写在前面
今天面试被问到:"如果数据量很大时查询数据用什么类型?"
我下意识回答:"GET。"
面试官摇了摇头:"POST 更合适。不要局限于什么类型就用什么类型,要根据实际业务场景决定。"
一瞬间,我愣住了。从学 HTTP 第一天起,就被灌输"GET 用于获取数据,POST 用于提交数据"的教条。但在真实的生产环境中,事情远没有那么简单。
今天,我们就来重新审视前后端交互这件事:有哪些交互方式?HTTP 方法到底该怎么选?GET 和 POST 的深层区别是什么?大数据量查询为什么 POST 更合适?以及 HTTP 和 HTTPS 的本质差异。
希望这篇文章能帮你打破思维定式,在面试和工作中做出更合理的技术决策。
一、前后端交互的"三大方式"
现代 Web 开发中,前后端交互主要有三种方式:
1.1 传统 HTTP 请求(AJAX / Fetch)
最常见的方式。前端通过 XMLHttpRequest 或 fetch 向后端发送 HTTP 请求,后端返回 JSON/XML/HTML。
javascript
// 现代前端示例
const response = await fetch('/api/users', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ name: '张三' })
});
const data = await response.json();1.2 WebSocket(双向实时通信)
建立持久连接,服务端可以主动推送消息给客户端。适用于聊天、实时行情、协同编辑等场景。
javascript
const ws = new WebSocket('wss://example.com/ws');
ws.onmessage = (event) => console.log('收到:', event.data);1.3 Server-Sent Events(SSE,单向推送)
服务端单向推送数据,客户端通过 EventSource 接收。适合新闻推送、通知、日志流等场景。
javascript
const eventSource = new EventSource('/api/events');
eventSource.onmessage = (event) => console.log('推送:', event.data);二、HTTP 请求类型(方法)的"正统"定义
根据 HTTP/1.1 规范(RFC 7231),常见方法有:
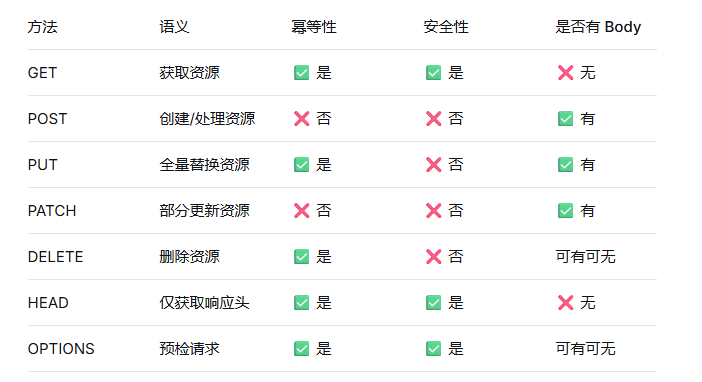
关键概念:
-
幂等性:多次执行结果相同(GET、PUT、DELETE 是幂等的;POST 不是)
-
安全性:不改变服务器状态(GET、HEAD、OPTIONS 是安全的)
教科书的教导:GET 用来获取,POST 用来提交。GET 参数放 URL,POST 参数放 Body。
三、打破教条:GET vs POST 的深层差异
当我们跳出规范,从工程实现角度看,GET 和 POST 的真正区别是什么?
3.1 参数传递方式
-
GET :参数拼在 URL 的 Query String 中(
?key=value) -
POST:参数放在请求 Body 中,格式多样(JSON、FormData、XML)
3.2 数据量限制
-
GET:受 URL 长度限制。不同浏览器和服务器限制不同:
-
Chrome:约 2KB(实际测试 8KB 以上也能工作,但规范不推荐)
-
Tomcat:默认 8192 字符
-
Nginx:默认 4KB~8KB
-
-
POST :理论上无限制,实际受服务器配置(如 Nginx
client_max_body_size)限制,可上传 GB 级数据。
结论:大数据量场景下,GET 可能被截断或拒绝,POST 更安全。
3.3 缓存与历史记录
-
GET:默认会被浏览器缓存、会被保存到历史记录、可以被收藏为书签
-
POST:默认不会被缓存、不会保存到历史记录、不能收藏为书签
3.4 安全性(不是指加密,而是指敏感信息暴露)
-
GET:参数在 URL 中,会出现在浏览器地址栏、服务器日志、Referer 头中,不适合传递密码、token 等敏感信息
-
POST:参数在 Body 中,相对隐蔽(但未加密时仍可被抓包)
3.5 语义与 RESTful
RESTful 风格推崇使用 HTTP 方法表达操作语义。但现实中,很多复杂查询(如 Elasticsearch 的复杂 JSON 查询)根本无法放在 URL 中。
四、大数据量查询:为什么 POST 更合适?
