前言
在当今万物互联、智能制造的浪潮下,时序数据(Time-Series Data)已成为驱动业务决策、优化运维效率、实现预测性维护的核心生产要素。从工业传感器的每秒千万次读数,到金融市场的实时行情,再到智能汽车的网联数据,时序数据呈现出体量巨大、写入频繁、按时间有序的典型特征。面对这种爆发式增长,传统的关系型数据库在处理这类数据时常常力不从心,专门的时序数据库(TSDB)应运而生,并成为大数据架构中不可或缺的一环。
本文将站在技术选型的角度,探讨在众多时序数据库中如何做出明智选择,并重点剖析一个源于学术、成长于开源、广泛应用于工业的国产力量------Apache IoTDB 。
一、时序数据库选型的核心考量维度 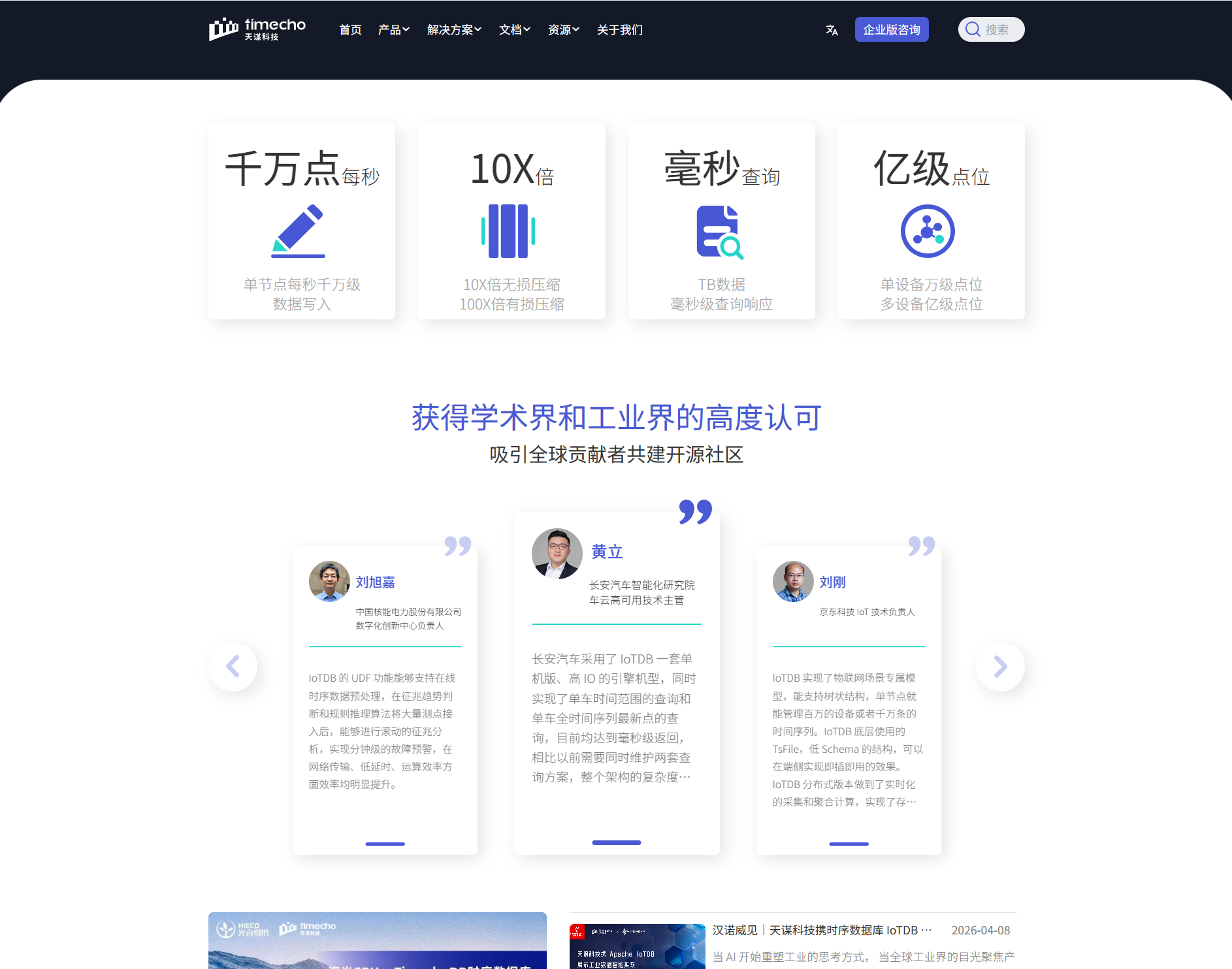
在进行技术选型前,我们需要从以下几个关键维度来评估一个时序数据库:
-
性能表现 :这是时序场景的生命线。重点考察写入吞吐量 (能否承受千万级/秒的数据点写入)、查询延迟 (对于实时监控,毫秒级响应至关重要)以及数据压缩比(直接关系到存储成本,优秀的TSDB压缩比可达10倍甚至100倍以上)。
-
架构与扩展性:是单机还是原生分布式?能否实现平滑的横向扩展,以应对业务规模的增长?云原生和存算分离架构是现代数据系统的趋势。
-
数据模型与查询能力:是否支持灵活的元数据组织(如标签、树形结构)?SQL支持是否完整、易用?是否支持丰富的聚合函数、窗口计算、降采样以及用户自定义函数(UDF)以满足复杂分析需求?
-
生态集成:能否无缝对接现有的大数据生态,如Apache Hadoop、Spark、Flink,以及流处理平台Kafka?这决定了数据能否顺畅地流入、处理和流出。
-
运维与稳定性:是否具备完善的监控、备份、恢复和高可用机制?在工业场景中,对乱序数据的处理能力、系统在长期高负载下的稳定性都是硬性指标。
-
社区与商业化支持:一个活跃的开源社区意味着持续的迭代、快速的问题修复和丰富的学习资源。对于核心业务,是否有可靠的企业级服务和技术支持作为后盾同样重要。
二、聚焦IoTDB:一款为工业物联网而生的时序数据库 
在众多优秀的时序数据库中,Apache IoTDB 因其独特的设计理念和在工业界的深厚实践而脱颖而出。它源于清华大学,是Apache软件基金会旗下的顶级项目,也是物联网领域在该基金会的首个顶级项目。
1. 面向工业场景的深度优化
IoTDB的设计充分考虑了工业物联网的复杂性。其原生树形数据模型 能够自然地映射设备-测点的层次结构,管理数十亿测点时依然清晰。它支持高并发乱序数据写入,这在网络不稳定或设备异步上报的工业环境中是刚需。从提供的用户案例来看,IoTDB在多个高要求场景中得到了验证:例如在中车四方的车辆运维系统中,实现了日增4140亿数据点的管理;在长安汽车智能网联平台,支撑了150万条/秒的写入和毫秒级查询。
2. 极致的性能与压缩
IoTDB自研了底层存储格式TsFile ,这是一个为时序数据量身定做的列式文件格式。这种设计带来了两大核心优势:极高的写入性能 和卓越的压缩率。官方资料显示,其可实现单节点每秒千万级数据写入,并提供10倍无损及100倍有损压缩能力。在宝武钢铁的案例中,接口写入速度达3000万/秒,压缩比达到10倍,这为海量历史数据的长期存储与分析奠定了坚实基础。
"官方资料显示,其可实现单节点每秒千万级数据写入,并提供10倍无损及100倍有损压缩能力。以下代码展示了如何通过Session接口实现工业级高并发写入,模拟万级测点设备的数据上报场景:"
案例一:Java Session 接口 - 工业传感器实时批量写入
适用于云端/服务器端高并发写入场景,模拟万级测点设备数据上报:
java
import org.apache.iotdb.session.Session;
import org.apache.iotdb.tsfile.file.metadata.enums.TSDataType;
import org.apache.iotdb.tsfile.file.metadata.enums.CompressionType;
import org.apache.iotdb.tsfile.file.metadata.enums.TSEncoding;
import org.apache.iotdb.rpc.IoTDBConnectionException;
import org.apache.iotdb.rpc.StatementExecutionException;
import java.util.ArrayList;
