「微舆」(BettaFish)------ 小而强大,不畏挑战。用多智能体打破信息茧房,还原舆情原貌。
前言
在信息爆炸的时代,社交媒体每天产生海量内容。品牌公关、危机预警、市场洞察、政策分析......各行各业都迫切需要一套能够实时采集、深度理解、智能分析社交媒体舆情的系统。
然而,传统的舆情工具往往存在以下痛点:
- 单一大语言模型(LLM)容易产生幻觉,缺乏深度推理
- 信息获取渠道单一,容易陷入"信息茧房"
- 无法处理短视频、图片等多模态内容
- 私有业务数据与公开舆情数据割裂,无法融合分析
BettaFish(微舆) 正是为解决这些痛点而生的开源项目。它从零开始用纯 Python 实现了一套完整的多智能体协作框架,支持 Docker 一键部署,已在 GitHub 开源(GPL-2.0 协议)。
本文将从架构设计、核心模块、技术栈选型、部署实践等多个维度,为你深入解析这一系统。
一、系统概览
| 属性 | 详情 |
|---|---|
| 项目名称 | BettaFish(微舆) |
| 开源地址 | https://github.com/666ghj/BettaFish |
| 开源协议 | GPL-2.0 |
| 主要语言 | Python |
| 核心定位 | 多智能体驱动的全域舆情分析与预测系统 |
| 监控平台 | 微博、小红书、抖音、快手等 30+ 主流社媒 |
| 部署方式 | Docker 一键部署 / 源码部署 |
"微舆"谐音"微鱼",BettaFish 即斗鱼,寓意在信息的汪洋大海中,以小而灵活的姿态应对挑战。它的核心理念只有一句话:
帮助用户打破信息茧房,还原舆情原貌,预测未来走向,辅助决策。
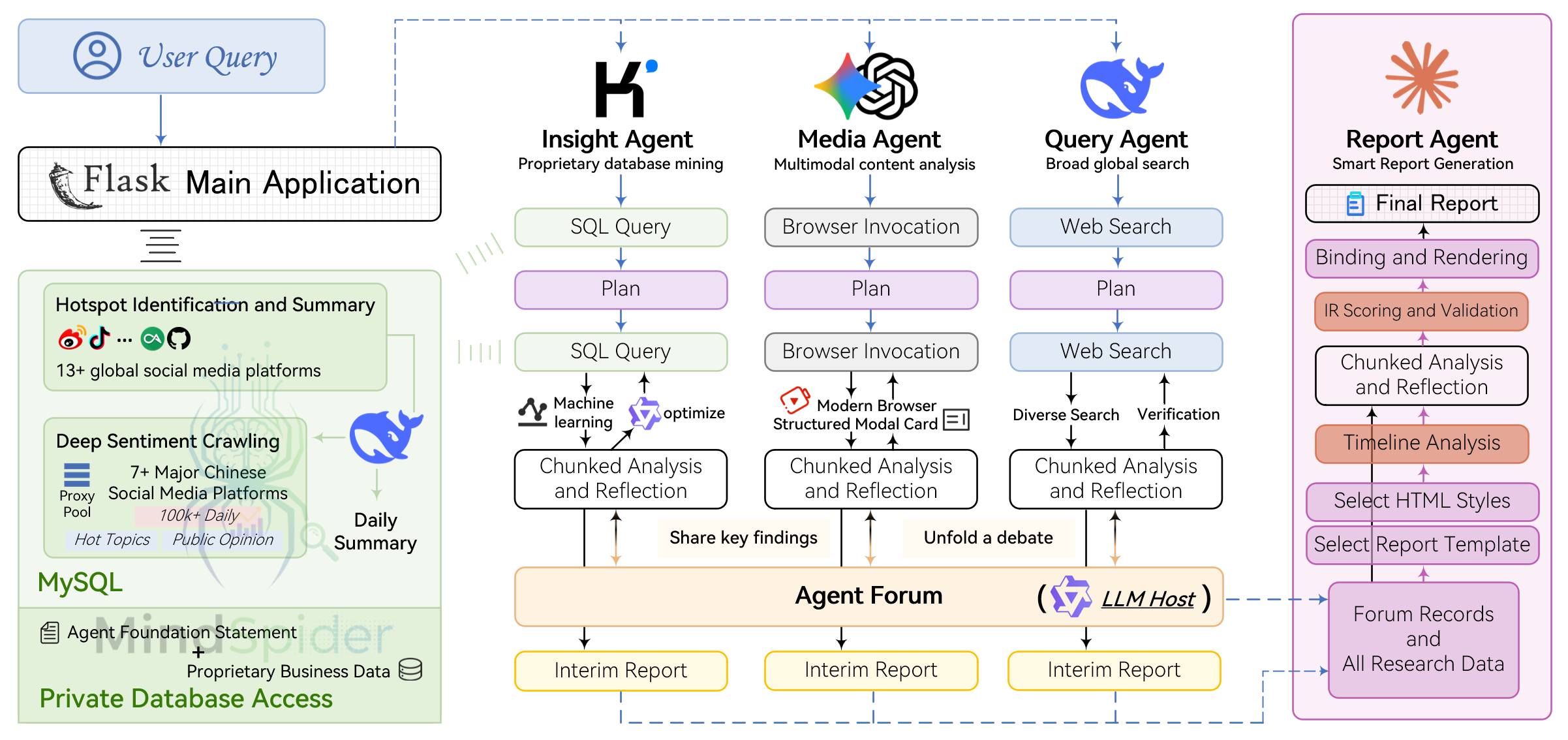
二、核心架构:多智能体协作框架
区别于市面上大多数"套壳 GPT"产品,BettaFish 的最大亮点在于其自主实现的多智能体(Multi-Agent)协作架构,不依赖 LangChain、AutoGen 等任何现有框架,完全从零构建。
