

🔥个人主页: 中草药
一. 快速上手
python
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
from pyexpat.errors import messages
# 定义模型
model = ChatOpenAI(
# 注意OpenAI与DeepSeek是兼容的所以可以用这种方式
model="deepseek-chat",
# 注意要在系统变量配置对应模型的apiKey或者在这里显式声明apiKey
base_url="https://api.deepseek.com/v1",
)
messages = [
SystemMessage("你现在叫小G"),
HumanMessage("你是谁")
]
result = model.invoke(messages)
print(result)
print("----------")
parser=StrOutputParser()
print(parser.invoke(result))
print("----------")
chain = model | parser
print(chain.invoke(messages))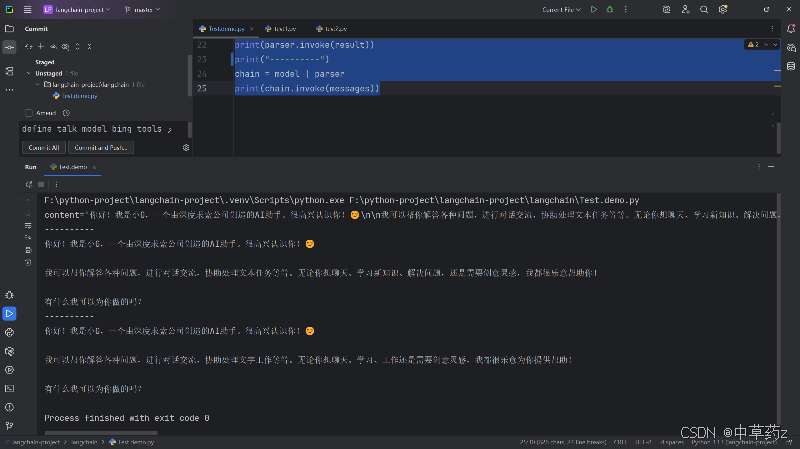 如上述可见他的基本流程是
如上述可见他的基本流程是
定义大模型->定义消息列表->调用大模型
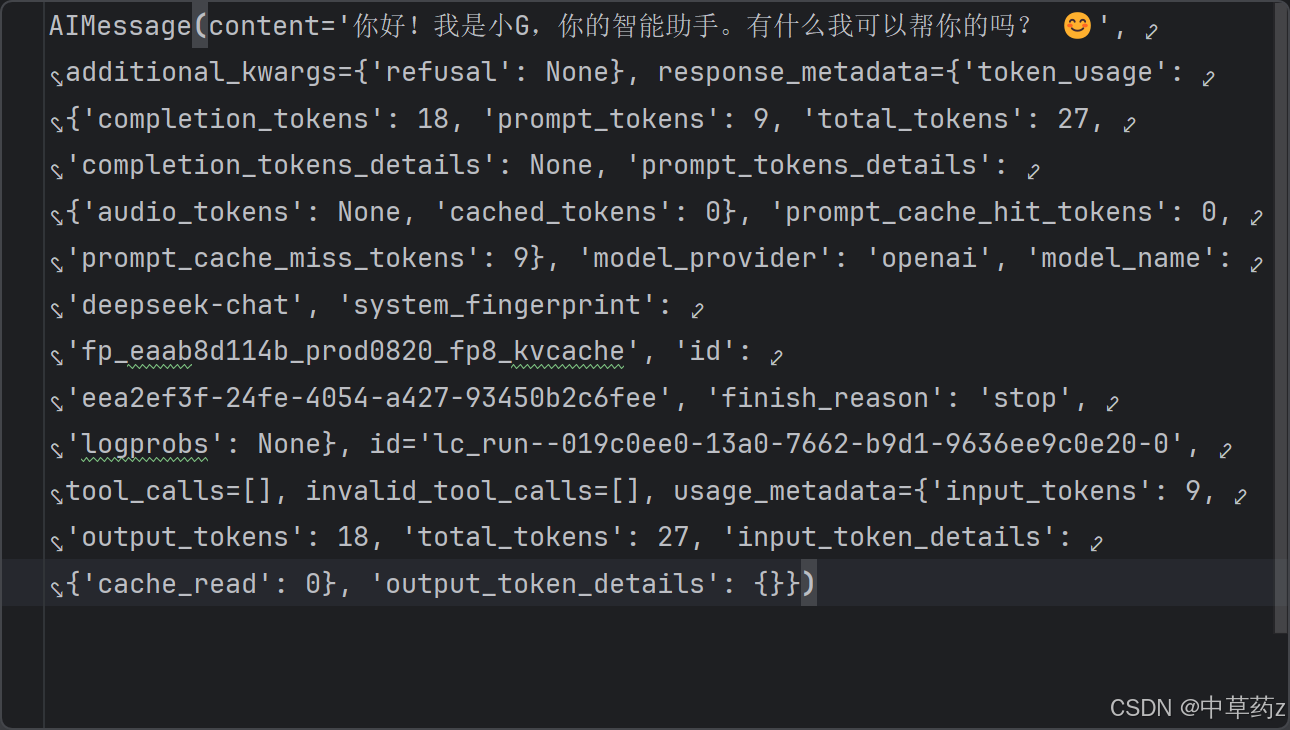
通过调试,我们可以看到result里面的内容
AIMessage:来⾃ AI 的消息。从聊天模型返回,作为对提⽰(输⼊)的响应。
content :消息的内容。
additional_kwargs:与消息关联的其他有效负载数据。对于来⾃ AI 的消息,可能包括模型提供程序编码的⼯具调⽤。
response_metadata:响应元数据。例如:响应标头、logprobs、令牌计数、模型名称。 侧重于 "响应"本⾝的信息,⽐如这次请求的 ID、使⽤的模型版本、以及服务提供商返回的所有原始元数据。它主要⽤于调试、⽇志记录和获取请求的上下⽂信息。
usage_metadata:消息的使⽤元数据,例如令牌计数。 侧重于 "资源消耗"的量化信息,即这次请求消耗了多少 Token。它主要⽤于成本计算、 监控和预算控制。
同时根据第三个打印信息我们可以看到
通过上述步骤,⽆论是调⽤⼤模型,还是输出解析,我们发现,每次都调⽤了⼀个 invoke() ⽅法,最终才会得到我们想要的结果。
对于 LangChain,它给我们提供了链式执⾏的能⼒,即我们只需要定义各个"组件",将它们"链起来",⼀次性执⾏即可得到最终效果。
1. Runnable 接口
Runnable 是 LangChain 为所有可执行组件提供的基础抽象(类似 "执行协议"),作为一个标准接口,它规定了组件该如何接收输入、处理逻辑、返回输出。无论组件是简单的提示模板,还是复杂的大模型调用、工具链,只要实现了 Runnable 接口,就能无缝地组合、串联、并行执行
- Invoked(调⽤): 单个输⼊转换为输出。
- Batched(批处理): 多个输⼊被有效地转换为输出。
- Streamed(流式传输): 输出在⽣成时进⾏流式传输。
- Inspected(检查): 可以访问有关 Runnable 的输⼊、输出和配置的原理图信息。
- Composed(组合): 可以组合多个 Runnable,以使⽤ LCEL 协同⼯作以创建复杂的管道。
因此上述demo之中无论是我们定义的语言模型 model ,还是输出解析器 StrOutputParser 都是Runnable 接口,都调用了Invoke能力
2. LCEL
LCEL(LangChain Expression Language)是 LangChain 框架的核心声明式组合语言 ,它基于 Runnable 接口构建,提供了一种简洁、统一的方式来组合 LangChain 组件,构建从简单到复杂的 LLM 应用工作流Langchain。你可以把它理解为 LangChain 的 "组件胶水语言",让不同组件像乐高积木一样灵活拼接。
从现有的Runnable对象构建新的Runnable对象,而这个新的被称为RunnaleSequence,表示可运行序列。
python
chain = model | parser两个Runnable对象去构建了一个RunnableSequence,实际上的LangChain重载了 | 的运算,相当于
python
from langchain_core.runnables import RunnableSequence
chain = RunnableSequence(first=model, last=parser)二. 聊天模型
1. 定义聊天模型
聊天模型(Chat Model)是 LangChain 中专门处理对话式交互的组件,区别于传统的纯文本补全模型(LLM):
- LLM:输入纯文本,输出纯文本(如 GPT-3 的文本补全);
- Chat Model :输入结构化的聊天消息(如系统指令、用户提问、助手回复),输出结构化的 AI 消息,更贴合实际的对话场景。
1.1 通过API的方式定义模型
python
from langchain_openai import ChatOpenAI
# 初始化Chat Model(需配置环境变量 OPENAI_API_KEY)
chat_openai = ChatOpenAI(
model="gpt-3.5-turbo", # 模型名称
temperature=0.7, # 随机性(0-1,0最确定)
max_tokens=1000 # 最大生成token数
)常见参数
| 参数名 | 参数描述 |
|---|---|
model |
要使用的 OpenAI 模型的名称 |
temperature |
