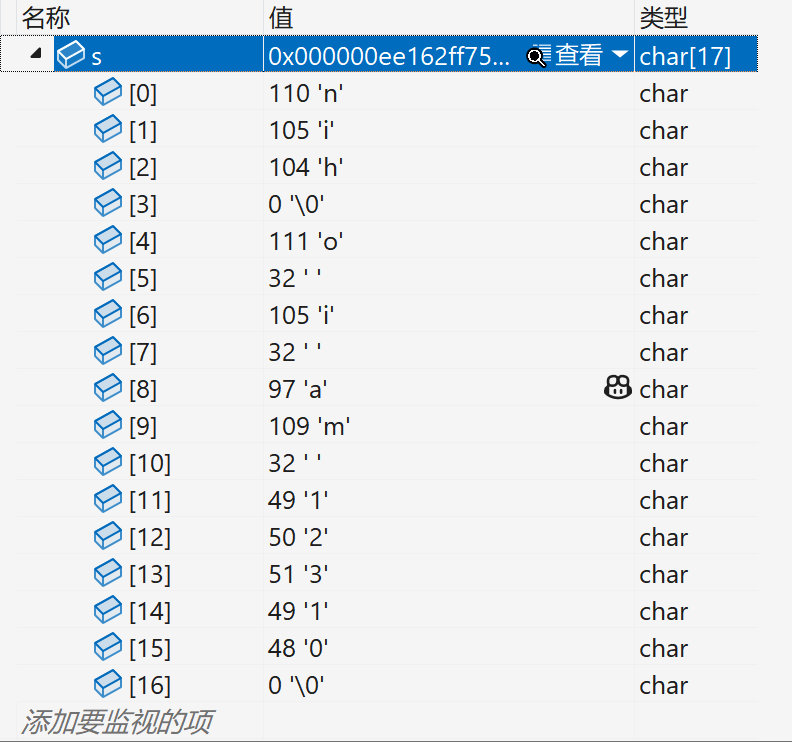
(该放进去的位置还是会放进去,只是不够的补成了\0)
模拟实现
- strcpy
cpp
#include<stdio.h>
char* mystrcpy(char* dest, char* sou)
{
char* ret = dest;
//从第一个字符开始,将sou中的复制到dest中
while (*sou)
{
*dest = *sou;
dest++;
sou++;
}
*dest = '\0';
return ret;
}
int main()
{
char s[] = "hello i am 12310";
char s0[] = "nihao";
printf("%s\n", mystrcpy(s, s0 ) );
return 0;
}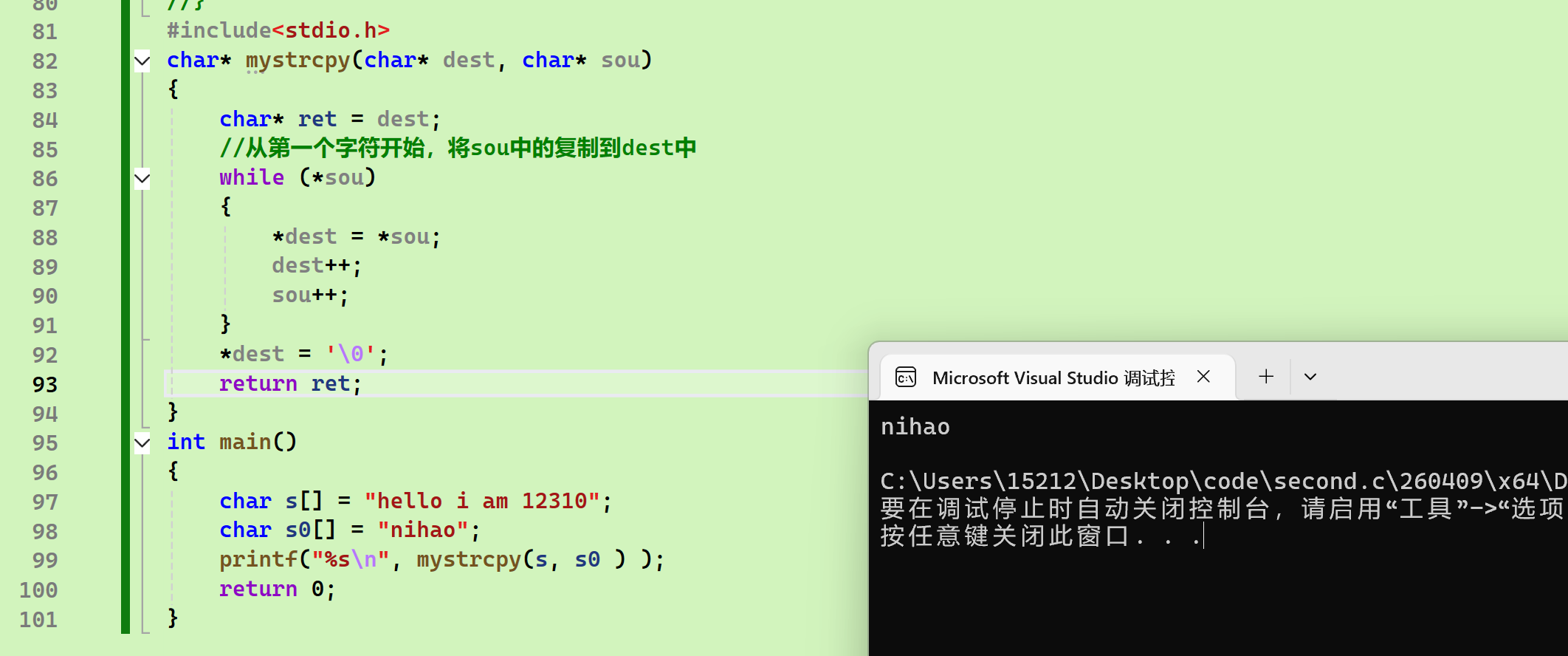
- 缺点:逻辑清晰,但是代码行数比较多。而且当sou到遇\0了就会停止进行复制
微微改造:后置加加,先使用再加加。相当于和前面一样那两句
再次微微改造:这个语句等号语句,它的返回值相当于就是赋值后的内容,那么当赋值为斜杠铃之后会停止,这时候斜杠0已经放进去了,不需要在结尾再单独再最后放一个\0
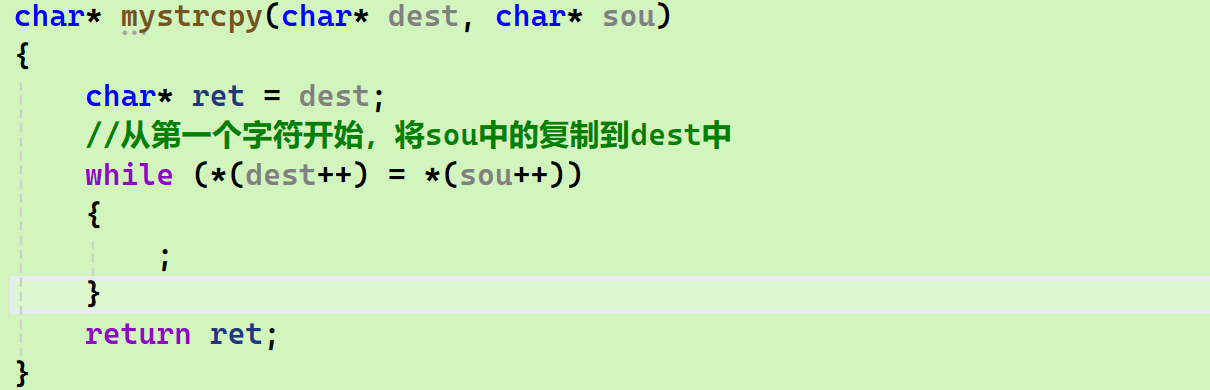
最终版本
cpp
#include<stdio.h>
char* mystrcpy(char* dest, char* sou)
{
char* ret = dest;
//从第一个字符开始,将sou中的复制到dest中
while (*(dest++) = *(sou++))
{
;
}
return ret;
}
int main()
{