回到面试问题:数据量很大时查询数据用什么方法?
面试官说 POST 更合适,理由如下:
4.1 避免 URL 长度限制
假设你需要传递一个包含 100 个 ID 的数组进行批量查询:
javascript
// GET 方式(不可取)
GET /api/users?ids=1,2,3,4,5,6,...(超过 2000 个字符时可能失败)
// POST 方式
POST /api/users/batch
Body: { "ids": [1,2,3,...,10000] }当 ID 数量很多或查询条件很复杂(如 Elasticsearch 的 DSL)时,URL 根本装不下。
4.2 复杂查询结构的表达
许多现代查询需要嵌套 JSON 对象,URL 参数无法优雅表达:
javascript
{
"conditions": {
"and": [
{ "field": "age", "op": ">", "value": 18 },
{ "or": [
{ "field": "city", "eq": "北京" },
{ "field": "city", "eq": "上海" }
]}
]
},
"sort": ["age:desc", "name:asc"],
"page": 1,
"size": 100
}这种结构只能放在 POST Body 中。
4.3 安全性考虑
大数据量查询往往涉及敏感筛选条件(如身份证号、手机号范围),放在 URL 中会增加泄露风险。
4.4 实践中的共识
许多大型系统已经打破"GET 只用于查询"的教条:
-
Elasticsearch :复杂搜索使用
POST /index/_search,Body 放 DSL -
GraphQL:所有查询都用 POST,Body 放 query 字符串
-
OData :支持
POST /odata/Products/GetByFilter传复杂参数 -
各大云厂商的 API:批量查询往往使用 POST
所以,面试官说的"不要局限于什么类型就用什么类型"是在提醒你: 理解业务场景和数据特征,灵活选择。如果查询条件简单、数据量小、可以缓存,用 GET;如果查询条件复杂、数据量大、参数敏感,用 POST。
五、HTTP vs HTTPS:差一个"S",差多少?
5.1 核心区别

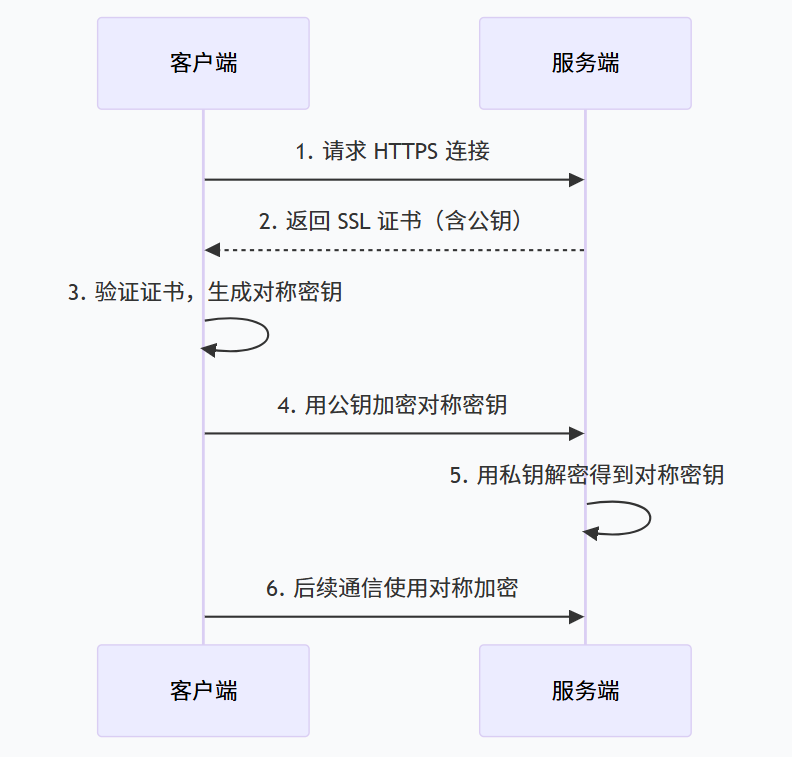
5.2 HTTPS 的工作流程(简化版)
-
客户端发起 HTTPS 请求,服务端返回 SSL 证书。
-
客户端验证证书合法性(CA 签名)。
-
客户端生成随机密钥,用证书中的公钥加密后发给服务端。
-
服务端用私钥解密得到对称密钥。
-
后续通信使用对称加密。
5.3 开发中怎么选?
