流媒体场景下的网络优化
前言
在前三篇文章中,我们从 Socket 编程出发,历经 I/O 多路复用和 Reactor 模式,构建了一套高性能网络编程的基础框架。但对于流媒体服务来说,"能跑起来"和"跑得好"之间还有很大的距离------一个未经调优的流媒体服务器,在用户看来可能就是卡顿、延迟、花屏甚至连接失败。
网络性能直接决定了流媒体的用户体验。一帧视频从采集到渲染,经过编码、封装、传输、解封装、解码、渲染的完整链路,其中网络传输环节的耗时和稳定性往往是体验的瓶颈。本篇聚焦实战层面的网络调优技巧,涵盖 Socket 选项配置、零拷贝技术、带宽估计、抓包分析以及系统级性能调优,为后续进入流媒体协议的学习打下坚实基础。
1. Socket 选项调优
Socket 选项是网络调优最直接的手段。对于流媒体场景,有几个选项几乎是必须调整的。
TCP_NODELAY
TCP 默认启用 Nagle 算法:当发送的数据包较小时,协议栈会等待更多数据凑够一个较大的包再发送,以此减少网络中的小包数量。这个策略对文件传输很友好,但对流媒体却是灾难性的------一帧视频的 NALU 可能就几十字节,Nagle 算法会给它额外增加几十毫秒的延迟。
在所有流媒体场景的 TCP 连接上,务必禁用 Nagle 算法。
SO_SNDBUF / SO_RCVBUF
内核为每个 Socket 维护独立的发送和接收缓冲区。默认大小通常是几十到几百 KB,对于高码率视频流(如 4K 视频可达 20~50 Mbps)往往不够用。缓冲区过小会导致内核频繁丢弃数据或阻塞写入;过大则浪费内存,并且在高延迟链路上可能引入额外的缓冲延迟。
经验值:对于高码率场景(10 Mbps 以上),发送缓冲区建议设到 512 KB ~ 2 MB;接收缓冲区根据实际带宽-延迟积(BDP)估算。
SO_REUSEADDR / SO_REUSEPORT
SO_REUSEADDR 允许在 TIME_WAIT 状态的端口上立即绑定新的 Socket,这对流媒体服务器的快速重启至关重要------生产环境中,RTSP/RTMP 服务停机重启后如果不能立即绑定端口,会导致服务不可用。
SO_REUSEPORT(Linux 3.9+)允许多个 Socket 绑定同一端口,内核会在它们之间做负载均衡。这对多进程架构的流媒体服务器(如 Nginx-RTMP)非常有用,可以避免惊群问题。
TCP_KEEPALIVE
流媒体连接往往是长连接,客户端可能因为网络切换、应用切到后台等原因静默断开。TCP 保活机制可以检测这些"死连接"并及时回收资源。
内核默认的保活间隔是 2 小时,这对流媒体来说太长了。建议缩短到几十秒级别:空闲 30 秒后开始探测,每 10 秒探测一次,3 次无响应则断开。
综合配置代码
下面是一个实用的 Socket 选项配置工具函数:
cpp
#include <sys/socket.h>
#include <netinet/tcp.h>
#include <netinet/in.h>
#include <cstring>
#include <stdexcept>
struct SocketOptions {
bool tcp_nodelay = true;
int sndbuf_size = 512 * 1024;
int rcvbuf_size = 512 * 1024;
bool reuse_addr = true;
bool reuse_port = false;
int keepalive_idle = 30;
int keepalive_interval = 10;
int keepalive_count = 3;