char s[] = "hello i am 12310";
char s0[] = "nihao";
printf("%s\n", mystrcpy(s, s0 ) );
return 0;
}-
strncpy
-
注意事项:我这个句子比较简便,我在while循环中直接&&上了一个num,可是可是while循环中的这个句子它是会从前往后顺下去,也就是说当你的num已经变成0时,前面的 (dest++) = (sou++)多进行了一次 ,进行了4次而不是num中的3。这时候会导致错误: 就比如我例子中,你好最后的\0也添加进去了,所以打印的时候只打印出了你好
-
错误示例:
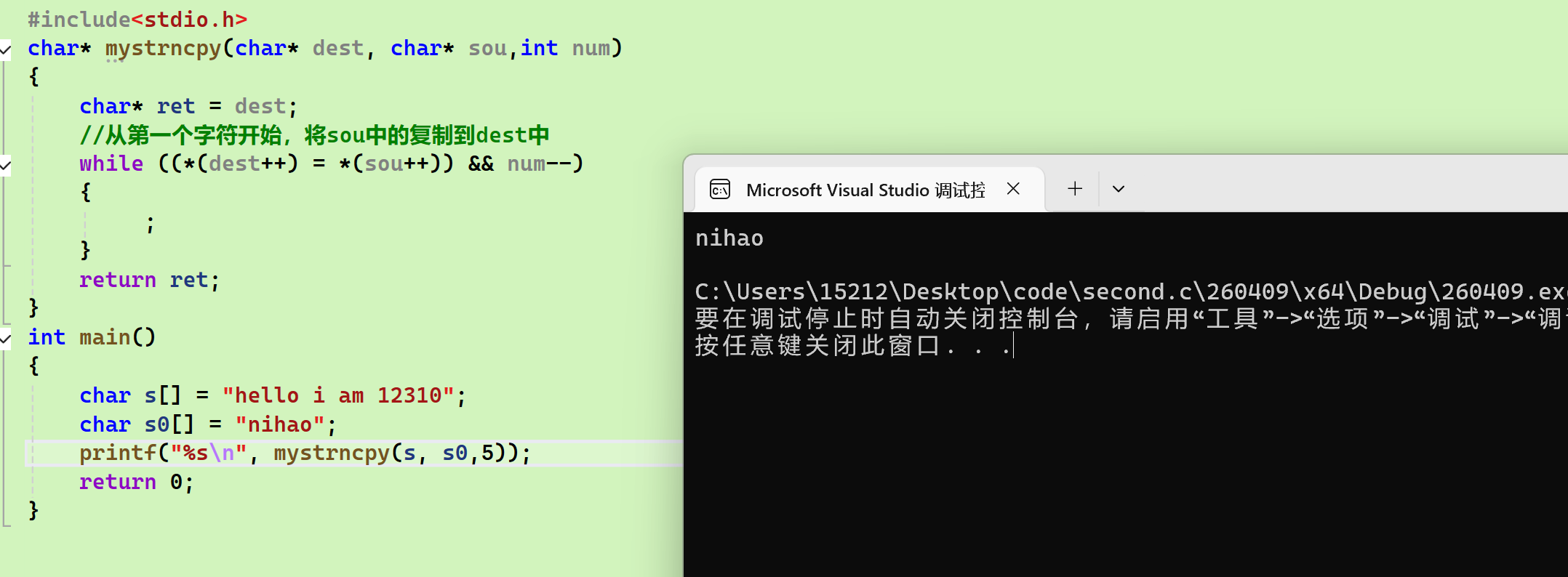
-
正确示例:
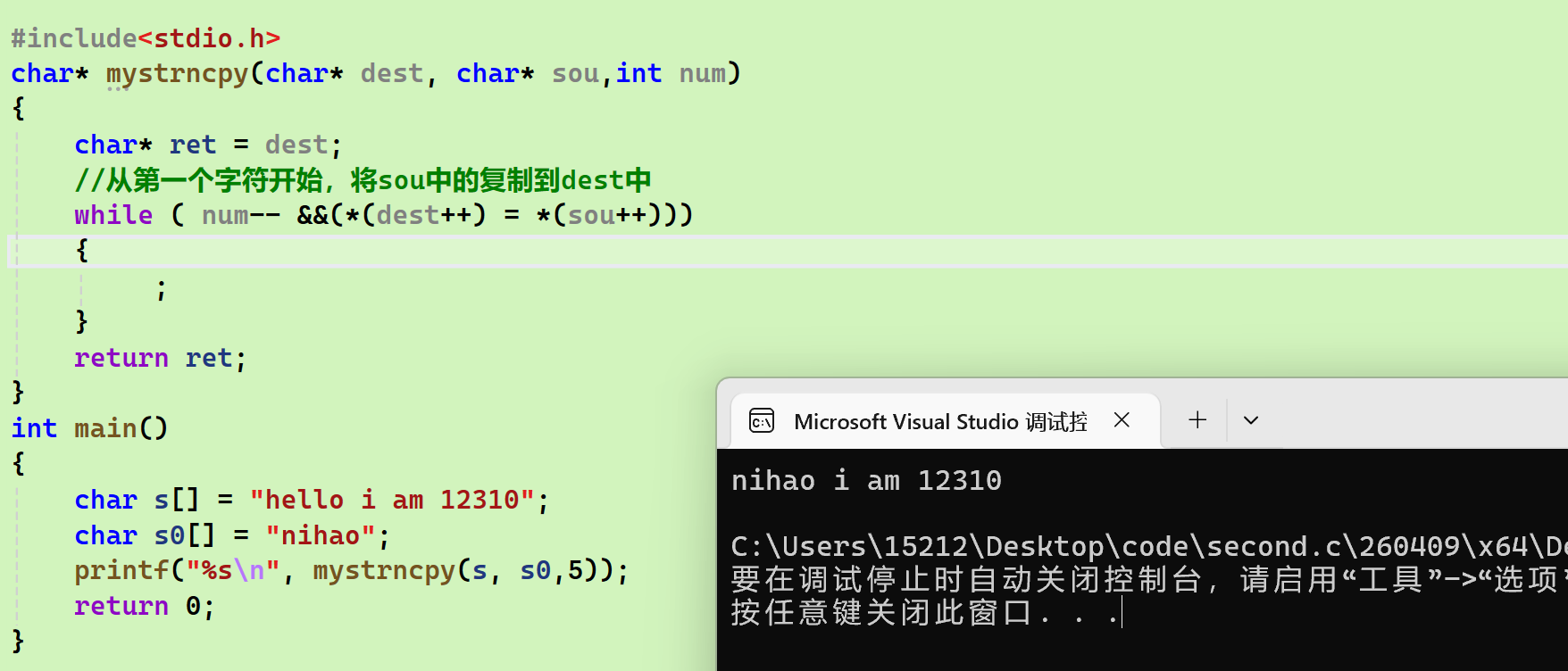
-
二者的区别:
- 后者有复制数的限制,参数也多一个
- 在有\0的字符串的复制中,前者只能起到覆盖作用,因为斜杠铃是必须会加进去的
strcat/strncat
基本用法
- 将source字符串添加到destination字符串的末尾
- 前者直接添加,后者有添加数的限制
注意事项:
我图中出现的错误:虽然我想把S0添加到S的后面,但是他们在初始化的时候字符串的长度已经把数组长度给填满了,所以已经没位置给我的S0了。所以如果想使用的话,字符串在创建的时候必须要给更长的长度
错误示例:
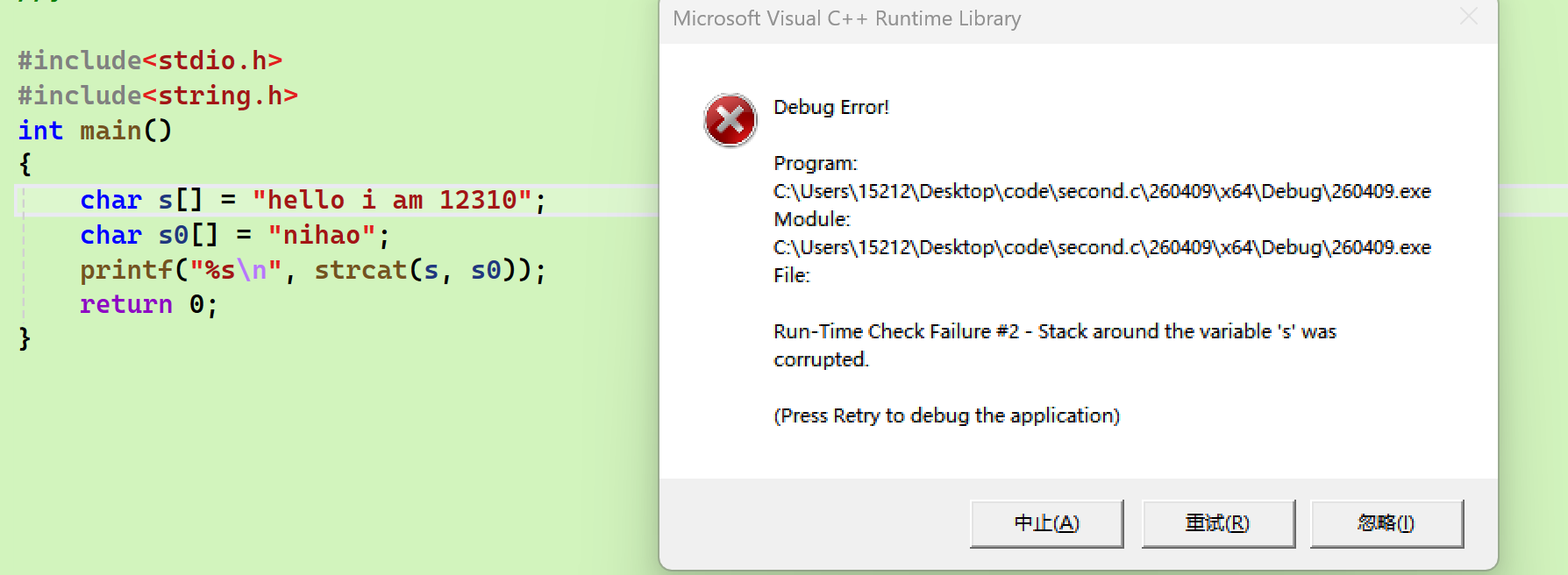
正确示例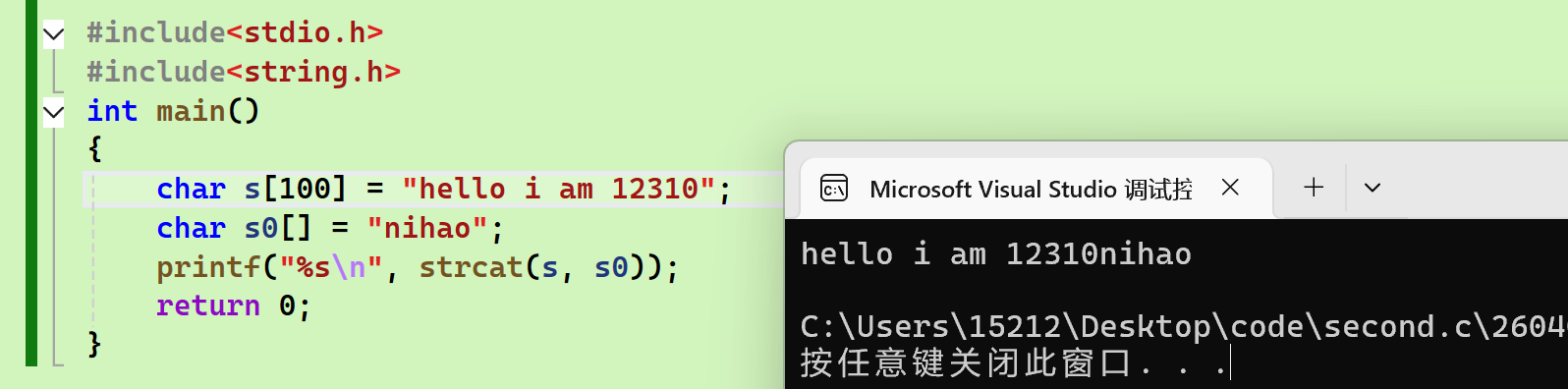
特殊情况
- sou中间有\0:只会添加\0之前的内容
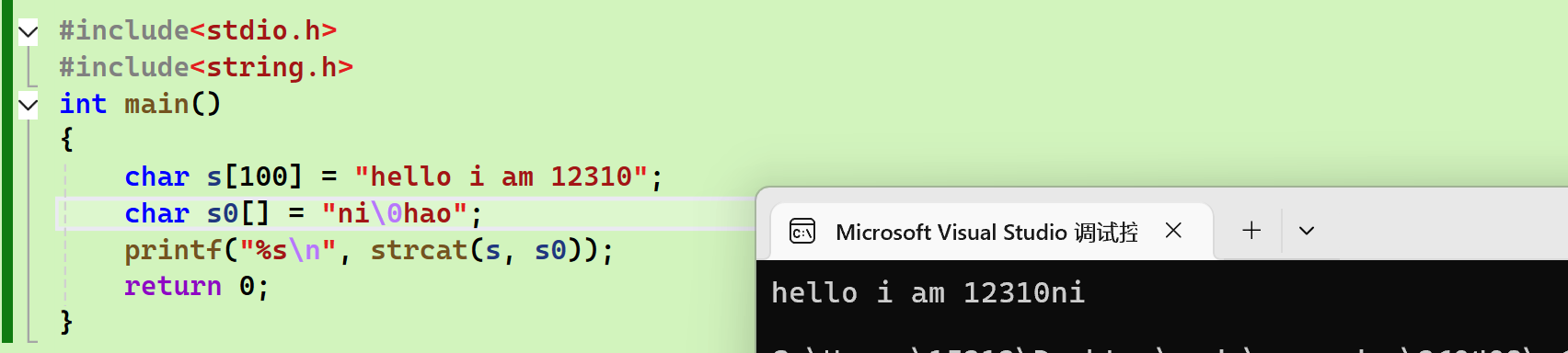
