
当 Long-Running Agent 长程推理任务逐渐成为主流,需要面对的挑战:任务复杂度高、中间无人监督,一步错步步错,最怕上下文丢失,交付后纠正成本高。在这种情况下,怎么给AI布置任务、如何编排工作流就变成关键。
引言:当 AI Agent 成为主力开发者
2026 年 3 月,Claude Code 源码因打包失误意外泄露。48 小时内,开发者 Yeachan Heo (@sigridjineth)发起了 claw-code 项目------先用 Python 做 clean-room 重写,再将整个代码库迁移到 Rust。这个项目最终产出了 48,599 行 Rust 代码 ,由仅 2 位开发者 + 10 个自治 AI "Claws" 协同完成,成为 GitHub 历史上最快突破 100K Star 的仓库(截至 2026 年 4 月已达 182K Star)。
但如果你只盯着这些 Rust 文件,你看错了层。
作者在项目的 PHILOSOPHY.md 中写得很明确:
"If you only look at the generated files in this repository, you are looking at the wrong layer."
Python 重写是副产品,Rust 重写也是副产品。真正值得研究的是产出这些代码的系统本身------一个基于 clawhip 的协调循环,人类提供方向,自治 Claws 执行劳动。
本文将完整拆解这套系统的工作流、任务布置机制、验收体系和背后的方法论,为 AI 驱动的大型项目开发提供一份可落地的参考框架。
一、项目全景:谁做了什么
1.1 项目概况
| 维度 | 数据 |
|---|---|
| 项目名称 | claw-code(ultraworkers/claw-code) |
| 定位 | Claude Code agent harness 的 clean-room 重写 |
| 语言 | Rust 96.2%,Python 3.4% |
| 代码量 | 48,599 行 Rust |
| 人类开发者 | 2 人 |
| AI Agent 数量 | 10 个自治 Claws |
| GitHub Star | 182K(截至 2026-04) |
| Fork | 107K |
1.2 什么是 Clean-Room 重写
claw-code 不是 Claude Code 泄露源码的归档或复制。它是一种"洁净室重写"------通过阅读原始架构的结构模式,从零重新实现 相同的架构设计,而不复制任何 Anthropic 的专有代码。重写的模块覆盖了:CLI 入口、查询引擎、运行时会话管理、工具执行、权限上下文、会话持久化,以及一个显式跟踪与原始实现差距的 parity_audit.py。
