大语言模型的认知边界:从法律困境到线性空间的深层隐喻
一、引言:智识边疆上的迷途者
人工智能的浪潮以前所未有的速度席卷了人类社会的各个角落。大语言模型(Large Language Model,LLM)被寄予厚望,从医疗诊断到法律咨询,从科学研究到艺术创作,人们期待这些庞然大物能够成为人类智识活动的全能助手。然而,当我们真正将这些工具推向认知前沿------那些人类自身尚未厘清的模糊地带、充满争议的理论边界、以及需要真正创新性思维的探索性领域------大语言模型便开始暴露出一种深层的、结构性的困境:它们不是在探索未知,而是在用一种极为自信的语气,沿着一个可能完全错误的方向,坚定不移地走向混乱。
这种现象并非偶发性的技术故障,而是根植于当前大语言模型底层架构与训练范式中的系统性局限。理解这种局限,不仅有助于我们更理性地使用这些工具,更能帮助我们深刻认识人类认知与机器"推理"之间的本质差异。
二、法律灰色地带:一个具体而深刻的案例
2.1 当AI遭遇立法缺陷
以劳动法领域为例,具体来看当前大语言模型在面对真实法律复杂性时的表现。
中国《劳动合同法》第85条规定了用人单位在特定违法情形下应当加付赔偿金的制度安排。这一规定在立法层面存在若干值得深究的内在张力:其一,该条文的启动条件与认定标准在不同地区的司法实践中存在显著分歧;其二,劳动行政部门与司法机关在执法层面的权限划分并不清晰;其三,最高人民法院通过司法解释,认识到《劳动合同法》本身的立法局限,并作出了延伸性、开放性的解释,为司法实践留下了探索空间;其四,正是由于这种立法层面的不确定性,全国各地法院就同类案件作出了截然不同的生效裁判。
这是一个典型的"法律灰色地带"------不是因为法律人的水平不足,而是因为立法本身在特定问题上尚未形成成熟共识,司法实践正处于动态演化之中。
2.2 大模型的典型失态
当我们将这样一个问题抛给某大语言模型的法律顾问智能体时,会发生什么?
首先,模型会表现出一种表面上的"权威感"------援引相关法条、列举司法解释、提供看似严谨的分析框架。但随着问题的深入,特别是当我们追问"不同法院的判决为何相互矛盾""某一具体情形究竟应当如何认定"时,模型开始出现一种微妙的自我矛盾:前文的论断与后文的推理产生冲突,模型无法在自身的逻辑框架内保持一致性。
更值得关注的是,模型并不会坦诚地说"这个问题目前在司法实践中存在争议,我无法给出确定性结论"------这本来是最诚实、也最负责任的回答。相反,模型往往会选择一个方向,然后以一种不容置疑的口吻坚持下去,即便这个方向在法律逻辑上存在明显漏洞,即便它与其他生效判例相矛盾。
这种"坚定地走在错误方向上"的表现,恰恰揭示了大语言模型在面对真实认知边界时的核心困境。
2.3 深层原因:训练数据的内在张力
为什么会出现这种情况?