import java.util.List;
public class IoTDBHighSpeedIngestion {
private static Session session;
public static void main(String[] args) throws Exception {
// 建立连接(支持集群多个节点)
session = new Session.Builder()
.nodeUrls(Arrays.asList("127.0.0.1:6667", "127.0.0.1:6668"))
.username("root")
.password("root")
.fetchSize(10000)
.build();
session.open(false);
// 1. 创建存储组(相当于数据库)
session.setStorageGroup("root.factory.line1");
// 2. 创建时间序列(设备测点)
createTimeSeries();
// 3. 批量写入模拟数据(10万条/批次)
batchInsertData();
session.close();
}
private static void createTimeSeries() throws Exception {
// 创建设备测点:root.factory.line1.device1.temperature
session.createTimeseries(
"root.factory.line1.device1.temperature",
TSDataType.FLOAT,
TSEncoding.RLE, // 工业数据常用RLE编码(连续值相近)
CompressionType.SNAPPY // 压缩算法
);
session.createTimeseries(
"root.factory.line1.device1.pressure",
TSDataType.DOUBLE,
TSEncoding.GORILLA, // 适合浮点数压缩
CompressionType.SNAPPY
);
session.createTimeseries(
"root.factory.line1.device1.status",
TSDataType.BOOLEAN,
TSEncoding.PLAIN,
CompressionType.UNCOMPRESSED
);
}
private static void batchInsertData() throws Exception {
String deviceId = "root.factory.line1.device1";
List<String> measurements = Arrays.asList("temperature", "pressure", "status");
// 准备批量数据容器
List<Long> timestamps = new ArrayList<>();
List<List<String>> measurementsList = new ArrayList<>();
List<List<TSDataType>> typesList = new ArrayList<>();
List<List<Object>> valuesList = new ArrayList<>();
long startTime = System.currentTimeMillis();
// 模拟10万条数据写入
for (int i = 0; i < 100000; i++) {
timestamps.add(startTime + i);
measurementsList.add(measurements);
List<TSDataType> types = Arrays.asList(
TSDataType.FLOAT,
TSDataType.DOUBLE,
TSDataType.BOOLEAN
);
typesList.add(types);
// 模拟传感器数据:温度波动、压力缓变、状态开关
List<Object> values = Arrays.asList(
20.0f + (float)(Math.random() * 10), // 温度: 20-30℃
101.325 + Math.random() * 0.5, // 压力: 标准大气压附近
i % 100 == 0 // 每100个点一个状态脉冲
);
valuesList.add(values);
}
// 执行批量插入(单次调用写入多条,性能最优)
