基础知识、Skill、Rules和MCP案例介绍
本文旨在为开发者提供一套完整的、可实操的智能体(Agent)配置与优化指南。通过深度解析 Skills(技能)、Rules(规则)、Workflows(工作流)以及 MCP(模型上下文协议)等核心组件,我们将揭示如何将一个通用的 AI 模型转化为具备专业领域知识、遵循特定工程规范、并能深度集成到现有开发工作流中的"自动化程序员"。
Agent Skills (智能体技能)
技能(Skills)是用于扩展智能体能力的开放标准 。一个 Skill 就是一个文件夹,其中包含一个 SKILL.md 文件,该文件记录了智能体在执行特定任务时可以遵循的指令。
什么是 Skills
Skills 是可复用的知识包,用于扩展智能体的功能。每个 Skill 包含:
- • 针对特定类型任务的处理指令
- • 需要遵循的最佳实践和约定
- • 智能体可以使用的可选脚本和资源
当你开始对话时,智能体会看到一份包含 Skill 名称和描述的可用 Skill 列表。如果某个 Skill 与你的任务相关,智能体会读取完整指令并按照指令执行。
Skill 的存储位置
以 Antigravity 为例,其支持两种类型的 Skills:
|--------------------------------|-------|--------------------------------|
| 位置 | 作用域 | 说明 |
| /.agent/skills/ | 工作区特定 | 适用于特定项目的流程,如团队的部署过程或测试约定。 |
| ~/.gemini/antigravity/skills/ | 全局 | 适用于所有项目。用于个人实用工具或你希望随处可用的通用工具。 |
创建 Skills
要创建一个 Skills:
-
- 在上述 Skills 目录中为你的 Skills 创建一个文件夹。
-
- 在该文件夹内添加一个
SKILL.md文件。
- 在该文件夹内添加一个
目录结构示例:
text
.agent/skills/
└─── skill-example/
└─── SKILL.md每个 Skills 都需要一个包含 YAML Frontmatter 的 SKILL.md 文件:
text
---
name: skill-example
description: 帮助处理特定任务。当需要执行 X 或 Y 时使用。
---我的技能 (My Skill)
此处填写给智能体的详细指令。
何时使用此技能
- 当...时使用
- 这对...很有帮助
如何使用
智能体应遵循的分步指南、约定和模式。
Skill 字段说明
|-------------|----|----------------------------------------|
| 字段 | 必填 | 描述 |
| name | 否 | 技能的唯一标识符(小写,空格用连字符代替)。如果未提供,默认使用文件夹名称。 |
| description | 是 | 清楚说明技能的作用及使用时机。这是智能体决定是否应用该技能的依据。 |
提示: 请使用第三人称编写描述,并包含有助于智能体识别相关性的关键词。例如:"使用 pytest 约定为 Python 代码生成单元测试。"
技能文件夹结构
虽然 SKILL.md 是唯一必需的文件,但你还可以包含其他资源:
text
.agent/skills/my-skill/
├─── SKILL.md # 主要指令(必填)
├─── scripts/ # 辅助脚本(可选)
├─── examples/ # 参考实现(可选)
└─── resources/ # 模板及其他资产(可选)智能体在执行技能指令时可以读取这些文件。
智能体如何使用技能
技能遵循渐进式披露(Progressive Disclosure)模式:
-
- 发现(Discovery): 对话开始时,智能体看到可用技能的名称和描述列表。
-
- 激活(Activation): 如果某个技能看起来与任务相关,智能体会读取完整的
SKILL.md内容。
- 激活(Activation): 如果某个技能看起来与任务相关,智能体会读取完整的
-
- 执行(Execution): 智能体在处理任务时遵循该技能的指令。
你不需要显式告诉智能体使用技能------它会根据语境自行决定。不过,如果你想确保使用某个技能,也可以通过名称提及它。
描述 Skill 需要遵循的原则
- • 保持 Skill 专注: 每个 Skill 只做好一件事。与其创建一个"全能" Skill,不如为不同的任务创建独立的 Skill。
- • 编写清晰的描述: 描述是智能体判断是否使用 Skill 的关键。务必具体说明 Skill 的作用和适用场景。
- • 将脚本视为黑盒: 如果你的 Skill 包含脚本,鼓励智能体先通过
--help运行它们,而不是阅读整个源代码。这能让智能体的注意力集中在任务本身。 - • 包含决策树: 对于复杂的 Skill,添加一个章节来帮助智能体根据情况选择正确的方法。
Skill 示例:代码审查技能
这是一个帮助智能体审查代码的简单技能示例:
text
---
name: code-review
description: 审查代码变更中的错误、风格问题和最佳实践。在审查 PR 或检查代码质量时使用。代码审查技能 (Code Review Skill)
在审查代码时,请遵循以下步骤:
审查清单
- 正确性:代码是否实现了预期的功能?
