1. 项目背景
本节我们将在上节构建的数据窗口的基础上,尝试使用基本的深度神经网络算法进行测试,预测未来24h的家庭用电量。整个过程包括:
1.数据准备
1)查看数据,计算缺失值数量
2)估算缺失值
3)数值类型转换
4)构建DataTime对象
5)按小时数据重采样
6)去掉不完整的小时数
2.特征工程
1)识别季节性
2)时间编码
3)缩放数据
3.划分数据
按7:2:1划分数据集
4.为深度学习建模做准备
1)实现DataWindow类
2)定义compile_and_fit函数
3)创建列索引和列名字典
5.深度学习模型
- 训练基线模型
2)训练DNN模型
3)训练LSTM模型
4)训练CNN模型
5)训练LSTM+CNN模型
6)训练自回归LSTM模型
7)模型性能对比选择
本项目的源代码在闲鱼上,感兴趣可以看看:
闲鱼 https://m.tb.cn/h.7A4LlmB?tk=NmqjUpGmNYM CZ356(https://m.tb.cn/h.7A4LlmB?tk=NmqjUpGmNYM CZ356 )
2. 数据准备
2.1 数据集介绍
该数据集是某家庭47个月的用电量,每分钟采集一次,总数据量超过200w点。数量集总共有9列,分别是:date(日期),time(时间),active_power(预测目标,有功功率),reactive_power(无功功率), voltage(电压), intensity(电流),metering_1(厨房区域有功功率),metering_2(洗衣房区域有功功率), metering_3(其他有功功率)。
2.2 数据处理
- 处理缺失值
通过此步骤处理缺失值和错误值,并将字符串变为数值类型,保证数据集的高质量和预测精度。
python
# 保证每次运行的结果可以重现, 设置一个随机种子。 为什么是42?可以网上搜索有趣的故事
tf.random.set_seed(42)
np.random.seed(42)
df = pd.read_csv('../data/household_power_consumption.txt', sep=';')
df.head()
df.shape
# 检查缺失值
df.isna().sum()返回结果展示sub_metering_3有25979个缺失值,需要进行处理。处理时有很多方法,常见的是缺失值填充和删除整列。 如果缺失值不集中,随机分布在数据中,则可以进行填充。如果缺失值集中,量大,而且没有明显的规律或算法来填充,则最好删除整个特征。
python
#检查是否存在大量连续集中的缺失值
na_groups = df['Sub_metering_3'].notna().cumsum()[df['Sub_metering_3'].isna()]
len_consecutive_na = na_groups.groupby(na_groups).agg(len)
longest_na_gap = len_consecutive_na.max()
longest_na_gap返回结果展示有7226分钟的连续缺失,无法进行填补,所有删除该行。
python
df = df.drop(['Sub_metering_3'], axis=1)- 类型转换
检查数据类型,如果是非数值类型,则需要转换后给到模型进行计算。
python
df.dtypes
#返回类型展示,所有数据都是object类型,需进行转换
#保留date,time列,后面再进行DataTime对象转换
cols_to_convert = df.columns[2:]
df[cols_to_convert] = df[cols_to_convert].apply(pd.to_numeric, errors='coerce')
df.dtypes
#所有数据都是float64类型了- 数据重采样
数据集是分钟级别的,但我们预测目标是小时预测,所以需要按小时重采样。
这个过程包括构建datatime列,按小时重采样,去除不够1小时的数据列。
python
# 创建datatime列
df.loc[:,'datetime'] = pd.to_datetime(df.Date.astype(str) + ' ' + df.Time.astype(str))
# 删除date和time列
df = df.drop(['Date', 'Time'], axis=1)
df.head()
# 按小时重采样
hourly_df = df.resample('H', on='datetime').sum()
hourly_df.head()
# 检查第一个小时和最后一个小时的数据。这两行都不满1小时,所以去掉。
# 刚刚中间去掉数据的部分,也应该进行类似处理,保证数据都是满1小时的数据。
hourly_df = hourly_df.drop(hourly_df.tail(1).index)
hourly_df = hourly_df.drop(hourly_df.head(1).index)
# 可以建立新索引,以整数为索引,将datetime变为普通的列
hourly_df = hourly_df.reset_index()绘制曲线查看,发现可能存在天级别的周期性规律,留在后面处理。
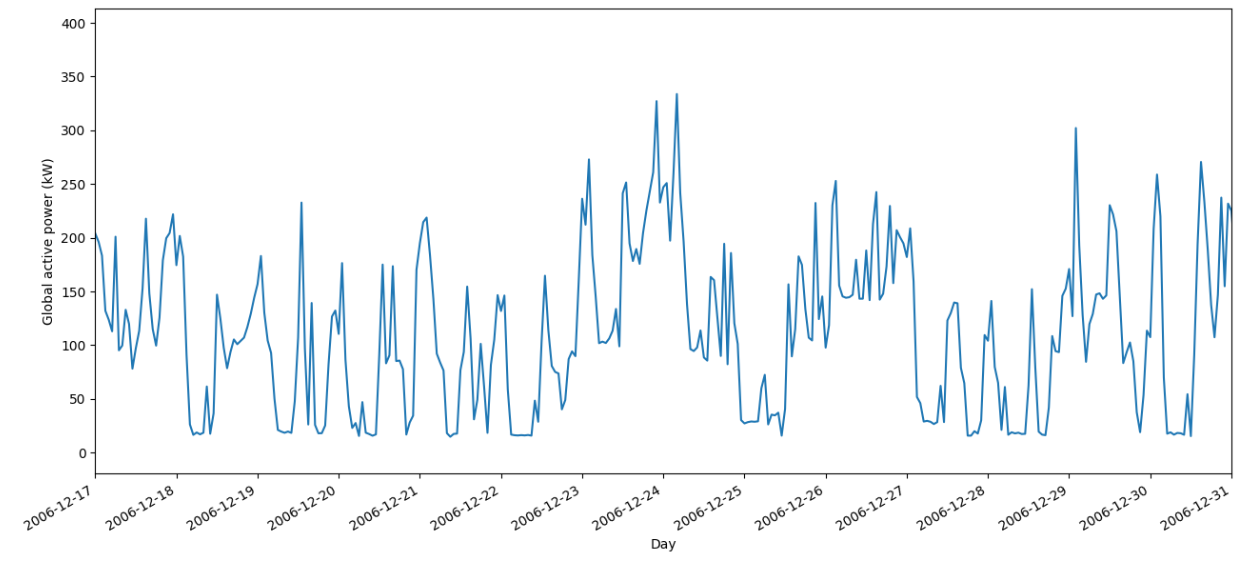