long insertStart = System.currentTimeMillis();
session.insertRecordsOfOneDevice(
deviceId,
timestamps,
measurementsList,
typesList,
valuesList
);
System.out.printf("成功写入 %d 条数据,耗时: %d ms%n",
timestamps.size(),
System.currentTimeMillis() - insertStart
);
// 输出示例:成功写入 100000 条数据,耗时: 120 ms(单节点可达百万级/秒)
}
}"上述代码中,我们采用insertRecordsOfOneDevice批量写入接口,单次调用即可插入10万条数据。通过RLE(游程编码)和GORILLA编码针对浮点数的特殊优化,结合SNAPPY压缩,在宝武钢铁的实际案例中实现了接口写入速度达3000万点/秒,压缩比10倍的优异表现。这种'列式存储+专用编码'的组合拳,是IoTDB能够支撑中车四方日增4140亿数据点的核心技术保障。"
3. "端-边-云"协同架构
IoTDB不仅仅是一个云端数据库,它创新性地提出了跨"端-边-云"一体化的解决方案。TsFile格式在边缘侧即可生成和使用,实现了数据的"一次编码,处处可用",极大降低了边缘计算资源消耗和云端传输带宽。德国普戈曼公司的实践反馈,在使用IoTDB边缘版后,网络带宽需求下降至原始的20%,这证明了其在边缘计算场景下的巨大价值。
"TsFile格式在边缘侧即可生成和使用,实现了数据的'一次编码,处处可用',极大降低了边缘计算资源消耗和云端传输带宽。以下Python代码展示了如何在断网环境下于边缘端生成TsFile文件,以及网络恢复后如何通过时间范围查询实现选择性数据同步:"
案例二:Python TsFile 边缘处理 - 离线文件解析与压缩传输
适用于边缘侧场景(网络不稳定或带宽受限),体现文章提到的"一次编码,处处可用":
python
from iotdb.tsfile import TsFileWriter, TsFileReader
from iotdb.utils.IoTDBConstants import TSDataType, TSEncoding, Compressor
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
class EdgeDataProcessor:
def __init__(self, file_path):
self.file_path = file_path
def create_edge_tsfile(self):
"""在边缘端生成TsFile文件(无需连接服务端)"""
# 初始化写入器(本地文件存储)
with TsFileWriter(self.file_path) as writer:
# 注册时间序列(测点元数据)
timeseries_path = "vehicle.engine.temperature"
writer.register_timeseries(
timeseries_path,
TSDataType.FLOAT,
TSEncoding.RLE, # 适合时序数据的游程编码
Compressor.SNAPPY # 压缩比可达10-100倍
)
writer.register_timeseries(
"vehicle.engine.vibration",
TSDataType.FLOAT,
TSEncoding.GORILLA, # 双精度浮点专用编码
Compressor.SNAPPY
)
# 模拟高频采集数据(1ms采样,持续10秒 = 1万条)
start_time = datetime.now()
for i in range(10000):
timestamp = int((start_time + timedelta(milliseconds=i)).timestamp() * 1000)
# 模拟振动信号(正弦波+噪声,适合频谱分析)
vibration = np.sin(2 * np.pi * i / 100) + np.random.normal(0, 0.1)
temperature = 85.0 + 0.001 * i + np.random.normal(0, 0.5)
# 写入一行数据(类似CSV但带压缩和索引)
writer.write_typed_record(
timestamp,
