未来已来,只需一句指令,养龙虾专栏导航,持续更新ing...
什么是 MemPalace?
MemPalace 是由好莱坞演员 Milla Jovovich(《生化危机》《第五元素》主演)与开发者 Ben Sigman 共同开发的本地 AI 记忆管理系统。它解决了传统 AI 对话中"每次新开会话就失忆"的核心痛点。
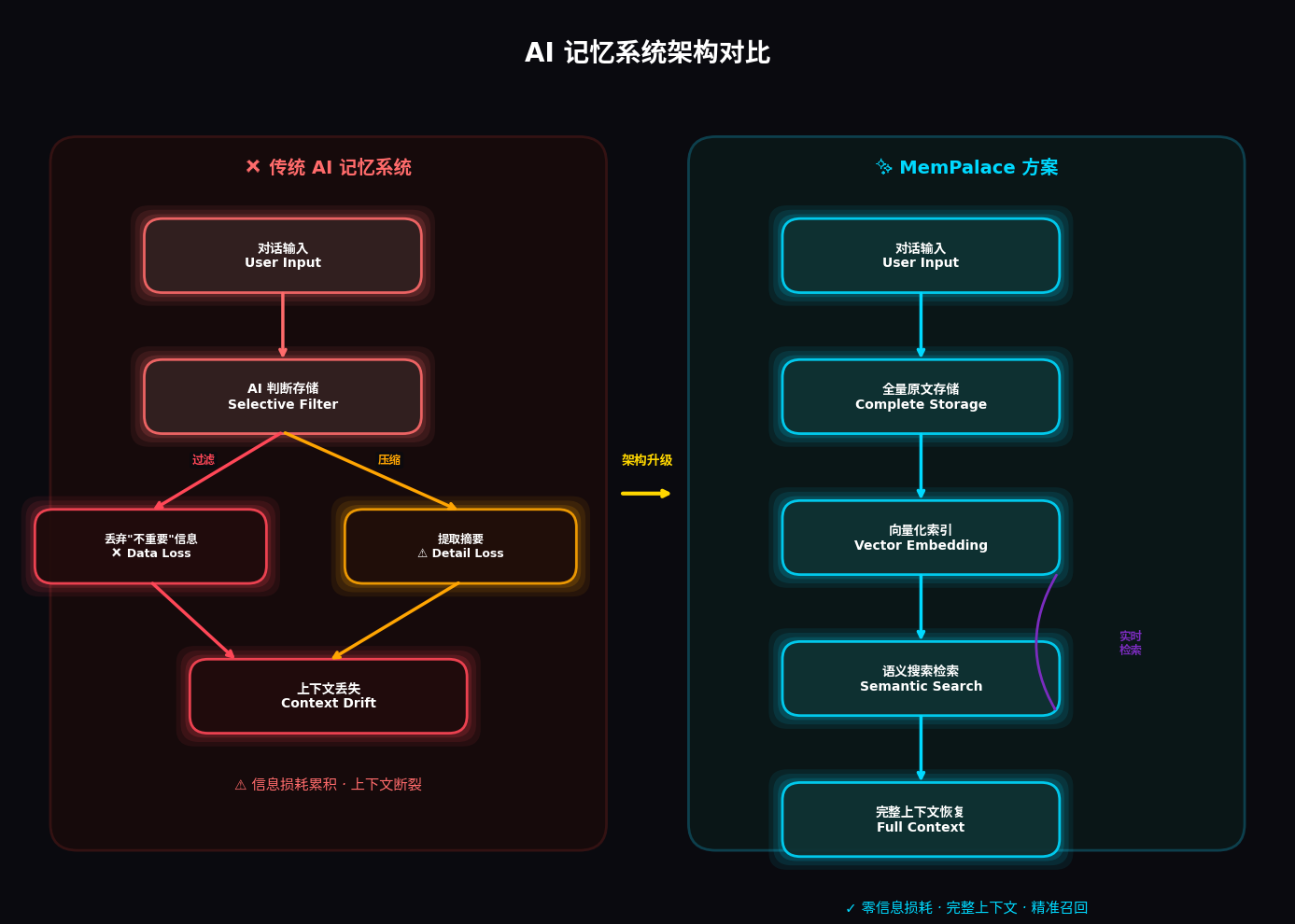
核心理念 :不同于 Mem0、Zep 等系统让 AI 决定"什么值得记住"(往往会丢弃推理过程和上下文),MemPalace 选择存储所有对话原文,通过向量搜索在需要时精准检索。这借鉴了古希腊"记忆宫殿"(Method of Loci)技巧------将信息按空间结构组织,大幅提升检索效率。
📋 前置环境条件
1. Python 版本要求
| 要求 | 版本 |
|---|---|
| 最低要求 | Python 3.9+ |
| 推荐版本 | Python 3.11+(性能最佳) |
检查命令:
bash
python --version
# 或
python3 --version2. 包管理工具选择
方案 A:uv(强烈推荐)
- 特点:由 Astral 开发的现代 Python 包管理器,速度极快,支持自动 Python 版本管理
- 安装:
bash
curl -LsSf https://astral.sh/uv/install.sh | sh- 验证:
uv --version
方案 B:pip + venv(传统方案)
- Python 内置,无需额外安装
- 适合习惯传统工作流的用户
3. 系统要求
| 项目 | 要求 |
|---|---|
| 操作系统 | Linux / macOS / Windows(Windows 需设置 PYTHONIOENCODING=utf-8) |
| 内存 | 至少 2GB 可用内存 |
| 磁盘空间 | 至少 500MB(用于模型和向量数据库) |
| 网络 | 首次安装需下载 ONNX 嵌入模型(约 80MB) |
4. 模型下载说明
首次运行时会自动下载 all-MiniLM-L6-v2 嵌入模型:
- 模型大小:~79MB
- 下载位置 :
~/.cache/chroma/onnx_models/all-MiniLM-L6-v2/onnx.tar.gz - 作用:将文本转换为 384 维向量,用于语义相似度搜索
🚀 安装步骤
方法一:使用 uv(推荐)
bash
# 1. 创建虚拟环境(自动安装 Python 3.11 如果未安装)
uv venv --python python3.11 ~/.mempalace-venv
# 2. 激活虚拟环境
source ~/.mempalace-venv/bin/activate
# 3. 安装 MemPalace
uv pip install mempalace
# 4. 验证安装
mempalace --helpuv 的优势:
- 自动处理 Python 版本
- 依赖解析速度比 pip 快 10-100 倍
- 原子化安装,失败自动回滚
方法二:使用 pip + venv
bash
# 1. 创建虚拟环境
python3.11 -m venv ~/.mempalace-venv
# 2. 激活虚拟环境
source ~/.mempalace-venv/bin/activate
# 3. 升级 pip
pip install --upgrade pip
# 4. 安装 MemPalace
pip install mempalace
# 5. 验证安装
mempalace --help方法三:全局安装(⚠️ 不推荐)
bash
pip3 install mempalace为什么不推荐:会污染系统 Python 环境,可能导致依赖冲突,且不利于后续卸载或版本管理。
如下图所示:
📦 预下载模型(网络慢的情况)
如果首次运行时下载模型超时,可手动预下载:
bash
# 1. 创建模型缓存目录
mkdir -p ~/.cache/chroma/onnx_models/all-MiniLM-L6-v2
