****论文题目:****GCGNET: GRAPH-CONSISTENT GENERATIVE NETWORK FOR TIME SERIES FORECASTING WITH EXOGENOUS VARIABLES(具有外生变量的时间序列预测的图一致生成网络)
会议:ICLR2026
****摘要:****外生变量为预测未来的内生变量提供了有价值的补充信息。使用外生变量进行预测需要考虑过去对未来的依赖关系(即时间相关性)和外生变量对内生变量的影响(即渠道相关性)。当未来的外生变量可用时,这是至关重要的,因为它们可能直接影响未来的内生变量。对于外生变量的时间序列预测,已经提出了许多方法,重点是建立时间和通道相关性模型。然而,它们中的大多数使用两步策略,分别建模时间和通道相关性,这限制了它们捕获跨时间和通道联合相关性的能力。此外,在现实场景中,时间序列经常受到各种形式的噪声的影响,这强调了鲁棒性在这种相关性建模中的重要性。为了解决这些限制,我们提出了GCGNet,一种用于外生变量的时间序列预测的图一致生成网络。具体来说,GCGNet首先使用变分生成器生成粗预测。然后,图形结构对齐器通过评估生成的相关性和真实相关性之间的一致性来进一步指导它,其中相关性表示为图形,并且对噪声具有鲁棒的。最后,提出了一个图细化器来细化预测,以防止退化和提高准确性。在12个真实数据集上进行的广泛实验表明,GCGNet优于最先进的基线。
作者在https://github.com/decisionintelligence/GCGNet上提供代码和数据集。
GCGNet:用"图一致性生成网络"解决时间序列预测中的外生变量建模难题
一、背景:什么是"带外生变量的时间序列预测"?
在时间序列预测中,我们想预测的目标序列叫内生变量(Endogenous Variable) ,而那些对目标有影响、可以作为参考的辅助序列叫外生变量(Exogenous Variable)。
举一个最直观的例子:
我们想预测明天的电力需求 (内生变量)。
而气温 对电力需求有显著影响------天越热,空调用得越多,电力需求越高。
气温就是一个外生变量。
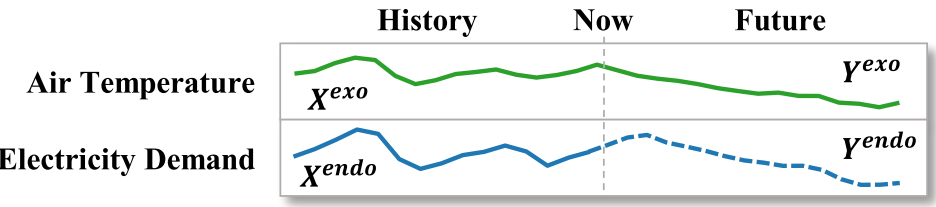
论文 Figure 1 ------ 展示历史/未来时间轴上电力需求与气温的关系示意图
更进一步,在很多实际场景中,未来的外生变量是可以提前获得的:
- 天气预报可以提供未来几天的温度预测
- 电力市场可以提供未来的负荷预测
- 风电场可以提供风速预测
这些"未来外生变量"非常宝贵,因为它们的时间跨度和预测目标完全对齐,理论上可以直接给预测提供信号。GCGNet 的核心任务,就是同时利用历史内生变量、历史外生变量和未来外生变量来进行更准确的预测。
二、现有方法的两个核心问题
问题一:两步建模策略导致信息干扰
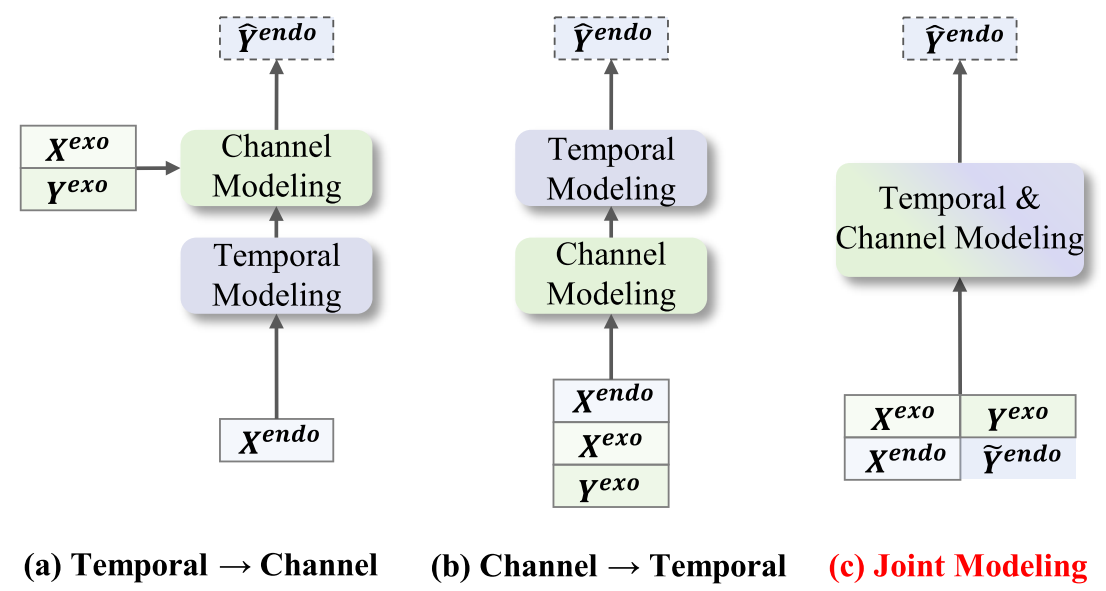
论文 Figure 2 ------ 展示三种建模策略 (a)(b)(c) 的对比示意图
现有的深度学习方法(如 TimeXer、TFT、CrossLinear 等)在处理外生变量时,几乎都采用两步分离策略:
- 策略 (a):先建模时间相关性,再建模通道相关性(如 TimeXer、ExoTST)
- 策略 (b):先建模通道相关性,再建模时间相关性(如 TFT、CrossLinear)
这两种方式的本质问题是:两步是分开的,互相干扰。第一步学到的信息可能被第二步覆盖或扭曲,导致两种相关性都没有被很好地捕捉到,最终预测效果受限。
从论文的可视化实验中可以看到(NP 数据集预测电价):
- CrossLinear 先做通道建模再做时间建模,结果"两头都没捕好",预测曲线严重偏离真实值
- 即使给 PatchTST 加上 MLP 融合模块来引入未来外生变量(两步策略),提升也非常有限------预测形状会"追随"未来外生变量(电网负荷)的形状,说明第二步的信息压制了第一步
问题二:噪声破坏相关性建模
现实数据中充满噪声:传感器故障、传输错误、人工记录失误......这些噪声会让观测数据不再准确反映真实的相关性。传统判别式模型直接从带噪声的观测中推断相关性,很容易过拟合噪声,学到的相关性不可靠。
三、GCGNet 的核心思路
GCGNet 的设计理念可以用一句话概括:
"先生成粗预测 → 用图结构对齐来约束生成 → 再用图卷积精化预测"
整个框架由三个模块组成,下面逐一介绍。
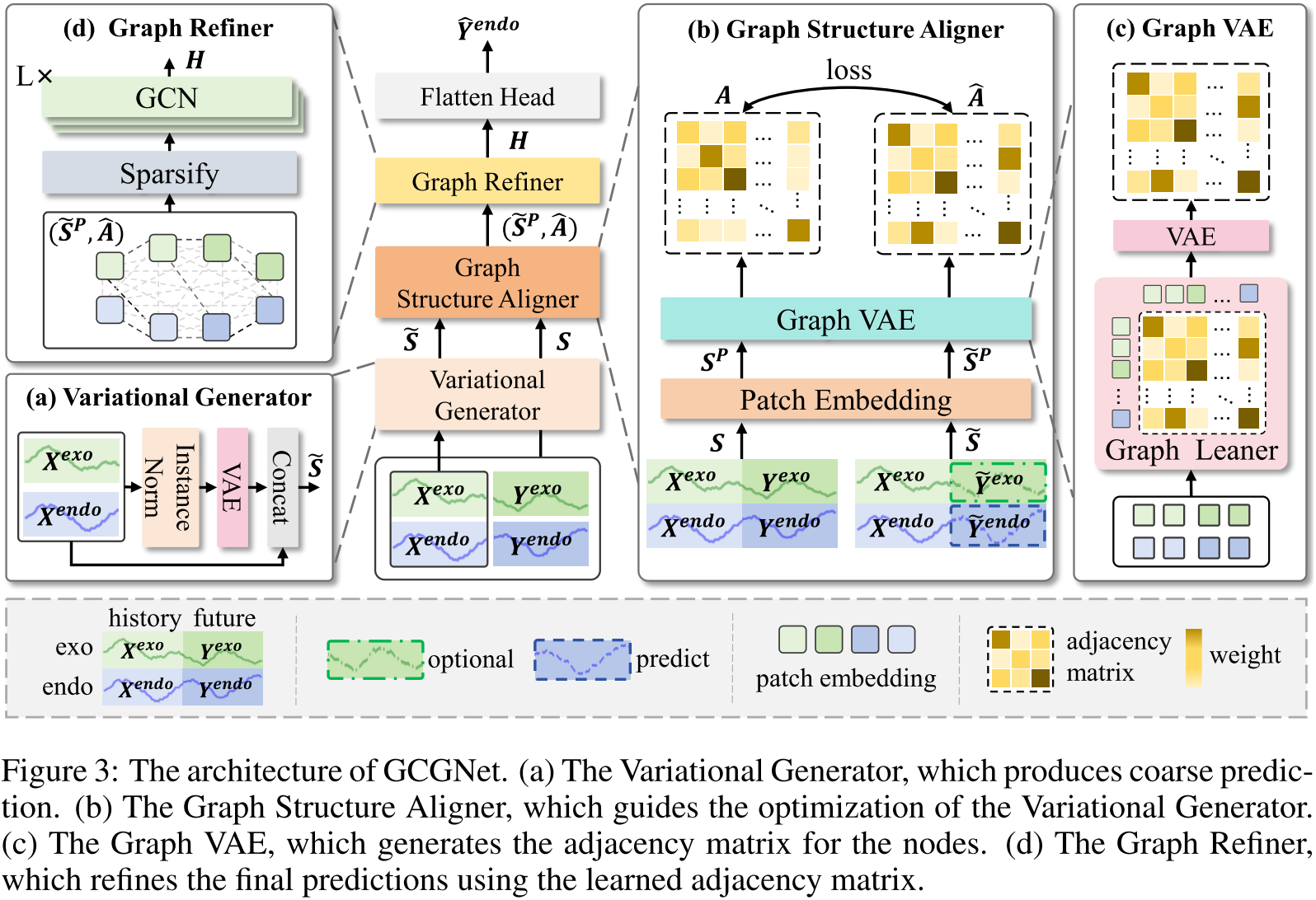
论文 Figure 3 ------ GCGNet 整体架构图(含四个子图 a/b/c/d)
四、模块详解
4.1 模块一:变分生成器(Variational Generator)
它做什么?