};
void set_socket_option(int fd, int level, int optname,
int value, const char* name) {
if (setsockopt(fd, level, optname, &value, sizeof(value)) < 0) {
throw std::runtime_error(
std::string("setsockopt ") + name + " failed: " + strerror(errno));
}
}
void configure_streaming_socket(int sockfd, const SocketOptions& opts) {
if (opts.reuse_addr) {
set_socket_option(sockfd, SOL_SOCKET, SO_REUSEADDR, 1, "SO_REUSEADDR");
}
if (opts.reuse_port) {
set_socket_option(sockfd, SOL_SOCKET, SO_REUSEPORT, 1, "SO_REUSEPORT");
}
set_socket_option(sockfd, SOL_SOCKET, SO_SNDBUF,
opts.sndbuf_size, "SO_SNDBUF");
set_socket_option(sockfd, SOL_SOCKET, SO_RCVBUF,
opts.rcvbuf_size, "SO_RCVBUF");
if (opts.tcp_nodelay) {
set_socket_option(sockfd, IPPROTO_TCP, TCP_NODELAY, 1, "TCP_NODELAY");
}
set_socket_option(sockfd, SOL_SOCKET, SO_KEEPALIVE, 1, "SO_KEEPALIVE");
set_socket_option(sockfd, IPPROTO_TCP, TCP_KEEPIDLE,
opts.keepalive_idle, "TCP_KEEPIDLE");
set_socket_option(sockfd, IPPROTO_TCP, TCP_KEEPINTVL,
opts.keepalive_interval, "TCP_KEEPINTVL");
set_socket_option(sockfd, IPPROTO_TCP, TCP_KEEPCNT,
opts.keepalive_count, "TCP_KEEPCNT");
}在建立连接后立即调用即可:
cpp
SocketOptions opts;
opts.sndbuf_size = 1024 * 1024; // 高码率场景用 1MB
opts.reuse_port = true; // 多进程架构
configure_streaming_socket(sockfd, opts);2. 零拷贝技术
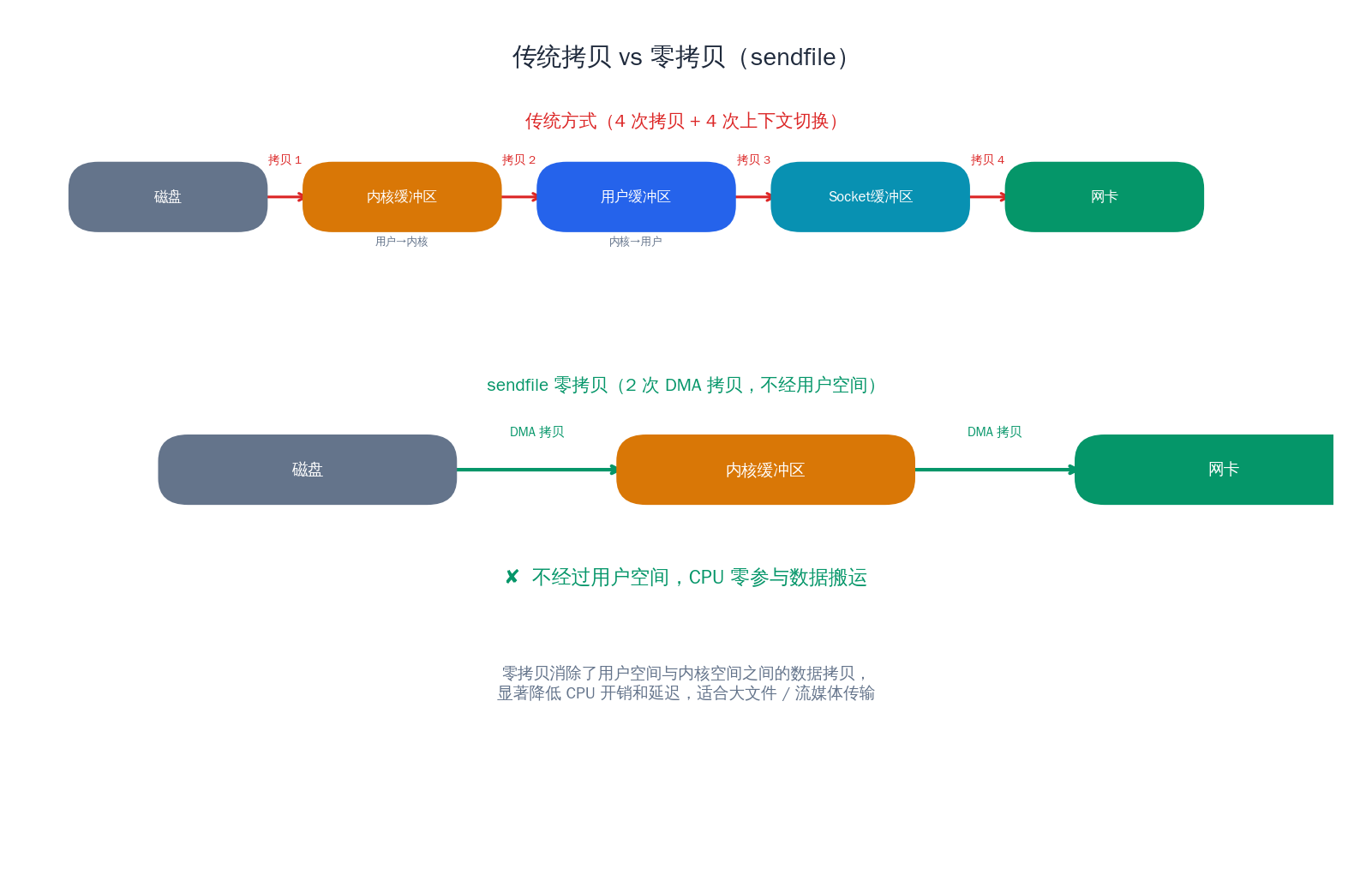
传统数据发送的问题
当一个流媒体服务器需要将磁盘上的 TS 切片发送给客户端时,传统的 read() + write() 方式会经历四次数据拷贝和多次上下文切换:
- 磁盘 → 内核页缓存(DMA 拷贝)
- 内核页缓存 → 用户空间缓冲区(CPU 拷贝)
- 用户空间缓冲区 → 内核 Socket 发送缓冲区(CPU 拷贝)
- Socket 发送缓冲区 → 网卡(DMA 拷贝)
