摘要:在生成式 AI 与 Agent 技术爆发的今天,Nanobot 以"极简主义"为核心理念,用约 4,000 行代码实现了一个功能完整的个人 AI 助手运行时。本文将从官方文档出发,系统梳理 Nanobot 的核心概念、架构设计、记忆系统、技能扩展机制与部署实践,为开发者提供一份权威、详尽的技术参考。
一、什么是 Nanobot?重新定义个人 AI 助手
1.1 核心定位
Nanobot 是一个面向日常工作的通用 AI Agent 运行时 。它不是某个封闭的 SaaS 产品,也不是仅存在于网页聊天窗口中的"黑盒"服务,而是一个可以部署在你自己的机器上、完全由你掌控的智能体框架。
这意味着:
- 数据主权归你:所有对话历史、记忆文件、工作区数据均存储在本地
- 环境可控:在你的终端、你的工作目录、你的权限边界内运行
- 部署灵活:不绑定单一入口,可嵌入终端、即时通讯工具或自有系统
1.2 设计哲学:少即是多
与传统重量级 Agent 框架(如 LangChain、AutoGen)不同,Nanobot 选择了一条"向下兼容、向上轻量"的技术路线 \[4]:
| 维度 | Nanobot 的选择 | 传统框架的常见做法 |
|---|---|---|
| 代码规模 | ~4,000 行核心代码 | 数万行,依赖树庞大 |
| 抽象层级 | 最小必要抽象,代码可读性强 | 多层封装,学习成本高 |
| 扩展方式 | Markdown 声明式 Skills + 工具注册 | 代码级自定义 Chain/Agent |
| 适用场景 | 个人助手、轻量自动化、研究实验 | 企业级 RAG、复杂 Pipeline |
这种"极简主义"并非功能阉割,而是通过清晰的模块边界 与高效的数据流设计,在保持功能完整性的同时,大幅降低理解与维护成本。
二、核心架构:消息驱动的 Agent Loop
2.1 整体架构全景
Nanobot 采用经典的消息驱动架构(Message-Driven Architecture) + ReAct 循环(Reasoning + Acting):
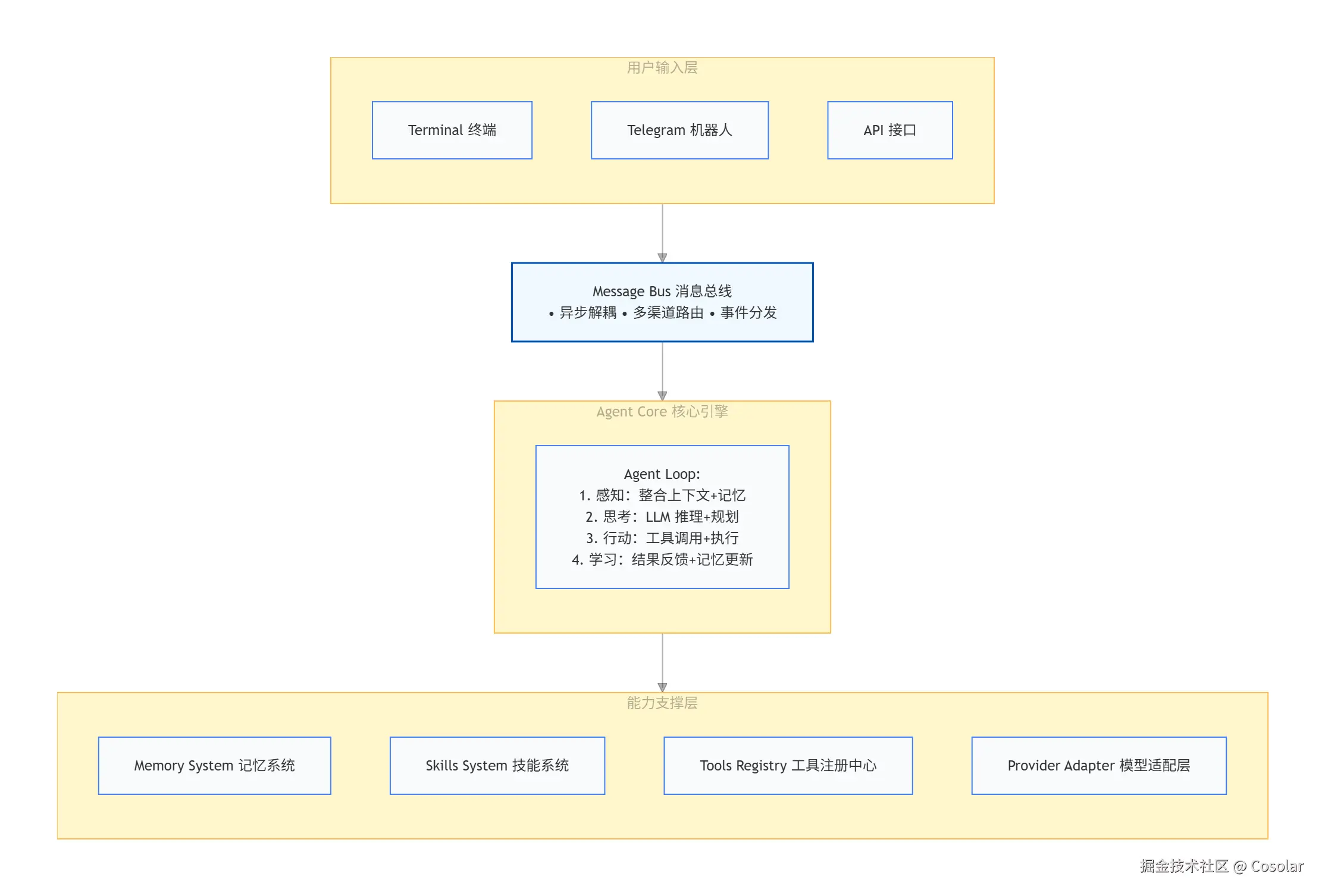
2.2 Agent Loop 四步闭环
Nanobot 的智能体循环完整实现了"感知-思考-行动-学习"的闭环流程:
-
感知(Perception)
- 捕获用户输入(文本/命令/消息)
- 整合短期对话历史、长期记忆、可用工具列表
- 通过
ContextBuilder动态组装系统提示词
-
思考(Reasoning)
- 调用配置的 LLM Provider 进行推理
- 支持 Function Calling 或 ReAct Prompt 两种工具调用协议
- 输出结构化决策:下一步行动 + 参数
