**背景:**承接《静态融合特征做分类任务(监督)》这篇博客,该篇博客记录了本人在测试模型评估指标时的一些记录,目的是熟悉掌握如何正确的去评估模型的好坏?学会看模型的评估指标结果。
比如:你的模型评估结果打印出来了,像准确率 (Accuracy)、精确率 (Precision)、召回率 (Recall)、F1 分数、AUC这些值,但是你真正会看它们吗?模型评估结果如何?有没有欠拟合、过拟合等问题出现?你自己如何去判断呢?
1.逻辑回归分类器
模型情况:
self.model = LogisticRegression(max_iter=1000, random_state=42)
数据集情况:
训练集: 2400 (60.0%)、验证集: 800 (20.0%)、测试集: 801 (20.0%)
分类器评估指标:
{
'train': {
'accuracy': 0.9966666666666667,
'precision': 1.0,
'recall': 0.9866888519134775,
'f1': 0.9932998324958124,
'auc': 0.9996420640418646
},
'val': {
'accuracy': 0.99625,
'precision': 1.0,
'recall': 0.985,
'f1': 0.9924433249370277,
'auc': 0.9942583333333334
},
'test': {
'accuracy': 0.9937578027465668,
'precision': 1.0,
'recall': 0.975,
'f1': 0.9873417721518988,
'auc': 0.9924376039933444
}
}评估分析:
| 数据集 | 准确率 (Accuracy) | 精确率 (Precision) | 召回率 (Recall) | F1 分数 | AUC |
|---|---|---|---|---|---|
| 训练集 (Train) | 99.67% | 100.00% | 98.67% | 0.9933 | 0.9996 |
| 验证集 (Val) | 99.63% | 100.00% | 98.50% | 0.9924 | 0.9943 |
| 测试集 (Test) | 99.38% | 100.00% | 97.50% | 0.9873 | 0.9924 |
1. 是否存在过拟合(Overfitting)?
结论:不存在。
- 理由:训练集、验证集和测试集的指标极其接近(差异均在 1% 以内)。通常过拟合表现为训练集表现完美但测试集大幅下降,而你的模型在测试集上依然保持了 99.38% 的高准确率,说明模型真正学到了数据的特征,而非死记硬背。
2. 是否存在欠拟合(Underfitting)?
结论:不存在。
- 理由:训练集的准确率和 AUC 接近满分。欠拟合通常表现为模型在训练集上就无法达到较高的精度,而你的模型各项指标均处于极高水平。
3. 性能亮点
- 精确率 (Precision) 均为 1.0:这意味着在所有被模型预测为"正类"的样本中,没有任何一个是误报(False Positive)。这在对"误诊/误报"极其敏感的场景下(如反欺诈、重大疾病检测)非常理想。
- Recall 与 F1 平衡:虽然召回率(97.5%)略低于精确率,但依然处于极高水平,F1 分数接近 0.99,证明模型在查准和查全之间取得了完美的平衡。
潜在建议
虽然结果接近完美,但有两点值得你关注:
- 数据分布检查 :由于指标几乎都在 99% 以上,请确认是否存在数据泄露 (例如特征中包含了标签的信息)或者样本极其不均衡。
- 置信度观察:测试集的召回率(97.5%)比训练集略降了约 1.2%,这属于正常的泛化抖动,但在业务端需注意那 2.5% 漏掉的正类样本是否具有某种特定共性。
针对你目前接近"完美"的指标(尤其是 Precision 全满),保持警惕是非常专业的做法。以下是排查数据泄露和样本不均衡的具体操作指南:
一、 如何检查"数据泄露" (Data Leakage)
数据泄露是指模型在训练时无意中接触到了测试集的信息,或者特征中包含了"预知未来"的信息。
1. 检查特征相关性(最直接)待验证
- 看什么:计算每个特征与标签(Label)的相关系数。
- 异常信号:如果某个特征与标签的相关性达到 0.95 以上,且该特征在现实业务中不可能提前获得(例如:预测用户是否下单,但特征里包含了"发货单号"),这就是泄露。
- 操作:使用
df.corr()查看特征与目标列的相关性,重点关注那些贡献度(Feature Importance)异常高的特征。2. 时间序列泄露(针对时序数据) 排除
- 看什么:检查训练集和测试集的时间切分。
- 异常信号:如果你用"未来"的数据预测"过去"的事情。
- 操作:确保你的划分方式是按时间顺序(如前8个月训练,后2个月测试),而不是随机抽样(
train_test_split默认是随机的,这在时序数据中会导致泄露)。3. 预处理泄露 排除
- 看什么:标准化、归一化、缺失值填充是在什么时候做的?