处理完成后,可以保存成干净的数据进行接下来的处理。
3. 特征工程
3.1 查看统计数据,删除无用列
第一步展示每列的基本统计信息,然后查看哪些特征大概率不会对预测结果产生影响。
python
hourly_df.describe().transpose()结果如下:
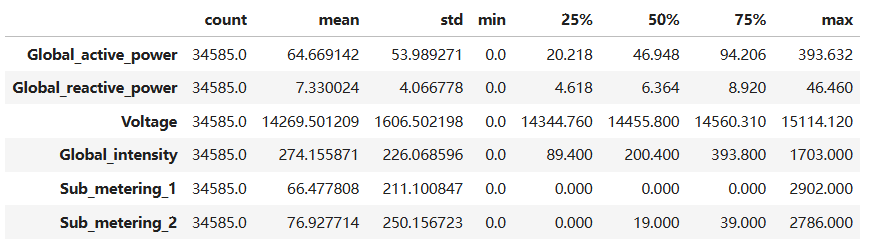
从中看到,sub_metering_1数据在75%的时间内都是0,没有任何变化趋势,可能不会对结果产生影响,因此可以去掉。(如果数据量庞大,特征非常多,则推荐去掉)
python
hourly_df = hourly_df.drop(['Sub_metering_1'], axis=1)
hourly_df.head()3.2 确定季节性周期
根据曲线很难确定周期性规律,需要通过傅里叶变换找到数据中真实的季节性规律。
python
#对目标列进行傅里叶变换
fft = tf.signal.rfft(hourly_df['Global_active_power'])
#获取频率数量
f_per_dataset = np.arange(0, len(fft))
#数据集有多少小时
n_sample_h = len(hourly_df['Global_active_power'])
#数据集有多少周
hours_per_week = 24 * 7
weeks_per_dataset = n_sample_h / hours_per_week
#数据集中一周的频率
f_per_week = f_per_dataset / weeks_per_dataset
#绘制频率和振幅图
plt.step(f_per_week, np.abs(fft))
plt.xscale('log')
# 标记
plt.xticks([1, 7], ['1/week', '1/day'])
plt.xlabel('Frequency')
plt.tight_layout()
plt.show()
plt.savefig('figures/CH18_F06_peixeiro.png', dpi=300)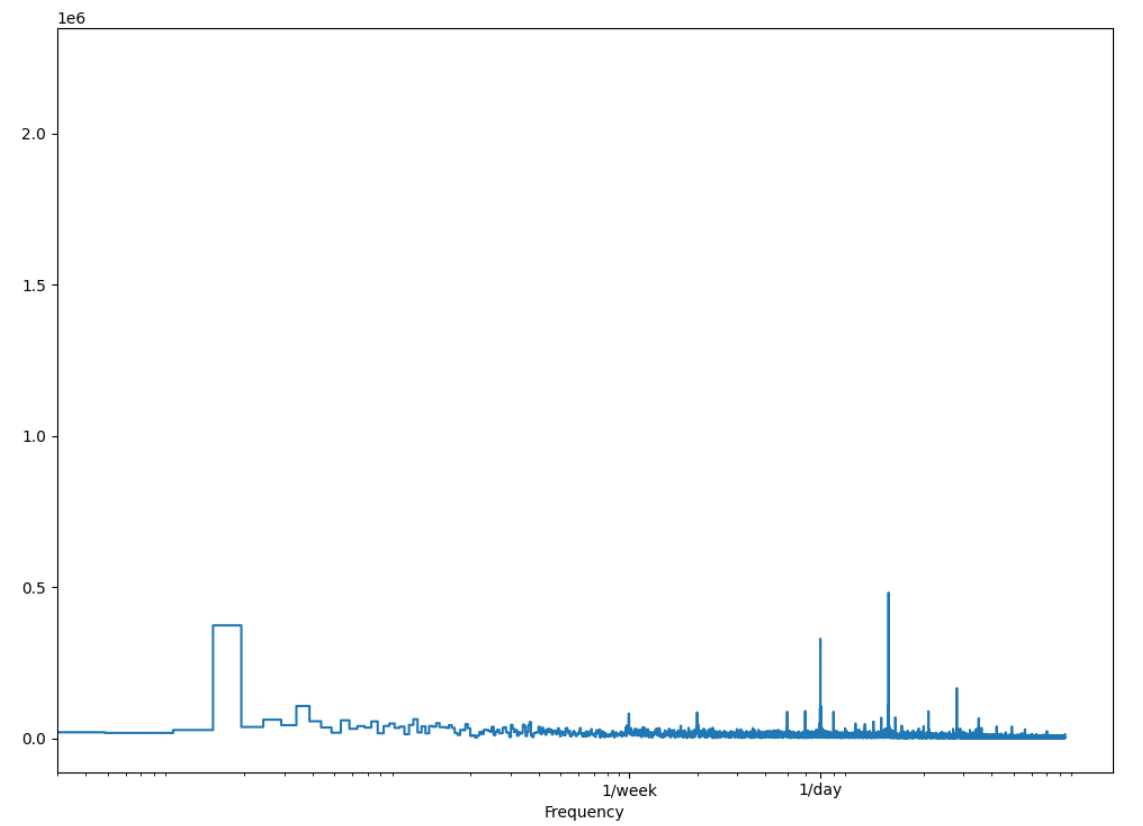
从图中可以看到,每天的季节性有个可见的峰值,但没有明显的每周的季节性。因此,我们判断用电量确实有每天的季节性。
3.3 拆分和缩放数据
将数据拆分为训练集、测试集和验证集,并进行缩放。
python
n = len(hourly_df)
# 划分70:20:10 (train:validation:test)
train_df = hourly_df[0:int(n*0.7)]
val_df = hourly_df[int(n*0.7):int(n*0.9)]
test_df = hourly_df[int(n*0.9):]
#进行缩放处理
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
# 为什么仅使用train数据进行缩放器训练? 如前几篇分析,是为了防止验证集和验证集的数据泄露。
scaler.fit(train_df)
train_df[train_df.columns] = scaler.transform(train_df[train_df.columns])
val_df[val_df.columns] = scaler.transform(val_df[val_df.columns])
test_df[test_df.columns] = scaler.transform(test_df[test_df.columns])4. 深度学习介绍
深度学习是一种以神经网络为架构,通过多层非线性变换,对数据进行学习的算法。相对于传统基于数据原理及统计学的机器学习策略,深度学习能够使用海量的数据进行学习,从而达到更高的精度。
4.1 深度学习常见概念
- 神经网络结构:用于定义数据流动路径和计算方式。子概念包括全连接层、卷积层、池化层,输入/输出层,隐藏层等。
- 前向传播:输入数据从输入层流向输出层,逐层计算得到预测值的过程。我们在使用各种AI模型推理的过程就是前向传播的过程。
- 反向传播:根据损失函数误差,从输出层反向逐层计算每个参数的梯度的过程。
- 优化器:根据反向传播计算出的梯度,更新网络权重及最小化损失函数的过程。常用的优化器包括SGD(随机梯度下降,容易不收敛), Momentum(动量优化器,加速并减少震荡),Adam(效果好,最常用)
- 激活函数:每个神经元的计算因子,用于引入非线性,控制神经元是否被激活及输出信息。常见的激活函数包括:Sigmoid(容易梯度消失,常用于二分类),Tanh(收敛速度快于sigmoid),Relu(计算高效,最常用),Softmax(输出为概率分布,用于多分类)
- 损失函数: 衡量模型预测结果与真实值之间差距的标量值。使用各种优化器的目的就是通过梯度下降,最小化这个损失函数的值。对于时间序列等回归任务,常见的有MSE(均方误差),MAE(平均绝对误差)。
- 正则化,防止模型在训练时过拟合,提高泛化能力,常见方法包括L1/L2权重正则化,Dropout和早停等
- 初始化:在训练开始前,对网络参数如权重w,偏置b等设置初始值
- 学习率:优化器更新权重的步长大小,是最终的超参数之一。
- Epoch: 整个训练集完整的通过神经网络计算并进行一次参数更新,叫做一轮。