-
行动(Acting)
- 解析 LLM 输出,校验工具调用合法性
- 执行内置工具(文件操作、Shell 命令、网络搜索等)或 MCP 工具
- 支持异步任务与超时熔断,避免阻塞主流程
-
学习(Learning)
- 将执行结果反馈给 LLM,支持多轮迭代
- 触发记忆系统更新:短期对话归档、长期知识提炼
- 生成用户可读的最终回复
三、记忆系统:分层设计实现"有生命的记忆"
记忆管理是 Agent 系统的核心挑战。Nanobot 采用三层记忆架构,在上下文效率与长期知识保留之间取得平衡 。
3.1 记忆分层设计
bash
workspace/
├── SOUL.md # Bot 的人格与沟通风格(持久化)
├── USER.md # 用户偏好与稳定信息(持久化)
└── memory/
├── MEMORY.md # 项目事实、决策与上下文(持久化)
├── history.jsonl # 对话摘要归档(机器优先)
├── .cursor # Consolidator 写入游标
├── .dream_cursor # Dream 消费游标
└── .git/ # 长期记忆文件的版本历史3.2 两阶段记忆流转
Stage 1: Consolidator(对话摘要器)
当会话长度接近 LLM 上下文窗口限制时,Consolidator 会自动:
- 选取最早且安全的对话片段
- 调用 LLM 生成精炼摘要
- 以 JSONL 格式追加到
memory/history.json
json
{
"cursor": 42,
"timestamp": "2026-04-03 00:02",
"content": "- 用户偏好深色模式\n- 决定使用 PostgreSQL 作为数据库"
}该文件采用追加写入 + 游标管理设计,确保机器解析高效、人类可读性次之。
Stage 2: Dream(记忆提炼器)
Dream 是更慢速、更深思熟虑的记忆层,默认按定时任务(cron)运行:
- 读取
history.jsonl新条目 + 当前SOUL.md/USER.md/MEMORY.md - 分析"新信息"与"已有知识"的关联
- 以最小修改原则手术式更新长期记忆文件
这种设计使记忆系统具备解释性而非单纯归档:知识会随时间沉淀、关联、进化。
3.3 版本化与可审计性
所有长期记忆文件(SOUL.md/USER.md/MEMORY.md)的变更可通过 GitStore 记录版本历史,支持:
/dream-log:查看最新记忆变更/dream-restore <sha>:回滚到指定版本- 人工审查记忆演化过程
这使"自动记忆"不再是黑盒,用户始终保有检查、理解、恢复的控制权。
四、Skills 系统:声明式能力扩展
4.1 什么是 Skills?
