工业数据基础设施正在经历一场深刻的变革。
在过去几十年中,工业实时数据库一直是工业运行体系的核心基础设施。它解决了工业计算中最关键、也最困难的问题之一:如何从设备与控制系统中持续采集、存储,并高效访问海量的时序数据。像 PI System 这样的系统,已经成为工厂、电厂和炼化企业中不可或缺的一部分。
但如今,工业数据所处的环境已经发生了变化。现代 IT 架构、云计算,以及人工智能的发展,正在重新定义企业对运行数据的使用方式。问题不再只是"如何存储数据",而是"如何从数据中获得洞察、形成智能,并支持决策"。
与此同时,另一个问题也变得越来越明显:许多传统工业实时数据库是以相对封闭的体系构建的,这使得工业数据很难融入现代 IT 基础设施之中。
要理解工业数据基础设施将走向何方,首先需要回到它的起点。
工业实时数据库的诞生
工业实时数据库诞生于上世纪 80 年代末至 90 年代初,当时工业自动化系统开始产生海量运行数据。
来自传感器、PLC 和 SCADA 系统的数据,会持续不断地生成时间序列信号,例如温度、压力、流量以及设备状态等。传统的关系型数据库并不适合处理这类数据:
-
高频时序数据
-
持续不断的数据流写入
-
海量数据规模
-
长周期历史存储
工业实时数据库正是为了解决这一问题而诞生的。它们提供了专门针对时序数据优化的存储引擎,用于支持高效的数据写入、压缩和查询。
这使得工业企业第一次可以长期保存运行历史数据,并基于这些数据进行故障排查、性能分析和持续优化。
工业实时数据库做对了什么
工业实时数据库之所以能够成为工业系统的核心基础设施,是因为它在下面几个关键方面表现非常出色。
-
可靠的时序数据存储:工业实时数据库能够持续接收高吞吐的数据流,并通过高效压缩实现长期存储。
-
与工业系统的集成能力:它可以直接对接 SCADA 系统、PLC 和各类工业协议,使数据采集过程简单可靠。
-
长期运行可视能力:工程师可以回看数月甚至数年的历史数据,用于分析问题和理解系统行为。
-
运行监控能力:操作人员可以通过趋势图和仪表盘观察系统状态。
正是这些能力,使工业实时数据库在几十年的时间里成为工业领域最重要的基础设施之一。
然而,这类系统本质上是作为一个相对封闭的运行系统设计的,而不是一个面向开放生态的数据平台。
工业实时数据库的典型架构
典型的工业实时数据库通常采用分层架构。以 PI System 为例,其系统中通常包含几个核心组件。
暂时无法在飞书文档外展示此内容
Data Archive
系统的核心是 Data Archive,用于存储来自工业设备的时序数据。
其主要职责包括:
-
高吞吐数据写入
-
时序数据压缩
-
长期历史存储
-
高效查询
这一组件解决的是工业数据存储的核心问题。
数据采集接口
工业实时数据库依赖一组接口来连接工业设备与系统。
这些接口可以从以下来源采集数据:
-
OPC / OPC-UA
-
PLC 与控制器
-
SCADA 系统
-
各类工业通信协议
这些接口会持续将现场数据流写入数据库。
但这些接口往往是厂商定制或专有实现,使得系统与其他数据平台的集成变得更加复杂。
资产模型(Asset Framework)
现代工业实时数据库中一个重要的创新是资产模型(AF)。
它不再以"信号列表"为中心,而是以工业设备和资产为组织方式。
例如:
暂时无法在飞书文档外展示此内容
这种以资产为中心的结构,使运行数据更容易被工程师理解。
分析与事件检测
工业实时数据库通常提供分析能力,使工程师可以在数据上定义计算逻辑与检测规则。