- Batch size: 单次前向/反向传播计算中使用的样本数量。
- Iteration: 完成一轮计算所需要的批处理次数(总样本数/batch size)
- 回调函数:它是一组在训练过程中的特点时间点(如一轮开始/结束时,每个批次处理后)被自动调用的函数,用于在训练过程中植入自己的代码,而不需修改训练循环本身。常见的回调函数有:模型检查点设置ModelCheckpoint、早停设置EarlyStopping,学习率调度器LearningRateScheduler,可视化监控TensorBoard。
5. 建模前准备
在创建深度学习模型前,需要明确要导入的python库,并创建数据窗口。
5.1 python库
python
import numpy as np # 多维数据操作基础
import pandas as pd # 结构化数据处理,如dataframe,series数据结构
import tensorflow as tf
import matplotlib.pyplot as plt # 绘图库
from tensorflow.keras import Model # keras的函数式API基类,用于创建复杂模型
from tensorflow.keras import Sequential # 顺序模型类,用于创建简单的层模型
from tensorflow.keras.optimizers import Adam # 自适应学习率优化器
from tensorflow.keras.callbacks import EarlyStopping # 早停回调函数
from tensorflow.keras.losses import MeanSquaredError # 均方差,回归任务常用损失函数
from tensorflow.keras.metrics import MeanAbsoluteError # 平均绝对值误差,回归任务评估指标
# Dense, 全连接层
# Conv1D, 一维卷积层,用于序列数据处理
# Reshape, 改变输入张量的形状而不改变数据
from tensorflow.keras.layers import Dense,Conv1D,LSTM,Lambda,Reshape,RNN,LSTMCell
5.2 创建DataWindow类
无需重写,使用上篇文章中详细介绍的DataWindow类,不再做介绍。
5.3定义训练函数
我们把model.complie,model.fit函数封装到一起,同时定义早停函数。
python
# 接受一个模型,窗口函数。默认早停参数为3,即连续3个epoch周期内损失指标没有改变,则停止。 默认最大轮数为50
def compile_and_fit(model, window, patience=3, max_epochs=50):
early_stopping = EarlyStopping(monitor='val_loss',
patience=patience,
mode='min')
model.compile(loss=MeanSquaredError(),
optimizer=Adam(),
metrics=[MeanAbsoluteError()])
history = model.fit(window.train,
epochs=max_epochs,
validation_data=window.val,
callbacks=[early_stopping])
return history5.4 用到的主要tf.keras模型介绍(tensorflow 2.16.1)
**1. EarlyStopping **
早停函数,它的完整函数描述如下:
tf.keras.callbacks.EarlyStopping(
monitor='val_loss', # 被监测的量化值,默认为 val_loss
min_delta=0, # 最小变化量,小于此值认为计算没有改善
patience=0, # 没有改善的轮数,达到这个数量没有改善则停止
verbose=0, # 控制是否输出进度记录。0不记录
mode='auto',
baseline=None, # 监测量的极限值
restore_best_weights=False, #是否恢复最佳权重
start_from_epoch=0
)
2. Dense
定义全连接神经网络层。
tf.keras.layers.Dense(
units, # 全连接层单元数,输出维度
activation=None, # 激活函数,默认线性激活函数
use_bias=True, # 是否添加偏置项b. out=activation(dot(input,kernel)+bias)
kernel_initializer='glorot_uniform', #权重初始化器,决定权重矩阵(kernel,w)初始化的方法
bias_initializer='zeros', # 初始化偏置b的方法
kernel_regularizer=None, # 权重正则化器,用于对权重矩阵w施加正则化,防止过拟合
bias_regularizer=None, #偏置正则化器
activity_regularizer=None, #激活值正则化器, 用于对该层的输出(激活值)施加正则化
