FunASR 离线语音识别与FunASR热词优化
FunASR 是阿里巴巴达摩院开源的语音识别工具库,提供了多种模型和丰富的参数配置,支持离线和实时语音识别。
在查阅 FunASR 热词功能相关资料时,发现网络上关于 FunASR 热词识别 的完整代码示例非常少,大部分文章只介绍了热词格式,却缺少:
- 完整的可运行代码:没有模型加载、音频处理的完整流程
- 热词模型选择:未说明只有特定模型支持热词优化
- 实际效果对比:缺少热词添加前后的识别效果对比测试
本文将从 FunASR 的基础功能出发,重点介绍 热词识别功能 的完整实现,并提供所有可运行的代码示例,帮助读者快速上手 FunASR 热词优化。
一、FunASR 支持的音频输入格式
FunASR 的 generate() 方法支持多种音频输入格式,非常灵活:
1. 基础格式
| 格式 | 示例 | 说明 |
|---|---|---|
| 单文件路径 | "audio.wav" |
字符串路径,最常用 |
| 多文件路径 | ["a.wav", "b.wav"] |
列表形式,批量处理 |
| URL | "http://xxx/audio.mp3" |
网络地址,自动下载 |
2. 数据格式
| 格式 | 示例 | 说明 |
|---|---|---|
| Numpy 数组 | np.array([...]) |
已加载的音频数据,需 float32 类型 |
| 原始字节流 | open("a.wav", "rb").read() |
二进制数据(含文件头) |
| Base64 解码 | base64.b64decode(str) |
需先解码为字节流 |
3. 支持的音频文件格式
.wav- 最推荐,无压缩.mp3- 支持,需 ffmpeg.flac- 支持.ogg/.opus- 支持.m4a- 支持
4. 音频格式要求
- 采样率:推荐 16kHz(模型默认)
- 声道:单声道最佳,多声道会自动转换
- Numpy 输入:必须是 float32 类型,值域 -1, 1
5. 各种格式支持代码示例
python
import os
import time
import base64
import wave
import numpy as np
import soundfile as sf
from dotenv import load_dotenv
from funasr import AutoModel
from pydub import AudioSegment
# 加载环境变量
load_dotenv()
root_path = os.environ.get("model_root_dir", "")
print(f"root_path: {root_path}")
# 模型路径
asr_model_path = root_path + "paraformer-zh"
vad_mode_path = root_path + "fsmn-vad"
# 加载模型
model = AutoModel(
model=asr_model_path,
vad_model=vad_mode_path,
punc_model="ct-punc-c",
)
# ========== 音频格式转换工具函数 ==========
def load_audio_as_numpy(audio_path: str) -> tuple[np.ndarray, int]:
"""加载音频为 numpy 数组(返回数据和采样率)"""
audio_data, sr = sf.read(audio_path)
return audio_data, sr
def load_audio_as_bytes(audio_path: str) -> bytes:
"""加载音频为原始字节流"""
with open(audio_path, "rb") as f:
return f.read()
def load_audio_as_base64(audio_path: str) -> str:
"""加载音频为 base64 编码字符串"""
audio_bytes = load_audio_as_bytes(audio_path)
return base64.b64encode(audio_bytes).decode()
def load_wav_to_pcm_data(wav_path: str):
"""保存pcm_data数据为音频文件"""
with wave.open(wav_path, "rb") as wf:
# 获取元信息
n_channels = wf.getnchannels() # 声道数
sample_width = wf.getsampwidth() # 采样宽度(字节):1→8bit, 2→16bit, 3→24bit(注意!)
