文章目录
- [Vue Diff 算法原理深度解析](#Vue Diff 算法原理深度解析)
-
- [1. Diff 算法的核心策略](#1. Diff 算法的核心策略)
- [2. 核心执行流程:patch 函数](#2. 核心执行流程:patch 函数)
- [3. Vue 2 vs Vue 3 算法实现](#3. Vue 2 vs Vue 3 算法实现)
-
- [Vue 2:双端 Diff (Double-Ended Diff)](#Vue 2:双端 Diff (Double-Ended Diff))
- [Vue 3:快速 Diff (Quick Diff)](#Vue 3:快速 Diff (Quick Diff))
- [4. 为什么 key 很重要?](#4. 为什么 key 很重要?)
- [Vue 3:快速 Diff (Quick Diff) 详解](#Vue 3:快速 Diff (Quick Diff) 详解)
-
- [1. 预处理前置节点](#1. 预处理前置节点)
- [2. 预处理后置节点](#2. 预处理后置节点)
- [3. 处理仅有新增节点情况](#3. 处理仅有新增节点情况)
- [4. 处理仅有卸载节点情况](#4. 处理仅有卸载节点情况)
- [5. 处理混合复杂情况(新增、卸载、移动)](#5. 处理混合复杂情况(新增、卸载、移动))
-
- [5.1 各个变量的作用](#5.1 各个变量的作用)
-
- [当前最远位置 (lastIndex / maxNewIndexSoFar):](#当前最远位置 (lastIndex / maxNewIndexSoFar):)
- [移动标识 (moved):](#移动标识 (moved):)
- [新节点位置映射表 (keyToNewIndexMap):](#新节点位置映射表 (keyToNewIndexMap):)
- [新旧节点位置映射表 (source / newIndexToOldIndexMap):](#新旧节点位置映射表 (source / newIndexToOldIndexMap):)
- [5.2 Diff 算法位置处理的详细流程](#5.2 Diff 算法位置处理的详细流程)
- 最长递增子序列算法
-
- [1. 定义](#1. 定义)
- [2. 示例](#2. 示例)
- [3. 核心算法实现](#3. 核心算法实现)
-
- 方法一:动态规划 (Dynamic Programming)
- [方法二:贪心 + 二分查找 (Greedy + Binary Search)](#方法二:贪心 + 二分查找 (Greedy + Binary Search))
- [4 vue3 diff 算法中的最长递增子序列](#4 vue3 diff 算法中的最长递增子序列)
-
- [4.1 二分查找 + 贪心算法 存在的问题](#4.1 二分查找 + 贪心算法 存在的问题)
- [4.2 回溯修正](#4.2 回溯修正)
- [Vue 2 双端 Diff 算法详解](#Vue 2 双端 Diff 算法详解)
-
- [1. 核心指针 (Four Pointers)](#1. 核心指针 (Four Pointers))
- [2. 五步查找策略](#2. 五步查找策略)
-
- [① 头-头匹配 (oldStart vs newStart)](#① 头-头匹配 (oldStart vs newStart))
- [② 尾-尾匹配 (oldEnd vs newEnd)](#② 尾-尾匹配 (oldEnd vs newEnd))
- [③ 旧头-新尾匹配 (oldStart vs newEnd)](#③ 旧头-新尾匹配 (oldStart vs newEnd))
- [④ 旧尾-新头匹配 (oldEnd vs newStart)](#④ 旧尾-新头匹配 (oldEnd vs newStart))
- [⑤ 乱序匹配 (Key Map Lookup)](#⑤ 乱序匹配 (Key Map Lookup))
- [3. 循环结束后的处理](#3. 循环结束后的处理)
- [4. 为什么双端 Diff 更快?](#4. 为什么双端 Diff 更快?)
Vue Diff 算法原理深度解析
Diff 算法是 Vue 中虚拟 DOM(Virtual DOM)渲染器的核心。其目标是:用最小的性能代价,找出新旧虚拟节点(VNode)之间的差异,并高效地更新真实 DOM。
1. Diff 算法的核心策略
为了将 O ( n 3 ) O(n^3) O(n3) 的通用树对比算法优化至 O ( n ) O(n) O(n),Vue 遵循了以下三个前提:
- 同层比较:只对同一层级的节点进行比较,不跨层级。
- 类型识别 :如果两个节点的
tag不同(如<div>变为<p>),直接销毁旧节点并创建新节点。 - Key 值复用 :通过
key属性唯一标识节点,尽量通过移动而非销毁来复用现有 DOM。
2. 核心执行流程:patch 函数
在源码中,Diff 过程主要由 patch 函数执行,其逻辑如下:
- 判断是否为相同节点 :
比较key和tag。如果不同,直接替换。 - 更新属性 (Props/Attrs) :
如果节点相同,对比并更新 Class、Style、事件等属性。 - 对比子节点 (Children) :
- 旧有新无:卸载(Unmount)旧子节点。
- 旧无新有:挂载(Mount)新子节点。
- 新旧都有 :触发核心 Diff 算法(双端比较 或 最长递增子序列)。
3. Vue 2 vs Vue 3 算法实现
Vue 2:双端 Diff (Double-Ended Diff)
Vue 2 使用四个指针分别指向新旧列表的头尾,进行四种假设性匹配:
- 头头 (oldStart vs newStart)
- 尾尾 (oldEnd vs newEnd)
- 头尾 (oldStart vs newEnd):命中则涉及 DOM 移动。
- 尾头 (oldEnd vs newStart):命中则涉及 DOM 移动。
- 乱序匹配 :若四次都没中,建立
key的映射表进行查找。
Vue 3:快速 Diff (Quick Diff)
Vue 3 借鉴了 inferno 算法,利用了 静态提升 和 预处理:
- 从头预处理:从前向后比对,直到遇到不同节点。
- 从尾预处理:从后向前比对,直到遇到不同节点。
- 处理未知序列 :
- 对于剩余的乱序节点,构建一个最长递增子序列 (LIS)。
- 子序列中的节点保持不动,只移动不在序列中的节点。
- 这是目前最优的 DOM 移动方案,减少了真实 DOM 的操作次数。
4. 为什么 key 很重要?