kernel_constraint=None, # 权重约束,在训练过程中对权重矩阵施加约束
bias_constraint=None, # 偏执约束
lora_rank=None,
**kwargs
)

3. Squential
squential是一个线性堆叠层的容器,它接受要添加到模型中的层列表,可以指定模型名称
model=tf.keras.Sequential(
layers=None, trainable=True, name=None
)
4.model.compile 模型配置
compile(
optimizer='rmsprop', # 优化器,定义如何更新模型权重即如何最小化损失
loss=None, # 损失函数
loss_weights=None,
metrics=None, # 评估指标
weighted_metrics=None, # 当样本有权重时,计算加权指标
run_eagerly=False,
steps_per_execution=1,
jit_compile='auto',
auto_scale_loss=True # 在混合精度训练中自动缩放损失值以防止梯度下溢
)
5.model.fit训练模型
model.fit(
x=None, # 输入数据,当使用dateset时,不需要指定y参数。datawindow中的处理方法,返回dataset
y=None, # 标签数据,即目标数据
batch_size=None, #批量大小,默认32
epochs=1, #训练轮数
verbose='auto', # 输出日志显示过程信息
callbacks=None, #回调函数列表
validation_split=0.0, # 验证集分割比例,从训练数据末尾切分一部分作为验证集
validation_data=None, # 验证集数据
shuffle=True, # 是否打乱数据
class_weight=None,
sample_weight=None,
initial_epoch=0,
steps_per_epoch=None, # 每轮步数,默认为样本数/批次数
validation_steps=None,
validation_batch_size=None,
validation_freq=1
)
6.LSTM
tf.keras.layers.LSTM(
units, # LSTM的单元数量,输出维度
activation='tanh', #控制输出门的激活函数,影响最终输出
recurrent_activation='sigmoid',用于循环步骤,即输入们,遗忘门,输出门的激活函数
use_bias=True,
kernel_initializer='glorot_uniform', #输入权重矩阵(W)初始化
recurrent_initializer='orthogonal', # 初始化循环权重举证(U)隐藏状态的权重矩阵
bias_initializer='zeros',
unit_forget_bias=True, # 遗忘门的偏置初始化
kernel_regularizer=None # 输入权重正则化
recurrent_regularizer=None # 循环权重正则化
bias_regularizer=None # 偏置正则化
activity_regularizer=None # 输出正则化
kernel_constraint=None # 输入权重约束
recurrent_constraint=None # 循环权重约束
bias_constraint=None # 偏置约束
dropout=0.0,
recurrent_dropout=0.0,
seed=None,
return_sequences=False, # 是否返回完整序列, 单层lstm用于分类,输出(batch_size,64)
return_state=False, # 是否返回隐藏状态,true返回最后一个时间步的隐藏状态和细胞状态
go_backwards=False,
stateful=False, # 是否保持批次间状态,false用于标准训练,批次独立
unroll=False,
use_cudnn='auto',
**kwargs
)
7.Conv1D 一维卷积模型
tf.keras.layers.Conv1D(
filters, # 输出空间的维度,卷积中滤波器的数量。数量越多捕捉的特征越丰富
kernel_size, # 卷积窗口大小。小窗口专注细节,大窗口感受整体
strides=1, #卷积步长,每次移动的步数
padding='valid', #输入数据的填充方式
data_format=None,
dilation_rate=1,
groups=1,
activation=None, # 激活函数
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs
)
6. 基线模型
在每个项目开始,根据经验或感觉先定义一个基线模型,作为接下来选择的模型的比较基准。这个项目中,我们设置基线模型为重复最后24h的数据,因为我们根据周期性,判断有天的季节性,所以理所当然认为明天的能耗应该和今天的一样。
** 1.定义数据窗口为输入长度24h,标签长度24h,位移24h,total_width = 48h**
python
