上一章节讲述了树的基本结构和代码实现,接下来讲解树的相关习题,以及结构代码的补充
一.求二叉树的节点个数
要求出一个二叉树所有节点的个数,首先可以想到遍历算法,遍历每一个节点,让size计数器自增即可。下面是代码实现的过程
c
void TreeSize(BTNode *root,int *psize)
{
if (root==NULL)//根结点为空,说明二叉树没有节点直接将函数返回即可。
return;
else //二叉树不为空时,进行如下操作
++(*psize);//将计数器加一
TreeSize(root->left,Asize);//之后利用递归的特性,查看左右节点是否存在。存在就将计数器加一,不存在的话直接返回。
TreeSize(root->right,Bsize);
}
int Asize=0;
TreeSize(A,Asize);
int Bsize=0;
TreeSize(B,Bsize);上述代码的具体解释:当二叉树的根结点为空指针时,将函数直接返回。否则将进行进一步的节点计算。当树节点不为空时,计数器加一,随后递归到左子树的节点上,之后递归到右子树的节点上,以此类推。最终就可以求出所有的节点个数。
因为在这个过程中,size计数器是需要根据情况变化的,所以需要为该函数传递size的地址。
以上就是函数遍历求二叉树节点个数的代码实现,下面是更简便的分治算法的代码实现:
c
int TreeSize(BTNode* root)
{
return root==NULL ? 0:return TreeSize(root->left)+TreeSize(root->right)+1;
}以上是求二叉树节点个数的代码实现,下面进行相关的拓展,让我们尝试利用简单的分治算法求一下二叉树叶子节点的个数。当该节点为空时直接返回。不为空时计算左右子树节点后加上该节点数1。
c
int TreeLeafSize(BTNode *root)
{
if (root==NULL)//分治算法的终止条件
return 0;
if(root->left==NULL && root->right==NULL)
return 1;
return TreeLeafSize(root->left)+TreeLeafSize(root->right);
}二.二叉树的层序遍历
上一章节讲了二叉树的先根遍历等,先根遍历是深度优先遍历。这次要讲的层序遍历是优先广度遍历。
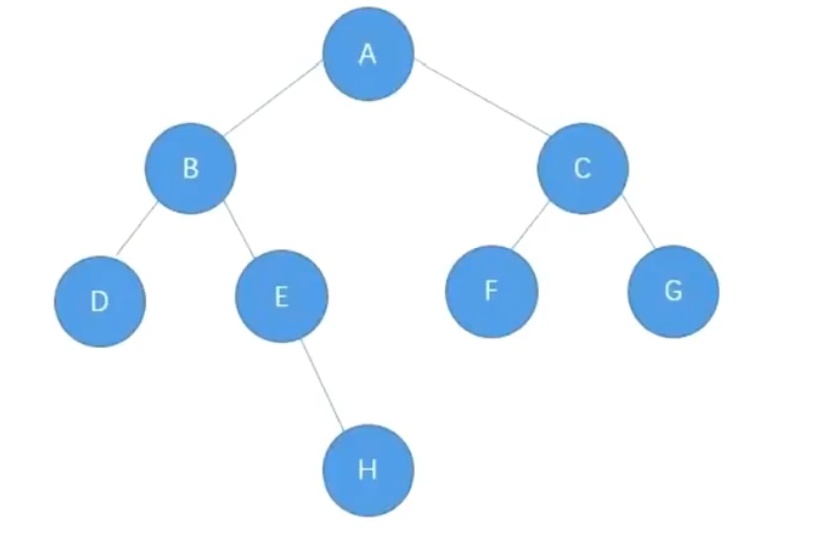
如上图所示:层序遍历的结果是ABCDEFGH。下面是二叉树实现层序遍历的代码实现。
c
void LevelOrder(BTNode *root)
{
Queue q;//创建一个新的队列
QueueInit(&q);//初始化一个队列
if (root)//如果节点不为空,先将其插入队列
QueuePush(&q,root);
while(!QueueEmpty(&q))//如果队列不为空,则进入循环
{
BTNode* front=QueueFront(&q);//将此时的节点设置为队头数据。
QueuePop(&q);
printf("%c",front->data);//打印队头的数据
if(front->left)//左孩子不为空就入队
QueuePush(&q,front->left);
if(front->right)//右孩子不为空就入队
QueuePush(&q,front->right);
}
QueueDestory(&q);
}上述代码的具体解释:二叉树的层序遍历会用到队列的结构性质。如果二叉树不为空那么就将节点插入队列中,如果其左子节点不为空就插入左子节点,右子节点类似。直到插入节点的子节点为空,就遍历结束。最终将队列的结构销毁即可。
三.二叉树的前序遍历
c
int TreeSize(struct TreeNode *root)
{
rerurn root==NULL? 0:TreeSize(root->left)+TreeSize(root->right)+1;
}//NULL是分治算法的终止条件
void PrevOrder(struct TreeNode* root,int *a,int* pi)//数组下标传址调用的原因是让每一个递归函数自增的下标为同一个变量
{
if(root==NULL)//分治算法的终止条件
return;//分治算法最终节点为空
a[*pi]=root->val;
++(*pi);//利用指针进行自增
PrevOrder(root->left,a,&i);
PrevOrder(root->right,a,&i);
}
int* preoderTraversal(struct TreeNode* root, int returnsize)
{
int size=TreeSize(root);
int* a=(int*)malloc(sizeof(int));
int i=0;
PrevOrder(root,a,&i);
*returnsize=size;
return a;
}上述代码的具体解释:首先求出二叉树的节点数,利用递归函数的思想(上一点讲解过)得出二叉树的总节点数,用于接下来的前序遍历。
前序遍历函数首先排除根结点为空的情况,接下来将每个节点的数据依次存储在数组a中,数组的下标也随着存储数据的增加而自增。最后继续利用函数递归的思想先存储左树后存储右树。这里数组下标用指针传递的原因是:在第一次函数递归左树结束后,数组自增的数据会随着左树递归函数的结束而结束,进入右树函数后i的值会重新计算。所以这里需要用到传址调用。