-
所有生产环境对外服务:必须用 HTTPS(Chrome 已标记 HTTP 为"不安全")
-
内部开发环境:可用 HTTP 简化调试
-
涉及登录、支付、个人信息:强制 HTTPS
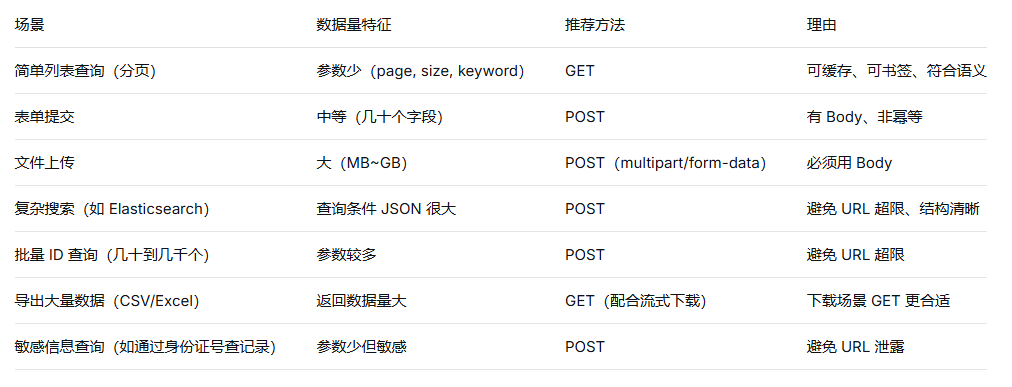
六、不同数据量场景下的请求类型选择指南
七、RESTful 的妥协与现代 API 设计趋势
RESTful 倡导资源导向,使用 HTTP 方法表达操作。但现实世界是复杂的:
-
需要批量操作 :
POST /users/batch/delete而非DELETE /users/{id}多次调用 -
需要复杂查询 :
POST /users/search而非GET /users?q=... -
需要跨多个资源的操作 :
POST /orders/123/payments而非严格 REST
趋势 :越来越多 API 设计采用 POST 作为通用动作入口 ,方法名放在 URL 中(如 /api/query、/api/command),这就是"动词式 API"或"操作型 API"。
GraphQL 更是彻底统一:所有请求都是 POST,查询语句放在 query 字段中。
八、面试题复盘:如果重来一次,我怎么答?
问:如果数据量很大时查询数据用什么类型?
标准回答框架:
"这个问题需要根据具体业务场景来分析。
首先,GET 和 POST 在规范上有明确的语义区别,GET 用于获取资源,POST 用于创建或处理资源。但在实际工程中,当查询条件复杂或数据量很大时,GET 会面临 URL 长度限制(通常浏览器和服务器限制在 2KB~8KB),并且参数暴露在 URL 中不够安全。
因此,对于大数据量查询,比如批量 ID 查询、复杂 JSON 筛选条件、Elasticsearch 式的 DSL 查询,使用 POST 更合适。我们可以将查询条件放在请求 Body 中,避免长度限制,同时表达更复杂的结构。
当然,如果查询条件简单且可以缓存,仍应优先使用 GET 以符合 RESTful 语义。总之,方法的选择不应死守教条,而应基于数据量、安全性、缓存需求等实际因素做出决策。"
总结:教条是起点,不是终点
前后端交互不是非黑即白的选择题。从 AJAX 到 WebSocket,从 GET 到 POST,从 HTTP 到 HTTPS,每一种技术都有其设计初衷和适用边界。
-
理解规范,是为了知道工具原本的设计意图。
-
理解限制(URL 长度、缓存、安全性),是为了避免踩坑。
-
理解业务场景,是为了做出最合适的决策。
面试官的提醒很宝贵:不要局限于什么类型就用什么类型。 这句话不是否定规范,而是要求我们站在工程的高度,灵活权衡。
希望这篇文章能帮你建立起更立体、更实战的前后端交互认知。下次再被问到这个问题,你不仅知道 POST 更适合大数据量查询,还能说出背后的完整逻辑。
最后留一个互动问题:你在实际项目中遇到过因为 GET 请求 URL 过长而导致的线上问题吗?你是如何解决的?欢迎在评论区分享你的经历。