multi_window=DataWindow(input_width=24,shift=24,label_columns=['Global_active_power'])** 2. 定义基线模型,训练,保存结果并plot**
python
# 定义一个继承自tf.keras.Model的基线模型类,接受label_index参数,使用父类的构造函数完成初始化
class RepeatBaseline(Model):
def __init__(self, label_index=None):
super().__init__()
self.label_index = label_index
def call(self, inputs):
return inputs[:, :, self.label_index:] # 返回(batch_size,24,num_label_index)的数值
# 实例化模型,指定要预测的目标特征
baseline_repeat = RepeatBaseline(label_index=column_indices['Global_active_power'])
# 编译模型,指定损失函数和评估指标
baseline_repeat.compile(loss=MeanSquaredError(), metrics=[MeanAbsoluteError()])
# 在验证集上评估模型
val_performance['Baseline - Repeat'] = baseline_repeat.evaluate(multi_window.val)
# 在测试集上评估模型(不显示详细输出)
performance['Baseline - Repeat'] = baseline_repeat.evaluate(multi_window.test, verbose=0)
# 绘制模型的预测结果
multi_window.plot(baseline_repeat)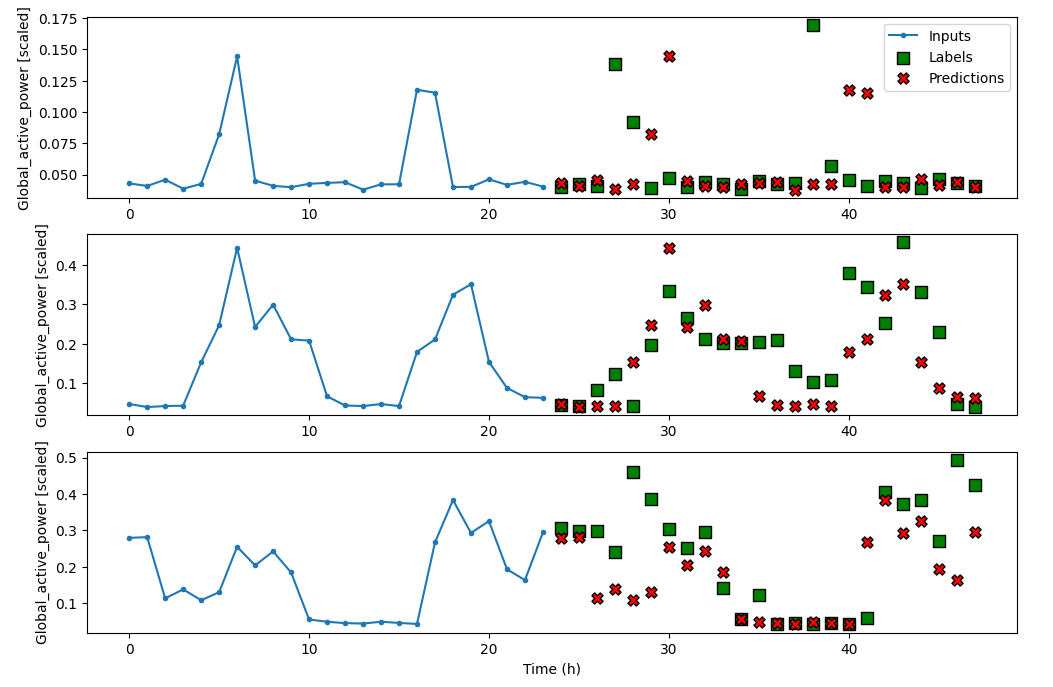
7. 线性模型
定义简单的线性模型,该模型只有输入层和输出层。因为只有一个预测目标,功率,所以输出层只有一个神经元。
python
label_index = column_indices['Global_active_power']
num_features = train_df.shape[1]
# 顺序模型堆叠, 只有一个输出单元,输入维度为global_active_power,global_reactive_power,intensity,voltage,sub_meter1 5个维度。这可以在Datawindow splite_to_inputs_labels函数中确定
linear = Sequential([
Dense(1, kernel_initializer=tf.initializers.zeros)
])
history = compile_and_fit(linear, multi_window)
val_performance['Linear'] = linear.evaluate(multi_window.val)
performance['Linear'] = linear.evaluate(multi_window.test, verbose=0)
multi_window.plot(linear)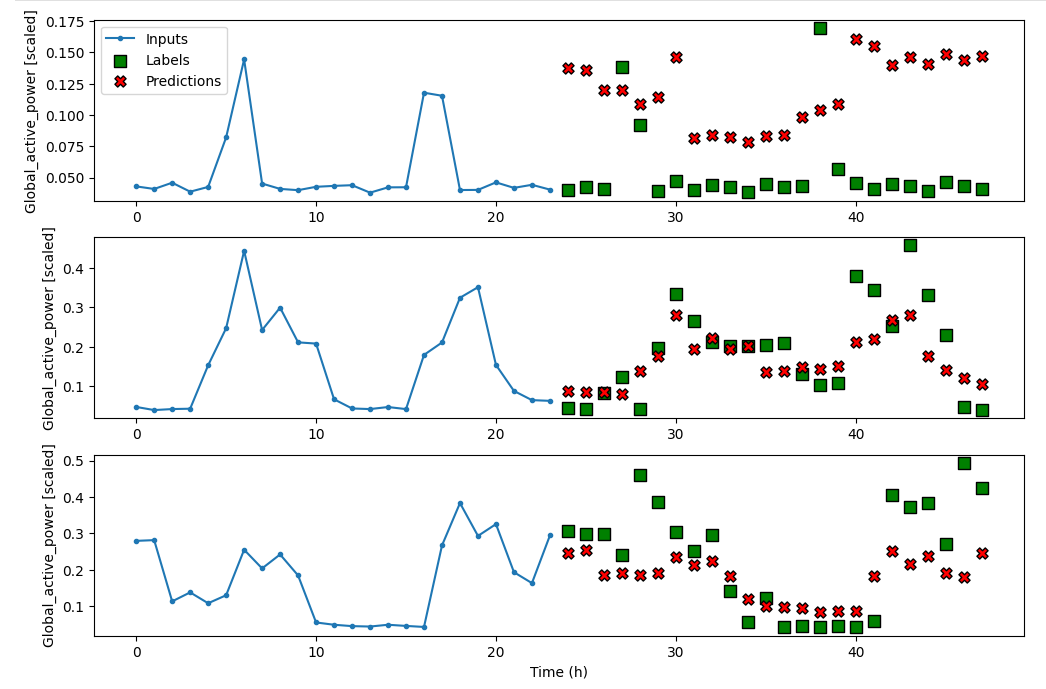
8. DNN实现预测
深度神经网络是由输入层,隐藏层和输出层组成的全连接神经网络,是最基础的深度神经网络。在其他如CNN,RNN等模型中DNN常用于分类/回归,用作输出层,用于输出结果。
通过增加隐藏层,构建DNN模型。需要注意的是,DNN对每个时间步独立计算权重w和偏置b,不会考虑时间步之间的关系,无法理解和捕捉时间序列的关系。
python
# 堆叠2层隐藏层,每个隐藏层64个神经元,并选择relu作为激活函数
dense = Sequential([
Dense(64, activation='relu'),
Dense(64, activation='relu'),
Dense(1, kernel_initializer=tf.initializers.zeros),
])
history = compile_and_fit(dense, multi_window)
val_performance['Dense'] = dense.evaluate(multi_window.val)
performance['Dense'] = dense.evaluate(multi_window.test, verbose=0)
multi_window.plot(dense)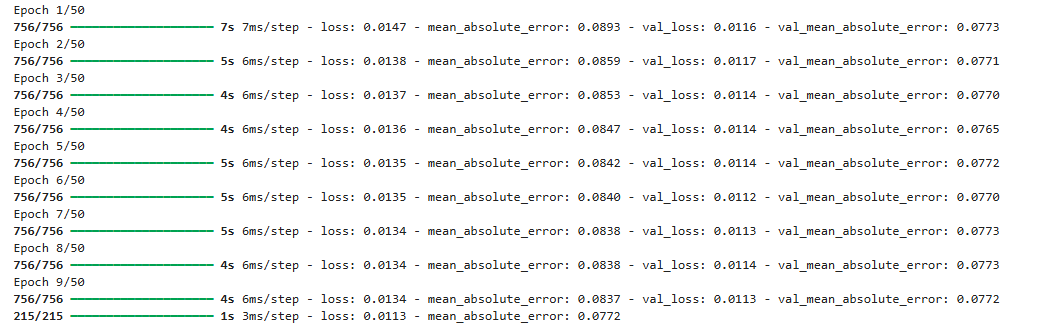
训练阶段756/756,没有指定steps_per_epoch参数。默认参数为总窗口数= 24209-48+1= 24162/32=755.06,向上取整为756。
*评估阶段215/215,表示模型在验证集/测试集上的评估批次次数,这是训练完成后额外执行的一次完整评估,不属于训练epoch的一部分。验证集6917-48+1=6870/32=214.6,取整为215.
