
文章目录
数据在内存中的存储
整数
前提知识
(1)原反补码
- 内存中都是补码
- 正数原反补码相同
- 负数都不同
- 第一位二进制是符号位,1
- 后面是正常的二进制
- 原码符号位不变,其他位取反得反码,再加一得补码
- 补码符号位不变,其他位取反再加一也可得原码
(2)大小端
-
为什么会有大小端
- 计算机的单位是字节,一个字节是8个bit(0/1),
- 一个int是4字节,是32个0/1,是8个16进制数字
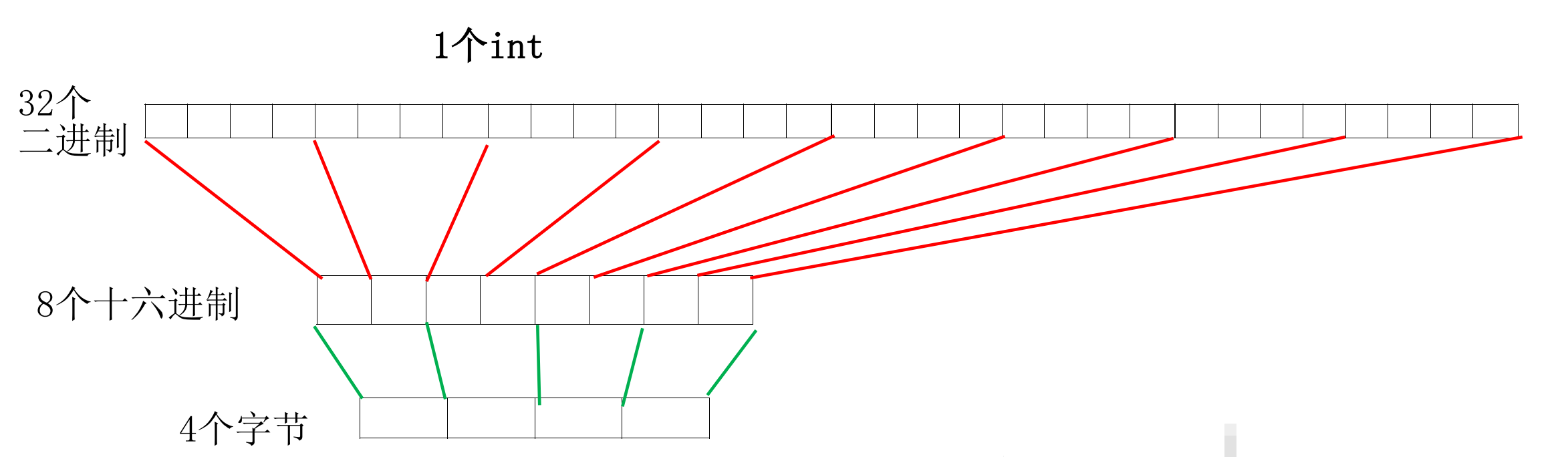
- 接下来就有如图的两种可能
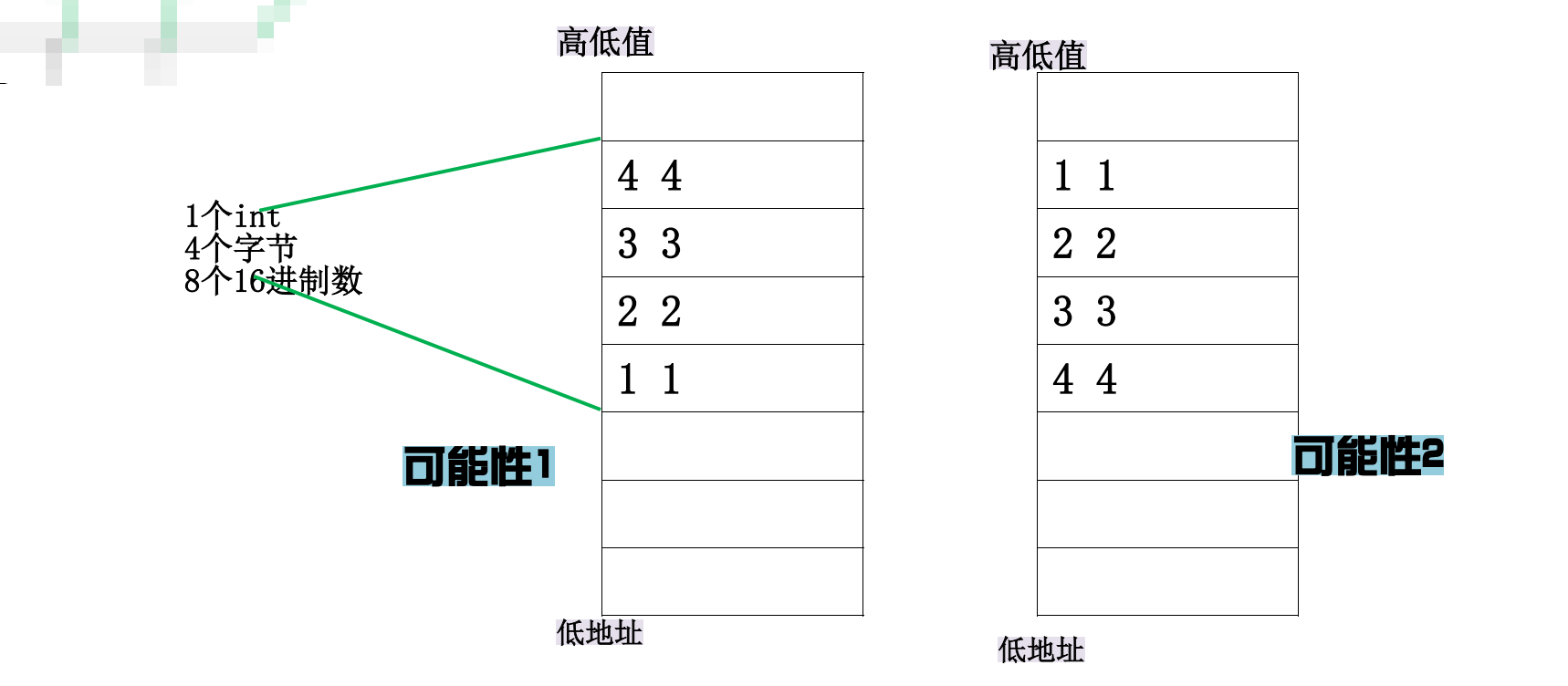
-
vs中是那种可能性呢?答案是可能性2
- 先看一眼正常情况
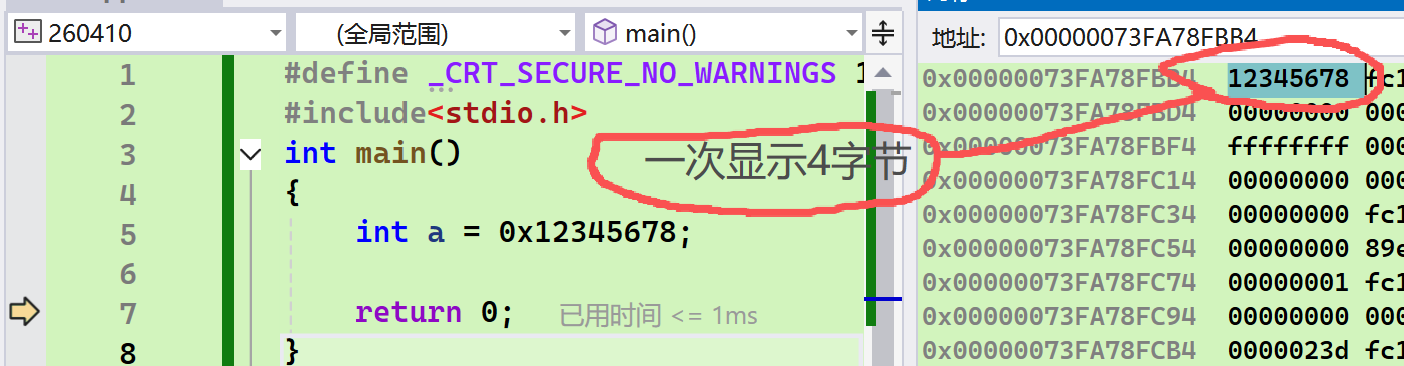
- 再看一眼真实情况
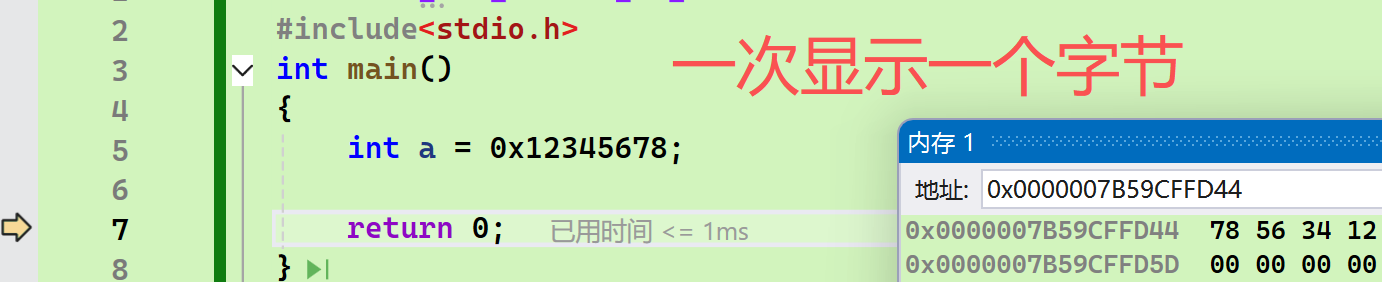
- 图中的7,8在最前面显示,而显示的是由低地址到高地址的访问,故为可能性2
- 先看一眼正常情况
-
大小端名字的由来(来源于《格列佛游记》):