sample_rate = wf.getframerate() # 采样率 Hz
n_frames = wf.getnframes() # 总采样点数(每声道)
print(f"声道数: {n_channels}")
print(f"采样宽度: {sample_width} 字节 ({sample_width * 8}-bit)")
print(f"采样率: {sample_rate} Hz")
print(f"总帧数: {n_frames}")
print(f"时长: {n_frames / sample_rate:.2f} 秒")
# 读取原始字节数据
raw_data = wf.readframes(n_frames)
return raw_data
def pcm_bytes_to_numpy(pcm_bytes: bytes) -> np.ndarray:
"""PCM 原始字节转 numpy 数组(16bit PCM,需确保是 16kHz 单声道)"""
pcm_array = np.frombuffer(pcm_bytes, dtype=np.int16)
return pcm_array.astype(np.float32) / 32768.0
def opus_to_numpy(opus_path: str) -> np.ndarray:
"""Opus 文件转 numpy 数组(自动转 16kHz 单声道)"""
audio = AudioSegment.from_file(opus_path, format="opus")
audio = audio.set_frame_rate(16000).set_channels(1)
samples = np.array(audio.get_array_of_samples(), dtype=np.float32)
return samples / 32768.0
def base64_to_numpy(base64_str: str) -> np.ndarray:
"""Base64 编码转 numpy 数组(假设是 WAV 格式)"""
audio_bytes = base64.b64decode(base64_str)
# WAV 字节流可以直接传给 model.generate
return audio_bytes # FunASR 支持字节流,无需再转 numpy
# ========== ASR 识别函数 ==========
def recognize(audio_input, description: str = "") -> str:
"""统一识别接口,打印结果"""
res = model.generate(
input=audio_input,
disable_pbar=True,
)
text = res[0]["text"]
print(f"{description}: {text}")
return text
# ========== 测试所有支持的输入格式 ==========
if __name__ == "__main__":
audio_file_path = "audio_data/01.wav" # 本地音频16khz
url_audio_path = "https://dashscope.oss-cn-beijing.aliyuncs.com/audios/welcome.mp3"
audio_files = ["audio_data/01.wav", "audio_data/02.wav"]
print("\n========== FunASR 支持的音频输入格式测试 ==========\n")
# 1. 单文件路径
recognize(audio_file_path, "1. 单文件路径")
# 2. URL 路径
recognize(url_audio_path, "2. URL 路径")
# 3. 多文件批量
start = time.time()
res_list = model.generate(input=audio_files, disable_pbar=True)
elapsed = time.time() - start
print(f"3. 多文件批量 ({elapsed:.2f}s):")
for i, res in enumerate(res_list):
print(f" [{i+1}] {res['text']}")
# 4. Numpy 数组
audio_numpy, sr = load_audio_as_numpy(audio_file_path) # 我这个是16kHz的wav音频
print(f" 采样率: {sr}Hz")
recognize(audio_numpy, "4. Numpy 数组")