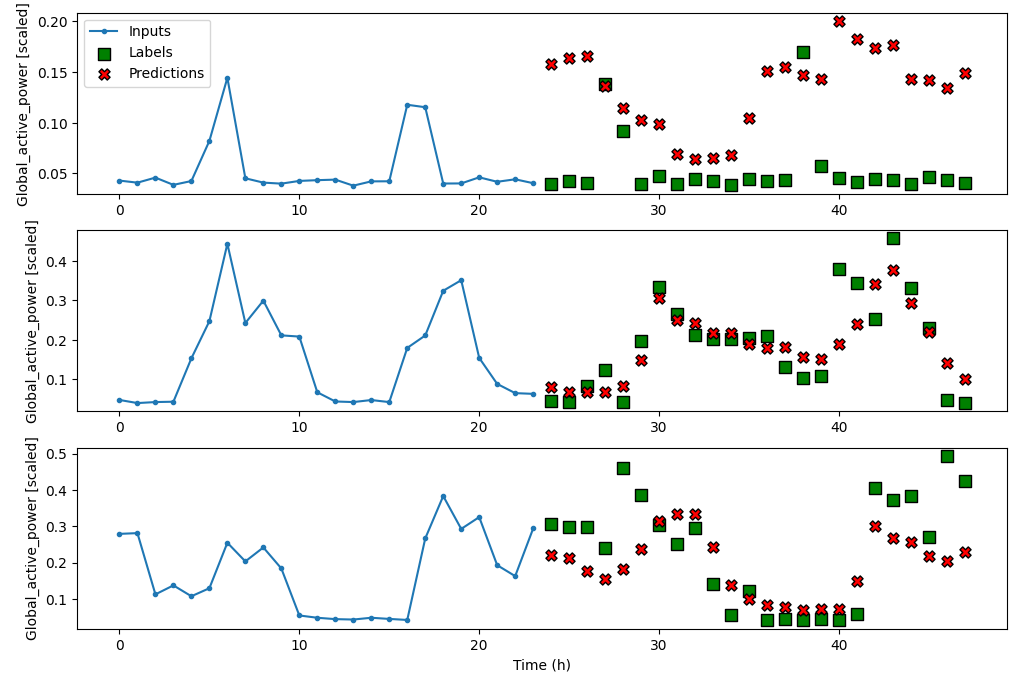
9. LSTM实现预测
时间序列预测的关键就在于变量是按照时间顺序排列的。处理这种序列数据的主流技术为RNN递归神经网络模型,它能够记录过去的信息并使用它处理序列的下一个元素。LSTM在RNN架构中增加了一个单元状态,避免了RNN的梯度消失问题,并且能够将过去的信息保留i在记忆中更长时间。
LSTM由三个门组成:
1)遗忘门,决定了来自过去步骤的那些信息仍然是相关的。
2)输入门,决定当前步骤的哪些信息是相关的。
3)输出门,决定将哪些信息传递到序列的下一个元素或作为结果传输到输出层。
实现代码如下:
python
lstm_model = Sequential([
LSTM(32, return_sequences=True),
Dense(1, kernel_initializer=tf.initializers.zeros),
])
history = compile_and_fit(lstm_model, multi_window)
val_performance['LSTM'] = lstm_model.evaluate(multi_window.val)
performance['LSTM'] = lstm_model.evaluate(multi_window.test, verbose=0)
multi_window.plot(lstm_model)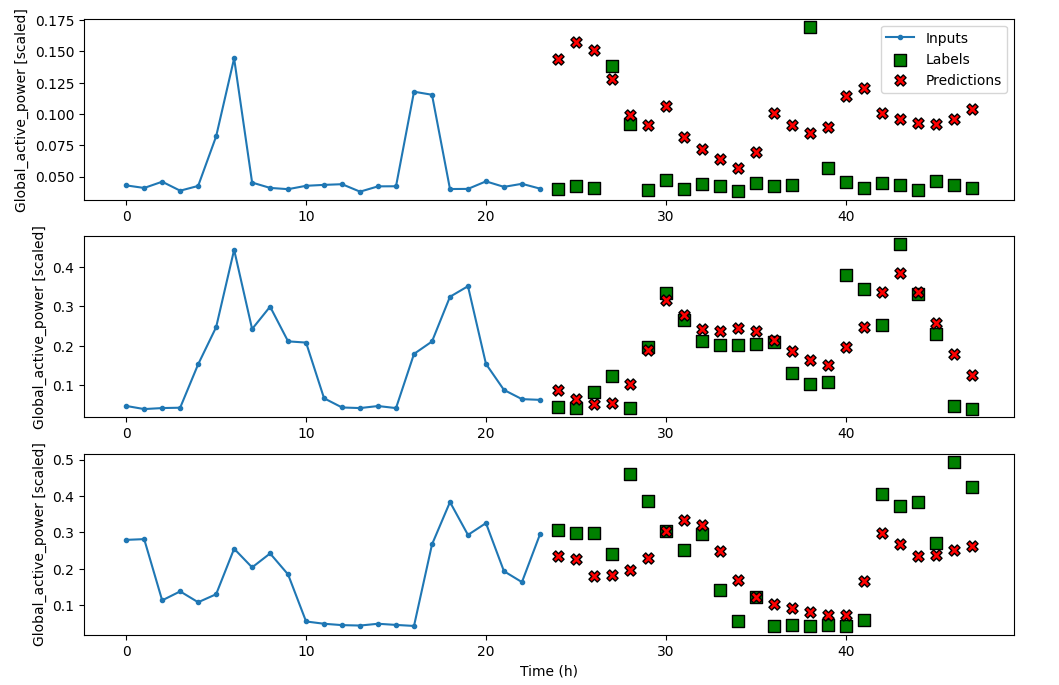
10. CNN实现预测
卷积神经网络可以通过卷积运算减少特征空间,在图像识别等领域应用广泛。卷积使用卷积核计算。卷积核的大小决定了它在卷积中每一步移动的步数。由于特征减少,训练更快,还支持并行计算。卷积操作减少了特征空间,因此必须提供稍长的输入序列确保输出序列包含24个时间步长,计算方法为: 输入长度=标签长度+核长度-1。对于本项目,定义核长度=3,输入长度=24+3-1=26。
代码如下:
python
#定义数据窗口
KERNEL_WIDTH = 3
LABEL_WIDTH = 24
INPUT_WIDTH = LABEL_WIDTH + KERNEL_WIDTH - 1
cnn_multi_window = DataWindow(input_width=INPUT_WIDTH, label_width=LABEL_WIDTH, shift=24, label_columns=['Global_active_power'])
#定义1维卷积层作为输入层,将输出提供给具有32个神经元的全连接层,然后再进入输出层。
cnn_model = Sequential([
Conv1D(32, activation='relu', kernel_size=(KERNEL_WIDTH)),
Dense(units=32, activation='relu'),
Dense(1, kernel_initializer=tf.initializers.zeros),
])
history = compile_and_fit(cnn_model, cnn_multi_window)
val_performance['CNN'] = cnn_model.evaluate(cnn_multi_window.val)
performance['CNN'] = cnn_model.evaluate(cnn_multi_window.test, verbose=0)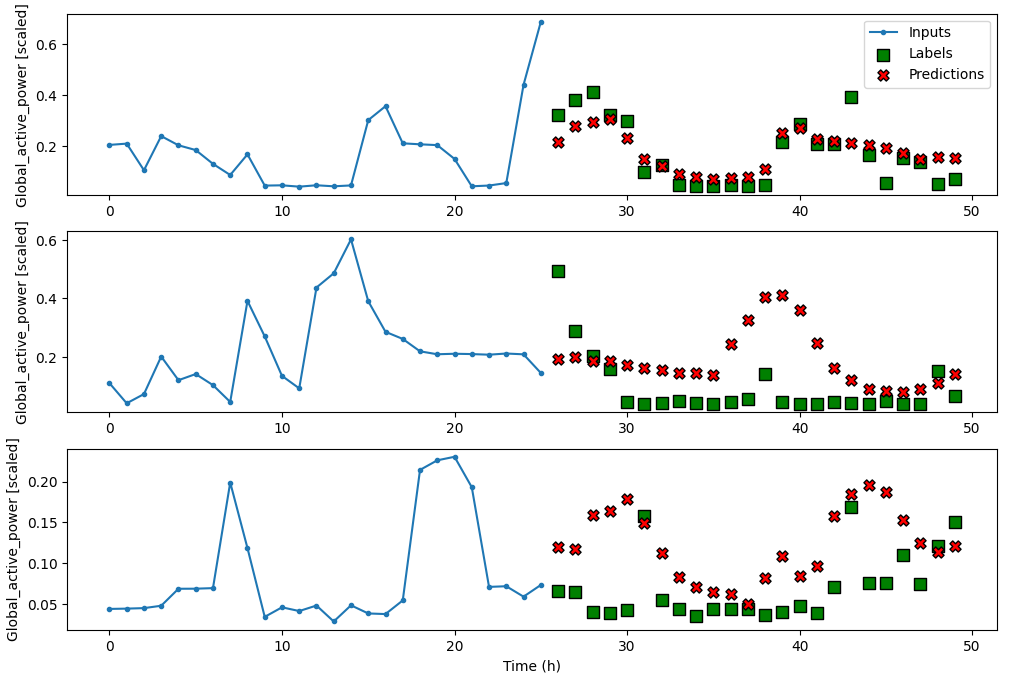