- 边界情况:是否处理了错误情况?
- 风格:是否符合项目约定?
- 性能:是否存在明显的低效之处?
如何提供反馈
-
明确指出需要修改的内容。
-
解释原因,而不只是告诉怎么做。
-
尽可能提供替代方案。
获取并安装生态系统中的 Skills
除了手动创建,你还可以使用
npx skillsCLI 工具从开放生态系统中发现并安装现成的 Skills。常用命令:
- • 查找 Skills :使用
npx skills find [关键词]搜索感性的技能。
npx skills find stock # 查找与股票分析相关的技能 - • 安装 Skills :使用
npx skills add [包名]进行安装。 -
- • 全局安装 :
npx skills add -g -y - • 本地安装 :
npx skills add -y(安装到当前项目的.agent/skills)
- • 全局安装 :
实战示例:
-
- 运行
npx skills find stock发现stock-research-executor。
- 运行
-
- 运行
npx skills add liangdabiao/claude-code-stock-deep-research-agent@stock-research-executor将其安装到当前项目。
- 运行
-
- 安装完成后,Agent 即可识别并使用该调研流程。
text> 更多资源:访问 https://github.com/vercel-labs/skills 深入了解开放标准及更多社区技能。Skill的总结
Skill 的核心价值在于将对智能体的零散要求 转化为结构化的知识资产。它不仅是指令的集合,更是最佳实践的沉淀。通过 Skill,我们可以实现:
- • 能力标准化:确保智能体在处理特定任务时具备一致的专业水准和行为模式。
- • 经验文档化:将复杂的业务逻辑、团队约定或操作流程固化,减少重复的提示词工程。
- • 按需扩展:利用"渐进式披露"机制,在不消耗过多上下文的前提下,赋予智能体无限的能力边界。
规则 (Rules)
规则是手动定义的约束条件,用于在局部和全局层面上引导智能体(Agent)。通过规则,用户可以根据特定的使用场景和风格,引导智能体遵循相应的行为准则。
规则说明
- • 形式: 规则本身是一个 Markdown 文件,您可以在其中输入约束条件,以引导智能体适应您的任务、技术栈和风格。
- • 字数限制: 每个规则文件限 12,000 个字符以内。
规则分类
- • 全局规则 (Global Rules): 以 Antigravity 为例,其存储在
~/.gemini/GEMINI.md中,适用于所有工作区。 - • 工作区规则 (Workspace Rules): 存储在工作区或 Git 根目录的
.agent/rules文件夹中。
如何使用规则
以 Antigravity 为例,按照以下步骤使用规则。
如何开始使用规则
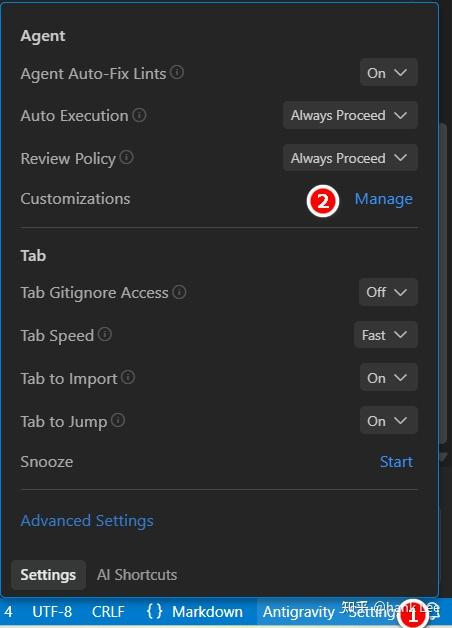
Antigravy Settings
Antigravy Settings
-
- 点击编辑器 Agent 面板底部的 Antigravy Settings。
-
- 点击 Customizations 的 Manage 。
提示: 也可以通过 Agent 面板顶部的 "..." 下拉菜单直接打开 Customizations (自定义)面板。
- 点击 Customizations 的 Manage 。
-
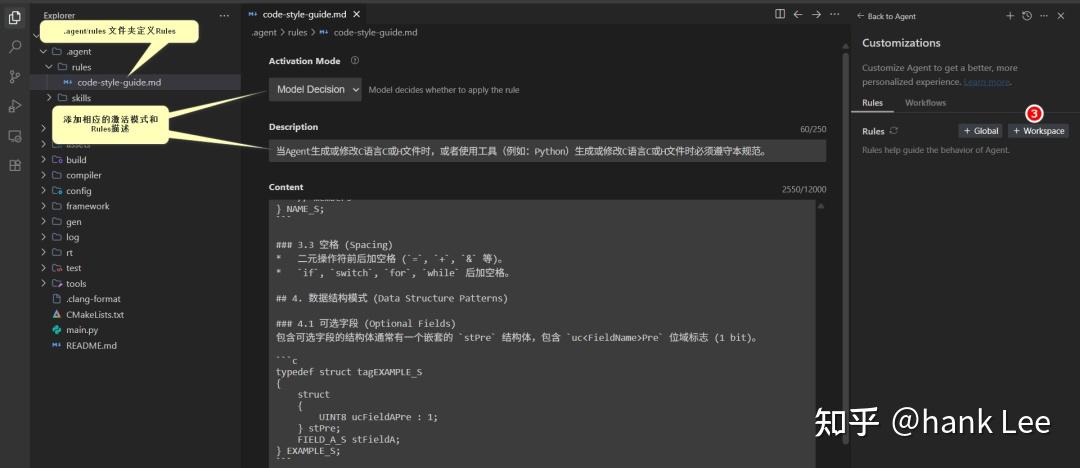
- 导航至 Rules (规则)面板,点击 + Global (+ 全局)创建新的全局规则,或点击 + Workspace(+ 工作区)创建特定于当前工作区的规则。
激活方式
在规则层级,您可以定义规则的激活方式:
- • Manual(手动): 通过在智能体输入框中使用
@提及来手动激活规则。 - • Always On(始终开启): 规则始终处于应用状态。
- • Model Decision(模型决策): 基于规则的自然语言描述,由模型决定是否应用该规则。
- • Glob(匹配模式): 基于您定义的 Glob 模式(例如
.js或src/**/*.ts),规则将应用于所有匹配该模式的文件。
@ 提及功能
您可以在规则文件中使用
@文件名来引用其他文件:- • 如果文件名是相对路径,将相对于该规则文件的位置进行解析。
- • 如果文件名是绝对路径,将按真实的绝对路径解析;否则,将相对于仓库(Repository)进行解析。
- • 示例:
@/path/to/file.md会首先尝试解析为/path/to/file.md,如果该文件不存在,则解析为workspace/path/to/file.md。
规则文件模板 (Example.md)
可以将以下内容作为模板,存放在你的
.agent/rules目录中。它包含了任务背景、技术要求和风格指南。text# 项目编程规范 (Project Coding Rules) - • 查找 Skills :使用
核心背景
Agent 必须严格遵循这些规范,确保 C 语言代码风格统一。
强制约束