- 性能提升 :
key是节点的身份标识。有了它,算法能精准匹配新旧节点,将"销毁-再创建"变成"低开销的移动"。 - 状态保持 :在处理带有状态的组件(如 Input 或切换动画)时,没有
key或使用index作为key可能会导致 UI 状态错乱。
注意 :避免使用
index作为key。当列表发生排序、插入、删除操作时,index的变化会导致 Vue 误判节点,产生不必要的 DOM 更新。
Vue 3:快速 Diff (Quick Diff) 详解
Vue 3 的快速 Diff 算法(Quick Diff)相比 Vue 2 的双端 Diff,最大的改进在于它通过预处理尽可能减少了需要参与复杂比对的节点数量,并利用数学上的最长递增子序列来计算出最少的 DOM 移动次数。
以下是该算法的详细分步拆解:
【【前端面试】Vue3 DOM Diff】https://www.bilibili.com/video/BV1Xp4y1V7TP?vd_source=517f82007a154270cea64ff97066d805
参考的哔站老师教学视频 【前端面试】Vue3 DOM Diff
1. 预处理前置节点
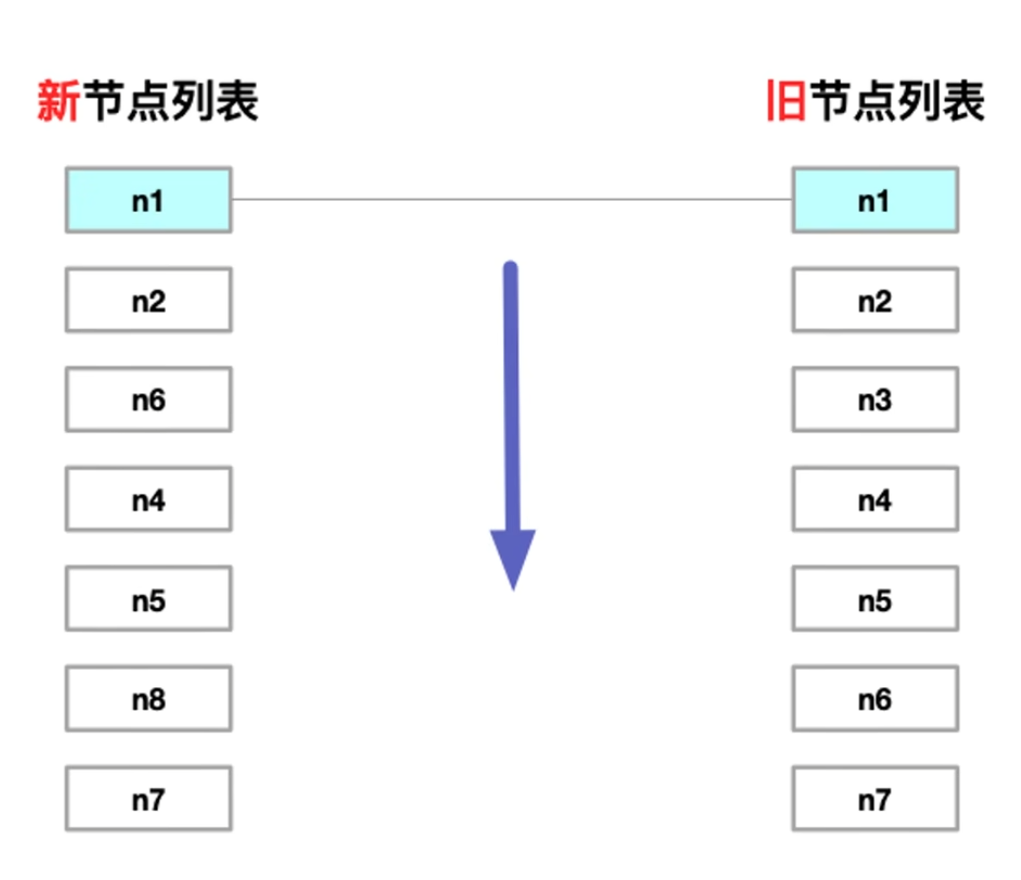
- 从前到后 对比两列 新旧 节点
- 从头部开始,如果
key和type相同,则直接patch(更新属性),直到遇到不同的节点为止。
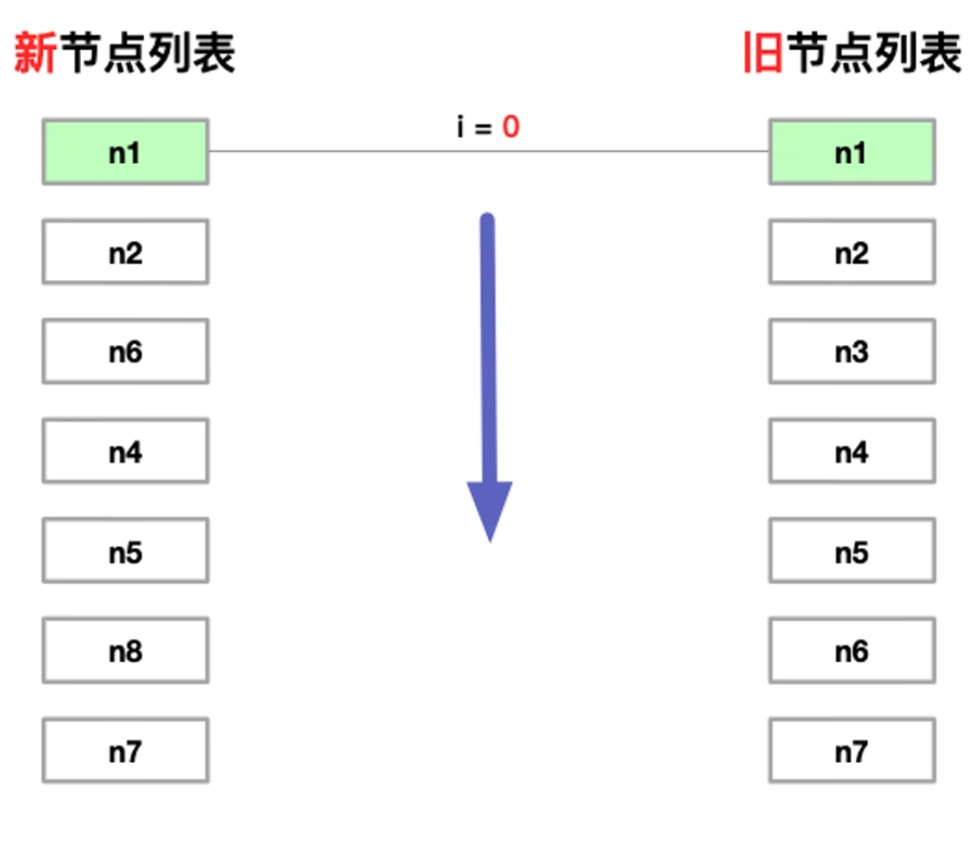
- 定义 i 变量:记录当前前置索引值
- i == 0 ,新旧节点都为 n1,直接更新节点
- i == 1,新旧节点都为 n2,直接更新节点
- i == 2,新旧节不一样,停在这里记录 i = 2
2. 预处理后置节点
- 从后到前 对比两列 新旧 节点
- 逻辑同预处理前置节点
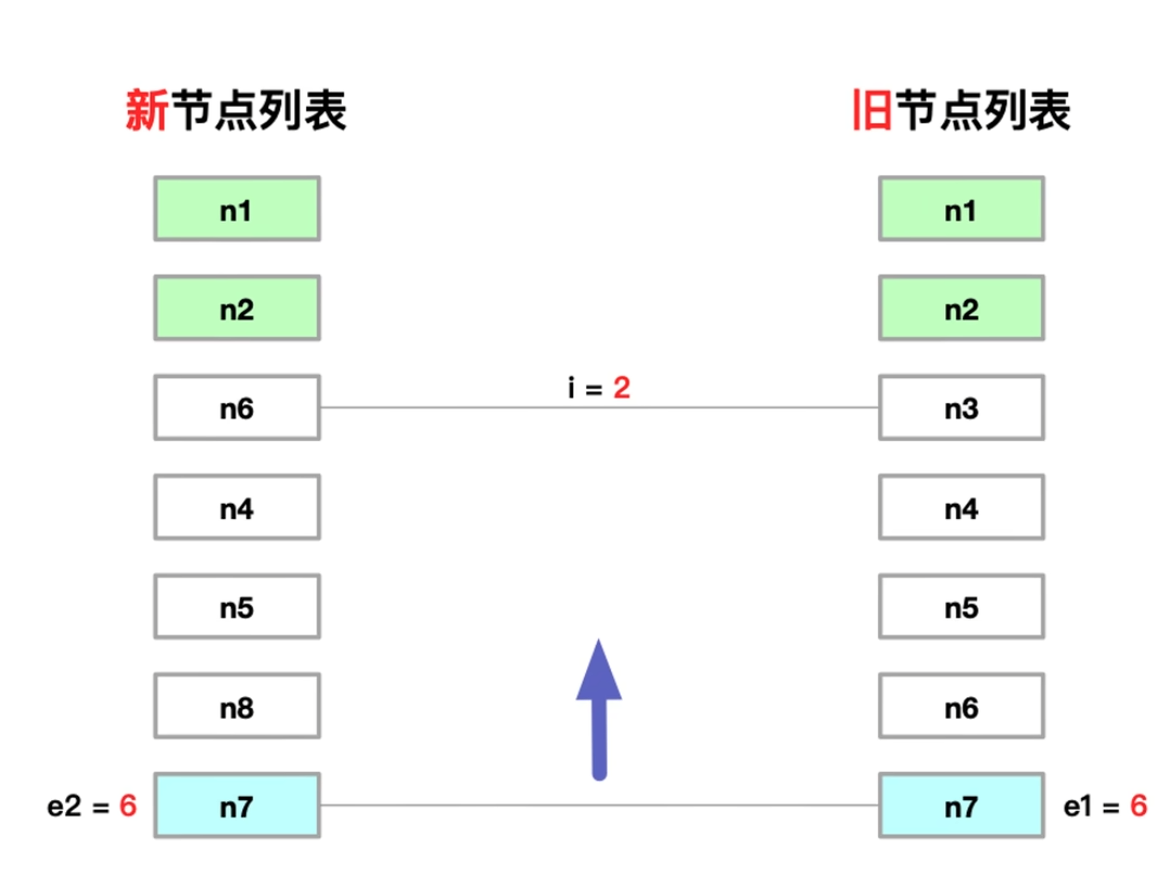
- 定义
