在工业数字化持续深入的今天,一个变化愈发明显:企业开始重新审视数据基础设施的价值。 当设备越来越多、数据越来越密、实时决策需求越来越强,过去够用的工业数据系统正在面临新的挑战,时序数据库开始走进人们的视野,成为越来越多企业的选择。
为什么现在越来越依赖时序数据库?
过去很长一段时间里,工业企业的数据系统更多依赖 PLC、SCADA、关系型数据库以及工业 Historian(如 PI System)等架构:设备采集数据、平台做监控、数据库存历史记录,再定期生成报表。在那个时代,数据量不大、采集频率有限、分析需求简单,"能存、能查、能出报表"已经足够。
但现在,底层逻辑正在发生变化。
首先,最明显的变化是数据规模。
一条现代化产线可能包含数万个测点,一个大型电厂可能部署数十万传感器,新能源汽车、储能、电网等行业更已进入百万级设备时代。与此同时,数据采集频率也在提高------从分钟级到秒级,甚至毫秒级采样逐渐成为常态。单个工厂每天新增 TB 级数据,已经不再罕见。
其次,业务需求也在发生变化。
过去,工业数据更多用于事后分析;现在,企业希望数据能够参与实时决策。设备故障需要秒级预警,生产参数需要动态优化,跨工厂协同需要实时感知状态,预测性维护、数字孪生、工业 AI 等新应用,更要求系统持续提供稳定、高质量的时序数据。
工业系统处理的,已经不再是数据库中的记录,而是持续不断的数据流。
这意味着,传统通用数据库架构开始显得笨重------它们擅长事务处理,却不擅长海量时序数据的持续写入、高压缩存储和实时分析。时序数据库由此从可选工具逐渐变成工业数字化的关键基础设施。
但新的问题又出现了:当时序数据库快速普及后,光是能用已经不够了。
为什么"能用"的时代正在结束?
时序数据库的第一阶段目标是解决接收数据、查询历史记录、支持基础分析的需求。这意味着产品至少具备了替代能力。
但当数据规模从 GB 上升到 TB、PB 时,传统数据库的问题会迅速暴露:写入性能下降、查询延迟上升、存储成本飙升。一旦高频设备同时上报,系统很容易出现数据堆积甚至延迟失控。
而决策、预警这类关键场景最怕的恰恰是慢。设备异常预警晚一分钟,可能意味着停产损失;电网负荷调节慢几秒,可能引发系统波动......与此同时,企业也希望直接在实时数据上完成异常检测、趋势预测、设备健康评估乃至 AI 推理。但许多传统方案依旧停留在"采---存---算"分离架构:设备数据进入消息系统,经过 Kafka 缓冲,写入时序数据库,再同步到 Spark、Flink 或 Python 环境完成分析。
这类方案在工业级压力下短板明显:
-
写入性能拉胯:高并发下写入吞吐骤降,甚至在边缘端测点批量上报时出现数据丢失或延迟堆积
-
存储效率低:缺乏针对时序数据特性的高效编码与压缩算法,原始数据存储膨胀严重,长期持有成本飙升
-
协议兼容差:无法直连 OPC UA/DA、MQTT 等主流工业协议,需要额外转发组件,增加系统复杂度和故障点
-
分析能力弱:只解决了存的问题,分析仍需将数据导出到 Python/Spark 等外部引擎,实时性大打折扣
-
跨平台迁移难:不同系统间的数据格式与模型不统一,历史数据难以平滑迁移到新平台,容易形成数据孤岛
于是,国产时序数据库进入了新的竞争阶段:从能用转向好用。
怎样才算真正的好用?