- 文件头部 :遵循
_H_的大写命名格式。 - 命名规范 :
- 基础类型使用大写(如
UINT8,VOID)。 - 结构体使用
tag前缀和_S后缀(如tagRRC_AS_CONFIG_S)。 - 成员变量使用匈牙利命名法(如
ui表示无符号整数)。
- 基础类型使用大写(如
- 格式化 :
- 使用 4 个空格 缩进。
- 使用 Allman 风格(大括号独占一行)。
代码风格
typedef struct tagEXAMPLE_S
{
UINT32 uiValue; /* 4 个空格缩进 /
} EXAMPLE_S; / Allman 风格 */
关联参考
@/docs/api-spec.md # 引用 API 文档
关于 Glob 模式 (Glob Patterns)
Glob 模式 是一种简化的正则表达式,专门用于匹配文件路径。当你设置规则为 "Glob" 激活时,智能体只会在你编辑或处理匹配该模式的文件时,才会启用这条规则。
常见的通配符说明
|----|---------------------|-----------------------------------------|
| 模式 | 说明 | 示例 |
| | 匹配当前目录下的任意字符(不跨目录)。 | .js 匹配所有的 JS 文件。 |
| | 递归匹配任意层级的子目录。 | src//.ts 匹配 src 及其所有子文件夹下的 TS 文件。 |
| ? | 匹配单个字符。 | file?.md 匹配 file1.md, fileA.md 等。 |
| {} | 匹配花括号内指定的多个选项。 | .{js,ts} 同时匹配 JS 和 TS 文件。 |
| ! | 排除特定文件。 | !node_modules/** 忽略 node_modules 文件夹。 |
实际应用场景
-
- 后端规则
- • 模式:
server//*.py - • 作用:只有当你修改服务器端的 Python 代码时,Python 的后端规范才会生效。
-
- 文档编写规则
- • 模式:
docs//*.md - • 作用:当你写文档时,自动应用中文排版规范(如中英文间加空格)。
工作流 (Workflows)
什么是工作流
工作流 允许定义一系列步骤,引导智能体(Agent)完成重复性任务,例如部署服务等。这些工作流以 Markdown 文件形式保存,提供了一种简单、可重复的方式来运行关键流程。保存后,可以通过斜杠命令格式 /workflow-name 在智能体中调用。
工作流与规则的区别
- • 规则 (Rules):在提示词(Prompt)层面提供持久、可重用的上下文指导。
- • 工作流 (Workflows):在轨迹(Trajectory)层面提供结构化的步骤或提示词序列,引导模型完成一系列互连的任务或动作。
如何创建工作流
-
- 通过编辑器智能体面板顶部的"..."下拉菜单打开 Customizations(自定义)面板。
-
- 导航至 Workflows(工作流)面板。
-
- 点击 + Global 按钮创建一个可在所有工作区访问的全局工作流,或点击 + Workspace 按钮创建特定于当前工作区的工作流。
如何执行
在智能体中使用 /workflow-name 命令即可调用。工作流可以相互嵌套调用(例如 /workflow-1 中包含"调用 /workflow-2"的指令)。智能体会按顺序处理每个定义的步骤,执行动作或生成响应。
文件规格
工作流保存为 Markdown 文件,包含标题、描述和一系列具体指令步骤。每个工作流文件限制在 12,000 个字符以内。
智能体生成的工作流
还可以要求智能体为您生成工作流!这在您手动引导智能体完成一系列步骤后效果尤为出色,因为它可以利用对话历史来创建工作流。
详细讲解:如何使用工作流
如果说 Rules(规则) 是给 AI 的"员工手册"(告诉它不该做什么、该用什么风格),那么 Workflows(工作流) 就是给 AI 的"标准操作程序"(告诉它第一步做什么,第二步做什么)。
1. 核心结构
一个标准的工作流 Markdown 文件通常包含:
- • Title: 工作流的名称(决定了你的斜杠命令叫什么)。
- • Description: 简述这个工作流的作用。
- • Steps: 核心部分,按 1, 2, 3 顺序列出你希望 AI 执行的指令。
2. 嵌套调用逻辑
这是工作流最强大的地方。你可以通过"原子化"工作流来构建复杂的自动化链:
- •
/check-style(检查代码风格) - •
/run-test(运行测试) - •
/deploy-prod(部署生产环境) - • 你可以创建一个总的
/release工作流,内容为:"首先执行/check-style,成功后执行/run-test,最后执行/deploy-prod"。
应用案例
案例 1:代码审查与修复 (Code Review & Fix)
- • 命令 :
/cr - • 工作流内容
-
- 阅读当前修改过的所有文件。
-
- 根据
@/rules/coding-style.md检查潜在的错误或性能问题。
- 根据
-
- 列出发现的问题。
-
- 询问用户是否需要自动修复。
-
- 如果用户同意,生成修复方案。