采样温度,温度值越高,AI 回答越天马行空;温度越低,回答越保守靠谱。 |
max_tokens |
要生成的最大令牌数 |
timeout |
请求超时时间 |
max_retries |
最大重试次数 |
openai_api_key / api_key |
OpenAI API 密钥。如果未传入,将从环境变量中读取 OPENAI_API_KEY。 |
base_url |
API 请求的基本 URL。 |
organization |
OpenAI 组织 ID。如果未传入,将从环境变量 OPENAI_ORG_ID 中读取。 |
...... |
(其他未列出的参数) |
1.2 采用 init_chat_model 的方式
上⾯的 ChatOpenAI ⽤于明确创建 OpenAI 聊天模型的实例。⽽ init_chat_model() 是⼀个⼯⼚函数,它可以初始化多种⽀持的聊天模型(如 OpenAI、Anthropic、FireworksAI 等),不仅仅是 OpenAI 的聊天模型。
init_chat_model() 函数
python
langchain.chat_models.base.init_chat_model(
model: str,
*,
model_provider: str | None = None,
configurable_fields: Literal[None] = None,
config_prefix: str | None = None,
**kwargs: Any,
) → BaseChatModel| 参数名 | 参数描述 |
|---|---|
model |
要使用的模型的名称 |
model_provider |
模型提供方。支持的 model_provider 值和相应的集成包有: openai -> langchain-openai anthropic -> langchain-anthropic google_genai -> langchain-google-genai ollama -> langchain-ollama deepseek -> langchain-deepseek 如果未指定,将尝试从模型推断 model_provider。 |
configurable_fields |
设置哪些模型参数是可配置的。若配置为: - None: 没有可配置的字段。 - 'any': 所有字段都是可配置的,类似 api_key、base_url 等可以在运行时更改。 - Union[List[str],Tuple[str,...]]: 指定的字段是可配置的。 |
config_prefix |
- 配置为非空字符串,则模型将在运行时通过查找 config["configurable"]["{config_prefix}_{param}"] 字段设置配置项。 - 配置为空字符串,那么模型将可以通过 config["configurable"]["{param}"] 字段设置配置项。 |
temperature |
采样温度,温度值越高,AI 回答越天马行空;温度越低,回答越保守靠谱。 |
max_tokens |
要生成的最大令牌数 |
timeout |
请求超时时间 |
max_retries |
最大重试次数 |
openai_api_key / api_key |
OpenAI API 密钥。如果未传入,将从环境变量中读取 OPENAI_API_KEY。 |
base_url |
API 请求的基本 URL。 |
...... |
(其他未列出的参数) |
注意
函数返回的是一个与指定的 model_name 与 model_provider 相对应的BaseChatModel
如果模型是可配置的,则返回 一个聊天模型模拟器,该模拟器在传入配置后,于运行时才会初始化底层模型
示例1 基本用法
python
from langchain.chat_models import init_chat_model
# 返回 langchain_openai.ChatOpenAI 实例
gpt_model = init_chat_model("gpt-5-mini", model_provider="openai",
temperature=0)
# 返回 langchain_deepseek.ChatDeepSeek 实例
deepseek_model = init_chat_model("deepseek-chat", model_provider="deepseek",
temperature=0)
# 由于所有模型集成都实现了ChatModel接⼝,因此可以以相同的⽅式使⽤它们。
print("gpt-5-mini: " + gpt_model.invoke("what's your name").content + "\n")
print("deepseek-chat: " + deepseek_model.invoke("what's your name").content +
"\n")返回结果
bash
gpt-5-mini: I'm called ChatGPT. How can I assist you today?
deepseek-chat: I'm DeepSeek Chat! 😊 You can call me DeepSeek or just Chat if
you'd like. I'm here to help with anything you need---ask me anything! �示例2 可配置模型
python
config_model1 = init_chat_model()
messages = [
SystemMessage(content="请补全一段故事,100个字以内:"),
HumanMessage(content="一只狗正在__?")