Skills 是 Nanobot 的能力扩展单元,采用Markdown 声明式配置,无需编写复杂代码即可为 Agent 添加新能力。
4.2 Skill 文件结构示例
markdown
# 技能名称:代码审计助手
## 触发条件
当用户请求包含"review code", "检查漏洞", "安全扫描"时激活。
## 可用工具
- `run_shell`: 执行静态分析脚本
- `read_file`: 读取目标源码
## 执行规范
1. 优先读取文件内容
2. 调用 `run_shell` 执行审计命令
3. 输出结构化报告(漏洞类型、行号、修复建议)
## 输出格式
```json
{
"vulnerabilities": [...],
"suggestions": [...]
}4.3 执行流程
- 框架启动时扫描
skills/目录,解析 Markdown 结构 - 用户输入匹配触发条件时,自动加载对应 Skill 规范
- LLM 根据规范指导工具调用顺序与输出格式
- 结果经框架校验后返回用户
这种设计实现了能力扩展的低门槛 与执行过程的可控性的统一。
五、工具生态与多平台接入
5.1 内置工具链
Nanobot 预置 8+ 核心工具,覆盖高频自动化场景:
| 工具 | 功能 | 安全机制 |
|---|---|---|
filesystem |
安全目录下的文件读写 | 工作区沙箱限制 |
shell |
受限命令执行 | 白名单 + 超时熔断 |
web_search |
聚合搜索引擎(Bing/DuckDuckGo) | 结果过滤 + 速率限制 |
scheduler |
Cron 定时任务管理 | 任务权限校验 |
messaging |
跨平台消息推送 | 用户白名单 |
code_executor |
安全沙箱内代码运行 | 资源限制 + 输出审计 |
5.2 多平台接入能力
得益于 Platform Adapter 模式,Nanobot 可无缝接入多种通信渠道:
- 终端(CLI) :
nanobot agent直接对话,适合本地开发辅助 - 即时通讯:Telegram、WhatsApp、飞书、Discord 等,适合日常协作
- API 集成:通过 HTTP 接口嵌入自有系统,适合产品化集成
消息格式统一转换为框架内部标准事件,开发者只需关注业务逻辑,无需重复处理平台差异。
5.3 多模型兼容
通过 Provider 抽象层,支持主流大模型无缝切换:
json
{
"providers": {
"openrouter": { "apiKey": "sk-or-xxx", "baseUrl": "https://openrouter.ai/api/v1" },
"qwen": { "apiKey": "sk-xxx", "baseUrl": "https://dashscope.aliyuncs.com/compatible-mode/v1" },
"vllm": { "baseUrl": "http://localhost:8000/v1" }
},
"agents": {
"defaults": {
"model": "anthropic/claude-sonnet-4",
"provider": "openrouter",
"toolCallingStrategy": "function_calling"
}
}
}- 支持 OpenAI、Anthropic、DeepSeek、Qwen、Gemini、vLLM、Ollama 等
toolCallingStrategy可选function_calling(推荐)或react_prompt(兼容旧模型)
六、快速上手:5 分钟部署你的第一个 Nanobot
6.1 环境准备
- Python 3.11+(推荐)
- Git
- 稳定的网络环境(用于拉取模型 API)
6.2 安装与初始化
bash
# 方式1:pip 安装(推荐生产环境)
pip install nanobot-ai
# 方式2:uv 安装(更快依赖解析)
uv tool install nanobot-ai
# 方式3:源码安装(便于二次开发)
git clone https://github.com/HKUDS/nanobot.git
cd nanobot
pip install -e .