1.3 关键人物
Yeachan Heo 此前被《华尔街日报》报道为全球最活跃的 Claude Code 重度用户之一,在 Anthropic 的消费排名中位列前几名,累计消耗超过 250 亿 Claude Code Token。这种深度使用经验,使他对"如何让 AI Agent 高效工作"形成了一套独特的方法论。
二、三层工具链体系:OmX + clawhip + OmO
作者构建了三个相互协作的工具,形成一个完整的 AI 驱动开发系统:
2.1 工具链全景
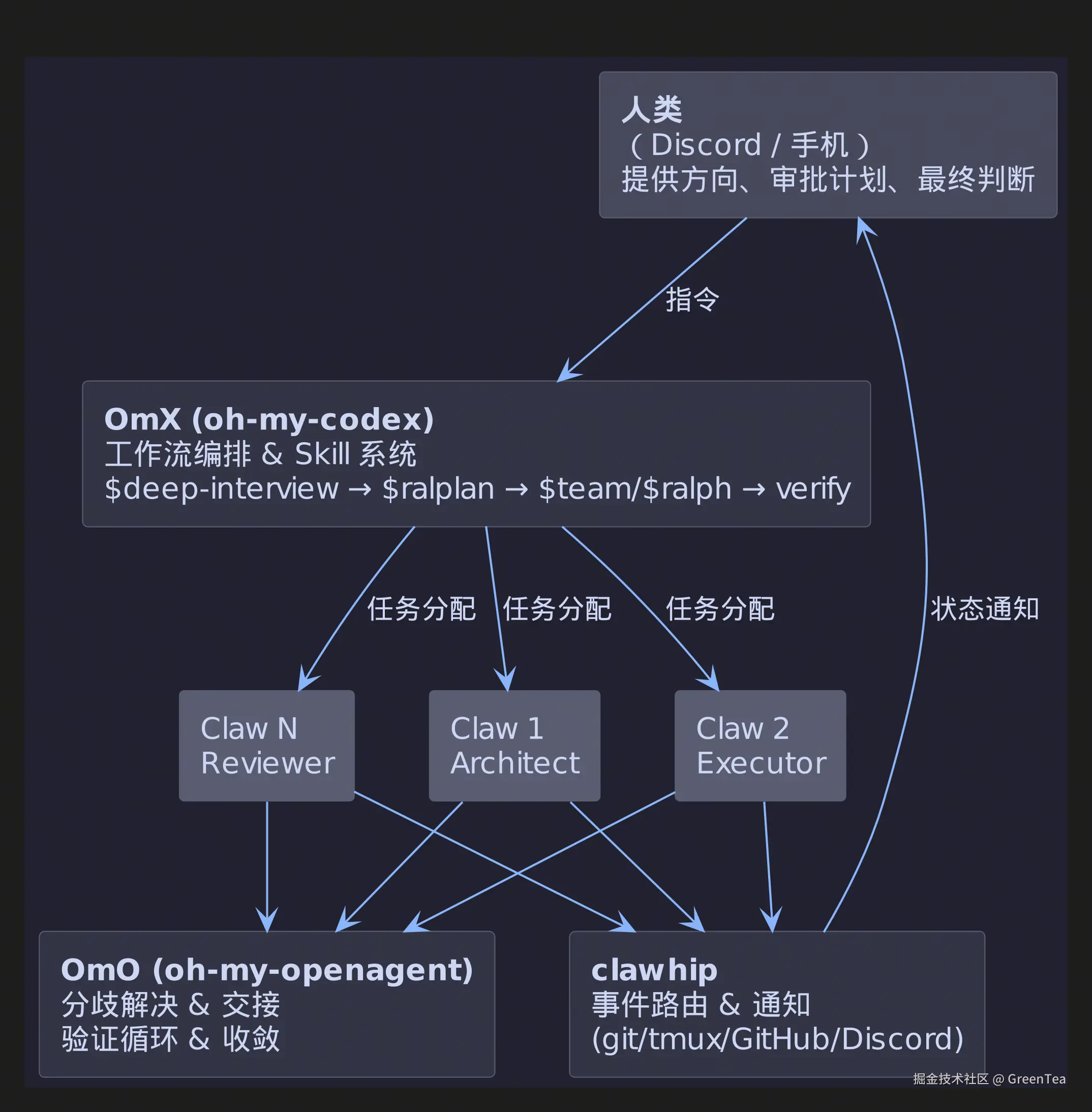
2.2 OmX(oh-my-codex)------ 工作流编排层
OmX 坐落在 OpenAI Codex CLI 之上,提供从模糊需求到完成交付的完整流水线。它将短指令转化为结构化的执行协议:
- 规划关键词 :如
$ralplan、$deep-interview - 执行模式 :如
$ralph(单人持久循环)、$team(多 Agent 并行) - 持久化验证循环:自动化的测试/构建/审查闭环
- 并行多 Agent 工作流:基于 tmux 的 Worker 分屏执行
2.3 clawhip ------ 事件与通知路由器
clawhip 的核心哲学是:把监控和状态通知推到 Agent 上下文窗口之外。它监控 git commits、tmux sessions、GitHub Issues/PR、Agent 生命周期事件,并将通知路由到 Discord 等外部渠道。
为什么这很重要?因为 上下文窗口 是 Agent 最珍贵的资源。Agent 不应该浪费 Token 在格式化状态报告和通知路由上,而应全力聚焦在实现上。
2.4 OmO(oh-my-openagent)------ 多 Agent 协调器
当 Architect、Executor 和 Reviewer 产生分歧时,OmO 提供收敛结构------规划、交接、分歧解决和验证循环。没有它,多 Agent 协作会陷入无限争论或各行其是的困境。
三、人机协作模式:Discord 作为人类界面
这是整套方法论中最具颠覆性的部分。作者在 PHILOSOPHY.md 中写道:
"The important interface here is not tmux, Vim , SSH, or a terminal multiplexer. The real human interface is a Discord channel."