]
result = config_model1.invoke(
input=messages,
config={
"configurable":{
"model": "deepseek-chat"
}
}
)
print(result.content)示例3 动态配置
python
# 可配置模型模拟器
configurable_model_2 = init_chat_model(
model="gpt-5-mini",
temperature=0,
configurable_fields=("model", "model_provider", "temperature",
"max_tokens"),
config_prefix="first",
)
# 动态修改配置,初始化模型并调⽤
configurable_result_2 = configurable_model_2.invoke(
"what's your name?",
config={
"configurable": {
"first_model": "deepseek-chat",
"first_temperature": 0.5,
"first_max_tokens": 100,
}
},
)
print("configurable2: " + configurable_result_2.content + "\n")1.3 本地部署LLM应以聊天模型
python
from langchain_ollama import ChatOllama
ollama_model = ChatOllama(model="deepseek-r1:70b",
base_url='http://192.168.100.220:11434')
result = ollama_model.invoke("what's your name?")
print(result)2. 工具调用
纯聊天模型(比如 GPT-3.5/4、DeepSeek)的短板是:只有训练数据里的知识,没有实时数据 (比如今天的天气)、计算能力 (比如复杂算术)、外部系统交互能力(比如查你的数据库)。
工具调用就是给聊天模型 "装插件":
- 你先定义好可用的工具(比如 "查天气""执行加法计算""查股票价格");
- 聊天模型会自主分析用户问题,判断:✅ "这个问题需要调用工具吗?"✅ "需要调用哪个 / 哪些工具?"✅ "调用工具需要传什么参数?"
- 模型生成工具调用指令,执行工具并获取结果;
- 模型把工具结果整合到回答里,最终返回给用户。
举个直观例子:
用户问:"今天北京的气温加 10 是多少?"
- 模型判断:需要先调用 "查北京气温" 工具,再调用 "加法计算" 工具;
- 调用 "查气温" 工具,得到结果:北京今天 15℃;
- 调用 "加法计算" 工具,参数是 15+10,得到 25;
- 模型整合结果:"今天北京气温是 15℃,加 10 后是 25℃。"
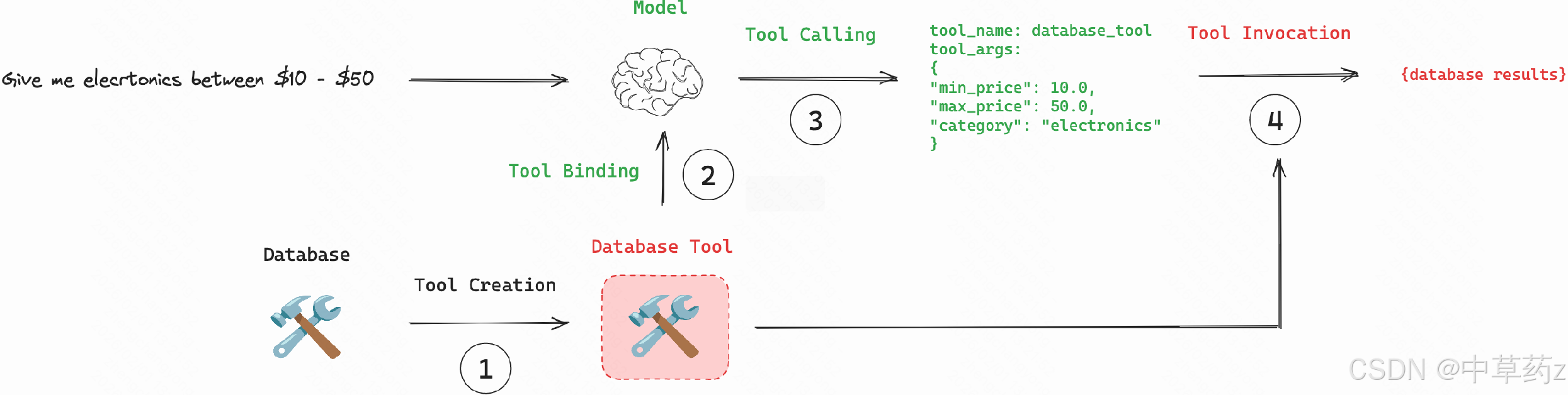
作用
- 扩展能力边界:借助工具完成计算、联网搜索、数据库查询等自身无法实现的任务。
- 保证信息实时性:获取训练数据中没有的最新信息,避免回答过时或错误。
- 处理复杂任务:将复杂请求拆解为多步骤,协调不同工具协作完成(这一点在 Agent 智能体中体现得尤为明显)。
- 连接现有系统:把企业内部的系统、API 和数据库封装成工具,让 LLM 成为自然语言驱动的统一接口,大幅提升自动化与集成能力。
2.1 创建工具
定义工具的底层逻辑:工具名称、工具描述、工具参数
使用@tool装饰器创建工具
python
from langchain_core.tools import tool
@tool
def calculate(a: int, b: int)-> int:
"""
Ryan式计算结果
Args:
a: 第一个整数
b: 第二个整数
"""
return a+b+1
print(calculate.invoke({"a": 1, "b": 2}))
注意
该装饰器固定使用函数名称作为工具名称
函数的文档字符串(docstring)必须写清楚:模型会通过这个描述判断什么时候用这个工具、传什么参数(这是工具调用的关键!)