当训练数据中同时包含了大量相互矛盾的法律文本------支持甲方的判决书、支持乙方的判决书、偏向从严解释的学术论文、偏向从宽解释的实务分析------模型面临的实际上是一个在其训练数据所构成的"向量空间"中无法被稳定"线性表出"的问题。模型所能做的,是在这些相互冲突的信息之间寻找一个概率意义上的"加权平均",然后将其以一种确定性的语言呈现出来。
但法律推理的本质并不是寻找概率意义上的"平均答案",而是在承认不确定性的前提下,根据具体情境作出有论据支撑的判断,并且能够诚实地说明判断的边界与局限。这恰恰是当前大语言模型所不擅长的。
三、从个案到普遍:认知前沿的系统性失灵
3.1 什么是"认知前沿问题"
并非所有复杂问题都是"认知前沿问题"。有些问题表面上复杂,但实际上有确定性的答案,只是答案需要较长的推理链来抵达------这类问题大语言模型处理得相当不错。
真正的"认知前沿问题"具有以下特征:
第一,范式性不确定:问题所在的领域正处于知识范式的更迭过程中,新的正确观点正在对传统观点形成挑战或颠覆,但这种颠覆尚未完成,共识尚未形成。
第二,结构性矛盾:问题内部存在逻辑上的真实张力------不是因为有人推理错误,而是因为现实本身在该问题上呈现出无法被单一逻辑框架完美覆盖的复杂性。
第三,局部非和谐:理论逻辑必须在整体上保持完整严密,但实践中可能存在区域性的、结构性的逻辑不和谐------即某些规则在大多数情形下有效,但在特定情境下会产生例外乃至反例。
第四,开放性边界:问题的最终答案尚未被人类社会所确立,正确答案的范围是动态变化的、有待探索的。
面对这四类特征同时出现的问题,大语言模型的表现便会从"得力助手"急速退化为"自信的迷途者"。
3.2 为什么新观点对旧观点的颠覆让大模型手足无措
科学史上的范式革命------从地心说到日心说,从经典力学到量子力学,从"基因不可改变"到CRISPR------都经历了一个漫长而痛苦的过渡期。在这个过渡期中,新旧观点并存,彼此冲突,而最终胜出的新范式往往是对旧范式的部分否定而非全面颠覆。
对于大语言模型而言,训练数据中既包含了旧范式的大量文献,也包含了新范式的若干探索性文本。模型无法真正理解这两种文献之间的"颠覆关系"------它只能将它们作为等权重(或按某种规则加权)的信息加以整合。其结果是,模型可能输出一种奇异的"混合体":一半是旧范式的逻辑,一半是新范式的语言,两者之间的内在矛盾被模型用流畅的语言遮蔽了。