最后一个函数是返回前序遍历之后存储的数组。
当然这里的i,也可以设置成全局变量,让所有参与递归的函数自增的变量是同一个全局变量。但是有个小问题,这是OJ题目,会有多组测试用例,每次测试用例结束后需要将i重置为0才可以测试下一个用例。
四.二叉树的最大深度
c
int maxdepth(struct TreeNode* root)
{
if(root==NULL)//当节点为空时,分治算法终止。
return 0;
int leftdepth=maxdepth(root->left);
int rightdepth=maxdepth(root->right);
return leftdepth>rightdepth ? leftdepth+1 : rightdepth+1;//返回左树和右树中最大高度加一
}上述代码的具体解释:二叉树的最大深度就是左树和右树的深度最大值加一。根据这个道理设计分治算法,就可以算出整个二叉树的最大深度。
五.平衡二叉树
c
int maxdepth(struct TreeNode* root)
{
if(root==NULL)
return 0;//当root为空时,分治算法终止
int leftdepth=maxdepth(root->left);
int rightdepth=maxdepth(root->right);
return leftdepth>rightdepth ? leftdepth+1 : rightdepth+1;
}
bool isBalanced(struct TreeNode* root)
{
if(root==NULL)
return;
int leftdepth=maxdepth(root->left);
int rightdepth=maxdepth(root->right);
return abs(leftdepth-rightdepth)<2 && isBalanced(root->left) && isBalanced(root->right);//平衡二叉树必须保证每一个节点的左右子树的高度差小于1。
}上述代码的具体解释:平衡二叉树需要满足左右树的高度差小于1,所以本题目需要求出二叉树的左右子树是否满足平衡二叉树的条件。这里需要注意的是左右子树并不单单指的是根结点的左右子树,也指左子树的左右子树。
首先代码需要排除二叉树为空的情况,当二叉树不为空时,算出左子树和右子树的高度,最后比较左右子树的高度差,并且利用分治算法
继续比较下面左右子树是否满足平衡二叉树的条件。
六.二叉树的销毁
c
void DestoryTree(struct TreeNode* root)
if(root==NULL)
{
return;//当节点为空时,分治算法终止。
}
DestoryTree(root->left);
DestoryTree(root->right);
free(root);
root=NULL;二叉树的销毁不能从上向下销毁,应该从下向上销毁,也就是后序遍历顺便销毁节点。所以代码首先需要排除二叉树为空的情况(分治算法的终止条件),随后依次释放左子树和右子树的空间。最后将该节点置为空指针。
本代码采用分治算法的思想,首先通过递归函数不断递归释放左右子树的空间,之后释放根结点的空间。
七.二叉树的遍历
下面是有关二叉树遍历的题目,题目内容大致是输入一串字符串,这个字符串是二叉树节点前序遍历的结果,在最后题目需要我们将其中序遍历的结果字符串打印在屏幕上。
c
#include <stdio.h>
typedef struct TreeNode//创建一个二叉树的节点
{
struct TreeNode* left;//左子树节点地址
struct TreeNode* right;//右子树节点地址
char val;//节点存储的数据
}TNode;
TNode* CreateTree(char* a,int* pi)//利用数组创建二叉树的结构,这里之所以用pi是为了保证下标自增时为同一个变量。
{
if(a[*pi]==#)
{
++(*pi);//当下标为字符#时,说明该二叉树节点为空
return NULL;
}
TNode* root=(TNode*)malloc(sizeof(TNode));//创建一个二叉树的节点空间
if (root==NULL)
{
printf("malloc fail");
exit(-1);
}
root->val=a[*pi];//将数组内容存储到新创建的二叉树空间中去
++(*pi);
root->left=CreateTree(a,pi);//根据数组的顺序进行分治算法的展开
root->right=CreateTree(a,pi);
return root;
}
void InOrder(TNode* root)//中序遍历之后数组打印函数
{
if(root==NULL)
return;
InOder(root->left);
printf("%c",root->val);
InOrder(root->right);
}
int main()
{
char str[100];
scanf("%s",str);
int i=0;
TNode* root=CreateTree(str,&i);
InOrder(root);
return 0;
}上述代码的具体解释:本题目需要先根据输入的字符串创建二叉树的结构,随后将该二叉树的中序遍历的结果打印即可。
所以我们首先利用结构体的知识搭建出二叉树节点的框架,之后根据数组内容构建出二叉树的结构,随后利用二叉树的结构得出中序遍历的数组序列。