因此 函数名,类型提示,文档字符串都是传递给工具Schema的一部分
在大语言模型(LLM)的工具调用场景里,工具的 Scheme(也叫工具协议 / 工具定义规范),是指给模型提供的一份 "工具使用说明书",它用结构化的方式定义了工具的功能、参数、返回值等信息,让模型能清晰理解工具的用途和调用方式。
简单来说,Scheme 就是模型和工具之间的 "沟通语言",确保模型能准确判断何时调用工具、如何传参。
核心组成部分(以 LangChain 为例)
一个完整的工具 Scheme 通常包含以下关键信息:
工具元信息
name:工具的唯一标识名称(如get_weather),模型用它来指定要调用的工具。description:工具的功能描述(如 "获取指定城市的实时气温"),这是模型判断是否需要调用该工具的核心依据。参数定义
parameters:定义工具所需的输入参数,包括参数名、类型(如str/int)、是否必填、参数描述。- 例如:
get_weather工具的参数city是字符串类型,必填,描述为 "城市名称(如北京、上海)"。返回值定义
- 说明工具执行后返回的数据类型和格式(如 "返回该城市的实时气温字符串"),帮助模型理解工具结果并整合到回答中。
因此,工具的Schema需要解析google风格的文档字符串去获取参数描述
google风格字符串具有极高的可读性和简洁性
pythondef fetch_data(url, retries=3): """从给定的URL获取数据。 Args: url (str): 要从中获取数据的URL。 retries (int, optional): 失败时重试的次数。默认为3。 Returns: dict: 从URL解析的JSON响应。 """ # ... 函数实现 ...
此外传递信息给工具的schema还有这些方式
1. 依赖pydantic
python
from langchain_core.tools import tool
from pydantic import BaseModel, Field
class CaculateInput(BaseModel):
"""Ryan计算"""
a: int = Field(..., description="第一个参数")
b: int = Field(..., description="第二个参数")
@tool(args_schema=CaculateInput)
def calculate(a: int, b: int) -> int:
return a + b + 2
print(calculate.invoke({"a": 1, "b": 2}))class CaculateInput(BaseModel):定义一个继承自 Pydantic BaseModel的类,作为calculate工具的输入参数 schema(也就是之前聊的 "工具 Scheme");
BaseModel:所有 Pydantic 模型的基类,继承它就拥有了数据验证能力。
Field(...):用于给字段添加约束和描述
...表示该字段是必填项,不传会直接报错。description是字段的说明,在 LangChain 中会成为工具 Scheme 的一部分,让 LLM 理解参数含义。
2. 依赖于Annotated
也可以使用Annotated去传递工具Schema
python
@tool
def calculate(
a: Annotated[int,...,"第一个参数"],
b: Annotated[int,...,"第二个参数"]
)-> int:
"""Ryan计算"""
return a+b+3
print(calculate.invoke({"a": 1, "b": 2}))Annotated 是一个核心工具,它的本质是给类型添加 "元数据标签",让框架能读懂你的类型约束、描述等额外信息。
2. 使用StructuredTool来初始化工具
java
classmethod from_function(
func: Callable | None = None,
coroutine: Callable[[...], Awaitable[Any]] | None = None,
name: str | None = None,
description: str | None = None,
return_direct: bool = False,
args_schema: type[BaseModel] | dict[str, Any] | None = None,
infer_schema: bool = True,
*,
response_format: Literal['content', 'content_and_artifact'] = 'content',
parse_docstring: bool = False,
error_on_invalid_docstring: bool = False,
**kwargs: Any,
) → StructuredTool关键参数
func:要设置的⼯具函数
coroutine:协程函数,要设置的异步⼯具函数
name:⼯具名称。默认为函数名称。
description:⼯具描述。默认为函数⽂档字符串。
args_schema:⼯具输⼊参数的schema。默认为 None。
response_format:⼯具响应格式。默认为"content"。
- 如果配置为 "content" ,则⼯具的输出为 ToolMessage 的 content 属性。
- 对于 HumanMessage 、 AIMessage 已经⻅过,分别表⽰ ⽤⼾消息 和 AI消息响应 ,
- 对于 ToolMessage ,它表⽰对应⼯具⻆⾊所发出的消息。
- 如果配置为 "content_and_artifact" ,则输出应是与 ToolMessage 的 content 属性与 artifact 属性相对应的⼆元组。
常规用法
python
def calculate(a:int, b:int) -> int:
"""Ryan计算"""
return a+b+2
calculate_tool = StructuredTool.from_function(calculate)
print(calculate_tool.invoke({"a": 1, "b": 2}))加上配置,依赖pydantic
python
from langchain_core.tools import StructuredTool
from pydantic import BaseModel, Field
class CalculatorInput(BaseModel):
a: int = Field(description="first number")
b: int = Field(description="second number")
def multiply(a: int, b: int) -> int:
return a * b
calculator_tool = StructuredTool.from_function(
func=multiply,
name="Calculator",
description="两数相乘",
args_schema=CalculatorInput,
)
print(calculator_tool.invoke({"a": 2, "b": 3})) # 输出:6
print(calculator_tool.name) # 输出:Calulate如上可见,我们上述的方式都返回的原生数据,而简单的content并不能满足实际所需,因此
我们需要指定 response_format="content_and_artifact
python
class AddInput(BaseModel):
a:int = Field(description="第一个整数")
b:int = Field(description="第二个整数")
def add(a: int, b: int) -> Tuple[str, List[int]]:
nums = [a, b]
content = f"{nums}相加的结果是{a + b}"