e1为旧节点列表的 后置索引值 - 定义
e2为新节点列表的 后置索引值
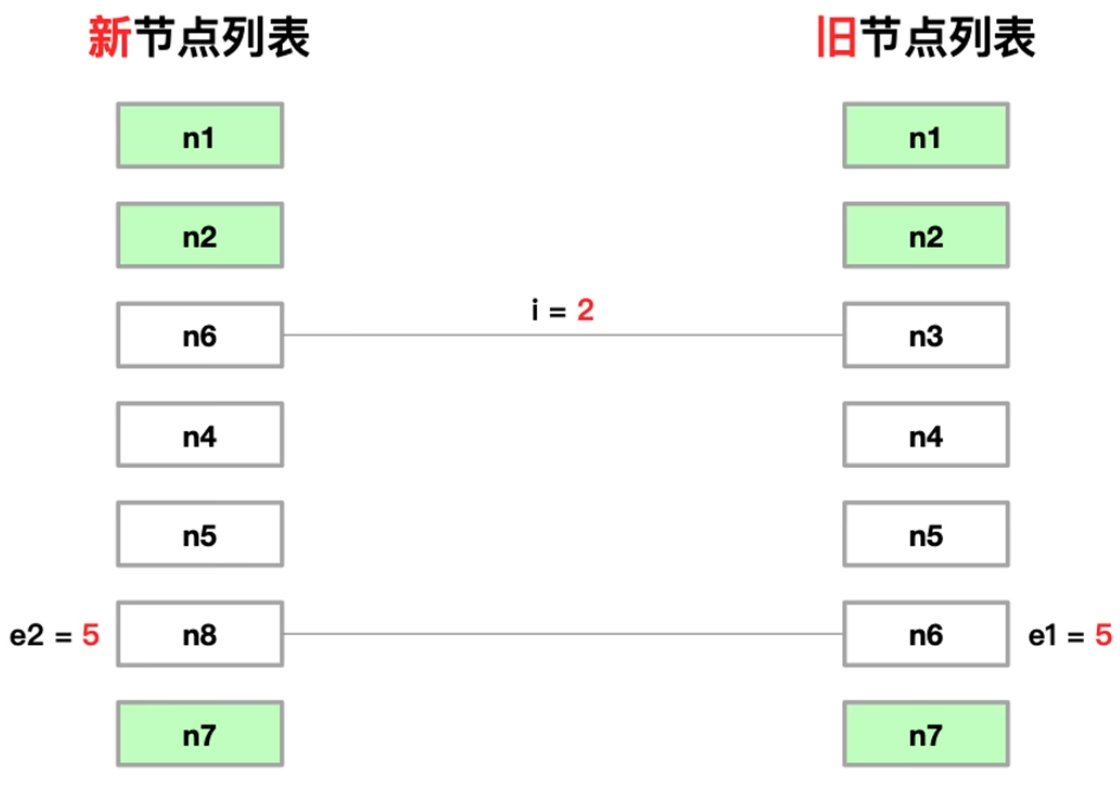
- e1 ==6、e2 == 6,新旧节点一样,直接更新
- e1 ==6、e2 == 5,新旧节点不一样。记录下 e1 e2 的位置
3. 处理仅有新增节点情况
- 假设只有新增节点的情况,新旧节点列表如下图
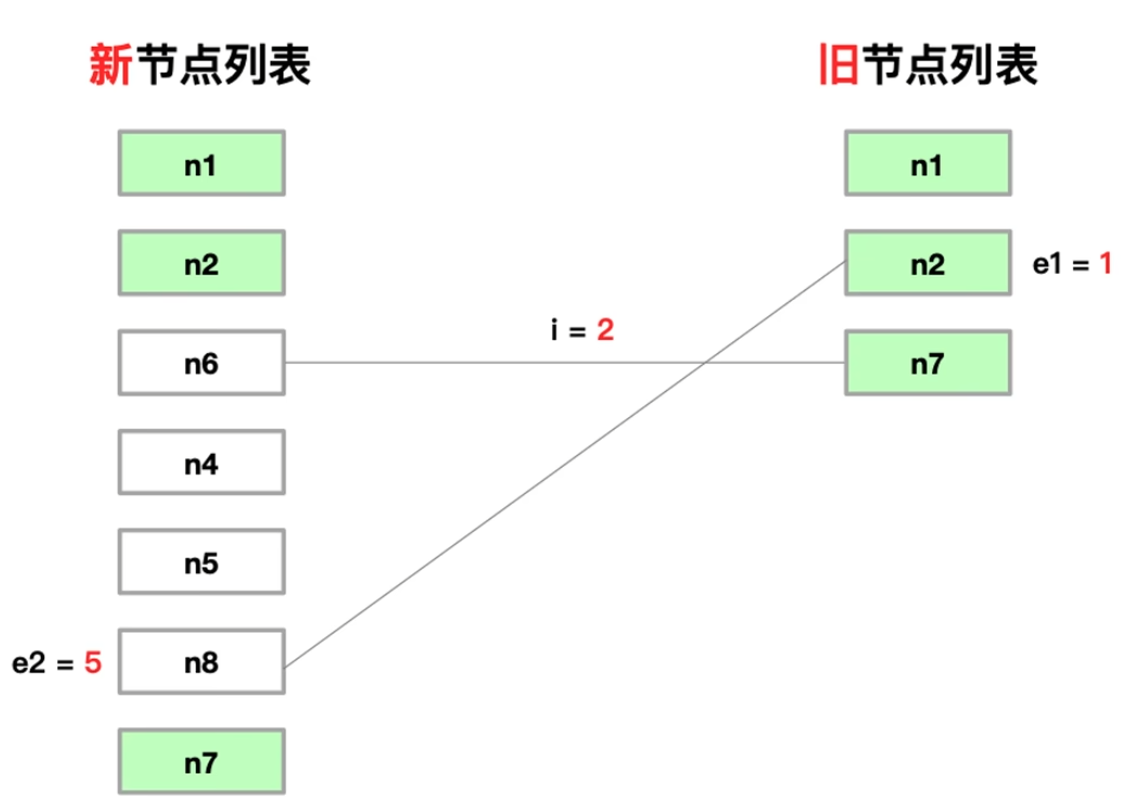
- 仅有新增节点: i > e1 && i <= e2
- i :前置索引值(节点不一样的那个记录)
- e1:旧节点后置索引值(节点不一样的那个记录)
- e2:新节点后置索引值(节点不一样的那个记录)
- 只需要将新增节点更新到页面上
4. 处理仅有卸载节点情况
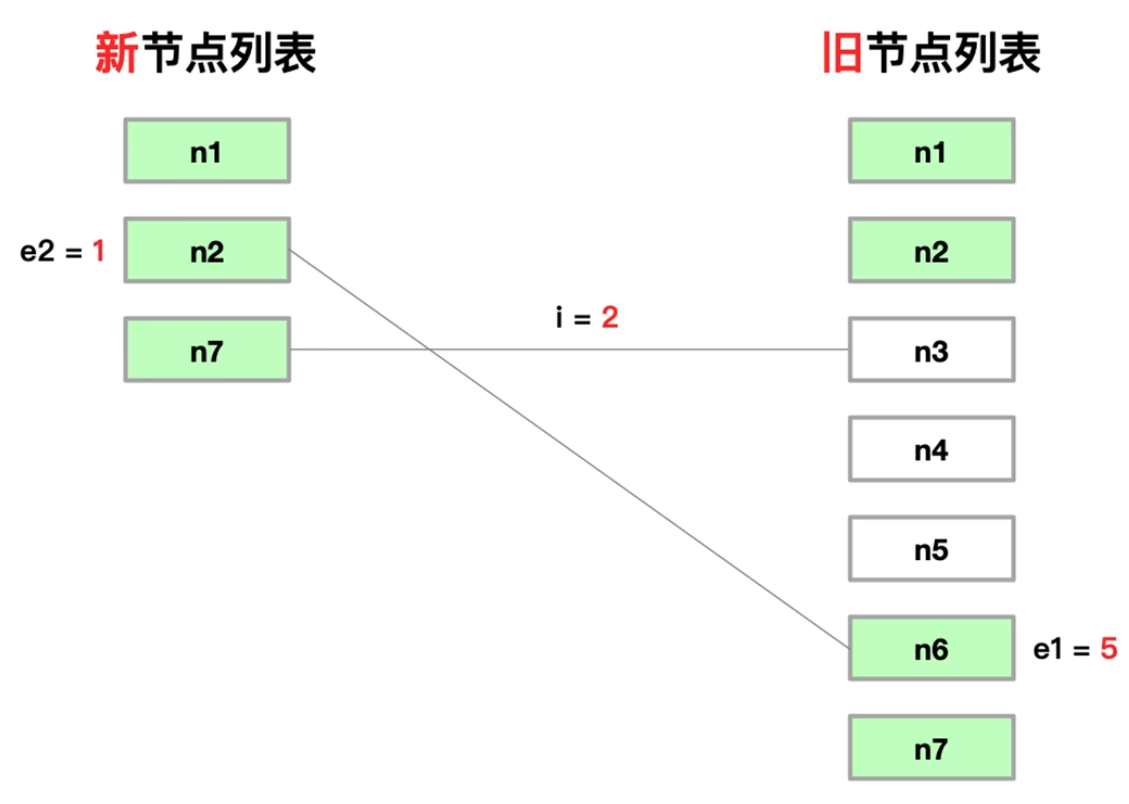
- 仅有删除节点: i > e2 && i <= e1
5. 处理混合复杂情况(新增、卸载、移动)
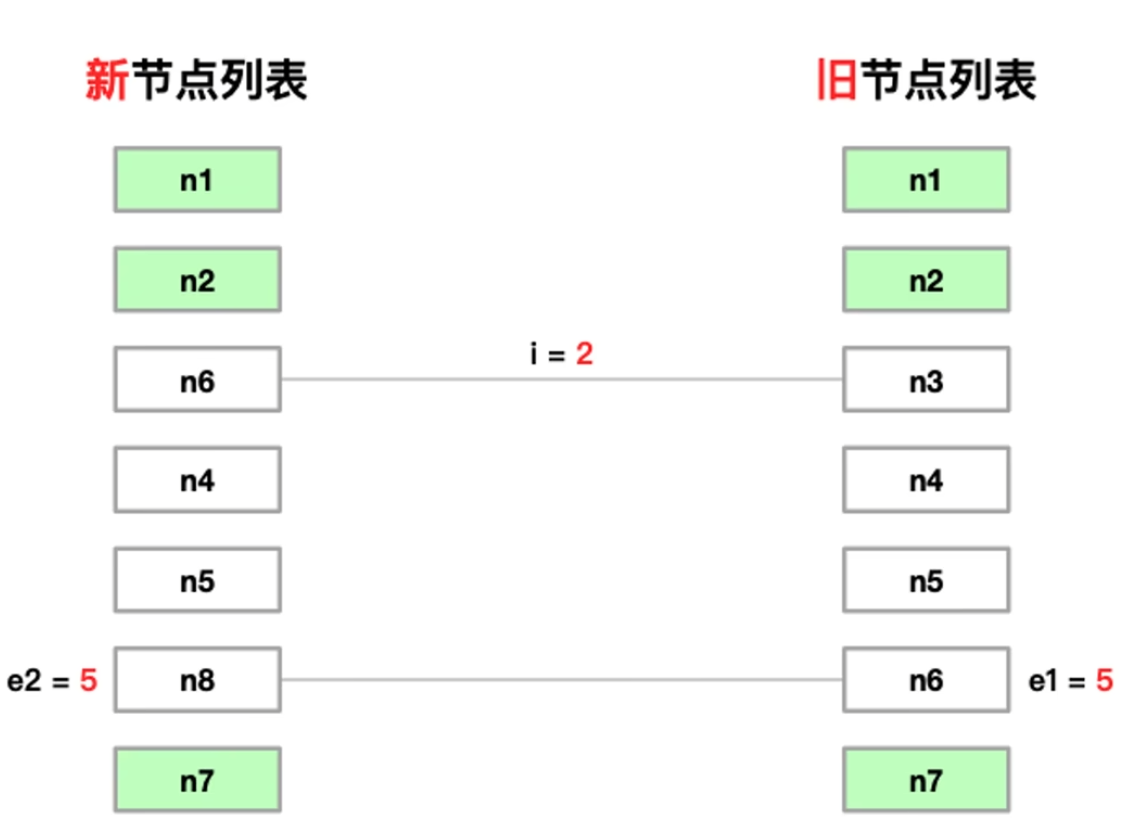
- 完成 预处理前置节点、 预处理后置节点、到达这个状态
- 在这个状态下我们需要:
- 新增 n8
- 卸载 n3
- 更新 n4、n5、n6
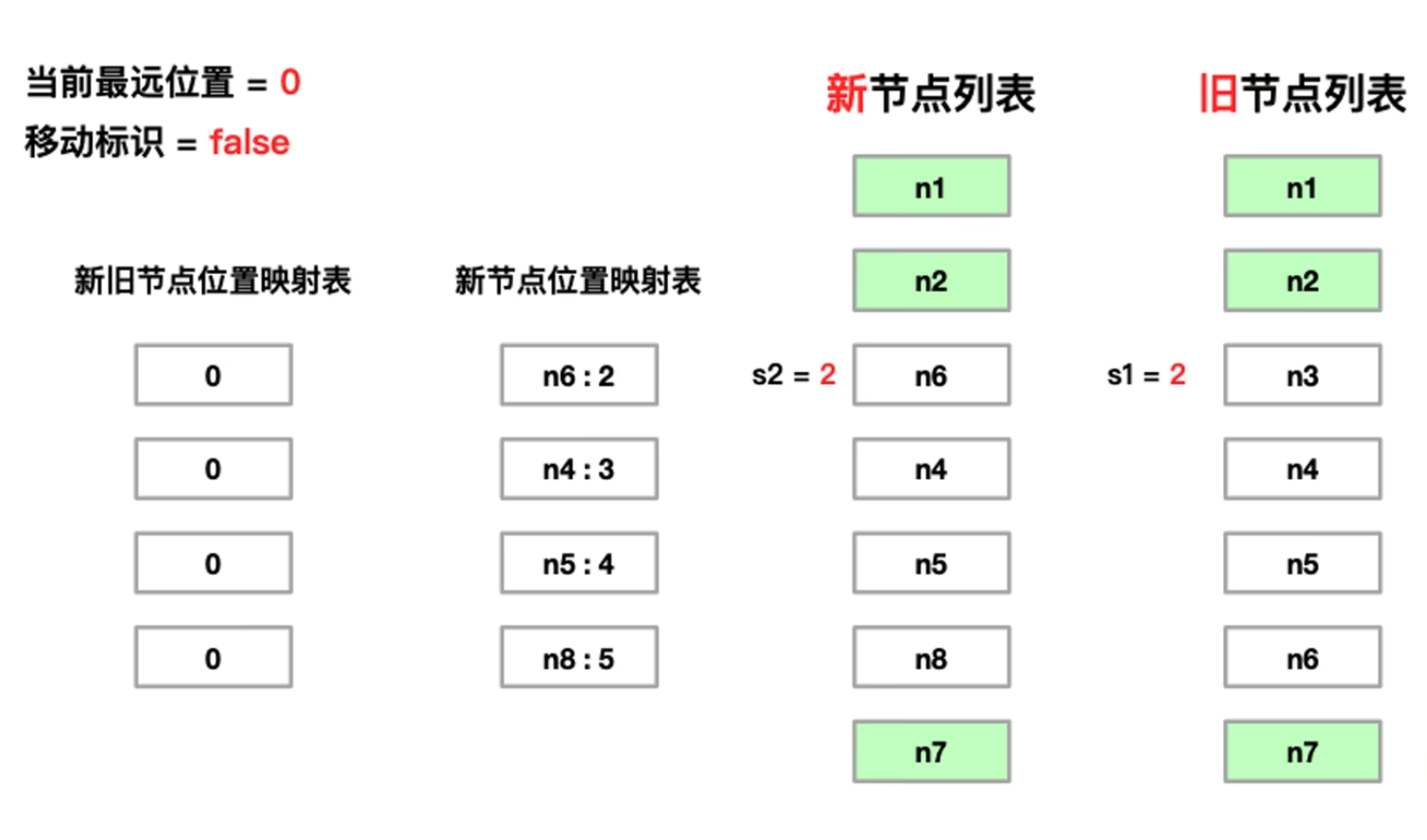
5.1 各个变量的作用
当前最远位置 (lastIndex / maxNewIndexSoFar):
- 初始为 0。记录在遍历旧节点时,对应新节点在 新列表中的最大索引位置。
- 目的:判断 新旧节点 在遍历的过程中是否 同时呈现递增趋势。如果不是则证明节点产生了移动。需要移动表示置为 true 。后续进行移动处理。
移动标识 (moved):
-
初始为 false。一旦发现新节点位置映射表中当前新节点的索引小于 lastIndex,说明节点顺序发生了交叉,该标识变为 true,后续将触发最长递增子序列(LIS)计算。