变分生成器的任务是产生一个粗略的预测,作为后续模块的起点。
具体步骤:
- 对输入数据做实例归一化(Instance Normalization),消除训练集和测试集分布差异
- 将历史内生变量
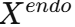 和历史外生变量
和历史外生变量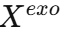 分别送入 VAE(变分自编码器) ,生成粗预测
分别送入 VAE(变分自编码器) ,生成粗预测 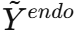 和
和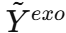
- 如果未来外生变量
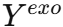 可用 ,就直接使用真实值;如果不可用 ,就用生成的
可用 ,就直接使用真实值;如果不可用 ,就用生成的 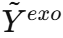 替代
替代 - 将所有序列拼接,构成完整的"生成全序列"
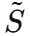
为什么用 VAE 而不用普通神经网络(MLP)?
VAE 是一种生成式模型,它学习数据背后的概率分布,而不是直接拟合输入-输出映射。这带来两个优势:
- 鲁棒性:对噪声不敏感,因为它关注的是潜在分布,而非逐点拟合
- 不确定性建模:VAE 的概率潜空间可以捕捉数据的多样性和不确定性
消融实验证实:将 VAE 换成 MLP 后,在 NP、DE、Energy、PJM 四个数据集上平均 MAE 从 0.360 上升到 0.386,性能明显下降。
4.2 模块二:图结构对齐器(Graph Structure Aligner)
这是 GCGNet 最核心的创新模块。
核心思想:用图来表示相关性,通过对齐图结构来约束生成器
传统方法直接对比预测值和真实值的逐点差异(MSE/MAE Loss)。GCGNet 不止于此------它还要求预测序列的"相关性结构"必须与真实序列的"相关性结构"保持一致。
什么是"相关性结构"?
论文将时间序列的相关性表示为一张图(Graph):
- 节点:时间序列被切成若干个 Patch(时间片段),每个 Patch 是一个节点