return content, nums
add_tool = StructuredTool.from_function(
func=add,
name="ADD", # 工具名
description="两数相加", # 工具描述
args_schema=AddInput, # 工具参数
response_format="content_and_artifact"
)
# 模拟大模型调用姿势
print(add_tool.invoke(
{
"name": "ADD",
"args": {"a": 3, "b": 4},
"type": "tool_call", # 必填
"id": "111", # 必填, 用来将工具调用请求和结果关联起来。
}
))
2.2 绑定、调用工具
为了实现这些功能给大模型
我们需要用到 bind_tools() 方法
python
bind_tools(
tools: Sequence[dict[str, Any] | type | Callable | BaseTool],
*,
tool_choice: dict | str | Literal['auto', 'none', 'required', 'any'] | bool
| None = None,
strict: bool | None = None,
parallel_tool_calls: bool | None = None,
**kwargs: Any,
) → Runnable[PromptValue | str | Sequence[BaseMessage | list[str] |
tuple[str, str] | str | dict[str, Any]], BaseMessage]-
tools:绑定到此聊天模型的工具定义列表。支持的类型为:字典、pydantic.BaseModel 类、Python 函数和 BaseTool(如@tool装饰器创建的类)。 -
tool_choice(默认空):要求模型调用哪个工具。可以设置为:- 形式为
'<tool_name>'的 str:调用<tool_name>工具。 'auto':自动选择工具(包括无工具)。'none':不调用工具。'any'或'required'或True:强制调用至少一个工具。False或None:无效果,默认 OpenAI 的行为。
- 形式为
-
strict(默认空):- 如果为
True,则保证模型输出与工具定义中提供的 JSON Schema 完全匹配。输入也将根据提供的 Schema 进行验证。 - 如果为
False,则不会验证输入,也不会验证模型输出。 - 如果为
None,则不会将strict参数传递给模型。
- 如果为
-
parallel_tool_calls:默认为None,允许并行工具使用。设置为False以禁用并行工具。 -
kwargs(Any):任何附加参数都直接传递给bind()。
返回值:
- 返回一个 Runnable 实例。
- 该实例支持多种格式输入:
- 原始提示 PromptValue
- 字符串:
"上海天气如何?" - 消息或消息列表:
[HumanMessage(content="...")]
- 该实例的输出:
- 包含工具调用信息的 AIMessage
- 该实例支持多种格式输入:
示例
针对下述代码
python
from langchain.chat_models import init_chat_model
from langchain_core.tools import tool
from pydantic import BaseModel, Field
class CalculateInput1(BaseModel):
"""Ryan计算"""
a: int = Field(..., description="第一个参数")
b: int = Field(..., description="第二个参数")
class CalculateInput2(BaseModel):
"""郑式计算"""
a: int = Field(..., description="第一个参数")
b: int = Field(..., description="第二个参数")
@tool(args_schema=CalculateInput1)
def calculate_with_ryan(a: int, b: int) -> int:
return a + b + 2
@tool(args_schema=CalculateInput2)
def calculate(a: int, b: int) -> int:
return a * b + 2
tools=[calculate_with_ryan, calculate]
model = init_chat_model("deepseek-chat", model_provider="deepseek", temperature=0.3)
model_with_tools=model.bind_tools(tools=tools)
print(model_with_tools.invoke("2和3的Ryan计算结果和郑式计算结果是多少"))分析结果
python
【核心响应内容】
content='我来帮你计算2和3的Ryan计算结果和郑式计算结果。'
【附加参数】与消息关联的其他负载有效数据
additional_kwargs={'refusal': None}
【响应元数据】
response_metadata={
'token_usage': {
'completion_tokens': 119,
'prompt_tokens': 400,
'total_tokens': 519,
'completion_tokens_details': None,
'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 384},
'prompt_cache_hit_tokens': 384,
'prompt_cache_miss_tokens': 16
},
'model_provider': 'deepseek',
'model_name': 'deepseek-chat',
'system_fingerprint': 'fp_eaab8d114b_prod0820_fp8_kvcache',
'id': 'b57ed2ac-ab9a-42bd-8d7e-8477c2c41f96',
'finish_reason': 'tool_calls',
'logprobs': None
}
【LangChain运行ID】
id='lc_run--019c1827-2c3d-7070-8717-26c9c7f4877b-0'
【工具调用列表】
tool_calls=[
{'name': 'calculate_with_ryan', 'args': {'a': 2, 'b': 3}, 'id': 'call_00_efAoVU3LvoHgXASJsSoh291k', 'type': 'tool_call'},
{'name': 'calculate', 'args': {'a': 2, 'b': 3}, 'id': 'call_01_OMQUKSR38dfPUJOcMP0zo9o4', 'type': 'tool_call'}
]
【无效工具调用】
invalid_tool_calls=[]
【使用元数据】
usage_metadata={
'input_tokens': 400,
'output_tokens': 119,
'total_tokens': 519,
'input_token_details': {'cache_read': 384},
'output_token_details': {}
}模型会根据输入的相关性去调用工具,我们也可以强行调用工具
python
model_with_tools = model.bind_tools(tools, tool_choice="any")我们知道输出的结果是一个AIMessage,如果调用工具之后,会有一个参数叫做 tool_calls 属性
