怎么用大模型生成推荐的训练数据?Data Augmentation怎么做?
🚀 本文收录于Github:AI-From-Zero 项目 ------ 一个从零开始系统学习 AI 的知识库。如果觉得有帮助,欢迎 ⭐ Star 支持!
by @Laizhuocheng
一、简介
想象你开了一家新餐厅,开业第一天几乎没有顾客评价。这时候你该怎么办?是等着慢慢积累口碑,还是想个办法先让菜单看起来更诱人?
推荐系统也面临同样的困境。一个推荐模型要训练得好,需要海量的用户行为数据------谁点了什么、看了什么、买了什么。但现实中,冷启动问题无处不在:新用户没有历史记录,新商品没有交互数据,小众品类样本稀疏。没有足够的数据,模型就像没有食材的厨师,再厉害的算法也做不出好菜。
大语言模型(LLM)的出现,给这个问题提供了一个全新的解法。它不仅能"理解"数据,还能"创造"数据。这篇文章就来聊聊,怎么用大模型来生成和增强推荐系统的训练数据。
二、什么是大模型数据生成与增强
简单来说,就是让大模型扮演一个"虚拟用户生成器"和"数据魔术师"的角色。
数据生成是从零开始创造新的训练样本。比如告诉大模型"这是一个喜欢科技产品的25岁男性用户",让它模拟出这个人可能浏览、点击、购买的一系列商品。就像写小说时塑造人物一样,大模型根据人设生成合理的行为故事。
数据增强是在已有数据基础上做改进,让稀疏的数据变得更丰富。比如把"手机壳"这个简单的商品标题,扩展成"适用于iPhone的透明防摔保护壳",增加语义信息。或者把用户行为序列中的某个商品替换成语义相近但不完全相同的商品,创造出新的训练样本。
两者的核心区别:
- 数据生成 = 从0到1,解决"没有数据"的问题
- 数据增强 = 从1到10,解决"数据不够丰富"的问题
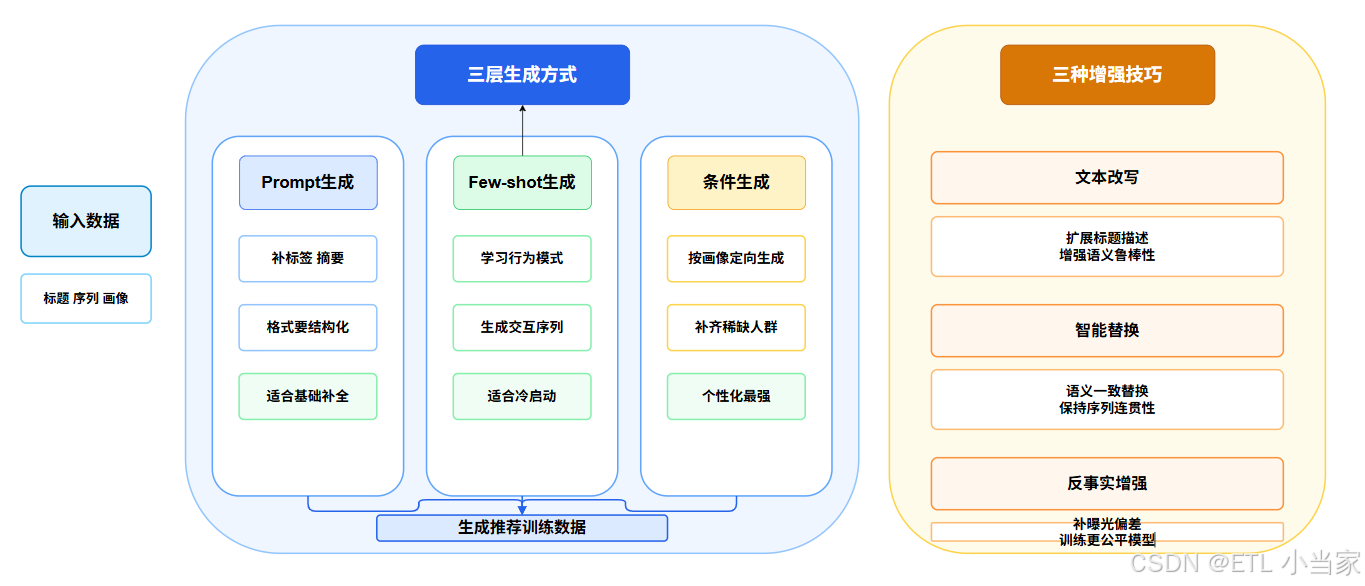
三、大模型如何生成和增强推荐数据
3.1 基于Prompt的特征生成(基础层)
这是最直接的用法。假设你有一批文章标题,但缺少分类标签和摘要,可以设计结构化提示词让大模型补全:
任务:根据标题生成三个主题标签和一句话摘要
标题:《AI在医疗领域的应用前景》
输出格式(JSON):
{
"tags": ["人工智能", "医疗科技", "行业趋势"],
"summary": "探讨AI技术如何改变医疗诊断和治疗方式"
}关键点:
- 明确输出格式(JSON方便后续处理)
- 批量处理提高效率
- 生成后要做去重和规范化
3.2 基于Few-shot的交互序列生成(进阶层)
推荐系统的核心数据是用户行为序列。要为新品类生成冷启动数据,可以让大模型学习真实序列的模式:
示例:
真实用户行为序列示例:
- 用户A:浏览跑鞋 → 点击运动T恤 → 加入购物车 → 购买瑜伽垫
- 用户B:搜索健身器材 → 浏览蛋白粉 → 点击运动手环 → 购买
任务:为新品类"户外露营装备"生成5条类似的虚拟用户行为序列
