目录
- 准备工作:环境与基础代码
- [🎀1. 矩阵乘C语言实现(基础版本)](#🎀1. 矩阵乘C语言实现(基础版本))
- [🎀2. 1x4 循环展开](#🎀2. 1x4 循环展开)
- [🎀3. 1x4展开 + 寄存器优化](#🎀3. 1x4展开 + 寄存器优化)
- [🎀4. 4x4 版本](#🎀4. 4x4 版本)
- [🎀5. 4x4 展开 + 寄存器优化](#🎀5. 4x4 展开 + 寄存器优化)
- [🎀6. Cache优化(仿存优化)](#🎀6. Cache优化(仿存优化))
- [🎀7. 矩阵分块后加速](#🎀7. 矩阵分块后加速)
- 主函数
- 性能
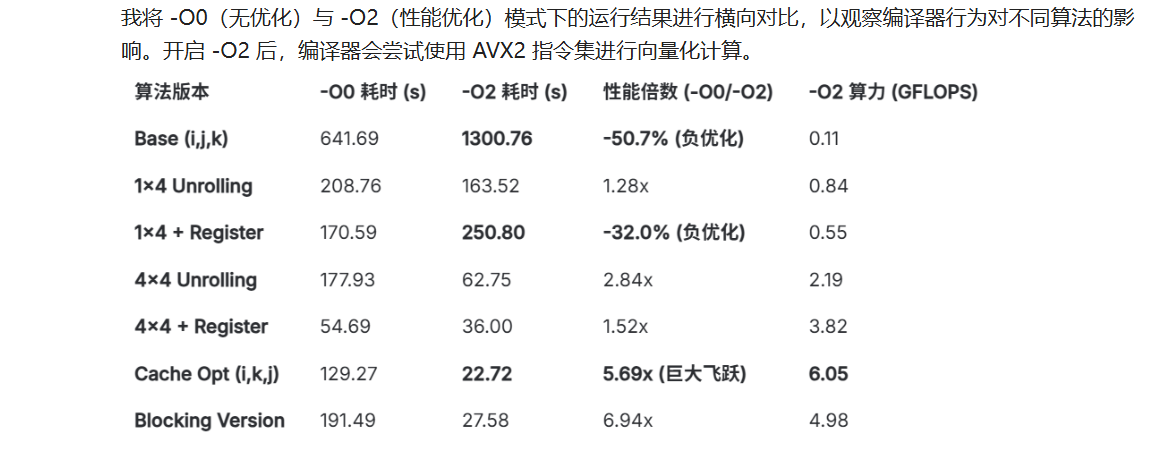
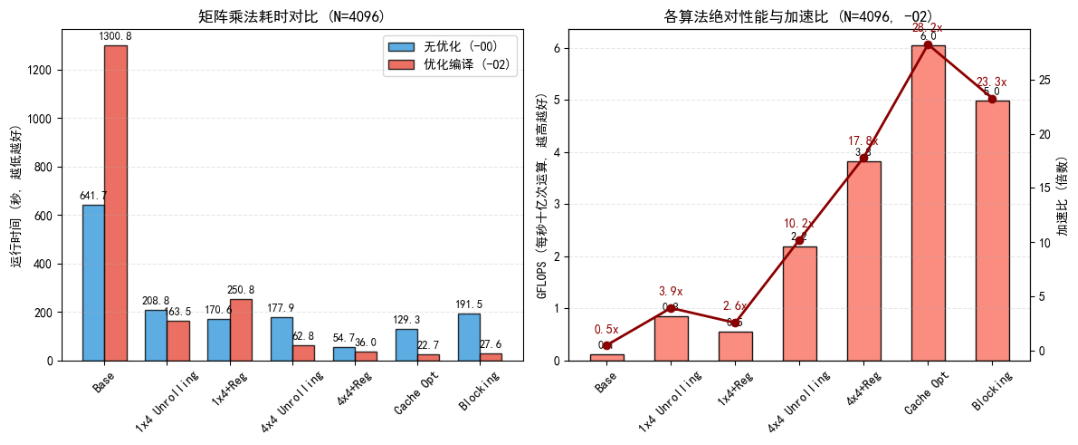
本实验的核心为通过减少访存延迟 (利用Cache局部性)和提高计算效率(循环展开、寄存器使用)来优化CPU上的矩阵乘法。
准备工作:环境与基础代码
考虑到跨平台兼容性,我写了 if 判断.
