目录
一句话概括
MixLinear是ICLR 2026 提出的面向极低资源场景 的多元长时序预测(LTSF)模型,仅含0.1K参数 ,创新采用时域分段趋势提取+频域自适应低秩谱滤波 双路径架构,将时序建模复杂度从O(n²)降至O(n) ;在8个标准基准数据集 上,实现与Transformer/线性SOTA模型相当的预测精度,达成最高16.2% MSE优化 、3.2倍推理加速 、81%参数量缩减,可高效部署于嵌入式、边缘传感器等算力受限设备。
不足之处:
对比方法较都是2024年以前,没有与最先进方法进行对比。
创新方法一般,感觉是以前方法的组合。
论文:MIXLINEAR: EXTREME LOW RESOURCE MULTIVARIATE TIME SERIES FORECASTING WITH \(0.1 K\) PARAME
作者:Aitian Ma, Dongsheng Luo, Mo Sha∗
单位:Knight Foundation School of Computing and Information Sciences Florida International University
代码:请各位同学给我点赞,激励我创作更好、更多、更优质的内容!^_^
更多资讯** 关注微信公众号:"时序前沿研究"**
添加** 小助手微信Aniose,加入时序交流群** 。
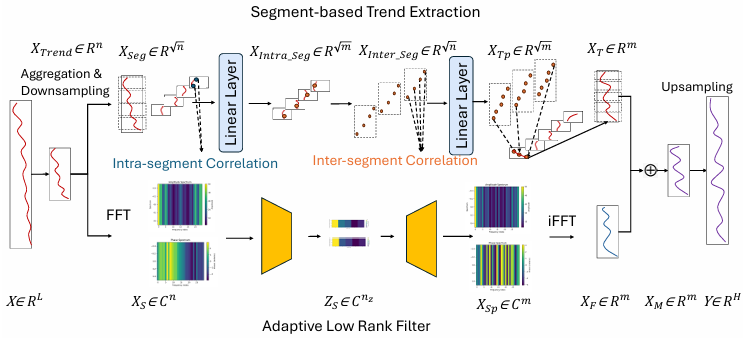
图1:MixLinear 架构概述。我们的双路径框架可高效处理时间序列数据。基于分段的路径(上方)将输入 X ∈ R L X \in \mathbb{R}^{L} X∈RL下采样为分段 X s e g ∈ R L / π X_{seg } \in \mathbb{R}^{L / \pi} Xseg∈RL/π,对分段内(蓝色)和分段间(橙色)的相关性进行线性变换,然后上采样至 X T ∈ R H X_{T} \in \mathbb{R}^{H} XT∈RH。频域路径(下方)通过快速傅里叶变换( ( X S ∈ C L / π ) (X_{S} \in \mathbb{C}^{L / \pi}) (XS∈CL/π))对分段进行变换,通过自适应低秩滤波将趋势压缩至潜在空间 Z S ∈ C n x Z_{S} \in \mathbb{C}^{n_{x}} ZS∈Cnx,通过逆快速傅里叶变换完成重构,并输出 X F ∈ R H X_{F} \in \mathbb{R}^{H} XF∈RH。最终预测结果 Y ∈ R H Y \in \mathbb{R}^{H} Y∈RH 结合了两路输出,仅用 0.1K 个参数就实现了具有竞争力的预测效果。
二、详细总结
1. 研究背景与动机
- 长时序预测(LTSF)痛点
- Transformer类模型精度优异,但参数量达百万级、计算复杂度O(L²),无法部署于边缘/嵌入式设备。
- 现有轻量模型未区分局部时域特征 与全局频域特征,采用单一架构建模导致参数冗余、效率低下。
- 核心科学洞察
- 局部时序波动适合时域分段线性建模 ,全局趋势/周期性在频域呈稀疏性,双域协同建模可实现极致效率。
2. 模型核心设计
MixLinear采用双路径加法融合 架构,总参数量仅0.1K,彻底解决参数爆炸问题。
- 时域路径:分段趋势提取
- 输入下采样→非重叠分段;
- 段内线性变换:捕捉局部斜率、短周期等细粒度特征;
- 段间线性变换:建模跨段漂移、周期相关性;
- 上采样重构,复杂度O(n)。
- 频域路径:自适应低秩谱滤波
- 下采样数据经FFT转换到频域;
- 秩约束矩阵分解(nz=2):将谱特征压缩至极低维隐空间;