其中第 2、3 步是完全多余的------数据在用户空间走了一个来回,只是为了从一个内核缓冲区搬到另一个。对于高并发的 HLS 分发服务器,这种开销会显著消耗 CPU 和内存带宽。
sendfile:最简单的零拷贝
sendfile() 让内核直接将文件内容从页缓存拷贝到 Socket 缓冲区,绕过用户空间。如果网卡支持 scatter-gather DMA,甚至可以进一步省掉内核内部的那次 CPU 拷贝,只传递文件描述符和偏移信息。
cpp
#include <sys/sendfile.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <cerrno>
ssize_t send_file_zero_copy(int sockfd, const char* filepath) {
int filefd = open(filepath, O_RDONLY);
if (filefd < 0) return -1;
struct stat st;
if (fstat(filefd, &st) < 0) {
close(filefd);
return -1;
}
off_t offset = 0;
ssize_t total_sent = 0;
size_t remaining = st.st_size;
while (remaining > 0) {
ssize_t sent = sendfile(sockfd, filefd, &offset, remaining);
if (sent < 0) {
if (errno == EAGAIN || errno == EINTR) continue;
break;
}
total_sent += sent;
remaining -= sent;
}
close(filefd);
return total_sent;
}这个函数可以直接用于 HLS 切片分发------当客户端请求一个 .ts 文件时,不需要把文件内容读入用户态缓冲区,直接 sendfile 即可。
splice:管道拼接
splice() 更加灵活,它可以在两个文件描述符之间移动数据,而不需要数据经过用户空间。典型用法是用一个管道(pipe)作为中介,在任意两个 fd 之间实现零拷贝转发:
cpp
#include <fcntl.h>
#include <unistd.h>
ssize_t splice_forward(int fd_in, int fd_out, size_t len) {
int pipefd[2];
if (pipe(pipefd) < 0) return -1;
ssize_t total = 0;
size_t remaining = len;
while (remaining > 0) {
ssize_t n = splice(fd_in, nullptr, pipefd[1], nullptr,
remaining, SPLICE_F_MOVE | SPLICE_F_MORE);
if (n <= 0) break;
ssize_t m = splice(pipefd[0], nullptr, fd_out, nullptr,
n, SPLICE_F_MOVE | SPLICE_F_MORE);
if (m <= 0) break;
total += m;
remaining -= m;
}
close(pipefd[0]);
close(pipefd[1]);
return total;
}splice 的一大优势是可以用于 Socket 到 Socket 的转发场景,比如流媒体代理服务器将上游数据直接转发到下游客户端,不需要在用户空间中转。