#ifdef _WIN32:意思是"如果当前是在 Windows 系统下编译"。
#else:意思是"否则(比如在 Linux 或 Mac 下)"。
#endif:意思是"判断结束"。
为了准确测量性能,我们需要一个计时函数和矩阵初始化函数。
核心点:
- 使用gettimeofday 测量微秒级时间(linux)。
- 矩阵4096*4096很大(约64MB),建议在堆(heap)上动态分配内存。
- 初始化范围要求在50-200之间。
c
#include <stdio.h>
#include <stdlib.h>
#ifdef _WIN32
#include <windows.h>
#else
#include <sys/time.h>
#endif
// 因为 4096 的基础版本跑起来非常慢(可能要好几分钟)
// 先用小数据(如512)测试,成功后再改成4060
#define N 4096
// 获取当前时间
double get_time(){
#ifdef _WIN32
LARGE_INTEGER frequency, counter;
QueryPerformanceFrequency(&frequency); //获取CPU频率
QueryPerformanceCounter(&counter); //获取当前计数
return (double)counter.QuadPart / frequency.QuadPart; //算出秒数
#else
struct timeval tv;
gettimeofday(&tv, NULL);
return tv.tv_sec + tv.tv_usec * 1e-6;
#endif
}
// 初始化随机矩阵
void init_matrix(float *mat,int size){
for(int i=0;i<size*size;i++){
mat[i] = 50.0f + (float)rand()/(float) (RAND_MAX / 150.0f);
}
}
// 每次换算法前,必须把结果矩阵 C 清零
void clear_matrix(float *mat) {
memset(mat, 0, sizeof(float) * N * N);
}🎀1. 矩阵乘C语言实现(基础版本)
最原始的 i,j,k 三层嵌套循环。这是性能评估的基准。
c
void gemm_base(float *a, float *b, float *c) {
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
float sum = 0;
for (int k = 0; k < N; k++) {
sum += a[i * N + k] * b[k * N + j];
}
c[i * N + j] = sum;
}
}
}🎀2. 1x4 循环展开
减少内层循环的次数,每次计算 C 的一行中的 4 个元素。这有助于减少循环开销,并给编译器更多指令并行的空间。
c
void gemm_1x4(float *a, float *b, float *c) {
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j += 4) { // 步长变为4
for (int k = 0; k < N; k++) {
c[i * N + j + 0] += a[i * N + k] * b[k * N + j + 0];
c[i * N + j + 1] += a[i * N + k] * b[k * N + j + 1];
c[i * N + j + 2] += a[i * N + k] * b[k * N + j + 2];
c[i * N + j + 3] += a[i * N + k] * b[k * N + j + 3];
}
}
}
}🎀3. 1x4展开 + 寄存器优化
频繁访问内存(ci*N+j)很慢。我们将中间结果存入寄存器变量(register关键字),计算完后再写回内存。同时提前读取 ai*N+k,避免重复加载。
c
void gemm_1x4_reg(float *a, float *b, float *c) {
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j += 4) {
register float c0=0, c1=0, c2=0, c3=0; // 使用寄存器
for (int k = 0; k < N; k++) {
register float aik = a[i * N + k]; // 提前取值
c0 += aik * b[k * N + j + 0];
c1 += aik * b[k * N + j + 1];
c2 += aik * b[k * N + j + 2];
c3 += aik * b[k * N + j + 3];
}
c[i * N + j + 0] = c0;
c[i * N + j + 1] = c1;
c[i * N + j + 2] = c2;
c[i * N + j + 3] = c3;
}
}
}🎀4. 4x4 版本
同时展开 i 和 j 两层循环,但依然直接操作内存。
c
void gemm_4x4(float *a, float *b, float *c) {
for (int i = 0; i < N; i += 4) {
for (int j = 0; j < N; j += 4) {
for (int k = 0; k < N; k++) {
// 第一行
c[(i+0)*N+j+0] += a[(i+0)*N+k] * b[k*N+j+0];
c[(i+0)*N+j+1] += a[(i+0)*N+k] * b[k*N+j+1];
c[(i+0)*N+j+2] += a[(i+0)*N+k] * b[k*N+j+2];