- 首先,对于一个数字12345678,最大的数字应该是第一位的1,因为代表1000 0000
- 其次,如图中的内存的访问,是从左向右(本质是低地址到高地址)
- 那么,我们先看到的是最左边的(低地址),
- 如果先看到的是最大的数字,比如12345678中的第一个1,就叫大端
- 先看到最小的数字,就叫小端
-
判断大小端的程序
- 直接看int 1的第一个字节储存的内容即可
cpp#include<stdio.h> int main() { int a = 1; int* pa = &a; if (*(char*)pa = 1) printf("是小端"); else printf("是大端"); return 0; } -
示例:
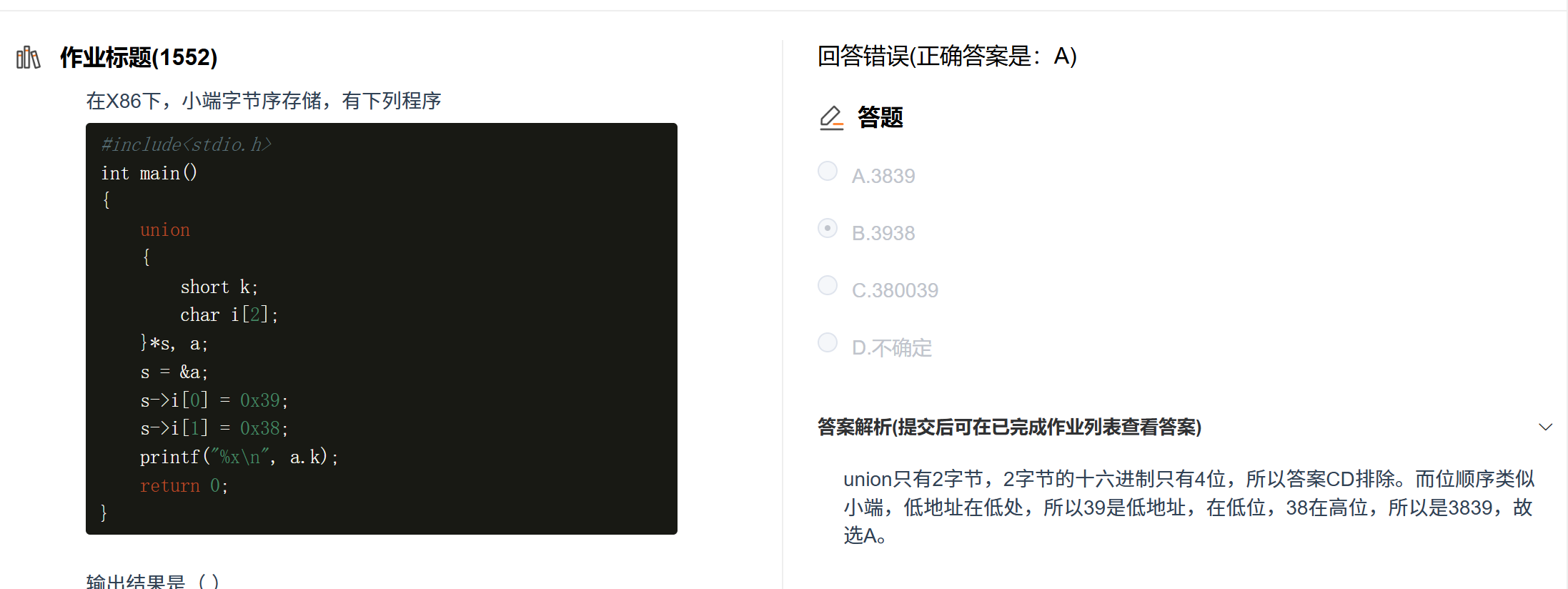
-
char i[2]是两个字节:i[0]对应低地址 ,i[1]对应高地址-
i[0] = 0x39→ 低地址存0x39i[1] = 0x38→ 高地址存0x38
-
-
字节
short k的 低位字节 =0x39,高位字节 =0x38 -
printf("%x")按十六进制打印,从高地址向低地址,输出3839
(3)整型提升
-
是什么:只要
