写在前面
本文看下中断相关内容。
1:什么是中断?
中断是一种异步的事件通知机制,用来接收来自外部的数据输入,如键盘,网卡等。收到中断后,首先执行硬中断,主要是读取数据到内存中,这个过程很快,并且会关闭中断,即此期间不会响应新的中断信号。接着是发送软件中断信号,执行软中断过程,这个过程由专门的内核线程来执行,一般名称是ksoftirqd/[CPU编号]。在实际的生产环境中,一般我们遇到的就是网卡的中断,所以本文来看个网卡中断的例子来加深理解。
2:实际案例
我们需要准备两个vm,一个vm运行ng服务,模拟一个web服务器,一个vm通过hping3命令来模拟大量的网络请求。
首先启动ng:
# 运行Nginx服务并对外开放80端口
$ docker run -itd --name=nginx -p 80:80 nginx验证下:
$ curl http://192.168.0.30/
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...一般没有啥问题。
接着我们在另一个vm来模拟大量网络请求:
root@hellohp:/home/dongyunqi# hping3 -S -p 80 -i u100 192.168.170.128
len=46 ip=192.168.170.128 ttl=63 DF id=0 sport=80 flags=SA seq=4280 win=64240 rtt=1.8 ms
len=46 ip=192.168.170.128 ttl=63 DF id=0 sport=80 flags=SA seq=4281 win=64240 rtt=1.6 ms
...此时如果一切正常的话,网络层面就会出问题了,对应到生产及环境的话,可能就是业务该反馈各种数据不及时啊,状态不对啊,等问题了,都是因为网卡消息过多,软中断过多,软中断线程处理不过来导致的了。接着我们来把其当作黑盒继续看下。
既然系统出现问题了已经,自然要先来top看下,哪些指标异常了:

负载正常,cpu利用率正常,任务也正常,但是就是有一个内核软中断的线程占用的cpu利用率比较高,也就是上图红框里的,说明可能是有大量的软中断在不断发生,可以看下proc文件系统,通过命令watch -d "/bin/cat /proc/softirqs | /usr/bin/awk 'NR == 1{printf \"%13s %s\n\",\" \",\$1}; NR > 1{printf \"%13s %s\n\",\$1,\$2}'":
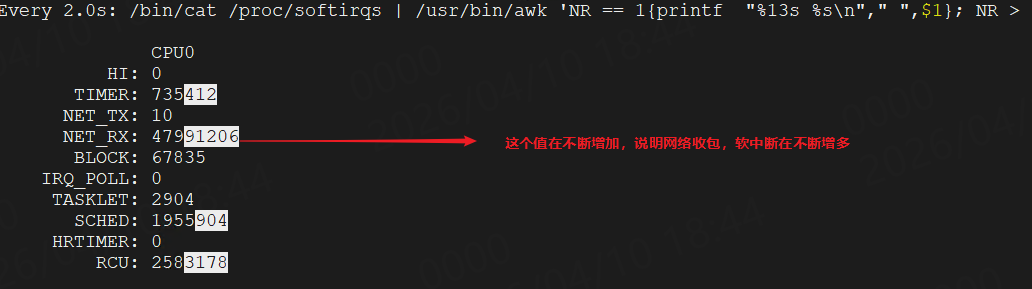
NET_RX是网络收包软中断,NET_TX是网络发包软中断,其他的都是内核的软中断,一般不会有问题,可以忽略。
既然确认是网络收包,就可以来看下来自哪些主机的包多了,通过命令root@hellohp:/proc# tcpdump -i ens33 -n tcp port 80 :
root@hellohp:/proc# tcpdump -i ens33 -n tcp port 80
10:50:35.778181 IP 192.168.170.129.8294 > 192.168.170.128.80: Flags [R], seq 1553464501, win 0, length 0
10:50:35.778181 IP 192.168.170.129.8295 > 192.168.170.128.80: Flags [R], seq 716403946, win 0, length 0
10:50:35.778181 IP 192.168.170.129.8296 > 192.168.170.128.80: Flags [R], seq 1660577291, win 0, length 0
10:50:35.778262 IP 192.168.170.128.80 > 192.168.170.129.8298: Flags [S.], seq 1277770738, ack 1834335578, win 64240, options [mss 1460], length 0
...可以看到来自192.168.170.129.8296的包最多,如果确认其有问题的话,加到黑名单或者是其他方案处理掉就行了。