本文整理自 B 站视频《LLVM后端流程与关键数据结构》和本地 PPT《LLVM - Another Toolchain Platform》。文章面向刚接触 LLVM 后端的同学,重点不是背类名,而是把"一个后端到底在 LLVM 里做什么"讲清楚。
关键词:LLVM、编译器后端、SelectionDAG、MachineInstr、MCInst、TableGen、汇编器、反汇编器
1. 先说清楚:什么是工具链?
写一个 C 程序,最后能跑起来,中间不是只有一个"编译器"在工作,而是一整套工具在接力。
常见工具链大致包括:
| 工具 | 作用 |
|---|---|
| 编译器前端 | 读取 C/C++/Objective-C 等源代码,做词法、语法、语义分析,生成中间表示 |
| 编译器后端 | 把中间表示翻译成目标机器能理解的汇编或机器码 |
| 汇编器 | 把 .s 汇编文本转成 .o 目标文件 |
| 链接器 | 把多个 .o 和库链接成可执行文件或动态库 |
| 反汇编器 | 把机器码还原成汇编文本,便于分析 |
| 调试器 | 运行、断点、查看寄存器和内存 |
这就是 toolchain,也就是"工具链"。它叫"链",是因为前一个工具的输出往往就是后一个工具的输入。
LLVM 不只是一个编译器,它更像一个工具链平台。你可以用 Clang 做 C/C++ 前端,用 LLVM IR 作为中间表示,用 LLVM 后端生成 x86、ARM、RISC-V 等平台的代码,还可以复用 LLVM 的汇编、反汇编、目标文件处理、调试等基础设施。
2. LLVM 编译流程的主线
先看最简化的流程:
text
C/C++ 源文件
|
| clang 前端
v
LLVM IR
|
| LLVM 后端,例如 llc
v
汇编文件 .s
|
| 汇编器
v
目标文件 .o
|
| 链接器
v
可执行文件可以用下面的命令亲手感受一下:
bash
clang -S -emit-llvm hello.c -o hello.ll
llc hello.ll -o hello.s
clang hello.s -o hello第一条命令把 C 代码变成 LLVM IR。第二条命令把 LLVM IR 交给后端,生成汇编。第三条命令继续完成汇编和链接。
如果你要指定目标平台,老版本资料里常见:
bash
llc -march=XX -mcpu=XY hello.ll -o hello.s在较新的 LLVM 中,也经常看到:
bash
llc -mtriple=riscv64-unknown-elf hello.ll -o hello.s具体参数以你使用的 LLVM 版本为准。PPT 中有些配置文件和示例来自较早版本,概念仍然有参考价值,但源码路径和构建方式可能已经变化。
3. LLVM 后端到底负责哪几件事?
从使用者角度看,LLVM 后端主要有 4 个能力:
| 输入 | 输出 | 对应能力 |
|---|---|---|
| LLVM IR | 汇编文件 .s |
静态编译中的代码生成 |
| LLVM IR | 目标文件 .o |
直接输出二进制目标文件 |
汇编文件 .s |
目标文件 .o |
汇编 |
目标文件 .o |
汇编文本 | 反汇编 |
很多初学者一开始以为"后端 = IR 变汇编"。这只说对了一部分。LLVM 后端还包含了和机器指令、目标文件格式、汇编解析、反汇编相关的一整套 MC Layer,也就是 Machine Code Layer。
所以理解 LLVM 后端,建议先分成两大块:
text
第一部分:LLVM IR -> MachineInstr
第二部分:MachineInstr -> MCInst -> 汇编文本或目标文件第一部分更像传统意义上的"代码生成"。第二部分更接近汇编器、反汇编器和目标文件处理。
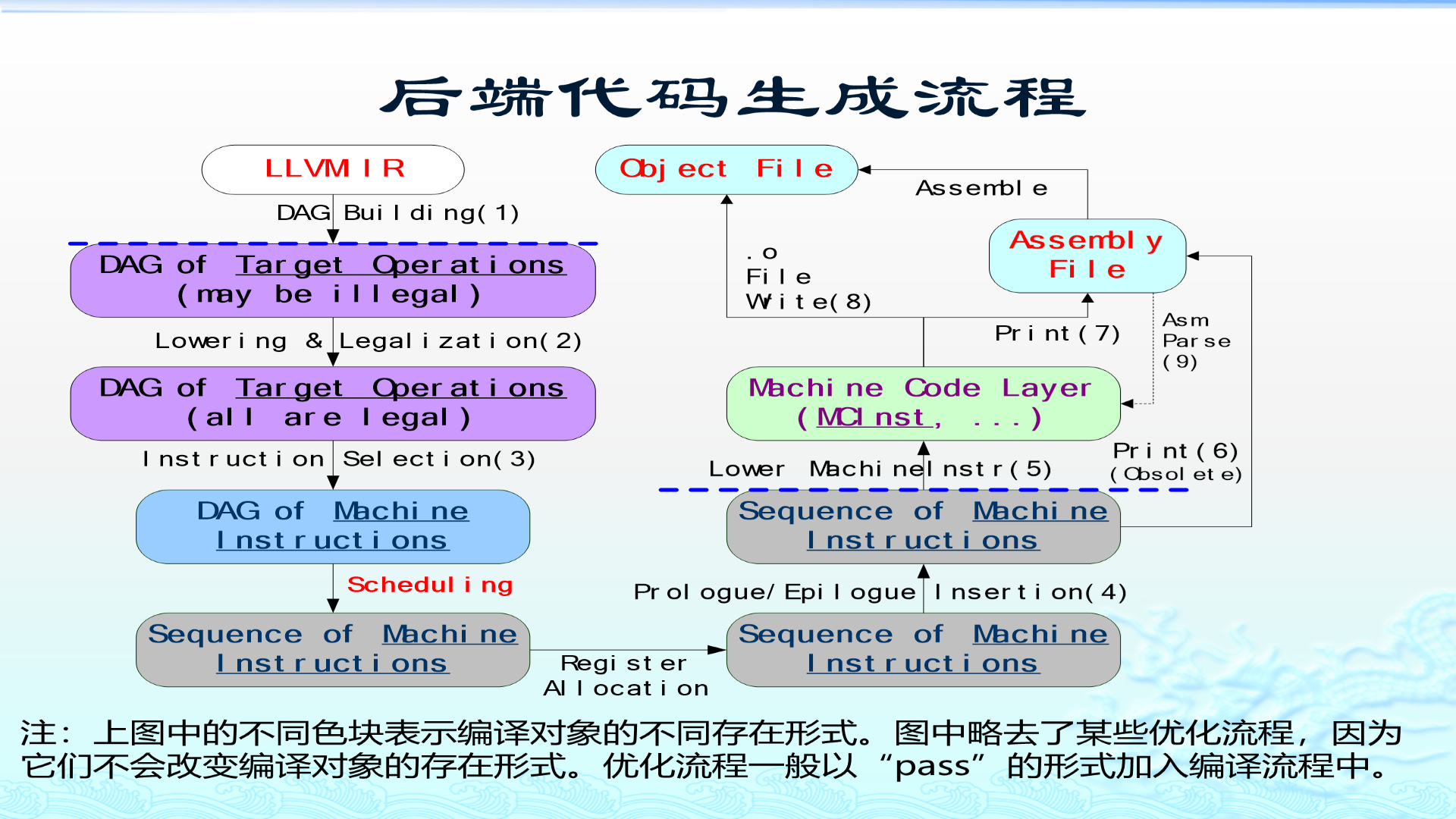
4. 第一部分:从 LLVM IR 到 MachineInstr
LLVM IR 是一种比较高级的中间表示。它有类型信息,适合做优化,也适合作为前端和后端之间的公共语言。
但是 CPU 不认识 LLVM IR。目标机器真正能执行的是具体指令,例如 x86 的 addq、ARM 的 ldr、RISC-V 的 addi。后端第一部分要做的事情,就是把 LLVM IR 一步步变成接近真实机器指令的 MachineInstr。
整体流程可以理解为:
text
LLVM IR
|
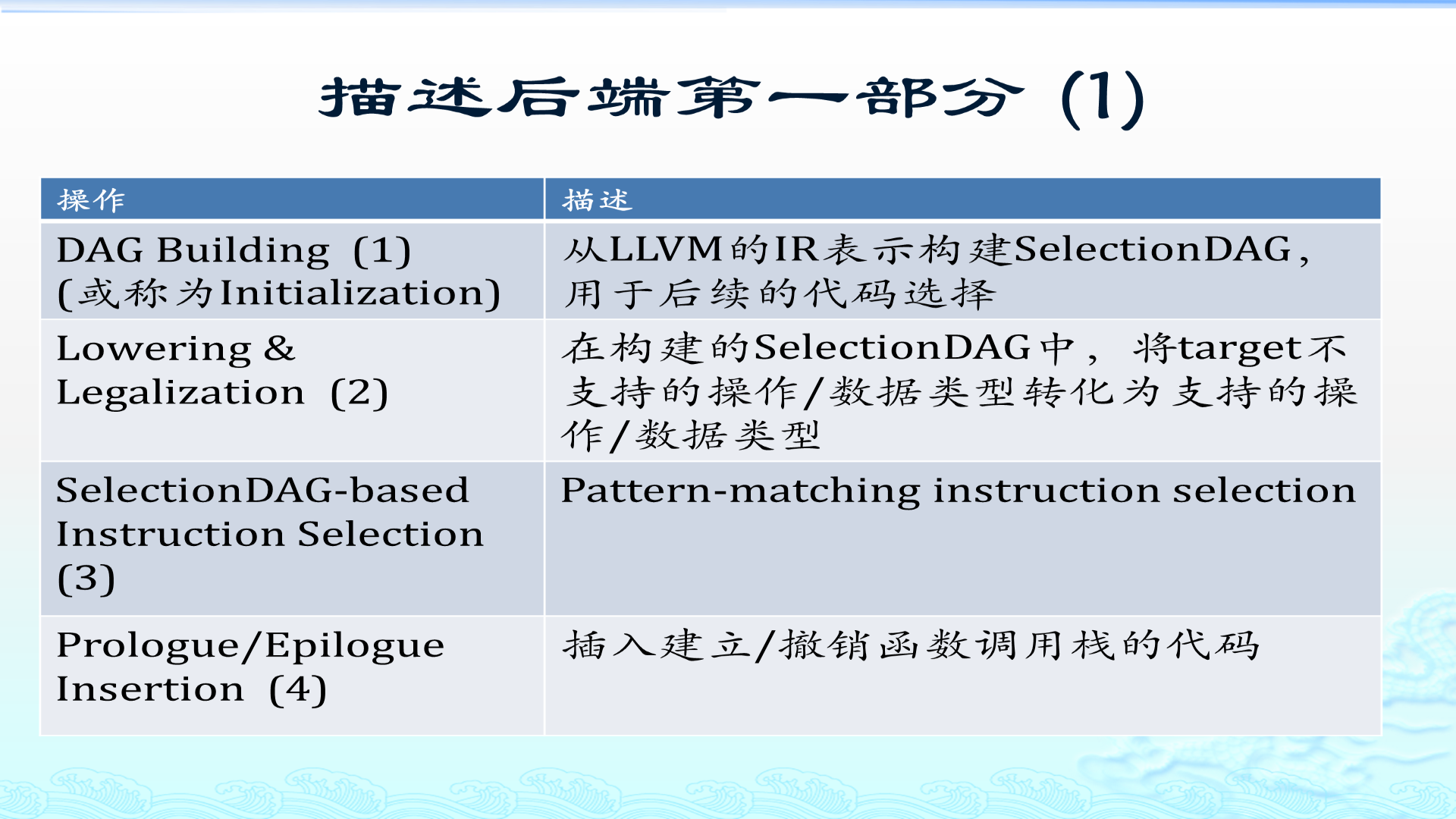
| 1. DAG Building
v
SelectionDAG,里面可能有目标不支持的操作或类型
|
| 2. Lowering & Legalization
v
SelectionDAG,所有操作和类型都被目标支持
|
| 3. Instruction Selection
v
MachineInstr DAG
|
| 4. Scheduling
v
MachineInstr 序列
|
| 5. Register Allocation
v
完成寄存器分配的 MachineInstr 序列
|
| 6. Prologue/Epilogue Insertion
v
最终的 MachineInstr 序列下面逐步解释。

4.1 DAG Building:把 IR 建成 SelectionDAG
DAG 是 Directed Acyclic Graph,也就是有向无环图。
