一、前言:为什么缓存同步如此重要?
在现代互联网架构中,我们普遍采用多级缓存(本地缓存 + Redis + 数据库)来提升性能。但随之而来的是一个经典难题:
当数据库数据更新后,如何确保各级缓存中的数据也同步更新?
若处理不当,将导致:
- ❌ 用户看到过期商品价格
- ❌ 管理员修改配置后不生效
- ❌ 订单状态不一致引发资损
缓存同步的本质 :在性能 与一致性之间找到最佳平衡点。
本文将系统性地介绍5 大主流缓存同步策略 ,并提供生产级选型建议。
二、核心挑战:缓存不一致是如何产生的?
场景 1:并发写操作
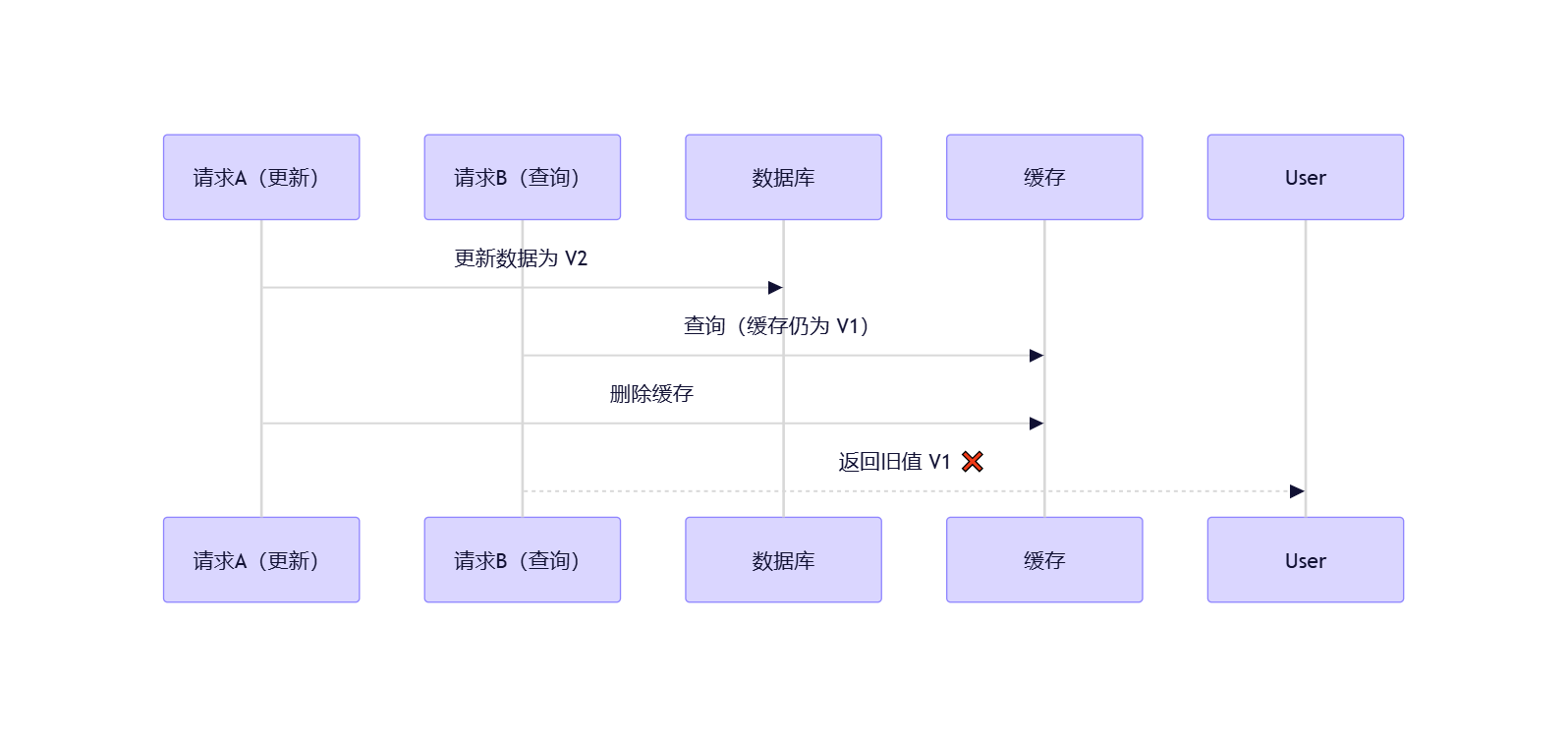
场景 2:多级缓存不同步
- 服务 A 更新了 Redis,但服务 B 的本地缓存仍是旧值
- 跨机房部署时,缓存失效消息未广播到所有节点
三、五大缓存同步策略详解
策略 1:Cache-Aside(旁路缓存)------ 最常用 ✅
流程:
- 读请求:先查缓存 → 未命中则查 DB → 回填缓存
- 写请求:先更新 DB → 再删除缓存
python
# 伪代码
def update_user(user_id, name):
# 1. 更新数据库
db.update("users", {"id": user_id, "name": name})
