背景
边记录边操作,目前有对应的需求考虑到采用ES来对业务提供查询接口使用。采用实时方案写入ES,通过FlinkCDC3.5读取mysql直接sink到ES。
配置依赖说明
为什么选择3.5,目前我看官网发布的最新是3.6,奈何我司的集群环境是jdk8所以只能选择了3.5。
- flink-sql-connector-mysql-cdc 依赖读取mysql binlog
- flink-connector-elasticsearch7 为啥是7.x版本,flink官网提供的最后一个ES支持版本为7.x,当时我们安装了ES9.x版本,结果就是我们集群的机器jdk是1.8,而ES的依赖是jdk17编译的,所以导致不兼容。最后的方案就是降级ES到7.x。
- flink 选择是1.20 也是最后jdk1.8的版本了吧。2.0以后得11起步了。
代码开发
读取mysql
java
Properties debeziumProperties = new Properties();
debeziumProperties.put("snapshot.locking.mode", "none"); // 避免锁表
debeziumProperties.put("decimal.handling.mode", "string"); // Decimal 转 String
debeziumProperties.put("bigint.unsigned.handling.mode", "long"); // 无符号 bigint 转 long
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
//.startupOptions(StartupOptions.timestamp(1667232000000L))
.hostname(MysqlConstant.SM_TEST_HOST)
.port(MysqlConstant.CMMON_PORT)
.databaseList(库名) // 设置捕获的数据库, 如果需要同步整个数据库,请将 tableList 设置为 ".*".
.tableList(库 + "." + 表) // 设置捕获的表
.username(MysqlConstant.SM_USER_NAME)
.password(MysqlConstant.SM_PASSWORD)
.startupOptions(StartupOptions.initial()) // initial: 先快照后增量
.deserializer(new JsonDebeziumDeserializationSchema()) // 将 SourceRecord 转换为 JSON 字符串
.debeziumProperties(debeziumProperties)
.build();写入ES sink
sink就是按照flink官网提供的就可以 https://nightlies.apache.org/flink/flink-docs-release-1.20/docs/connectors/datastream/elasticsearch/
java
HttpHost[] hosts = new HttpHost[]{
new HttpHost(ESApiConstant.SERVER_IP1, ESApiConstant.SERVER_PORT, ESApiConstant.SERVER_PROTOCOL)