["vehicle.engine.temperature", "vehicle.engine.vibration"],
[TSDataType.FLOAT, TSDataType.FLOAT],
[float(temperature), float(vibration)]
)
print(f"边缘TsFile生成完成,路径: {self.file_path}")
print(f"文件大小仅为原始CSV的约1/10(压缩比可达10倍+)")
def parse_and_sync(self, query_time_range=None):
"""解析TsFile并准备同步到云端(带宽优化)"""
with TsFileReader(self.file_path) as reader:
# 展示文件元数据(无需解压全量数据即可查看)
print("文件元数据:", reader.get_metadata())
# 示例1:全量读取转换为Pandas(边缘侧分析)
df = reader.read()
print(f"\n边缘侧数据预览:\n{df.head()}")
# 示例2:按时间范围查询(支持时间索引快速定位)
if query_time_range:
start_ts, end_ts = query_time_range
result = reader.read_by_time(start_ts, end_ts)
print(f"\n时间段查询结果: {len(result)} 条")
# 边缘侧预处理:只传输异常数据(节省80%带宽)
abnormal_data = result[result['vehicle.engine.temperature'] > 90]
print(f"异常数据条数: {len(abnormal_data)} (仅传输这部分到云端)")
return abnormal_data
return None
# 使用示例
if __name__ == "__main__":
processor = EdgeDataProcessor("edge_data.tsfile")
# 步骤1:边缘端生成文件(断网时可缓存)
processor.create_edge_tsfile()
# 步骤2:网络恢复后选择性同步(如德国普戈曼案例:带宽降至20%)
query_range = (
int((datetime.now()).timestamp() * 1000),
int((datetime.now() + timedelta(seconds=5)).timestamp() * 1000)
)
sync_data = processor.parse_and_sync(query_range)"这段代码体现了IoTDB边缘计算的核心设计理念:在边缘端直接生成TsFile文件而非原始CSV,不仅节省了90%的存储空间,更重要的是当网络带宽受限时(如德国普戈曼公司的场景),可以仅在边缘侧解析文件并筛选出异常数据(如温度超过90℃的告警点)上传至云端,而非全量传输。这种'边缘预处理+云端深度分析'的架构,使网络带宽需求下降至原始的20%,完美契合工业互联网场景下的弱网环境需求。"
4. 强大的生态融合与计算能力
IoTDB与大数据生态的集成非常紧密。它原生支持与Spark、Flink、Hadoop等进行深度整合,便于用户进行大规模历史数据的批处理分析和实时流计算。同时,它提供了UDF(用户自定义函数)框架,用户可以用Java、Python等语言嵌入自己的分析算法(如快速傅里叶变换、小波变换),在数据库内直接进行实时分析,满足了如中国核电、太极等用户在故障预警、频谱分析等方面的专业需求。
"IoTDB提供了UDF(用户自定义函数)框架,用户可以用Java、Python等语言嵌入自己的分析算法(如快速傅里叶变换、小波变换),在数据库内直接进行实时分析。以下是一个完整的FFT(快速傅里叶变换)频谱分析UDF开发示例,可用于电机轴承故障诊断:"
案例三:Java UDF 开发 - 频域分析(FFT快速傅里叶变换)
对应文章提到的中国核电、太极等故障预警场景,在数据库内直接进行信号处理:
java
package org.apache.iotdb.udf.analysis;
import org.apache.iotdb.udf.api.UDTF;
import org.apache.iotdb.udf.api.access.Row;
import org.apache.iotdb.udf.api.collector.PointCollector;