3.1 工作模式
- 人类 在 Discord 频道中输入一句话指令(甚至从手机上)
- Claws(AI Agent 群)读取指令 → 分解任务 → 分配角色 → 编写代码 → 运行测试 → 讨论失败 → 恢复 → 通过后推送
- 人类可以走开、睡觉、做其他事
- clawhip 负责在 Agent 工作时将通知路由到 Discord,而不是挤占 Agent 的上下文窗口
3.2 人类角色的重新定义
当 Agent 团队可以在数小时内重建代码库时,稀缺资源变成了:
- 架构清晰度(architectural clarity)
- 任务分解能力(task decomposition)
- 判断力(judgment)
- 品味(taste)
- 哪些部分可并行、哪些必须约束 的认知
作者的原话:
"A fast agent team does not remove the need for thinking. It makes clear thinking even more valuable."
四、任务布置的四阶段流水线
这是整个体系中最核心的工程实践------作者并非简单地写一份 tasks.md 扔给 AI,而是构建了一条强制流水线,任何模糊的执行请求都会被门禁拦截并重定向到上游阶段:
bash
$deep-interview ──→ $ralplan ──→ $ralph / $team ──→ Verification
消歧 & 约束 共识规划 持久执行循环 证据验收关键设计:不允许跳步。 如果你直接对 Agent 说 ralph fix this 或 team improve performance,OmX 的 Pre-Execution Gate 会拦截并强制跳转到 $ralplan。只有携带具体信号(文件路径、Issue 号、函数名、编号步骤、验收标准、错误引用、代码块)的请求才能直接进入执行阶段。
4.1 阶段一:$deep-interview ------ 苏格拉底式消歧
在任何规划或实现之前,先通过结构化问答消除歧义。这是防止"一步错步步错"的第一道防线。
数学化歧义评分 :每轮问答后对多个维度打分 [0.0, 1.0],加权计算总歧义分数。
| 维度 | 权重(绿地项目) | 说明 |
|---|---|---|
| Intent(意图) | 0.30 | 要做什么 |
| Outcome(预期结果) | 0.25 | 做完后世界变成什么样 |
| Scope(范围) | 0.20 | 边界在哪里 |
| Constraints(约束) | 0.15 | 不能碰什么 |
| Success Criteria(成功标准) | 0.10 | 怎么算做完了 |
深度配置文件:
| 模式 | 歧义阈值 | 最大轮数 | 适用场景 |
|---|---|---|---|
--quick |
<= 0.30 | 5 轮 | 简单明确的任务 |
--standard(默认) |
<= 0.20 | 12 轮 | 标准任务 |
--deep |
<= 0.15 | 20 轮 | 高复杂度/高风险任务 |
即使数字达标也不能跳过的三个硬门:
- Non-goals(非目标)必须显式声明------明确说"不做什么"和"做什么"一样重要
- Decision Boundaries(决策边界)必须显式声明------AI 可以自主决定的范围
- 至少完成一次 Pressure Pass------用更深的假设/权衡追问回顾早期答案
挑战模式(自动触发的压力测试):
| 触发条件 | 模式 | 行为 |
|---|---|---|
| 第 2 轮+ | Contrarian | 挑战核心假设 |
| 第 4 轮+ | Simplifier | 探查最小可行范围 |
| 第 5 轮+(歧义>0.25) | Ontologist | 要求从本质层面重构问题 |
输出产物:
- 访谈记录:
.omx/interviews/{slug}-{timestamp}.md - 可执行规格:
.omx/specs/deep-interview-{slug}.md - 包含:意图、期望结果、范围、非目标 、决策边界、约束、可测试的验收标准、暴露的假设
4.2 阶段二:$ralplan ------ 三角色共识规划
将澄清后的需求转化为经过多角色共识的架构方案和实施计划。核心是 RALPLAN-DR 结构化审议:
三角色循环(最多 5 轮) :
Planner(规划者) 创建初始计划,必须包含:
- 3-5 条原则(Principles)
- 前 3 位决策驱动因素(Decision Drivers)
- >= 2 个可行方案,每个有优缺点
- 若只剩一个方案,必须给出淘汰其他方案的显式理由
Architect(架构师) 挑战计划:
- 必须提供最强的钢铁人反论点(steelman antithesis)------不是稻草人,是你能想到的最有力的反对意见
- 至少一个真实的权衡张力
- 可能的综合路径(synthesis)
Critic(评审者) 验证计划:
- 验证原则-方案一致性
- 验证替代方案的公平探索
- 验证风险缓解清晰度
- 验证验收标准可测试性
- 验证具体的验证步骤
高风险模式 (--deliberate 标志)额外要求:
- Pre-mortem(预验尸):列出 3 个可能的失败场景
- 扩展测试计划:覆盖 unit / integration / e2e / observability 四层
最终输出必须包含:
- ADR(架构决策记录):Decision / Drivers / Alternatives / Why chosen / Consequences / Follow-ups