# 2. 删除缓存(不是更新!)
cache.delete(f"user:{user_id}")优点 :简单、高效、避免脏数据
缺点:存在短暂不一致窗口
策略 2:延迟双删(Delayed Double Delete)------ 应对高并发 ⚡
适用场景:高并发写 + 读场景(如秒杀库存)
流程:
- 删除缓存
- 更新数据库
- 延迟 N 毫秒后再次删除缓存
python
def update_stock(product_id, new_stock):
cache.delete(f"stock:{product_id}") # 第一次删
db.update("products", {"id": product_id, "stock": new_stock})
time.sleep(500) # 延迟 500ms
cache.delete(f"stock:{product_id}") # 第二次删原理 :覆盖"读请求在写操作中间"导致的脏读
注意:延迟时间需 > 一次 DB 主从同步 + 业务查询耗时
策略 3:订阅 Binlog(异步监听)------ 企业级方案 🏢
架构:
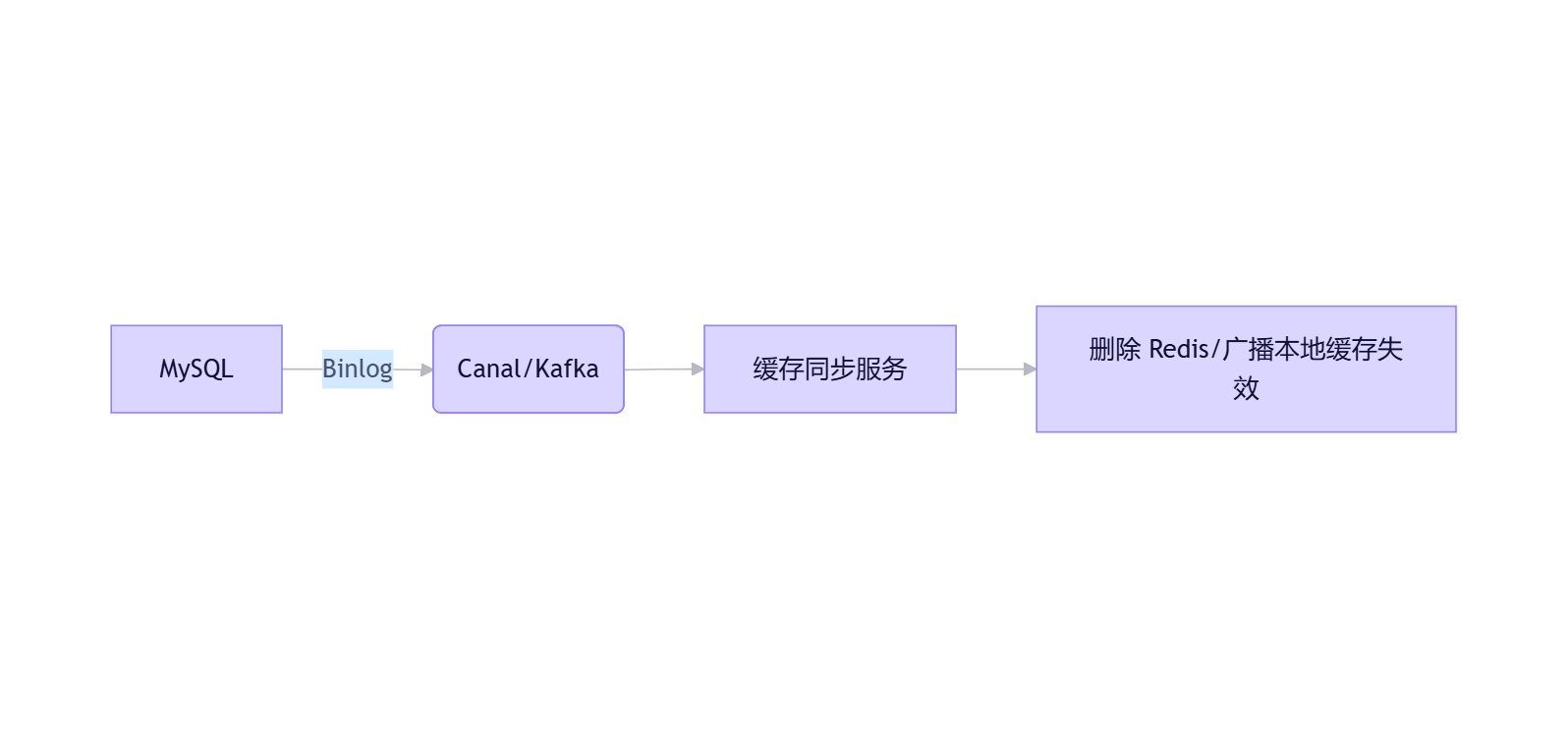
优势:
- 解耦:业务代码无需关心缓存
- 可靠:基于数据库日志,不丢事件
- 支持多级缓存同步
缺点:
- 架构复杂
- 存在秒级延迟(最终一致性)
💡 典型应用:阿里 Canal + RocketMQ 实现缓存同步
策略 4:Write-Through(写透模式)------ 强一致性 🔒
流程:
- 写请求同时更新 DB 和缓存
- 读请求只查缓存
python
def write_through(key, value):
db.set(key, value)
cache.set(key, value) # 同步更新适用场景 :对一致性要求极高(如金融交易)
缺点:写性能下降,缓存不可用时写失败
策略 5:读写锁 / 分布式锁 ------ 极端强一致 ⚠️
流程:
- 写操作前加全局锁
- 确保"读-改-写"原子性
python
with distributed_lock("user_update"):
old = cache.get("user:1001")
new = update_in_db(old)
cache.set("user:1001", new)警告:严重降低吞吐量,仅用于极少数核心场景
四、特殊场景补充策略
4.1 热点 Key 一致性
- 问题:单个 Key 被百万 QPS 查询,更新时易不一致
- 方案 :