约束条件:
1. 序列长度在5-10之间
2. 必须包含至少一次购买行为
3. 行为要有逻辑连贯性Few-shot的作用不是简单复制模板,而是让模型理解行为的连贯性和合理性。
3.3 基于条件生成的个性化数据(高阶层)
这是最能体现推荐系统个性化本质的方法。把用户画像作为条件输入,生成符合特定人群特征的行为序列:
用户画像:25-30岁女性,关注美妆护肤,消费能力中等
生成行为序列:
1. 浏览平价护肤品专区
2. 点击美妆教程视频
3. 查看口红试色对比
4. 将面膜加入购物车
5. 购买润唇膏这种方法的价值在于可以针对性地补充稀缺人群的数据。当你发现某个细分人群的样本太少导致推荐效果不好时,就可以定向生成数据来平衡。
3.4 数据增强的三大技巧
(1)文本改写增强
把简短的商品标题扩展成丰富的描述:
- 原标题:"无线蓝牙耳机"
- 改写后:"真无线蓝牙耳机"、"TWS蓝牙耳机"、"无线入耳式耳机"
这些改写后的文本可以作为正样本,帮助embedding模型学到更鲁棒的语义表示。
(2)智能序列替换
不是随机替换商品,而是用大模型做语义层面的替换:
- 原序列:跑步鞋 → 运动T恤 → 购买瑜伽垫
- 增强后:运动鞋 → 健身背心 → 购买泡沫轴
大模型理解上下文,会把"跑步鞋"换成"运动袜"或"健身手环",保持序列的连贯性,而不是随机换成"高跟鞋"这种语义不合理的商品。
(3)反事实数据增强
解决推荐系统的曝光偏差问题------用户只能点击系统推荐给他的物品,那些没推荐的物品可能不是不喜欢,而是根本没机会看到。
反事实增强构造"如果当时推荐了其他物品会怎样"的场景:
用户点击了商品A,基于用户历史行为,
生成:"如果推荐商品B,用户会有60%概率点击"这些反事实样本可以用来训练更公平的推荐模型,减少马太效应。
四、大模型数据生成 vs 传统方法的对比
| 维度 | 传统方法 | 大模型方法 |
|---|---|---|
| 速度成本 | 快,几乎零成本 | 慢,API调用有费用 |
| 语义理解 | 无,纯规则驱动 | 强,理解上下文和语义关系 |
| 生成质量 | 可能产生不合理组合(如跑步鞋→高跟鞋) | 保持逻辑连贯性 |
| 适用场景 | 简单的数据扩充 | 需要语义理解的复杂任务 |
| 可解释性 | 高,规则明确 | 中,依赖模型内部知识 |
| 冷启动能力 | 弱,需要已有数据 | 强,可以从零生成 |
选择建议:
- 如果只是简单的数据扩充,传统方法(随机裁剪、掩码)就够了
- 如果需要语义理解、跨模态特征生成、反事实推理,大模型更适合
五、工程实践的关键细节
5.1 冷启动场景落地三步走
第一步:设计Prompt模板
python
prompt_template = """
你是一个用户行为分析专家。根据以下视频信息,生成5个可能对这个视频感兴趣的用户画像,
以及每个用户可能的后续观看序列(3-5个视频标题)。
