
Bun 最近发了一篇很长的审计文章,标题很吓人:在尚未发布的 Rust 版的 Bun 里,有 13,365 个 unsafe。
这个数字很容易被转成一句粗暴的结论:Rust 也不安全,或者 Bun 写得不安全。事实确实如此吗?
unsafe 在 Rust 里更接近一个边界标记:这里有些事情,编译器没法替你证明,只能由程序员或库作者自己保证。真正要看的是这些 unsafe 为什么存在,边界是否清楚,能不能被收拢,以及有没有把不安全的东西伪装成 safe API。
这篇审计的价值,也正在这里。
先确认范围:这不是当前 Bun 版本的事故
这篇文章审计的是 Bun 尚未发布的 Rust port。现在你安装和使用的 Bun,仍然是原来的 Zig 实现。所以它不是「当前 Bun 线上版本突然爆出 13,365 个 unsafe」。更准确的说法是:Bun 在把一部分实现迁移到 Rust 的过程中,公开了一次预发布审计。
这点很重要。
一个已经上线的生产版本被发现大量 soundness bug,和一个迁移中的代码库主动审计 unsafe,性质完全不同。前者是事故,后者更像体检。
当然,体检结果不好也不能假装没事。但至少讨论要落在正确对象上。
unsafe 到底是什么?

Rust 平时强调内存安全。比如借用检查器会阻止悬垂引用、数据竞争、重复释放等问题。但 Rust 也要和现实世界打交道。
现实世界里有 C 库,有操作系统接口,有手写内存布局,有 JIT,有 GC,有跨语言对象生命周期。这些东西很多都超出了 Rust 编译器能证明的范围。于是 Rust 提供了 unsafe。
unsafe 允许你做几类编译器平时不允许的事,比如:
-
• 解引用裸指针。
-
• 调用 C 函数。
-
• 访问或修改可变静态变量。
-
• 实现某些编译器无法验证的 trait。
-
• 告诉编译器「这里的内存布局/生命周期/别名关系我自己保证」。
注意,这里有个关键点:unsafe 是把证明责任从编译器转移给人。所以,一个 Rust 项目里有 unsafe 并不稀奇。很多成熟项目都有。问题在于:这些证明责任有没有被集中管理?有没有写成清楚的 API 契约?调用者是否会在不知情的情况下踩进去?