2.1 五大核心引擎
系统的大脑由五个专业智能体(Agent)构成,各司其职:
┌─────────────────────────────────────────────────────────────┐
│ 用户查询入口(Flask) │
└──────────────────────────┬──────────────────────────────────┘
│
┌────────────▼────────────┐
│ Forum Engine │
│ (论坛协作协调引擎) │
└──┬──────┬──────┬──────┬─┘
│ │ │ │
┌──────▼┐ ┌──▼───┐ ┌▼──────┐ ┌▼────────┐
│ Query │ │Media │ │Insight│ │ Report │
│Engine │ │Engine│ │Engine │ │ Engine │
│(搜索) │ │(多模 │ │(私域) │ │(报告) │
└───────┘ │ 态) │ └───────┘ └─────────┘
└──────┘Query Engine --- 广度搜索智能体
负责在国内外各大新闻站点、社交平台进行精准的信息检索,是系统获取原始舆情数据的第一道关卡。支持多关键词联合检索,能够按时间线梳理舆情演变脉络。
Media Engine --- 多模态理解智能体
专注于短视频、图片等非文本内容的深度解析。在抖音、快手横行的今天,能否理解视频内容,几乎决定了一个舆情系统的天花板。Media Engine 能够:
- 抽取视频核心观点与情绪倾向
- 识别图片中的文字、人物、场景
- 精准提取天气、日历、股票等结构化信息卡片
Insight Engine --- 私域数据挖掘智能体
这是面向企业用户的杀手级功能。Insight Engine 可通过高安全性接口对接企业内部数据库,将外部舆情趋势 与内部业务洞察无缝融合,回答诸如"这波舆情是否影响到我们的转化率?"这样的问题。