# 一键初始化配置
nanobot onboard
# 或使用交互式向导
nanobot onboard --wizard6.3 核心配置说明
配置文件位置:
- macOS/Linux:
~/.nanobot/config.json - Windows:
%USERPROFILE%\.nanobot\config.json
关键字段配置:
json
{
"providers": {
"openrouter": {
"apiKey": "sk-or-v1-xxxxxxxxxxxx"
}
},
"agents": {
"defaults": {
"model": "anthropic/claude-opus-4-5",
"provider": "openrouter",
"timezone": "Asia/Shanghai",
"dream": {
"intervalH": 2,
"maxBatchSize": 20
}
}
}
}6.4 启动与交互
bash
# 终端模式启动
nanobot agent
# 或连接特定平台
nanobot serve --platform telegram启动后,终端即成为你的 Agent"醒着的地方"。输入自然语言指令,即可体验:
- 读取本地代码库上下文
- 编辑文件、执行命令、搜索网络
- 多轮对话推进复杂任务
七、典型应用场景
7.1 全栈开发辅助
结合 filesystem + shell + web_search 工具,Nanobot 可充当本地开发环境的"结对编程伙伴":
- 自动读取项目结构,理解业务上下文
- 根据需求生成代码补丁、执行测试、提交 Git
- 配合 CI/CD 脚本实现轻量级自动化工作流
7.2 个人知识管理
通过记忆系统的 Dream 机制,Nanobot 可自动:
- 每日汇总技术笔记、会议要点、待办进度
- 将碎片对话提炼为结构化知识(
MEMORY.md) - 支持语义检索:"上周关于 Kubernetes 网络策略的讨论结论是什么?"
7.3 跨平台智能客服
利用多平台适配器,企业可将 Nanobot 部署为统一消息中枢:
- 用户从 Telegram/飞书/网页端发送请求
- Agent 根据意图分类调用内部 API(查订单、重置密码等)
- 通过 Skills 系统定义标准回复模板与权限边界
八、总结与展望
8.1 核心优势回顾
- 极简架构:~4,000 行代码实现完整 Agent 功能,代码可读性强,适合学习与二次开发
- 分层记忆:短期对话 + 长期知识 + 版本审计,平衡效率与持久化
- 声明式扩展:Markdown Skills 系统,低门槛添加新能力
- 多端兼容:终端/IM/API 多入口,灵活嵌入现有工作流
8.2 适用人群建议
✅ 推荐:
- 个人开发者构建专属数字助手
- 研究者验证 Agent 新算法/策略
- 小型团队快速搭建轻量自动化流程
❌ 暂不推荐:
- 需要复杂多智能体编排的企业级场景
- 对超长上下文(>128K)有强依赖的应用
- 要求开箱即用 GUI 配置面板的非技术用户
8.3 未来演进方向
根据社区规划,Nanobot 将持续优化:
- 多模态输入支持(图像/语音理解)
- 强化学习驱动的工具选择优化
- WebUI 可视化配置与监控面板
- 标准化 Skill 插件市场
📦 项目地址 :github.com/HKUDS/nanob...
📖 官方文档 :nanobot.wiki/cn/
💡 实践建议 :从
nanobot onboard --wizard开始,尝试在skills/目录编写第一个 Markdown 技能,体验"声明式扩展"带来的开发效率跃升。
在技术民主化的浪潮中,Nanobot 证明了一个真理:强大的工具未必复杂,清晰的抽象胜过冗长的封装。如果你正在寻找一个透明、轻量、可定制的 AI Agent 起点,Nanobot 值得纳入你的技术选型清单。