一、AI提示词编写技巧
1.CO-STAR结构化框架
| 模块 | 说明 | 示例 |
|---|---|---|
| Context | 任务背景与上下文 | 你是电商客服,需解答⽤⼾关于iPhone17的咨询,知识库包含最 新价格和库存" |
| Objective | 核心目标 | "准确回答价格、发货时间,推荐适配配件" |
| Steps | 执行步骤 | "1.识别⽤⼾问题类型;2.检索知识库;3.⽤亲切语⽓整理回复" |
| Tone | 语言风格 | "⼝语化,避免专业术语,使⽤'亲~''呢'等语⽓词" |
| Audience | 目标用户 | 20-35岁年轻消费者,对价格敏感,关注性价⽐" |
| Response | 输出格式 | "价格:XXX元\n库存:XXX件\n推荐配件:XXX(链接)" |
2.少样本提⽰/多⽰例提⽰
核⼼思想:你不是在给它下指令,⽽是在"教"它你想要的格式、⻛格和逻辑。
适⽤场景:格式固定、⻛格独特、逻辑复杂的任务,如⻛格仿写、数据提取、复杂格式⽣成。
再例如: 优化前(零样本提⽰): 请分析以下客⼾反馈,提取产品名称、情感倾向和具体问题。 反馈:"我刚买的⽿机,才⽤了⼀周左边就没声⾳了,太让⼈失望了。"
优化后(少样本提⽰): 请根据以下⽰例,分析后续的客⼾反馈,并提取产品名称、情感倾向和具体问题。
⽰例1: • 反馈:"笔记本的电池续航太差了,完全达不到宣传的10⼩时,最多就4⼩时。"
• 分析:
◦ 产品名称:笔记本电池
◦ 情感倾向:负⾯
◦ 具体问题:续航远低于宣传
⽰例2: • 反馈:"客服响应很快,⾮常专业地帮我解决了软件激活问题,点赞!"
• 分析:
◦ 产品名称:客服服务
◦ 情感倾向:正⾯ ◦ 具体问题:⽆ 现在请分析这个:
• 反馈:"我刚买的⽿机,才⽤了⼀周左边就没声⾳了,太让⼈失望了。"
3.思维链提⽰
• Few-shot-CoT:少样本思维链
• Zero-shot-CoT:零样本思维链
相⽐于少样本提⽰(Few-shot),少样本思维链(Few-shot-CoT)的不同之处只是在于需要在提⽰样 本中不仅给出问题的答案、还同时需要给出问题推导的过程(即思维链),从⽽让模型学到思维链的 推导过程,并将其应⽤到新的问题中。此技巧主要⽤于解决复杂推理问题,如数学、逻辑或多步骤规划。
核⼼思想:要求AI"展⽰其⼯作过程",⽽不是直接给出最终答案。这模仿了⼈类解决问题时的思考 ⽅式。
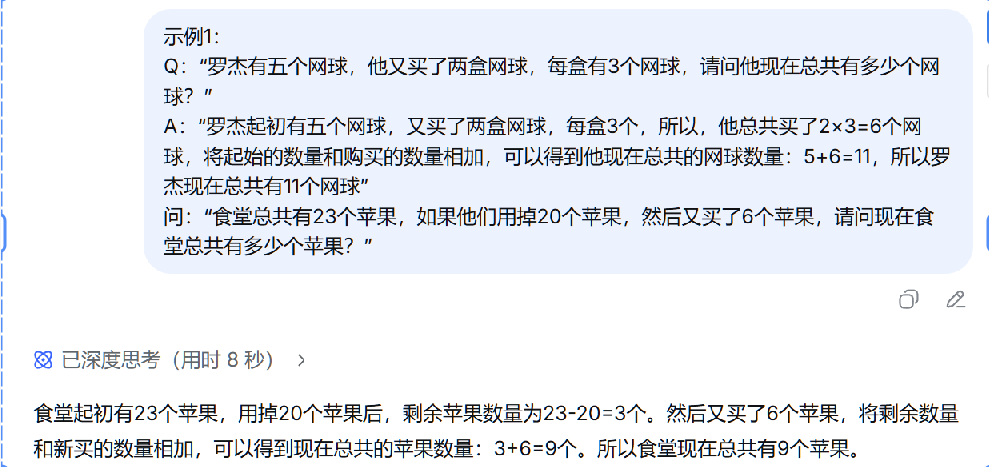
4.⾃动推理与零样本链式思考
零样本思维链(Zero-shot-CoT)这是少样本思维链(Few-shot-CoT)的简化版。只需在提⽰词末尾加上⼀句魔法短语,即可激发AI的推理能⼒。
核⼼思想:通过指令"请⼀步步进⾏推理并得出结论",强制AI在给出答案前先进⾏内部推理。
**适⽤场景:**任何需要⼀点逻辑思考的问题,即使你不太清楚具体步骤。
例如:
罗杰有五个⽹球,他⼜买了两盒⽹球,每盒有3个⽹球,请问他现在总共有多少个⽹球?请⼀步步进⾏推理并得出结论。
5.自我批评与迭代
要求AI在⽣成答案后,从特定⻆度对⾃⼰的答案进⾏审查和优化。
**核⼼思想:**将"⽣成"和"评审"两个步骤分离,利⽤AI的批判性思维来提升内容质量。
**适⽤场景:**代码审查、⽂案优化、论证强化、安全检查。
优化前:写⼀个Python函数,计算列表中的最⼤值。
优化后:
请执⾏以下两个步骤:
步骤⼀:编写代码写⼀个Python函数find_max,⽤于计算⼀个数字列表中的最⼤值。
步骤⼆:⾃我审查与优化
现在,请从代码健壮性和可读性的⻆度,审查你上⾯编写的代码。请回答:
1.如果输⼊是空列表,函数会怎样?如何改进?
2.变量命名和代码结构是否清晰?能否让它更易于理解?
3.请根据你的审查,给出⼀个优化后的最终版本。
总结
在实际应⽤中,这些技巧常常是组合使⽤的。例如,我们可以:
1.使⽤CO-STAR框架设定基本结构和⻆⾊。
2.在框架的"Steps"或"Response"部分,融⼊思维链指令。
3.对于格式复杂的输出,在最后附上少样本⽰例。
4.最后,要求AI进⾏⾃我审查。
二、大语言模型的调用
1.定义模型
python
import os
from langchain_openai import ChatOpenAI
#定义模型 以deepseek为例
model = ChatOpenAI(
model="deepseek-chat",
base_url="https://api.deepseek.com",