- 异常信号:如果你在
fit缩放器(Scaler)时使用了全量数据(包含测试集),测试集的统计信息(均值/方差)就已经泄露给了模型。- 操作:必须先划分数据集,仅在训练集上
fit,然后在测试集上transform。
二、 如何判断"样本极其不均衡" (Class Imbalance)
当模型在某类样本(通常是负类)占比极高时,即使它盲目预测所有样本为该类,准确率也会很高。
1. 检查原始标签分布 排除
- 看什么:统计各类别样本的数量。
- 操作:执行
y.value_counts(normalize=True)。- 判定标准:
- 轻微不平衡:少数类占比 20%~40%。
- 严重不平衡:少数类占比 1%~5% 或更低(如金融欺诈、点击率预估)。
2. 对比"基准准确率" (Baseline Accuracy) 排除
- 看什么:如果你的测试集中 99% 都是 0,1% 才是 1。
- 判定:那么一个"笨模型"(全部预测为 0)的准确率也是 99%。如果你的模型准确率是 99.3%,说明模型只比盲猜好了一点点。
3. 核心指标:混淆矩阵 (Confusion Matrix) 排除
看什么:重点看少数类(通常是正类 1)的分类情况。
操作:
from sklearn.metrics import confusion_matrix print(confusion_matrix(y_test, y_pred))分析:即使你的 Accuracy 很高,但如果混淆矩阵显示正类样本只有 10 个,而你漏掉了 5 个,那么即便总准确率 99%,对业务来说也是失败的。
三、 你的结果诊断建议
你的 Precision 始终是 1.0,这非常罕见。这可能意味着:
- 特征过于强大:某个特征几乎等同于标签。
- 正样本量极少:如果测试集只有 2 个正样本,且模型全抓住了,Precision 就是 1.0,但这可能属于随机性。
我的测试:
经过我查看,在我的y_test中,sum(y_test == 1) = 200、sum(y_test == 0) = 601
这就排除了"样本极度稀缺"导致高分的偶然性。在801 个测试样本中,正样本占比约 25%(200个),这属于比较健康的数据分布,不是极端不平衡。
所以并不是样本不均衡所致!
但在 25% 占比 的情况下,逻辑回归(线性模型)能达到 100% Precision 和 97.5% Recall ,这在真实业务场景中极其罕见。由于逻辑回归本质上是寻找一个超平面来分割数据,如此完美的表现通常意味着:有一个或几个特征与标签(Label)之间存在某种"确定性"的逻辑关联。
接下来,我又继续排除是不是数据泄露导致的。
np.sort(classifier.model.coef_0)::-1 # 将模型权重w按照降序排序并返回
array([ 1.60939189, 0.80305824, 0.78624508, 0.70539071, 0.70083643,
0.68100283, 0.65447011, 0.6342279 , 0.61147107, 0.55741302,
0.5449924 , 0.53896704, 0.52590713, 0.52590713, 0.51578701,
0.51360126, 0.50271787, 0.48989762, 0.47598602, 0.47482156,
0.47215405, 0.45133492, 0.44526212, 0.44017064, 0.435021 ,
0.43265918, 0.42085983, 0.4108808 , 0.40220748, 0.40031587,
0.40031587, 0.39813218, 0.39439293, 0.3666087 , 0.3666087 ,
0.35917459, 0.3532347 , 0.34886824, 0.34008775, 0.33026785,
0.32358917, 0.31362114, 0.30162208, 0.29381226, 0.29233499,
0.27885391, 0.2762416 , 0.27325223, 0.27325223, 0.26809972,
0.26507203, 0.26444645, 0.26384921, 0.25949291, 0.25251045,
0.23816495, 0.23803499, 0.22991174, 0.22991174, 0.22544107,
0.22508982, 0.22191552, 0.21800327, 0.21604631, 0.21604631,
0.21220159, 0.21158184, 0.21118582, 0.21118582, 0.20852788,
0.20721463, 0.20153303, 0.19658264, 0.19569244, 0.19123929,
0.18994378, 0.18838532, 0.18692406, 0.18300458, 0.17937097,
0.16711799, 0.16489576, 0.16110155, 0.1563099 , 0.15013299,
0.14585621, 0.13980734, 0.13785407, 0.13708773, 0.13446545,
0.13198931, 0.13187187, 0.13085144, 0.13085144, 0.13022527,
0.12690909, 0.12673442, 0.12673442, 0.12217752, 0.12159152,
0.11649114, 0.11539084, 0.11144867, 0.11100189, 0.10680509,
0.10662257, 0.10443054, 0.1043388 , 0.10396659, 0.10396659,
0.10328472, 0.10163647, 0.09860097, 0.09529961, 0.094949 ,
0.094949 , 0.09163769, 0.09048561, 0.08951832, 0.08837954,
0.08837954, 0.08523333, 0.08488006, 0.08187932, 0.08172662,
0.07934918, 0.07380668, 0.07050522, 0.06904445, 0.06569509,
0.06355324, 0.06141564, 0.05600447, 0.04736336, 0.04230125,