案例 2. 多维度投资标的扫描流
这个工作流文件应存放在项目根目录的 .agent/workflows/retail-scan.md。
Workflow 步骤设计:
-
- 多源数据提取:
- • 搜索并总结即时零售头部玩家(美团闪购、京东到家、饿了么)最新的季度财务报告。
- • 重点提取关键指标:AOV(客单价)、履约成本、以及活跃商家增长率。
-
- 行业景气度交叉分析:
- • 将即时零售板块的毛利增长与当前 O2O 行业整体景气度进行交叉比对。
- • 分析非餐品类(如数码、医药)的渗透率变动,判断行业是否处于扩张期
-
- 竞争壁垒与份额复核:
- • 参考成熟行业的市场份额研究模型,重新计算目标公司的行业壁垒(如配送网络密度、用户黏性)。
- • 复核当前美团与京东在即时零售领域的市场占有率动态变化。
-
- 自动化投资存盘:
- • 将上述分析结论、对比图表数据以 Markdown 格式生成总结。
- • 自动追加到你的
etf-investment-analysis仓库的相关文档中,完成本次投资调研留档。
Workflow 通过智能体生成
不要自己手写复杂的 Markdown!
当你和 AI 完成了一次复杂的交互(比如你让它帮你调优了代码、写了单元测试、又更新了文档),你可以直接对它说:
"刚才这一套流程很好,帮我把它总结并保存为一个名为 'test-and-docs' 的 Workflow。"
它会根据刚才的对话轨迹,自动梳理出逻辑步骤并生成文件。
Workflow vs. Implementation Plan 深度解析
在 Antigravity(以及类似的 AI 编程助手)的运作中,AI 主动生成会生成一个 implementation_plan.md 文件,来指导它如何修改代码以满足用户的需求。而 Workflow 则是用户预先定义的、可复用的流程模板。虽然两者都是以 Markdown 文件形式存在,但它们在目的、时效性和使用方式上有着本质的区别。
1. 相同点 (Commonalities)
- • 目标一致性:二者最终都是为了确保项目的正确交付,减少因人为疏忽或 AI 幻觉导致的错误。
- • 结构化表达:均采用 Markdown 格式存储,利用列表、步骤和复选框来增强可读性和可执行性。
- • 上下文补充:它们都充当了 LLM 核心 Prompt 之外的"外挂上下文",帮助 Agent 在复杂任务中保持逻辑一致性。
2. 不同点 (Differences)
|------|-------------------------------------------------|-------------------------------------------------|
| 维度 | Workflow (工作流/SOP) | Implementation Plan (实现计划/施工图) |
| 存在意义 | 定义"如何做"。是长期存在的流程模板,用于规范化重复性操作。 | 定义"做什么"。是针对特定需求的单次任务拆解,描述具体改动点。 |
| 时效性 | 持久性文档。存放在 .agent/workflows/ 中,作为项目数字资产永久留档。 | 一次性载体。任务合入 (Merge) 后即告作废,甚至可以从代码库中删除。 |
| 颗粒度 | 流程级。侧重于阶段跳跃(如环境检查 -> 代码生成 -> 测试运行 -> PR 创建)。 | 文件级。侧重于代码细节(如修改 main.py 第 50 行,新增 utils.py 文件)。 |
| 通用性 | 跨 Agent 通用。即使更换了模型,新的 Agent 依然可以加载此 SOP 维持服务标准。 | 环境强相关。仅对当前代码分支和当前需求有效。 |
| 激活方式 | 被动调用。通过 /slash 命令手动或根据逻辑触发。 | 主动生成。通常由 Agent 在分析需求后自动生成,等待用户确认 (Approve)。 |
3. 补充说明:二者的协同关系 (Synergy)
你可以将二者的关系想象成 "工厂流水线" 与 "定制化订单":
- • Workflow 是流水线:它规定了每一个产品必须经过"零件组装、电路测试、质检签名"这三个环节。
- • Implementation Plan 是订单要求:它规定了这次组装的是"红色外壳、5000mAh 电池、搭载 v1.0 固件"。
在实际操作中,如果发现某个 implementation_plan.md 的步骤在多次需求中高度重复(例如每次修改代码都要先跑一遍格式化检查),可以考虑将这部分逻辑沉淀到 Workflow 中。
MCP:让 AI 真正走进你的代码库
在 AI 辅助开发的领域,我们正在经历从"对话框"向"全案集成"的范式转移。而**MCP (Model Context Protocol)**则是这场变革中的"全栈接口"。
1. 什么是 MCP?AI 时代的"USB-C 接口"
MCP 是由 Anthropic 发布的一套开放标准,旨在解决 AI 智能体(Agent)与外部数据、工具之间"连接难"的痛点。
- • 实时上下文:不再需要手动复制粘贴代码或日志,AI 能直接读取数据库模式、文件系统或 API 文档。
- • 双向交互:不仅是"读",AI 还能通过连接的服务器执行"写"操作,比如创建 Git 分支或更新数据库记录。