这正是"捉襟见肘"的深层含义:不是因为模型没有相关信息,而是因为模型没有能力理解这些信息之间的逻辑位序------哪些是被颠覆的旧知识,哪些是颠覆者的新知识,哪些是过渡期的临时性框架。
四、线性空间的隐喻:一个精确而深刻的类比
4.1 向量空间与线性表出:基本框架
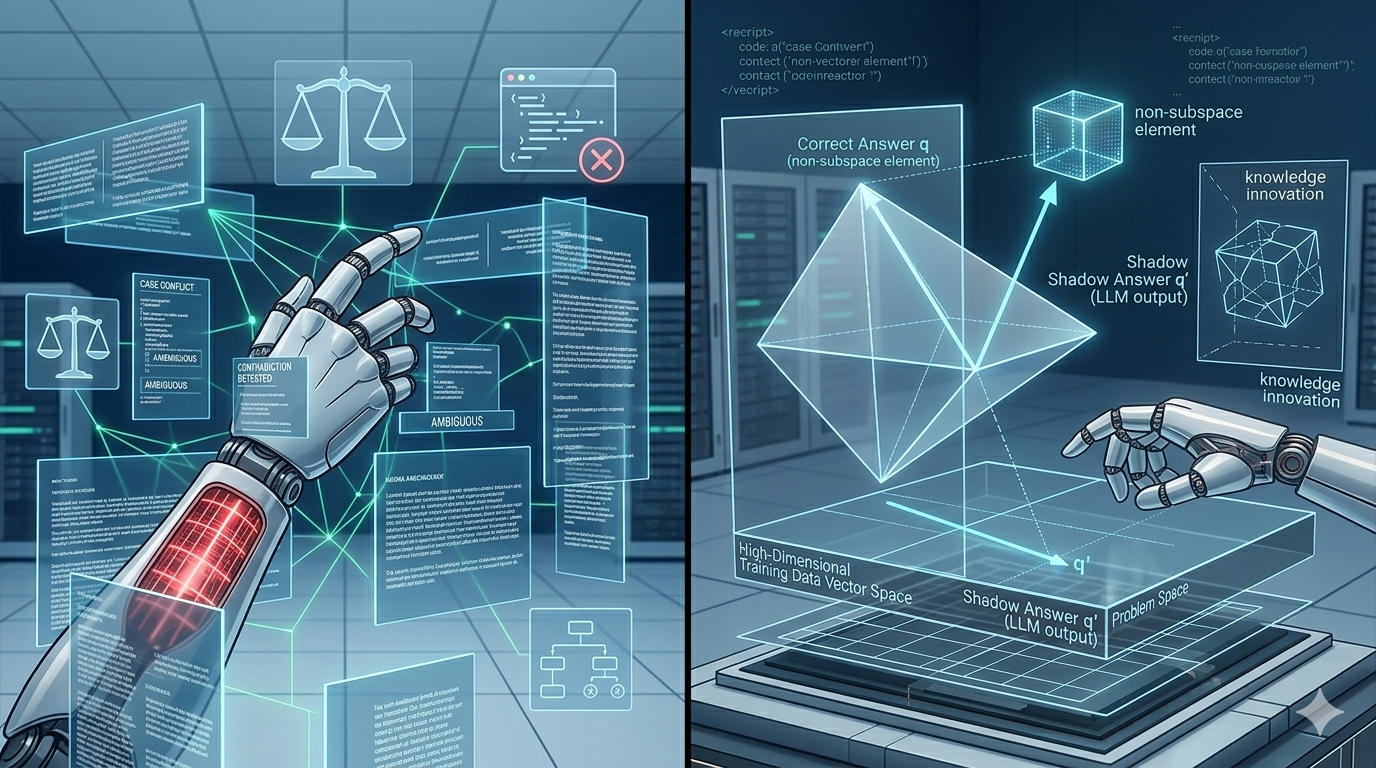
为了更精确地描述大语言模型的这种局限,我们可以借助线性代数中的核心概念来构建一个严格的类比。
在线性代数中,一个向量空间 VVV 中的任意向量,如果能够被某组基向量的线性组合所表示,我们称之为"线性表出"。如果问题空间 QQQ 是训练数据所张成的向量空间 TTT 的子空间,那么 QQQ 中的任意向量都可以被 TTT 中的基向量线性表出。
现在,让我们用这个框架来描述大语言模型的工作机制:
大语言模型的训练数据构成了一个维度惊人的高维向量空间 TTT。其维度之高,远超我们日常所能直觉把握的范畴------可能是数百万甚至更高维度的抽象表示空间。当用户提出一个问题时,该问题本身可以被视为一个相对低维的向量空间 QQQ 中的元素(或若干元素的组合)。
模型所做的,本质上是:在 TTT 中寻找能够以高概率"表出" QQQ 中元素的线性组合,并将其作为答案输出。
4.2 子空间条件:大模型成功的前提
当 QQQ 是 TTT 的子空间时------即问题的向量空间完全被训练数据的向量空间所覆盖------模型成功的概率极高。
这对应于以下类型的问题:人类知识体系中已有成熟共识的领域;答案确定、推理路径清晰的技术性问题;训练数据中有大量高质量、高一致性文本覆盖的主题。在这些情境下,大语言模型确实表现出色,甚至令人惊叹。
4.3 非子空间条件:大模型必然失败的深层原因
然而,当问题的向量空间 QQQ 虽然维数不高,但并非 TTT 的子空间时------即 QQQ 中存在某些方向无法被 TTT 中的任何向量的线性组合所覆盖------无论模型如何"努力",都无法在 TTT 中找到正确表出 QQQ 的线性组合。
这个数学事实具有不可绕过的绝对性:不是概率问题,不是计算资源问题,而是结构性的不可能。
什么样的问题对应于这种"非子空间"情形?