11. LSTM+CNN实现预测
可以将多种模型组合在一起进行预测,比如使用CNN进行特征过滤、特征提取,捕捉细节,然后再交给lstm进行处理。代码如下:
python
cnn_lstm_model = Sequential([
Conv1D(32, activation='relu', kernel_size=(KERNEL_WIDTH)),
LSTM(32, return_sequences=True),
Dense(1, kernel_initializer=tf.initializers.zeros),
])
history = compile_and_fit(cnn_lstm_model, cnn_multi_window)
val_performance['CNN + LSTM'] = cnn_lstm_model.evaluate(cnn_multi_window.val)
performance['CNN + LSTM'] = cnn_lstm_model.evaluate(cnn_multi_window.test, verbose=0)
12. 自回归LSTM模型实现预测
之前我们的预测模型都是一次性生成24h的数据,自回归lstm模型允许一次生成一个预测,并使用该预测作为下一个输入来生成下一个预测。这就为生成任意长度的预测带来了灵活性,不需要重新训练模型。但他会将误差引入后面的预测中,如果第一个预测非常差,这个错误会传递到后面的预测中,导致误差放大。代码如下:
python
#定义ARLSTM类
class AutoRegressive(Model):
def __init__(self, units, out_steps):
super().__init__()
self.out_steps = out_steps # 表示预测序列的长度,项目中=24
self.units = units # 表示神经元的数量
self.lstm_cell = LSTMCell(units) # 允许访问更细粒度的信息,如状态核输出
self.lstm_rnn = RNN(self.lstm_cell, return_state=True) # rnn层包装lstmcell层,更容易在训练集上训练lstm
self.dense = Dense(train_df.shape[1]) # 预测
# 定义输出第一个预测的函数,warmup复制一个单步lstm模型,将输入传递到lstm_rnn层,并从dense层获得预测,返回预测核状态
def warmup(self, inputs):
x, *state = self.lstm_rnn(inputs)
prediction = self.dense(x)
return prediction, state
# 重写model的call函数
def call(self, inputs, training=None):
predictions = [] # 收集所有的预测结果
prediction, state = self.warmup(inputs) # 获取第一个预测结果
predictions.append(prediction)
# 预测结果作为下一个预测的输入
for n in range(1, self.out_steps):
x = prediction