这比单纯数 unsafe 更重要。
原文里有几个数字可以帮助我们冷静下来:
-
• 10,575 个匹配项包含声明,不全是执行代码。
-
• 3.1% 和性能优化相关。
-
• 约 233 个只是注释或文档里的文本匹配。
也就是说,13,365 是一个入口,不是判决书。
Bun 的 unsafe 主要从哪里来?
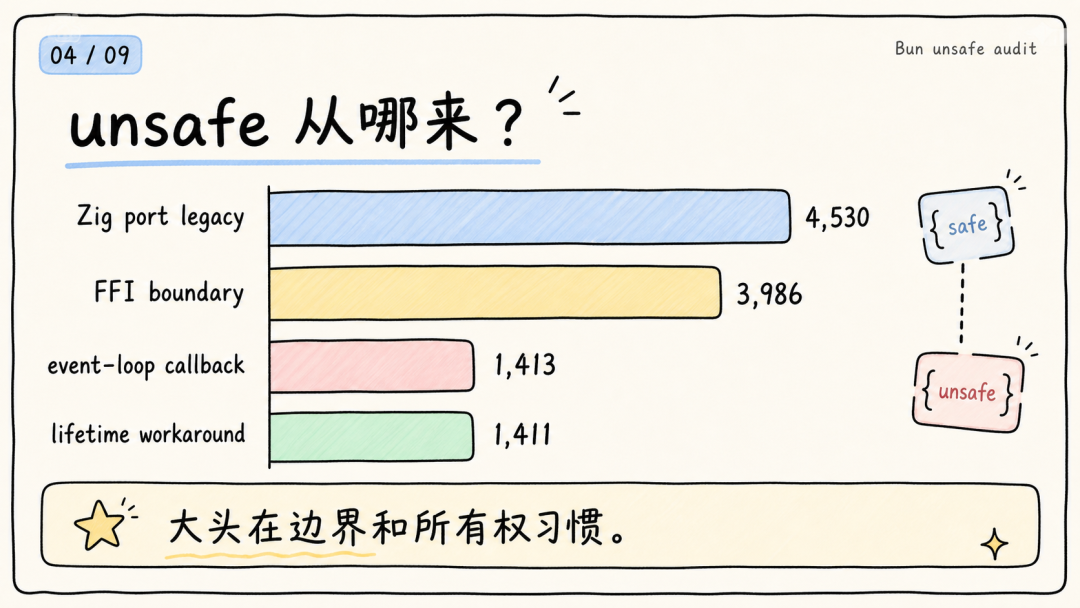
原文把这些 unsafe 的来源做了分类。最大的几块是:
-
• Zig port legacy:4,530
-
• FFI boundary:3,986
-
• event-loop callback:1,413
-
• lifetime workaround:1,411
这里可以拆开看。
第一类是迁移遗留。Bun 原来主要用 Zig 实现。Zig 和 Rust 对内存、别名、生命周期的表达方式不一样。把一套原来在 Zig 里成立的写法搬到 Rust 时,很多地方会先落成裸指针、手工生命周期、手工状态机。这在迁移早期很常见。
第二类是 FFI,也就是 Rust 和 C/C 的边界。Bun 要和 JavaScriptCore、uWebSockets、uSockets、libuv、BoringSSL、c-ares、zlib 等组件打交道。Rust 编译器不知道这些 C/C 函数内部做什么,也没法验证它们的指针和生命周期要求。所以 FFI 边界天然会产生 unsafe。
第三类是事件循环和回调。运行时系统经常会把一个对象指针交给 C 库,等事件发生时再由 C 回调回来。这个过程中,对象还活着吗?类型还是原来的类型吗?回调过程中会不会重入 JS,又改掉同一个对象?这些问题都不是一个普通函数调用能解释清楚的。
第四类是生命周期 workaround。Rust 的生命周期系统很强,但它也要求你把所有权关系说清楚。有些运行时对象、GC 对象、跨语言对象,本来就很难直接用普通借用表达,只能先用较底层的形式绕过去。
所以 Bun 的 unsafe 大头,主要是边界、迁移和所有权表达。
横向比较要看代码形态
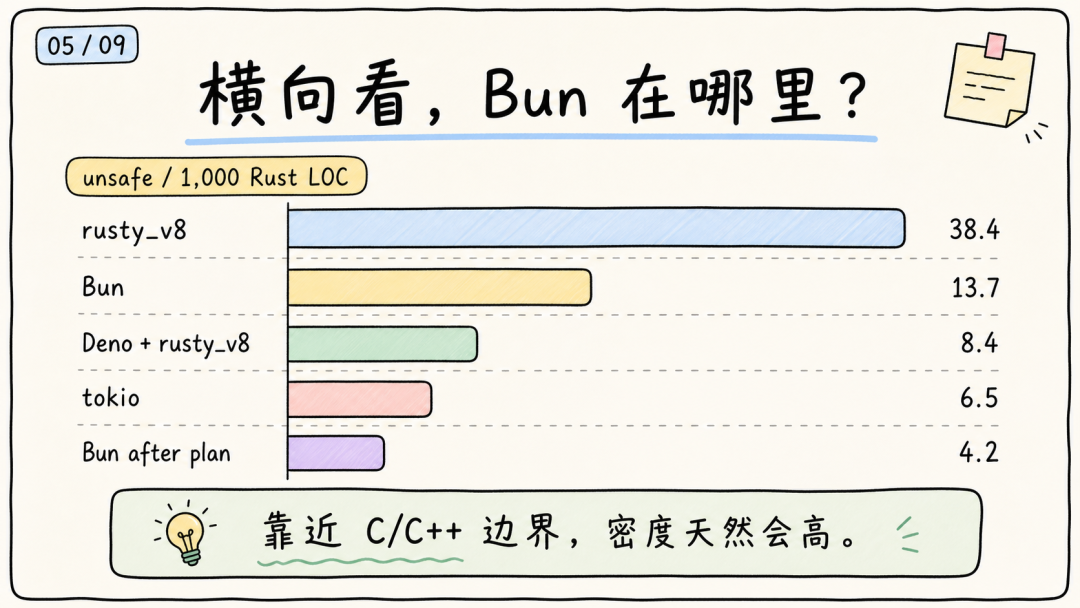