mmap + write
mmap 将文件映射到用户空间的虚拟地址,避免了 read() 的一次拷贝。配合 write() 发送时,数据从内核页缓存直接进入 Socket 缓冲区。这种方式的好处是应用层可以方便地访问文件内容(比如需要解析 TS 头部做时间戳修改),同时仍然减少了一次拷贝。
如何选择
| 场景 | 推荐方案 |
|---|---|
| 文件点播(HLS/DASH 切片分发) | sendfile |
| 代理转发(Socket → Socket) | splice |
| 需要读取并修改内容再发送 | mmap + write |
| 实时流(内存中的编码数据) | 不适用零拷贝,直接 writev 聚集写入 |
3. 带宽估计与拥塞感知基础
为什么流媒体需要感知网络状况
流媒体和普通文件下载的本质区别在于:文件下载只关心总传输时间,而流媒体关心的是持续稳定的传输速率。网络带宽波动时,流媒体应用需要及时调整策略:
- 带宽充足时,可以提升视频码率改善画质
- 带宽不足时,必须降低码率或切换低分辨率流,避免卡顿
- 检测到丢包加重时,可以启用 FEC 冗余或降低发送速率
这就是自适应码率(ABR)技术的核心------实时感知网络状况,动态调整发送策略。
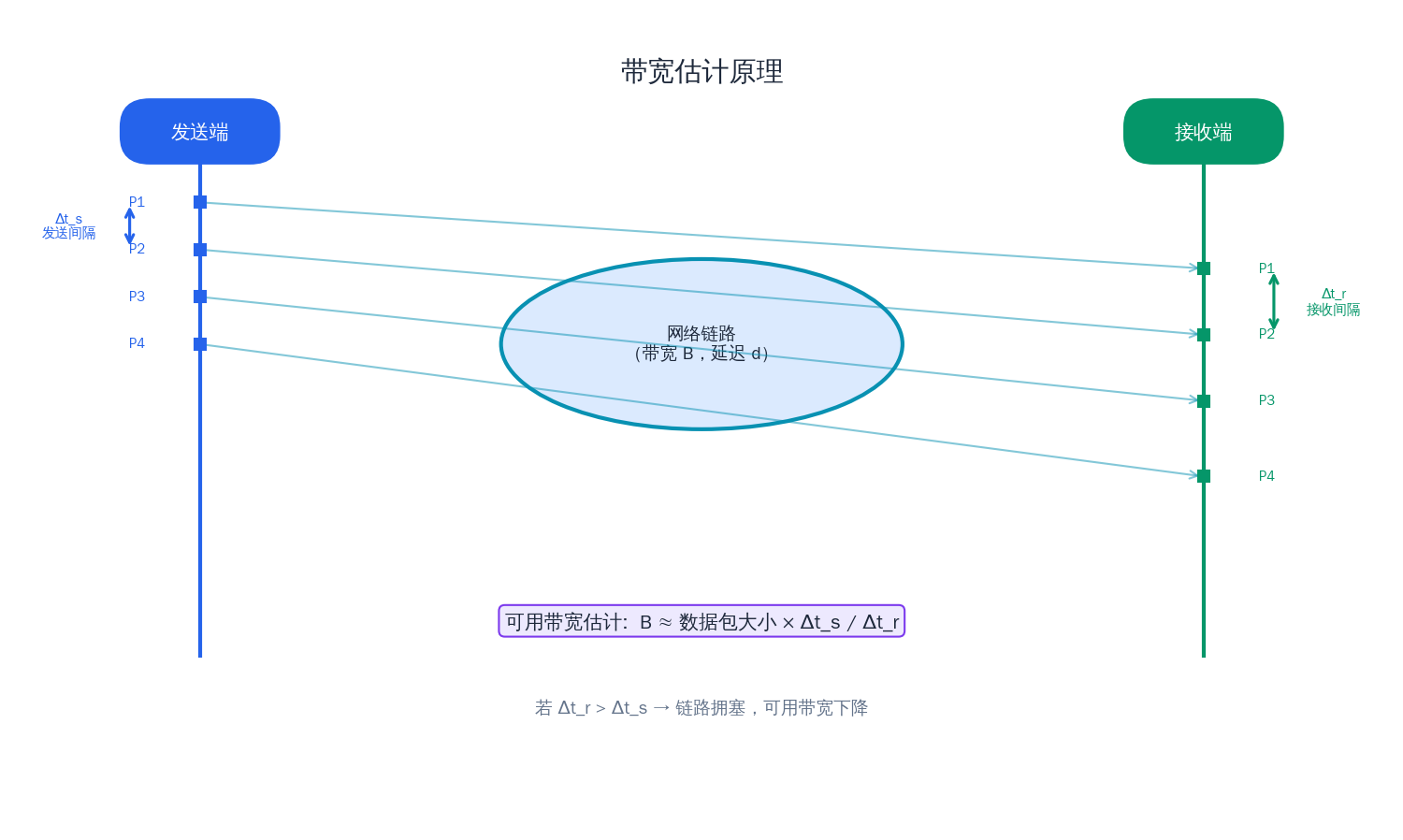
简单的带宽估计方法
最直觉的带宽估计是:在一段时间窗口内,统计成功发送或接收的数据量,除以时间即可得到吞吐量。下面是一个带滑动窗口的带宽估计器:
cpp
#include <chrono>
#include <deque>
#include <cstdint>
class BandwidthEstimator {
public:
explicit BandwidthEstimator(int window_ms = 1000)
: window_ms_(window_ms) {}
void on_packet_sent(size_t bytes) {
auto now = std::chrono::steady_clock::now();
samples_.push_back({now, bytes});
purge_old(now);
}
double estimate_bps() const {
if (samples_.size() < 2) return 0.0;
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(
samples_.back().time - samples_.front().time);
if (duration.count() == 0) return 0.0;
size_t total_bytes = 0;
for (const auto& s : samples_) {
total_bytes += s.bytes;
}
return static_cast<double>(total_bytes) * 8.0 * 1000.0
/ duration.count();
}
private:
struct Sample {
std::chrono::steady_clock::time_point time;
size_t bytes;
};
void purge_old(std::chrono::steady_clock::time_point now) {
auto cutoff = now - std::chrono::milliseconds(window_ms_);