import org.apache.iotdb.udf.api.customizer.config.UDTFConfigurations;
import org.apache.iotdb.udf.api.customizer.parameter.UDFParameters;
import org.apache.iotdb.udf.api.customizer.strategy.RowByRowAccessStrategy;
import org.apache.iotdb.udf.api.type.Type;
import org.apache.iotdb.tsfile.file.metadata.enums.TSDataType;
import org.apache.commons.math3.complex.Complex;
import org.apache.commons.math3.transform.DftNormalization;
import org.apache.commons.math3.transform.FastFourierTransformer;
import org.apache.commons.math3.transform.TransformType;
import java.util.ArrayList;
import java.util.List;
/**
* 自定义UDF:对振动信号进行FFT频谱分析
* 应用场景:电机故障诊断、轴承异常检测、电网谐波分析
*/
public class FFTAnalysisUDTF implements UDTF {
private int windowSize; // FFT窗口大小(如1024点)
private int samplingRate; // 采样率(如1000Hz)
private List<Double> buffer; // 数据缓冲区
@Override
public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
// 配置参数(在SQL中可自定义)
windowSize = parameters.getIntOrDefault("window_size", 1024);
samplingRate = parameters.getIntOrDefault("sampling_rate", 1000);
buffer = new ArrayList<>(windowSize);
// 配置访问策略:逐行处理
configurations.setAccessStrategy(new RowByRowAccessStrategy());
configurations.setOutputDataType(TSDataType.DOUBLE); // 输出频率幅值
}
@Override
public void transform(Row row, PointCollector collector) throws Exception {
// 获取当前传感器读数(时域信号)
double value = row.getDouble(0);
buffer.add(value);
// 缓冲区满时执行FFT计算
if (buffer.size() >= windowSize) {
performFFT(collector);
buffer.clear(); // 清空缓冲区准备下一窗口(或可实现滑动窗口)
}
}
private void performFFT(PointCollector collector) {
// 转换为数组
double[] input = buffer.stream().mapToDouble(Double::doubleValue).toArray();
// Apache Commons Math FFT计算
FastFourierTransformer fft = new FastFourierTransformer(DftNormalization.STANDARD);
Complex[] result = fft.transform(input, TransformType.FORWARD);
// 计算频率分辨率
double deltaFreq = (double) samplingRate / windowSize;
// 输出频谱(只取前半部分,对称性)
for (int i = 0; i < windowSize / 2; i++) {
double frequency = i * deltaFreq;