- 边:节点之间的边权重表示两个 Patch 之间的相关程度(无论是时间上的还是跨通道的)
这样,一张图就同时编码了时间相关性 (同一通道不同时间的 Patch 之间的关系)和通道相关性 (不同变量同一时间的 Patch 之间的关系)------实现了联合建模。
Graph VAE 的作用
直接计算出的原始邻接矩阵可能包含噪声,也难以捕捉高阶依赖。因此论文引入 Graph VAE 对原始邻接矩阵进行去噪和概率化处理:
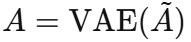
Graph VAE 输出的是鲁棒、平滑的邻接矩阵,对噪声不敏感。
对齐损失
- 从真实全序列 S 中提取图结构 A(真实相关性)
- 从生成全序列
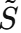 中提取图结构
中提取图结构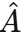 (生成相关性)
(生成相关性) - 最小化两者之间的 L1 距离:
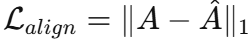
这个损失反向传播给变分生成器,迫使它生成的序列不仅在数值上接近真实值,而且在相关性结构上也与真实序列一致。
4.3 模块三:图精化器(Graph Refiner)
为什么需要图精化器?
图结构对齐器中,A 和 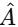 都由同一个 Graph VAE 生成。如果没有额外约束,Graph VAE 可能会退化(Degeneration) ------无论输入什么,都输出相同的矩阵。这样
都由同一个 Graph VAE 生成。如果没有额外约束,Graph VAE 可能会退化(Degeneration) ------无论输入什么,都输出相同的矩阵。这样 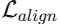 永远为 0,但模型什么也没学到。
永远为 0,但模型什么也没学到。
图精化器通过将 用于最终预测 来解决这个问题:如果 是无意义的,最终预测误差就会很大,迫使 Graph VAE 必须输出有意义的邻接矩阵。
图精化器的工作流程
- 输入:生成序列的 Patch 嵌入