- • 标准化协议:类似于硬件领域的 USB-C,无论你使用的是什么模型,只要工具符合 MCP 标准,就能实现即插即用。
2. GitHub MCP 实战演示:从本地代码到远程提交
为了直观展示 MCP 的威力,我们模拟一个真实场景:利用 AI 将你本地编写的一个 5G 协议解析脚本自动化部署到 GitHub 仓库中。
第一步:环境配置(以 Windows 11 为例)
你需要一个具有 repo 权限的 GitHub Personal Access Token (PAT) 。由于 Windows 环境下 Docker 配置较为复杂且易报错(如 executable file not found),建议直接使用 Node.js (npx) 方案。
-
- 打开
mcp_config.json配置文件。
- 打开
-
- 直接复制并替换以下 GitHub 服务器配置:
text
{
"mcpServers": {
"github": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-github"
],
"env": {
"GITHUB_PERSONAL_ACCESS_TOKEN": "您的_ghp_开头的_Token_填在这里"
}
}
}
}注意 :请确保您的电脑已安装 Node.js。保存后在 MCP Store 面板点击 Refresh 即可看到状态变为绿色的 Enabled。
第二步:代码上传与提交演示
一旦连接成功,你可以直接通过自然语言命令 AI 完成以下复杂轨迹:
|------|---------------------------------------|-----------------------|-----------------|
| 动作阶段 | 你的指令 (Prompt) | AI 调用工具 (Tool Call) | 预期结果 |
| 初始化 | "帮我建一个名为 nr-protocol-analyzer 的公开仓库。" | create_repository | GitHub 上出现新仓库。 |
| 分支管理 | "创建一个名为 feat/rrc-parsing 的新分支。" | create_branch | 完成分支切换与隔离。 |
| 代码上传 | "将本地 parser.py 的内容提交到该分支。" | create_or_update_file | 代码文件被推送到远程。 |
| 代码审查 | "为此改动提交一个 Pull Request,并总结改动。" | create_pull_request | 生成 PR,附带 AI 总结。 |
3. MCP 协议开发实战:构建自己的 Client 与 Server
除了使用现成的 MCP Server(如 GitHub),开发者还可以轻松构建自己的 MCP 工具链。
我们提供了一个完整的 MCP Demo,展示了如何从零开始构建 Client 和 Server,并将其与 Google Gemini 模型集成。
参考代码库 :https://github.com/second-rate-hall/Agent-Labs (在 mcp_demo 目录下)
核心架构
这个 Demo 包含两个主要部分:
-
- MCP Server (
server.py):
- MCP Server (
- • 基于
mcpPython SDK 构建。 - • 通过
FastMCP快速定义了两个工具: -
- •
add(a, b):简单的加法计算器。 - •
get_weather(city):模拟的天气查询工具。
- •
- • 通过标准输入/输出 (Stdio) 暴露协议接口。
-
- MCP Client (
client.py):
- MCP Client (
-
- • LLM 集成 :使用 Google 最新的
google-genaiSDK 连接 Gemini 2.0 Flash 模型。 - • 协议连接 :通过
StdioServerParameters启动 Server 子进程并建立连接。 - • 双向交互闭环:
-
- Client 获取 Server 的工具列表,并转换为 Gemini 兼容的
Tool定义。
- Client 获取 Server 的工具列表,并转换为 Gemini 兼容的
-
- 用户输入(如"计算 100+3")发送给 Gemini。
-
- Gemini 思考后返回 Tool Call 指令。
-
- Client 拦截指令,通过 MCP 协议调用 Server 的
add函数。
- Client 拦截指令,通过 MCP 协议调用 Server 的
-
- Server 返回结果
103。
- Server 返回结果
-
- Client 将结果回传给 Gemini,生成最终自然语言回复。
代码实战片段
Server 端 (Python):
textfrom mcp.server.fastmcp import FastMCPmcp = FastMCP("Demo Server")
@mcp.tool()
def add(a: int, b: int) -> int:
"""Add two numbers."""