视频标题:{video_title}
视频标签:{video_tags}
时长:{duration}
输出格式(JSON):
{{
"user_profiles": [
{{
"age_range": "25-30",
"interests": ["科技", "数码"],
"next_videos": ["标题1", "标题2", "标题3"]
}}
]
}}
"""关键设计点:明确输出格式、指定生成数量、避免输出发散。
第二步:批量生成和质量过滤
两层过滤机制:
- 格式校验:JSON是否合法、必填字段是否齐全
- 业务规则校验 :
- 序列长度是否合理(3-10)
- 行为时间是否递增
- 是否存在不合理的连续购买(不超过2次)
第三步:混合训练策略
生成数据不能直接全量替换真实数据:
- 初始:10%生成数据 + 90%真实数据
- 评估指标下降不超过1% → 提升到20%
- 逐步找到最优比例(通常在30%-40%)
5.2 质量控制的三个层次
生成阶段:在Prompt中加入硬约束
- "生成的商品ID必须在现有商品库中"
- "用户行为时间必须递增"
- "生成的序列必须覆盖至少两个非热门品类"
统计验证:对比生成数据和真实数据的分布
- 检查序列平均长度、点击转化率、品类分布
- 计算KL散度或JS散度量化差异
- 设定阈值作为质量门槛
在线验证:小流量A/B测试
- 5%用户看到新模型的推荐结果
- 关注CTR、CVR、停留时长
- 确保实验跑够一周再下结论
5.3 成本优化策略
大模型调用是最大瓶颈,优化方向:
批处理和缓存:
- 相同类型的生成任务聚合成批次
- 通用改写结果做缓存(如常见商品标题扩展)
小模型替代:
- 用大模型生成1万条种子数据
- 用这些数据fine-tune一个小BERT模型
- 推理成本降低到原来的十分之一
分阶段使用:
- 冷启动阶段用大模型
- 稳定后用小模型做增强
- 整体成本约为纯大模型方案的五分之一
六、总结与思考
大模型在推荐系统数据生成中的价值,不只是"造数据"这么简单。它真正的意义在于让模型理解推荐场景的语义关系,然后按照这种关系来创造新样本。
从基于Prompt的特征生成,到Few-shot交互序列学习,再到条件化的个性化数据生成,这是一个从简单到复杂、从通用到精准的演进过程。而数据增强则是让已有数据发挥更大价值,通过文本改写、智能替换、反事实构造等手段,让稀疏的数据变得丰富。
更深层的思考 :生成数据的价值不只是补充数量,更重要的是它能暴露模型的盲点。当你发现模型对某个品类的推荐效果一直不好,用大模型生成这个品类的行为序列后,可能会发现是特征工程阶段缺少了关键属性。这个发现反过来会帮助优化整个数据处理流程。
技术不是机械应用,而是要从实践中总结规律、反哺系统设计。大模型数据生成也是如此------它既是解决当下问题的工具,也是发现系统改进方向的探针。