c[(i+0)*N+j+3] += a[(i+0)*N+k] * b[k*N+j+3];
// --- 第 2 行 (i+1) ---
c[(i + 1) * N + (j + 0)] += a[(i + 1) * N + k] * b[k * N + (j + 0)];
c[(i + 1) * N + (j + 1)] += a[(i + 1) * N + k] * b[k * N + (j + 1)];
c[(i + 1) * N + (j + 2)] += a[(i + 1) * N + k] * b[k * N + (j + 2)];
c[(i + 1) * N + (j + 3)] += a[(i + 1) * N + k] * b[k * N + (j + 3)];
// --- 第 3 行 (i+2) ---
c[(i + 2) * N + (j + 0)] += a[(i + 2) * N + k] * b[k * N + (j + 0)];
c[(i + 2) * N + (j + 1)] += a[(i + 2) * N + k] * b[k * N + (j + 1)];
c[(i + 2) * N + (j + 2)] += a[(i + 2) * N + k] * b[k * N + (j + 2)];
c[(i + 2) * N + (j + 3)] += a[(i + 2) * N + k] * b[k * N + (j + 3)];
// --- 第 4 行 (i+3) ---
c[(i + 3) * N + (j + 0)] += a[(i + 3) * N + k] * b[k * N + (j + 0)];
c[(i + 3) * N + (j + 1)] += a[(i + 3) * N + k] * b[k * N + (j + 1)];
c[(i + 3) * N + (j + 2)] += a[(i + 3) * N + k] * b[k * N + (j + 2)];
c[(i + 3) * N + (j + 3)] += a[(i + 3) * N + k] * b[k * N + (j + 3)];
}
}
}
}
}🎀5. 4x4 展开 + 寄存器优化
同时计算一个 4×4 的小块。这种方法能最大限度复用寄存器中的数据(一行 A 和 一列 B 的数据可以被多次使用)。
c
void gemm_4x4_reg(float *a, float *b, float *c) {
for (int i = 0; i < N; i += 4) {
for (int j = 0; j < N; j += 4) {
// 定义16个寄存器变量存储 4x4 块的结果
register float c00=0, c01=0, c02=0, c03=0,
c10=0, c11=0, c12=0, c13=0,
c20=0, c21=0, c22=0, c23=0,
c30=0, c31=0, c32=0, c33=0;
for (int k = 0; k < N; k++) {
// 加载 A 的一列,加载 B 的一行
float a0 = a[(i+0)*N+k], a1 = a[(i+1)*N+k], a2 = a[(i+2)*N+k], a3 = a[(i+3)*N+k];
float b0 = b[k*N+j+0], b1 = b[k*N+j+1], b2 = b[k*N+j+2], b3 = b[k*N+j+3];
// 累加
c00 += a0*b0; c01 += a0*b1; c02 += a0*b2; c03 += a0*b3;
c10 += a1*b0; c11 += a1*b1; c12 += a1*b2; c13 += a1*b3;
c20 += a2*b0; c21 += a2*b1; c22 += a2*b2; c23 += a2*b3;
c30 += a3*b0; c31 += a3*b1; c32 += a3*b2; c33 += a3*b3;
}
// --- 计算结束,将 16 个寄存器的结果写回到矩阵 C ---
// 第 i 行
c[(i + 0) * N + (j + 0)] = c00;
c[(i + 0) * N + (j + 1)] = c01;
c[(i + 0) * N + (j + 2)] = c02;
c[(i + 0) * N + (j + 3)] = c03;
// 第 i + 1 行
c[(i + 1) * N + (j + 0)] = c10;
c[(i + 1) * N + (j + 1)] = c11;
c[(i + 1) * N + (j + 2)] = c12;
c[(i + 1) * N + (j + 3)] = c13;
// 第 i + 2 行
c[(i + 2) * N + (j + 0)] = c20;
c[(i + 2) * N + (j + 1)] = c21;
c[(i + 2) * N + (j + 2)] = c22;
c[(i + 2) * N + (j + 3)] = c23;
// 第 i + 3 行
c[(i + 3) * N + (j + 0)] = c30;
c[(i + 3) * N + (j + 1)] = c31;
c[(i + 3) * N + (j + 2)] = c32;
c[(i + 3) * N + (j + 3)] = c33;
}
}
}🎀6. Cache优化(仿存优化)
核心点: 这是最关键的一步。C语言矩阵是"行主序"存储。
- 原本的 (i,j,k) 顺序中,访问 bk\*N+j 时,k 变化会导致在内存中跳跃非常大(跳过一整行),这会引起大量 Cache Miss。
- 将循环顺序改为 (i,k,j),此时内层循环 j 增加,b 和 c 都是连续访问内存的,极大利用了 Cache。
c
void gemm_cache(float *a, float *b, float *c) {