return a + b
Client 端 (Gemini SDK):
text# 自动发现工具并转换 schema tools_result = await session.list_tools()... 转换为 gemini_tools_list ...
发送给 LLM
chat = client.chats.create(
model="gemini-2.0-flash",
config=types.GenerateContentConfig(
tools=types.Tool(function_declarations=gemini_tools_list)
)
)
这个示例展示了 MCP 作为"AI 神经触角"的强大之处:LLM 不在本地运行,工具不在 LLM 运行,但两者通过 MCP 协议实现了无缝的远程调用与控制。
4. Agent 实战案例:Agent-Labs 项目上传
在本项目
second-rate-hall/Agent-Labs的上传过程中,我们经历了一个典型的"工具分层"场景,展现了 Agent 如何在不同工具间灵活切换以达成目标。场景还原
Agent 尝试将本地的
Agent-Labs知识库上传到 GitHub。尝试一:标准 Git CLI (失败)
Agent 首先尝试使用标准 Git 命令推送:
-
- 初始化 :
git init,git add .,git commit
- 初始化 :
-
- 创建远程库 :调用 MCP 工具
create_repository成功创建远程库。
- 创建远程库 :调用 MCP 工具
-
- 推送 :
git push -u origin main
- 推送 :
- • 结果:失败。由于本地环境未配置 HTTPS 凭证辅助程序,且 SSH Key 权限被拒绝 (Permission denied),导致无法从终端直接推送。
尝试二:MCP 工具接管 (成功)
当终端工具 (CLI) 遇到环境鉴权问题时,Agent 并没有卡住,而是降级使用 MCP 协议提供的原生文件操作工具:
-
- 读取文件 :Agent 使用
view_file等工具读取了本地核心文件的内容。
- 读取文件 :Agent 使用
-
- 直接推送 :调用
mcp_github_push_files工具。
- 直接推送 :调用
- • 原理 :该工具通过 MCP Server 建立的 API 连接直接与 GitHub 交互,绕过了本地的 Git 鉴权配置。
- • 结果:成功将代码和文档部署到远程仓库。
启示 :
这展示了 Agent 的 鲁棒性。当一条路(CLI)被环境配置堵死时,MCP 为 Agent 提供了另一条"专用通道"(API),确保任务能够闭环。
4. MCP 的核心价值:深度集成 VS 浅层对话
通过 MCP 驱动的 GitHub 集成,AI 已经从一个"代码生成器"进化为了一个"自动化程序员":
- • 逻辑连贯性 :由于 AI 可以读取
repos及其历史 commit,它生成的代码能完美适配你现有的项目结构。 - • 操作原子化 :所有的
git操作对你来说是透明的,Agent 会在 任务组 (Task Groups) 中清晰地展示每一步进度,并在敏感操作前请求你的批准。 - • 跨工具协同:你可以让 AI 同时连接 GitHub 和数据库(如 PostgreSQL),实现"根据数据库模式自动修改代码并提交 PR"的高级自动化。
AI 伙伴的一点建议:
在 Windows 上使用npx方案可以避开繁琐的 Docker 路径配置。连接成功后,记得试试让 AI 帮你"搜索 GitHub 仓库中关于 沪深300投资分析示例",它会直接翻阅你的私有库给出最懂你的建议。在 Antigravity 的 Agent Manager 界面中,Knowledge(知识库) 标签页代表了智能体从"原始信息"向"结构化智慧"转化的核心能力。
根据你提供的截图和系统逻辑,以下是关于 Knowledge 的深度解析:
Knowledge 知识库
1. Knowledge 的核心作用与意义
Knowledge是智能体的 "长期记忆" 和 "研究成果区"。
- • 沉淀深度研究结果 :在Agent Manager 适用于 Deep Research(深度研究)。当智能体完成一次长达数小时的资料搜集后,它不会把几万字的网页源码塞给你,而是将其提炼成几条核心的"知识条目"存放在这里。
- • 跨 Agent 共享上下文:如果你有 Agent A 在研究"即时零售 AOV 模型",Agent B 在处理"编程开发",它们生成的 Knowledge 可以被后续的任务直接引用,避免重复搜索。
- • 解决"长对话遗忘"问题:普通的对话历史会随着 Token 长度增加而变得模糊,但存入 Knowledge 的内容是持久且高权重的,它是智能体认知的"基石"。
2. 如何生成 Knowledge?