- 本地缓存 + Redis 二级架构
- 更新时通过 MQ 广播失效消息到所有节点
4.2 跨机房缓存同步
- 问题:北京机房更新数据,上海机房缓存未失效
- 方案 :
- 全局消息队列(如 Kafka)广播缓存失效事件
- 设置较短 TTL(如 30s)作为兜底
4.3 缓存与 DB 并发冲突
- 经典问题:"先删缓存 vs 先更新 DB"?
- 结论 :先更新 DB,再删缓存 (Cache-Aside 标准做法)
- 即使出现不一致,下次读也会修复(自愈)
五、生产环境最佳实践
5.1 策略选型指南
| 业务场景 | 推荐策略 | 一致性级别 |
|---|---|---|
| 商品详情页 | Cache-Aside + TTL | 最终一致 |
| 秒杀库存 | 延迟双删 | 准实时一致 |
| 用户余额 | Write-Through + 分布式锁 | 强一致 |
| 配置中心 | Binlog 监听 | 最终一致 |
5.2 必须遵守的原则
- 删除缓存,而非更新缓存(避免并发写覆盖)
- 设置合理的 TTL(兜底机制,防永久不一致)
- 监控缓存命中率 & 不一致率(如对比 DB 与缓存差异)
- 避免大 Value 缓存(更新成本高,易雪崩)
5.3 代码防御示例
java
// Spring Boot 示例:更新后删除缓存
@Transactional
public void updateUser(Long id, String name) {
// 1. 更新数据库
userMapper.update(id, name);
// 2. 删除缓存(使用 @CacheEvict)
// 注意:放在事务提交后执行!
applicationEventPublisher.publishEvent(new UserUpdatedEvent(id));
}
@EventListener
@Async
public void handleUserUpdate(UserUpdatedEvent event) {
redisTemplate.delete("user:" + event.getId());
}六、常见误区与陷阱
| 误区 | 正确做法 |
|---|---|
| "先删缓存,再更新 DB" | → 易导致缓存被旧值回填 |
| "更新缓存而不是删除" | → 并发写可能覆盖新值 |
| "不设 TTL" | → 一旦同步失败,数据永久错误 |
| "本地缓存不处理失效" | → 多实例部署必出问题 |
七、结语
感谢您的阅读!如果你有任何疑问或想要分享的经验,请在评论区留言交流!