这些能力包括:
-
派生计算
-
KPI 指标
-
规则驱动分析
-
事件检测(例如 Event Frames)
这一层使原始数据可以转化为有意义的运行信息。
可视化工具
最后,可视化工具(如 PI Vision)为操作人员与工程师提供趋势图、仪表盘与报表。
这些工具构成了工业数据的人机交互界面。
在很长一段时间里,这种架构运行良好,并成为工业数据管理的标准模式。
但工业数据环境已经发生变化。
世界已经改变
在过去十年中,IT 基础设施发生了巨大的变化。
企业运行在以下环境中:
-
云计算
-
分布式数据平台
-
实时数据管道
-
机器学习
-
AI 驱动分析
工业企业也越来越希望:
-
将运行数据与企业系统打通
-
进行高级数据分析
-
构建预测模型
-
实现实时决策
然而,传统工业实时数据库并不是为开放数据生态设计的。将其中的数据接入现代系统,往往需要额外接口、定制集成或数据复制流程。结果是,工业数据仍然被隔离在系统内部。
OT 与 IT 融合的尝试
在过去十年中,许多企业意识到工业数据的价值远不止于运行监控,开始尝试弥合 OT 与 IT 之间的差距。
这一时期出现了大量工业物联网平台,云厂商也相继推出了面向工业数据接入的托管服务。与此同时,Databricks、Snowflake 等现代数据平台凭借强大的扩展性和分析能力,开始进入工业企业的视野。许多企业尝试将历史数据导出,接入这些平台,希望借助现代数据工具释放工业数据的价值。
但结果普遍令人失望。
问题并不在于这些平台能力不足。恰恰相反,它们在数据处理规模、机器学习集成、查询性能等方面都非常强大。问题在于,它们是为数据工程师设计的,而不是为工艺工程师或操作人员设计的。构建数据管道、定义数据模式、编写复杂查询------这些工作对 IT 团队来说是日常,但对 OT 工程师来说却意味着陡峭的学习曲线和沉重的运维负担。
更根本的问题是:工业数据在离开原始系统之后,往往也失去了它的上下文。
一个温度读数,在工厂现场的意义是清晰的------它属于某台压缩机,处于某个工艺阶段,发生在某次计划停机之前。但当这个数字被导入通用数据平台之后,它变成了一行记录,一个浮点数。设备归属、工艺流程、运行状态、关联事件------这些让数据具有意义的上下文,在迁移过程中悄然丢失。
工程师为了分析一个异常,不得不先花大量时间重建数据关系,手动关联设备台账、查阅工艺记录、比对事件日志。分析本身反而成了次要工作。
这也是为什么大量 OT 与 IT 融合项目停留在概念验证阶段,始终无法真正落地。弥合这道鸿沟,靠的不是更强的数据平台,而是一套能够在工业现场原生保存数据上下文的架构。这正是传统工业实时数据库和通用数据平台共同缺失的东西,也是 AI 时代工业数据底座必须解决的核心问题。
在 AI 时代,这一问题更加突出
在 AI 时代,这些问题被进一步放大。
AI 并不只是需要数据量,它更需要具备上下文的数据。
温度、压力、振动这些信号,只有在系统能够理解以下内容时才有意义:
-
数据来自哪个设备
-
所属工艺流程
-
发生了哪些事件
-
设备运行行为
如果缺乏这些上下文,AI 很难产生有效洞察。这也是为什么许多工业 AI 项目难以落地。
下一阶段:AI 原生工业数据底座
工业数据基础设施正在进入一个新的阶段。
这一演进可以总结为三步:
暂时无法在飞书文档外展示此内容
一个现代工业数据底座需要具备以下能力:
-
高性能时序数据存储
-
以资产为中心建模
-
实时流处理
-
事件建模
-