Knowledge 通常不是由用户手动录入的,而是通过以下方式自动或受控生成:
- • 触发深度研究 (Deep Research):当你启动一个长周期的背景任务(例如:"调研过去三年美团与京东的履约成本变化趋势"),智能体在完成任务后,会自动将总结性的结论(如核心数据表、竞争对手对比结论)生成为 Knowledge 项。
- • 手动指令提炼:你可以在对话中对 Agent 说:"把你刚才分析的 5G NR 架构图的关键点保存到我的 Knowledge 中",它就会在左侧生成一个新的条目。
- • 代码/文档扫描 :当你连接了 GitHub MCP 并让 AI 进行全库审计时,它识别出的"代码架构设计模式"或"项目特有规则"也会转化为 Knowledge,方便以后查询。
3. 如何使用 Knowledge?
生成后的知识条目会显示在"Knowledge 知识库"所在的区域,你可以通过以下方式使用:
- • 点击查阅(Artifacts 模式):点击左侧生成的条目,右侧的大空白区会像"在线文档"一样展示完整内容。
- • 自动背景增强:当你在新对话中提问时,Agent 会自动后台检索 Knowledge 里的信息。例如,只要 Knowledge 里有"5G 系统消息流程",你下次问"分析5G 系统消息流程"时,它无需再次上网搜索即可给出专业回答。
- • 导出与归档 :Knowledge 里的内容可以一键转化为
.md文件,存入你的etf-investment-analysis等本地仓库中。
总结:Knowledge 与 Workflow 的关系
- • Workflow 是"如何做"(Action):规定了抓取数据的步骤。
- • Knowledge 是"得到了什么"(Information):存储了抓取后提炼的精华。
Agent 系统的"四梁八柱":底层原理深度解析
在现代 AI 开发架构中,大语言模型(LLM ) 负责逻辑推理与意图理解,而 Agent 负责环境感知、状态管理与工具调用。两者的协同通过以下四个维度实现从"对话"到"执行"的跨越。
Agent Architecture
1. Rules (规则):行为约束的"宪法"
底层原理:静态上下文注入与注意力约束
- • 工作机制 :Rules 是一套预定义的指令集,通常以
.md格式存储在项目或全局目录中。 - • LLM 角色 :在推理阶段,Rules 会被动态合并至 System Prompt(系统提示词) 中。LLM 的注意力机制(Attention Mechanism)会将这些规则视为高权重的边界条件,确保生成的每一行代码或建议都符合预设的规范。
- • Agent 角色 :Agent 负责维护规则的物理索引,并根据当前工作的路径(Workspace)自动识别并挂载对应的
.agent/rules文件。它确保了约束的实时性,即"环境变,规则变"。
2. Workflow (工作流):复杂任务的"蓝图"
底层原理:状态机编排与任务组调度
- • 工作机制 :Workflow 是人类定义的结构化执行序列,旨在将宏大目标拆解为可追踪的 Task Groups(任务组)。
- • LLM 角色:LLM 充当"现场执行官"。它在每一个步骤节点读取当前状态,并根据 Workflow 定义的逻辑判定是否达成目标、是否需要重试或修复错误。
- • Agent 角色 :Agent 充当"系统管理员"。它维护着整个执行的 Trajectory(轨迹) ,负责跨步骤的状态持久化。同时,它是安全防线,在执行 Workflow 定义的敏感写操作前,会强制触发 Human-approval(人工审批) 中断。
3. MCP (模型上下文协议):连接世界的"神经触角"
底层原理:标准化远程过程调用 (RPC) 与 客户端-服务器架构
- • 工作机制 :MCP 是一套开放的标准协议,采用 Client-Server 架构。Antigravity 编辑器作为 Client,而各种工具(GitHub、数据库、外部 API)作为 Server。
- • LLM 角色 :LLM 并不直接操作外部工具,它负责"翻译"。它阅读 MCP Server 提供的 Tools(工具清单) ,并将用户的意图转化为结构化的 JSON 格式工具调用指令 (Tool Call)。
- • Agent 角色 :Agent 负责底层的通讯链路。它通过 Stdio 或 HTTP/SSE 与 MCP Server 交换数据,将 LLM 的 JSON 指令发送出去,并将服务器返回的 Resources(资源) 实时反馈给 LLM,作为其下一步决策的上下文。
4. Skill (技能):模块化能力的"专业插件"
底层原理:知识资产的动态链接与 Persona(人格)增强