while (!samples_.empty() && samples_.front().time < cutoff) {
samples_.pop_front();
}
}
int window_ms_;
std::deque<Sample> samples_;
};每次发送数据包后调用 on_packet_sent(),任意时刻调用 estimate_bps() 获取当前估计带宽(单位 bps)。窗口大小的选择是一个权衡:窗口太小估计值会剧烈波动,窗口太大则对带宽变化反应迟钝。1~2 秒是一个常见的选择。
TCP 拥塞控制简述
TCP 协议栈内置了拥塞控制算法,流媒体应用通常运行在 TCP 之上(RTMP、HLS、DASH),因此理解底层的拥塞控制行为很有必要。
Cubic(Linux 默认)是基于丢包的拥塞控制算法。它在检测到丢包前持续增大拥塞窗口,丢包后快速回退。问题在于,它必须"撞墙"(引发丢包)才能知道带宽上限,这在高带宽高延迟链路上表现不佳。
BBR(Bottleneck Bandwidth and RTT)是 Google 提出的基于模型的拥塞控制算法。它通过主动探测来估计瓶颈带宽和最小 RTT,而不依赖丢包信号。在流媒体场景中,BBR 通常能提供更高的吞吐量和更低的延迟,特别是在有一定丢包率的网络上。
在流媒体服务器上启用 BBR:
bash
sysctl -w net.core.default_qdisc=fq
sysctl -w net.ipv4.tcp_congestion_control=bbr应用层配合
即使底层 TCP 有拥塞控制,应用层仍然需要做自己的速率控制。比如一个 RTMP 推流客户端,编码器输出 5 Mbps 的码流,但网络只能承载 3 Mbps,此时 TCP 的发送缓冲区会持续积压。应用层应该监控发送缓冲区的使用情况(通过 ioctl(SIOCOUTQ) 或 getsockopt(TCP_INFO)),当积压超过阈值时,通知编码器降低码率或丢弃非关键帧。
cpp
#include <sys/ioctl.h>
#include <linux/sockios.h>
size_t get_send_buffer_pending(int sockfd) {
int pending = 0;
ioctl(sockfd, SIOCOUTQ, &pending);
return static_cast<size_t>(pending);
}
bool should_reduce_bitrate(int sockfd, size_t threshold = 1024 * 1024) {
return get_send_buffer_pending(sockfd) > threshold;
}4. 抓包分析实战
网络调优离不开抓包分析。当用户报告卡顿或花屏时,主观感受往往无法定位问题,抓包数据才是客观证据。
tcpdump 常用命令
bash
# 抓取指定端口的 RTMP 流量并保存
tcpdump -i eth0 port 1935 -w rtmp_capture.pcap
# 抓取指定 IP 的 RTP 流量(UDP,常见端口范围)
tcpdump -i eth0 host 192.168.1.100 and udp portrange 10000-60000 -w rtp.pcap
# 抓取 RTSP 信令(TCP 554 端口)
tcpdump -i eth0 port 554 -A -s 0
# 限制抓包大小,只抓前 200 字节的包头
tcpdump -i eth0 port 1935 -s 200 -w header_only.pcap