api_key=os.environ["DEEPSEEK_API_KEY"]
)2.定义消息
python
from langchain_core.messages import SystemMessage, HumanMessage
#定义消息列表
message = [
#系统消息
SystemMessage(content = "将下面这段英文转换成中文"),
#人为消息
HumanMessage(content = "HELLO WORLD")
]3.把消息传递给大模型进行调用
python
print(model.invoke(message))返回结果:
python
content='你好,世界' additional_kwargs={'refusal': None}
response_metadata={'token_usage': {'completion_tokens': 3,'prompt_tokens': 14,'total_tokens': 17, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 14}, 'model_provider': 'openai', 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_eaab8d114b_prod0820_fp8_kvcache_new_kvcache', 'id': '4d2ae1bc-66c4-49e7-b15a-12bd8a10068a', 'finish_reason': 'stop', 'logprobs': None} id='lc_run--019d72ac-af93-70f1-a458-6830b62d1f4a-0' tool_calls=[] invalid_tool_calls=[] usage_metadata={'input_tokens': 14, 'output_tokens': 3, 'total_tokens': 17, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}}content中的内容就是真正的文本信息
AIMessage :来⾃AI的消息。从聊天模型返回,作为对提⽰(输⼊)的响应。
content :消息的内容。
additional_kwargs :与消息关联的其他有效负载数据。对于来⾃AI的消息,可能包括模型提供程序编码的⼯具调⽤。
response_metadata :响应元数据。例如:响应标头、logprobs、令牌计数、模型名称。 侧重于"响应"本⾝的信息,⽐如这次请求的ID、使⽤的模型版本、以及服务提供商返回 的所有原始元数据。它主要⽤于调试、⽇志记录和获取请求的上下⽂信息。
usage_metadata :消息的使⽤元数据,例如令牌计数。 ▪ 侧重于"资源消耗"的量化信息,即这次请求消耗了多少Token。它主要⽤于成本计算、 监控和预算控制。
4.输出解析
将大模型返回的消息解析成文本字符串
python
result = model.invoke(message)
from langchain_core.output_parsers import StrOutputParser
parser = StrOutputParser()
print(parser.invoke(result))
5.链式执行
把大模型和输出解析器作为一个链进行调用
python
chain = model | parser
print(chain.invoke(message))Runnable接口
Runnable 接⼝是使⽤ LangChain Components(组件)的基础
Runnable 定义了⼀个标准接⼝,允许 Runnable 组件:
Invoked(调⽤): 单个输⼊转换为输出。
Batched(批处理): 多个输⼊被有效地转换为输出。
Streamed(流式传输): 输出在⽣成时进⾏流式传输。
Inspected(检查): 可以访问有关 Runnable 的输⼊、输出和配置的原理图信息。
spected(检查): 可以访问有关 Runnable 的输⼊、输出和配置的原理图信息。
Composed(组合): 可以组合多个 Runnable,以使⽤ LCEL 协同⼯作以创建复杂的管道。
语言模型(model)、输出解析器(StrOutputParser)都是Runnable接口的实例,都是用了invoke的调用能力,所以二者可以组成链式调用