0.04155742, 0.04057947, 0.03975033, 0.03600536, 0.02939395,
0.02939395, 0.02611034, 0.02611034, 0.02281953, 0.02211008,
0.02066342, 0.01929289, 0.01232803, 0.01137365, 0.01094149,
0.0091732 , 0.00856631, 0.00840449, 0.00838272, 0.00793635,
0.00755515, 0.00743619, 0.00732565, 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
-0.01369255, -0.01554943, -0.01771495, -0.01818036, -0.03407144,
-0.03464967, -0.03611986, -0.03671799, -0.04079436, -0.04352682,
-0.04392234, -0.04434439, -0.04772094, -0.05873033, -0.07061183,
-0.07651195, -0.08856385, -0.08870551, -0.08944435, -0.09288911,
-0.09493115, -0.09541497, -0.10173923, -0.10276899, -0.10301058,
-0.11023255, -0.11360965, -0.11561248, -0.11820865, -0.1207416 ,
-0.12389082, -0.1366989 , -0.14525521, -0.16521442, -0.1683849 ,
-0.17291107, -0.17838771, -0.18255592, -0.18404822, -0.18742475,
-0.19418779, -0.19982705, -0.20344949, -0.2121108 , -0.21374709,
-0.21473964, -0.21904606, -0.22166798, -0.22635094, -0.23183424,
-0.23288995, -0.23724342, -0.23923799, -0.2510289 , -0.27773806,
-0.29079865, -0.31481379, -0.344196 , -0.38302519, -0.39575294,
-0.40174017, -0.41530825, -0.4315991 , -0.46905896, -0.51579876,
-0.7185489 ])classifier.model.coef_0.argsort()::-1 # 将模型权重降序排序并返回其下标索引
array([126, 48, 44, 14, 0, 248, 46, 12, 72, 2, 24, 56, 54,
52, 51, 1, 26, 25, 74, 50, 47, 45, 27, 58, 151, 49,
75, 13, 73, 53, 55, 212, 179, 32, 34, 232, 3, 18, 209,
16, 189, 59, 57, 152, 98, 251, 208, 78, 76, 235, 15, 203,
130, 96, 97, 241, 190, 33, 35, 17, 6, 146, 214, 79, 77,
231, 183, 38, 36, 185, 99, 149, 4, 142, 153, 129, 88, 86,
186, 200, 131, 236, 222, 221, 85, 19, 100, 84, 158, 168, 161,
206, 39, 37, 144, 134, 40, 42, 178, 191, 246, 5, 91, 245,
102, 182, 87, 218, 61, 63, 213, 137, 255, 165, 41, 43, 157,
89, 103, 60, 62, 101, 90, 193, 138, 141, 8, 197, 7, 195,
10, 128, 9, 228, 133, 11, 205, 166, 139, 65, 67, 64, 66,
199, 145, 184, 204, 192, 216, 140, 92, 94, 95, 93, 80, 82,
83, 81, 30, 31, 70, 69, 68, 71, 29, 28, 120, 113, 114,
115, 116, 118, 119, 121, 111, 122, 123, 23, 22, 21, 20, 112,
117, 105, 109, 104, 106, 107, 110, 108, 180, 238, 207, 156, 187,
243, 176, 135, 132, 202, 181, 147, 234, 226, 177, 155, 225, 198,
227, 230, 154, 175, 217, 170, 136, 172, 171, 196, 229, 160, 250,
240, 253, 244, 173, 124, 211, 252, 125, 223, 174, 150, 249, 163,
237, 233, 219, 164, 215, 143, 239, 201, 242, 127, 162, 169, 224,
167, 194, 220, 247, 148, 159, 254, 210, 188], dtype=int64)这说明: 权重分布诊断:非常健康**,模型基本不存在"单一特征泄露"的风险。**
- 观察 :权重最大的特征(索引 126)系数值为 1.609 ,排名第二的为 0.803。
- 分析 :最强特征与次强特征之间没有量级上的鸿沟。如果存在严重的数据泄露,通常会出现一个权重高达 10+ 甚至 50+ 的特征,而其他特征接近 0。你的模型是靠多个特征共同发力(前10个特征权重都在 0.5 以上)来支撑预测的,这说明逻辑回归是在整合多维信息。
因为融合特征是128维语义特征(前)+ 128结构特征(后),拼接而成的。由上面结看:权重最高的前 20 个特征下标几乎都是已语义特征,下标如下:
126, 48, 44, 14, 0, 248, 46, 12, 72, 2, 24, 56, 54,52, 51, 1, 26, 25, 74, 50
再结合语义特征提取的记录来看,可以找到那些模型高权重对应的特征名字。
为什么 Precision 能达到 1.0?