- 逆FFT重构+上采样,仅需4rnz实参数,规避全滤波O(r²)复杂度。
- 复杂度分析
- 时间复杂度:O(nlogn)(由FFT操作主导);
- 空间复杂度:O(n),远优于注意力模型的O(L²)。
3. 实验验证与核心数据
(1)实验配置
- 数据集:8个LTSF标准基准(ETTh1/ETTh2/ETTm1/ETTm2、Exchange、Solar、Electricity、Traffic);
- 训练设置:回溯窗口720,预测跨度96/192/336/720,Adam优化器,学习率0.02,30轮训练;
- 硬件环境:单卡NVIDIA A100 80GB,基于PyTorch实现。
(2)核心性能对比
| 对比维度 | MixLinear | SparseTSF | FITS | 核心优势 |
|---|---|---|---|---|
| 参数量 | 0.1K | 1K | 10K | 较SparseTSF减81%,较FITS减94%-98% |
| 精度提升 | 最高+16.2% MSE | 基线 | - | Exchange数据集最优 |
| 推理加速 | 最高3.2× | 1× | 1.72× | 低维场景(Exchange)优势显著 |
| 计算量(MACs) | 196.56K(ETTh1-720) | 277.20K | 292.32K | 降低41.32%-48.98% |
(3)消融实验结论
- 双路径必要性 :完整MixLinear的MSE显著低于仅时域/仅频域单路径模型,双域特征互补;
- 超参鲁棒性 :分段长度4-8、谱秩nz=2 、下采样因子π=24为最优配置,性能波动<3%;
- 复杂度有效性:低秩滤波与分段分解切实降低计算量,且无明显精度损失。
4. 核心贡献
- 提出时域分段线性分解方法,将时序建模复杂度从O(n²)降至O(n);
- 创新频域自适应低秩谱滤波,实现全局趋势的极致压缩与高效建模;
- 构建双域融合架构,在0.1K极轻参下达成SOTA级长时序预测精度。
5. 应用与拓展
- 落地场景:边缘传感器、嵌入式设备等算力/存储严格受限的终端;
- 行业方向:洪水检测、环境健康监测、交通管控等实时长时序预测任务;
- 模型拓展:设计思路可用于高效大模型、基础模型的轻量化研发。
四、关键问题与答案
问题1:MixLinear实现0.1K极轻参数与高效计算的核心原理是什么?
答案 :核心是双域分离建模+低秩分解 :①时域采用分段线性分解 ,分离段内局部特征与段间全局关联,将复杂度从O(n²)降至O(n);②频域采用秩约束谱滤波(nz=2) ,把全局谱特征压缩至极低维隐空间,仅需极少参数;双路径采用加法融合,无参数爆炸,最终仅0.1K参数,时间复杂度优化为O(nlogn)。
问题2:MixLinear在预测精度 与推理效率上,相比主流轻量基线的核心优势有哪些?
答案 :精度层面,在8个基准数据集上实现最高16.2% MSE提升 (Exchange数据集),ETTh1/ETTh2等数据集也有3%-5%的精度优化,优于SparseTSF、FITS等轻量模型;效率层面,低维场景推理最高加速3.2倍 ,高维场景最高加速2.58倍,计算量(MACs)最高降低48.98%,参数量较SparseTSF缩减81%、较FITS缩减94%-98%,完美适配资源受限设备。
问题3:MixLinear的消融实验验证了哪些关键设计的有效性?
答案 :①双路径互补性 :仅保留时域/频域单路径的模型,MSE均显著高于完整MixLinear,证明时频双域建模缺一不可;②超参最优性 :谱秩设为2、分段长度4-8、下采样因子24时,精度与效率平衡最优,且模型对超参不敏感;③架构高效性:分段线性分解与低秩谱滤波,切实降低了计算量与参数量,同时保证预测精度。