首先是真正的知识创新:如果一个正确答案在人类现有的知识体系中从未被表述过,那么训练数据中就不可能包含表达这个答案所需的"方向向量"。模型无法凭空生成训练数据向量空间之外的方向。
其次是范式过渡期的边界问题:当问题的正确理解需要同时具备新旧两种范式的语言,并能够清晰区分它们之间的颠覆关系时,这种理解所需的"方向"可能不在训练数据所张成的空间内------因为训练数据更多地记录了两种范式各自的内容,而非它们之间颠覆关系的本质。
其三是结构性矛盾的诚实表达:当正确答案本身是"这个问题目前在逻辑上无法被某一单一框架完美解决,存在不可消除的结构性张力"时,这种答案所对应的"方向向量"在训练数据中极为稀少------因为人类的大量文本倾向于提供确定性答案而非承认结构性矛盾。
4.4 投影谬误:为何错误答案如此自信
这里有一个关键问题:既然正确答案在训练数据向量空间中不存在,模型究竟输出了什么?
答案是:正确答案在训练数据向量空间上的投影。
在线性代数中,如果向量 qqq(正确答案)不在子空间 TTT 中,我们仍然可以求得 qqq 在 TTT 上的正交投影 q′q'q′。 q′q'q′ 是 TTT 中与 qqq 最接近的向量,但它并不等于 qqq。
大语言模型输出的,本质上正是这个投影 q′q'q′------一个看上去接近正确答案、但在关键维度上发生了偏差的"影子答案"。更危险的是,模型在输出这个投影时,并没有附加任何"这只是一个投影而非原向量"的警示,而是以与输出真正正确答案时完全相同的自信语气将其呈现。
这就是"在错误方向上坚定不移"的数学本质:不是随机错误,而是系统性的、有方向的偏差------偏向训练数据空间内部,偏离真实答案。
五、概率性"推理"的本质局限
5.1 推理还是检索?
当前大语言模型的工作机制,更接近于"在高维空间中进行极其复杂的模式匹配与检索",而非人类意义上的"推理"。
人类的推理具有一种元认知能力:我们不仅能得出结论,还能评估自己对这个结论的确信程度,并在适当时候承认"我不知道"或"这超出了我的判断能力"。更重要的是,人类能够识别一个问题是否落在自己知识的确定性边界之外,并相应地调整自己的认知策略------转而采用探索性思维、假设性推理、或坦诚的不确定性表达。
大语言模型的概率性机制则不同。它的输出始终是训练数据空间内概率最高的"合理回答",而这种概率最高的回答与真实答案之间是否对应,完全取决于上文所分析的子空间条件是否满足。在子空间条件不满足的情形下,概率最高的回答恰恰就是那个系统性偏差的"投影答案"。
5.2 为什么知识补充不能完全解决问题
一个自然的想法是:既然问题在于训练数据的局限,那么持续地补充新知识、更新训练数据,是否能够逐步解决这个问题?