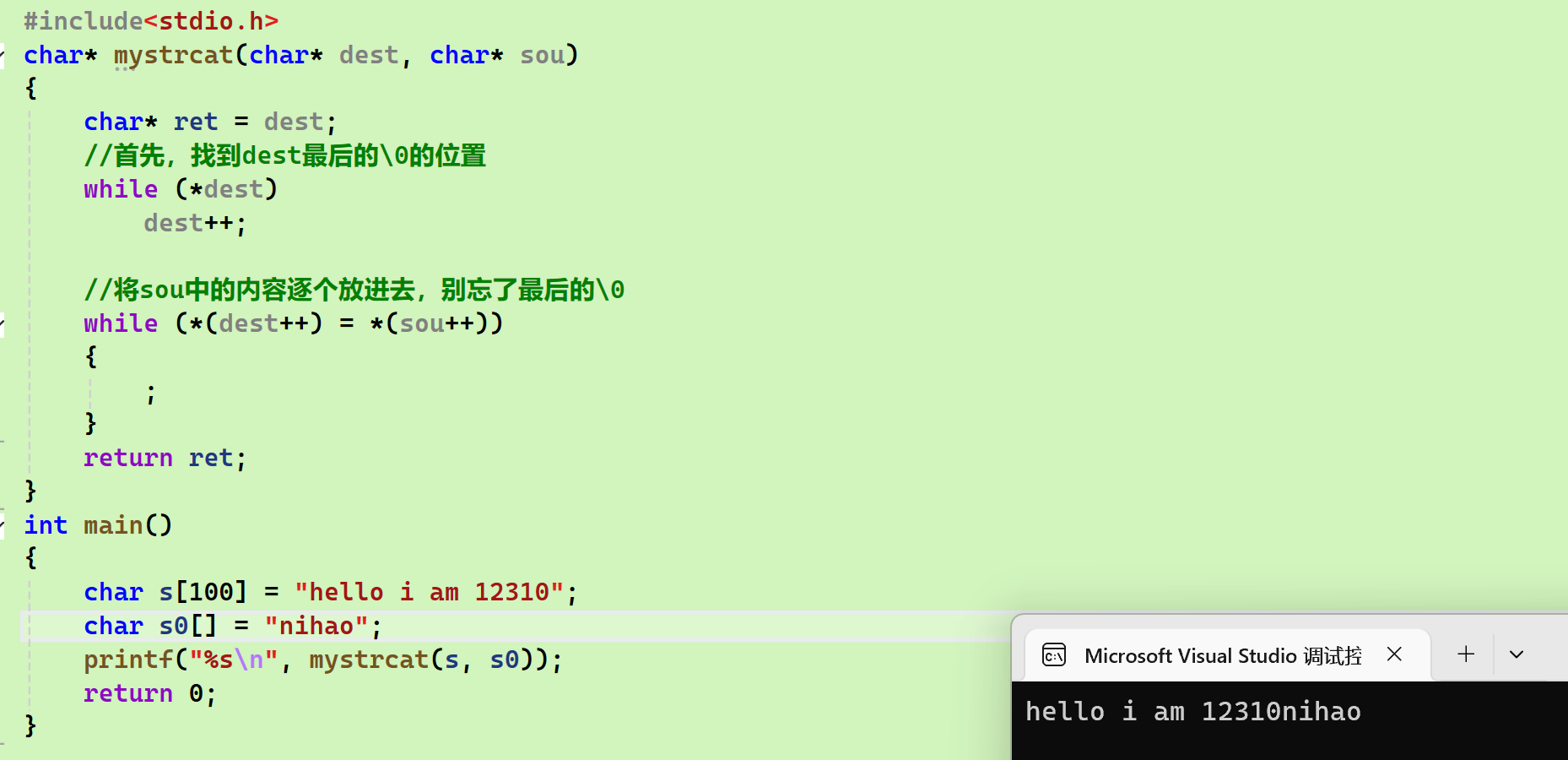
模拟实现
-
strcat
-
strncat
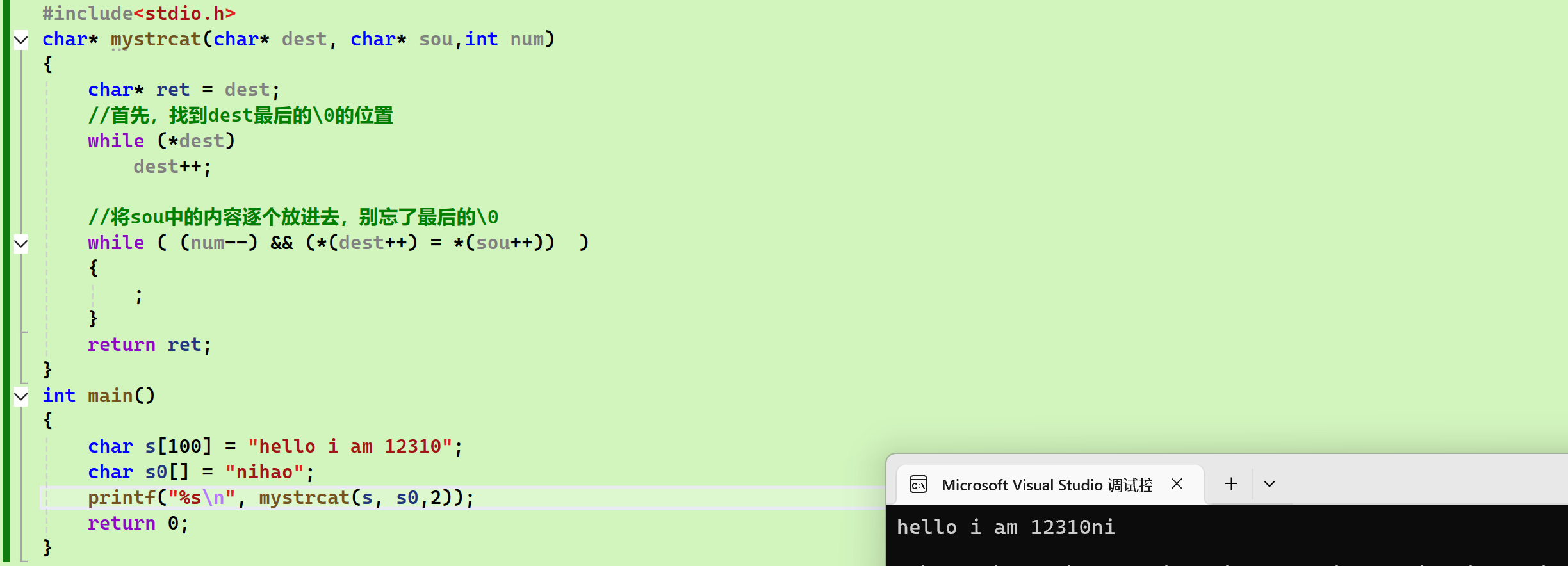
二者的区别
- 后者多了一个参数,更灵活更安全。
- 后者的source也不需要有\0了
strcmp/strncmp
基本用法
- 传参基本和前两个一样
- 返回值是int类型
- 如果前者大就返回正数
- 后者大就返回负数
- 一样大返回0
- 按照字典去比较
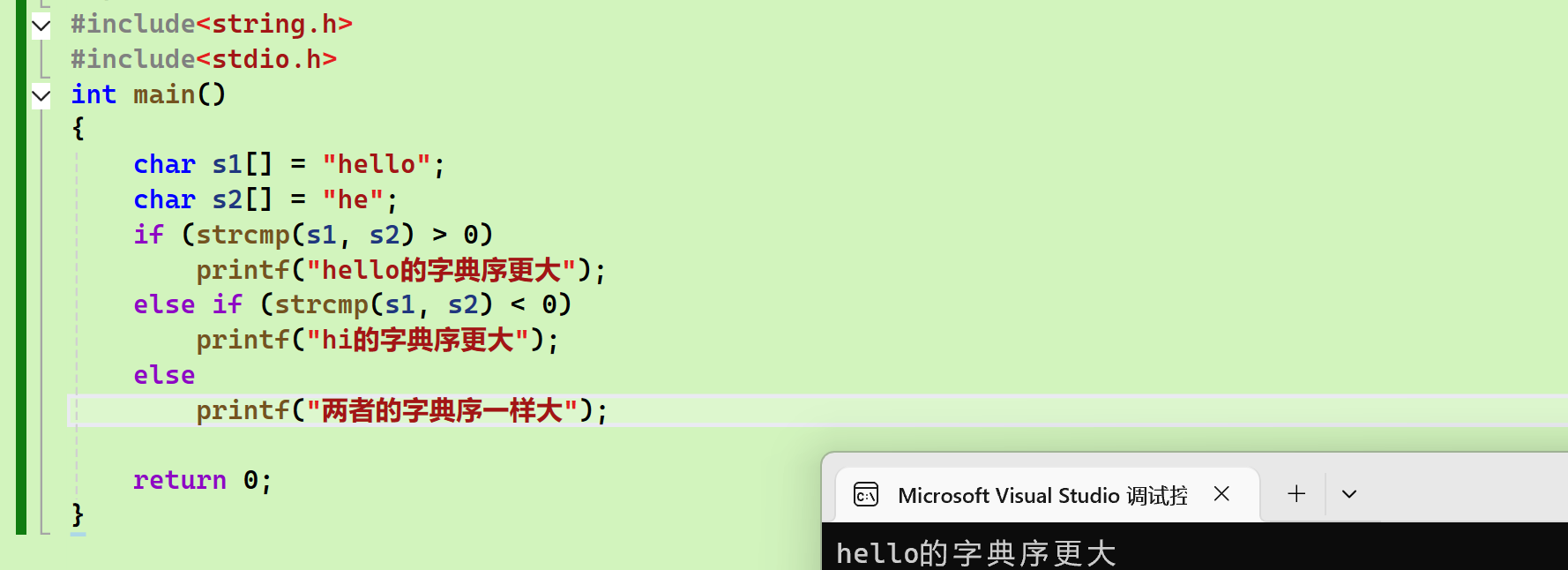
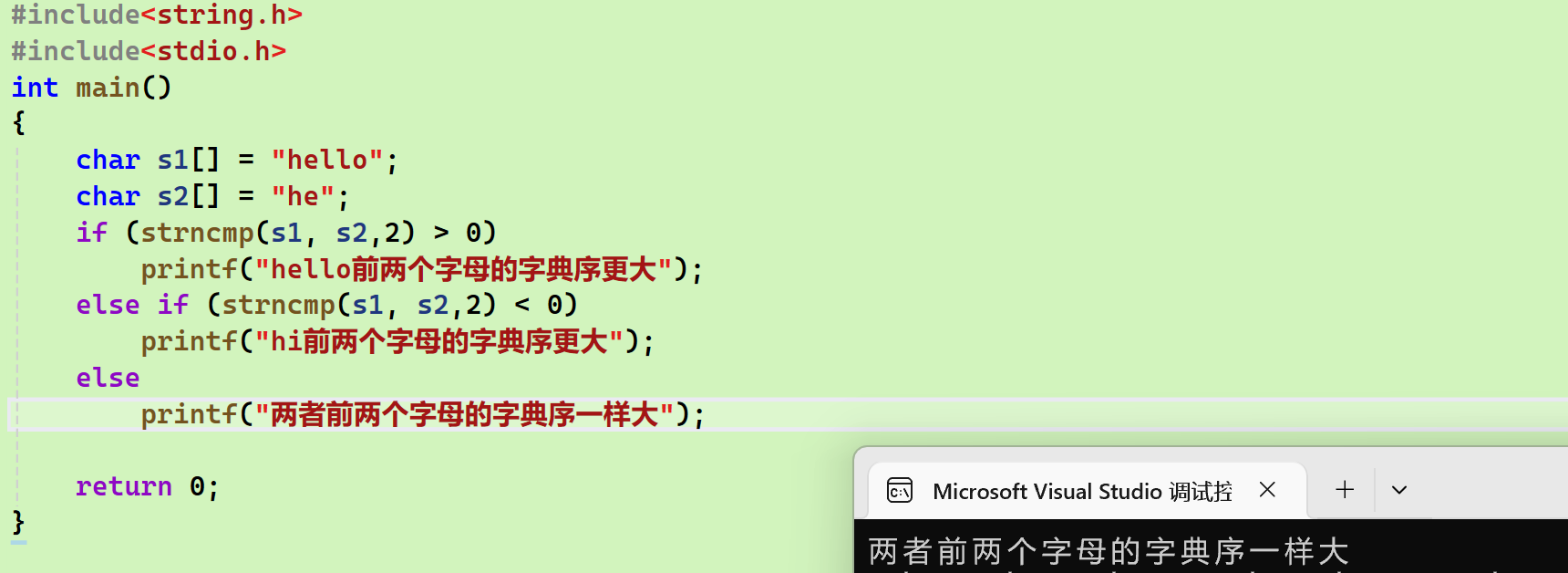
模拟实现
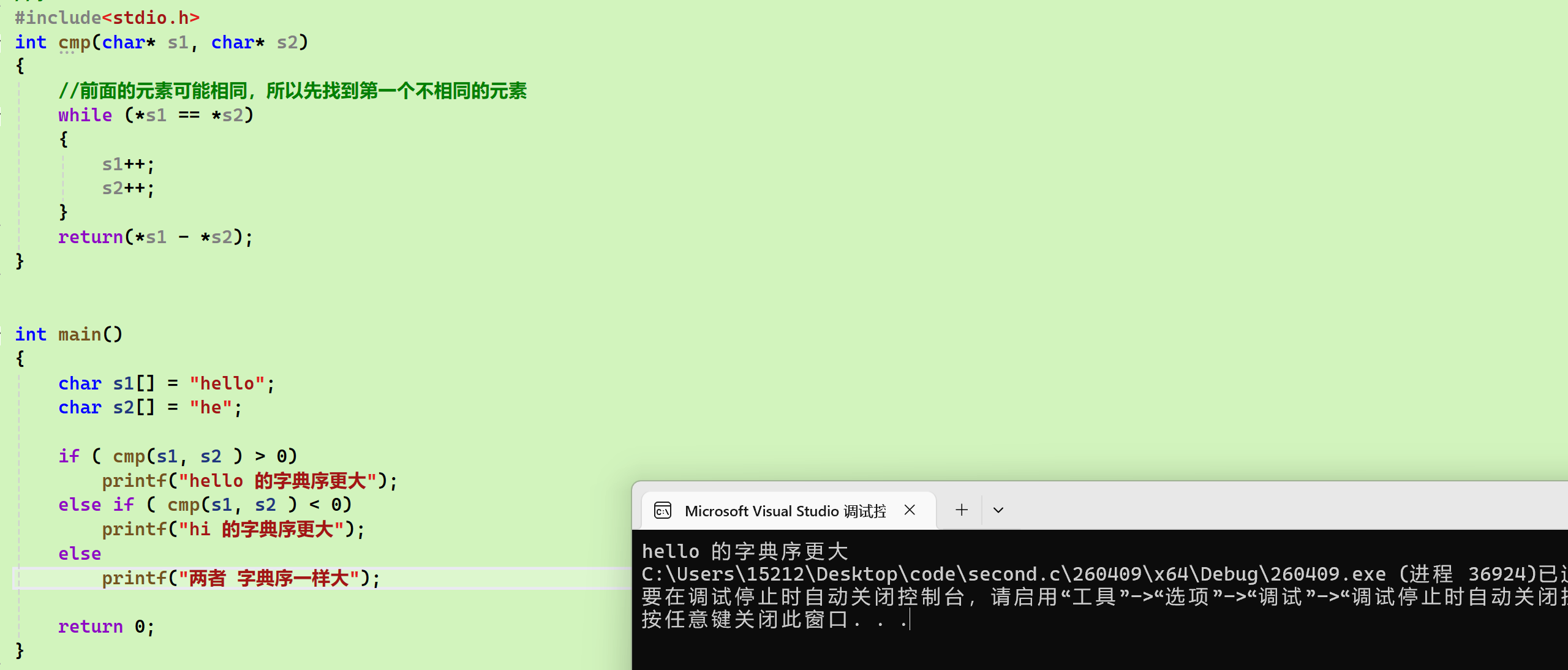
- strcmp
cpp
#include<stdio.h>
int cmp(char* s1, char* s2)
{
//前面的元素可能相同,所以先找到第一个不相同的元素
while (*s1 == *s2)
{
s1++;
s2++;
}
return(*s1 - *s2);
}
int main()
{
char s1[] = "hello";
char s2[] = "he";
if ( cmp(s1, s2 ) > 0)
printf("hello 的字典序更大");
else if ( cmp(s1, s2 ) < 0)
printf("hi 的字典序更大");
else
printf("两者 字典序一样大");
return 0;
}
- strncmp:
错误示范(原因是: 我只想比较前两个字符,while循环也的确只进行了两次,但是两次++之后得到的是第三个字符,通过第三个字符来比较自然是不合理的):