对于工业企业而言,好用意味着数据库在场景适配、存算效率、运维体验三个维度同时达标:
-
全场景数据接入:从 OPC UA 到 MQTT、从边缘到云端,数据通路通畅,减少集成适配成本
-
高效存算一体:简化技术栈,降低跨平台数据迁移成本,避免数据反复搬运带来的延迟与开销
-
低门槛生产运维:自动化部署、可视化监控、智能诊断,并支持利用 AI 以自然语言编写业务脚本,大幅降低编程门槛
在国产化替代与自主可控的趋势下,越来越多工业企业开始关注本土自研的数据库产品。DolphinDB 作为完全自研的国产时序数据库,从四个维度实现了真正的好用:
存储引擎:列式存储 + 两级分区 + 自适应压缩
时序数据的天然特性是写入连续、查询按时间范围和标签过滤。DolphinDB 的存储引擎围绕这一特性做了三层针对性设计:
-
列式存储:按列而非按行组织数据,同列数据类型一致,天然适合压缩和向量化计算。
-
两级分区机制:数据库首先按时间(天/月/年)分区,再按标签(设备 ID、测点编号等)进行二级分区。查询时只需扫描相关分区而非全表。
-
自适应压缩:针对不同类型的时序数据,自动选择最适配的编码压缩算法。在工业客户的实际场景中,DolphinDB 的压缩比通常达到 10:1~20:1。
计算引擎:向量化 + 分布式 SQL + 内置分析函数
DolphinDB 让计算尽量靠近数据:
-
向量化执行:计算引擎基于列式存储逐列操作,对于移动平均、滑动窗口等时序场景的常见操作,性能相比行式引擎提升 5~10 倍。
-
分布式 SQL:SQL 语法兼容性强,支持窗口函数、滑动聚合、Pivot 等时序场景的高频操作。查询自动下推到各数据节点并行执行,对用户透明。
-
2000+ 内置函数:覆盖时间序列分析(移动平均、指数平滑、FFT)、流式计算(事件时间窗口、累计聚合)、机器学习(KMeans、XGBoost、ARIMA)等场景。
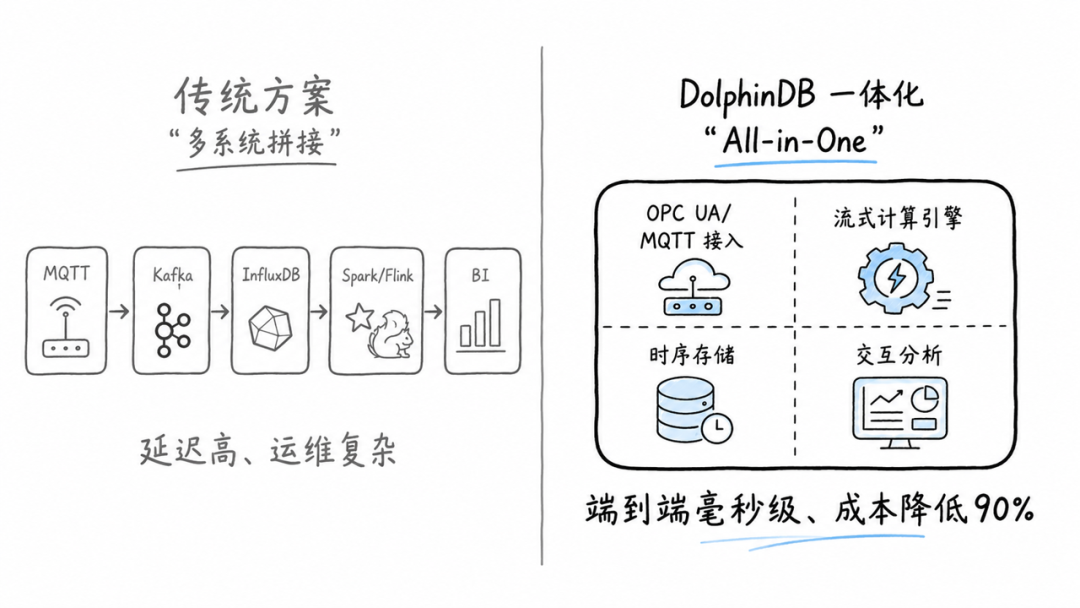
一体化架构:告别多系统拼接
DolphinDB 将消息订阅、实时写入、流式计算、时序存储、交互分析整合为一个平台。某大型水务集团用这套架构替换了原有的"SQL Server + InfluxDB + Kafka + RabbitMQ"多系统方案后,省去了超八成的运维组件,存储与计算资源成本降低 90%,告警响应从分钟级缩短至秒级。