# 2. 下载模型
cd ~/.cache/chroma/onnx_models/all-MiniLM-L6-v2
curl -L -o onnx.tar.gz https://chroma-onnx-models.s3.amazonaws.com/all-MiniLM-L6-v2/onnx.tar.gz
# 3. 解压模型
tar -xzf onnx.tar.gz🏗️ 初始化与核心概念
1. 初始化记忆宫殿
bash
# 激活环境
source ~/.mempalace-venv/bin/activate
# 初始化项目(扫描目录结构,创建房间)
mempalace init /path/to/your/project初始化过程原理:
- 扫描目录结构:识别项目文件、代码、文档
- 实体检测:自动识别人名、项目名(如 "Kai"、"Driftwood")
- 创建配置文件 :
~/.mempalace/config.json:全局配置~/.mempalace/wing_config.json:翼楼映射~/.mempalace/identity.txt:身份层(L0)
记忆宫殿架构
Wing 翼楼
项目/人物
Hall 大厅
记忆类型
Room 房间
具体主题
Closet 壁橱
AAAK压缩摘要
Drawer 抽屉
原文存储
核心概念解释:
| 概念 | 说明 | 类比 |
|---|---|---|
| Wing(翼楼) | 顶级容器,每个项目或人物一个翼楼 | 图书馆的不同分馆 |
| Hall(大厅) | 记忆类型走廊:facts(事实)、events(事件)、discoveries(发现)、preferences(偏好)、advice(建议) | 图书馆的分类标签 |
| Room(房间) | 翼楼内的具体主题,如 "auth-migration"、"pricing" | 图书馆的书架 |
| Closet(壁橱) | 存储 AAAK 压缩摘要,指向原始内容 | 书籍的索引卡片 |
| Drawer(抽屉) | 原始文件存储,永不删除 | 书籍本身 |
2. 挖掘数据(Mining)
项目文件挖掘:
bash
# 挖掘代码、文档、笔记
mempalace mine /path/to/your/project对话记录挖掘:
bash
# 挖掘 Claude、ChatGPT、Slack 导出文件
mempalace mine /path/to/chats --mode convos
# 自动分类为决策、里程碑等
mempalace mine /path/to/chats --mode convos --extract general三种挖掘模式:
- projects:代码和文档(按段落分块)
- convos:对话导出(按问答对分块)
- general:自动分类为 decisions(决策)、milestones(里程碑)、problems(问题)、preferences(偏好)、emotional context(情感上下文)
3. 搜索记忆
bash
# 基础搜索
mempalace search "为什么我们切换到 GraphQL"
# 在特定翼楼搜索
mempalace search "定价讨论" --wing my_app
# 在特定房间搜索
mempalace search "定价讨论" --wing my_app --room costs
# 查看状态
mempalace status4. 唤醒上下文(Wake-up)
bash
# 显示 L0 + L1 唤醒上下文(约 170 tokens)
mempalace wake-up
# 特定项目的唤醒上下文
mempalace wake-up --wing my_app四层记忆栈原理:
四层记忆栈
主题匹配
需要更多上下文
语义搜索
L0: Identity 身份层
~50 tokens
始终加载
L1: Critical Facts 关键事实
~120 tokens
始终加载
L2: Room Recall 房间回忆
按需加载