在 LLVM 后端中,SelectionDAG 用来表达"值和操作之间的依赖关系"。比如:
c
extern int *a;
extern int *b;
int foo(void) {
return *a + *b;
}这里至少包含:
- 读取全局变量
a的地址; - 从
a指向的位置 load; - 读取全局变量
b的地址; - 从
b指向的位置 load; - 把两个 load 出来的值相加;
- 返回结果。
这些操作之间有依赖关系,所以适合用 DAG 表示。
在代码层面,常见关键类包括:
| 概念 | 类 |
|---|---|
| 整张 DAG | SelectionDAG |
| DAG 节点 | SDNode |
| DAG 边或节点输出值 | SDValue |
| 通用操作码 | ISD::ADD、ISD::MUL、ISD::LOAD 等 |
需要特别注意:SDValue 不是"值本身"那么简单,它更像"某个节点的某个结果"。一个 SDNode 可以产生多个结果,所以 LLVM 用 SDValue 来精确表示"我要拿这个节点的第几个输出"。
4.2 Lowering & Legalization:把目标不支持的东西改成支持的东西
刚构建出来的 SelectionDAG 不一定能被目标机器直接支持。原因很简单:LLVM IR 是通用的,但硬件各有各的限制。
举几个例子:
| LLVM IR 或初始 DAG 中的东西 | 某些目标可能不支持 | 后端要做什么 |
|---|---|---|
i64 加法 |
32 位 CPU 可能没有直接的 64 位加法 | 拆成多个 32 位操作 |
乘累加 a * b + c |
有的 DSP 有 MAC 指令,有的没有 | 有 MAC 就匹配 MAC,没有就拆成乘法和加法 |
| 浮点操作 | 小型 MCU 可能没有硬件浮点 | 转成运行时库调用或软浮点序列 |
| 特殊寻址模式 | 目标 CPU 不支持 | 改写成多个简单操作 |
这一步常见地由目标相关的 lowering 类控制,例如:
text
lib/Target/XX/XXISelLowering.h
lib/Target/XX/XXISelLowering.cpp其中 XX 代表你的目标架构名称。这个类通常继承自 TargetLowering。
一个经典例子是拆分乘累加:
cpp
// 伪代码:把 mac(a, b, c) 拆成 a * b + c
SDValue LowerMAC(SDValue Op, SelectionDAG &DAG) {
DebugLoc DL = Op.getDebugLoc();
SDValue Mul = DAG.getNode(ISD::MUL, DL, MVT::i32,
Op.getOperand(0),
Op.getOperand(1));
SDValue Add = DAG.getNode(ISD::ADD, DL, MVT::i32,
Mul,
Op.getOperand(2));
return Add;
}初学者可以把 lowering 理解为一句话:
lowering 负责把"LLVM 想表达的操作"改写成"当前目标机器能处理的操作"。
4.3 Instruction Selection:把 DAG 模式匹配成真实指令
Lowering 之后,DAG 中的操作已经合法了,但它仍然不是具体机器指令。
Instruction Selection,也就是指令选择,负责把类似:
text
(add i32:$lhs, i32:$rhs)匹配成某个目标架构的真实指令,例如:
asm
add r1, r2, r3在 LLVM 后端里,这一步大量依赖 TableGen 中的指令描述。比如我们用 TableGen 写:
tablegen
def AddI32 : Instruction {
let OutOperandList = (outs I32Reg:$d);
let InOperandList = (ins I32Reg:$s1, I32Reg:$s2);
let AsmString = "add $d, $s1, $s2";
let Pattern = [(set I32Reg:$d, (add I32Reg:$s1, I32Reg:$s2))];
}这里的 Pattern 表示:
text
如果看到一个 i32 加法,并且两个输入来自 I32Reg,
就可以选择 AddI32 这条目标指令。目标相关代码通常在:
text
lib/Target/XX/XXISelDAGToDAG.h
lib/Target/XX/XXISelDAGToDAG.cpp对应类名常见为 XXDAGToDAGISel,基类通常是 SelectionDAGISel。
4.4 Scheduling:指令调度
指令选择之后,我们已经拿到了 MachineInstr 形式的机器指令,但这些指令还不一定是最佳顺序。
现代 CPU 有流水线、访存延迟、执行单元限制等问题。调度器会尝试调整指令顺序,让 CPU 更高效地执行,同时不能破坏依赖关系。
这一步仍然发生在 MachineInstr 层面。
4.5 Register Allocation:寄存器分配
LLVM IR 和 SelectionDAG 中经常使用虚拟寄存器。虚拟寄存器可以很多,但真实硬件寄存器数量有限。
寄存器分配要解决:
text
虚拟寄存器 vreg1、vreg2、vreg3 ...