char/short参与运算、传参、printf 等操作,就会被自动转换为int -
为什么:CPU 的通用寄存器默认按
int(32 位)宽度设计 -
对象:short,char(包括signed和unsigned)
-
使用场景:
- 算术运算 :
char + char、short - short、char | short等所有位运算、算术运算 - 传参 :虽然应该传int类型,但是你也可以传char类型 ,因为char会被转化成int
- 比如memset设置字符串,使用printf大小写转换时对char加减数字 的情况等等
- printf如果想打印char字符的ASCII码值,使用%d,这时候char也会被转化成int
- 作为返回值
- if,while等条件判断
sizeof(char + char)结果是sizeof(int)
- 算术运算 :
-
具体内容:
以使用printf("%u")打印两个char相加为例:
- 在计算/打印等使用之前,先整型提升
- 如果是unsigned char,相当于二进制直接在前面补上24个0
- 如果是有符号char,前面补24个符号位
- 得到的结果再转化为char类型
- 这时候再把char转成unsigned int来打印
- 在计算/打印等使用之前,先整型提升
(4)数据的循环圈
- 以char类型不停+1来举例(0,1,2...127,-128,-127,-126...-1,0):
- 从0000 0000开始,一直到01111111,就是从0变成127
- 01111111再加一就是10000000(负数的补码),这个数字默认是-128
- 然后10000000(补码)加一得到的就是-127,继续加上数字就从-127一直加到-1,然后是0
- 接下来就会回到第一步,是一个循环
- 各种数据类型都有这样的过程
(5)%x用来打印16进制数字
- 在vs中,直接得到的是有效数字,没有前面的0x和无效的0
- 比如打印11的十六进制,直接打印b而不是0xb
6个题目
第1题
- 设计程序判断机器是大端还是小端
- 小端:权重小的放在低地址
- 大端:权重大的放在低地址
第2题
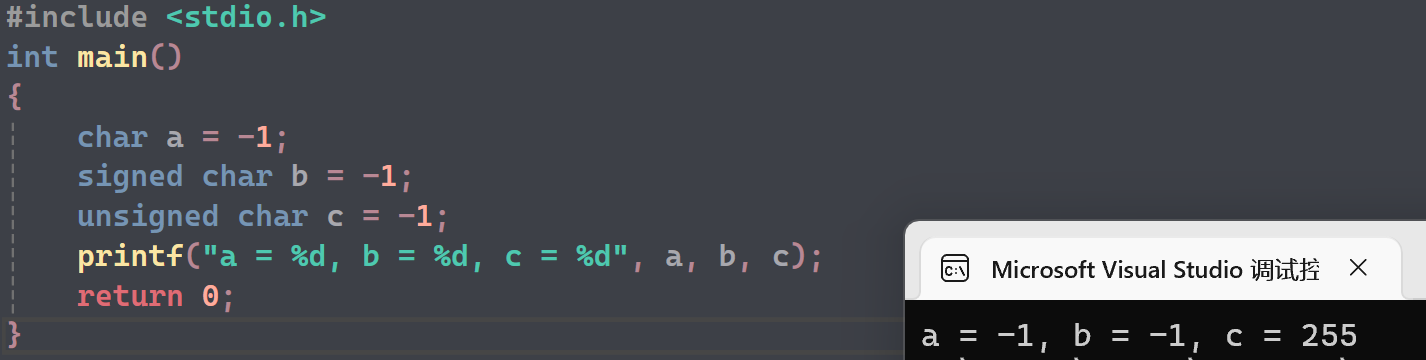
- a
- a的原码:10000001
- a的反码:11111110
- a的补码:11111111
- 打印前时整形提升为11111111 11111111 11111111 11111111