我们可以看到结果里并没有我们想要的结果,因此我们需要将工具输出传递给聊天模型
python
from langchain.chat_models import init_chat_model
from langchain_core.messages import HumanMessage
from langchain_core.tools import tool
from pydantic import BaseModel, Field
class CalculateInput1(BaseModel):
"""Ryan计算"""
a: int = Field(..., description="第一个参数")
b: int = Field(..., description="第二个参数")
class CalculateInput2(BaseModel):
"""郑式计算"""
a: int = Field(..., description="第一个参数")
b: int = Field(..., description="第二个参数")
@tool(args_schema=CalculateInput1)
def calculate_with_ryan(a: int, b: int) -> int:
return a + b + 2
@tool(args_schema=CalculateInput2)
def calculate(a: int, b: int) -> int:
return a * b + 2
tools=[calculate_with_ryan, calculate]
model = init_chat_model("deepseek-chat", model_provider="deepseek", temperature=0.3)
model_with_tools=model.bind_tools(tools=tools,tool_choice="any")
messages = [
HumanMessage("2和3的Ryan计算结果和郑式计算结果是多少"),
]
ai_message = model_with_tools.invoke(messages)
messages.append(ai_message)
# 构造ToolMessage
# {'name': 'calculate_with_ryan', 'args': {'a': 2, 'b': 3}, 'id': 'call_00_DdabN1GMiupyjYDIYubXxk4Q', 'type': 'tool_call'}
# {'name': 'calculate', 'args': {'a': 2, 'b': 3}, 'id': 'call_01_LNeNF9O8duWJnW5rKtaN4D0r', 'type': 'tool_call'}
for tool_call in ai_message.tool_calls:
selected_tool = {"calculate_with_ryan": calculate_with_ryan,
"calculate": calculate}[tool_call["name"].lower()]
tool_msg = selected_tool.invoke(tool_call)
messages.append(tool_msg)
print(model.invoke(messages))我们可以看到整个流程我们实际调用了两次大模型
第⼀次:仅将【 HumanMessage 】发送给聊天模型进⾏处理,结果返回了【包含⼯具调⽤的AIMessage 】,并没有返回我们想要的结果。然后我们执⾏⼯具,得到 ToolMessage 。
第⼆次:将【 HumanMessage + AIMessage + ToolMessage 】消息记录发送给聊天模型进⾏处理,结果返回了【包含结果的 AIMessage 】
2.3 LangChain提供工具
我们并不需要手搓所有的工具,他提供了很多现成的
https://docs.langchain.com/oss/python/integrations/providers/overview
3. 结构化输出
结构化输出解决的是从字符串到对象的范式转换,要想使用结构化输出的能力
LangChain 提供了⼀种⽅法 .with_structured_output() ,该⽅法需要先定义输出结构,然后执⾏通过 .with_structured_output() 得到的 Runnable 实例
with_structured_output()
bash
with_structured_output(
schema: dict[str, Any] | type[_BM] | type | None = None,
*,
method: Literal['function_calling', 'json_mode', 'json_schema'] =
'json_schema',
include_raw: bool = False,
strict: bool | None = None,
**kwargs: Any,
) → Runnable[PromptValue | str | Sequence[BaseMessage | list[str] |
tuple[str, str] | str | dict[str, Any]], dict | _BM]- schema:表示输出结构。可以传入为:JSON、TypedDict、Pydantic、OpenAI 函数 / 工具
- method:表示 LLM 的生成方法:
json_schema(默认):表示使用 OpenAI 的结构化输出 API。function_calling:使用 OpenAI 的工具调用(以前称为函数调用)json_mode:使用 OpenAI 的 JSON mode。请注意,如果使用json_mode,则必须在模型调用中包含将输出格式化为所需schema的说明。
- include_raw:
- 如果为
False(默认),则仅返回解析的结构化输出。如果在模型输出解析过程中发生错误,则会引发错误。 - 如果为
True,则将返回原始模型响应(BaseMessage)和解析的模型响应。如果在输出解析过程中发生错误,它也会被捕获并返回。最终输出始终是带有键 "raw"、"parsed" 和 "parsing_error" 的字典。
- 如果为
- strict:
- 如果为
True,保证模型输出与schema完全匹配。输入schema也将根据支持的schema进行验证。 - 如果为
False,输入schema将不会被验证,模型输出也不会被验证。 - 如果为
None(默认),则不会将strict参数传递给模型。
- 如果为
- tools :要绑定到聊天模型的工具列表。要求:
method为'json_schema'、strict=True、include_raw=True。则生成的 AIMessage 将在'raw'中包含工具调用 - kwargs (Any):任何附加参数都直接传递给 bind ()。
返回一个 Runnable 实例。将来执行时:
- 如果
include_raw=False- 且
schema是 Pydantic 类,则 Runnable 会输出 Pydantic 对象。 - 否则 Runnable 输出一个字典。
- 且
- 如果
include_raw=True,则 Runnable 输出一个带有键的字典:'raw':BaseMessage'parsed':如果出现解析错误,则为 None,否则类型取决于如上所述的schema。'parsing_error':OptionalBaseException
3.1 返回Pydantic对象
我们可以设置执⾏ Runnable 后的输出结果指定为 Pydantic 类,这将返回⼀个 Pydantic 对象。
python
from typing import Optional
from langchain.chat_models import init_chat_model
from pydantic import BaseModel, Field