# 实时查看 RTP 包的摘要信息
tcpdump -i eth0 udp port 5004 -n -q几条实用原则:
- 生产环境抓包务必加
-w保存为文件,事后用 Wireshark 分析 - 用
-s 0抓完整包,用-s 200只抓包头(降低 I/O 压力) - 加
-c 10000限制抓包数量,避免磁盘被撑满
Wireshark 分析技巧
Wireshark 对流媒体协议有很好的支持。几个实用的分析方法:
RTMP 分析 :Wireshark 能自动解析 RTMP chunk,通过 rtmpt 过滤器可以看到每个 RTMP 消息的类型、时间戳和大小。关注点是 chunk 的时间戳是否连续递增------如果出现跳变,说明发送端可能有编码延迟或缓冲积压。
RTP 分析 :使用 Telephony → RTP → RTP Streams 可以查看 RTP 流的统计信息,包括丢包率、抖动、序列号不连续等。还可以通过 rtp.seq 过滤器检查序列号连续性。
RTSP 分析 :RTSP 基于文本协议,可以用 rtsp 过滤器查看完整的请求/响应对话。重点检查 DESCRIBE 返回的 SDP、SETUP 中的传输参数、以及 PLAY 后 RTP 是否正常到达。
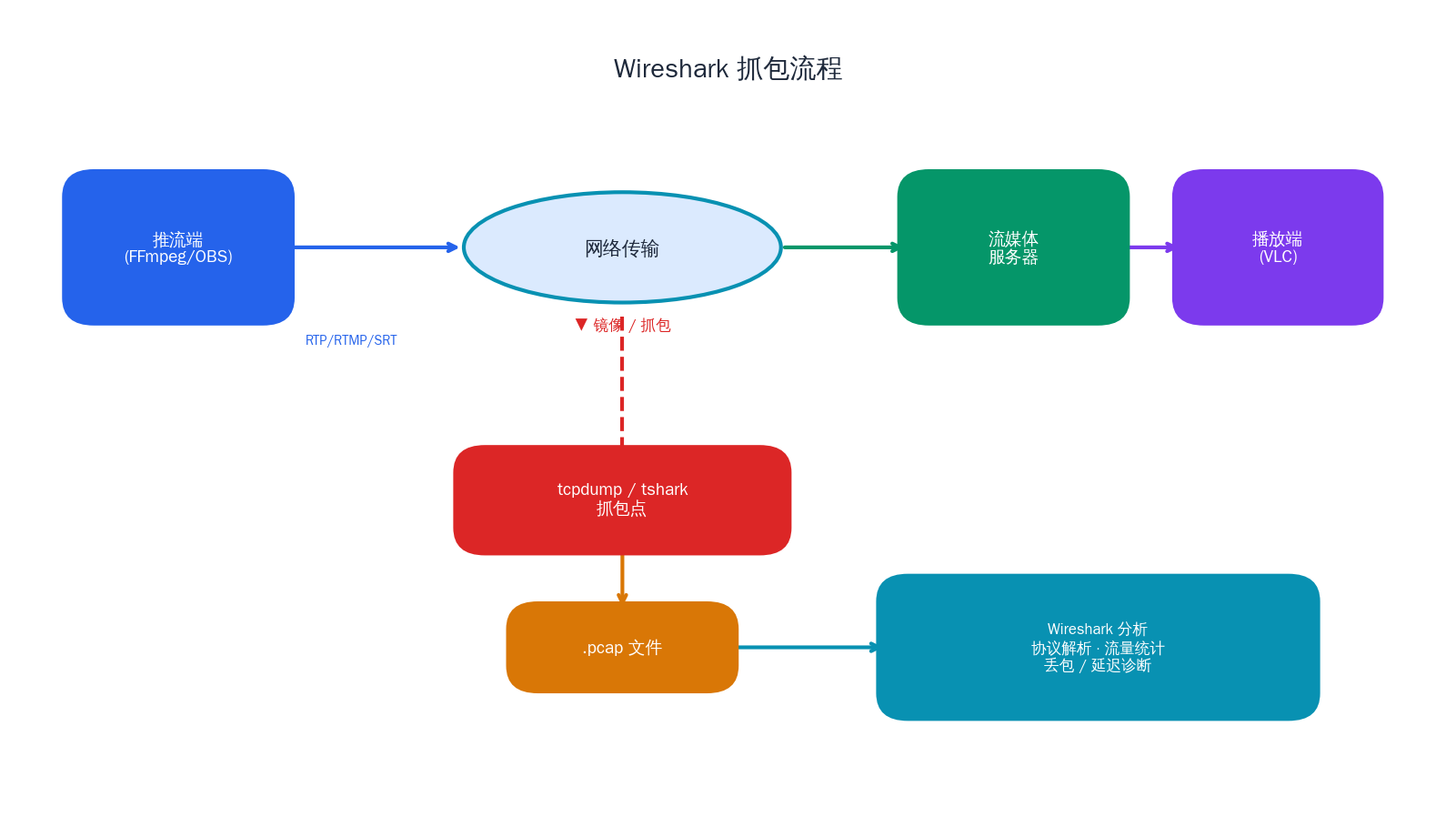
常见问题诊断
丢包 :在 Wireshark 中查看 RTP 流的 Lost 列,或者通过序列号间隙判断。如果是零星丢包(< 1%),通常是正常的网络波动;如果是持续高丢包,需要检查链路质量或是否存在带宽瓶颈。同时可以通过 RTCP RR(Receiver Report)中的丢包率字段来确认。
乱序 :TCP 层乱序不影响应用层(协议栈会重组),但 UDP/RTP 的乱序需要应用层处理。在 Wireshark 中查看 rtp.seq 是否非单调递增。乱序通常是中间设备做了负载均衡或路径抖动。
延迟抖动:Wireshark 的 RTP 分析可以直接给出 jitter 统计。抖动过大会导致播放端的 Jitter Buffer 频繁调整,影响播放流畅度。关注抖动的均值和 P95------均值可能正常,但偶尔的抖动尖峰就足以导致一次卡顿。
连接超时 :过滤 TCP 握手(tcp.flags.syn == 1),检查 SYN 是否有重传。如果看到多次 SYN 重传,说明服务端不可达或端口未监听。如果握手成功但数据传输中出现超时,检查是否有 TCP Zero Window(接收端缓冲区满)或 TCP Retransmission。
5. 流媒体服务器性能调优清单
性能调优是一个系统工程,需要从操作系统内核、网络栈到应用层逐层优化。
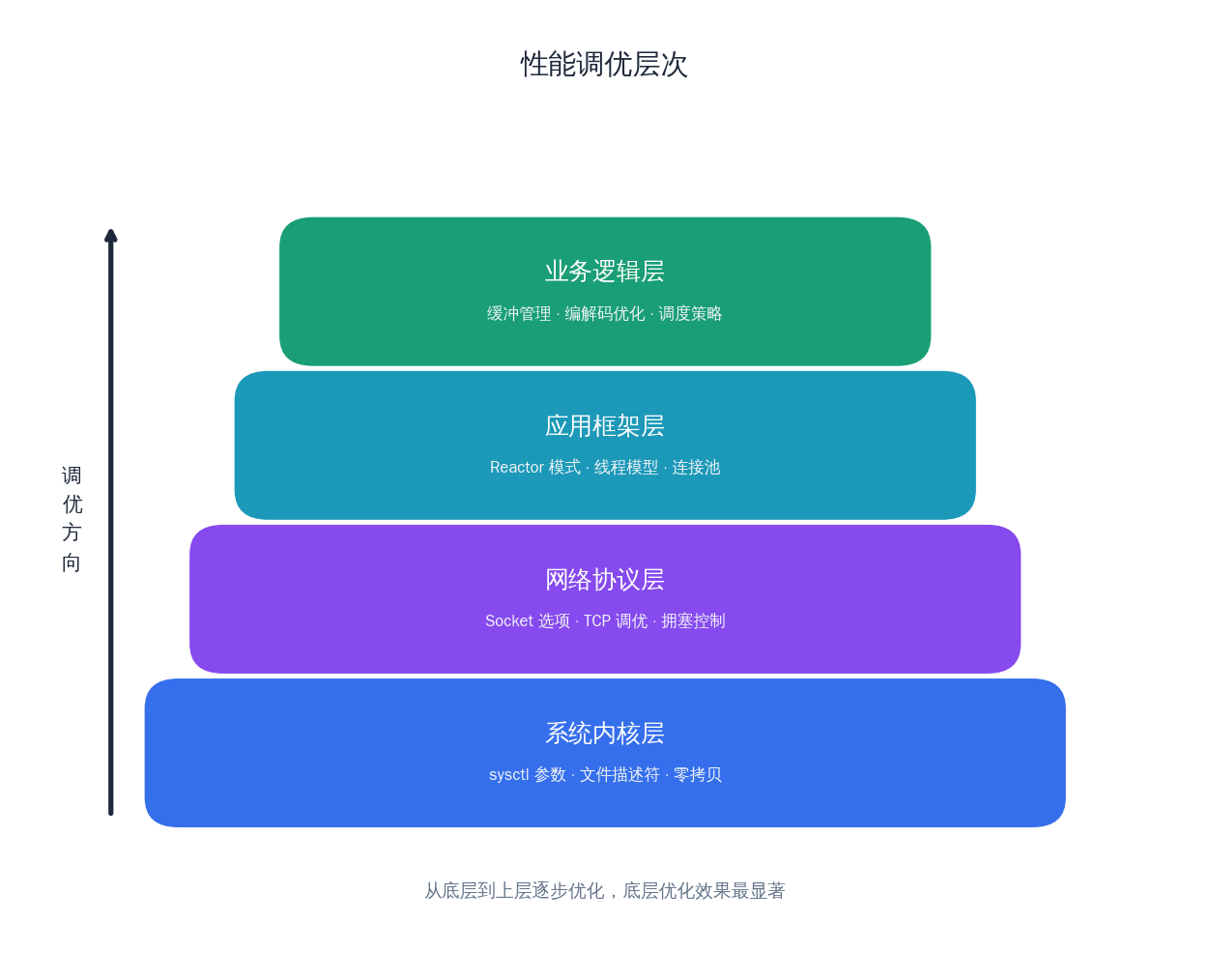
系统层面
文件描述符限制:每个 TCP 连接、每个打开的文件都消耗一个文件描述符。默认的 1024 对流媒体服务器远远不够。
bash
# 查看当前限制
ulimit -n
# 临时设置(当前 Shell 会话)
ulimit -n 1000000
# 永久设置:编辑 /etc/security/limits.conf
# * soft nofile 1000000
# * hard nofile 1000000TCP 内核参数优化:以下是一份针对流媒体服务器的 sysctl 配置清单:
bash
# === 连接管理 ===
# 半连接队列大小,防止 SYN Flood
net.ipv4.tcp_max_syn_backlog = 65535