L3: Deep Search 深度搜索
按需加载
用户提问
ChromaDB
| 层级 | 内容 | 大小 | 加载时机 |
|---|---|---|---|
| L0 | 身份定义(你是谁、AI 是谁) | ~50 tokens | 始终加载 |
| L1 | 关键事实(团队、项目、偏好) | ~120 tokens(AAAK 压缩) | 始终加载 |
| L2 | 房间回忆(当前主题相关会话) | 可变 | 主题匹配时 |
| L3 | 深度语义搜索(全文检索) | 可变 | 显式请求时 |
成本对比(基于 6 个月对话历史约 1950 万 tokens):
| 方案 | 加载 Tokens | 年成本 |
|---|---|---|
| 粘贴全部 | 19.5M(超出上下文窗口) | 不可行 |
| LLM 摘要 | ~650K | ~$507 |
| MemPalace wake-up | ~170 | ~$0.70 |
| MemPalace + 5 次搜索 | ~13,500 | ~$10 |
🔧 与 AI 集成
Claude Code(推荐)
方式 1:插件市场安装
bash
claude plugin marketplace add milla-jovovich/mempalace
claude plugin install --scope user mempalace方式 2:手动 MCP 配置
bash
claude mcp add mempalace -- python -m mempalace.mcp_server重启 Claude Code,输入 /skills 验证 "mempalace" 是否出现。
其他 MCP 兼容工具(ChatGPT、Cursor、Gemini)
bash
# 通用 MCP 配置命令
claude mcp add mempalace -- python -m mempalace.mcp_server配置后,AI 可自动调用 19 个 MCP 工具:
读取工具:
mempalace_status:宫殿概览mempalace_list_wings:列出翼楼mempalace_list_rooms:列出房间mempalace_search:语义搜索mempalace_kg_query:知识图谱查询
写入工具:
mempalace_add_drawer:添加原文mempalace_diary_write:写入代理日记
本地模型(Llama、Mistral 等)
方式 1:唤醒命令
bash
mempalace wake-up > context.txt
# 将 context.txt 粘贴到本地模型的系统提示中方式 2:命令行搜索
bash
mempalace search "auth decisions" > results.txt
# 将结果包含在提示词中方式 3:Python API
python
from mempalace.searcher import search_memories
results = search_memories(
"auth decisions",
palace_path="~/.mempalace/palace"
)
# 将结果注入本地模型上下文📁 目录结构详解
安装后生成的文件结构:
~/.mempalace/ # 全局记忆宫殿
├── palace.db # SQLite 元数据数据库
├── chroma/ # ChromaDB 向量数据库
├── config.json # 全局配置
├── wing_config.json # 翼楼映射配置
├── identity.txt # 身份层(L0)
└── wings/ # 翼楼目录
├── wing_kai/ # 人物翼楼示例
│ ├── hall_facts/
│ ├── hall_events/
│ ├── hall_discoveries/
│ ├── hall_preferences/
│ └── hall_advice/
└── wing_driftwood/ # 项目翼楼示例
└── ...