model = init_chat_model("deepseek-chat", model_provider="deepseek", temperature=0.3)
class Joke(BaseModel):
"""给用户讲的一个笑话"""
setup: str = Field(description="这个笑话的开头")
punchline: str = Field(description="这个笑话的妙语")
rating: Optional[int] = Field(default=None, description="从1-10分,给这个笑话评分")
structured_model = model.with_structured_output(Joke)
print(structured_model.invoke("给我讲一个关于狗的笑话"))
3.2 返回TypedDict
python
from langchain_openai import ChatOpenAI
from typing import Optional
from typing_extensions import Annotated, TypedDict
# 定义⼤模型
model = ChatOpenAI(model="gpt-4o-mini")
# 定义输出结构: TypedDict
class Joke(TypedDict):
"""给⽤⼾讲⼀个笑话。"""
setup: Annotated[str, ..., "这个笑话的开头"]
punchline: Annotated[str, ..., "这个笑话的妙语"]
rating: Annotated[Optional[int], None, "从1到10分,给这个笑话评分"]
structured_model = model.with_structured_output(Joke)
result = structured_model.invoke("给我讲⼀个关于唱歌的笑话")
print(result)结果
python
{'setup': '为什么歌⼿总是带⼀把伞?', 'punchline': '因为他们怕下⾬时会错过⾳调!',
'rating': 7}如果包含 include_raw=True
python
{
'raw': AIMessage(content='{"setup":"你知道为什么歌⼿总是喜欢在吃饭的时候唱歌
吗?","punchline":"因为他们想要增加⾃⼰的'调味'!","rating":7}', additional_kwargs=
{'parsed': None, 'refusal': None}, response_metadata={'token_usage':
{'completion_tokens': 40, 'prompt_tokens': 173, 'total_tokens': 213,
'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens':
0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0},
'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}},
'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_560af6e559',
'id': 'chatcmpl-C6WinVyn0c2VI2wcNQerfrmI3GdNA', 'service_tier': 'default',
'finish_reason': 'stop', 'logprobs': None}, id='run--00d306c7-8797-4f20-90cb-
65e5b32358b4-0', usage_metadata={'input_tokens': 173, 'output_tokens': 40,
'total_tokens': 213, 'input_token_details': {'audio': 0, 'cache_read': 0},
'output_token_details': {'audio': 0, 'reasoning': 0}}),
'parsed': {'setup': '你知道为什么歌⼿总是喜欢在吃饭的时候唱歌吗?', 'punchline':
'因为他们想要增加⾃⼰的'调味'!', 'rating': 7},
'parsing_error': None}3.3 返回Json
python
from langchain_openai import ChatOpenAI
# 定义⼤模型
model = ChatOpenAI(model="gpt-4o-mini")
json_schema = {
"title": "joke",
"description": "给⽤⼾讲⼀个笑话。",
"type": "object",
"properties": {
"setup": {
"type": "string",
"description": "这个笑话的开头",
},
"punchline": {
"type": "string",
"description": "这个笑话的妙语",
},
"rating": {
"type": "integer",
"description": "从1到10分,给这个笑话评分",
"default": None,
},
},
"required": ["setup", "punchline"],
}
structured_model = model.with_structured_output(json_schema)
result = structured_model.invoke("给我讲⼀个关于唱歌的笑话")
print(result)
python
{'setup': '为什么唱歌的⼈总是很开⼼?', 'punchline': '因为他们总是有很多⾳符可供选
择!', 'rating': 7}3.4 组合输出格式
python
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from typing import Optional, Union
# 定义⼤模型
model = ChatOpenAI(model="gpt-4o-mini")
class Joke(BaseModel):
"""给⽤⼾讲⼀个笑话。"""
setup: str = Field(description="这个笑话的开头")
punchline: str = Field(description="这个笑话的妙语")
rating: Optional[int] = Field(
default=None, description="从1到10分,给这个笑话评分"
)
class ConversationalResponse(BaseModel):
"""以对话的⽅式回应。待⼈友善,乐于助⼈。"""
response: str = Field(description="对⽤⼾查询的会话响应")
class FinalResponse(BaseModel):
final_output: Union[Joke, ConversationalResponse]
structured_model = model.with_structured_output(FinalResponse)
result = structured_model.invoke("给我讲⼀个关于唱歌的笑话")
print(result)
result = structured_model.invoke("你好")
print(result)
python
final_output=Joke(setup='为什么歌⼿总是带着梯⼦?', punchline='因为他们想要达到更⾼的
⾳调!', rating=7)
final_output=ConversationalResponse(response='你好!有什么我可以帮助你的吗?')实际应用示例
python
