
在工业互联网、物联网、能源大数据、智能网联等场景持续落地的背景下,时序数据已经成为工业大数据体系中占比最高、增长最稳定的数据类型。传感器测点、设备工况、电网运行、车辆状态、气象观测、金融行情等数据,均具备时序递增、写入密集、冗余度高、长期留存、多维度聚合分析的典型特征。
传统关系型数据库、通用NoSQL存储、普通大数据组件,均是为通用业务数据设计,无法适配时序数据的高频写入、海量存储、低延迟查询、乱序兼容等专属诉求。因此,搭建工业大数据平台、物联网监控系统、设备运维分析平台时,专用时序数据库的选型,直接决定系统的稳定性、资源开销与长期扩展性。
目前开源与商用时序数据库品类繁多,海外产品生态成熟但存在本地化适配不足、边缘部署笨重、成本高昂等问题;国内部分产品存在迭代不稳定、工业场景适配薄弱、生态不完善等短板。本文从技术架构、场景适配、性能指标、运维成本、生态兼容五个技术维度,总结一套可落地的时序数据库选型标准,并结合开源时序数据库Apache IoTDB的技术特性,分析其在工业大数据场景的适配价值,为开发者和架构师选型提供参考。
一、工业时序数据库核心选型指标
时序数据库选型切忌只参考公开跑分,需结合工业真实业务痛点,聚焦写入适配、存储效率、查询能力、部署架构、生态兼容、迭代稳定性六大核心技术指标,规避落地踩坑。
1. 高并发写入与非有序数据兼容能力
工业现场普遍存在网络抖动、设备离线重连、终端时钟漂移等问题,会产生大量乱序、延时、重复的时序数据。优质的时序数据库,需原生支持高批量写入,无需业务层做数据排序、清洗预处理,同时支持海量测点、海量设备并发接入,适配毫秒、微秒级高频采集场景,保障高负载下的写入稳定性。
2. 专属存储压缩机制,控制长期存储成本
工业时序数据留存周期长,普遍需要3-10年全量数据归档,存储成本是长期运维的主要开销。通用存储压缩算法对时序数据适配性差,而专业时序数据库需搭载时序专属文件格式与编码压缩策略,针对时间戳、连续数值、状态量数据做定向优化,大幅降低磁盘占用,减少服务器与存储硬件投入。
3. 低延迟查询与专业时序分析能力
实时监控告警、设备故障回溯、趋势分析、能耗统计、工况研判等业务,对查询延迟要求严苛。合格的时序数据库需支持最新值毫秒级查询、大范围历史数据秒级检索,同时内置降采样、插值、滑动窗口、时序对齐、聚合统计等专属分析能力,无需依赖额外中间件即可完成基础时序计算。
4. 端边云一体化部署架构适配
现代工业大数据架构呈现"边缘采集缓存、云端汇聚计算、全局统一分析"的分层模式。时序数据库需要同时适配轻量化边缘部署 与大规模集群云端部署,低资源占用适配边缘网关、工控机等终端设备,集群模式支持线性扩容,满足海量数据长期增长需求。