# 5. 原始字节流
audio_bytes = load_audio_as_bytes(audio_file_path)
recognize(audio_bytes, "5. 原始字节流")
# 6. Base64 编码(需解码后传入)
base64_str = load_audio_as_base64(audio_file_path) # 先构造的到base64数据
audio_bytes_from_base64 = base64.b64decode(base64_str) # audio_bytes == audio_bytes_from_base64
recognize(audio_bytes_from_base64, "6. Base64 解码")
# ========== 其他格式示例(注释,需对应文件) ==========
# 7. PCM 原始数据(假设已有 pcm 文件), pcm_bytes ---> numpy.array
pcm_bytes = load_wav_to_pcm_data(audio_file_path)
pcm_numpy = pcm_bytes_to_numpy(pcm_bytes)
recognize(pcm_numpy, "7. PCM 数据")
# 8. Opus 文件(需 pydub + ffmpeg) opus也是转化为pcm_data --> numpy.array在识别
# 略
# print("\n========== 测试完成 ==========\n")二、三大模型组件详解
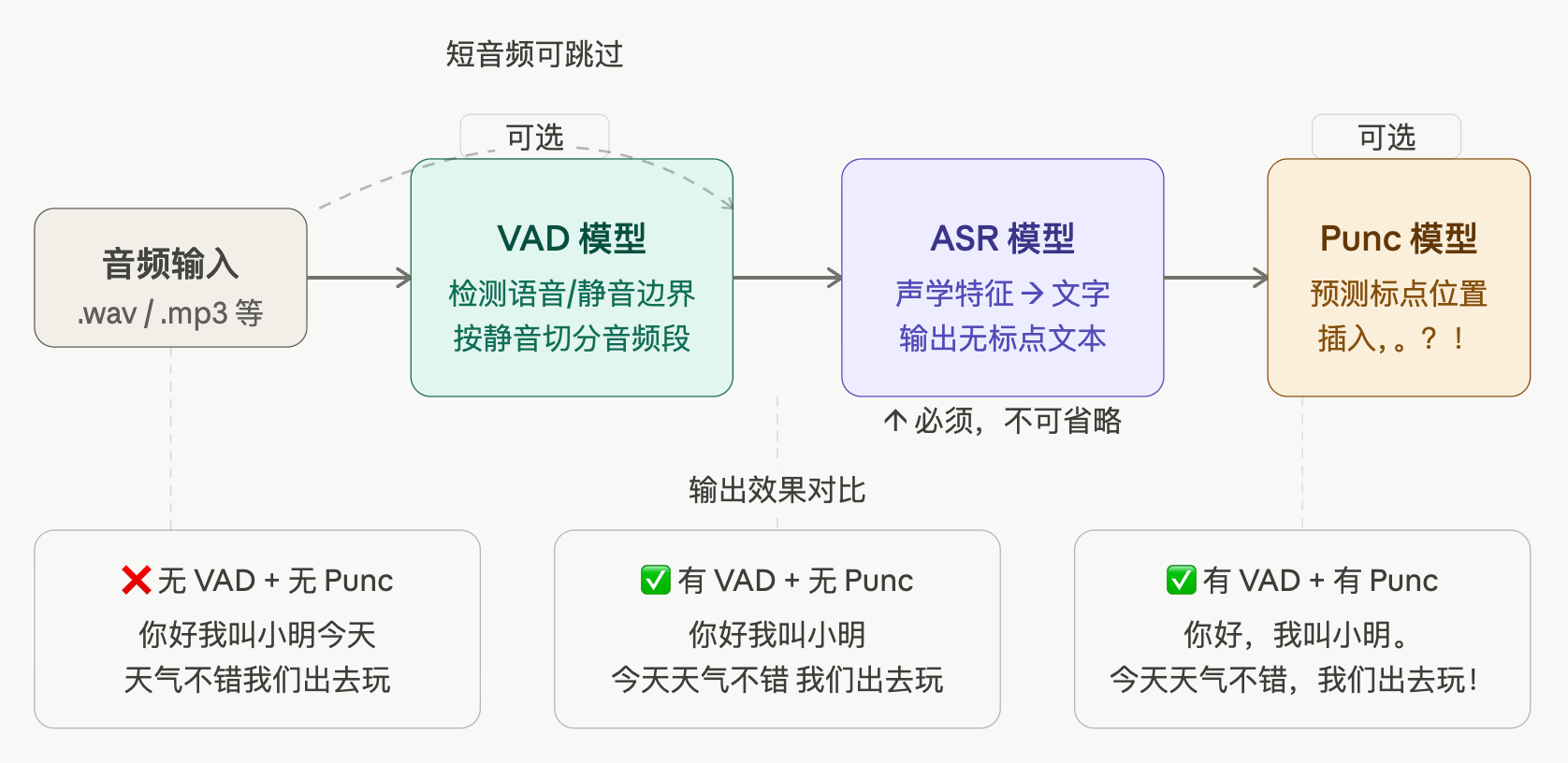
FunASR 采用流水线架构,由三个核心模型组成,分工明确:
| 模型 | 参数名 | 是否必需 | 功能职责 | 适用场景 |
|---|---|---|---|---|
| ASR 模型 | model |
✅ 必需 | 核心语音识别,音频 → 文本转换 | 所有语音识别场景 |
| VAD 模型 | vad_model |
❌ 可选 | 语音活动检测,分割静音与有效语音 | 长音频、实时流式、会议录音 |
| 标点模型 | punc_model |
❌ 可选 | 自动添加标点符号,提升可读性 | 需要完整文本输出的场景 |
三模型协作流程
音频输入 → [VAD: 检测语音片段] → [ASR: 语音转文本] → [标点: 添加标点] → 输出结果
↑ 可选 ↑ 必需 ↑ 可选组合配置建议
| 音频类型 | 推荐配置 | 说明 |
|---|---|---|
| 短音频(<2分钟) | model |
仅 ASR 模型即可 |
| 长音频(>5分钟) | model + vad_model |
VAD 防显存溢出 |
| 完整输出 | model + vad_model + punc_model |
三模型组合 |
| 实时流式 | model + vad_model |
VAD 是必需组件 |
VAD 模型的特殊效果
重要结论 :添加 VAD 模型后,即使没有 punc_model,识别结果中的短句之间也会用空格分隔开。
无 VAD + 无标点: 在异步编程中协程可以高效处理大量并发任务
有 VAD + 无标点: 在 异 步 编 程 中 协 程 可 以 高 效 处 理 大 量 并 发 任 务
有 VAD + 有标点: 在异步编程中,协程可以高效处理大量并发任务。原因:VAD 将音频切分为多个语音片段,每个片段单独识别后拼接,自然形成空格分隔。
1. ASR 模型(必需)
作用:核心语音识别模型,将音频转换为文本。
python
model = AutoModel(
model="paraformer-zh", # ASR 模型(必需)
)选择建议:
- 短音频(<30秒):只用 ASR 模型即可
- 热词需求:使用
speech_seaco_paraformer_large热词优化版
2. VAD 模型(可选)
作用:语音活动检测,分割静音和有效语音片段。
python
model = AutoModel(
model="paraformer-zh",
vad_model="fsmn-vad", # VAD 模型(可选)
)适用场景:
| 场景 | 是否需要 VAD |
|---|---|
| 短音频(<2分钟) | 可选 |
| 长音频(>5分钟) | 推荐(防显存溢出) |
| 会议录音(大量静音) | 推荐(节省算力) |
| 实时流式识别 | 必需 |
重要限制 :有 VAD 模型时,batch_size 必须为 1!
python
# 有 VAD,batch_size 必须为 1
model = AutoModel(model="paraformer-zh", vad_model="fsmn-vad")
res = model.generate(input=["a.wav", "b.wav"], batch_size=1) # 正确