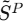 (作为图的节点特征)+ 邻接矩阵 (作为图的边)
(作为图的节点特征)+ 邻接矩阵 (作为图的边) - 稀疏化(Sparsify) :对每个节点只保留权重最大的 Top-K 条边,去掉不重要的连接,得到稀疏邻接矩阵
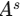
- 多层 GCN(图卷积网络):在稀疏图上做多层图卷积,让每个节点聚合邻居信息,实现跨时间步和跨通道的信息交流
- 线性输出头 :将精化后的节点特征展平,映射为最终预测
消融实验表明,去掉图精化器后,平均 MSE 从 0.323 飙升至 0.605,是所有消融项中损失最大的。
4.4 总体损失函数
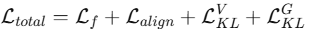
其中:
- Lf:预测损失(L1),监督图精化器的最终输出
- :图结构对齐损失,约束变分生成器
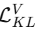 :变分生成器 VAE 的 KL 正则化
:变分生成器 VAE 的 KL 正则化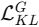 :Graph VAE 的 KL 正则化
:Graph VAE 的 KL 正则化
五、实验结果
5.1 数据集
论文在 12 个真实数据集上进行实验,涵盖多个领域:
| 领域 | 数据集 | 外生变量 | 内生变量 |
|---|---|---|---|
| 电力价格 | NP, PJM, BE, FR, DE | 电网负荷、风电预测等 | 电力价格 |
| 能源 | Energy | 风电、水电、太阳能等 | 火力发电 |
| 水文 | Colbun, Rapel | 降水、支流入流 | 水位 |
| 风电 | Sdwpfh1/2, Sdwpfm1/2 | ERA5 气象数据 | 有功功率 |
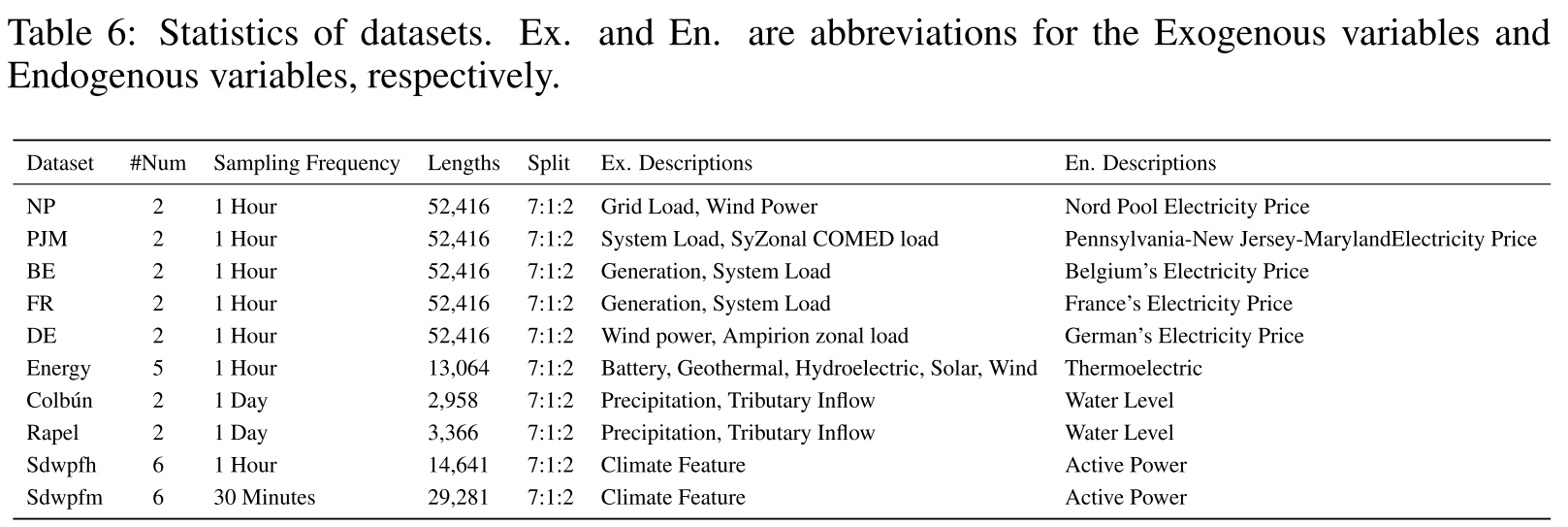
论文 Table 6 ------ 数据集统计信息表
5.2 主实验结果(有未来外生变量)
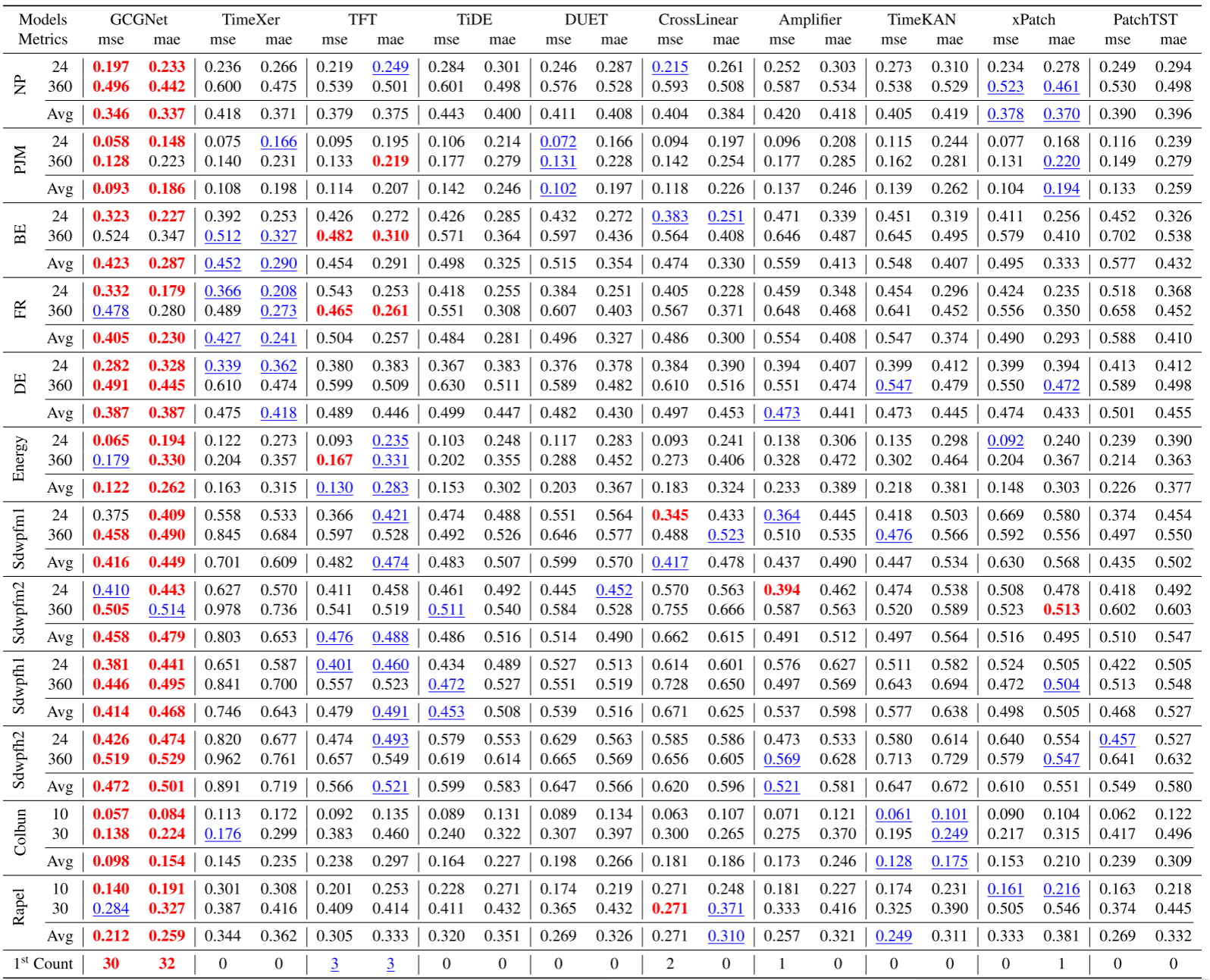
论文 Table 1 ------ 12 个数据集上的 MSE/MAE 对比主表