- • 工作机制:Skill 是将特定的 Prompt、Tools 和文档(Artifacts)封装在一起的模块化功能包。
- • LLM 角色:LLM 负责"角色扮演"。当一个 Skill 被加载时,LLM 会学习该技能包中的知识摘要,并在处理相关问题时,自动采用该技能要求的逻辑框架和专业领域知识。
- • Agent 角色 :Agent 负责"资产管理"。它利用 CLI 工具 (如
npx skills)实现技能的全局存储、版本控制和 Linking(链接)。当技能被链接到特定项目时,Agent 会在对话启动时,将这些非易失性的"技能产物"注入 LLM 的活跃上下文窗口中。
核心对比表:一目了然的架构逻辑
|----------|---------|----------|---------------|
| 组件 | 核心隐喻 | 底层技术本质 | 核心交付价值 |
| Rules | 宪法/法律 | 系统提示词约束 | 确保行为与风格的 统一性。 |
| Workflow | 施工蓝图 | 任务状态机调度 | 确保复杂任务的 确定性。 |
| MCP | 神经/肢体 | RPC 协议通讯 | 实现外部数据的 实时性。 |
| Skill | 技能包/App | 模块化上下文注入 | 实现领域知识的 可复用性。 |
5. 避坑指南与最佳实践 (Best Practices)
在实际落地 Agent 体系时,我们总结了以下"三要三不要"原则,帮助开发者少走弯路:
✅ 最佳实践
-
- 分层治理:通用规范(如 Clean Code)放全局 Rule,项目特定规范放 Workspace Rule。不要混淆作用域。
-
- 原子化 Workflow :将大流程拆解为小模块(如
/test,/lint),通过嵌套调用组合成/release。这样便于调试和复用。
- 原子化 Workflow :将大流程拆解为小模块(如
-
- MCP 权限隔离 :在生产环境中部署 MCP Server 时,务必对
write操作(如 Git Push, DB Update)设置人工确认或白名单机制。
- MCP 权限隔离 :在生产环境中部署 MCP Server 时,务必对
❌ 常见误区 (Anti-patterns)
- • 误区 1:把 Rule 当万能药。不要写"写出世界上最好的代码"这种空泛的规则。规则必须具体且可验证,例如"变量名强制使用驼峰式"或"禁止在循环中进行数据库查询"。
- • 误区 2:Skill 过度设计 。不要把 Python 基础语法写进 Skill,LLM 本身已经掌握了。Skill 应该包含的是你们团队特有的架构设计模式、业务逻辑或 API 使用约定。
- • 误区 3:忽视上下文开销。不要在 Skill 中塞入几万字的文档。利用 Knowledge 存储长文档,Skill 只保留核心指令和索引。
结语:从 Prompt Engineering 到 Agent Engineering
通过本文的深入解析,我们构建了一个完整的 Agent 能力图谱:从 Skills 的能力扩展,到 Rules 的行为约束,从 Workflows 的流程标准化,到 MCP 的外部世界连接,最后到 Knowledge 的长期记忆沉淀。
这"四位一体"的架构,标志着我们正在经历一次重要的范式转移:
- • Prompt Engineering (提示词工程) 是一维的。我们在对话框里通过微调字句,试图让模型输出更好的结果。
- • Agent Engineering (智能体工程) 是三维的。我们通过构建环境、配置规则、挂载工具、沉淀知识,为 AI 打造一个"数字车间"。在这里,AI 不再是单纯的对话者,而是遵守纪律、熟练使用工具的"数字员工"。
作为开发者,我们的角色正在从亲自编写每一行代码,转变为定义规则、沉淀知识、编排流程的 Agent 架构师。
立即行动 (Call to Action)
纸上得来终觉浅,绝知此事要躬行。
-
- Clone 本项目 :
git clone https://github.com/second-rate-hall/Agent-Labs
- Clone 本项目 :
-
- 运行 MCP Demo :进入
mcp_demo目录,按照 README 运行 Client,体验与 AI 的双向交互。
- 运行 MCP Demo :进入
-
- 动手扩展 :尝试修改
server.py,添加一个你自己的工具(例如multiply乘法工具),看看 Gemini 能否自动学会使用它。
- 动手扩展 :尝试修改
掌握这些工具,将使你在 AI 浪潮中保持绝对的竞争优势,真正实现"一人即团队"的高效开发模式。
- • LLM 集成 :使用 Google 最新的