应该放到真实寄存器 r0、r1、r2 ...
还是因为寄存器不够而溢出到栈上?这一步完成后,MachineInstr 会更接近最终机器代码。
4.6 Prologue/Epilogue Insertion:插入函数入口和出口代码
函数不是只有你写的主体逻辑。真正生成机器代码时,函数入口和出口往往还要处理:
- 调整栈指针;
- 保存和恢复被调用者保存寄存器;
- 建立或销毁栈帧;
- 处理返回地址;
- 对齐栈空间。
这部分通常和 XXFrameLowering 有关,常见文件:
text
lib/Target/XX/XXFrameLowering.h
lib/Target/XX/XXFrameLowering.cpp5. 第二部分:从 MachineInstr 到 MCInst
到这里我们已经有了 MachineInstr。那为什么还要有 MCInst?
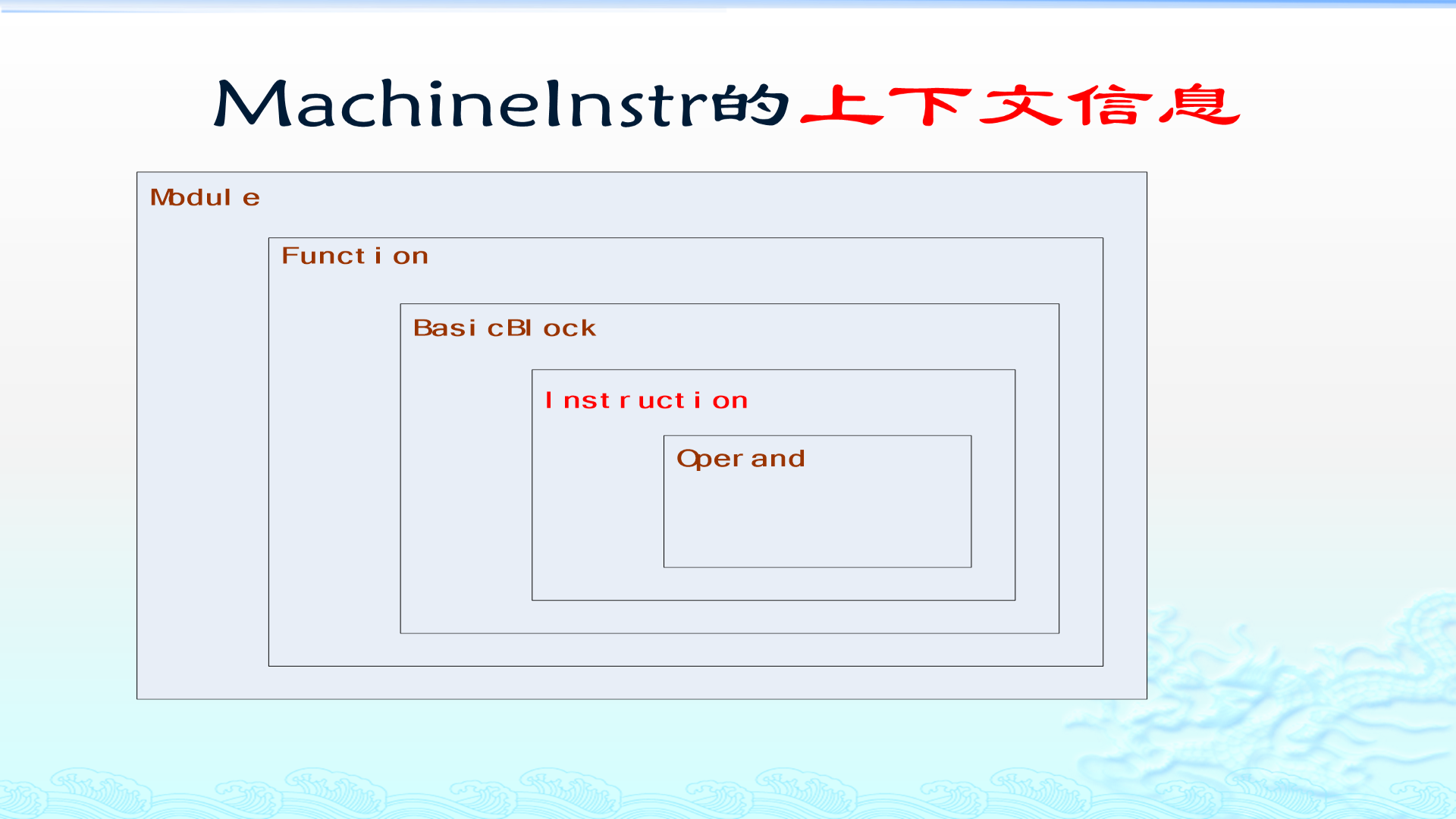
原因是 MachineInstr 信息太丰富了。它不仅包含 opcode 和 operand,还知道自己在哪个 MachineBasicBlock、哪个 MachineFunction,还有调度、寄存器分配、调试、pass 所需的上下文。
但到了汇编打印、指令编码、目标文件输出这一层,我们并不需要那么多上下文。我们更关心:
text
这条指令的 opcode 是什么?
操作数是什么?
怎么打印成汇编?
怎么编码成机器码?
有没有重定位?