在有未来外生变量的设置下,GCGNet 与 10 个基线(包括 TimeXer、TFT、TiDE、DUET、CrossLinear、PatchTST 等)对比:
- MSE 第一名:30 次(共 24 个测试场景 × 2 指标 = 48 次机会中,MSE 占 24 次)
- MAE 第一名:32 次
具体来看,GCGNet 平均结果(Avg)在几乎所有数据集上都是最优:
- NP:MSE 0.346 vs. 次优 TimeXer 0.418(提升 17%)
- DE:MSE 0.387 vs. 次优 DUET 0.482(提升 20%)
- Energy:MSE 0.122 vs. 次优 TFT 0.130(提升 6%)
5.3 无未来外生变量设置
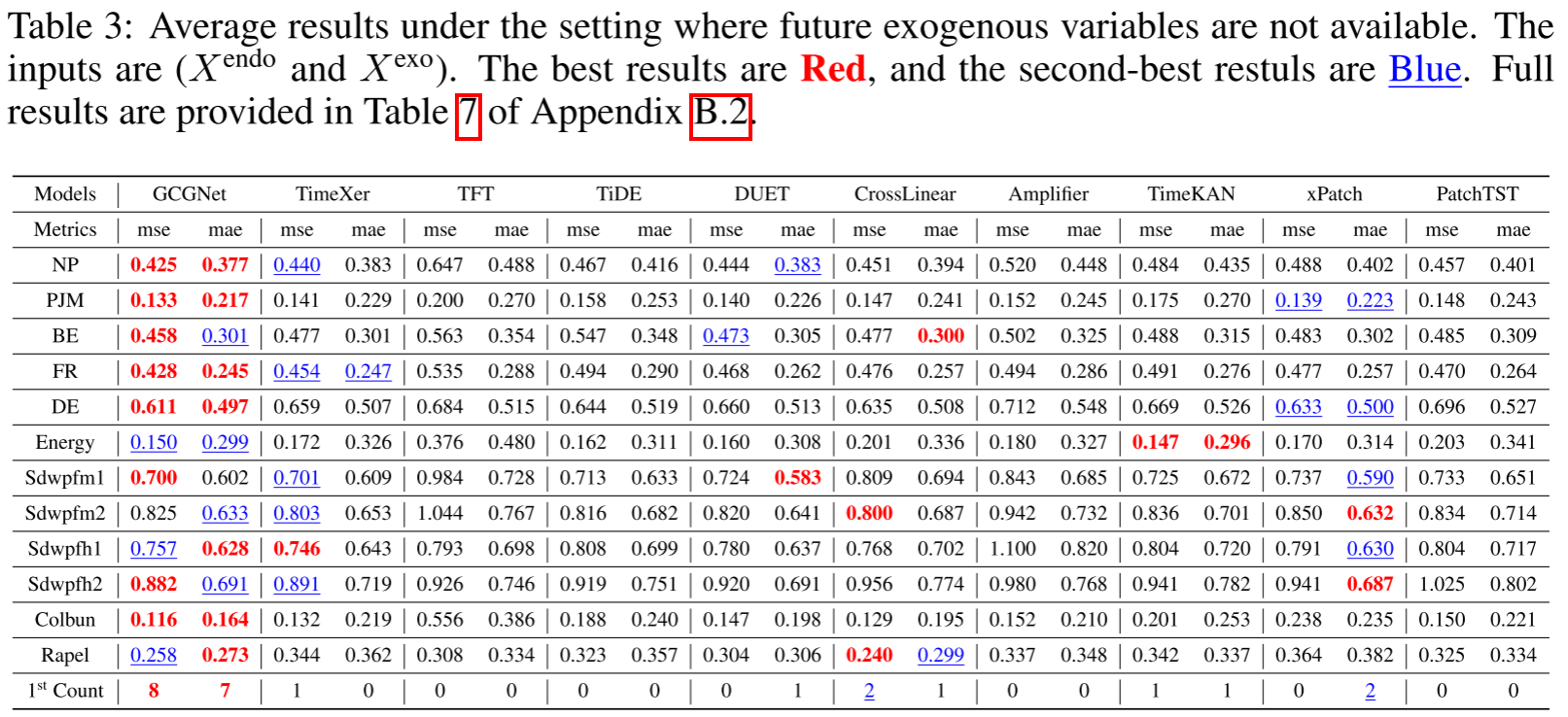
论文 Table 3 ------ 无未来外生变量的平均结果
当未来外生变量不可用时(GCGNet 自动用变分生成器生成替代),MSE 第一名 8 次,MAE 第一名 7 次,仍然领先所有基线。而 PatchTST 由于完全不能利用历史外生变量,表现最差。
5.4 缺失值鲁棒性实验
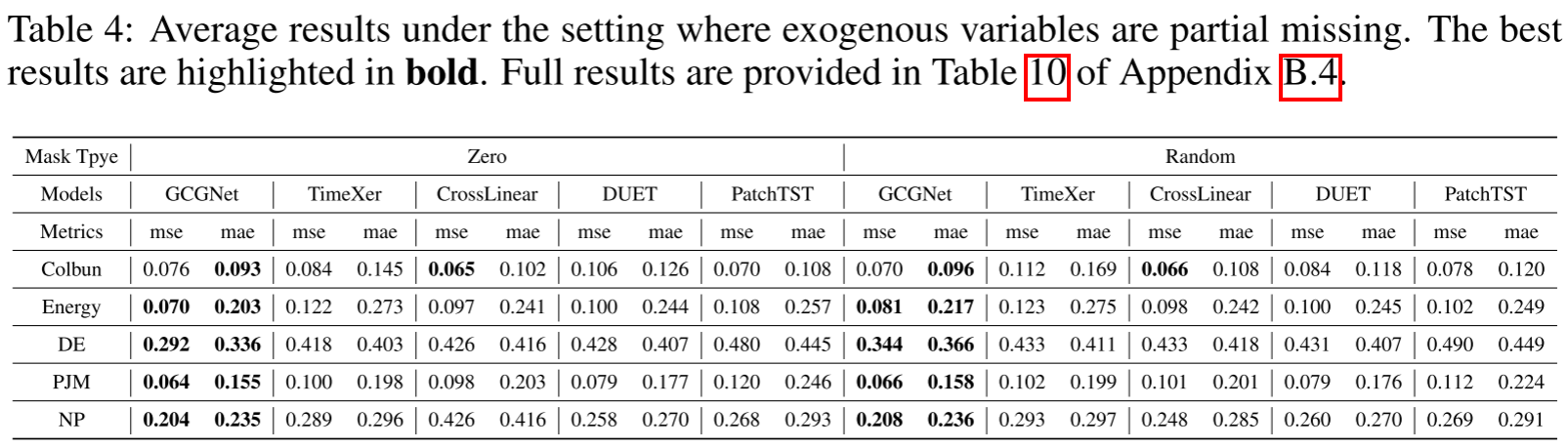
论文 Table 4 ------ 部分外生变量缺失的平均结果
通过将 10%、30%、50% 的外生变量替换为 0 或随机噪声来模拟缺失,GCGNet 在所有场景下均保持最佳性能,证明了生成网络设计的鲁棒性。
5.5 消融实验
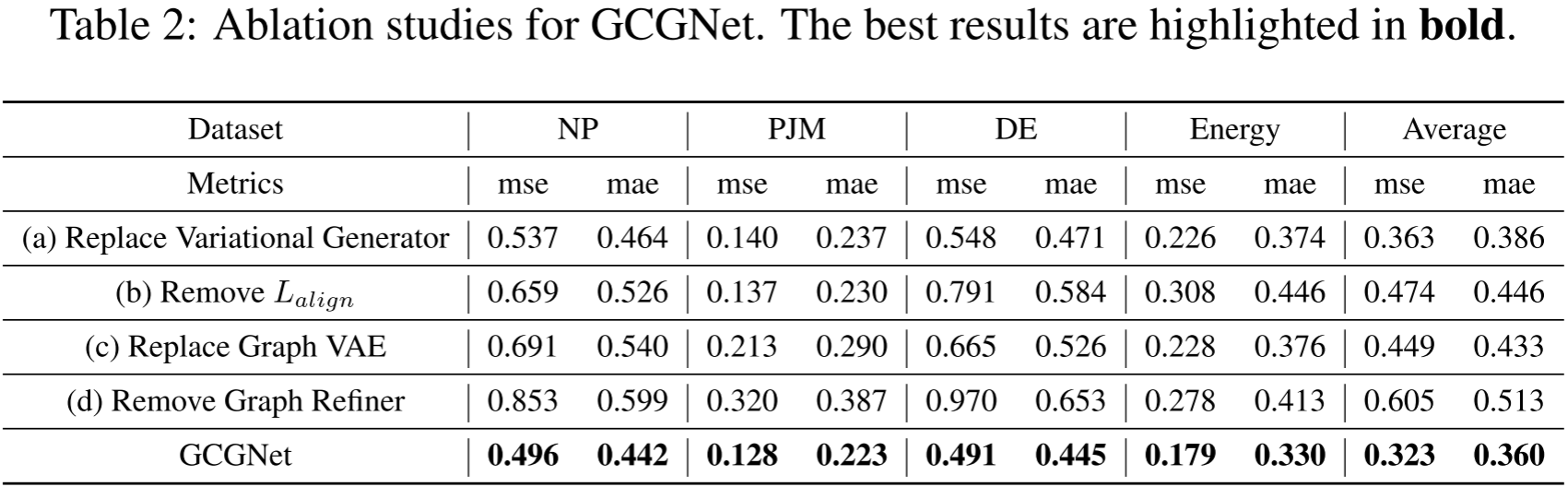
论文 Table 2 ------ 消融实验结果
5.6 预测可视化
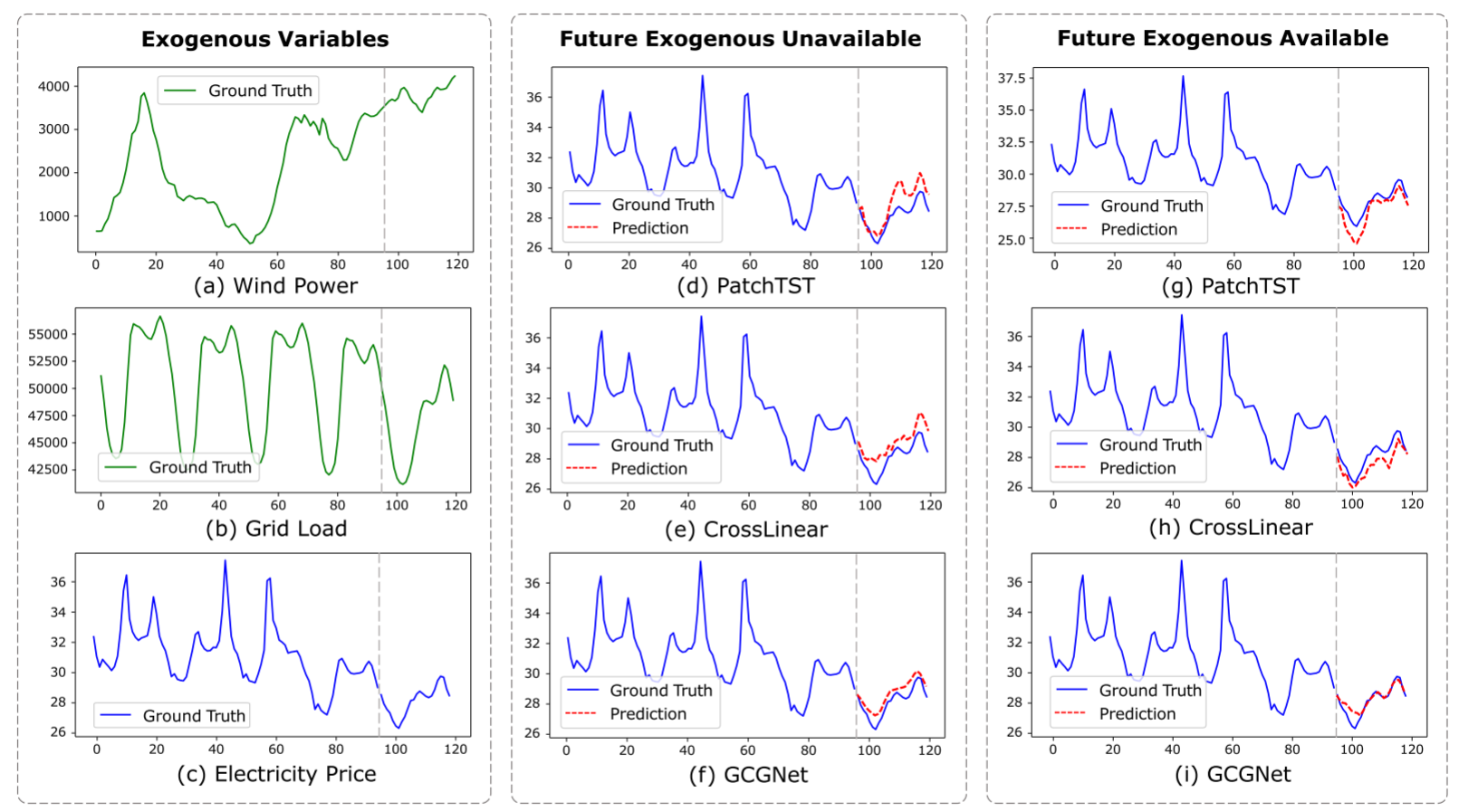
在 NP 数据集(预测电价)的可视化中:
- PatchTST(无外生变量):主要复制历史模式,无法响应外生变量变化
- CrossLinear(两步策略):两步相互干扰,预测曲线偏离真实
- GCGNet(无未来外生):预测与真实值高度吻合
- GCGNet(有未来外生):进一步提升,最接近真实曲线
六、参数敏感性分析
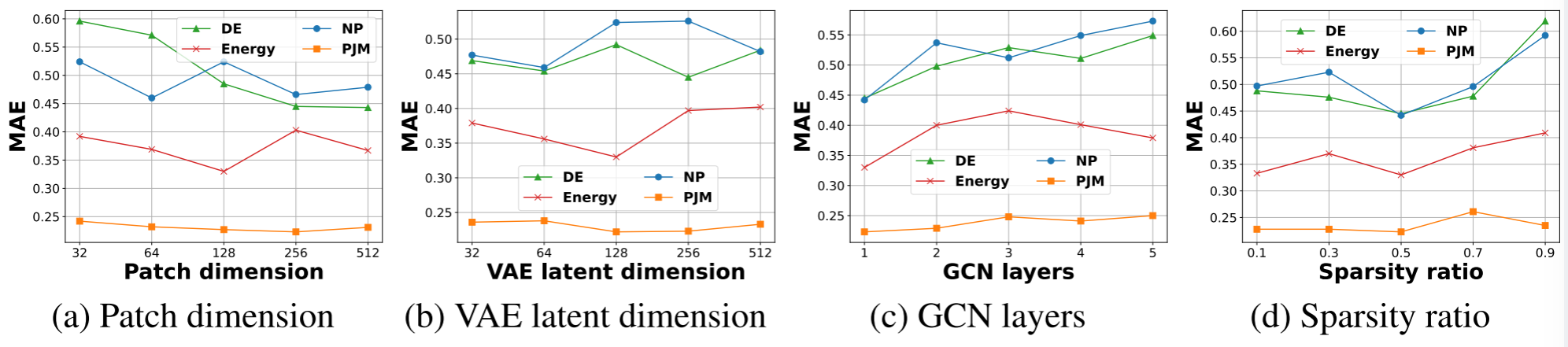