for (int i = 0; i < N; i++) {
for (int k = 0; k < N; k++) { // 交换 k 和 j
float r = a[i * N + k];
for (int j = 0; j < N; j++) {
c[i * N + j] += r * b[k * N + j];
}
}
}
}🎀7. 矩阵分块后加速
将大矩阵拆成小的 Block(如 64*64),确保小块能完全塞进 L2/L3 Cache。这是 6 层循环。
c
void gemm_blocking(float *a, float *b, float *c) {
int block_size = 64; // 分块大小,可以尝试 32, 64 或 128
for (int bi = 0; bi < N; bi += block_size) {
for (int bk = 0; bk < N; bk += block_size) {
for (int bj = 0; bj < N; bj += block_size) {
// 内部的小矩阵乘法
for (int i = bi; i < bi + block_size; i++) {
for (int k = bk; k < bk + block_size; k++) {
register float r = a[i * N + k];
for (int j = bj; j < bj + block_size; j++) {
c[i * N + j] += r * b[k * N + j];
}
}
}
}
}
}
}主函数
c
int main() {
// 1. 分配内存 (注意:4096*4096 很大,必须用 malloc)
float *A = (float *)malloc(sizeof(float) * N * N);
float *B = (float *)malloc(sizeof(float) * N * N);
float *C = (float *)malloc(sizeof(float) * N * N);
if (A == NULL || B == NULL || C == NULL) {
printf("内存分配失败!\n");
return -1;
}
// 2. 初始化数据
printf("正在初始化 %dx%d 矩阵...\n", N, N);
init_matrix(A,N);
init_matrix(B, N);
double start, end, duration;
// --- 测试 1: Base 版本 ---
printf("开始测试: Base Version... ");
clear_matrix(C);
start = get_time();
gemm_base(A, B, C); // 调用你之前写的函数名
end = get_time();
duration = end - start;
printf("耗时: %.4f 秒\n", duration);
// --- 测试 2: 1*4 版本 ---
printf("开始测试: 1*4 Version... ");
clear_matrix(C);
start = get_time();
gemm_1x4(A, B, C);
end = get_time();
duration = end - start;
printf("耗时: %.4f 秒\n", duration);
// --- 测试 3: 1*4 + 寄存器优化版本 ---
printf("开始测试: 1*4 + 寄存器优化 Version... ");
clear_matrix(C);
start = get_time();
gemm_1x4(A, B, C);
end = get_time();
duration = end - start;
printf("耗时: %.4f 秒\n", duration);
// --- 测试 4: 4*4 版本 ---
printf("开始测试: 4*4 Version... ");
clear_matrix(C);
start = get_time();
gemm_4x4(A, B, C);
end = get_time();
duration = end - start;
printf("耗时: %.4f 秒\n", duration);
// --- 测试 5: 4*4 + 寄存器优化版本 ---
printf("开始测试: 4*4 + 寄存器优化 Version... ");
clear_matrix(C);
start = get_time();
gemm_4x4_reg(A, B, C);
end = get_time();
duration = end - start;
printf("耗时: %.4f 秒\n", duration);
// --- 测试 6: Cache 优化版本 (重点) ---
printf("开始测试: Cache Optimized... ");
clear_matrix(C);
start = get_time();
gemm_cache(A, B, C);
end = get_time();
duration = end - start;
printf("耗时: %.4f 秒\n", duration);
// --- 测试 7: 矩阵分块 版本 ---
printf("开始测试: 矩阵分块 Version... ");
clear_matrix(C);
start = get_time();
gemm_blocking(A, B, C);
end = get_time();
duration = end - start;
printf("耗时: %.4f 秒\n", duration);
// 释放内存
free(A); free(B); free(C);
printf("\n实验结束。\n");
return 0;
}性能