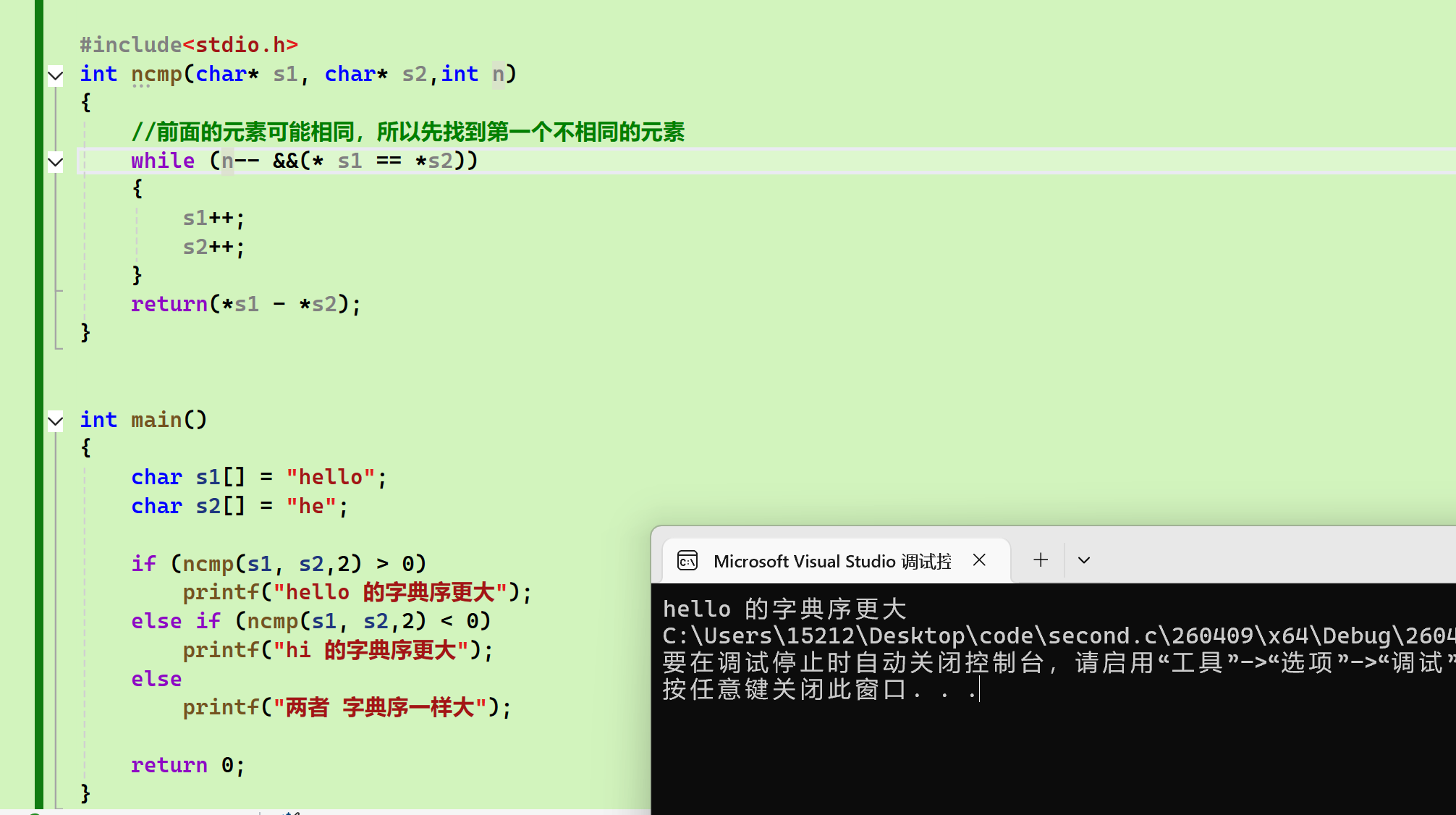
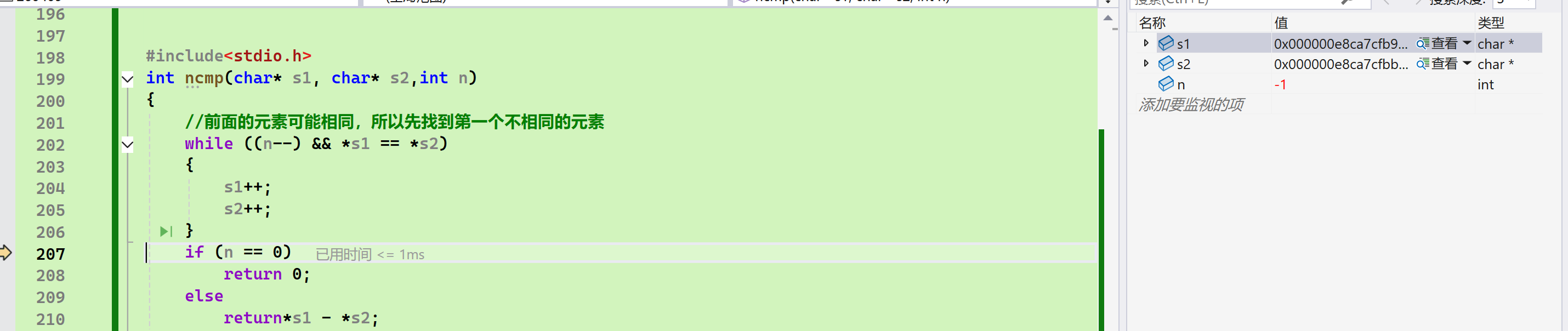
正确示范 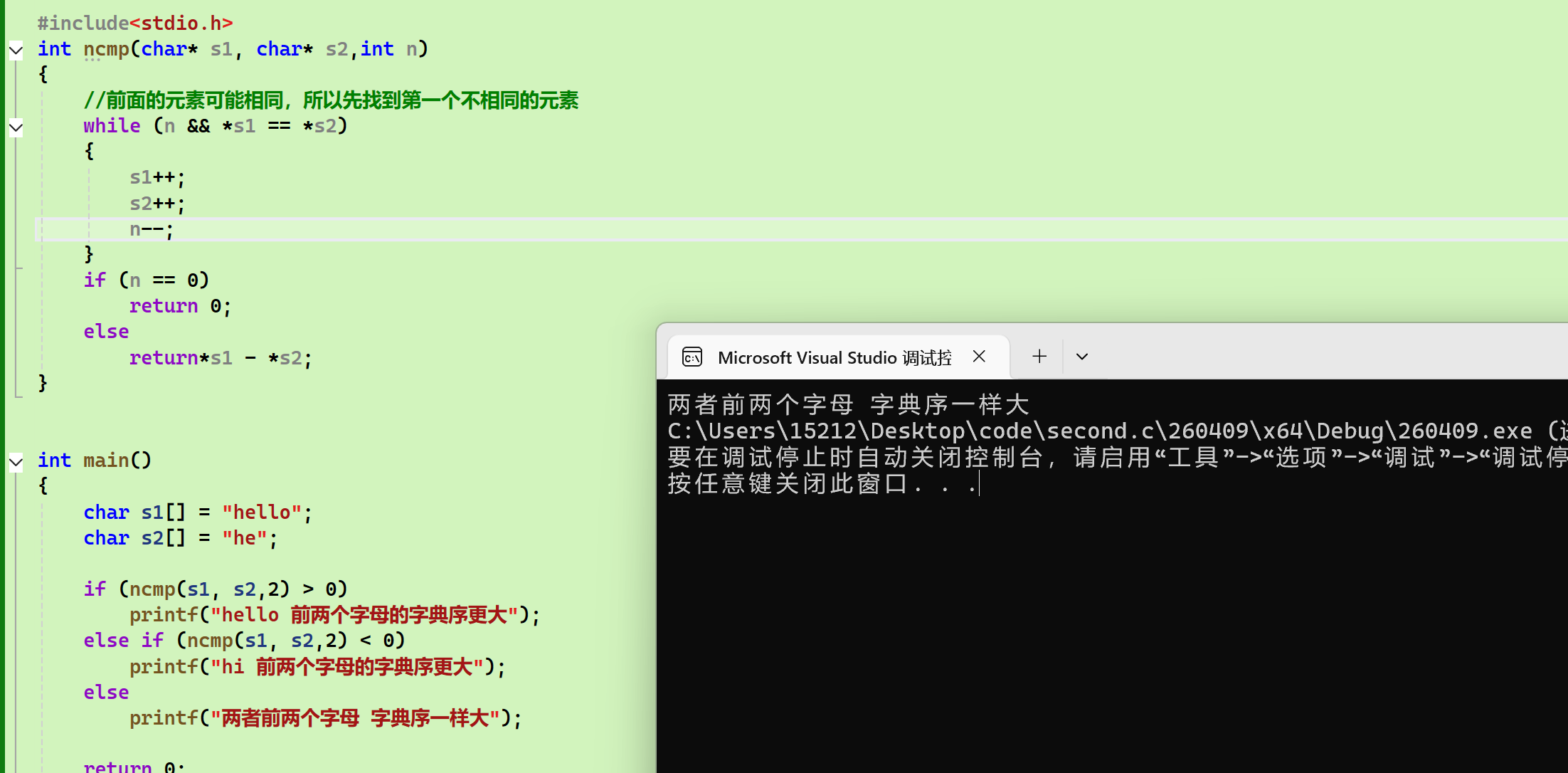
得到的教训:
While循环实际进行的次数,和我们想要的次数 的关系 比较难以确定
- 如本题中:想要while中的数组只比较下标为0和1的元素,但是因为while执行两次,最后指针指向的下标是2,想让比较过的元素在最后相减,就不行
strstr
基本用法:
- 传参传两参数
第一个参数是一个字符串的地址
第二个参数是想找的字符串的地址 - 返回值也是个地址,是想找的字符串在第一个字符串中 第一次出现的位置。
- 如果不存在返回NULL
例子:
找到abcddfghi中的dd,并改为de
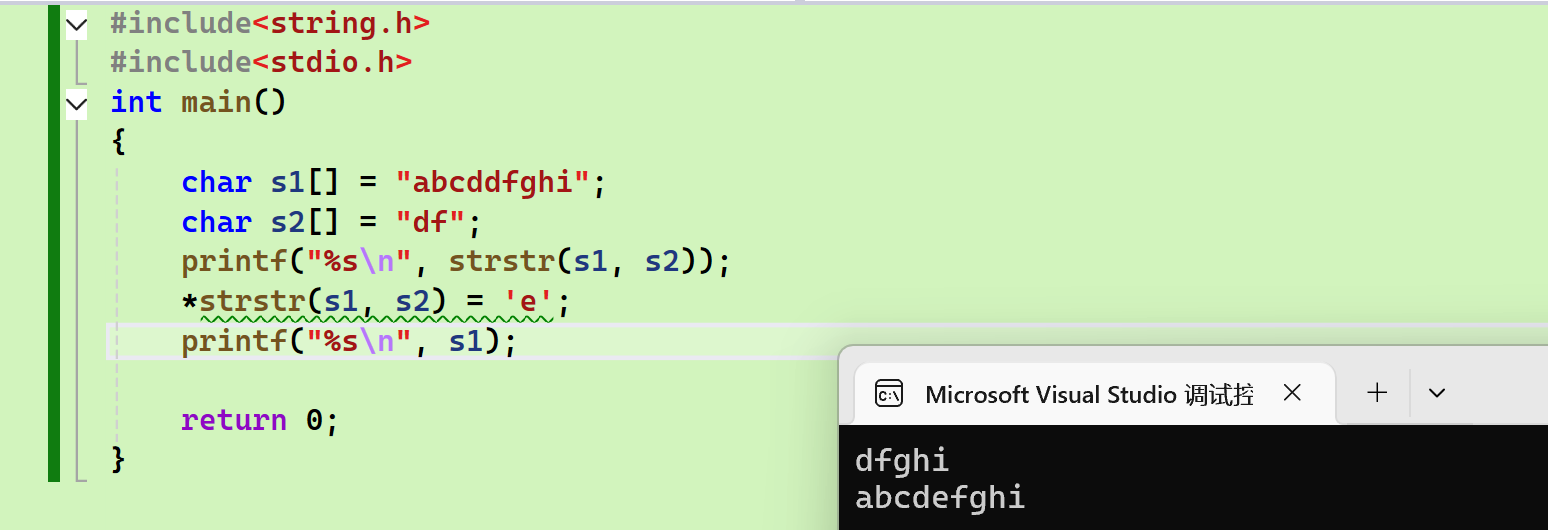
模拟实现
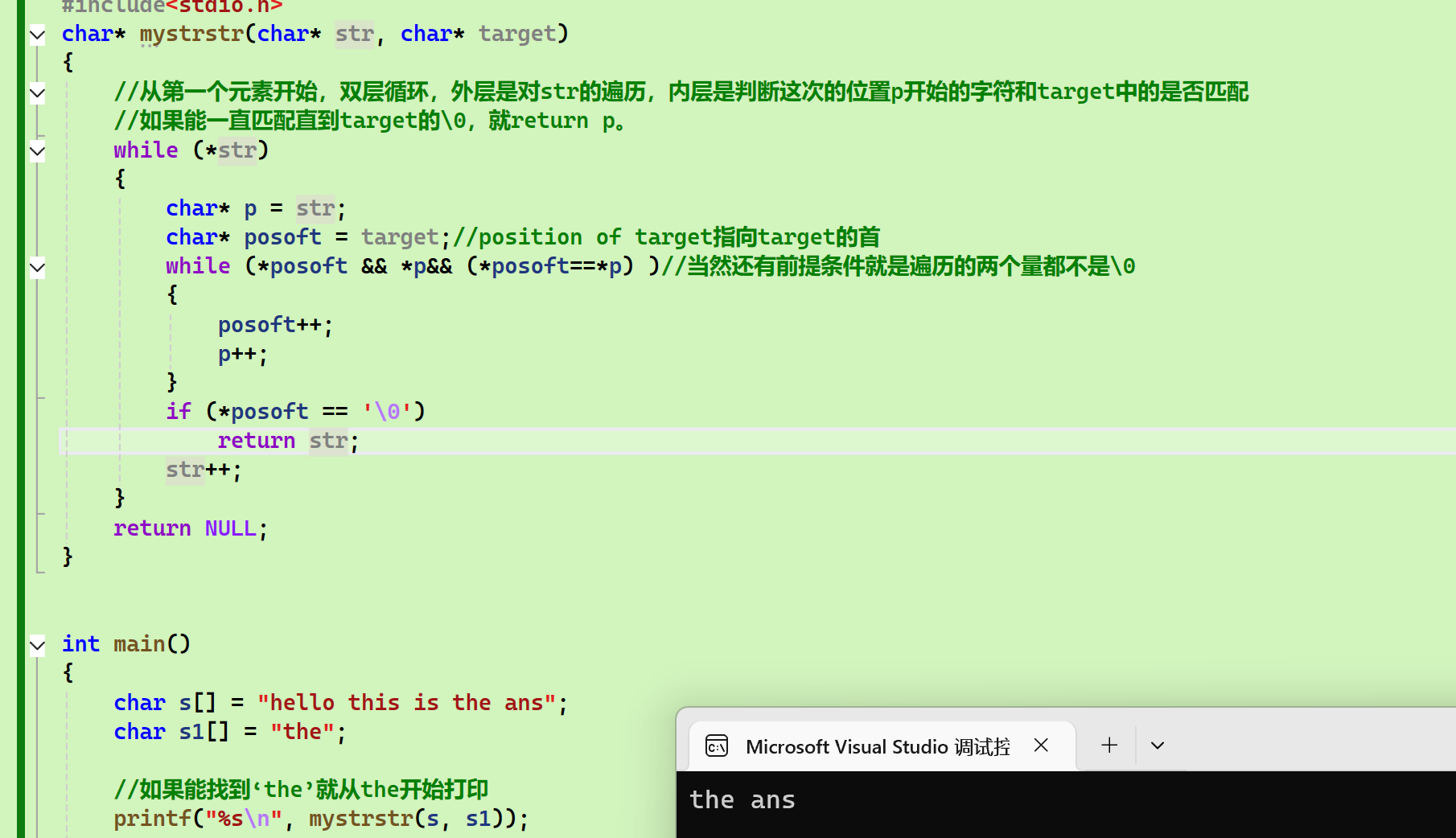
cpp
//模拟实现strstr
#include<stdio.h>
char* mystrstr(char* str, char* target)
{
//从第一个元素开始,双层循环,外层是对str的遍历,内层是判断这次的位置p开始的字符和target中的是否匹配
//如果能一直匹配直到target的\0,就return p。
while (*str)
{
char* p = str;
char* posoft = target;//position of target指向target的首
while (*posoft && *p&& (*posoft==*p) )//当然还有前提条件就是遍历的两个量都不是\0
{
posoft++;
p++;
}
