基本概念:
决策树广泛应用于分类和回归问题。
决策树以一种树状结构表示决策过程,每个内部节点表示一个特征或属性,每个分支表示测试的结果,每个叶子节点代表一个值或类别。
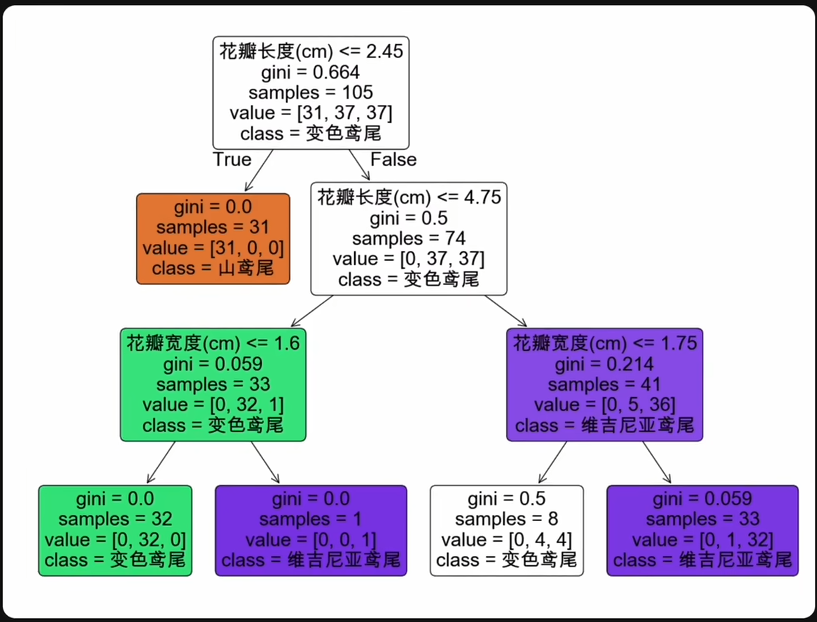
纯度:衡量一个子集中的样本类别是否一致。纯度越高,说明子集中的样本越相似。
基尼系数:用于分类的分裂标准,选择划分后基尼系数最小或纯度最大的特征,基尼系数为0表示完全纯净。
信息增益:衡量某一特征后的纯度提升。
决策树能展现完整的决策过程,相较于回归而言,有清晰的链路。
决策树不需要对数据进行归一化。
一般需要限制树的高度,如:3层,高于3层不再继续分裂。
缺点:
1.容易过拟合。
如果不限制决策额数,他会为了把每一个异常值分对,长出无数繁琐的分支,所以需要剪枝,只保留核心主干。
1)预剪枝
限制最大深度
限制叶节点最少样本数
2)后剪枝
先让树肆无忌惮生长,然后自下而上减掉非关键分支。效果更好,但是计算量大。
决策树延伸
随机森林:多颗相互独立的决策树,解决单树稳定性差,容易过拟合的问题。
每次抽取部分数据和特征,面对未知数据,所有树独立预测,投票表决。
梯度提升树(GBDT、XGBoost、LightGBM)
树之间不再独立,前赴后继,第二棵树专门纠正第一棵树的错误,不断迭代提升精度。