应该写进哪个 section?因此 LLVM 引入了更轻量的 MCInst。
| 数据结构 | 所在阶段 | 可以粗略理解为 |
|---|---|---|
MachineInstr |
代码生成阶段 | 带上下文的机器指令 |
MCInst |
MC Layer | 极简机器指令,只关心 opcode 和 operands |
PPT 中给出的 MCInst 组成很适合作为入门记忆:
text
MCInst
- Opcode
- Operand
- Register
- Immediate
- FPImmediate
- Expression
- MCInst发射接口大致是:
cpp
MCStreamer::EmitInstruction(MCInst);可以把 MCStreamer 理解为 MC 层的"流水线出口"。它接收 MCInst,然后根据具体 streamer 的实现,把指令打印成汇编、编码进目标文件,或者用于其它工具。
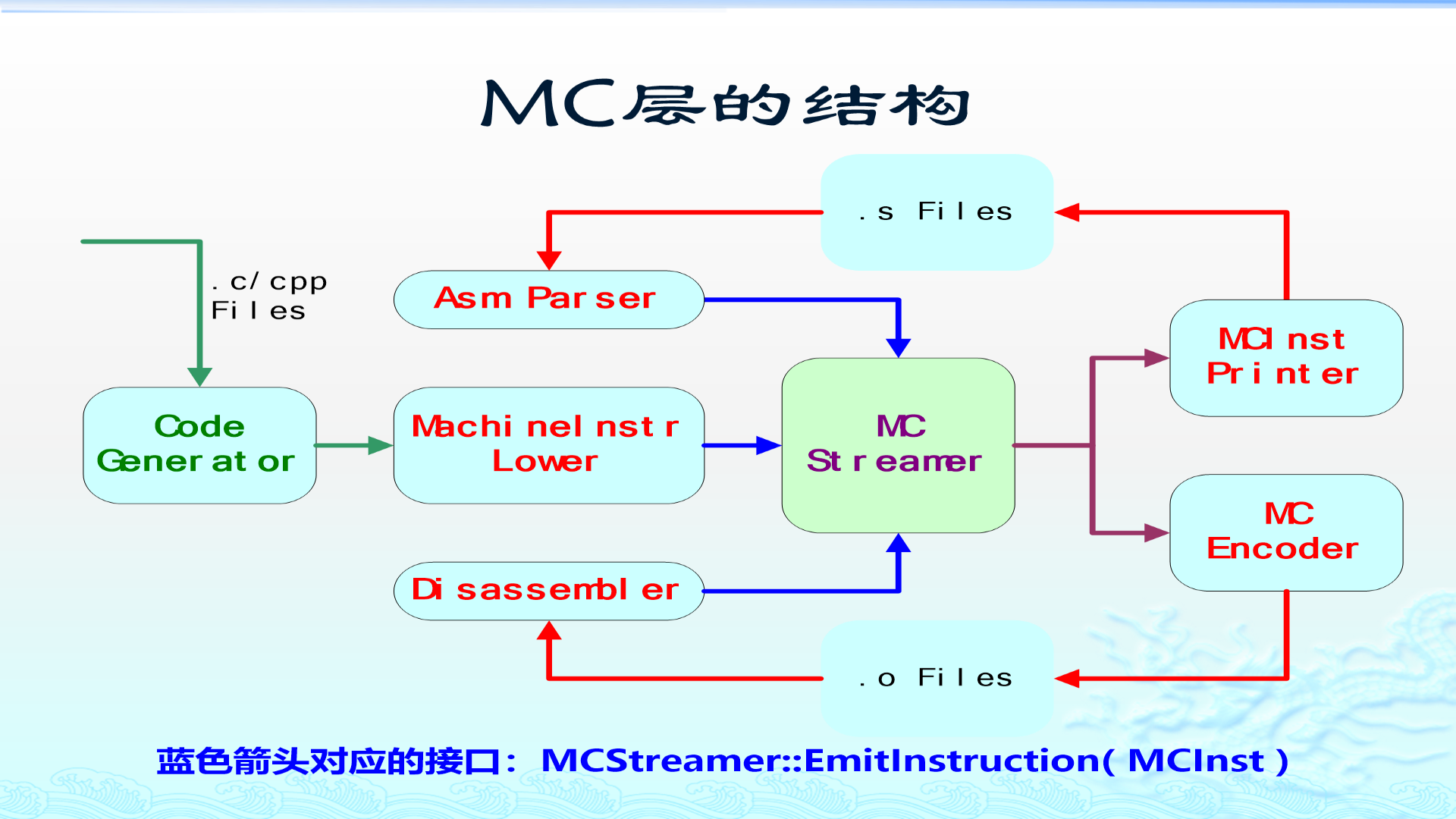
6. MC Layer:汇编、反汇编和目标文件的共同基础
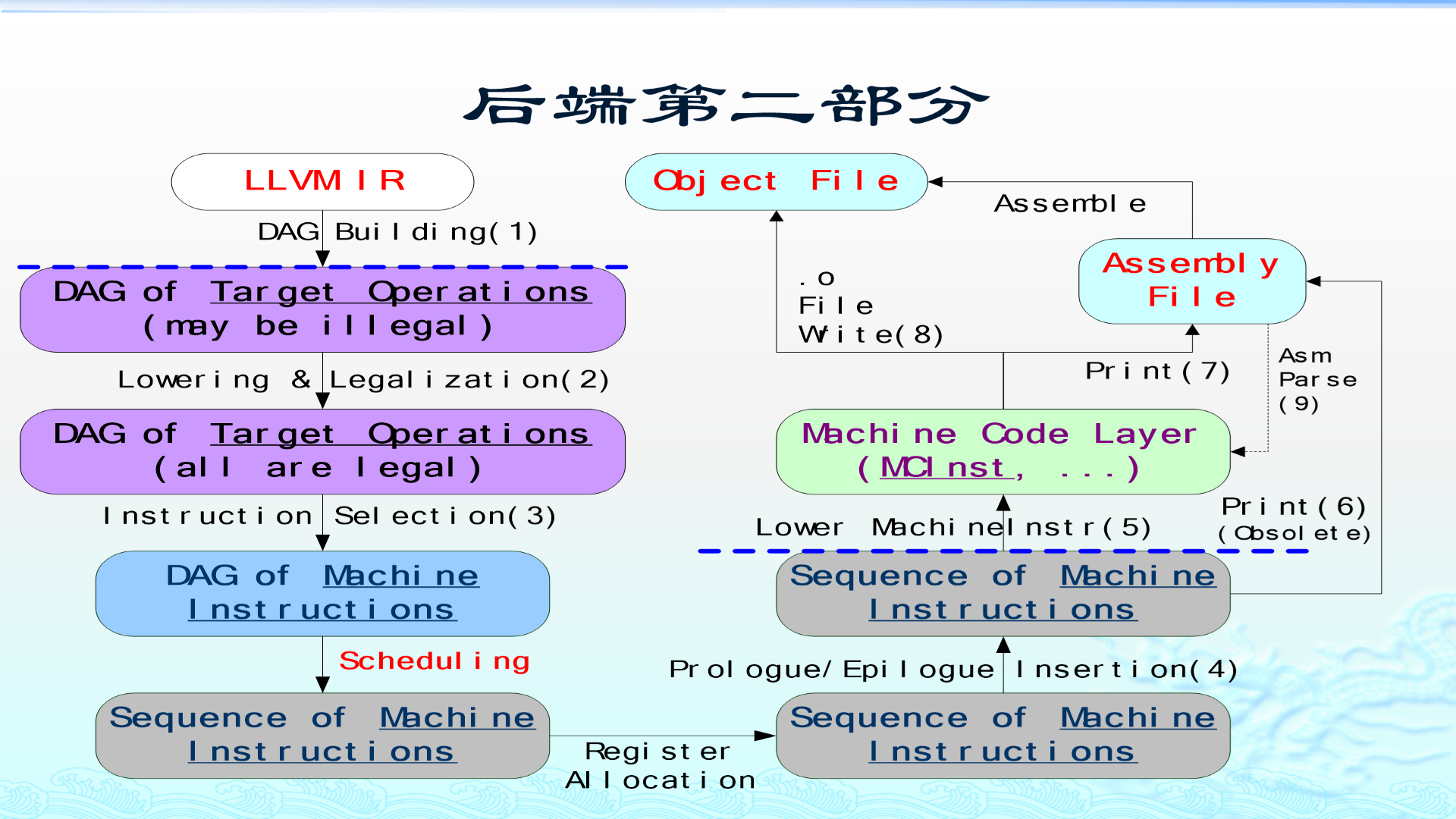
MC Layer 的结构可以这样理解:
text
.s 汇编文件
|
| AsmParser
v
CodeGen -> MachineInstrLower -> MCInst -> MCStreamer
|
+-------------------+-------------------+
| |