/path/to/your/project/ # 项目目录
├── mempalace.yaml # 项目特定配置(可选)
└── .mempalace_entities.json # 项目实体检测缓存🛠️ 常见问题与解决方案
Q: pip: command not found
解决方案:
bash
# 使用 pip3
pip3 install mempalace
# 或安装 uv(推荐)
curl -LsSf https://astral.sh/uv/install.sh | shQ: Python 版本过低(< 3.9)
解决方案:
bash
# 使用 uv 安装新 Python
uv python install 3.11
uv venv --python python3.11 ~/.mempalace-venvQ: 下载模型超时
解决方案:手动预下载模型(见上方"预下载模型"部分)
Q: No palace found
解决方案:
bash
# 必须先初始化
mempalace init <dir>
# 然后挖掘数据
mempalace mine <dir>Q: 如何重置/删除记忆宫殿
解决方案:
bash
# 删除宫殿目录
rm -rf ~/.mempalace/palace
# 然后重新初始化
mempalace init <dir>Q: Windows 下 Unicode 编码错误(GitHub issue #47)
解决方案:
powershell
# Windows PowerShell
$env:PYTHONIOENCODING = "utf-8"
mempalace initQ: ChromaDB 依赖构建失败
解决方案:
bash
# macOS
xcode-select --install
# Ubuntu/Debian
sudo apt-get install build-essential python3-dev
# 然后重试安装
pip install mempalace📊 性能参考与基准测试
| 操作 | 性能指标 |
|---|---|
| 初始化 | 扫描 100 个文件约 10-30 秒 |
| 挖掘 | 每分钟处理 10-50 个文件(取决于大小) |
| 搜索 | < 1 秒返回结果 |
| 首次运行 | 额外 2-5 分钟下载模型 |
基准测试成绩:
| 基准测试 | 模式 | 成绩 | API 调用 |
|---|---|---|---|
| LongMemEval R@5 | Raw(纯本地) | 96.6% | 零 |
| LongMemEval R@5 | Hybrid + Haiku 重排序 | 100% (500/500) | ~500 次 |
| LoCoMo R@10 | Raw,会话级别 | 60.3% | 零 |
与竞品对比:
| 系统 | LongMemEval R@5 | 成本 | 本地运行 |
|---|---|---|---|
| MemPalace (hybrid) | 100% | 免费 | 是 |
| Supermemory ASMR | ~99% | 付费 | 否 |
| MemPalace (raw) | 96.6% | 免费 | 是 |
| Mastra | 94.87% | API 费用 | 否 |
| Mem0 | ~85% | $19-249/月 | 否 |
| Zep | ~85% | $25/月+ | 否 |
🔗 官方资源
⚠️ 重要说明(来自官方)
根据 Milla Jovovich 和 Ben Sigman 在 2026 年 4 月 7 日的声明:
-
AAAK 压缩是实验性的 :目前 LongMemEval 成绩 96.6% 来自 Raw 模式(原文存储),而非 AAAK 压缩模式(84.2%)。AAAK 在大量重复实体场景下才能体现压缩优势。
-
"30x 无损压缩"表述过度:AAAK 是有损缩写系统,通过实体编码和句子截断实现压缩,并非无损压缩。
-
"+34% 宫殿提升"说明:该数字比较的是无过滤搜索 vs 翼楼+房间元数据过滤,这是 ChromaDB 的标准元数据过滤功能,并非全新的检索机制。
-
矛盾检测 :
fact_checker.py工具存在,但尚未自动集成到知识图谱操作中。
总结 :MemPalace 是一个真实、可用的开源项目,其核心优势在于本地运行、零 API 成本、原文存储、高检索准确率。96.6% 的 LongMemEval 原始成绩(零 API 调用)是可信的,代表了当前免费本地 AI 记忆系统的最高水平。