# 无 VAD,batch_size 可以 > 1
model = AutoModel(model="paraformer-zh")
res = model.generate(input=["a.wav", "b.wav"], batch_size=8) # 正确3. 标点模型(可选)
作用:为识别结果自动添加标点符号。
python
model = AutoModel(
model="paraformer-zh",
punc_model="ct-punc-c", # 标点模型(可选)
)效果对比:
| 配置 | 输出结果 |
|---|---|
| 无标点模型 | 在异步编程中协程可以高效处理大量并发任务 |
| 有标点模型 | 在异步编程中,协程可以高效处理大量并发任务。 |
4. 三模型组合使用
python
# 短音频 - 最简配置
model = AutoModel(model="paraformer-zh")
# 长音频 - 加 VAD 切分
model = AutoModel(
model="paraformer-zh",
vad_model="fsmn-vad",
)
# 长音频 + 标点 - 完整配置
model = AutoModel(
model="paraformer-zh",
vad_model="fsmn-vad",
punc_model="ct-punc-c",
)5. 单个文件与批量识别代码示例
python
import os
import time
from dotenv import load_dotenv
from funasr import AutoModel
# 加载环境变量
load_dotenv()
root_path = os.environ.get("model_root_dir", "")
print(f"root_path: {root_path}")
# 模型路径
# https://huggingface.co/JunHowie/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch
# https://huggingface.co/funasr/paraformer-zh
# https://huggingface.co/FunAudioLLM/SenseVoiceSmall
# ["paraformer-zh", "SenseVoiceSmall", "speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch"]
asr_model_path = os.path.join(root_path, "paraformer-zh")
vad_mode_path = os.path.join(root_path, "fsmn-vad")
# 加载模型
model = AutoModel(
model=asr_model_path, # ASR 模型(必需)
vad_model=vad_mode_path, # VAD 模型(可选) 长音频,主要作用于实时流式语音中的识别,加了VAD识别在asrtext,就算没有punc_mode, 短句之间也会有空格区分开来
punc_model="ct-punc-c", # 标点模型(可选) 是否针对asr识别文本添加标点符号,不加这个asr文本中不会有标点符号
# 常用参数(可选)
# device="cuda", # 设备:cuda / cpu / cuda:0 / cuda:1
# ncpu=4, # CPU 线程数,默认 4
# disable_update=True, # 禁用自动下载更新
# disable_log=True, # 禁用日志
)
# ========== ASR 识别函数 ==========
def recognize(audio_input, hotword: str = "", description: str = "") -> str:
"""统一识别接口"""
res = model.generate(
input=audio_input,
hotword=hotword,
disable_pbar=True, # 不限时rtf
)
text = res[0]["text"]
print(f"{description}: {text}")
return text
def recognize_batch(audio_files: list, hotword: str = "", description: str = "") -> list:
"""批量识别接口"""
start = time.time()
res_list = model.generate(
input=audio_files,