论文 Figure 6 ------ 超参数敏感性分析(四个子图)
论文还对主要超参数进行了敏感性分析(预测长度 360),得出几条实用结论:
- Patch 维度 / VAE 潜空间维度:64~256 之间最优;太大会引入冗余,增加过拟合风险
- GCN 层数:1~2 层最优;更深的网络会出现过平滑问题
- 稀疏化比例:50% 最优;这一比例在"去除噪声连接"和"保留关键连接"之间取得了最佳平衡
七、🌟 小白也能懂的直觉解释
到这里,如果你还对 GCGNet 的方法感到迷惑,让我用一个更生动的比喻来解释整个流程。
类比:给学生批改作文
想象有一位作文老师(GCGNet),想判断一篇学生作文(预测序列)的好坏。
传统方法(两步策略)就像两个老师先后批:
- 语文老师先批了语法(时间相关性)
- 数学老师再批了逻辑(通道相关性)
- 但数学老师的批注可能和语文老师矛盾,结果两个维度都没批好
GCGNet 的方法分三步走:
第一步:先打草稿(变分生成器)
学生(VAE)先写一篇草稿作文(粗预测)。
草稿不需要完美,但要抓住大致方向。VAE 的特别之处在于它不是"死记硬背",而是真正理解了"写好作文的套路"(学习概率分布),所以即使原材料(输入数据)有点脏(噪声),它写出来的草稿也不会太离谱。
如果参考资料(未来外生变量)现成可查,就直接用真实资料;如果没有,学生自己推测一份替代资料。
第二步:对比"文章结构"(图结构对齐器)
这是最关键的一步。
老师(图结构对齐器)不看具体词句,而是分析文章结构:哪些段落之间有呼应?哪些论点之间有逻辑关系?
具体做法:
- 把草稿切成若干"段落"(Patch)
- 画出段落之间的关系网(Graph):哪两段关系紧密,哪两段关系松散
- 同样,对标准答案(真实序列)也画一张关系网
- 要求两张关系网要尽量相似
这就相当于说:你的作文结构必须和优秀范文的结构一致------不只是字面相似,更要"形神兼备"。
Graph VAE 的作用是:先把关系网里的噪声(比如因为某次停电导致的异常关联)过滤掉,得到更可靠的关系网。
第三步:精修定稿(图精化器)
老师拿着这张"关系网"(邻接矩阵),对草稿进行精修:
- 稀疏化:只关注最重要的段落关联(Top-K),忽略无关紧要的
- 图卷积:让每个段落参考相关段落的内容来修改自己(信息在图上传播)