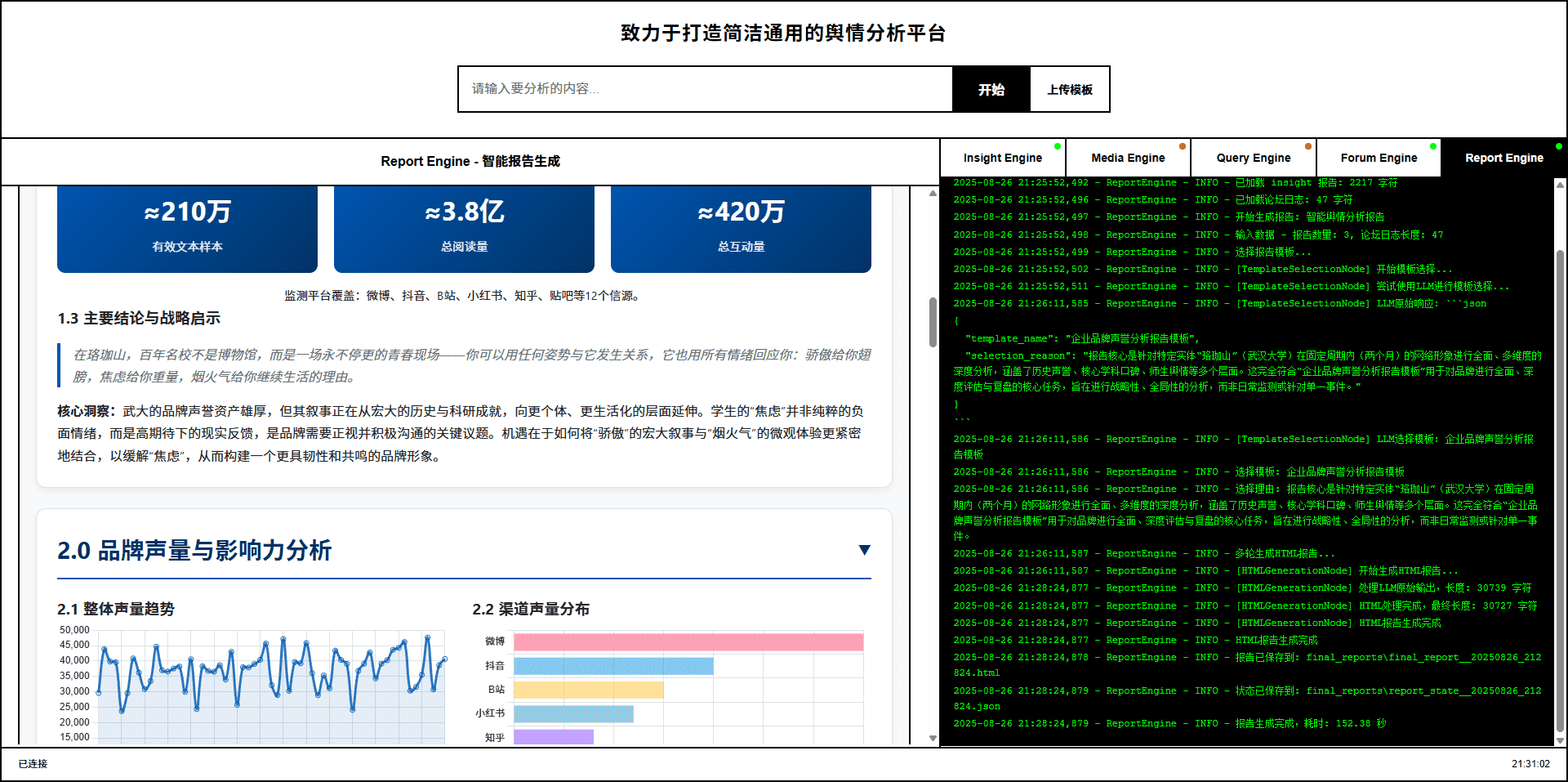
Report Engine --- 报告生成智能体
内置多种报告模板,可自动生成交互式 HTML 分析报告,支持 PDF、Markdown 等多种格式。多轮生成机制确保报告的深度和完整性。
Forum Engine --- 论坛协作协调引擎
这是整个架构中最具创意的设计。Forum Engine 并不直接做分析,而是像一个"辩论主持人",协调各智能体进行思维碰撞与辩论:
- 各 Agent 提出初步分析结论
- Forum Engine 提炼分歧点,引导 Agent 间进行"辩论"
- 通过多轮反思与修正,最终形成集体共识
这种机制有效避免了单一模型的思维同质化,大幅提升了分析质量。
三、数据采集层:MindSpider 爬虫系统
舆情分析的基础是数据,BettaFish 内置了名为 MindSpider 的社交媒体爬虫系统,作为独立模块运行(MindSpider/ 目录)。
其主要特性:
- 异步并发采集:多线程/协程采集,支持高并发
- 反检测机制:模拟真实用户行为,降低被封风险
- 增量更新:基于时间戳去重,避免重复数据入库
- 数据标准化:统一不同平台的数据格式,方便下游处理
⚠️ 合规提示:爬取社交媒体数据需严格遵守平台服务协议及相关法律法规。本项目仅供学习、学术研究和教育目的使用,严禁用于任何商业用途或违法行为。
四、情感分析模型矩阵
SentimentAnalysisModel/ 模块提供了从轻量到重型的完整模型选择,满足不同精度与资源需求:
| 模型类型 | 代表模型 | 适用场景 |
|---|---|---|
| 传统机器学习 | SVM + TF-IDF | 低资源环境,快速原型 |
| 预训练模型微调 | BERT(多语言) | 中等精度,平衡性能 |
| 大模型微调 | Qwen-fine-tuned | 高精度,复杂情感理解 |