hotword=hotword,
batch_size=1,
disable_pbar=True,
)
elapsed = time.time() - start
print(f"{description} ({elapsed:.2f}s):")
for i, res in enumerate(res_list):
print(f" [{i+1}] {res['text']}")
return res_list
# ========== 测试 ==========
if __name__ == "__main__":
audio_file = "audio_data/01.wav"
audio_files = ["audio_data/01.wav", "audio_data/02.wav"]
print("\n========== FunASR 识别测试 ==========\n")
# 1. 单文件识别(无热词)
recognize(audio_file, description="1. 单文件识别")
# 2. 多文件批量识别
recognize_batch(audio_files, description="3. 批量识别")
print("\n========== 测试完成 ==========\n")
print("模型说明:")
print(f" ASR 模型: {asr_model_path}")
print(f" VAD 模型: {vad_mode_path}")
print(f" 标点模型: ct-punc-c")
print()
print("注意事项:")
print(" - 有 VAD 模型时,batch_size 必须为 1") # 不为1时候会报错
print(" - 无 VAD 模型时,batch_size 可以 > 1")
print(" - 热词格式: '词1 词2' 或 '词1:权重 词2:权重'")三、FunASR 支持的参数详解
1. AutoModel 初始化参数
python
model = AutoModel(
model="paraformer-zh", # ASR 模型(必需)
vad_model="fsmn-vad", # VAD 模型(可选)
punc_model="ct-punc-c", # 标点模型(可选)
# 设备与性能
device="cuda", # 设备:cuda / cpu / cuda:0 / cuda:1
ncpu=4, # CPU 线程数,数据预处理并行度
# 其他配置
disable_update=True, # 禁用自动下载更新(离线环境必需)
disable_log=True, # 禁用日志
hub="ms", # 模型源:ms(魔搭) / hf(HuggingFace)
)device 与 ncpu 的区别:
| 参数 | 作用阶段 | 任务类型 |
|---|---|---|
device |
模型推理阶段 | GPU 并行计算(神经网络) |
ncpu |
数据预处理阶段 | CPU 密集型(音频加载、特征提取) |
2. generate() 方法参数
python
res = model.generate(
input="audio.wav", # 音频输入
# 解码参数
batch_size_s=300, # 每批处理音频秒数(长音频切分)
hotword="协程 异步", # 热词
# 输出控制
disable_pbar=True, # 关闭进度条
# 并行处理(无 VAD 时有效)
batch_size=8, # 同时处理 N 条音频
num_workers=4, # 数据加载线程数
# 语言设置
language="zh", # 语言:自动检测或指定
)batch_size 与 batch_size_s 的区别:
| 参数 | 作用 | 适用场景 |
|---|---|---|
batch_size |
同时处理 N 条音频 | 多音频批量处理 |
batch_size_s |
每批处理 N 秒音频 | 单条长音频切分 |
四、主流小模型对比
| 模型 | 特点 | 适用场景 | 热词支持 |
|---|---|---|---|
| paraformer-zh | 通用中文 ASR,速度快 | 常规语音识别 | ❌ 较弱 |
| SenseVoiceSmall | 多语言、情感识别、语音事件检测 | 需要多模态信息 | ❌ 较弱 |
| speech_seaco_paraformer_large | 热词优化版 | 专业术语、品牌名识别 | ✅ 效果好 |
1. paraformer-zh
最常用的通用中文 ASR 模型,速度快,准确率高。
- HuggingFace : https://huggingface.co/funasr/paraformer-zh
python