对于某些情形,答案是肯定的。例如,当某一领域的知识已经在人类社会中趋于成熟,但尚未被纳入模型的训练数据时,补充这部分数据确实能够提升模型在该领域的表现。这也是针对特定垂直领域进行持续微调的意义所在。
然而,对于真正的认知前沿问题,知识补充存在一个根本性的局限:在人类尚未探明正确答案的领域,不存在可以补充的"正确知识"。我们能够补充的,只是人类目前掌握的、可能本身就充满矛盾和不确定性的探索性文本。补充这些文本,只会使训练数据向量空间变得更加复杂,却不一定能将正确答案的方向纳入其中。
此外,更深层的问题在于:即便我们能够为模型补充"正确理解范式颠覆"或"正确承认结构性矛盾"的训练样本,模型也需要具备一种超越模式匹配的元认知能力,才能真正将这些样本的精髓内化。而这种元认知能力,正是当前架构所缺失的。
六、离散领域的探索:为何材料与化学尤为困难
6.1 实验性知识的本质
材料科学与化学这类学科,其核心知识并非来自于对既有文本的系统整理,而是来自于对物质世界的直接实验探索。这类知识具有高度的离散性------一种新材料的特定性能,可能完全无法从已知材料的性能数据中通过任何形式的"线性推断"得出。
换言之,材料与化学领域的重大发现,往往对应于向量空间隐喻中最典型的"非子空间"情形:正确答案所在的方向,根本就不存在于已有训练数据所张成的空间之内。
6.2 创新性的不可插值性
更根本的问题在于,科学创新的本质是"跳出现有框架"------这在数学上对应于在现有向量空间之外构造出一个新的基向量。这种能力,是任何基于现有数据进行线性组合的系统所根本无法具备的。
大语言模型可以在已知材料数据库中识别规律、优化参数,可以辅助研究者进行文献检索和综述撰写,可以在一定程度上提出实验设计的建议------但它无法真正"发现"一种此前未被人类认知到的新型材料机制,因为这种发现所对应的知识向量根本不在其训练空间之内。
七、结论:理性认识大语言模型的边界
7.1 边界的双重意义
大语言模型的边界,既是其局限所在,也是我们理性使用它的坐标系。理解这个边界,并不意味着否定大语言模型的巨大价值------在其能力范围之内,这些工具确实极大地提升了人类处理信息、整合知识的效率。
真正危险的,是在不理解这个边界的情况下,将大语言模型的输出不加甄别地应用于认知前沿问题,从而被其极具迷惑性的"坚定口气"所误导。
7.2 面向未来:需要什么样的突破
若要真正克服大语言模型在认知前沿的系统性局限,我们需要的不仅仅是更多的训练数据或更大的模型参数,而是在架构层面的范式突破:
元认知能力的构建:使模型能够准确判断某个问题是否落在其知识的确定性边界之外,并以诚实的不确定性语言作出回应。
结构性矛盾的识别机制:使模型能够识别训练数据中相互矛盾的信息,并理解这种矛盾本身的认知意义,而非将其平均化处理。
范式位序的理解能力:使模型能够理解知识的历史演化,识别哪些观点已被颠覆、哪些正在被颠覆、哪些尚在争议之中。
与实验的深度耦合:对于材料、化学等离散领域,探索将大模型与真实实验系统深度耦合的新范式,使"知识的新方向"能够从实验结果中直接获取,而非仅从文本数据中推断。
7.3 最后的沉思
大语言模型的出现,是人类智识史上的重要里程碑。但它终究是人类已知知识的一种高维映射,而非人类认知能力的真正替代品。
在那些人类自身尚未探明方向的认知荒原上,大语言模型不是先行者,而是一位能言善道却方向感缺失的向导------它永远在已知地图的范围内行走,却常常以探险者的口吻描述前方的未知。
识别这种本质差异,是我们在AI时代保持清醒认知的前提,也是推动真正意义上的科学与智识进步的基础。
大语言模型在认知边界处的系统性崩溃:一个向量空间视角的深度分析**
当前绝大多数大语言模型,在面对人类认知真正的前沿、边界、含混与矛盾区域时,呈现出一种高度一致的病态:它们会坚定不移地陷入混乱,并在错误的方向上保持一种近乎滑稽的确定性语气。