# 全连接队列大小
net.core.somaxconn = 65535
# TIME_WAIT 状态的最大数量
net.ipv4.tcp_max_tw_buckets = 200000
# 允许 TIME_WAIT 状态的 socket 被快速回收
net.ipv4.tcp_tw_reuse = 1
# === 缓冲区 ===
# TCP 自动调优的内存范围:最小值 默认值 最大值(字节)
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 65536 16777216
# 全局 Socket 缓冲区上限
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.rmem_default = 262144
net.core.wmem_default = 262144
# === 拥塞控制 ===
net.core.default_qdisc = fq
net.ipv4.tcp_congestion_control = bbr
# === 性能 ===
# 启用 TCP Fast Open(减少握手延迟)
net.ipv4.tcp_fastopen = 3
# 网络设备队列长度
net.core.netdev_max_backlog = 65535
# 端口范围(用于主动连接)
net.ipv4.ip_local_port_range = 1024 65535将以上内容保存为 /etc/sysctl.d/99-streaming.conf,然后执行 sysctl -p /etc/sysctl.d/99-streaming.conf 使其生效。
应用层面
缓冲区管理 :流媒体数据具有明显的特征------大量大小相近的数据块(视频帧、音频帧、TS 切片)。使用内存池来管理这些缓冲区,避免频繁的 malloc/free 带来的碎片和系统调用开销。
cpp
#include <vector>
#include <mutex>
#include <memory>
#include <cstdint>
#include <cstdlib>
class BufferPool {
public:
BufferPool(size_t block_size, size_t initial_count)
: block_size_(block_size) {
for (size_t i = 0; i < initial_count; ++i) {
pool_.push_back(static_cast<uint8_t*>(std::malloc(block_size)));
}
}
~BufferPool() {
for (auto* p : pool_) std::free(p);
}
uint8_t* acquire() {
std::lock_guard<std::mutex> lock(mutex_);
if (pool_.empty()) {
return static_cast<uint8_t*>(std::malloc(block_size_));
}
auto* buf = pool_.back();
pool_.pop_back();
return buf;
}
void release(uint8_t* buf) {
std::lock_guard<std::mutex> lock(mutex_);
pool_.push_back(buf);
}
size_t available() const {
std::lock_guard<std::mutex> lock(mutex_);