5. 大数据生态兼容性
时序数据并非孤立存储,需要与大数据计算、可视化监控、数据治理组件打通。选型需重点关注数据库是否兼容主流开源生态,可无缝对接大数据计算引擎、可视化工具、数据仓库组件,降低架构改造与二次开发成本,适配企业现有大数据技术栈。
6. 持续迭代与开源合规性
工业核心业务对系统稳定性、安全性、可扩展性要求极高。优先选择社区活跃、版本迭代稳定、开源协议商业友好、无版权风险的产品,同时具备完善的版本升级方案、问题修复机制,适配国产化软硬件生态,满足企业长期数字化建设需求。
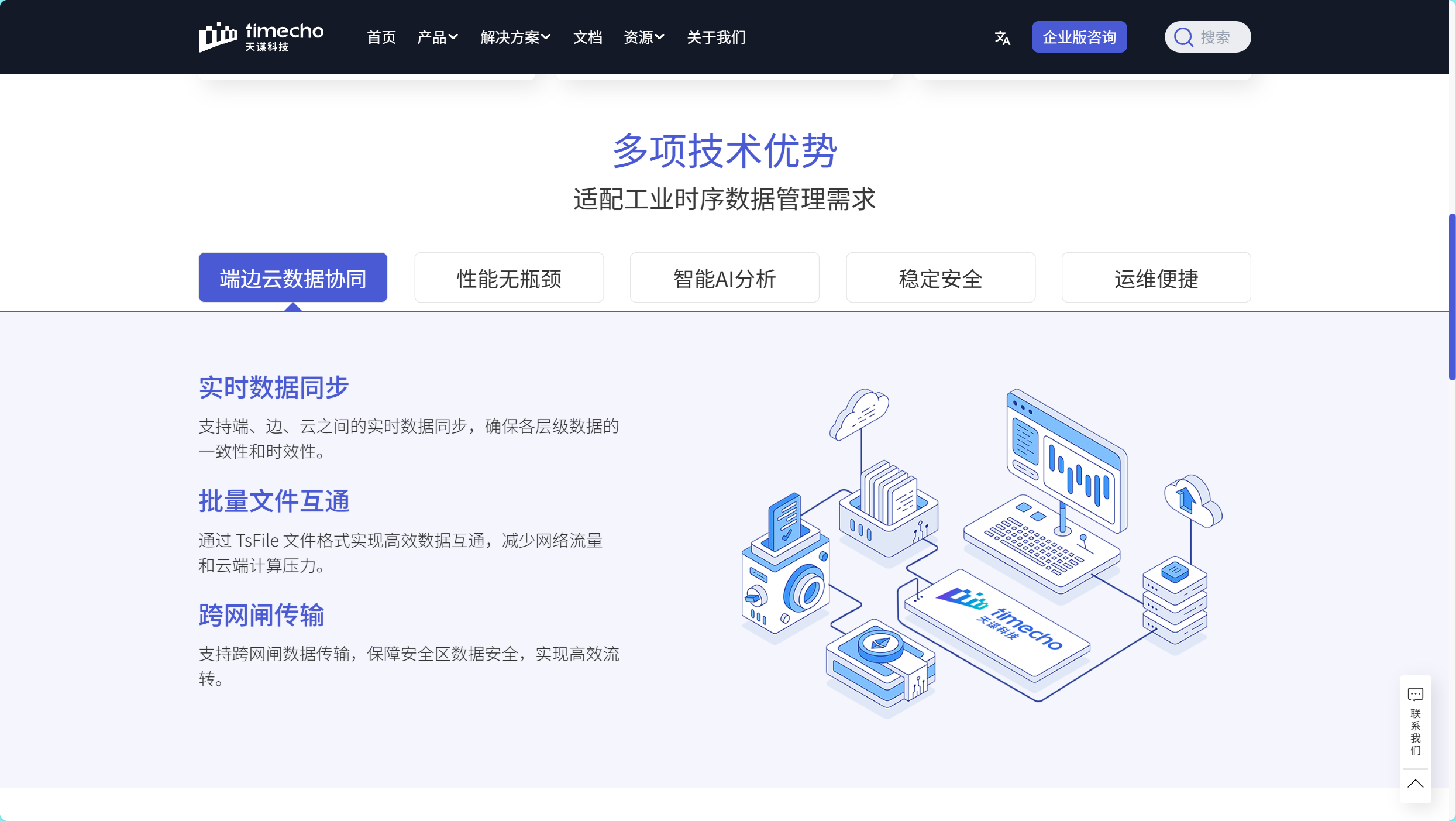
二、Apache IoTDB 核心技术架构与场景适配优势
Apache IoTDB 是 Apache 基金会旗下顶级开源时序数据库项目,专为物联网、工业大数据场景设计,依托自研底层存储架构,针对性解决传统时序数据库在工业场景的适配短板,在架构设计、场景适配、生态兼容上具备鲜明的技术优势。
1. 自研时序存储架构,适配工业高并发写入
IoTDB 自研专属时序文件格式 TsFile,搭配优化后的 LSM-Tree 存储架构,摒弃通用存储架构的冗余逻辑,全程采用追加写入模式,规避随机IO瓶颈,完美契合时序数据有序写入的核心特征。同时原生优化乱序数据、延时数据处理逻辑,无需业务层预处理,适配工业现场复杂的网络环境与采集场景,高负载下写入稳定性优异。
2. 高压缩存储设计,降低长期运维开销
基于 TsFile 专属时序存储格式,IoTDB 针对不同类型时序数据适配差异化编码与压缩算法,对连续数值、布尔状态、文本告警等数据做定向优化,有效压缩时序数据冗余。在海量测点、长期数据留存的工业场景中,能够显著降低磁盘存储空间占用,减少硬件扩容频次,降低整体运维成本。
3. 树表双模型,贴合工业层级业务结构
区别于通用时序数据库的单一标签模型,IoTDB 采用树模型+表模型双架构设计。树模型天然适配工业"工厂-车间-设备-测点"的层级拓扑结构,支持通配符批量查询,贴合工业设备管理逻辑;表模型兼容标准SQL语法,适配传统大数据开发习惯,降低开发人员上手成本,兼顾场景适配性与易用性。
4. 轻量化全场景部署,适配端边云架构
IoTDB 极致优化资源占用,边缘部署模式下仅需极低内存即可稳定运行,可部署在工控机、边缘网关等低资源终端,满足边缘数据本地缓存、预处理需求。云端支持集群部署,支持秒级扩容,无需复杂数据迁移,适配企业从边缘采集到云端汇聚的一体化大数据架构。