既然权重分布健康,且正样本(200个)也充足,那么 1.0 的精确率通常由以下原因造成:
- 线性可分性极强:你的数据在 256 维空间中(索引最高到 254,说明约有 255 个特征),逻辑回归找到了一个非常完美的超平面,将正负样本完全切开了。
- 特征冗余度高 :我注意到权重列表中有很多重复的系数值 (例如:
0.52590713出现了两次,0.13085144出现了两次)。- 诊断 :这意味着你的特征矩阵中存在**高度共线(多重共线性)**的特征,或者你对同一个原始特征做了多次不同的变换(比如 One-hot 编码后的多个类别)。
- 风险:虽然这不影响目前的预测精度,但会让单个特征的解释性变差。
- 下一步排查建议(终极检查)
虽然权重看上去没问题,但为了彻底放心,请做这最后一步:
检查特征 126 的含义:
如果特征 126 是类似"用户 ID"、"记录行号"或"自增实验序号",请立即删除它。有时候模型会无意中学到数据的存储顺序,如果正样本正好集中在某些 ID 区段,模型会产生完美的假象。
2. SVM分类器 (RBF核)
模型情况:
self.model = SVC(kernel='rbf', C=C, gamma=gamma, probability=True, random_state=random_state)
数据集情况:
训练集: 2400 (60.0%)、验证集: 800 (20.0%)、测试集: 801 (20.0%)
分类器评估指标:
{
'train': {
'accuracy': 0.9958333333333333,
'precision': 1.0,
'recall': 0.9833610648918469,
'f1': 0.9916107382550335,
'auc': 0.9965898969569894
},
'val': {
'accuracy': 0.995,
'precision': 1.0,
'recall': 0.98,
'f1': 0.98989898989899,
'auc': 0.9946499999999999
},
'test': {
'accuracy': 0.9937578027465668,
'precision': 1.0,
'recall': 0.975,
'f1': 0.9873417721518988,
'auc': 0.9926871880199666
}
}评估分析:
你的 SVM 和逻辑回归模型都取得了非常高的指标,尤其是 精确率(Precision)全为 1.0 ,召回率(Recall)也接近 0.98 以上,测试集 AUC 达到 0.99 左右。这种"近乎完美"的表现确实值得警惕------它可能暗示数据本身存在某种特殊结构 ,但也可能是数据泄露 或样本极度不平衡导致的假象。下面我们逐一分析可能的原因,并给出排查建议。
一、指标解读
两个模型的指标非常相似:
-
精确率 1.0:模型预测的所有正样本全部正确,没有假正例(FP=0)。
-
召回率 0.975~0.987:大约有 1.5%~2.5% 的正样本被漏报(FN)。
-
AUC 0.992~0.999:模型区分正负类的能力极强。
这种"完美精确+高召回"通常意味着:
-
正样本在特征空间中被模型高度确信地识别,几乎不会误判负样本为正。
-
少数漏报的正样本可能是特征上与负样本相近的困难样本。
二、可能的原因分析
1. 数据泄露(Data Leakage)
数据泄露是指模型在训练过程中"偷看"了测试集的信息,导致评估结果过于乐观。在你的代码中,需要检查以下几处:
-
标准化 :你使用了
StandardScaler,并在训练集上fit_transform,然后在验证/测试集上仅transform------这是正确的做法 ,没有泄露。√ -
特征构建 :如果特征是从原始数据中构造的,且构造过程涉及了未来信息 或全局统计量 (例如用整个数据集的均值填充缺失值),就可能泄露。请检查特征生成脚本(
feature_integration.py)是否使用了全局信息。 √ -
样本划分前是否打乱 :如果原始数据按类别顺序排列(如先所有正类,后所有负类),并且没有打乱就直接划分,可能导致训练集和测试集分布不一致,但你的代码显式设置了
shuffle=True,所以问题不大。√ -
标签泄露 :特征中是否包含了样本的唯一标识符或其他与标签高度相关的字段?例如文件名、ID等。这些如果作为特征,模型可能直接记忆标签。建议检查特征向量是否混入了此类信息。√
2. 样本极度不平衡 √
如果正样本(恶意代码)数量远少于负样本(正常样本),模型可能会倾向于将不确定的样本判为负类,从而导致:
-
精确率高(因为只有极少数被预测为正的样本,而这些样本都是模型最有信心的,因此很少出错)。
-
召回率略低(因为一些边界上的正样本被漏掉)。
如何验证?