return pool_.size();
}
private:
size_t block_size_;
std::vector<uint8_t*> pool_;
mutable std::mutex mutex_;
};典型的使用方式是为不同大小的数据块创建不同的池:
cpp
BufferPool video_pool(256 * 1024, 100); // 256KB × 100,用于视频帧
BufferPool audio_pool(4 * 1024, 200); // 4KB × 200,用于音频帧
BufferPool ts_pool(188 * 7, 500); // TS 包(7个一组)× 500连接池:当流媒体服务器需要作为客户端向上游拉流时(比如 CDN 边缘节点回源),维护一个连接池可以避免频繁建立和销毁 TCP 连接的开销。连接池需要处理空闲连接的超时回收和健康检查。
聚集写入(writev) :实时流场景中,一帧数据可能由多个不连续的内存块组成(RTP 头 + 扩展头 + 载荷)。使用 writev() 一次系统调用发送多个内存块,避免多次 write() 或先拷贝到连续缓冲区:
cpp
#include <sys/uio.h>
ssize_t send_rtp_packet(int sockfd,
const uint8_t* rtp_header, size_t header_len,
const uint8_t* payload, size_t payload_len) {
struct iovec iov[2];
iov[0].iov_base = const_cast<uint8_t*>(rtp_header);
iov[0].iov_len = header_len;
iov[1].iov_base = const_cast<uint8_t*>(payload);
iov[1].iov_len = payload_len;
return writev(sockfd, iov, 2);
}调优闭环
性能调优不是一次性的工作。建议建立以下监控体系:
- 实时指标采集:连接数、吞吐量、帧率、缓冲区使用率
- 关键指标告警:丢包率 > 1%、延迟 > 200ms、缓冲区使用率 > 80%
- 周期性抓包:每天在低峰期自动抓取 5 分钟的流量样本,用于基线比较
- 压测验证 :每次调优后用压测工具(如
wrk、iperf3、自定义的流媒体压测客户端)验证效果
总结
本篇从五个维度梳理了流媒体场景下的网络优化技术:
- Socket 选项调优 是最直接的手段,
TCP_NODELAY、缓冲区大小、保活参数是流媒体服务的基本配置 - 零拷贝技术 (
sendfile、splice、mmap)在文件点播和代理转发场景中能显著降低 CPU 开销 - 带宽估计与拥塞感知是自适应码率的基础,应用层需要主动监控网络状态并配合编码器调整策略
- 抓包分析 是定位网络问题的终极武器,
tcpdump+ Wireshark 的组合应该成为每个流媒体开发者的必备技能 - 系统级调优需要从文件描述符、TCP 内核参数到应用层缓冲区管理全面考虑
至此,第一篇「网络编程基础」的四篇文章就全部完成了。我们从最基础的 Socket 编程出发,经过 I/O 多路复用、Reactor 模式,最终到达本篇的网络优化,建立了一套完整的高性能网络编程知识体系。
下一篇,我们将正式进入流媒体传输的核心领域------RTP/RTCP 协议深度解析,了解音视频数据是如何封装成 RTP 包在网络上传输的,以及 RTCP 如何提供传输质量反馈。