if (*posoft == '\0')
return str;
str++;
}
return NULL;
}
int main()
{
char s[] = "hello this is the ans";
char s1[] = "the";
//如果能找到'the'就从the开始打印
printf("%s\n", mystrstr(s, s1));
return 0;
}strtok
基本用法
- 最基本的用法
- 第一次使用传参的第一个参数是一个字符串的 地址
第二个参数也是一个字符串,字符串中的每一个字符都会被当做想要截断的字符(对应位置在被截断的时候会变为\0) - 在第二次以及以后的传参,第一个参数变成了NULL
- 每次都会返回一个地址:截断所得的 前一段的地址
- 当整个字符串已经都被截断过了,返回的就是NULL
- 第一次使用传参的第一个参数是一个字符串的 地址
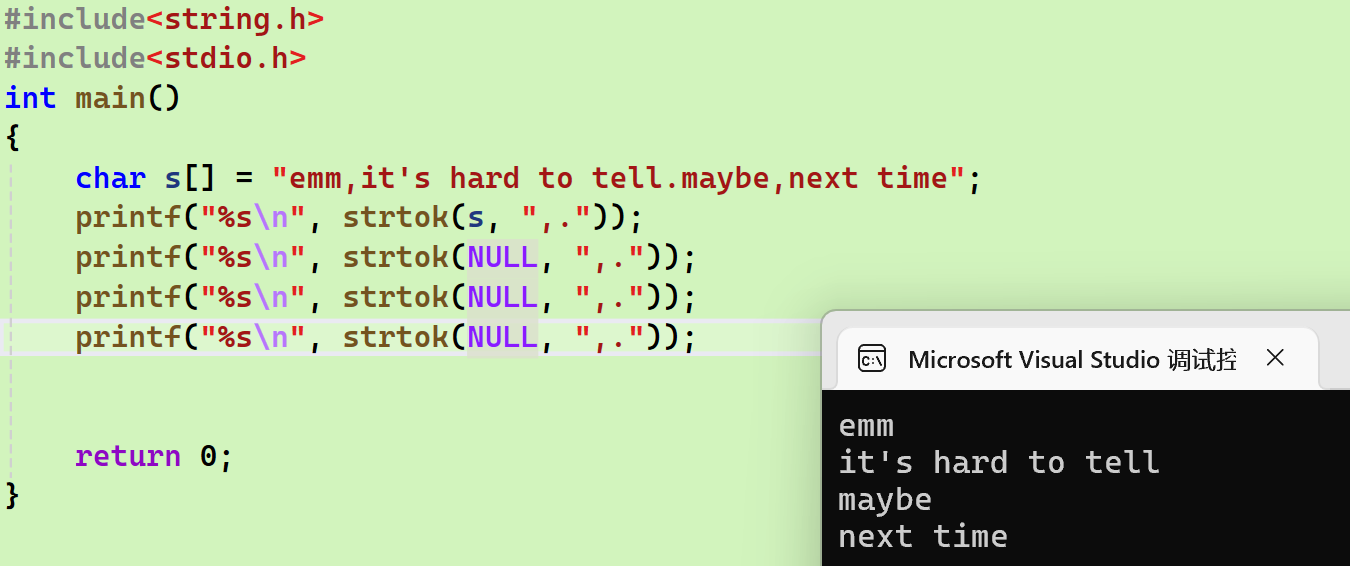
cpp
#include<string.h>
#include<stdio.h>
int main()
{
char s[] = "emm,it's hard to tell.maybe,next time";
printf("%s\n", strtok(s, ",."));
printf("%s\n", strtok(NULL, ",."));
printf("%s\n", strtok(NULL, ",."));
printf("%s\n", strtok(NULL, ",."));
return 0;
}
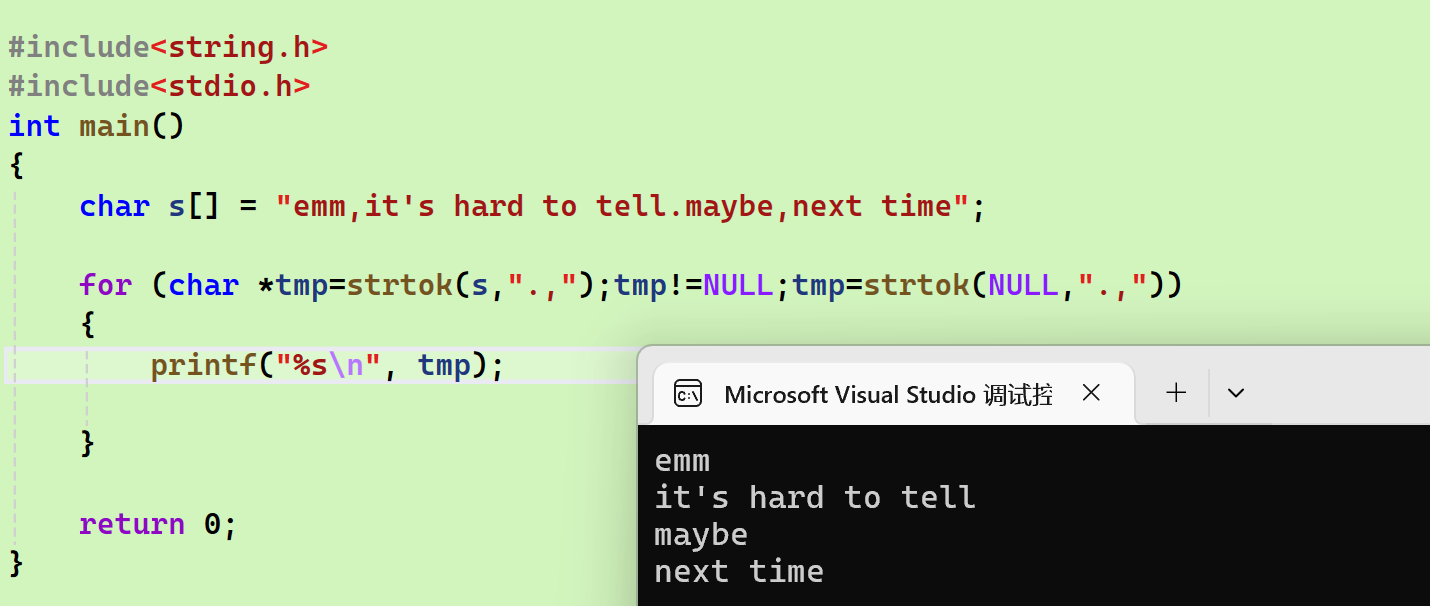
- 一般用法(使用for循环):
cpp
#include<string.h>
#include<stdio.h>
