数组
一维数组
先来看标准的数组定义方式:
go
package main
import "fmt"
func main() {
var nameList [3]string = [3]string{"sxk", "kunkun", "Y_Yao"}
fmt.Println(nameList) // [sxk kunkun Y_Yao]
}数组也可使用简短声明:
go
arr := [3]int{1, 2, 3}
fmt.Println(arr) // [1,2,3]也可以不写长度,让编译器自己判断:(len函数会返回数组的长度)
go
arr1 := [...]int{1, 2, 3}
fmt.Println(arr1) // [1,2,3]
fmt.Println(len(arr1)) //3注意:长度省略的时候一定要初始化,编译器才能自己推断,不初始化会编译报错!!!。
注意:数组不写长度时,方括号里一定要写... 这是为了和切片区分,切片后面会讲。
还可以指定下标初始化,其他未指定的地方,为零值:
go
arr3 := [...]int{1: 8, 5: 8, 9: 8}
fmt.Println(arr3) //[0 8 0 0 0 8 0 0 0 8]
fmt.Println(len(arr3)) //10此时数组长度就是最大下标+1。
二维数组
go
// 二维数组
var matrix [3][3]int
matrix = [3][3]int{
{1, 2, 3},
{4, 5, 6},
{7, 8, 9},
}
fmt.Println(matrix) //[[1 2 3] [4 5 6] [7 8 9]]
// 也可以简写
matrix2 := [2][2]int{{1, 2}, {3, 4}}
fmt.Println(matrix2) //[[1 2] [3 4]]也可以省略行,让编译器自己推断:
go
matrix3 := [...][2]int{{1, 2}, {3, 4}, {5, 6}}
fmt.Println(matrix3) //[[1 2] [3 4] [5 6]]
fmt.Printf("行数:%d\n", len(matrix3)) //行数:3
fmt.Printf("列数:%d\n", len(matrix3[0])) //列数:2注意:二维数组的定义,可以省略行(用...),但一定不能省略列!!!
为什么可以省略行,而不能省略列?下面来深入理解一下:
其实很多语言都有这样的特性,比如c语言的二维数组,也是可以省略行,不能省略列。
主要看这门语言是编译时确定类型 (静态语言),还是运行时确定类型(动态语言)。go和c语言都是编译时确定,像Python/JavaScript等动态语言都是运行时确定。
先来看看,编译时确定类型的语言省略行时是如何推到行的:
go
// 当前合法的语法:
arr1 := [...][3]int{
{1, 2, 3}, // ← 这是一个元素
{4, 5, 6}, // ← 这是另一个元素
}
// 每个 {1, 2, 3} 是一个完整的 [3]int
// 编译器看到的是:有2个 [3]int 元素
// 所以能推断出行数 = 2如上例子,编译器在编译期就知道,arr1是个数组,里面的每个元素都是3int类型,它只需数一下arr1里面有几个3int就知道行数了。
现在设想一下,如果不省略行,省略列。
go
//设想,实际编译会报错
arr2 := [2][...]int{
{1, 2, 3},
{4, 5, 6},
}按理来说,知道行推导列,其实也不难。
首先编译器知道arr2是个数组,有两行,里面每个元素都是...int,...int是个不确定的类型,所以还需要往里推导一下,发现里面有3个元素,进而推导出,arr2是个数组,有2行,里面的每个元素都是3int类型。
从技术的角度上看起来不难实现。
但是实际编译期确定类型的语言(静态语言)有严格的类型系统的约束:
变量在声明时必须确定类型
再回到刚才设想的案例:
首先编译器知道arr2是个数组,有两行,里面每个元素都是...int,...int是个不确定的类型,此时就已经违反类型系统的约束了,直接报错。
静态语言为什么要有这样的约束?
因为编译器是"死脑筋",它没有人类的推理能力,只能在编译时确定一切。
go
// 你写:
var x = 10
// 编译器想:
1. var x = 10
2. 10 是什么?是整数
3. 整数占用多少内存?4字节(32位)或8字节(64位)
4. 记录:x → 地址0x1000~0x1008,类型int
5. 这个地址以后只能存整数
go
// 编译时
var x = 10 // 编译时确定x是int
x = "hello" // 编译错误:不能把字符串赋值给int
// 编译器在编译时就锁定了x的类型如果是动态语言:
python
运行时
x = 10 # 现在x是int
x = "hello" # 现在x变成str
x = 3.14 # 现在x变成float
# Python解释器在运行时处理类型变化切片
✅ 切片是数组的"视图"
✅ 切片本身只包含指针、长度、容量
✅ 没有独立存在的切片,有切片就一定有底层数组
✅ 所有切片操作最终都作用在某个数组上
先来看看标准切片的定义:
go
package main
import "fmt"
func main() {
var slice1 []int = []int{1, 2, 3}
fmt.Println(slice1) //[1 2 3]