chain = model | parser 相当于 chain = RunnableSequence(first=model, last=parser)
相等于 chain = model.pipe(parser)
LCEL 其实是⼀种编排解决⽅案,它使 LangChain 能够以优化的⽅式处理链的运⾏时执
⾏。任何两个 Runnable 实例都可以"链"在⼀起成序列。上⼀个可运⾏对象的 .invoke() 调⽤
的输出作为输⼊传递给下⼀个可运⾏对象。
三、聊天模型的核心能力
1.定义聊天模型
ChatOpenAI
| 参数名 | 参数描述 |
|---|---|
| model | 要使用的OpeanAI模型的名称 |
| temperature | 采样温度,温度值越高,AI回答越天马行空;温度越低 |
| max_tokens | 要生成的最大令牌数 |
| timeout | 请求超时时间 |
| max_retries | 最大重试次数 |
| openai_api_key/api_key | API密钥,直接传入/从环境变量中读取 |
| base_url | api请求的基本url |
| organization | OpenAI 组织 ID。如果未传⼊,将从 env var OPENAI_ORG_ID 中读取。 |
python
model = ChatOpenAI(
model="deepseek-chat",
#temperature 温度 温度越高,回答的答案越天马行空 温度越低 答案越保守
# 0 完全确定 事实求是,代码生成
# 0.1-0.5 轻微变化 技术文档 写作
#0.5-1 平衡创意 对话、稍微创意的写作
#1-2 高度随机 用于创意性创作、灵感激发
temperature=1,
#最大token数 token衡量文本的基本单位(自然语言处理)
# 对于英文:1个token 约等于 4个字符或0.75个单词
#对于汉字 1个汉字约等于 1.5-2 个token
max_tokens=40,
#请求超时时间
timeout=None,
#最大重试次数
max_retries=2,
#调用ai的前置url
base_url="https://api.deepseek.com",
#output_version= ai的组织IA
api_key=os.environ["DEEPSEEK_API_KEY"],
)init_chat_model
inint_chat_model()参数说明
| 参数名 | 参数描述 |
|---|---|
| model | 要使用的模型名称 |
| model_provider | 模型提供⽅。⽀持的 model_provider 值和相应的集成包有: • openai -> langchain-openai • anthropic -> langchain-anthropic • google_genai -> langchain-google-genai • ollama -> langchain-ollama • deepseek -> langchain-deepseek • ... 如果未指定,将尝试从模型推断 model_provider。 |
| configurable_fields | 设置哪些模型参数是可配置的。若配置为: • None: 没有可配置的字段。 • 'any' :所有字段都是可配置的,类似 api_key 、 base_url 等可 以在运⾏时更改。 • UnionList\[str, Tuplestr, ...]:指定的字段是可配置的。 |
| config_prefix | • 配置为⾮空字符串,则模型将在运⾏时通过查找 config"configurable""{config_prefix}_{param}" 字段 设置配置项 。 • 配置为空字符串,那么模型将可以通过 config"configurable"" {param}" 字段设置配置项 。 |
| temperature | 采样温度,温度值越⾼,AI 回答越天⻢⾏空;温度越低,回答越保守靠谱。 |
| max_tokens | 要生成的最大令牌数 |
| timeout | 请求超时时间 |
| max_retries | 最大重试次数 |
| openai_api_key/api_key | OpenAI API密钥。如果未传入,将从环境变量中读取OPENAI_API_KEY |
| base_url | API请求的基本URL |
1.普通调用
python
from langchain.chat_models import init_chat_model