model = AutoModel(model="paraformer-zh")特点:
- 输出分词结果,词之间有空格
- 支持 VAD、标点模型组合
- 适合常规语音识别场景
2. SenseVoiceSmall
多功能模型,除 ASR 外还支持:
- HuggingFace : https://huggingface.co/FunAudioLLM/SenseVoiceSmall
python
model = AutoModel(model="SenseVoiceSmall")输出示例:
<|zh|><|NEUTRAL|><|Speech|><|woitn|>在异步编程中携程可以高效处理大量并发任务特殊标记含义:
<|zh|>- 语言标识(中文)<|NEUTRAL|>- 情感识别(中性)<|Speech|>- 语音事件检测- 文本部分是连续的,无空格
3. speech_seaco_paraformer_large
热词优化版模型,对专业术语识别效果好。
- HuggingFace : https://huggingface.co/JunHowie/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch
python
model = AutoModel(
model="speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch",
model_revision="v2.0.4",
)适用场景:
- 专业领域术语(医疗、法律、金融)
- 品牌名、人名识别
- 新词、生僻词识别
五、Funasr热词功能
- 在线TTS 语音生成测试
我测试的音频"audio_data/hot_words_01.wav"通过tts生成然后下载到本地,你也可以通过录音采集,我测试的音频是
【"在 异 步 编 程 中 携 程 可 以 高 效 处 理 大 量 并 发 任 务"】, 热词为携程 / 协程, 案例只是为了演示热词的使用案例,但是针对复杂专业术语受限于模型能力他不一定能能识别到。
1. 为什么需要热词?
普通 ASR 模型对专业术语、人名、品牌名等识别率较低。热词功能可以提升特定词汇的识别准确率。
2. 热词模型选择
重要 :只有 speech_seaco_paraformer_large 对热词响应较好!
| 模型 | 热词效果 |
|---|---|
speech_seaco_paraformer_large |
✅ 热词优化版,效果好 |
paraformer-zh |
❌ 响应较弱 |
SenseVoiceSmall |
❌ 响应较弱 |
3. 热词使用示例完整代码
python
import os
from funasr import AutoModel
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
root_path = os.environ.get("model_root_dir", "")
print(f"root_path: {root_path}")
# 热词优化版 Paraformer 模型(非实时)
# 注意:普通 paraformer-zh 和 SenseVoiceSmall 对热词识别效果较差
model_path = os.path.join(root_path, "speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch")
print(f"model_path: {model_path}")
vad_mode_path = os.path.join(root_path, "fsmn-vad")
# 加载模型
model = AutoModel(
model=model_path,
vad_model=vad_mode_path, # VAD 模型(可选) 长音频,主要作用于实时流式语音中的识别,加了VAD识别在asrtext,就算没有punc_mode, 短句之间也会有空格区分开来
punc_model="ct-punc-c", # 标点模型(可选) 是否针对asr识别文本添加标点符号,不加这个asr文本中不会有标点符号
model_revision="v2.0.4",
)
audio_path = "audio_data/hot_words_01.wav"
# ========== 热词测试函数 ==========
def recognize_with_hotword(audio: str, hotword: str = "", description: str = "") -> str:
"""带热词的识别测试"""
res = model.generate(
input=audio,
hotword=hotword,
batch_size_s=300,