-
s1 & s2: 分别指向旧子序列和新子序列的起始索引(本图中均为 2,即从 n3/n6 开始)。
新节点位置映射表 (keyToNewIndexMap):
- 作用: 存储 新子序列中节点 的 key 与其 索引 的对应关系(例如 n6: 2, n4: 3)。
- 目的: 为了在遍历旧节点时,能以 O ( 1 ) O(1) O(1) 的复杂度快速找到该节点在新列表中是否存在。
新旧节点位置映射表 (source / newIndexToOldIndexMap):
- 结构: 长度等于新子序列长度的数组(图中四个 0 的方块)。
- 作用: 记录新节点在旧列表中的原始位置索引。
- 值含义:
- 初始全为 0。
- 如果处理后值为 5,代表新子序列该位置的节点在旧序列中的索引是 5。
- 0 是特殊值,代表该新节点是全新的(需挂载)。
5.2 Diff 算法位置处理的详细流程
第一阶段:遍历新子序列,建立新节点位置映射表,
- 遍历新子序列(从 s 2 s2 s2 到 e 2 e2 e2),构建 keyToNewIndexMap。方便接下来遍历 旧子序列节点时候,知道哪些节点要更新和卸载。
第二阶段:遍历旧子序列,寻找可复用节点,
遍历旧子序列(从 s 1 s1 s1 到 e 1 e1 e1),对每一个旧节点执行以下逻辑:
-
检查旧节点是否存在: 通过旧节点的 key 去 keyToNewIndexMap 中查找。
-
找不到: 说明该旧节点在新列表中已不存在,直接卸载(Unmount)。
-
找到了: 说明节点可以复用。
-
-
执行 Patch: 对新旧节点进行打补丁(更新属性、子节点等)。
-
填充 新旧节点位置映射表:
-
遍历接子序列节点,当前旧节点在 新节点位置映射表中找到了,则将旧节点的下标+1,存放到新旧节点为止映射表中
-