- %d打印,看到是负数,打印对应的原码:10000000 00000000 00000000 00000001,结果是-1
- b
- b和a是同一种类型,打印结果相同
- c
- c的补码也是11111111
- 打印前,因为是unsigned char ,整型提升为00000000 00000000 00000000 11111111
- %d打印,看到是正数,直接打印 ,结果是255
第3题
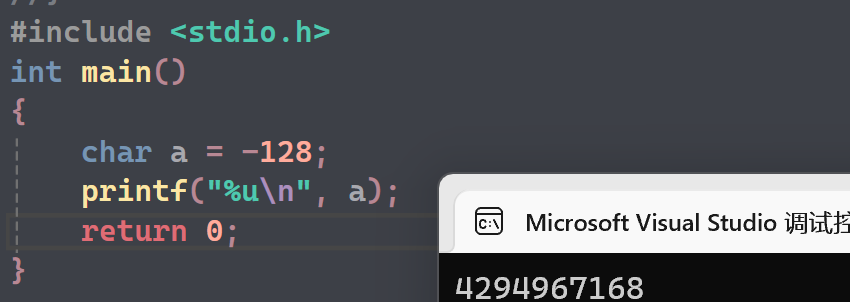
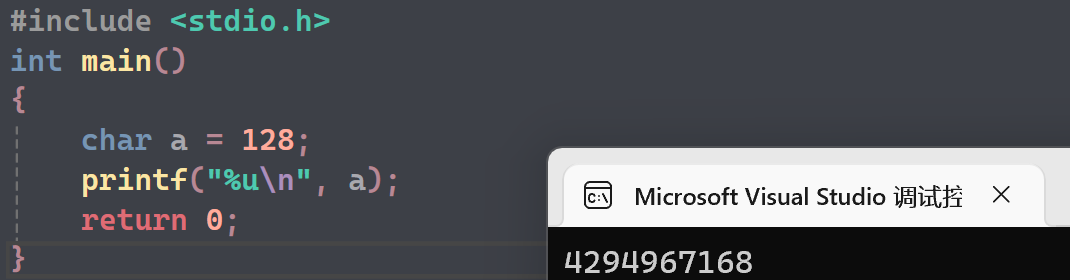
- a的补码:10000000(这是-128的默认补码值,没有原码和补码的概念)
- 打印前时整形提升为11111111 11111111 11111111 10000000
- %u打印,无符号,默认是正数,直接打印,结果是4294967168
- a的原反补码相同:10000000
- 和上半题的补码相同,在使用%u打印前的整形提升自然也相同,结果也相同
第4题
-
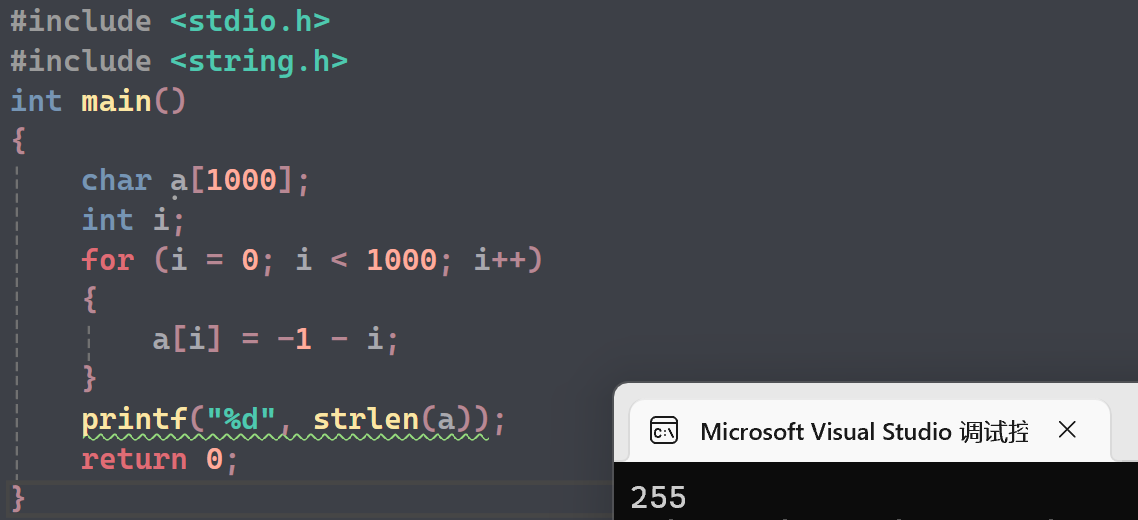