原文也给了一个横向比较:每 1,000 行 Rust 代码里有多少个 unsafe 点。
大致数字是:
-
• rusty_v8:38.4
-
• Bun:13.7
-
• Deno + rusty_v8:8.4
-
• tokio:6.5
-
• Bun after plan:4.2
这个比较有参考价值,但不能机械解读成排行榜。
rusty_v8 是 Deno 的 V8 绑定 crate。它本来就站在 Rust 和 C++ 引擎之间,unsafe 密度高并不奇怪。
tokio 是异步运行时,它也接触操作系统接口,但它和 Bun 这种「运行时 + JS 引擎绑定 + 网络库 + 压缩库 + 加密库 + 文件系统适配」的形态不一样。
所以这个对比更应该用来理解项目结构。一个靠近 C/C++ 边界的 Rust 项目,unsafe 密度天然会高一些。真正值得看的是:这些 unsafe 是散落在业务逻辑里,还是被收进少数清楚的模块里。
原文给出的目标是,经过改造后,Bun 大约会剩下 4,000 个左右 unsafe 点。这个目标是「把 unsafe 放回边界」。
比 unsafe 数量更严重的,是 safe API 的 soundness 问题
如果只关心 unsafe 数量,很容易错过真正危险的部分。
Rust 里有一个重要边界:调用 safe API 的人,默认不需要自己证明内存安全。库作者可以在内部使用 unsafe,但必须保证暴露出去的 safe API 是 sound 的。
换句话说,unsafe 藏在库内部可以接受;不安全的行为从 safe API 泄漏出来,就比较严重。
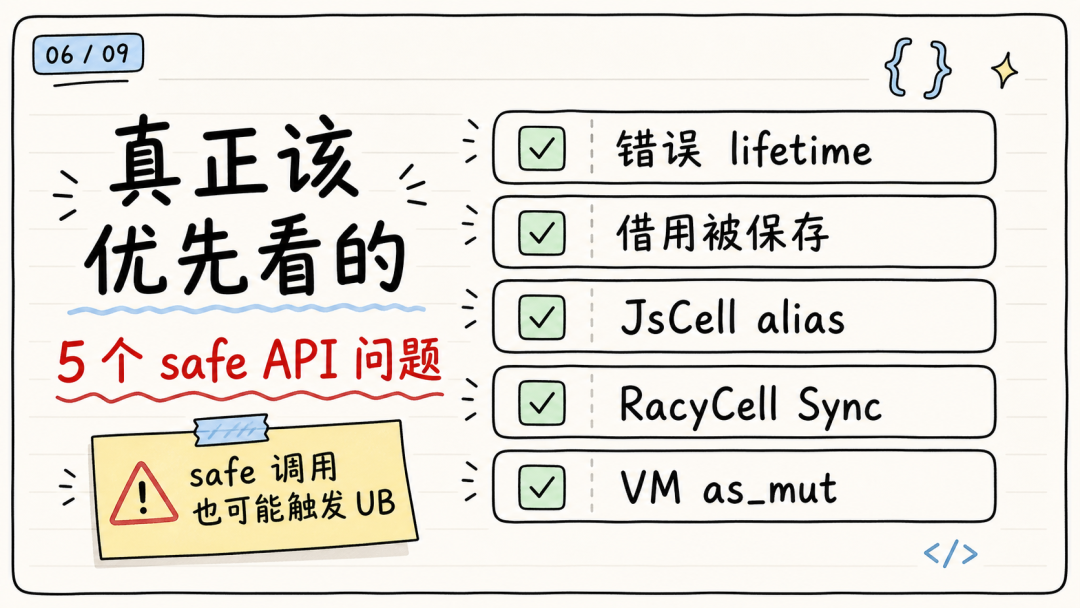
原文列出了 5 个手工确认的 safe API soundness 问题:
-
•
picohttp::Header::name()/value()的 lifetime 问题。 -
•
ArrayBuffer::from_bytes(bytes: &mut [u8], ..)把借用保存成 JS 可见对象。 -
•
JsCell::get()和with_mut()/set()/replace()之间可能制造别名问题。 -
•
RacyCell<T>的无条件Sync。 -