现代的可视化
-
高级分析能力
-
AI 集成能力
-
开放架构
系统的目标不再只是存储数据,而是将数据转化为洞察、预测与决策。
同样重要的是,系统必须是开放的,使工业数据能够自然融入企业数据平台、分析工具和 AI 系统。
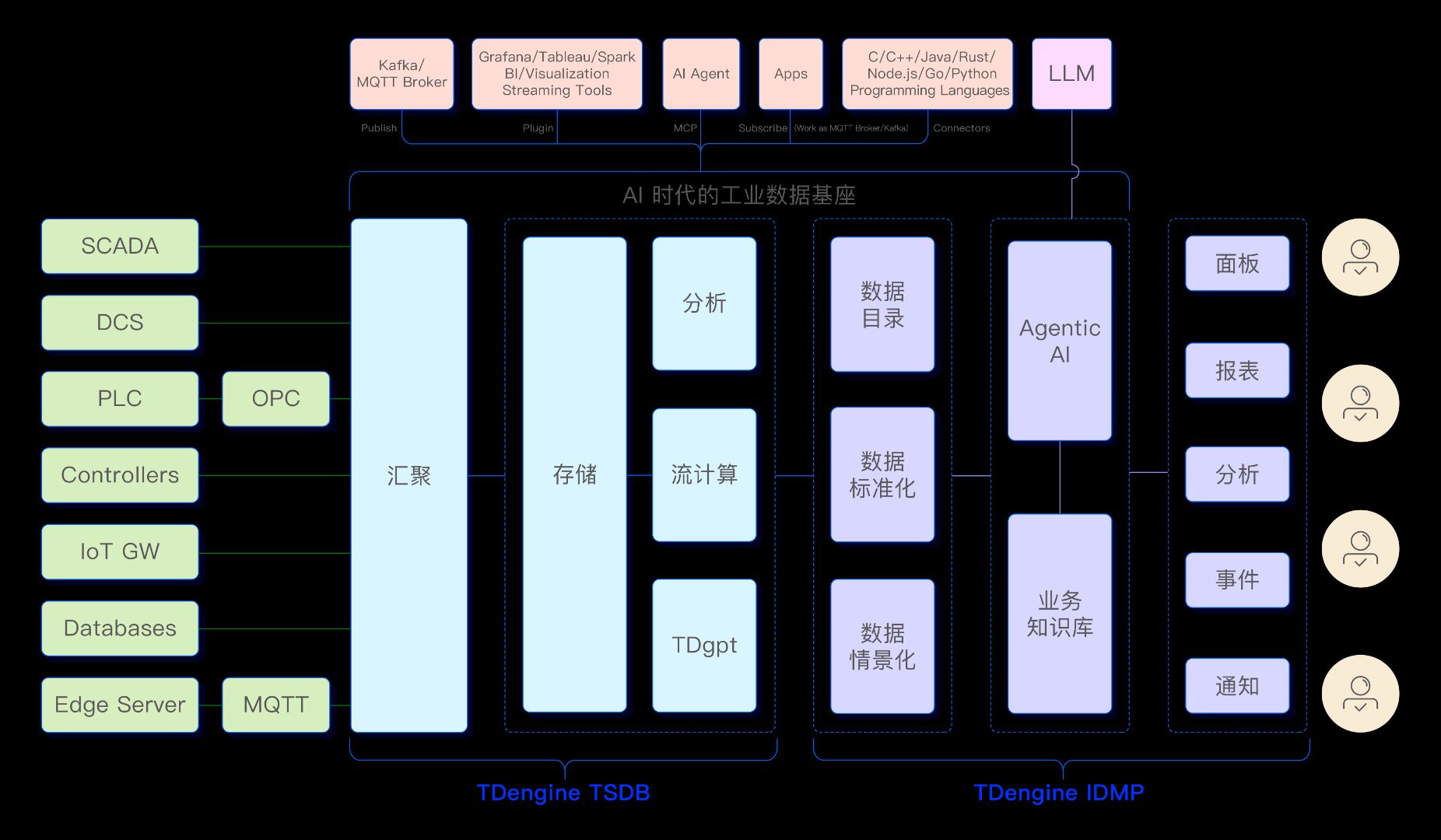
TDengine 的定位
涛思数据成立于 2017 年,从第一天起就只做一件事:为工业和物联网场景构建一款高性能、可水平扩展的时序数据库。这款产品------TDengine 时序数据库------如今已在全球六十多个国家和地区累计部署超过一百万个实例,用户涵盖高速成长的制造企业,以及全球最大的一批能源、汽车和新能源公司。
但正如这个系列将要论证的,一款高性能时序数据库是必要的基础,而不是完整的答案。两年前,我们开始构建 TDengine IDMP------一个 AI 原生的工业数据管理平台,它运行在时序数据库之上,专门解决纯时序引擎无法回答的问题:资产建模、数据标准化、数据情景化、事件分析、高级数据分析,以及 AI 驱动的运营洞察。
TSDB 与 IDMP 结合在一起,构成了我们认为 AI 时代工业数据基座应有的形态------不是一个把数据锁在专有格式里的封闭系统,而是一个开放的数据底座:既保留工程师所依赖的运营上下文,又让数据能够自然流向现代 IT 系统、分析工具和 AI Agent。
这不是一个保守的目标。工业数据基础设施市场被几个建立在旧假设之上的系统主导了几十年------关于存储成本的假设,关于数据规模的假设,关于 AI 角色的假设,关于"开放"意味着什么的假设。我们认为,这些假设需要被替换,而不是被修补。
在接下来的系列文章中,我们将逐一拆解这场变革的每个维度:资产建模如何改变工业数据的组织方式和理解方式,为什么事件分析在 AI 时代比以往任何时候都更加重要,哪些高级分析能力应该内建于平台而不是外挂附加,以及为什么开放性不只是一项功能,而是任何希望在 AI 重塑工业运营的时代保持相关性的系统的前提条件。
这个系列的目标不是推销一款产品,而是阐明一个判断:工业数据基础设施正站在一个拐点上。那些早早认清这一点的企业和厂商,将对那些还没有意识到的人拥有巨大的先发优势。
未来的软件形态:Agent Interface + 数据基座
在 AI 时代,工业软件的形态本身也正在发生变化。
过去,工业系统由多个独立软件构成:SCADA、MES、工业实时数据库、报表系统。每个系统都有自己的界面与逻辑,工程师需要在多个系统之间切换。
但未来的软件形态将发生根本变化。
AI 正在成为新的交互方式。工程师不再通过复杂界面操作系统,而是通过自然语言与系统交互,由 AI 自动完成查询、分析与解释。
在这种模式下:软件的"界面"正在变成 AI Agent,系统的核心,变成底层的数据基座。
换句话说:未来的软件形态是:Agent Interface + 数据基座
AI Agent 负责理解问题与生成洞察,数据基座负责提供完整、实时、有上下文的数据。
如果没有数据基座,AI 就没有智能。系统的核心不再是应用,而是数据本身。
关键结论
工业实时数据库解决了数据"可用"的问题。
但在 AI 时代,不仅数据规模大幅增加,仅仅存储数据已经远远不够。
企业需要的是一个开放、可扩展、AI 原生的数据底座,它能够理解资产、事件与运行上下文,从而支撑下一代工业智能系统。
传统工业实时数据库让数据可用,现代数据平台让数据可扩展,而 AI 原生数据底座让数据真正被理解