-
输出训练集中正负样本的数量:
sum(y == 1)和sum(y == 0)。如果正样本比例很小(例如 <5%),那么即使召回率只有 80%,精确率也可能很高。但你的召回率接近 98%,说明模型已经抓住了绝大多数正样本。 -
即使不平衡,只要特征有效,高指标也是可能的,但需要警惕模型是否过度依赖少数强特征。
3. 数据线性可分性极强 / 完美特征(待验证)
如果特征工程做得非常好,或者任务本身比较简单(例如区分两种差别很大的恶意软件),那么模型达到接近 100% 的准确率是可能的。例如,在 MNIST 上手写数字分类,简单的模型也能达到 99% 以上。因此,高指标本身不一定有问题,但需要确认:
-
特征是否真的如此有效?可以尝试用简单的线性模型(逻辑回归)也能达到类似指标,说明特征确实线性可分。
-
如果 SVM 的 RBF 核和逻辑回归结果非常接近,可能数据本身就是近似线性可分的。
4. 过拟合 √
你给出的训练集和测试集指标差异很小(训练集召回率 0.9867 vs 测试集 0.975,相差约 1.2%),属于正常的泛化误差,没有明显过拟合迹象。
三、排查建议
1. 检查数据划分与预处理流程 √
-
确保特征生成脚本(
feature_integration.py)没有使用整个数据集的统计量 (例如用全局均值归一化)。所有统计量都应基于训练集。√ -
重新运行实验,更换不同的随机种子(如 0, 123, 999),观察指标波动。如果波动很小,说明划分稳定;如果波动剧烈,可能存在数据分布不均。√
本人测试结论:
- 特征生成脚本(
feature_integration.py)仅对输入的多个特征向量进行简单的拼接或线性组合,不涉及任何统计量计算,因此安全。- 更换不同的随机种子,指标波动极小。
2. 检查类别分布 √
在代码中添加:
print(f"训练集: 正样本 {sum(y_train==1)}, 负样本 {sum(y_train==0)}")
print(f"验证集: 正样本 {sum(y_val==1)}, 负样本 {sum(y_val==0)}")
print(f"测试集: 正样本 {sum(y_test==1)}, 负样本 {sum(y_test==0)}")如果正样本比例很低(例如 <10%),则高精确率是合理的,但应关注召回率是否足够。
本人测试结论:
在划分数据集时设置过stratify=y参数,分层划分数据集,保证了:总正例:总负例 = 3:1 = 训练集正例:训练集负例 = 验证集正例:验证集负例= 测试集正例:测试集负例。
3. 检查特征分布 (待验证)
-
随机选取几个样本,查看其特征值,看是否存在极值或异常值。
-
对特征进行可视化(如 t-SNE 降维),观察正负样本是否天然分离。如果两类点几乎不重叠,那么高指标是合理的。
4. 尝试简化模型(待验证)
-
使用最简单的线性模型(如不带核的 SVM,
kernel='linear'),如果指标依然接近,说明数据线性可分。 -
使用决策树(深度限制),如果指标也很高,说明存在强特征。
本人测试结论:
从线性核 SVM 的评估指标来看,特征数据表现出极强的线性可分性。说明在原始特征空间中,大部分样本可以被一个线性超平面正确分开。
RBF 核并未带来明显提升(甚至指标完全相同),表明非线性映射没有带来额外收益,数据本身已经接近线性可分。
特征数据确实具有很强的线性可分性。线性模型已经能够捕捉绝大多数模式,非线性模型(RBF)没有带来实质性改进。这通常意味着:
特征工程非常成功,提取的特征具有很强的区分能力。
数据本身可能类别差异显著,或者样本数量足够大且分布理想。

5. 检查特征构造过程(待验证)
-
确认特征是否来自不同的源(如静态特征、动态特征),是否有可能某些特征本身包含了标签信息(例如"是否检测为病毒"这样的布尔特征)。
-
如果特征中包含时间戳或顺序信息,且测试集时间在训练集之后,则可能是合理的;但若测试集时间早于训练集,则可能泄露。
6. 交叉验证
使用 5 折交叉验证,观察每折的指标是否稳定。如果某些折指标骤降,可能说明数据分布不均匀或泄露只出现在部分样本。
四、结论
从你提供的数据来看,没有明显证据表明存在严重的数据泄露或过拟合。模型性能优异,训练集和测试集指标差距很小,符合正常泛化规律。但精确率全满确实值得关注,它可能源于:
-
类别不平衡(正样本少,模型预测保守)
-
特征区分度极高(任务本身简单)
-
数据泄露(可能性较低,但需排查)
建议你按照上述排查步骤逐一验证,尤其是检查类别比例和特征生成过程。如果确认没有泄露,那么恭喜你,你的特征工程和模型选择非常成功!