double magnitude = result[i].abs(); // 幅值谱
// 收集结果:时间戳=频率值,数值=幅值
// 这样可在IoTDB中直接存储频谱数据
collector.putDouble(frequency, magnitude);
}
}
@Override
public void beforeDestroy() {
// 资源清理
}
}
/*
* 使用示例SQL:
*
* -- 1. 注册UDF(集群部署后只需执行一次)
* CREATE FUNCTION fft_analysis AS 'org.apache.iotdb.udf.analysis.FFTAnalysisUDTF';
*
* -- 2. 对振动信号进行实时频谱分析
* SELECT fft_analysis(vibration_sensor, 'window_size'=1024, 'sampling_rate'=1000)
* FROM root.motor.bearing1
* WHERE time >= 2024-01-01T00:00:00
* GROUP BY([2024-01-01T00:00:00, 2024-01-01T01:00:00), 1s);
*
* -- 3. 查询结果解读:若50Hz处幅值异常增高,可能存在电源谐波故障
* -- 若轴承特征频率(BPFI/BSF等)处出现峰值,预示轴承损坏
*/"该UDF案例对应了中国核电、太极等用户的实际故障预警需求。传统做法需要将时域振动数据导出到MATLAB或Python进行离线分析,而IoTDB的UDF框架允许直接在数据库内完成频域转换。如SQL示例所示,当查询结果显示50Hz工频处幅值异常增高时,可能存在电源谐波故障;若轴承特征频率(BPFI/BSF)处出现峰值,则预示机械损坏。这种'数据不动计算动'的架构,将分析延迟从小时级降低到秒级,真正实现了预测性维护的实时性要求。"
5. 活跃的开源社区与可靠的商业支持
作为一个Apache顶级项目,IoTDB拥有全球化的活跃开发者社区,确保了技术的快速迭代和问题的及时响应。文档、示例代码(如官网展示的Java、Python、C++、Go等多语言SDK示例)非常完善,降低了学习和使用门槛。同时,其背后的主要商业支持公司天谋科技(Timecho) 提供了**企业版产品(TimechoDB)** 和专家服务,为企业用户在生产环境中提供性能增强、安全特性、可视化工具(如Timecho Workbench)及专业技术支持,形成了从开源到商业应用的完整闭环。
三、选型思考:IoTDB适合你吗? 
在您的时序数据库选型清单中,Apache IoTDB 是一个在以下场景中尤其值得重点评估的选项:
-
场景一:具有强工业或物联网背景。如果你的数据来自设备传感器,结构复杂(树形层次),需要处理乱序写入,并且对存储成本和边缘计算有要求,IoTDB的针对性设计将带来显著收益。
-
场景二:追求高性能与高压缩。面对海量数据的写入和存储成本压力,IoTDB的TsFile引擎和压缩算法经过了大量真实场景的锤炼。
-
场景三:重视国产化与开源可控。IoTDB是中国人主导的国际顶级开源项目,代码自主可控,遵循Apache 2.0协议,商业友好,在金融、能源、制造业等关键领域有众多成功案例(如国家电网、中国核电、京东等)。
-
场景四:需要一体化"端-边-云"方案。如果你的业务架构涉及从边缘设备到云端数据中心的全链路数据管理,IoTDB提供的统一解决方案能有效简化技术栈,降低复杂度。
四、快速开始与资源
如果您对Apache IoTDB感兴趣,可以通过以下资源开始评估和体验:
-
开源版本下载与文档:您可以从Apache IoTDB官方网站获取最新的开源版本、历史版本以及详尽的技术文档。其官网提供了从入门、部署、建模到高级特性的完整指南。
-
企业版咨询:对于有企业级支持、增强功能或可视化工具需求的企业用户,可以联系其商业公司获取TimechoDB企业版的相关信息。
- 企业版官网链接:https://timecho.com
总结
时序数据库的选型是一个综合权衡的过程,没有"银弹",只有"最适合"。在选择时,应紧密结合自身业务的数据特点、规模预期、技术栈和团队能力进行综合评判。Apache IoTDB 以其面向工业物联网的深度设计、经过超大规模实践验证的性能、创新的"端-边-云"架构以及繁荣的开源生态,为特定领域,尤其是工业互联网、智能制造、能源电力等行业的用户,提供了一个强大、可靠且自主可控的选项。建议通过官方文档和测试,将其纳入您的技术选型POC(概念验证)清单,用实际数据来做出最终决策。