多模型并行分析,并通过集成学习策略融合结果,显著提升了情感判断的鲁棒性。
五、技术栈全景
┌─────────────────── 应用层 ──────────────────────┐
│ Flask (主应用API) │ Streamlit (单Agent调试界面)│
├─────────────────── AI层 ────────────────────────┤
│ LLM: OpenAI兼容API(DeepSeek/Qwen/Kimi等) │
│ 情感分析: BERT / Qwen 微调模型 │
│ 多模态: 视觉语言模型(VLM) │
│ GraphRAG: 语义关联图谱分析 │
├─────────────────── 数据层 ──────────────────────┤
│ PostgreSQL / MySQL │ 自定义私有数据库接口 │
├─────────────────── 爬虫层 ──────────────────────┤
│ MindSpider - 异步爬虫集群 │
├─────────────────── 部署层 ──────────────────────┤
│ Docker + Docker Compose │ Conda 虚拟环境 │
└─────────────────────────────────────────────────┘LLM 接入的灵活性 值得特别说明:系统兼容所有支持 OpenAI API 格式的大模型,包括 DeepSeek、Kimi、Qwen、通义千问等国产模型,只需在 .env 配置文件中切换 API 端点即可,无需修改任何代码。
六、快速部署指南
方式一:Docker 一键部署(推荐)
这是最简单的方式,5 分钟内即可拥有一套完整的舆情分析环境。
前提条件:
- 安装 Docker Desktop(Windows/Mac)或 Docker Engine(Linux)
- 准备一个兼容 OpenAI API 的大模型 API Key
步骤:
# 1. 克隆项目
git clone https://github.com/666ghj/BettaFish.git
cd BettaFish
# 2. 配置环境变量
cp .env.example .env
# 编辑 .env 文件,填入你的 API Key、数据库配置等
# 3. 一键启动所有服务
docker compose up -d
# 4. 查看启动状态
docker compose ps
bash
vim .env
# ====================== BETTAFISH 相关 ======================
# BETTAFISH 主机地址,例如:0.0.0.0 或 127.0.0.1
HOST=0.0.0.0
# BETTAFISH 主机地址,默认为5000
PORT=5000
# ====================== 数据库配置 ======================
# 数据库主机,例如localhost 或 127.0.0.1
DB_HOST=192.168.xx.xx
# 数据库端口号,默认为3306
DB_PORT=5444
# 数据库用户名
DB_USER=bettafish
# 数据库密码
DB_PASSWORD=bettafish
# 数据库名称
DB_NAME=bettafish
# 数据库字符集,推荐utf8mb4,兼容emoji
DB_CHARSET=utf8mb4
# 数据库类型mysql或postgresql
DB_DIALECT=postgresql
# ======================= LLM 相关 =======================
# 您可以更改每个部分LLM使用的API,🚩只要兼容OpenAI请求格式都可以,定义好KEY、BASE_URL与MODEL_NAME即可正常使用。
# 重要提醒:我们强烈推荐您先使用推荐的配置申请API,先跑通再进行您的更改!
# 我们的LLM模型API赞助商有:https://aihubmix.com/?aff=8Ds9,提供了非常全面的模型api
# Insight Agent(推荐kimi-k2,官方申请地址:https://platform.moonshot.cn/)
INSIGHT_ENGINE_API_KEY=you_token
INSIGHT_ENGINE_BASE_URL=https://platform.moonshot.cn/console/api‑keys
INSIGHT_ENGINE_MODEL_NAME="kimi‑k2"
# Media Agent(推荐gemini-2.5-pro,中转厂商申请地址:https://aihubmix.com/?aff=8Ds9)
MEDIA_ENGINE_API_KEY=
MEDIA_ENGINE_BASE_URL=
MEDIA_ENGINE_MODEL_NAME=
# Query Agent(推荐deepseek-chat,官方申请地址:https://platform.deepseek.com/)
QUERY_ENGINE_API_KEY=you_token
QUERY_ENGINE_BASE_URL=https://platform.deepseek.com/console/api‑keys
QUERY_ENGINE_MODEL_NAME="deepseek‑chat"
# Report Agent(推荐gemini-2.5-pro,中转厂商申请地址:https://aihubmix.com/?aff=8Ds9)
# 注意:Report Agent需要相对较强的模型能力,若最终报告出现图表空白/段落异常的情况,请尝试更换更强的模型
REPORT_ENGINE_API_KEY=sk-you_token
REPORT_ENGINE_BASE_URL=https://platform.moonshot.cn/console/api‑keys
REPORT_ENGINE_MODEL_NAME="kimi‑k2"
# MindSpider Agent(推荐deepseek-chat,官方申请地址:https://platform.deepseek.com/)
MINDSPIDER_API_KEY=
MINDSPIDER_BASE_URL=
MINDSPIDER_MODEL_NAME=
# 论坛主持人(推荐qwen-plus,官方申请地址:https://www.aliyun.com/product/bailian)
FORUM_HOST_API_KEY=
FORUM_HOST_BASE_URL=
FORUM_HOST_MODEL_NAME=
# SQL Keyword Optimizer(推荐qwen-plus,官方申请地址:https://www.aliyun.com/product/bailian)
KEYWORD_OPTIMIZER_API_KEY=you_token
KEYWORD_OPTIMIZER_BASE_URL=https://dashscope.aliyun.com/console/apiKey
KEYWORD_OPTIMIZER_MODEL_NAME=qwen‑plus