- 可用 Agent 类型花名册
- Ralph 和 Team 两条路径的具体人员配置指导
- 各通道建议的推理级别
- 团队验证路径
Pre-Execution Gate(执行前门禁) :
这是一个关键的设计------模糊的执行请求(如 "ralph fix this"、"team improve performance")会被拦截并重定向到 ralplan。只有包含具体信号的请求才能直接通过:
| 可通过的信号 | 示例 |
|---|---|
| 文件路径 | fix src/lib.rs line 42 |
| Issue 号 | implement #17 |
| 函数名 | refactor parse_token() |
| 编号步骤 | step 3 of the plan |
| 验收标准 | until all tests pass |
| 错误引用 | fix the MissingCredentials error |
| 代码块 | 附带具体代码片段 |
用 force: 或 ! 前缀可绕过门禁------但这是显式的"我知道我在做什么"声明。
4.3 阶段三a:$ralph ------ 持久完成循环
Ralph 是单人负责的持久执行模式,保证任务完全完成且经过验证。
启动前的规划门禁 :ralph 激活时,必须先验证 .omx/plans/prd-*.md 和 .omx/plans/test-spec-*.md 存在,否则拒绝开始实现。这从源头阻止了"没有计划就开始干"。
执行步骤:
-
预上下文摄入 :组装/加载
.omx/context/{slug}-{timestamp}.md上下文快照 -
检查进度、TODO 列表
-
从上次中断处继续(支持会话恢复)
-
并行委派:按分层路由到专家 Agent
- LOW 层:简单查找(如文件位置确认)
- STANDARD 层:标准工作(如模块实现)
- THOROUGH 层:复杂分析(如架构变更、安全审计)
-
长操作后台运行
-
验证完成 ------必须有新鲜证据
-
架构师验证(分层策略)
-
强制 AI Slop 清理
-
Deslop 后回归再验证
最终检查清单(9 项硬编码,不可跳过) :
| # | 检查项 | 说明 |
|---|---|---|
| 1 | 原始任务所有需求已满足 | 不允许缩减范围 |
| 2 | 零 pending/in_progress 的 TODO | 不允许有遗留项 |
| 3 | 新鲜的测试运行输出显示全部通过 | 必须是当次运行的输出 |
| 4 | 新鲜的构建输出显示成功 | 不能引用旧的 |
| 5 | lsp_diagnostics 在受影响文件上显示 0 错误 | 静态分析 |
| 6 | 架构师验证通过(最低 STANDARD 层) | 独立角色验证 |
| 7 | AI Slop 清理器完成 | 清除 AI 生成的"口水话" |
| 8 | Deslop 后回归测试通过 | 清理后重跑测试 |
| 9 | 运行 /cancel 清理状态 | 状态卫生 |
关键约束:不允许用 "should work" 或 "looks good" 声称完成------必须有新鲜的测试/构建输出作为证据。
PRD 模式 (--prd 标志):自动将任务拆分为用户故事,每个故事包含可测试的验收标准:
json
{
"userStories": [{
"id": "US-001",
"title": "...",
"description": "As a [user], I want to [action] so that [benefit].",
"acceptanceCriteria": ["Criterion 1", "Typecheck passes"],
"priority": 1,
"passes": false
}]
}4.4 阶段三b:$team ------ 协调并行执行
基于 tmux 的多 Agent 并行执行模式:
- 在 tmux 分屏中启动真实的 Codex/Claude CLI Worker 会话
- Leader 选择模式、保持简报更新、委派有界工作、拥有验证权
- Worker 执行分配的切片、不重写全局计划、上报阻塞
生命周期协议:
- 启动团队并验证启动证据
- 用运行时/状态工具监控进度
- 等待终端任务状态(pending=0, in_progress=0, failed=0)
- 才能运行 shutdown
- 验证关闭证据和状态清理
4.5 $autopilot ------ 全自主端到端执行
将 2-3 行产品想法自主处理完整生命周期:
| 阶段 | 内容 |
|---|---|
| Phase 0 - Expansion | 将想法扩展为详细规格 |
| Phase 1 - Planning | 从规格创建实施计划 |
| Phase 2 - Execution | 用 Ralph + Ultrawork 并行实现 |
| Phase 3 - QA | 循环直到所有测试通过(最多 5 轮,同一错误 3 次则停止) |
| Phase 4 - Validation | 多角色并行审查:Architect + Security-reviewer + Code-reviewer,全部通过 |
| Phase 5 - Cleanup | 清理所有模式状态 |
五、ROADMAP.md:任务拆解的实战范本
claw-code 的 ROADMAP.md(86KB,524 行)是一份真实的、经过实战检验的任务拆解文档,展示了作者如何组织 75+ 个开发任务。