(若新旧节点列表根本 没有相同的前节点,那么在进行最后一步比对时,s1就会是从0开始的,此时若不进行+1,则无法与表示代表该新节点是全新的 0 区分了。)
-
检测移动:
-
如果当前找到的新子序列中新节点索引 >= lastIndex,则更新 lastIndex = newIndex。
-
如果当前找到的旧节点索引(+1之后的值) >= lastIndex,则更新 lastIndex = newIndex。
-
-
如果当前找到的新索引 < lastIndex,则说明该节点"跑到了前面节点的前面",将 moved 设为 true。
第三阶段:移动与挂载(最核心)
一旦 moved 为 true,算法会执行以下操作:
-
计算最长递增子序列 (LIS): 针对 source 数组计算 LIS。
- 意义: LIS 中的节点代表了在位置变换中相对顺序没有改变的最大节点集合。这些节点是不需要移动的"锚点"。
-
倒序遍历新旧节点位置映射表:
-
情况 A: 如果 sourcei === 0,说明是新节点,执行 挂载(Mount)。
-
情况 B: 如果当前索引不在 LIS 中,说明该节点需要移动,执行 移动(Move/Insert)。
-
情况 C: 如果当前索引在 LIS 中,跳过,不做任何操作(保持原位)。
-
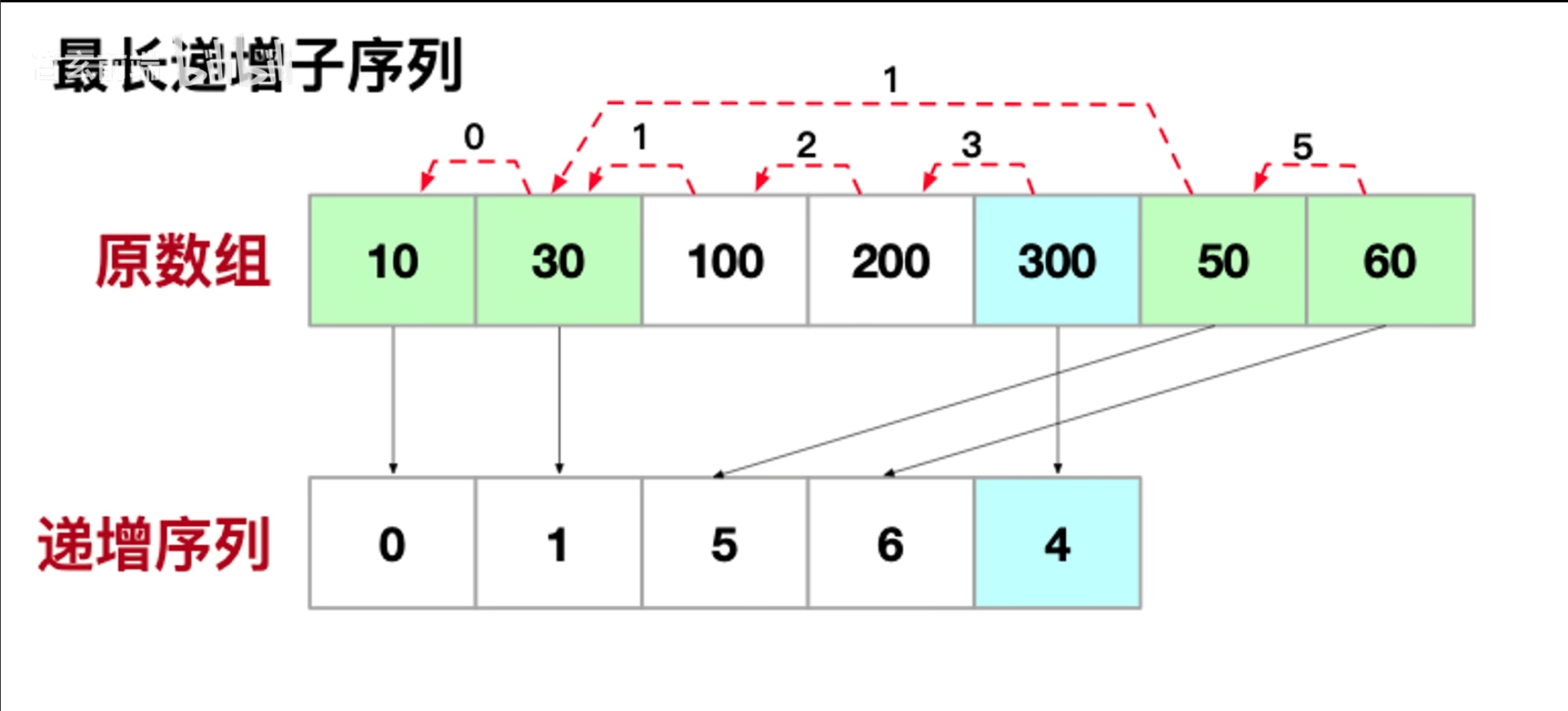
最长递增子序列算法
最长递增子序列算法
1. 定义
最长递增子序列是指在一个给定的序列中,找出一个子序列,使得子序列中的元素自左向右依次递增,且长度尽可能长。
- 子序列:不需要在原数组中连续,但必须保持原始的相对顺序。
- 严格递增 :子序列中相邻元素必须满足 a i < a i + 1 ai < ai+1 ai<ai+1。
2. 示例
假设输入数组:[10, 9, 2, 5, 3, 7, 101, 18]
- 一个递增子序列是:
[2, 3, 7, 18] - 最长递增子序列的长度为:4
3. 核心算法实现
方法一:动态规划 (Dynamic Programming)