- 最终输出一篇精修好的预测
防退化:如果老师的关系网是乱写的(Graph VAE 退化),精修出来的作文就会很差,预测误差就会很大------这个大误差反过来惩罚老师,迫使老师认真画关系网。这就是图精化器防止退化的机制。
更具体的数字例子
以 NP 数据集(预测电价,外生变量为风电和电网负荷)为例:
假设我们用过去 168 小时(7天)的数据,预测未来 24 小时的电价:
-
变分生成器接收过去7天的电价、风电、电网负荷,生成一个粗略的未来24小时电价曲线(可能误差较大,但大方向对)
-
图结构对齐器把整个时间窗口(过去7天+预测未来24天)切成若干 Patch,比如每8小时一个 Patch,共24个节点。然后:
- 从真实数据中学到:深夜Patch和早高峰Patch之间的电价关联很强(因为电网负荷的周期性)
- 检查生成序列有没有同样的规律
- 如果没有,对齐损失就会惩罚生成器
-
图精化器把这种"深夜↔早高峰强相关"的结构用于最终精修:早高峰的预测可以参考深夜的负荷和价格信息来修正,最终得到更准确的结果
在这个数据集上,GCGNet 的平均 MSE 为 0.346 ,而最强的基线 TimeXer 的平均 MSE 为 0.418 ,提升了约 17%。
八、总结与展望
核心贡献回顾
| 设计 | 解决的问题 | 效果 |
|---|---|---|
| 变分生成器(VAE) | 噪声鲁棒性 + 未来外生变量缺失降级 | 替换为MLP后MAE上涨7% |
| 图结构对齐器 | 时间/通道相关性联合建模 | 去掉后MSE上涨47% |
| Graph VAE | 相关性表示的去噪和鲁棒性 | 替换为确定性图学习器后MSE上涨39% |
| 图精化器 | 精化预测 + 防止 Graph VAE 退化 | 去掉后MSE上涨87%,损失最大 |
GCGNet 的适用场景
GCGNet 特别适合以下场景:
- 有可靠的未来外生变量预报(如气象预报、负荷预测)
- 数据中存在明显噪声(传感器失效、传输错误)
- 需要同时建模跨时间和跨变量的复杂相关性
局限性与未来方向
论文本身没有明确讨论局限性,但从方法设计来看:
- Graph VAE 和 GCN 引入了额外的计算成本,在超大规模数据集上的效率值得进一步研究
- 当前的图构建基于 Patch 级别的相关性,更细粒度的图构建方式可能带来进一步提升