•
VirtualMachine::as_mut(&self) -> &mut VirtualMachine这类 safe 的&self -> &mut逃逸。
这些问题的共同点是:调用者可能只写 safe Rust,却触发本不该发生的未定义行为。这比「某个 FFI 调用点写了 unsafe」更值得优先修。
因为 FFI 的 unsafe 至少在告诉你:这里有边界。safe API soundness 问题则是边界消失了,调用者不知道自己已经站在危险区域里。
降 unsafe,不是把关键字藏起来
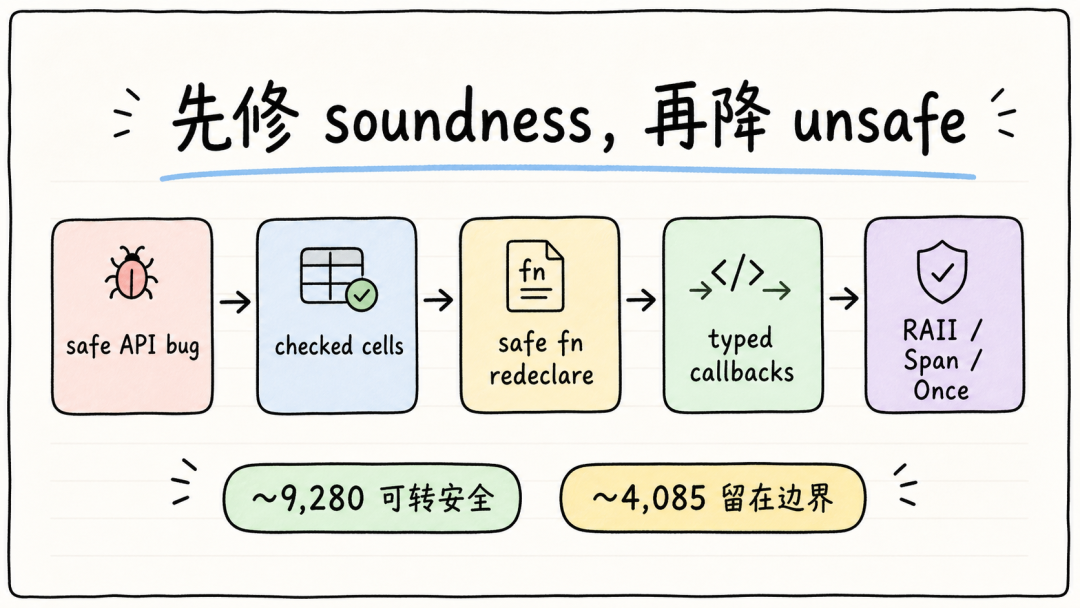
原文给了一个改造路线。它大致分成几类:
第一,先修 safe API soundness 问题。这个动作未必减少 unsafe 数量,但优先级最高。
第二,把一部分裸指针状态机改成 checked cells。比如 Copy 标量字段,可以用 Cell<T> 这类模式表达内部可变性。短生命周期的非 Copy 借用,可以用带检查的 cell 缩小危险窗口。
第三,把一部分纯 C 函数重新声明成 safe fn。这里的前提是函数的安全条件能被参数类型表达出来。比如把裸指针换成引用、slice、拥有 RAII 的 handle。这样调用点就不需要每次都写 unsafe。
第四,把 callback、userdata、引用计数、未初始化 buffer、C span 等模式封装起来。比如 typed callback registration、RAII handle、Span<T>、Once<T>。
这些动作的共同目标,是把原来散落在调用点的证明,搬到类型和 API 边界里。但这里也有个容易误解的地方:减少 unsafe 数量,不等于安全性自动提高。如果只是把 unsafe 包进一个 safe 函数,函数内部并没有真正维护好契约,那只是把风险藏起来。更好的做法是让 wrapper 自己承担并验证契约,让调用者不能轻易传错东西。
好的 unsafe 封装,应该让调用者少做证明,而不是让证明消失。
这篇审计真正难得的地方,是可复查
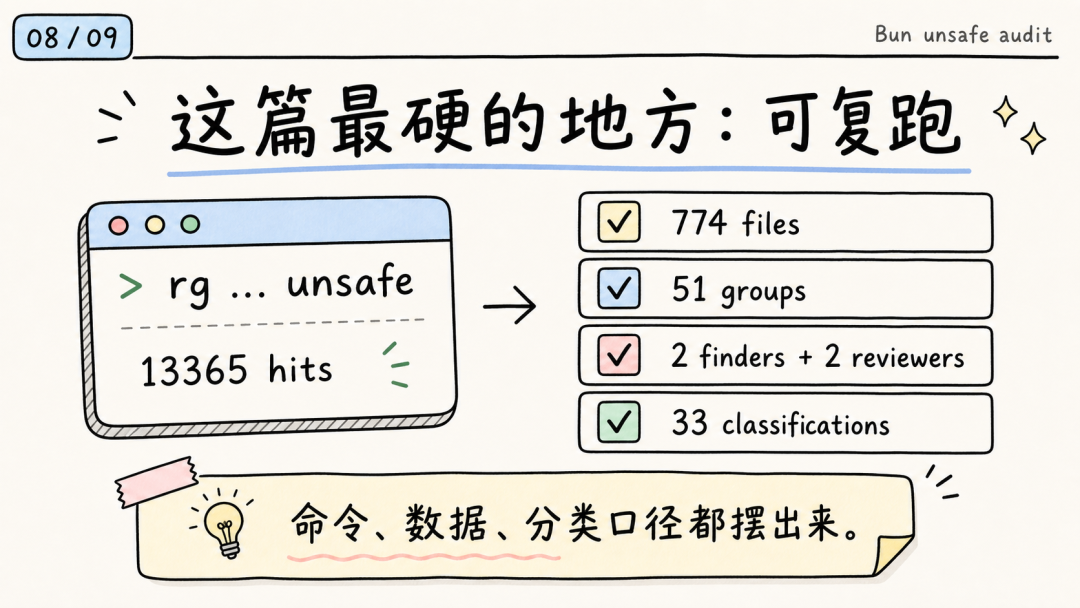