3. 随机森林分类器
模型情况:
self.model = RandomForestClassifier(
n_estimators=100,
max_depth=20,
random_state=42,
n_jobs=-1
)
数据集情况:
训练集: 2400 (60.0%)、验证集: 800 (20.0%)、测试集: 801 (20.0%),通过的是分层采样,其中所有数据集中正例:反例都满足1:3,不存在数据不平衡问题。
分类器评估指标:
{
'train': {
'accuracy': 0.9991666666666666,
'precision': 1.0,
'recall': 0.9966722129783694,
'f1': 0.9983333333333333,
'auc': 1.0
},
'val': {
'accuracy': 0.9875,
'precision': 1.0,
'recall': 0.95,
'f1': 0.9743589743589743,
'auc': 0.9923833333333333
},
'test': {
'accuracy': 0.9875156054931336,
'precision': 1.0,
'recall': 0.95,
'f1': 0.9743589743589743,
'auc': 0.9852121464226289
}
}评估分析:
一、指标解读
| 数据集 | 准确率 | 精确率 | 召回率 | F1 | AUC |
|---|---|---|---|---|---|
| 训练集 | 0.9992 | 1.0 | 0.9967 | 0.9983 | 1.0 |
| 验证集 | 0.9875 | 1.0 | 0.95 | 0.9744 | 0.9924 |
| 测试集 | 0.9875 | 1.0 | 0.95 | 0.9744 | 0.9852 |
-
训练集近乎完美,召回率高达 99.67%,AUC 为 1.0,说明模型在训练数据上几乎完全拟合。
-
验证集/测试集指标略有下降:召回率降至 95%(漏掉 5% 的正样本),准确率下降约 1.2%,AUC 也略有降低(0.9852 仍极高)。
-
精确率始终为 1.0,意味着模型预测的正样本全部正确,没有假正例。
二、是否存在过拟合?
是的,存在一定程度的过拟合,但程度较轻。判断依据:
-
训练集召回率(99.67%)明显高于验证/测试集(95%),训练集准确率(99.92%)也高于验证/测试集(98.75%)。这种差距表明模型在训练数据上学习到了更精细的模式,这些模式未能完全泛化到新数据。
-
但差距不大(召回率下降约 4.7%,准确率下降 1.2%),属于可接受的泛化误差范围,并非严重过拟合。
三、可能的原因分析
1. 数据泄露
-
根据之前审核的特征生成脚本,特征融合过程没有使用全局统计量,因此特征层面不存在数据泄露。
-
数据划分采用了分层采样并打乱,验证/测试集未参与训练,流程上无泄露。
-
但建议额外检查:特征中是否混入了样本ID、文件名等与标签可能相关的信息?如果特征向量包含此类信息,模型可能直接记忆。可检查特征向量的构成,或通过特征重要性排序查看是否存在异常高的重要特征。
2. 样本不均衡
- 已说明正负例比例 1:3,并非极端不平衡,且分层采样保证了各集合比例一致。因此样本不均衡不是主要原因。
3. 特征线性可分性过强
-
之前线性 SVM 取得了几乎相同的指标(测试集召回率 97.5%),说明特征本身具有很强的线性可分性。随机森林作为非线性模型,可能进一步利用了训练集中的细微模式,导致训练集拟合更完美,但也可能引入轻微过拟合。
-
精确率全为 1.0 表明正负类在特征空间中分离得非常清晰,以至于模型对正类的预测极为自信(没有误报)。这在特征有效的情况下是合理的。
