做电力负荷预测的时候,经常会陷入一种很努力但不踏实的状态:模型写了好几版、特征也堆了不少,指标看着也不错,但心里总会犯嘀咕------这个提升到底是模型真强,还是评估或者baseline给了错觉?
最近重看了 Bergmeir 的 NeurIPS 2024 邀请报告,他讲 forecasting foundation models,但核心信息其实特别接地气:别被 benchmark 指标带跑偏,先把评估做对、基线补强、把泄漏控制住。
1)先别跑模型:得先把"在预测什么"说清楚
先说句大实话:电力负荷预测不是一种任务,是一类任务。不把设定写清楚,后面所有对比都容易被质疑。
建议一开始就把下面几件事写死,最好写进实验设置表格里:
- 粒度:15min / 30min / 1h / 1day
- 预测类型:短期(小时到天)/ 中期(周)/ 长期(月)
- 预测方式:点预测还是分位数预测(P10/P50/P90)
- 预测步长:典型是 day-ahead 24h(或 48 step 的 30min)
有些长序列预测设得特别激进,看起来像在做科研突破,但在电力场景里,两三周后的负荷靠历史本身很难推,更多靠天气、节假日、事件。NeurIPS 报告里对超长 horizon 的质疑逻辑,在电力负荷这里同样成立。
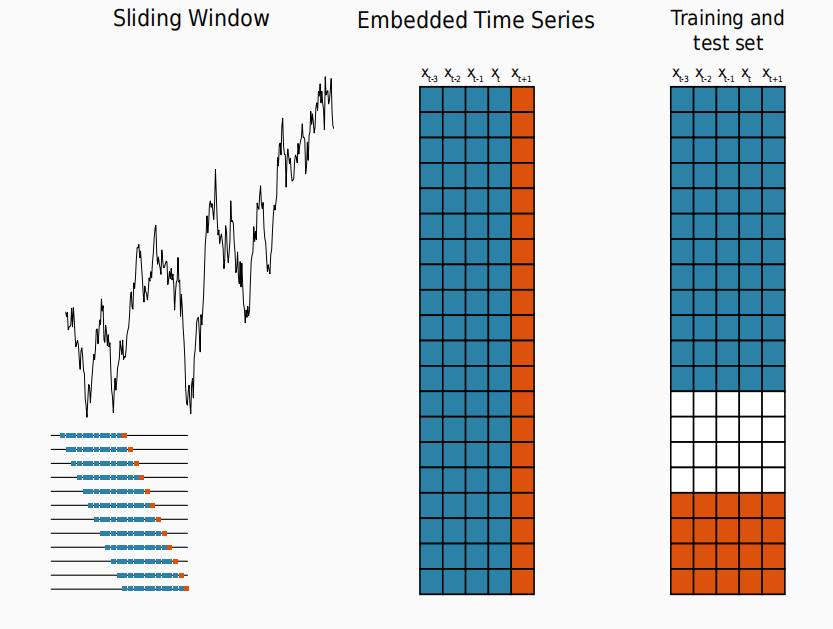
2)跑实验前先做数据体检:电力负荷最常见的坑不是噪声,是"时间轴"
电力负荷数据常见问题包括:
- DST(夏令时)导致 23/25 小时
- 采集系统导致不等间隔
- 停电/表计故障造成缺失段
- 设备更换/用户迁移导致结构突变
NeurIPS 报告里有个很典型的例子:汇率数据集样本数和声称的时间跨度对不上,怀疑去掉了非交易日,直接影响自相关结构与评估可靠性。电力数据也一样,时间轴一旦有"被动过手脚"的地方,后面讲再多模型都容易站不住。
3)评估协议:电力负荷强烈建议 rolling-origin,不然很容易刚好切到好预测的那段
说完数据,进入最关键的地方:评估协议。 电力负荷有强季节性,也有概念漂移;单次 train/test split 很容易"碰巧切到容易的那段",结论不稳。最佳实践里非常推荐 rolling-origin,用多个 out-of-sample 段来验证结论。
- 训练窗口:最近 6--12 个月(看数据量)
- 测试窗口:1 周或 1 个月
- 滚动步长:按 1 周或 1 个月滚
- 任务:day-ahead 24h(或 48 step)
另外,如果是多序列(很多用户/变压器),建议统一用同一套 calendar 切分(所有序列同一组滚动起点),这样 global model 和 local model 才公平。

4)Baseline怎么选
模型到底该跟谁比,作者的建议是:电力负荷别只放一个 naive 糊弄,要把基线按层次补齐,不然赢了也很难说明赢在哪里。
A)Seasonal Naive
- naive:(y^t+h=yt)(\hat{y}_{t+h}=y_t)(y^t+h=yt)
- seasonal naive:
- 小时级:用"昨天同一小时"或"上周同一小时"
- 形式就是(y^t+h=yt+h−s) (\hat{y}{t+h}=y{t+h-s}) (y^t+h=yt+h−s),s=24 或 168
复杂模型不一定比常识强,naive 是下限,不是装饰。
B)带季节的统计模型
报告里喷得很狠的一点是:有些 benchmark 的统计基线根本没建模季节性,属于基线错设,赢了也不说明问题。电力负荷这里同理:不带季节项的 ARIMA 不能算强基线。
可以选择:
- ETS(带日/周季节)
- SARIMA / SARIMAX
- 或者 Fourier 项回归 + ARIMA error(报告里类似思路在强周期数据上很能打)
C)日历 + 天气 的线性/GAM/XGB
电力负荷的可预测性很大一部分来自外生信息(温度、节假日)。所以作者强烈建议至少加一个"天气+日历回归"的基线:hour、dow、holiday、month + temperature(可加湿度/体感温度),模型用线性/GAM/XGB 都行。这一层基线非常关键:它能帮你把深度模型提升到底来自哪里讲清楚。