v v
MCInstPrinter MCCodeEmitter
| |
v v
.s 汇编文本 .o 目标文件
.o 目标文件 -> Disassembler -> MCInst这一层涉及很多类。初学者先抓住下表即可:


| 功能 | 常见类 | 作用 |
|---|---|---|
| MachineInstr 转 MCInst | XXMCInstLower |
去掉 MachineInstr 上下文,抽取 opcode 和 operand |
| 打印汇编 | XXAsmPrinter、XXInstPrinter |
把指令输出为人能读的汇编文本 |
| 指令编码 | XXMCCodeEmitter |
把 MCInst 编码成机器码字节 |
| 处理 fixup/relax | XXAsmBackend |
处理重定位、指令放松等汇编后端细节 |
| 写目标文件 | XXELFObjectWriter 等 |
输出 ELF、COFF、Mach-O 等格式 |
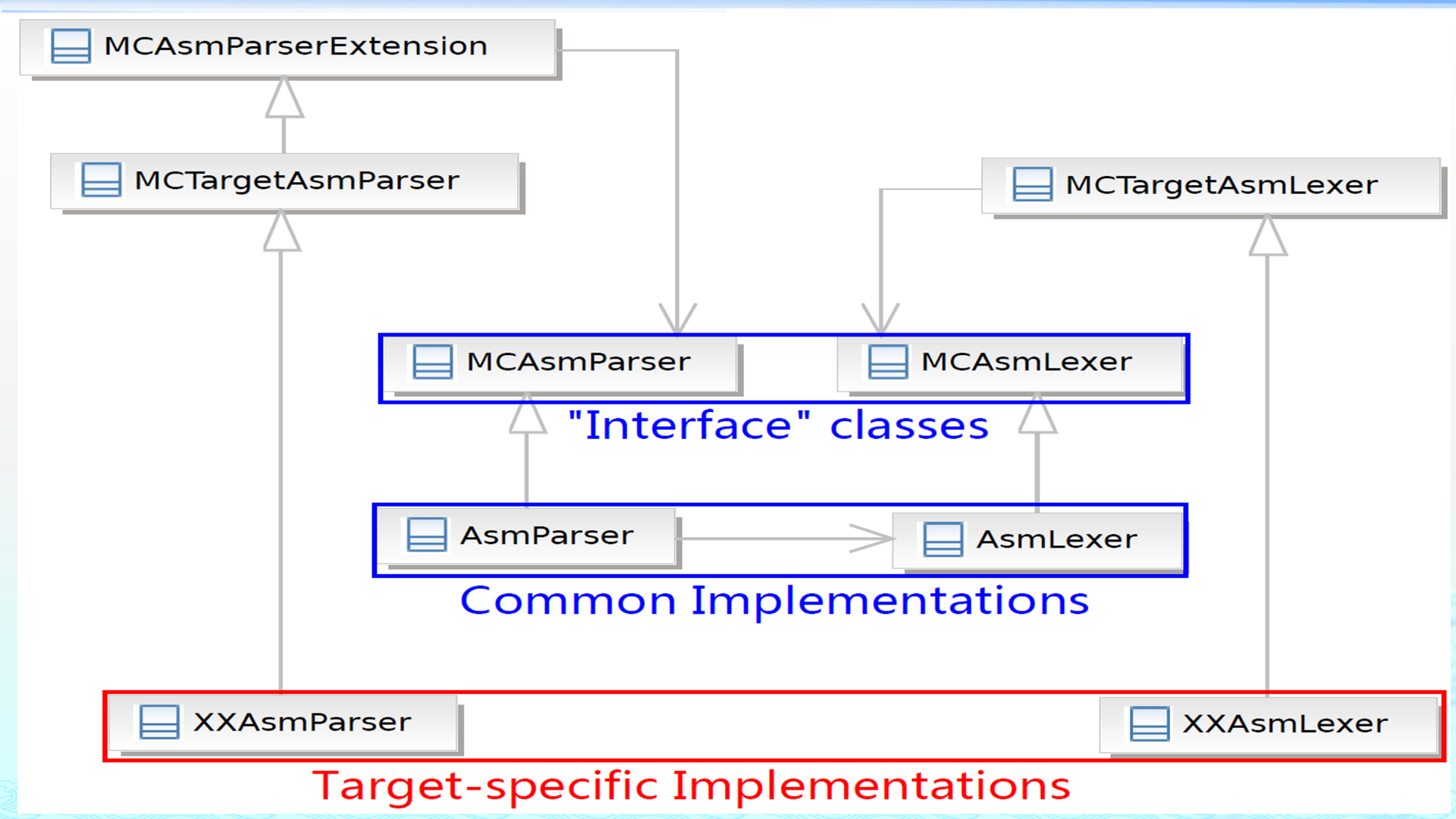
| 解析汇编 | XXAsmParser、XXAsmLexer |
把 .s 文本解析成 MCInst |
| 反汇编 | XXDisassembler |
把机器码解码成 MCInst |
这就是为什么 LLVM 后端不只是 llc 生成汇编,还能支撑 llvm-mc、llvm-objdump 等工具。
7. TableGen:不要手写重复代码
如果你要支持一套新指令集,最痛苦的事情是什么?