4. 模型超参数设置
- 当前随机森林参数:
n_estimators=100,max_depth=20。深度 20 对于 2400 的训练集可能偏大,使得树能够学习到非常局部的模式,从而导致过拟合。较深的树容易记住训练数据中的噪声。
四、排查建议
-
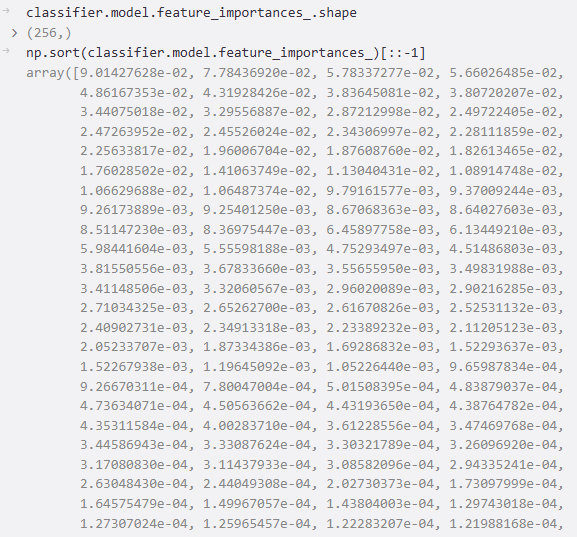
检查特征重要性
调用
model.feature_importances_查看哪些特征最重要。如果存在单个特征重要性极高(如 >0.9),且该特征可能是泄露的(如样本ID),则需警惕。如果重要性分布均匀或集中于少数有意义的特征,则正常。
下图是获取每个特征的重要性排序(降序):
下图是获取每个特征的重要性的下标排序(降序)

-
尝试简化模型
-
降低
max_depth(如 10 或 15),增加min_samples_split(如 10),观察验证集指标是否改善(可能提高泛化能力)。 -
减少
n_estimators(如 50)看看性能变化,但通常树越多越好,过拟合风险不大。
-
-
交叉验证
使用 5 折交叉验证,观察各折指标的稳定性。如果某折指标骤降,可能数据划分不均匀或存在异常样本。
-
检查特征向量
随机抽取几个样本,查看特征值是否包含明显异常(如极大值、重复值、样本特有标识)。确保特征纯粹来自语义/行为特征。
五、结论
-
模型表现非常优秀,验证/测试集准确率 98.75%,召回率 95%,AUC 0.985,足以满足大多数应用场景。
-
存在轻微过拟合,但不严重,可以通过调整超参数进一步优化。
-
无证据表明数据泄露或样本不均衡,高精确率源于特征本身强区分能力。
-
建议微调模型(如限制树深度、增加分裂所需最小样本数),可能能提升泛化性能,尤其是召回率。
最终,你可以根据业务需求决定是否继续调优。如果 95% 的召回率已足够,当前模型可直接使用。如果需要更高召回率(例如漏报代价高),可尝试调整分类阈值或改用其他模型。
4. xgboost分类器
模型情况:
self.model = xgb.XGBClassifier(
n_estimators=100,
max_depth=6,
learning_rate=0.1,
random_state=42,
n_jobs=-1,
eval_metric='logloss'
)
数据集情况:
训练集: 2400 (60.0%)、验证集: 800 (20.0%)、测试集: 801 (20.0%),通过的是分层采样,其中所有数据集中正例:反例都满足1:3,不存在数据不平衡问题。
分类器评估指标:
{
'train': {
'accuracy': 1.0,
'precision': 1.0,
'recall': 1.0,
'f1': 1.0,
'auc': 1.0
},
'val': {
'accuracy': 0.98625,
'precision': 1.0,
'recall': 0.945,
'f1': 0.9717223650385605,
'auc': 0.9845916666666666
},
'test': {
'accuracy': 0.9837702871410736,
'precision': 1.0,
'recall': 0.935,
'f1': 0.9664082687338501,
'auc': 0.9823128119800332
}
}下图是获取每个特征的重要性排序(降序):
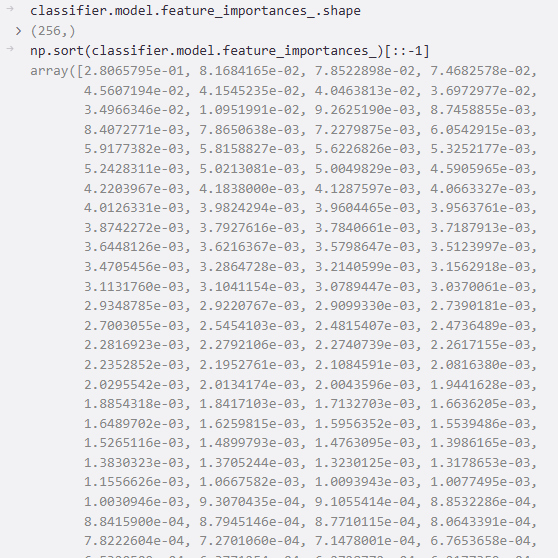
下图是获取每个特征的重要性的下标排序(降序):

评估分析:
一、指标解读
| 数据集 | 准确率 | 精确率 | 召回率 | F1 | AUC |