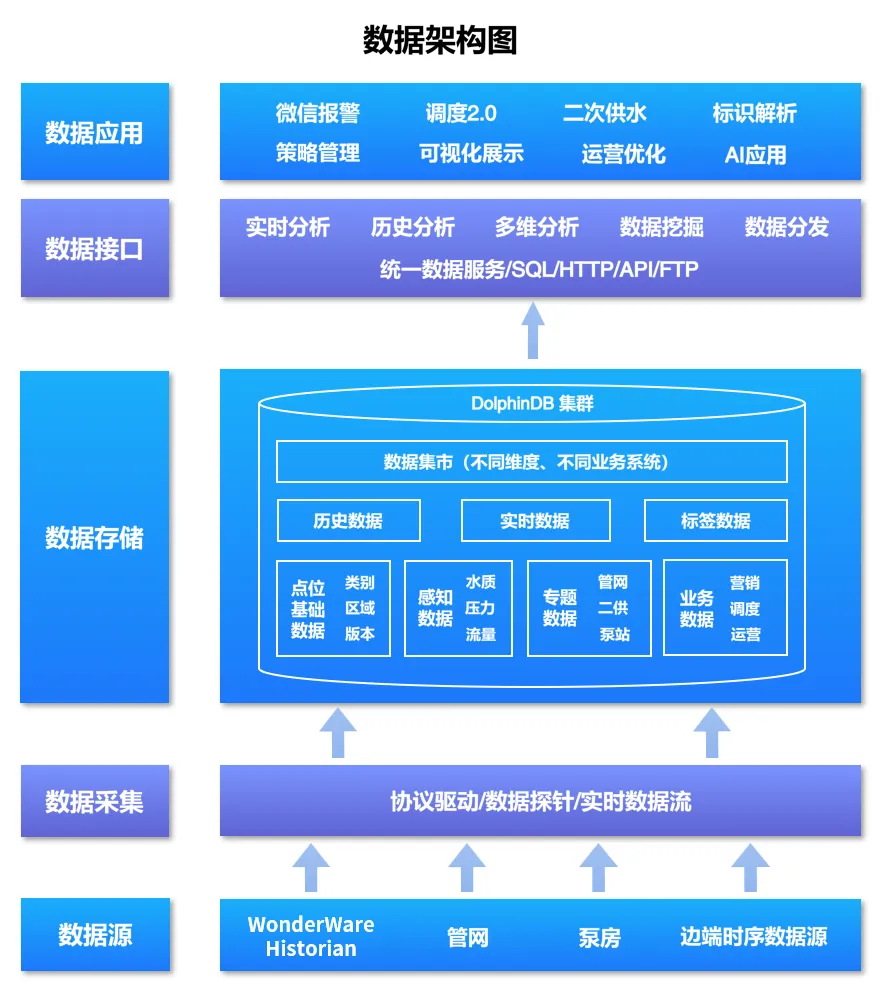
全链路工业协议适配
DolphinDB 对工业协议的对接以原生插件而非网关中转的方式实现。目前已上线的插件包括:OPC UA/DA 插件、MQTT 插件、S7 插件。这种模式减少了一个或多个中间转发节点,既降低了端到端延迟,也减少了因中间件故障导致的数据丢失风险。
DolphinDB × AI
DolphinDB 还支持多项 AI 应用:AI Agent 实现自然语言数据检索与分析;内置多种机器学习算法,并提供 xgboost、libtorch 等插件,支持模型训练与推理;基于 MCP 接口,既服务传统展示层,也支撑 AI 告警、参数优化、电力交易分析等场景,加速数据向智能决策转化;DolphinDB 推出的 CPU-GPU 异构计算平台 Shark,能将 GPU 的极致算力充分应用于工业仿真、参数优化等高性能场景;提供的文本存储引擎(TextDB)和向量存储引擎(VectorDB)可用于实现 RAG 的知识库。
不仅好用,还敢用作核心
真正衡量数据库能力的,从来不是实验室的 benchmark,而是能不能把核心业务压上去。在这一点上,DolphinDB 在中广核的实践就极具代表性。
场景挑战
核反应堆运行监控对数据系统提出了以下几重极端要求:
-
毫秒级精度:反应堆状态参数(温度、压力、中子通量等)的变化以毫秒为单位,错过一个数据点可能意味着遗漏一次潜在的异常征兆
-
全量数据覆盖:单个反应堆涉及 6500+ 个关键测点,涵盖中子测量、热工水力、设备振动、电气参数等数十类数据
-
7×24 零中断:核反应堆连续运行周期以年为单位,数据库不能有任何计划外停机
-
隐蔽故障诊断:如蒸汽管道小破口泄露等早期征兆极其微弱,需要高效的时域/频域关联分析才能识别
替代方案:从进口 PI System 到 DolphinDB
在采用 DolphinDB 之前,中广核的核反应堆状态数据主要依赖 OSIsoft PI System(美国进口工业数据管理平台,已被 Aveva 收购)。该方案存在以下痛点:
-
数据写入实时性不足,批处理模式导致预警响应存在分钟级延迟
-
分析能力有限,复杂诊断需要将数据导出到 MATLAB/Python,牺牲实时性