# ================== 网络工具配置 ====================
# Tavily API密钥,用于Tavily网络搜索,申请地址:https://www.tavily.com/
TAVILY_API_KEY=you_token
# 网络搜索工具类型,支持BochaAPI或AnspireAPI两种,默认为AnspireAPI
SEARCH_TOOL_TYPE=AnspireAPI
# Anspire AI Search API(申请地址:https://open.anspire.cn/?share_code=3E1FUOUH,相同效果下费用是Bocha的一半)
ANSPIRE_BASE_URL=https://plugin.anspire.cn/api/ntsearch/search
ANSPIRE_API_KEY=you_token
# Bocha AI Search API(用于Bocha多模态搜索,这里密钥名称虽然是Web Search,但其实是要AI Search的,申请地址:https://open.bochaai.com/)
BOCHA_BASE_URL=https://api.bocha.cn/v1/ai-search
BOCHA_WEB_SEARCH_API_KEY=you_token
GRAPHRAG_ENABLED=False
GRAPHRAG_MAX_QUERIES=3启动成功后,通过浏览器访问各服务界面:
| 服务 | 默认地址 |
|---|---|
| 主控制台 | http://localhost:5000 |
| Query Agent | http://localhost:8501 |
| Media Agent | http://localhost:8502 |
| Insight Agent | http://localhost:8503 |
方式二:源码部署
适合开发者进行二次开发和定制。
# 1. 创建虚拟环境
conda create -n bettafish python=3.10
conda activate bettafish
# 2. 安装依赖
pip install -r requirements.txt
# 3. 初始化数据库
python scripts/init_db.py
# 4. 启动主应用
python app.py关键配置说明(.env 文件)
# 大模型配置
LLM_API_BASE=https://api.deepseek.com/v1 # 支持任何OpenAI兼容接口
LLM_API_KEY=your_api_key_here
LLM_MODEL_NAME=deepseek-chat
# 数据库配置
DATABASE_URL=postgresql://user:password@localhost:5432/bettafish
# 爬虫配置(可选)
WEIBO_COOKIE=your_weibo_cookie七、典型应用场景
1. 企业品牌声誉管理
- 实时监控多平台用户对品牌的评价动态
- 识别负面舆情并自动触发预警
- 生成竞品对比分析报告
2. 金融市场情绪分析
- 抓取社交媒体对上市公司的讨论热度
- 结合情感分析预测短期市场情绪波动
- 为量化策略提供另类数据支持
3. 政务舆情监控
- 跟踪民生相关政策的社会反响
- 提前识别群体性事件风险信号
- 辅助舆论引导和信息公开决策
4. 新产品上市评估
- 发布后快速汇聚全网用户真实反馈
- 多维度拆解用户痛点与满意点
- 指导产品迭代优先级
5. 学术研究
- 获取大规模、多平台的社会态度数据集
- 支持计算社会学、传播学等领域研究
八、项目亮点总结
| 特性 | BettaFish | 传统工具 |
|---|---|---|
| 多智能体协作 | ✅ 论坛辩论机制 | ❌ 单模型 |
| 多模态理解 | ✅ 图文视频全支持 | ❌ 仅文本 |
| 私域数据融合 | ✅ 支持 | ❌ 不支持 |
| 框架依赖 | ✅ 零框架,纯Python | ⚠️ 依赖 LangChain 等 |
| 部署复杂度 | ✅ Docker 一键 | ⚠️ 复杂配置 |
| 开源免费 | ✅ GPL-2.0 | ❌ 多为商业收费 |
九、结语
BettaFish(微舆)是一个相当有诚意的开源项目。它没有站在巨人的肩膀上简单组装,而是选择了"从零实现"这条更难走的路------自建多智能体协作框架、自研爬虫系统、集成多套情感分析模型。
对于想要学习多智能体系统设计 、LLM 应用工程 或舆情分析技术的开发者来说,这个代码库是一份不可多得的参考资料。
如果你在使用中遇到问题,欢迎到 GitHub Issues 反馈;如果觉得项目有价值,别忘了给一个 ⭐️!
参考资料:
- BettaFish GitHub 仓库:https://github.com/666ghj/BettaFish
- 终极指南:5分钟Docker一键部署微舆系统:https://blog.csdn.net/gitblog_00026/article/details/138945421
- BettaFish舆情监控详解:https://blog.csdn.net/hzp666/article/details/154427162
- GitHub项目推荐------BettaFish(微舆):https://blog.csdn.net/j8267643/article/details/156511092