x, state = self.lstm_cell(x, states=state, training=training)
# 使用上一个预测结果作为输入,生成新的预测
prediction = self.dense(x)
predictions.append(prediction)
#将预测结果堆叠起来
predictions = tf.stack(predictions)
#将形状转换为(batch,time,features)
predictions = tf.transpose(predictions, [1, 0, 2])
return predictions
# 进行预测
AR_LSTM = AutoRegressive(units=32, out_steps=24)
history = compile_and_fit(AR_LSTM, multi_window)
val_performance['AR - LSTM'] = AR_LSTM.evaluate(multi_window.val)
performance['AR - LSTM'] = AR_LSTM.evaluate(multi_window.test, verbose=0)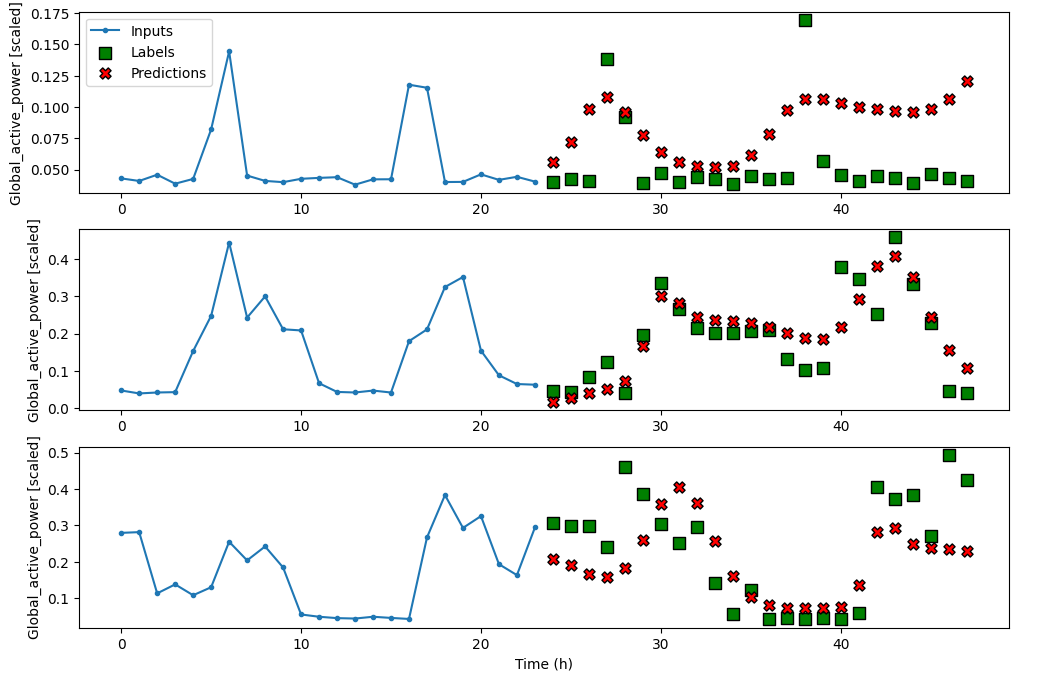
13. 比较结果,选择本项目效果最好的模型
python
mae_val = [v[1] for v in val_performance.values()]
mae_test = [v[1] for v in performance.values()]
x = np.arange(len(performance))
fig, ax = plt.subplots()
ax.bar(x - 0.15, mae_val, width=0.25, color='black', edgecolor='black', label='Validation')
ax.bar(x + 0.15, mae_test, width=0.25, color='white', edgecolor='black', hatch='/', label='Test')
ax.set_ylabel('Mean absolute error')
ax.set_xlabel('Models')
for index, value in enumerate(mae_val):
plt.text(x=index - 0.15, y=value+0.005, s=str(round(value, 3)), ha='center')
for index, value in enumerate(mae_test):
plt.text(x=index + 0.15, y=value+0.0025, s=str(round(value, 3)), ha='center')
plt.ylim(0, 0.33)
plt.xticks(ticks=x, labels=performance.keys())
plt.legend(loc='best')
plt.tight_layout()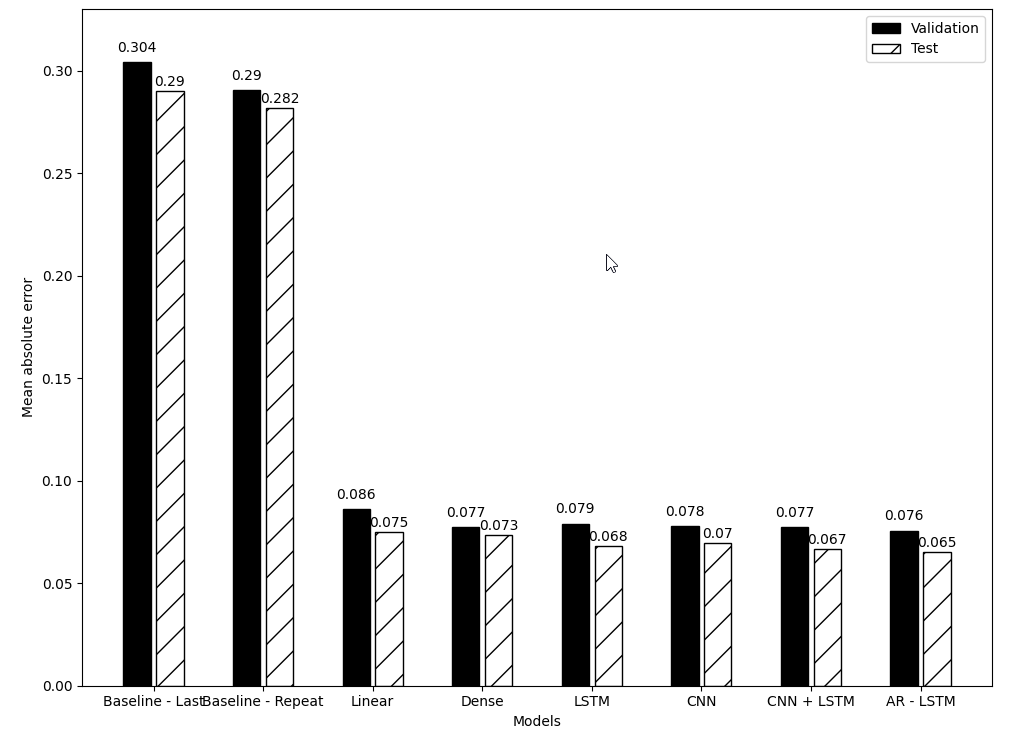
可以看到,本项目效果最好的模型是ARlstm自回归模型。
14. 总结
通过1篇文章,将数据处理、常用的深度学习的时间序列模型作了介绍。模型没有好坏之分,并且模型可调参数非常多,遇到具体项目时也需要不断尝试和调试。如果遇到具体项目,可以一起沟通和尝试。