-
国产化合规压力:关键基础设施行业对进口软件的依赖存在政策与供应链风险
-
运维成本高:PI System 的商业许可和驻场运维费用逐年上涨
技术架构
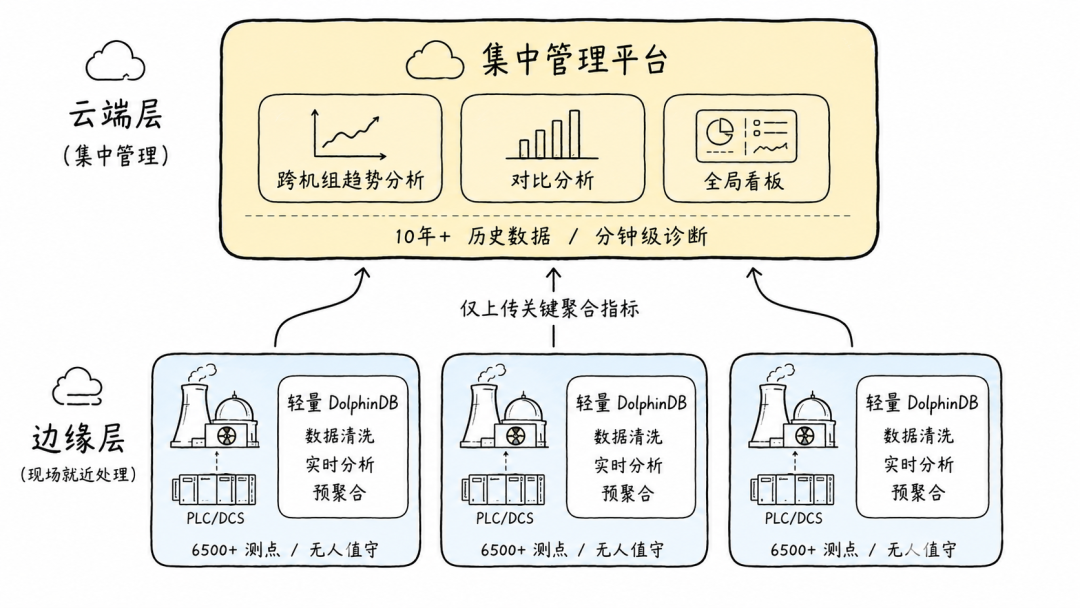
DolphinDB 在中广核的部署采用边缘-云两级架构:
边缘层:在核电机组本地部署轻量级 DolphinDB 实例,直接通过 OPC UA 采集 PLC 和 DCS 系统的实时数据。边缘端完成数据清洗、预聚合和本地实时分析------只需将关键聚合指标上传云端,避免海量原始数据跨网传输。
云端层:集中管理多个边缘节点的聚合数据,提供跨机组、跨基地的趋势分析、对比分析和全局看板。历史数据保留 10 年以上,支持任意时间范围的即席查询。
量化成果
经过长期稳定运行,DolphinDB 在中广核实现了:
-
数据完整性:持续运行期间未发生数据丢失或因数据库导致的计划外中断
-
故障诊断效率:蒸汽管道小破口泄露等隐蔽故障的诊断时间,从传统人工报表分析的数小时级缩短到分钟级
-
分析深度:在库内完成振动信号的时域/频域分析、趋势异常检测、多测点关联分析,无需数据导出
-
运维效率:边缘实例实现无人值守运行,无需专职 DBA 维护
国产替代的未来:从单点突破到生态协同
国产时序数据库从能用到好用,再到敢用作核心的三级跳,本质上是技术成熟度曲线的必经之路。DolphinDB 的路径代表了其中一种务实选择:不追求全能,而是在最难的场景中打磨出极致的性能和可靠性,再降维覆盖通用工业场景。
展望下一步,国产时序数据库还需补齐以下短板:
-
生态兼容性:降低从国外产品迁移的改造成本,提供兼容 InfluxDB Line Protocol、Prometheus Remote Write 等标准协议的接入层
-
云原生能力:适应 K8s 容器化部署、存算分离、自动弹性伸缩等云原生趋势
-
行业解决方案:针对电力、石化、制造等细分行业,输出预配置的最佳实践模板,降低客户选型和试错成本
对于正在评估国产时序数据库的工业客户,一个务实的建议是:从非核心的边缘监控场景入手,积累运维经验和团队信心;一旦验证通过,逐步替代进口数据库向核心业务推进。这条路 DolphinDB 在中广核已经走过一遍了,其方法论和经验是可以被复制的。