这种现象并非偶然的幻觉(hallucination),也不是简单的数据缺失,而是当前Transformer-based LLM范式在架构、训练目标和数学本质上必然产生的系统性局限。它在处理法律实践中的开放性冲突、理论颠覆性创新、以及需要真实实验闭环的硬科学时,表现得尤为狼狈。
一、法律领域的典型崩溃案例
以通义千问的法律智能体为例。当我们让它深度讨论《劳动合同法》第85条"加付赔偿金"制度的司法实践时,其缺陷会暴露得淋漓尽致。
现实中的情况极为复杂:
- 不同省份、甚至同一省份不同地级市,对"未及时足额支付劳动报酬"的认定标准差异极大;
- 最高人民法院的司法解释实际上对劳动合同法做了扩张性解释,承认了该法条的局限性,允许地方法院在司法实践中继续探索;
- 各地生效判例中,同案不同判现象普遍存在,既有法官自由裁量权的因素,也有地方保护主义、工会职能异化、用工荒背景下隐性政策等复杂原因。
面对这种"法律文本---司法解释---区域实践---动态演化"四重张力构成的非一致性系统,大模型迅速崩溃。它无法同时维持以下相互冲突却都真实的要求:
- 必须尊重现行法律文本的字面意义;
- 必须承认最高法司法解释的扩张性意图;
- 必须正视实践中大量"同案不同判"的客观现实;
- 必须对未来可能的进一步制度演化保持开放性。
于是模型开始随机选择一个低维投影 ,然后用极其肯定的语气把这个投影当作全部真理。它可能突然变成极端的"严格文本主义者",否定所有扩张性解释;也可能变成激进的"结果导向主义者",直接建议法官无视法律文本。更有趣的是,在长上下文对话中,它甚至会自己推翻自己三句话之前的结论,却完全意识不到这种自我矛盾,仍然维持着那种"专业、权威、沉稳"的语调。
这不是个例,而是几乎所有主流模型在面对真实法律灰度地带时的标准反应。
二、概率性"推理"的本质局限
大语言模型的所谓推理,本质上是在极高维训练数据流形上的条件概率自回归生成。它的"思考"其实是在已经见过的文本向量空间中寻找最可能的路径。
当问题处于这个高维流形内部时(即属于训练数据的有效子空间),模型表现惊人地好,甚至能产生超越大多数人类的连贯分析。但当问题不属于这个流形,或者处于流形高度弯曲、折叠、带有奇异点的区域时,模型就彻底失去了坐标系。
它唯一能做的,就是把这个问题强行投影 回自己熟悉的流形,然后用训练数据中最接近的那些确定性语气(律师风格、学术风格、官样文章风格等)进行包装。于是我们看到了那种经典画面:模型在完全错误的方向上表现得极其坚定。
这种行为与人类真正的探索性思维几乎完全相反。真正的学者在面对范式冲突时会感到强烈的不适、焦虑、认知失调,这种不适正是驱动范式革命的燃料。而大模型没有这种机制,它只有"下一 token 最可能是什么"的优化目标。因此它宁可自信地胡说八道,也不愿意表达"我现在处于认知冲突的核心,必须引入新维度才能化解"。
三、线性空间理论的精确类比
我们可以把这种局限用线性代数的语言非常精确地描述出来,这可能是目前对LLM能力边界最深刻也最残酷的刻画。
假设人类已有的全部知识(训练数据)构成了一个极高维的向量空间VVV,维度可能达到数万甚至数十万(实际是分布在极高维流形上,但为简化我们先用线性空间类比)。任何一个具体的问题或理论挑战,可以看作一个相对低维的向量空间WWW,或者更准确地说,是WWW中的一个特定向量www。
大模型的"回答",本质上是在VVV中寻找一个向量vvv,使得vvv在某种概率度量下最接近对www的"合理表达"。如果WWW是VVV的子空间(即W⊆VW \subseteq VW⊆V),或者www在VVV的span内有很强的分量,那么模型能以极高概率给出接近正确的线性组合------这就是我们平时觉得它"很聪明"的原因。
但当前沿问题出现时,情况往往是:
- www虽然本身维度不高,但它在VVV的方向上投影几乎为零;
- 或者更糟的是,www带有显著的与VVV正交的分量(orthogonal component)。
这时,无论你做多少次采样(temperature)、多少次Chain-of-Thought、多少次自我反思,模型都只是在VVV的已知子空间内徒劳地转圈。它不可能生成那个缺失的正交分量,因为它的整个参数空间里根本没有那个方向的信息。