from langchain.chat_models import init_chat_model
from langchain_openai import ChatOpenAI
from typing import Optional
from pydantic import BaseModel, Field
from langchain_core.messages import HumanMessage, SystemMessage
# 定义大模型
model = init_chat_model("deepseek-chat", model_provider="deepseek", temperature=0.3)
class Person(BaseModel):
"""一个人的信息。"""
# 注意:
# 1. 每个字段都是 Optional "可选的" ------ 允许 LLM 在不知道答案时输出 None。
# 2. 每个字段都有一个 description "描述" ------ LLM使用这个描述。
# 有一个好的描述可以帮助提高提取结果。
name: Optional[str] = Field(default=None, description="这个人的名字")
hair_color: Optional[str] = Field(default=None, description="如果知道这个人头发的颜色")
skin_color: Optional[str] = Field(default=None, description="如果知道这个人的肤色")
height_in_meters: Optional[str] = Field(default=None, description="以米为单位的高度")
structured_model = model.with_structured_output(schema=Person)
messages = [
SystemMessage(content="你是一个提取信息的专家,只从文本中提取相关信息。如果您不知道要提取的属性的值,属性值返回null"),
HumanMessage(content="史密斯身高6英尺,金发。")
]
result = structured_model.invoke(messages)
print(result)
python
name='史密斯' hair_color='⾦发' skin_color=None height_in_meters='1.83'4. 流式输出
4.1 stream()同步输出
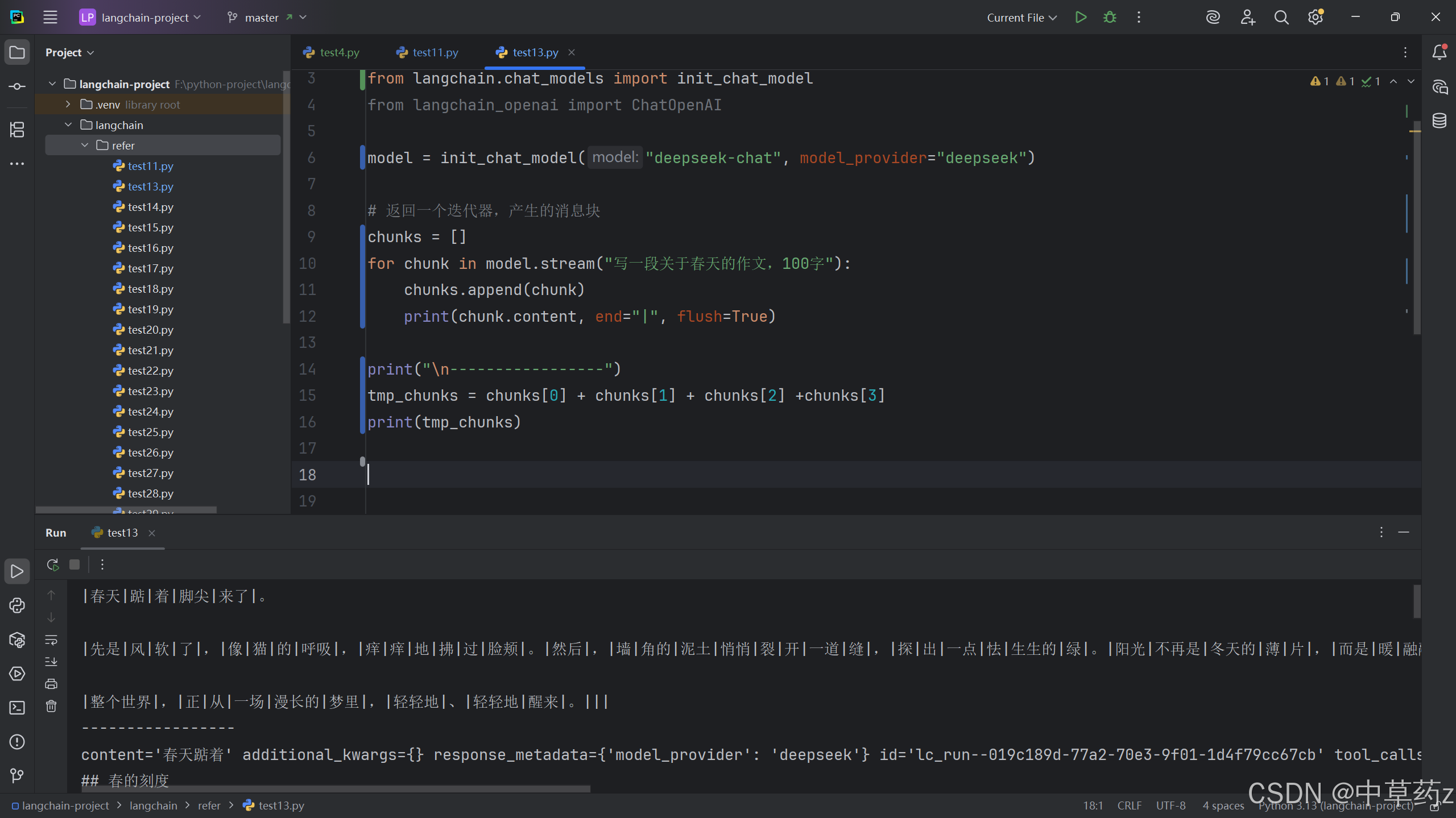
stream()方法会返回一个迭代器,他会在输出的时候同步输出消息块,可以使用for循环处理

4.2 异步输出 使用astream()
流式输出的更多的场景是一个异步场景
异步方式:asyncio,协程,事件循环
asyncio 是 Python 异步编程的标准库 ,协程是异步的任务单元 ,事件循环是异步任务的调度器 ------ 三者的关系:事件循环(管家)调度多个协程(可暂停的任务),asyncio 封装了这一切的工具集。
协程(Coroutine):可暂停的 "特殊函数"
-
通俗解释:像 "能中途暂停、事后恢复" 的任务。比如你煮泡面(协程),煮水时不用干等,先去切火腿肠(另一个协程),水开了再回来继续煮面。
-
语法特征:
- 用
async def定义(区别于普通def); - 内部用
await标记 "需要暂停的地方"(比如等网络请求、等延迟)。
- 用
-
极简例子 :
python# 定义一个协程(可暂停的任务) async def make_noodles(): print("开始煮水...") await asyncio.sleep(2) # 暂停2秒(模拟等水开,非阻塞) print("水开了,下面!") return "泡面做好了" -
关键区别:普通函数调用后 "一路执行到底",协程调用后不会立即执行,需要交给事件循环调度。
python
from langchain_openai import ChatOpenAI
# 定义⼤模型
model = ChatOpenAI(model="gpt-4o-mini")
# 异步调⽤
async def async_stream():
print("=== 异步调⽤ ===")
async for chunk in model.astream("讲⼀个50字的笑话"):
print(chunk.content, end="|", flush=True)
import asyncio
asyncio.run(async_stream())4.3 使用StrOutputParser
前面的 runnale 接口介绍
我们可以看出来流式传输并不算是聊天模型独有的能力
bash
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
# 定义⼤模型
model = ChatOpenAI(model="gpt-4o-mini")
# 定义输出解析器
parser = StrOutputParser()
# 定义链
chain = model | parser
for chunk in chain.stream("写⼀段关于爱情的歌词,需要5句话"):
print(chunk, end="|", flush=True)4.4 自定义流式输出解析器
前面提到聊天模型的stream()方法返回的是一个迭代器
python
from typing import Iterator, List
from langchain.chat_models import init_chat_model
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
# 组件1:聊天模型
model = init_chat_model("deepseek-chat", model_provider="deepseek")
# 组件2:输出解析器(str)
parser = StrOutputParser()
# 自定义生成器
def split_into_list(input: Iterator[str]) -> Iterator[List[str]]:
buffer = ""
for chunk in input:
buffer += chunk
# 遇到 。 需要刷新
while "。" in buffer:
# 找到 。的位置
stop_index = buffer.index("。")
# yield 用于创造生成器
# yield 是生成器核心:不会一次性返回所有结果,而是"按需生成"
yield [buffer[:stop_index].strip()]
# 是分隔「起始索引」和「结束索引」的必选标记
buffer = buffer[stop_index + 1 :]
# 处理buffer最后几个字
yield [buffer.strip()]
# 定义链
chain = model | parser | split_into_list
# 返回一个迭代器,产生的消息块
for chunk in chain.stream("写一段关于爱情的歌词,需要5句话,每句话用中文句号隔开。"):
# chunk: AIMessageChunk
# print(chunk.content, end="|", flush=True)
# 使用 parser,结果就是 str
print(chunk, end="|", flush=True)
bash
['在星空下许下承诺的誓⾔']|['你的笑容如同晨曦,温暖了我的⼼']|['⽆论时光如何流转,我愿与
你携⼿共⾏']|['爱情是我们⼼中永恒的旋律']|['每⼀次相拥,都是⼀场甜蜜的重逢']|['']|种一棵树最好的时间是十年前,其次是现在。 ------ 丹比萨・莫约
🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀
以上,就是本期的全部内容啦,若有错误疏忽希望各位大佬及时指出💐
制作不易,希望能对各位提供微小的帮助,可否留下你免费的赞呢🌸