int main()
{
char s[] = "emm,it's hard to tell.maybe,next time";
for (char *tmp=strtok(s,".,");tmp!=NULL;tmp=strtok(NULL,".,"))
{
printf("%s\n", tmp);
}
return 0;
}
注意事项
- 这会将整个字符串截断,字符串应该提前复制保留
- 传的第二个参数是个字符串,其中的每个字符都会被当做单独的 要去截断的字符,截段意味着把它变成\0
strerror与perror
- 前者的使用需要配合errno(需要单独的头文件errno.h),当运行有错误的时候,使用strerror,参数为errno,打印的时候使用%s,就能打印对应错误信息
cpp
#include <stdio.h>
#include <string.h>
#include <errno.h>
int main() {
// 尝试打开一个不存在的文件
FILE *fp = fopen("不存在的文件.txt", "r");
// 判断:fopen 失败会返回 NULL
if (fp == NULL) {
// 用 strerror 翻译 errno 里的错误码
printf("文件打开失败!原因:%s\n", strerror(errno));
//打印出来的结果:"文件打开失败!原因:No such file or directory"
return 1;
}
fclose(fp);
return 0;
}- 后者的使用更加简洁,(不过头文件相同)。
- 传的参数是一个字符串,打印错误时会在字符串后面添上一个冒号再添加上对应的错误
cpp
perror("打开文件失败");