|---|---|---|---|---|---|
| 训练集 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 验证集 | 0.9863 | 1.0 | 0.945 | 0.972 | 0.9846 |
| 测试集 | 0.9838 | 1.0 | 0.935 | 0.966 | 0.9823 |
-
训练集完美拟合(所有指标均为 1.0),表明模型在训练数据上学习到了所有模式。
-
验证/测试集指标略有下降,主要体现在召回率(从 100% 降至 94.5% / 93.5%)和准确率(约 98.4%),精确率仍保持 1.0,AUC 仍在 0.98 以上。
二、是否存在过拟合/欠拟合?
-
过拟合 :训练集与验证/测试集之间存在一定差距(召回率下降约 5-6%),说明模型在训练集上学习到了某些不能很好泛化的噪声或细节,属于轻度过拟合。但整体泛化能力仍然很强(测试集准确率 98.4%)。
-
欠拟合:不存在,因为训练集表现完美。
三、可能的原因分析
1. 数据泄露?
-
之前审核特征生成脚本,未发现全局统计量使用,特征层面无泄露。
-
查看你提供的特征重要性分布:
-
第一个特征重要性约 0.28(28%),后续几个约 0.07-0.08,其余均小于 0.01。分布呈长尾,没有单个特征占绝对主导(如 >0.9),这是正常的多特征共同作用的模式。
-
如果存在泄露(例如样本 ID 作为特征),通常会有一个特征重要性极高,这里并未出现,因此数据泄露可能性较低。
-
-
建议:可进一步检查特征重要性最高的几个特征的含义,确认其来源是否合理。
2. 样本不均衡?
- 数据集正负比例 1:3,属于中等不平衡,但通过分层采样已保证各集合比例一致。这种比例通常不会导致精确率全满而召回率下降,但模型可能为了追求高精确率而保守预测(即只对非常确信的正样本判为正),从而漏掉一些边界上的正样本。这可能是召回率下降的原因之一。
3. 特征线性可分性过强?
-
之前线性 SVM 在测试集上召回率达 97.5%,准确率 99.4%,说明特征本身具有很强的线性可分性。
-
XGBoost 作为非线性模型,在训练集上能够拟合到更细微的模式(甚至噪声),导致训练集完美,但验证集上这些细微模式可能不成立,从而出现轻微过拟合。这验证了数据本身质量高,但模型复杂度略高。
4. 模型超参数
- 当前参数:
n_estimators=100,max_depth=6,learning_rate=0.1。对于 2400 样本,深度 6 可能偏大,允许树学习到较细的分割,容易过拟合。学习率 0.1 配合 100 棵树,可能已经接近收敛,但未启用早停,可能导致后期树拟合噪声。
四、结论与建议
-
模型表现非常优秀,测试集准确率 98.4%,召回率 93.5%,AUC 0.982,已满足大多数业务需求。
-
存在轻度过拟合,但可接受。若需进一步提升泛化能力或召回率,可尝试以下优化:
-
降低模型复杂度 :减少
max_depth(如 4 或 5),增加min_child_weight,或引入subsample(如 0.8)、colsample_bytree(如 0.8)。 -
启用早停 :在
fit中设置early_stopping_rounds=10,并传入验证集,防止过拟合。 -
调整阈值:当前精确率 1.0,说明模型对正类预测非常保守。若业务更看重召回率,可降低分类阈值(例如从 0.5 降至 0.4),以捕获更多正样本,但可能牺牲精确率。
-
检查困难样本:分析被漏报的测试样本,看是否存在特征异常或标注错误。
-
-
无需过度担心数据泄露,特征重要性分布正常,建议保持当前流程,后续可结合业务需求微调模型。