5)指标怎么选:电力负荷场景,MAPE 真的是高发事故
电力负荷的数据特性决定MAPE经常不靠谱。电力负荷常见:
- 夜间低谷接近 0(用户级更明显)
- 节假日负荷下降,百分比误差夸张
- 不同用户规模差异大,直接平均会被大用户支配
最佳实践论文对 MAPE 的问题讲得很系统:低值/含 0 时会失真甚至不可用。
作者建议给一个"够用且好解释"的组合:
- 主指标:MAE(或者 RMSE)
- 补充 1:MASE 或 sMAPE(相对尺度更稳)
- 补充 2(可选):峰时段加权 MAE(如果业务更关心晚高峰)
6)泄漏(leakage)排查:电力预测里最容易漏的是"天气"和"归一化"
真正容易不小心翻车的是泄漏。电力负荷里最常见两类:
6.1 天气特征:用的是"真实未来温度"还是"预报温度"?
这两种设置差别非常大:
- 现实设置(更严格):day-ahead 只能用天气预报
- 学术设置(更宽松):直接用真实未来温度
可以用真实温度做上限实验,但一定要写清楚假设,不然很容易被认为用了未来信息。
6.2 标准化/分解/特征提取:只能在训练窗 fit
rolling-origin 下,所有 scaling 都要:
- 只在训练窗 fit
- apply 到测试窗
- 每滚一次都重新 fit
- 这是最佳实践里反复强调的核心坑。
7)如果用 foundation model / global model:别只看"平均赢了"
NeurIPS 报告后半段讲得很克制:它们在一些大 benchmark 上平均表现很好,但平均变好不等于的某条序列就变好,这和 global model 的 shrinkage/正则化效应有关。落到电力负荷上,这句话尤其重要:大用户/工业用户规律强,小用户噪声大,平均指标可能掩盖子群体差异。所以作者建议:
- 按用户规模/波动程度分组汇报
- 按 horizon(1h...24h)分开汇报
8)总结
Protocol
- rolling-origin:训练 12 个月 → 测试 1 个月 → 滚动 12 次
- 任务:day-ahead 24h(或 48 step)
- 特征:日历(hour/dow/holiday)+ 温度(设置写清楚:真实 or 预报)
Baselines(按优先级)
- seasonal naive(s=24/168)
- ETS/SARIMA(带季节)
- 日历+天气回归(线性/GAM/XGB)
- 你的 DL / foundation 方法
Metrics
- MAE(主)+ MASE/sMAPE(补充)+ 峰时段加权 MAE(可选)
Reporting
- 按 horizon 报(1--24h)
- 按规模/波动分组报
- 写清楚 leakage 控制与天气信息假设
电力场景最典型的 context 就是:天气、节假日、重大事件、电价/需求响应信号。模型结构可能年年变,但你把上下文用得是否合理、是否泄漏、是否在 OOS 下成立"讲清楚,结论就稳。
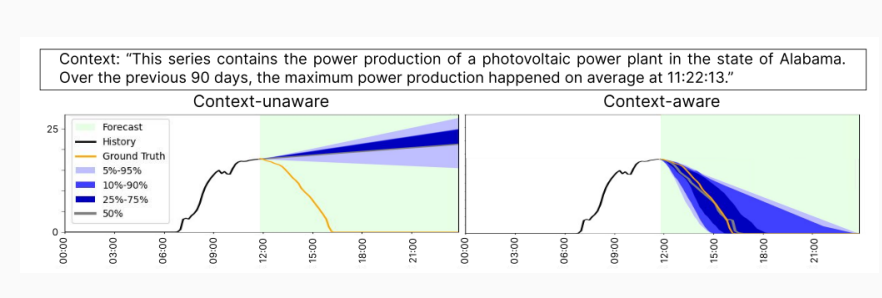
9)相关链接
官网链接:https://cbergmeir.com/talks/neurips2024/
https://cbergmeir.com/talks/acml-tutorial/
Youtube讲解:youtube.com/watch?v=vNul_AjRPFw&embeds_referring_euri=https%3A%2F%2Fcbergmeir.com%2F&source_ve_path=Mjg2NjY
PDF下载:https://cbergmeir.com/talks/bergmeir2024NeurIPSInvTalk.pdf
https://cbergmeir.com/talks/acml-tutorial/
2Fcbergmeir.com%2F&source_ve_path=Mjg2NjY
PDF下载:https://cbergmeir.com/talks/bergmeir2024NeurIPSInvTalk.pdf