不是写一两条指令,而是写成百上千条指令,并且每条指令都可能要描述:
- 指令名;
- 输入操作数;
- 输出操作数;
- 汇编格式;
- 指令选择模式;
- 二进制编码;
- 寄存器约束;
- 调用约定;
- 调度信息。
这些内容非常结构化,所以 LLVM 使用 TableGen 来描述它们,再由 llvm-tblgen 生成 C++ 可包含的 .inc 文件。
典型组织关系如下:
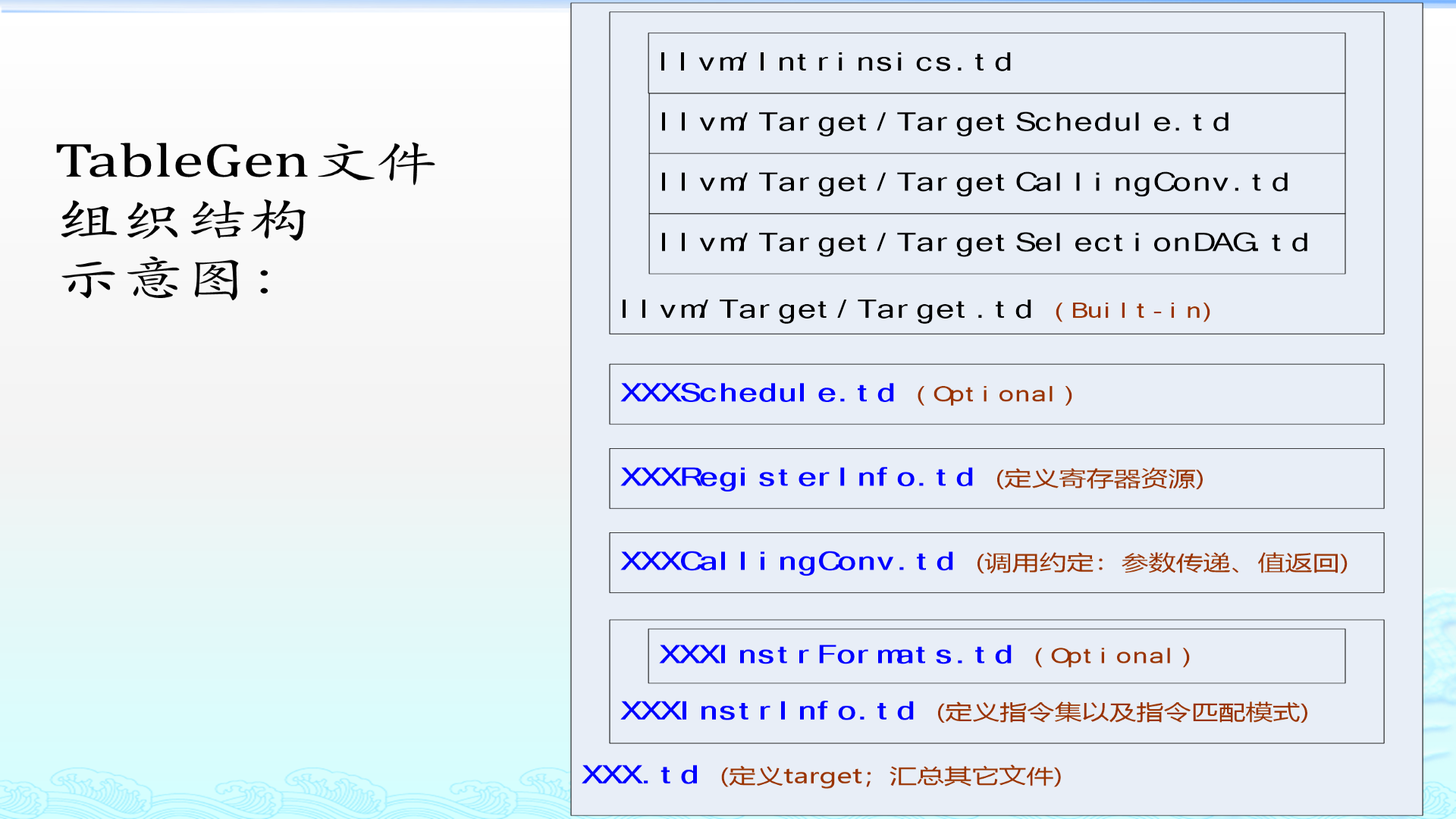
text
XXX.td
|
+-- include "llvm/Target/Target.td"
|
+-- XXXRegisterInfo.td
+-- XXXCallingConv.td
+-- XXXInstrFormats.td
+-- XXXInstrInfo.td
+-- XXXSchedule.td构建时大致会执行:
bash
llvm-tblgen [options] XXX.td然后生成类似:
text
XXXGenInstrInfo.inc
XXXGenRegisterInfo.inc
XXXGenAsmWriter.inc
XXXGenDAGISel.inc
XXXGenDisassemblerTables.inc这些 .inc 文件会被目标后端的 C++ 源码 #include 进去。
7.1 指令描述的两个方面
一条指令至少要描述两类信息。
第一类是"长什么样":
tablegen
let OutOperandList = (outs I32Reg:$d);
let InOperandList = (ins I32Reg:$s1, I32Reg:$s2);
let AsmString = "add $d, $s1, $s2";这告诉 LLVM:
text
这条指令有一个输出寄存器 d;
有两个输入寄存器 s1、s2;
汇编文本打印成 add d, s1, s2。第二类是"语义是什么":
tablegen
let Pattern = [(set I32Reg:$d, (add I32Reg:$s1, I32Reg:$s2))];这告诉 LLVM:
text
这条目标指令可以实现 SelectionDAG 里的 add 操作。如果一条指令没有 Pattern,它不一定不能用。它可能不会参与自动指令选择,但仍然可以在伪指令展开、汇编器、反汇编器或手写代码生成中使用。
7.2 寄存器和调用约定
TableGen 也常用来描述寄存器:
tablegen
def R0 : Register<"R0">;
def R1 : Register<"R1">;
def I32Reg : RegisterClass<"XX", [i32], 32, (sequence "R%u", 0, 31)>;这里表示:
text
R0、R1 是物理寄存器;
I32Reg 是一组能放 i32 的寄存器类;
它包含 R0 到 R31。调用约定也可以用 TableGen 描述,例如:
tablegen
def XX_CC : CallingConv<[
CCIfType<[i32], CCAssignToReg<[R0, R1, R2, R3]>>
]>;意思是:如果函数参数类型是 i32,优先放到 R0 到 R3 这些寄存器中。
实际后端会比这个例子复杂得多,但初学者先理解"参数如何传递、返回值放哪里、哪些寄存器要保存"都属于调用约定问题即可。
8. 如果要实现一个 LLVM 后端,大概要做什么?