根据"数据的循环圈", char类型的+1循环:(0,1,2...127,-128,-127,-126...-1,0)
可以得到,char类型的-1循环:0,-1,-2... -128 ,127,126...2,1,0
-
a数组元素从-1开始,到-128,再从127开始,到1,然后到了一个0,这个0是ASCII码值,strlen读到这个就会停,所以打印的结果是128+127=255
第5题
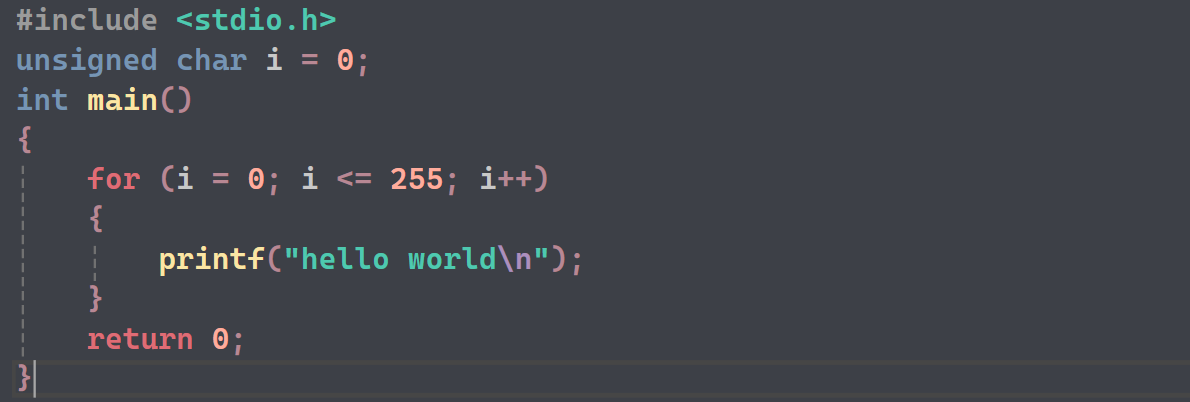
- 由于"数据的循环圈",i的最大值就是255,再加1会变成1,会无限循环下去,不停打印
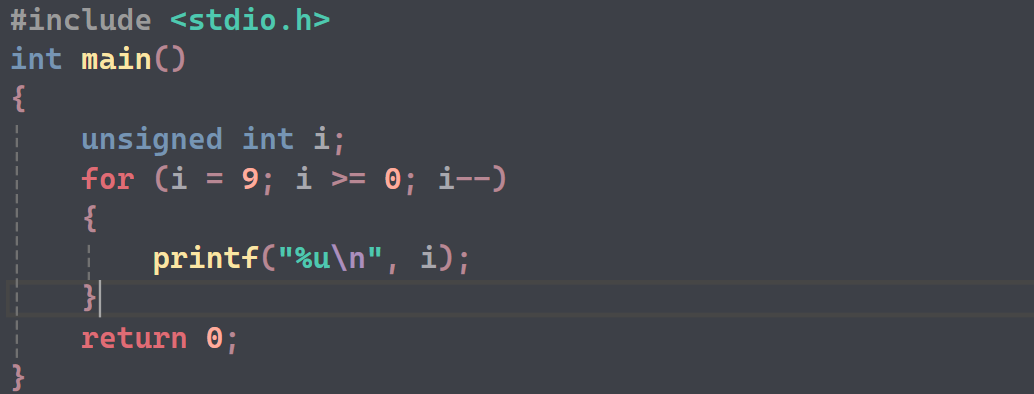
- 同理可得,i作为unsigned,是不会出现负数的,所以也会不停打印
第6题
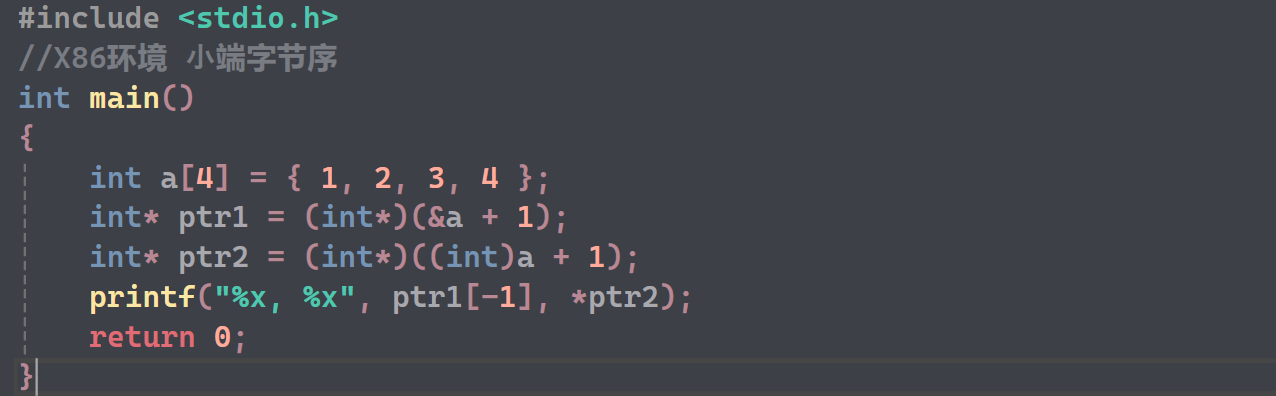

- 地址如图所示,
- 通过ptr2得到的,有因为是小端字节序,所以2是高位,
- 使用%x打印16进制,得到的结果应该是2000000和4
浮点数
(1)浮点数的类型
- float、32位,4字节
- double、64位,8字节