//打印的结果:"打开文件失败: No such file or directory"memcpy
基本用法
- 使用时的目的和strcpy相似
- 前两个参数和strcpy相同,但是第三个参数变成了字节长度
和strcpy对比
- 前者仅对字符串有效,后者没有限制
- 前者在遇到\0时停止,并且会把\0也添加上去。后者不会
局限
- memcpy无法处理内存重叠的情况(此时使用memmove)
模拟实现
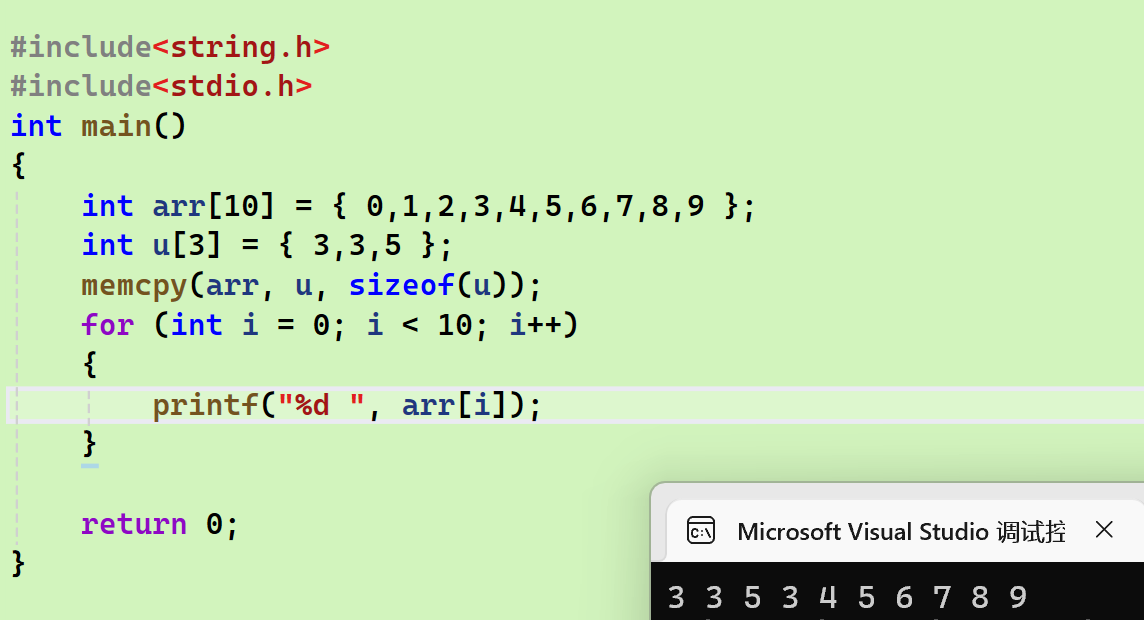
cpp
#include<stdio.h>
void* mymemcpy(void* dest, void* sou, int len)
{
void* ret = dest;
//逐个字节进行修改
for (int i = 0; i < len; i++)
{
*((char*)dest + i) = *((char*)sou + i);
}
return dest;
}
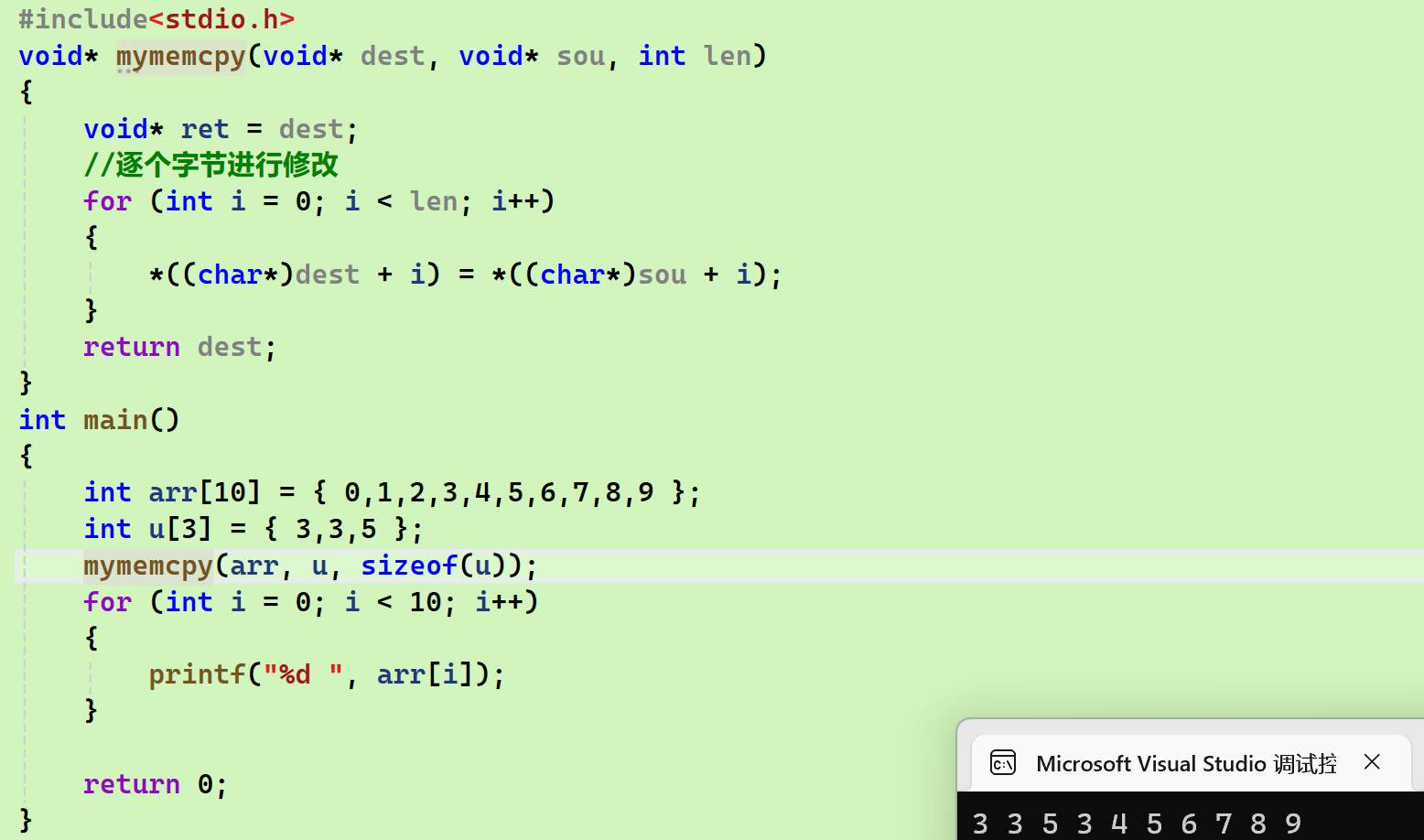
int main()
{
int arr[10] = { 0,1,2,3,4,5,6,7,8,9 };
int u[3] = { 3,3,5 };
mymemcpy(arr, u, sizeof(u));
for (int i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
memmove
基本用法
- 基本用法和memcpy相同,但是能处理内存重叠的情况
- 在模拟实现的时候需要考虑从前往后还是从后往前
和memcpy对比
- memmove能够应对内存重叠的情况
模拟实现
cpp
#include<stdio.h>
void* mymemmove(void* dest, void* sou, int len)