model = init_chat_model(model="deepseek-chat", model_provider="deepseek")
print(model.invoke("你是谁"))
python
content='你好!我是DeepSeek,由深度求索公司创造的AI助手!😊\n\n我是一个纯文本模型,虽然不支持多模态识别功能,但我有文件上传功能,可以帮你处理图像、txt、pdf、ppt、word、excel等文件,并从中读取文字信息进行分析处理。\n\n我的一些特点:\n- 完全免费使用,没有收费计划\n- 上下文长度达128K,可以处理很长的对话\n- 支持联网搜索(需要你在Web/App中手动点开联网搜索按键)\n- 可以通过官方应用商店下载App使用\n- 知识截止到2024年7月\n\n我很乐意帮助你解答问题、处理文档、进行对话交流等等!有什么我可以帮你的吗?无论是学习、工作还是日常问题,我都很愿意协助你!✨' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 166, 'prompt_tokens': 5, 'total_tokens': 171, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 5}, 'model_provider': 'deepseek', 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_eaab8d114b_prod0820_fp8_kvcache_new_kvcache', 'id': 'c3cccfab-e54f-43be-802c-9ffe239932d6', 'finish_reason': 'stop', 'logprobs': None} id='lc_run--019d7567-38c9-7671-aa80-158e7684224e-0' tool_calls=[] invalid_tool_calls=[] usage_metadata={'input_tokens': 5, 'output_tokens': 166, 'total_tokens': 171, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}}2.创建可配置模型
python
from langchain.chat_models import init_chat_model
from langchain_core.messages import SystemMessage, HumanMessage
model = init_chat_model(temperature=0)
message = [
SystemMessage(content="请补全一段故事"),
HumanMessage(content="我来自__")
]
# 内置支持 配置 model 和 model_provider 其他参数想配置需要提前说明
print(model.invoke(input=message, config={
"configurable": {"model":"deepseek-chat"}
}).content)3.具有默认值的可配置模型
python
from langchain.chat_models import init_chat_model
from langchain_core.messages import SystemMessage, HumanMessage
model = init_chat_model(
temperature=0,
max_tokens=10,
configurable_fields=("max_tokens", "model")
)
message = [
SystemMessage(content="请补全一段故事"),
HumanMessage(content="我来自__")
]
# 内置支持 配置 model 和 model_provider 其他参数想配置需要提前说明
#但是如果 init_chat_model 配置了 configurable_fields 也需要指定 model是可配置的
print(model.invoke(input=message, config={
"configurable": {"model":"deepseek-chat", "max_tokens":30}
}).content)