- long double,16字节
(2)浮点数的存储
1.存之前
- 一个浮点数,计算机理解为为 (−1)^S ∗ M ∗ 2 ^E
- S是0或1,决定了浮点数的正负
- M是浮点数转为二进制后,再进行取有效数字(相当于把1234转化为1.234*10^3次方中的1.234)
- M大于1,小于2,(和科学计数法中的转化一样)
- E是次方数,(相当于把1234转化为1.234*10^3次方中的10的3次方中的3,不过这里是2的E次方)
- 举例:十进制的6.0,
- 先转化为二进制:110.0,
- 再进行科学计数法:1.100*2的2次方
- 那么,S=0;M=1.1;E=2
2.存的时候
- 32位的浮点数(float):最⾼的1位存储符号位S,接着的8位存储指数E+127 ,剩下的23位存储有效数字 M的小数位
- 对于64位的浮点数(double),最⾼的1位存储符号位S,接着的11位存储指数E+1023 ,剩下的52位存储有效数字M的小数位
(3)浮点数的读取
- 一般情况:将二进制数字转化为对应的S,M,E ,然后再使用
- 指数二进制部分全为0:相当于于1-127(或者1-1023),这时候还原M的时候不再加上1,直接读0.xxx,这是为了表示0或者很小的数字