5. 完善的版本迭代与升级体系
经过多年迭代,IoTDB 形成了规范的版本更新与升级方案,针对不同大版本、小版本提供清晰的升级路径,解决版本迭代兼容性问题。其中小版本之间完全兼容,可直接替换升级;跨大版本针对语法、API、目录结构的不兼容改动提供明确适配方案,同时持续优化SQL语法、Session接口、字符串转义逻辑,统一接口处理规范,提升系统稳定性与一致性。
6. 开源友好,生态兼容性完善
IoTDB 基于 Apache 2.0 开源协议,商业友好、无版权绑定,支持自由部署、二次开发与商用。项目社区活跃,版本持续迭代,兼容Spark、Flink、Hadoop、Grafana等主流大数据与监控生态,同时提供Java、Python、C++、Go等多语言SDK,适配不同技术栈的开发需求,融入企业现有大数据架构无门槛。

三、工业大数据场景适配总结
结合工业时序数据的核心痛点与选型标准来看,通用型时序数据库大多侧重云端场景优化,对边缘部署、工业层级结构、乱序数据适配、长期存储成本控制等场景考虑不足。而 Apache IoTDB 从底层架构出发,针对性适配工业物联网、能源电力、轨道交通、智能制造、气象金融等海量时序场景,解决了传统存储方案在高并发、高冗余、分层部署、复杂拓扑场景下的各类问题。
对于企业架构师与开发人员而言,时序数据库的选型核心是场景匹配优先、技术适配优先、长期稳定优先。在国产化适配、端边云一体化架构普及、海量时序数据爆发的当下,贴合工业场景、开源稳定、生态完善、运维成本低的时序存储方案,更适配企业长期数字化建设需求。
四、资源获取说明
Apache IoTDB 开源版本持续迭代更新,开发者可通过官方渠道获取最新安装包、源码、校验文件及完整技术文档,用于学习、测试与项目落地:https://iotdb.apache.org/zh/Download/
面向企业生产级高可用、定制化运维场景的进阶能力,可参考原厂技术服务相关介绍:https://timecho.com
五、总结
工业大数据时序数据库的选型,核心是摒弃单一性能跑分的片面判断,聚焦业务真实痛点,从写入适配、存储成本、查询能力、部署架构、生态兼容、迭代稳定性多个维度综合评估。
Apache IoTDB 凭借自研时序存储架构、树表双模型设计、轻量化端边云部署、高压缩存储、完善的开源生态与版本迭代体系,精准适配工业海量时序数据的存储与分析需求,能够有效解决传统存储方案的适配短板与运维痛点,是工业大数据、物联网时序场景中具备高实用性、高稳定性、高性价比的开源存储方案。