链式法则,就是复合函数求导的规则 ,也是 PyTorch 自动求导的数学本质 。
我用最直白、一步一步的方式讲清楚,看完你就懂反向传播到底在算什么。
一、什么是链式法则?
一句话:
对复合函数求导,等于把每一步的导数乘起来。
公式:

二、最简单例子:一步链式

非常简单。
三、经典神经网络式例子(真正理解反向传播)
我们用一个真实的"计算图"结构:

这就是链式法则在神经网络里的真实用法 。
反向传播本质就是:
从损失 L 出发,沿着计算图往回走,一路把局部导数乘起来。
四、再复杂一点:多层链式(真正像神经网络)

每一步都是局部导数相乘 。
这就是深度网络反向传播的全部数学原理。
五、链式法则 + 计算图 = PyTorch 自动求导
PyTorch 做的事情非常简单:
- 前向传播:
构建计算图,记录每一步操作 - 反向传播:
从 loss 开始,沿着计算图反向遍历
对每个算子,算出局部导数
然后一路相乘 (链式法则)
最终得到参数的梯度
所以:
自动求导 = 计算图 + 链式法则
六、一句话总结
链式法则就是:
复合函数求导 = 路径上所有局部偏导数相乘。
反向传播就是:
从损失往输入反向走,用链式法则把梯度一路乘回参数。
下面给你画清晰的计算图 + 梯度反向流动(链式法则),用文字+结构画出来,一眼看懂。
1. 我们的模型
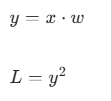
2. 前向计算图(数据流向:左 → 右)
x (1.0)
\
\ *
\
y = x*w (2.0) → L = y² (4.0)
/
/
w (2.0)这就是计算图。
3. 反向梯度流(链式法则:右 → 左)
梯度从损失 L 往回传,每一步都是乘上局部导数。
x
↑
dy/dw = x
↑
y ←─────────── L
dy/dy=1 dL/dy=2y
(这里是 4)完整链式路径:
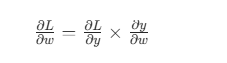
4. 梯度流动画(最直观)
正向:
x(1) ──[×w]──> y(2) ──[²]──> L(4)
反向(链式相乘):
L ←──[dL/dy=2y=4]── y ←──[dy/dw=x=1]── w
所以:
dL/dw = 4 × 1 = 45. 再画一个带偏置 b 的通用版(神经网络标准结构)
正向:
x
\
\ * w
\
+ → y → L
/
b /
反向链式:
dL/dw = dL/dy * dy/dw = dL/dy * x
dL/db = dL/dy * dy/db = dL/dy * 1一句话记住
反向传播 = 沿着计算图往回走,一路用链式法则把梯度乘起来。