PPT 给出的路径很适合建立整体认识,可以整理为 6 步。
第 0 步:先读资料
至少建议读:
- LLVM 官方文档:Writing an LLVM Backend;
- LLVM 官方文档:The LLVM Target-Independent Code Generator;
- 一个现有后端的源码,例如你当前 LLVM 版本里的
llvm/lib/Target/RISCV、llvm/lib/Target/AVR、llvm/lib/Target/Mips等; - TableGen 文档。
不要一上来就从零写。LLVM 后端涉及的接口很多,直接从一个现有目标改起更容易摸到边界。
第 1 步:复制或参考一个已有 Target
PPT 中以 MBlaze 为例。需要注意,MBlaze 是旧版本 LLVM 中较常见的学习例子,新版本中未必还存在。
现在更现实的做法是:
- 选择你本地 LLVM 版本中仍然存在的目标;
- 选规模不要太大的;
- 同时参考成熟目标,例如 X86、AArch64、RISCV;
- 如果是 out-of-tree backend,先搭好独立构建框架。
第 2 步:接入构建和 Target 注册
一个目标要能被 LLVM 识别,至少要进入目标注册系统。
老版本资料里会看到:
text
configure
autoconf/configure.ac
LLVMBuild.txt新版本 LLVM 主要看 CMake 相关文件,以及目标注册、Triple、TargetParser 等位置。具体文件随版本变化,一定要以你使用的源码版本为准。
概念上,你要完成的是:
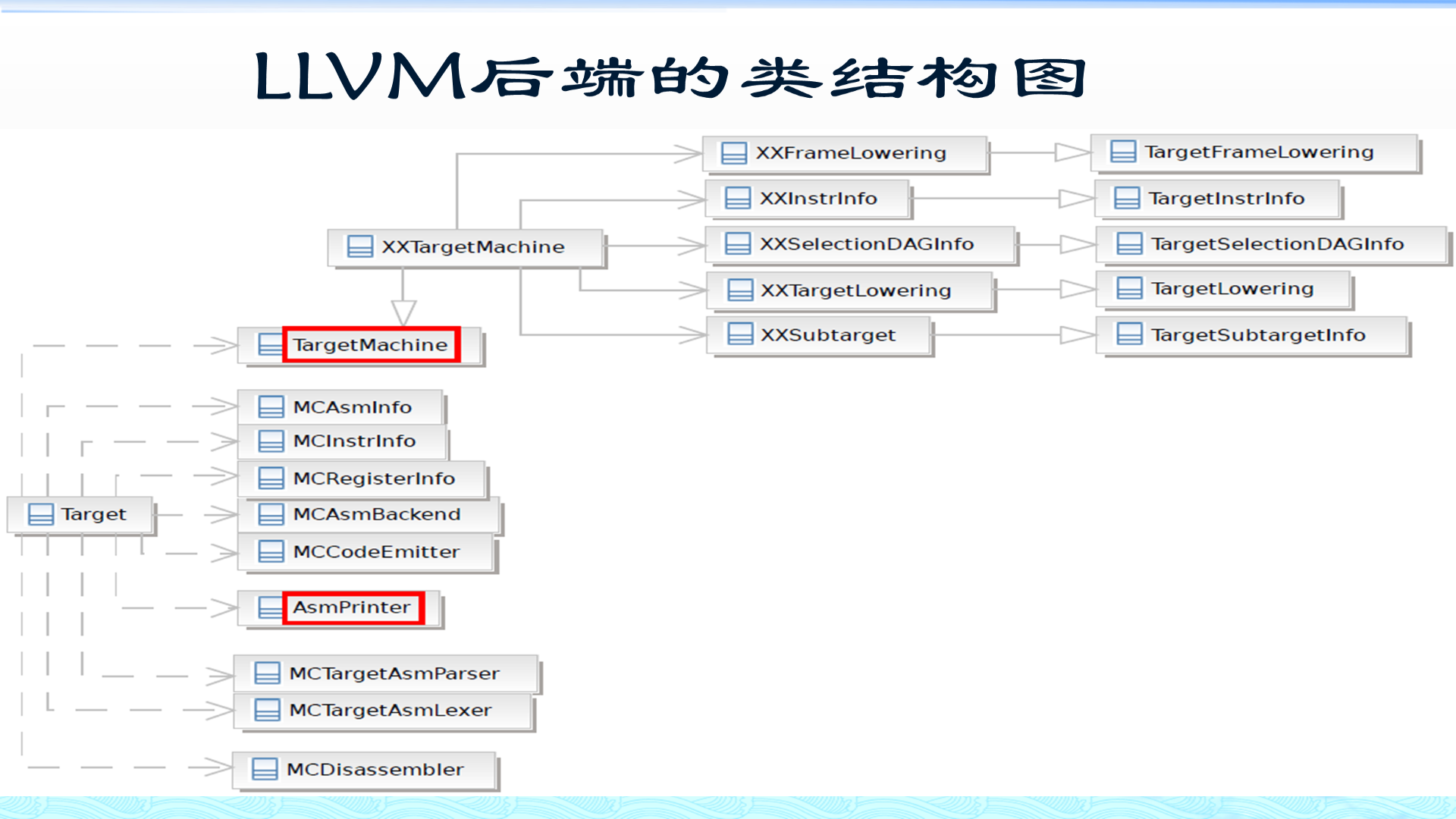
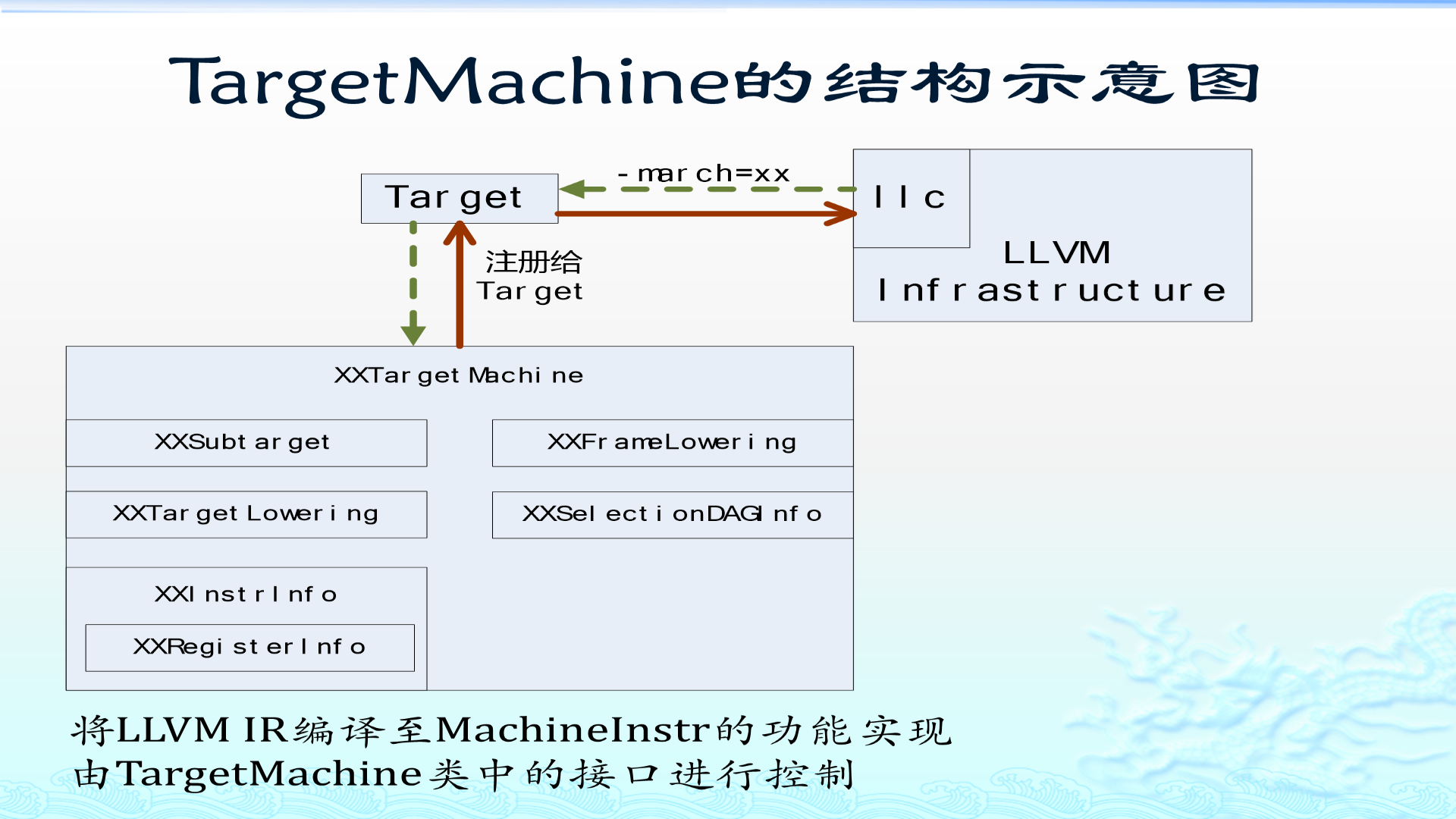
text
让 LLVM 知道存在一个叫 XX 的目标;
让 llc -march=xx 或类似参数能找到它;
让构建系统能编译 lib/Target/XX;
让 TableGen 能生成 XX 相关的 inc 文件。第 3 步:整理目标目录中的源码和 TableGen
目标目录通常包括:
text
lib/Target/XX/
XX.td
XXInstrInfo.td
XXRegisterInfo.td
XXCallingConv.td
XXSubtarget.h/.cpp
XXTargetMachine.h/.cpp
XXISelLowering.h/.cpp
XXISelDAGToDAG.cpp
XXFrameLowering.h/.cpp
MCTargetDesc/
InstPrinter/
AsmParser/
Disassembler/不是每个后端一开始都要完整实现所有目录,但这些名字代表了后端的主要职责。
第 4 步:先让它能编译
这一步很朴素,但非常重要。
你可能会遇到:
- CMake 没接好;
- TableGen 文件有语法错误;
- 生成的
XXGen*.inc缺字段; - C++ 类没有实现必要接口;
- Target 注册名称不一致;
- Triple 或 CPU feature 没处理好。
排错时要重点看构建目录下生成的:
text
lib/Target/XX/XXGen*.inc很多"为什么我的指令没被识别""为什么寄存器类不对"的问题,最终都能在生成文件中找到线索。
第 5 步:逐步支持目标特性
让一个后端能编译,不等于它能生成正确代码。
后面要逐步补齐:
| 模块 | 解决的问题 |
|---|---|
XXRegisterInfo |
有哪些寄存器,哪些保留,如何消除 frame index |
XXInstrInfo |
指令属性、拷贝、分支分析等 |
XXTargetLowering |
不支持的 IR 操作如何 lowering |
XXDAGToDAGISel |
SelectionDAG 如何匹配目标指令 |
XXFrameLowering |
栈帧、函数入口和出口如何生成 |
XXSubtarget |
不同 CPU、feature、指令扩展如何区分 |
XXTargetMachine |
如何组织 pass pipeline 和目标配置 |
第 6 步:接入汇编器和反汇编器
如果只想 llc 输出 .s,可以先做最小实现。
如果想进一步支持:
bash
llc -filetype=obj input.ll -o input.o
llvm-mc -filetype=obj input.s -o input.o
llvm-objdump -d input.o就要补齐 MC 层能力:
| 目录或文件 | 作用 |
|---|---|
MCTargetDesc/XXMCCodeEmitter.cpp |
指令编码 |
MCTargetDesc/XXAsmBackend.cpp |
fixup、relaxation、重定位相关 |
MCTargetDesc/XXELFObjectWriter.cpp |
ELF 目标文件写出 |
InstPrinter/XXInstPrinter.cpp |
MCInst 打印成汇编 |
AsmParser/XXAsmParser.cpp |
汇编文本解析 |
Disassembler/XXDisassembler.cpp |
机器码反汇编 |
这部分是 LLVM 作为"工具链平台"的关键。只实现 IR 到汇编,还不能算完整工具链。
9. 初学者最容易混淆的几个问题
9.1 Lowering 和 Instruction Selection 有什么区别?
Lowering 解决"目标机器能不能表达"的问题。
Instruction Selection 解决"用哪条目标指令表达"的问题。