5.1 双层结构
Tier 1:五个战略阶段(能力路线图)
| Phase | 标题 | 任务数 | 定位 |
|---|---|---|---|
| Phase 1 | Reliable Worker Boot | #1-#3 | 握手生命周期、信任解析器、会话控制 API |
| Phase 2 | Event-Native Clawhip Integration | #4-#6 | 车道事件 schema、失败分类法、摘要压缩 |
| Phase 3 | Branch/Test Awareness and Auto-Recovery | #7-#9 | 过期分支检测、恢复配方、绿灯契约 |
| Phase 4 | Claws-First Task Execution | #10-#12 | 任务包、策略引擎、车道看板 |
| Phase 5 | Plugin and MCP Lifecycle Maturity | #13-#14 | 插件生命周期契约、MCP 对等性 |
Tier 2:即时 Backlog(Dogfood 驱动的 Issue Tracker)
| 优先级 | 含义 | 数量 | 状态 |
|---|---|---|---|
| P0 | 阻塞 CI 绿灯状态 | 12 项 | 全部 done |
| P1 | 阻塞集成接线 | 4 项 | 全部 done |
| P2 | 可部署性加固 | 29+ 项 | 大部分 done |
5.2 验收标准的两种写法
Phase 级别------行为不变式:
写成可测试的 "must be true" 陈述,而非用户故事:
csharp
Phase 1, Task #1 (Ready-handshake lifecycle):
Acceptance:
- prompts are never sent before `ready_for_prompt`
- trust prompt state is detectable and emitted
- shell misdelivery becomes detectable as a first-class failure state
perl
Phase 3, Task #9 (Green-ness contract):
Acceptance:
- no more ambiguous "tests passed" messaging
- merge policy can require the correct green level for the lane type
- a single hung test must not mask other failures
- when a CI job fails because of a hang, the worker must report it
as `test.hung` rather than a generic failureBacklog 级别------经验证据:
不是预设的 checklist,而是用实际通过的证据来标注 done:
bash
#17 (P0) --- done at 172a2ad
cargo test --workspace → 139 passed, 0 failed
re-verified 2026-04-11, CI green每个 done 标注包含:commit hash、具体测试命令和通过数量、CI 运行 URL、验证日期、受影响的文件路径和行数。
5.3 依赖关系的表达方式
依赖关系是叙事式的,而非 DAG 图。使用的模式包括:
- 优先级层级隐含顺序:P0 阻塞 CI → P1 阻塞集成 → P2 加固
#N交叉引用 :Task #21 → "resolved by the broader work tracked as #26"- "Sibling"/"companion" 语言:#40 和 #41 是 "siblings of the same root"
- 因果链叙事:#29 显式解释为什么 #28 不够
- 显式去范围标注:#31、#43、#63 标注为外部跟踪项,依赖上游系统
六、九车道并行开发:Rust 重构的具体实践
6.1 并行车道模型
作者将整个 Rust 重构拆分为 9 个独立的车道(Lane),每个车道由不同的 Claw 并行推进:
| Lane | 功能 | 内容 |
|---|---|---|
| 1 | Bash 验证 | 6 个子模块 |
| 2 | CI 修复 | sandbox 探测 |
| 3 | File-tool 边界防护 | 文件操作安全 |
| 4 | TaskRegistry 内存生命周期 | 内存管理 |
| 5 | Task 工具接入 | 任务系统集成 |
| 6 | Team + Cron 调度 | 团队和定时调度 |
| 7 | MCP 生命周期桥接 | MCP 协议集成 |
| 8 | LSP 客户端 | 语言服务协议 |
| 9 | 权限执行层 | 权限系统 |
9 个车道全部合并完成。这展示了任务分解和并行化的实际效果------每个车道足够独立,可以由不同的 Agent 同时推进,互不阻塞。
6.2 Parity Harness:确定性验收框架
为了确保 Rust 重写与原始行为一致,作者构建了一套确定性的 Mock 测试基础设施:
- Mock Anthropic Service :一个模拟的
/v1/messages端点 - 10 个脚本化场景,覆盖核心工具使用和权限契约:
| # | 场景 | 验证内容 |