这篇文章还有一个值得注意的地方:它把方法公开了。
原文给了 ground truth 的命令:
go
rg -o -e 'unsafe \{' -e 'unsafe fn' -e 'unsafe extern' -e 'unsafe impl' -e 'unsafe trait' --type rust -g '!vendor/*' src/它还说明了审计口径:
-
• 774 个包含 unsafe 的文件。
-
• 51 个 subsystem groups。
-
• 两个 independent finders 加两个 adversarial reviewers。
-
• 33 个 classification groups。
-
• 每个 disagreement 都做了 adjudication。
这不代表它的每个分类都绝对正确。原文自己也承认,有些分类的一致性更低,比如 parent pointer liveness 这类问题就很难判断。但它至少把讨论变成了可以复查的东西。
你可以不同意某个分类,也可以去看对应 file:line。你可以质疑某个 wrapper 是否真的 sound,也可以检查它的前置条件有没有被类型表达出来。
技术讨论最怕的不是结论错,而是结论没法检查。
我怎么看这件事
一个系统级项目、运行时项目、跨语言绑定项目,不可能完全没有 unsafe。强行追求零 unsafe,很多时候只是把事情推给别的语言、别的库,或者推到更隐蔽的地方。
更专业的目标是:
-
• 哪些 unsafe 必须存在,承认它。
-
• 哪些 unsafe 可以收拢,重构它。
-
• 哪些 safe API 其实不 sound,优先修它。
-
• 哪些证明只存在于注释里,尽量搬进类型、生命周期、RAII 和 wrapper。
Bun 这次审计的意义,不是证明它已经安全,也不是证明它不安全。
它更像是一次迁移中的公开体检:问题很多,但分类清楚;风险不小,但修复路线也写出来了。
如果只看 13,365,会得到一个很热闹但没什么用的结论。
如果顺着它的分类往下看,反而能学到 Rust 项目里真正重要的一件事:
unsafe 不是洪水猛兽。关键是边界要清楚,证明要集中,safe API 不能撒谎。