这是最经典的方法,适合理解问题的本质。
- 时间复杂度 : O ( n 2 ) O(n^2) O(n2)
- 空间复杂度 : O ( n ) O(n) O(n)
javascript
/**
* @param {number[]} nums
* @return {number}
*/
function lengthOfLIS(nums) {
if (!nums.length) return 0;
// dp[i] 表示以 nums[i] 结尾的最长递增子序列的长度
const dp = new Array(nums.length).fill(1);
let maxLen = 1;
for (let i = 1; i < nums.length; i++) {
for (let j = 0; j < i; j++) {
// 如果当前值大于前面的值,可以尝试拼接
if (nums[i] > nums[j]) {
dp[i] = Math.max(dp[i], dp[j] + 1);
}
}
maxLen = Math.max(maxLen, dp[i]);
}
return maxLen;
}方法二:贪心 + 二分查找 (Greedy + Binary Search)
-
二分查找(Binary Search):
- 也叫折半查找,是一种效率极高的搜索算法。
- 它的核心思想是:每一步都将搜索范围缩小一半。
- 但有一个极其重要的前提:目标集合必须是有序的(通常是升序)。
-
贪心算法(Greedy Algorithm):
- 是一种在每一步选择中都采取在当前状态下**最好或最优(最有利)**的选择,从而希望导致结果是全局最优的策略。
- 通俗点说,贪心算法就是"目光短浅"的算法:只看眼前的利益,不考虑长远的影响。
4 vue3 diff 算法中的最长递增子序列
4.1 二分查找 + 贪心算法 存在的问题
- vue采用的是 二分查找 + 贪心算法