举例:
text
LLVM IR 里有一个操作 A
目标机器没有 A那就先 lowering,把 A 改成 B + C。
之后再 instruction selection,把 B 和 C 分别匹配成具体机器指令。
9.2 MachineInstr 和 MCInst 为什么不能合并?
因为它们服务的阶段不同。
MachineInstr 在代码生成阶段使用,需要携带大量上下文,方便做调度、寄存器分配、栈帧处理、pass 分析。
MCInst 在 MC 层使用,只需要表示"这条机器指令是什么"。它越简单,越适合被汇编器、反汇编器、指令编码器、目标文件写出器共同复用。
9.3 TableGen 是不是能自动生成整个后端?
不能。
TableGen 能帮你生成大量结构化代码,例如指令信息、寄存器信息、匹配表、汇编打印表、反汇编表。但目标相关的 lowering、复杂寻址模式、栈帧处理、特殊 ABI、伪指令展开等逻辑,仍然需要写 C++。
更准确地说:
text
TableGen 负责描述规则;
C++ 负责处理规则覆盖不到的控制逻辑。9.4 为什么 LLVM 后端资料经常看起来"版本对不上"?
LLVM 发展很快,后端接口、构建系统和目录组织会变。
例如早期资料中会提到 configure、autoconf、LLVMBuild.txt、MBlaze 等内容,新版本可能已经变化或移除。
学习时建议分两层看:
- 概念层:IR、SelectionDAG、MachineInstr、MCInst、TableGen、MC Layer,这些主线长期有效;
- 实现层:具体类名、函数签名、构建文件、目录路径,以你当前 LLVM 版本源码为准。
10. 建议的学习路线
如果你是初学者,不建议一开始就写完整后端。可以按下面的顺序来:
第一步:先跑通 IR 到汇编
准备一个 hello.c:
c
int add(int a, int b) {
return a + b;
}生成 IR:
bash
clang -S -emit-llvm hello.c -o hello.ll生成汇编:
bash
llc hello.ll -o hello.s观察 hello.ll 和 hello.s 的差异。
第二步:理解一条 add 指令如何被选出来
去目标后端里找:
text
XXXInstrInfo.td
XXXISelLowering.cpp
XXXISelDAGToDAG.cpp重点看:
add的 TableGen pattern;- 是否有 custom lowering;
- 是否有手写选择逻辑。
第三步:理解寄存器
看:
text
XXXRegisterInfo.td
XXXRegisterInfo.cpp重点看:
- 物理寄存器如何定义;
- 寄存器类如何定义;
- 哪些寄存器是 reserved;
- frame index 如何消除。
第四步:理解函数调用
看:
text
XXXCallingConv.td
XXXISelLowering.cpp
XXXFrameLowering.cpp重点看:
- 参数放寄存器还是栈;
- 返回值放哪里;
- caller-saved 和 callee-saved 寄存器;
- prologue/epilogue 如何生成。
第五步:理解 MC Layer
尝试使用:
bash
llvm-mc -filetype=obj input.s -o input.o
llvm-objdump -d input.o再回头看:
text
MCTargetDesc/
InstPrinter/
AsmParser/
Disassembler/这时候 MCInst、MCStreamer、MCCodeEmitter、AsmBackend 这些概念会更容易串起来。
11. 一句话总结
LLVM 后端不是一个简单的"翻译函数",而是一条从高级 IR 到目标文件的完整流水线。
可以把核心路径记成:
text
LLVM IR
-> SelectionDAG
-> 合法化后的 SelectionDAG
-> MachineInstr
-> 完成调度、寄存器分配、栈帧处理的 MachineInstr
-> MCInst
-> 汇编文本或目标文件如果你想实现一个后端,先不要被大量类名吓到。抓住这条主线,再逐个理解 TargetMachine、TargetLowering、SelectionDAGISel、MachineInstr、MCInst、TableGen 和 MC Layer,整个 LLVM 后端的轮廓就会清晰很多。
参考资料
- 视频:《LLVM后端流程与关键数据结构》:https://www.bilibili.com/video/BV1caFBeiESA/
- 本地 PPT:《LLVM - Another Toolchain Platform》
- LLVM 官方文档:Writing an LLVM Backend:https://llvm.org/docs/WritingAnLLVMBackend.html
- LLVM 官方文档:The LLVM Target-Independent Code Generator:https://llvm.org/docs/CodeGenerator.html
- LLVM 官方文档:TableGen Overview:https://llvm.org/docs/TableGen/
- LLVM 官方博客:Intro to the LLVM MC Project:https://blog.llvm.org/2010/04/intro-to-llvm-mc-project.html
- StormQ's Blog