, new HttpHost(ESApiConstant.SERVER_IP2, ESApiConstant.SERVER_PORT, ESApiConstant.SERVER_PROTOCOL)
, new HttpHost(ESApiConstant.SERVER_IP3, ESApiConstant.SERVER_PORT, ESApiConstant.SERVER_PROTOCOL)
};
// ES 配置
ElasticsearchSinkConfig config = ElasticsearchSinkConfig.builder()
.indexName("test-" + LocalDate.now().getYear())
.idField("id")
.hosts(hosts)
.bulkActions(1000)
.bulkIntervalMs(5000)
.maxRetries(5)
.retryDelayMs(1000)
.build();
DataStream<Elasticsearch7Sink.CDCRequest> esRequests = mySQLSource
.map(new CDCToESRequestMapper(config.getIndexName(), config.getIdField()))
.filter(request -> request != null);
esRequests.sinkTo(
new Elasticsearch7SinkBuilder<Elasticsearch7Sink.CDCRequest>()
.setHosts(config.getHosts())
.setConnectionUsername(ESApiConstant.USER_NAME)
.setConnectionPassword(ESApiConstant.USER_PASSWORD)
.setEmitter((request, context, indexer) -> {
switch (request.getType()) {
case INDEX:
indexer.add(request.getIndexRequest());
break;
case UPDATE:
indexer.add(request.getUpdateRequest());
break;
case DELETE:
indexer.add(request.getDeleteRequest());
break;
}
})
.setBulkFlushMaxActions(config.getBulkActions())
.setBulkFlushInterval(config.getBulkIntervalMs())
.setBulkFlushBackoffStrategy(
FlushBackoffType.EXPONENTIAL,
config.getMaxRetries(),
config.getRetryDelayMs()
)
.build()
).setParallelism(1);提交任务
- 完成以上的工作就可以提交任务了 打包jar,部署我选择是Streampark提交任务。

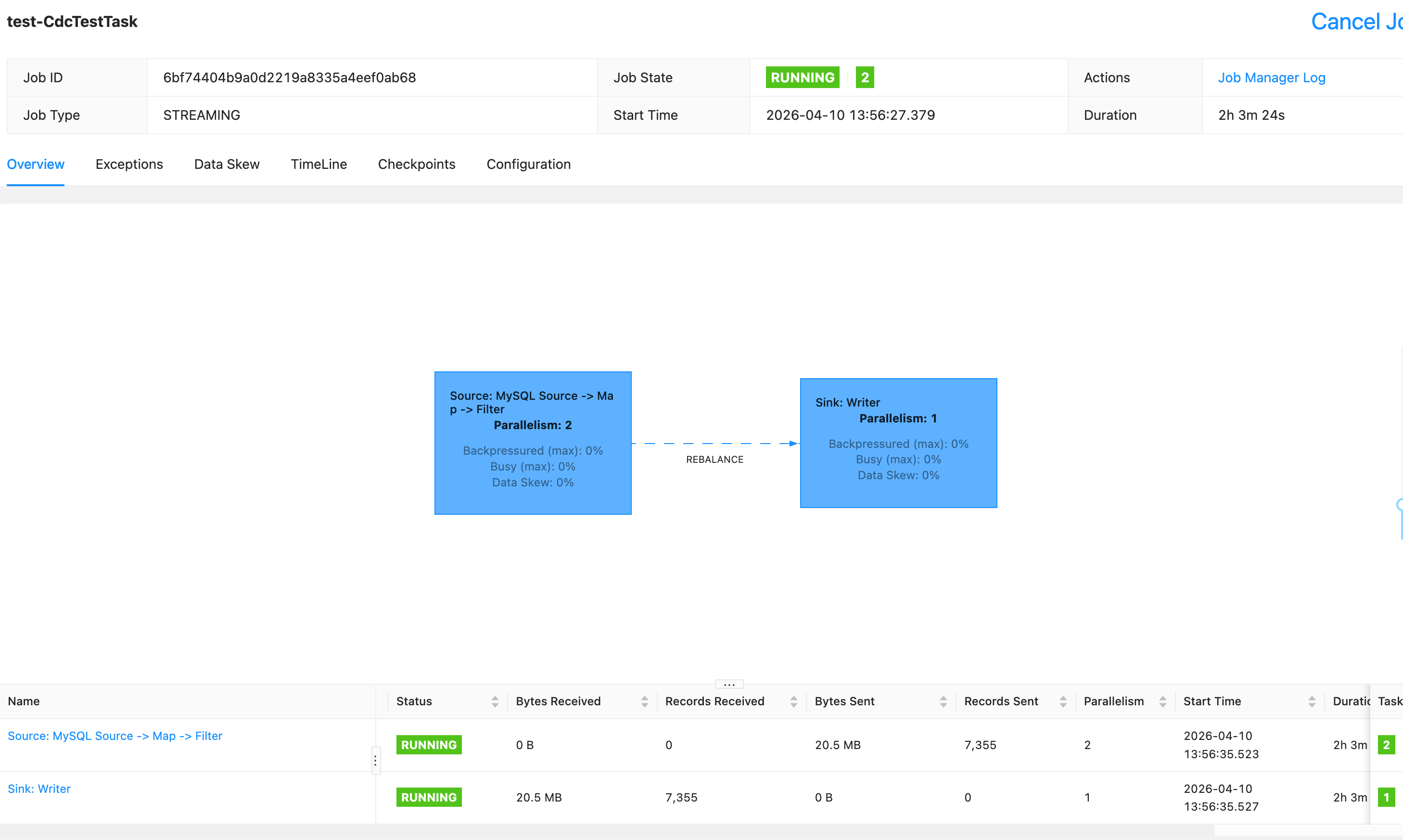
`
总结
使用Streaming开发流程自主控制性比较大,主要就是环境中ar冲突的问题。实践为王,光想为寇。边做边记,下次直接复制粘贴就可以了,千里之行始于足下。