- 贪心算法求的是 局部最优解,导致 全局最终解 出现偏差
- vue3 新增了一个 回溯修正 步骤
4.2 回溯修正
- 构建一个反向列表,每个节点记录上一个节点的位置,最后回溯修正
Vue 2 双端 Diff 算法详解
Vue 2 的 双端 Diff 算法 (Double-Ended Diff) 是基于 snabbdom 修改而来的。它的核心是通过四个指针同时从新旧两个列表的两端向中间遍历,尽可能地复用 DOM 节点。
1. 核心指针 (Four Pointers)
在 Diff 开始时,会定义四个索引变量:
oldStartIdx: 指向旧子节点列表的第一个节点。oldEndIdx: 指向旧子节点列表的最后一个节点。newStartIdx: 指向新子节点列表的第一个节点。newEndIdx: 指向新子节点列表的最后一个节点。
2. 五步查找策略
算法在一个 while 循环中运行(条件:oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx)。每一步都会按顺序进行以下五种匹配:
① 头-头匹配 (oldStart vs newStart)
- 逻辑 :检查两个列表的第一个节点是否相同(
key和sel相同)。 - 操作 :调用
patchVnode更新;两个Start指针同时后移(+1)。
② 尾-尾匹配 (oldEnd vs newEnd)
- 逻辑:检查两个列表的最后一个节点是否相同。
- 操作 :调用
patchVnode更新;两个End指针同时前移(-1)。
③ 旧头-新尾匹配 (oldStart vs newEnd)
- 场景:原来的第一个节点现在跑到了最后。
- 操作 :更新节点,并将
oldStart指向的真实 DOM 移动到当前oldEnd对应的 DOM 之后。 - 指针 :
oldStartIdx++,newEndIdx--。
④ 旧尾-新头匹配 (oldEnd vs newStart)