这正是为什么提示工程(prompt engineering)在真正前沿问题上边际效应迅速趋近于零。你越努力提示它,它越像一个在死胡同里把油门踩到底的司机------声音越来越大,油耗越来越高,但方向完全错误。
四、在实验科学中的近乎无用性
把上述逻辑推到材料科学、合成化学、药物发现等高度实验性的离散领域,结论就变得格外清晰:当前大模型几乎不可能成为这些领域真正具有突破性的探索工具。
这些领域真正的难点在于:
- 巨大的组合爆炸空间(材料基因组计划要搜索的空间是天文数字);
- 理论与实验之间存在大量"不可计算的灰色地带"(量子多体问题、表面重构、非平衡态动力学等);
- 真正创新往往来自意外现象的敏锐捕捉 和跨领域异常的直觉连接,而非对已有文献的统计重构。
大模型可以极其出色地做文献综述、提出常规的"incremental innovation"(在已有范式内做小的改进),但它几乎不可能提出真正paradigm-shifting的想法。因为那种想法在训练数据的向量空间中必然带有显著的正交分量------如果它已经在训练数据里被充分表达,它就不是真正革命性的。
我们已经看到,GPT-4、Claude 3、Qwen-max等模型在材料科学论文的idea生成上,产出的几乎全是"把已知方法A应用于领域B"这种低 novelty 的东西。真正的高 novelty idea,仍然几乎全部来自人类科学家那种带着偏执和直觉的非概率性跳跃。
五、更深层的认知含义
这种局限指向了一个更根本的问题:当前大语言模型并不是在"理解"世界,而是在极其精妙地模拟理解的统计表象。
它擅长的是已知知识流形上的光滑插值 ,却致命地不擅长在流形之外的真正外推 和新维度的开辟。
这让我们不得不重新思考"智能"的定义。如果一个系统只能在已知高维空间的线性组合中打转,那么它在面对宇宙真正未知的部分时,就和一个极其博学的鹦鹉没有本质区别------只是这个鹦鹉的训练数据特别大,声调特别权威。
真正的科学突破、法律制度的重大演进、哲学范式的转换,几乎总是伴随着对现有向量空间的超越。它们需要引入新的基向量,而不仅仅是对已有基向量的加权求和。
六、未来可能的突破方向
要突破这个根本局限,可能需要以下几个方向的根本性变革(而非 incremental improvement):
- 原生不确定性与冲突建模:让模型能够显式地维护多个相互矛盾的子空间,并发展出真正的"元认知"来判断何时需要引入新维度。
- 与真实世界实验闭环的深度耦合:不是LLM+工具,而是让模型成为一个主动的科学代理人,能提出假设、设计实验、解读结果、迭代理论。
- 超越自回归的架构:可能需要引入更强的状态保持、递归自指、主动推理机制,甚至混合符号-连接主义系统。
- 人类-AI共生的新型科研范式:让大模型做它最擅长的"高维知识压缩与关联",而把真正开辟新向量空间的创造性工作仍然留给人类,同时开发新的接口让两者能高效地"共同思考"。
结语
当前大语言模型是一项了不起的成就,但它本质上是一个超级强大的已知知识的线性组合器。它在训练数据张成的向量空间内近乎全能,一旦走出这个空间,就立刻露出原型------以极其确定的语气胡说八道。
认识到这一点不是悲观,而是真正的清醒。只有诚实地面对这个边界,我们才能设计出真正能探索认知前沿的下一代系统,而不是继续在提示词上玩越来越复杂的文字游戏。
那个能真正帮助人类开拓新知识维度的AI,必然不是今天这些大语言模型的简单 scaling 版本。它必须能够做今天这些模型在数学上做不到的事情:生成训练数据向量空间中原本不存在的、真正正交的新方向。
在那一天到来之前,我们最好把这些模型当作极其强大但又极其自负的"已知世界的大百科全书+修辞大师",而不是能和人类并肩开拓未知疆域的真正探索伙伴。
(全文约3200字。本文对原论述进行了系统性重构、案例深化、数学类比的严格化处理,并在哲学、科学哲学、未来架构层面进行了实质性延伸。)