{
void* ret = dest;
//逐个字节进行修改
if ((char*)sou + len - 1 >= dest && sou < dest)
{
while(len--)
{
*((char*)dest + len) = *((char*)sou + len);
}
}
else
{
for (int i = 0; i < len; i++)
{
*((char*)dest + i) = *((char*)sou + i);
}
}
return dest;
}
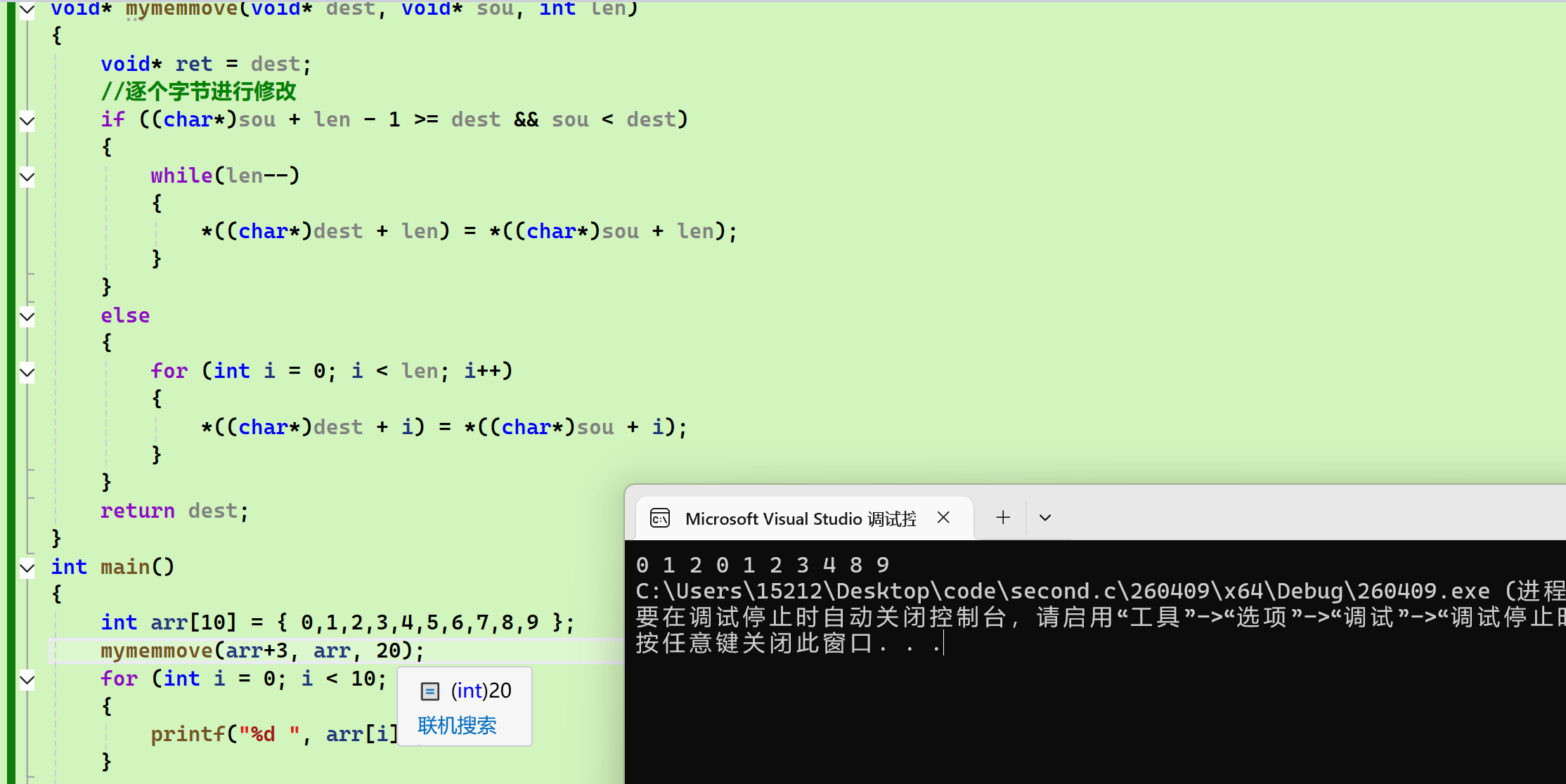
int main()
{
int arr[10] = { 0,1,2,3,4,5,6,7,8,9 };
mymemmove(arr+3, arr, 20);
for (int i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
memset
基本用法
-
第一个参数是一个地址
第二个参数是想把地址上设置的内容,可以是数字也可以是字符
第三个参数是想设置的字节数
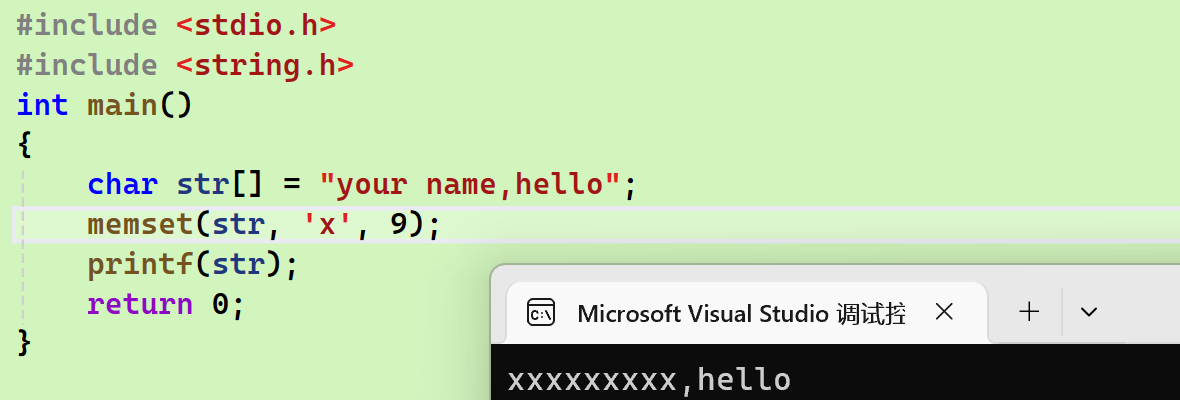
局限性
- 在设置字符的时候自然是没有问题,因为一个字符就是一个字节
- 但是如果想将整型数组设置的话就不太行,毕竟一个征信的是4个字节嘛
- 一般对整型数组使用的时候只设****0
memcmp
基本用法
- 传的参数和strcmp相似,第三个参数的含义变了------>相比较的字节数
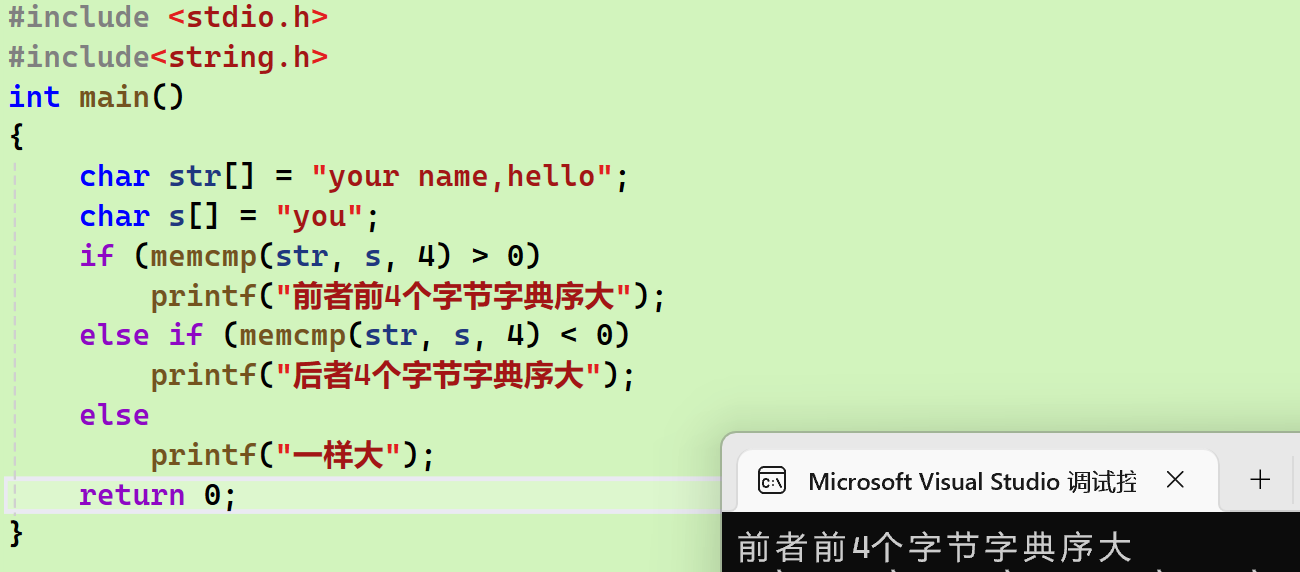
和strcmp对比
- strcmp只能比较字符串,而且只能比较到一个字符串的\0 。而memcmp没有限制