//简写
slice2 := []int{1, 2, 3}
fmt.Println(slice2) //[1 2 3]
}可以注意到,切片和数组定义的区别就是切片\[\]里什么也没有,这也是为什么数组省略长度时必须加...用来区分切片的原因。
切片其实可以理解成一个数组的窗口,其实就是数组的一部分,因为它还可以这样定义:
go
var arr [5]int = [5]int{1, 2, 3, 4, 5}
//整个数组的切片
var slice1 []int = arr[:]
//数组前两个元素的切片
var slice2 []int = arr[:2]
//数组后两个元素的切片
var slice3 []int = arr[2:]
//数组中间3个元素的切片
var slice4 []int = arr[1:4] //左闭右开
fmt.Println(slice1) //[1 2 3 4 5]
fmt.Println(slice2) //[1 2]
fmt.Println(slice3) //[3 4 5]
fmt.Println(slice4) //[2 3 4]还可以通过make函数创建:
go
//创建切片,长度为5,容量是10,里面元素默认为零值
slice5 := make([]int, 5, 10)
fmt.Println(slice5) //[0 0 0 0 0]切片实现的底层可以大致理解成如下结构体
go
type sliceHeader struct {
Data unsafe.Pointer // 指向底层数组元素的指针
Len int // 切片长度
Cap int // 切片容量
}与数组不同的是,切片可以扩容,数组的长度是固定的。切片的扩容依赖append函数,且可能会影响原来数组的类型,场景如下:
go
package main
import "fmt"
func main() {
var arr [5]int = [5]int{1, 2, 3, 4, 5}
fmt.Println("初始状态:")
fmt.Printf("arr地址: %p, 值: %v\n", &arr, arr)
// 切片1
slices1 := arr[:2]
fmt.Printf("\n创建切片 slices1 = arr[:2]\n")
fmt.Printf("slices1地址: %p, 值: %v, len=%d, cap=%d\n",
&slices1[0], slices1, len(slices1), cap(slices1))
// 第一次 append
fmt.Printf("\n执行 slices1 = append(slices1, 1)\n")
slices1 = append(slices1, 1)
fmt.Printf("slices1地址: %p, 值: %v, len=%d, cap=%d\n",
&slices1[0], slices1, len(slices1), cap(slices1))
fmt.Printf("arr值: %v (被修改!)\n", arr)
// 第二次 append
fmt.Printf("\n执行 slices1 = append(slices1, 2, 3, 4)\n")
slices1 = append(slices1, 2, 3, 4)
fmt.Printf("slices1地址: %p, 值: %v, len=%d, cap=%d\n",
&slices1[0], slices1, len(slices1), cap(slices1))
fmt.Printf("arr值: %v (不再被引用)\n", arr)
}注意:append函数的返回值必须接收,覆盖旧切片,因为切片是值传递,传递的是切片的副本,返回新切片,需要将新切片赋值给旧切片。
输出如下:
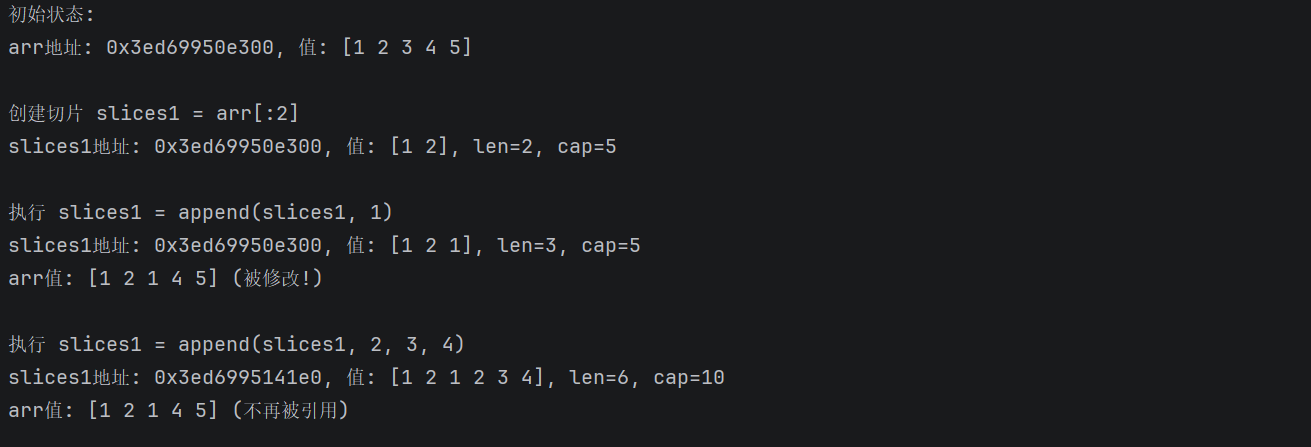
对切片尾插时,如果容量够,会直接在切片后面追加,并且切片指向数组,切片后的那个元素会被覆盖修改。
如果容量不足,编译器会在堆上创建一个新数组,新数组的大小一般是原来的两倍(当数组大小>1024时是1.25倍),再将旧数组数据拷贝到新数组,然后在新数组上创建新的切片返回出来。这时旧数组上就没有切片了。
既然切片可以尾插,那是不是可以尾删?其实确实可以,但是没有函数调用:
尾删的本质是减小切片的长度 ,而不改变底层数组(删除的元素在底层数组中仍然存在,只是不在切片范围内了)。
可以通过重新切片实现:
package main
import "fmt"
func main() {
s := []int{1, 2, 3, 4, 5}
fmt.Println("原切片:", s) // [1 2 3 4 5]
// 尾删:删除最后一个元素
s = s[:len(s)-1] // 长度减1
fmt.Println("尾删后:", s) // [1 2 3 4]
}不改变底层数组*(删除的元素在底层数组中仍然存在,只是不在切片范围内了)。
可以通过重新切片实现:
package main
import "fmt"
func main() {
s := []int{1, 2, 3, 4, 5}
fmt.Println("原切片:", s) // [1 2 3 4 5]
// 尾删:删除最后一个元素
s = s[:len(s)-1] // 长度减1
fmt.Println("尾删后:", s) // [1 2 3 4]
}