- 场景:原来的最后一个节点现在跑到了最前面。
- 操作 :更新节点,并将
oldEnd指向的真实 DOM 移动到当前oldStart对应的 DOM 之前。 - 指针 :
oldEndIdx--,newStartIdx++。
⑤ 乱序匹配 (Key Map Lookup)
如果以上四种假设全都不成立:
- 生成映射表 :建立旧列表所有节点的
{ key: index }哈希表。 - 查找 :用
newStart的 key 去表里查。- 没找到 :它是新节点,创建并插入到
oldStartDOM 之前。 - 找到了 :如果是相同节点,将其对应的真实 DOM 移动到
oldStart之前 ,并将旧列表该位置设为undefined。
- 没找到 :它是新节点,创建并插入到
- 指针 :
newStartIdx++。
3. 循环结束后的处理
头尾指针交叉循环结束,头指针 <= 尾指针 循环继续。
当其中一个列表遍历完时,循环停止:
- 旧列表先完 (
oldStartIdx > oldEndIdx) :- 说明新列表中
newStartIdx到newEndIdx之间的节点是新增的。 - 处理:批量创建并插入。
- 说明新列表中
- 新列表先完 (
newStartIdx > newEndIdx) :- 说明旧列表中
oldStartIdx到oldEndIdx之间的节点是多余的。 - 处理:批量从 DOM 中移除。
- 说明旧列表中
4. 为什么双端 Diff 更快?
- 减少移动次数 :通过
旧头-新尾和旧尾-新头的检测,能极大地优化"倒序"或"首尾互换"的场景。 - 命中率高:在实际开发中,列表往往只是在两端增删节点,双端对比能迅速收窄范围。
- 空间换时间:通过 Key 映射表将 O(n²) 的暴力查找降为 O(n) 的线性处理。
注意:Vue 3 进一步引入了"静态标记"和"最长递增子序列"算法,处理乱序匹配的性能比 Vue 2 的双端 Diff 更加极致。