- 指数二进制部分全为1:这相当于 ± 无穷大
(4)一个题目
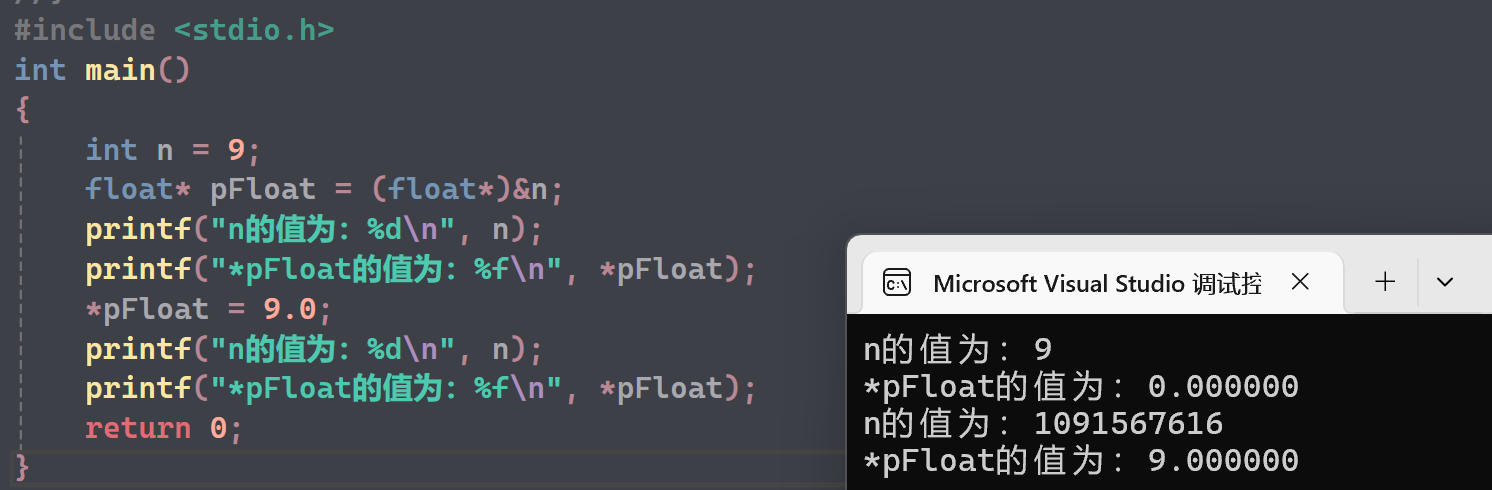
-
第一个就是9
-
第二个:将int 类型的9看做一个float进行打印,
- 9的原反补码:00000000 00000000 00000000 00001001
- 当做float看:
- S(符号位)是0,代表正数
- 接下来的8位代表指数位(E+127),全0,代表无穷小,所以打印是0(默认保留小数点后 6 位)
-
第三个:(因为float* pFloat 代表该地址存的就是一个浮点数,所以即使是*pFloat = 9 ;也依然成立)将浮点数存到原来n的位置,并且当做整型打印
- 储存9时:1.001*2^3
- 符号位S是0,后面 接着的8位存储指数E+127 =130(二进制是10000010),后面接着23位存1.001的小数位001
- 就是0 10000010 00100000000000000000000
- 作为int类型打印就是 1091567616
-
第四个:类型符合,打印正确,默认六位小数,就是9.000000