disable_pbar=True,
)
text = res[0]["text"]
print(f"{description}: {text}")
return text
# ========== 热词对比测试 ==========
# 我看网上的一些针对funasr的热词识别都不怎么有效,可能原始还是模型本身能力的问题,或者是我用的不规范
# TTS 生成语音参考 网址 我测试的音频是 【"在 异 步 编 程 中 携 程 可 以 高 效 处 理 大 量 并 发 任 务"】, 热词为携程 / 协程
# https://modelscope.cn/studios/Qwen/Qwen3-TTS-Demo
if __name__ == "__main__":
print("\n========== FunASR 热词识别对比测试 ==========\n")
# 测试音频说明
print(f"音频文件: {audio_path}")
print(f"模型: speech_seaco_paraformer_large (热词优化版)")
print()
# 1. 无热词识别
text_before = recognize_with_hotword(audio_path, hotword="", description="1. 无热词")
# 2. 单热词识别。这个有效
text_single = recognize_with_hotword(audio_path, hotword="协程", description="2. 单热词: '协程'")
# 3. 多热词识别(空格分隔) 效果一般,无法识别, 词多了可能也无法识别
text_multi = recognize_with_hotword(
audio_path,
hotword="协程 并发 123",
description="3. 多热词: '协程 异步 并发'"
)
# 4. 热词权重测试(格式: 热词:权重) 效果一般,无法识别, 可能不支持这种写法
text_weight = recognize_with_hotword(
audio_path,
hotword="协程:50 异步:3",
description="4. 带权重: '协程:5 异步:3'"
)
print("\n========== 测试总结 ==========\n")
print("热词格式说明:")
print(" - 单热词: '协程'")
print(" - 多热词: '协程 异步 并发' (空格分隔)")
print(" - 带权重: '协程:5 异步:3' (数值越大权重越高)")
print()
print("模型选择:")
print(" ✅ speech_seaco_paraformer_large - 热词优化版,效果好")
print(" ❌ paraformer-zh / SenseVoiceSmall - 对热词响应较弱")4. 热词使用注意事项
- 模型选择:必须使用热词优化版模型
- 热词数量:不宜过多,效果可能下降
- 权重格式 :
热词:数值,数值越大优先级越高 - 实际效果:单热词效果最好,多热词和权重效果不稳定
六、进阶推荐
FunASR 提供的是轻量级小模型,如果对 ASR 识别准确率和热词识别要求更高,且有足够的计算资源,推荐使用以下开源大模型:
| 模型 | 说明 | 链接 |
|---|---|---|
| Fun-ASR-Nano-2512 | Qwen2.5-32B 微调的 ASR 模型,准确率高,支持热词 | HuggingFace |
| Qwen-ASR | 阿里通义千问语音识别模型,准确率高 | ModelScope |
| ChatGLM-ASR | 智谱 GLM 语音识别模型,支持多语言 | ModelScope |
Fun-ASR-Nano-2512 特点:
- 基于 Qwen2.5-32B 微调,识别准确率更高
- 支持热词功能,效果优于 FunASR 小模型
- 适合对识别质量有较高要求的场景
七、常见问题
Q1: VAD 和 batch_size 的关系?
有 VAD 模型时,batch_size 必须为 1。VAD 模型不支持批量处理。
Q2: 为什么热词不生效?
检查是否使用了热词优化版模型 speech_seaco_paraformer_large。
Q3: Paraformer 输出有空格怎么办?
后处理去掉空格即可:
python
text = res[0]["text"].replace(" ", "")Q4: Base64 音频如何识别?
先解码为字节流:
python
audio_bytes = base64.b64decode(base64_str)
res = model.generate(input=audio_bytes)参考资料
博客为个人学习笔记,如有错误,请指正修改。