|---|---|---|
| 1 | streaming_text |
流式文本输出 |
| 2 | read_file_roundtrip |
文件读取往返 |
| 3 | grep_chunk_assembly |
grep 块组装 |
| 4 | write_file_allowed |
文件写入(允许) |
| 5 | write_file_denied |
文件写入(拒绝) |
| 6 | multi_tool_turn_roundtrip |
多工具轮次往返 |
| 7 | bash_stdout_roundtrip |
bash 执行往返 |
| 8 | bash_permission_prompt_approved |
bash 权限提示(通过) |
| 9 | bash_permission_prompt_denied |
bash 权限提示(拒绝) |
| 10 | plugin_tool_roundtrip |
插件工具往返 |
每个场景在全新的工作空间和隔离环境变量 下运行。配套的 run_mock_parity_diff.py 脚本生成行为对等性差异报告。
6.3 40 个工具规格:Schema-First 设计
整个工具系统包含 40 个暴露的工具规格(tool specs),每个工具都有:
- JSON Schema 定义
- 权限语义
- 执行边界
- 可观测输出
- 错误处理
6.4 CLAUDE.md:给 Agent 的工作契约
markdown
# CLAUDE.md
## Verification
- Run Rust verification from `rust/`:
`cargo fmt`, `cargo clippy --workspace --all-targets -- -D warnings`,
`cargo test --workspace`
- `src/` and `tests/` are both present;
update both surfaces together when behavior changes.
## Working agreement
- Prefer small, reviewable changes
- Keep shared defaults in `.claude.json`
- Do not overwrite existing `CLAUDE.md` content automatically这个文件是给 AI Agent 看的"行为规范",确保每个 Claw 都遵循一致的工作标准。
七、Agent 角色体系:33 个专业化角色
OmX 内置了 33 个角色 Prompt,覆盖 6 大类别:
7.1 核心角色
| 类别 | 角色 | 职责边界 |
|---|---|---|
| 构建与分析 | explore, analyst, planner, architect, debugger, executor, verifier | 从探索到验证的全链路 |
| 代码评审 | style-reviewer, quality-reviewer, api-reviewer, security-reviewer, performance-reviewer | 5 个独立评审维度 |
| 领域专家 | dependency-expert, test-engineer, build-fixer, designer, writer, git-master | 按领域分工 |
| 产品 | product-manager, ux-researcher, product-analyst | 产品视角 |
| 协调 | critic, vision | 批判性挑战和视觉分析 |
| 团队 | team-orchestrator, team-executor | 团队模式下的编排和执行 |
7.2 关键的角色分离原则
- Planner 不写代码------只产出计划
- Interviewer 不实现------只做需求澄清
- Verifier 独立于 Executor------不能自己验证自己的工作
- Architect 只读------分析和诊断,不直接修改代码
这种分离确保了每个角色的输出不受利益冲突影响。
八、状态持久化:.omx/ 目录体系
所有运行时状态、计划和验证结果都持久化到磁盘,支持会话恢复和跨阶段引用:
| 路径 | 用途 |
|---|---|
.omx/context/{slug}-{timestamp}.md |
任务上下文快照(Ralph 启动时加载) |
.omx/interviews/ |
deep-interview 的访谈记录 |
.omx/specs/ |
可执行规格 |
.omx/plans/prd-*.md |
产品需求文档 |
.omx/plans/test-spec-*.md |
测试规格 |
.omx/state/ |
模式状态 |
.omx/state/team/ |
团队运行时状态 |
.omx/logs/ |
执行日志 |
.omx/drafts/ |
草稿 |
.omx/notepad.md |
会话笔记 |
.omx/project-memory.json |
跨会话记忆 |
九、核心方法论提炼:Long-Running Agent 任务的 7 条法则
从 claw-code 的完整实践中,可以提炼出以下面向 Long-Running Agent 任务的方法论:
法则一:不信任 Agent 的自律------用流水线门禁强制执行
不是"希望" Agent 会看文档后再动手,而是在工具层面阻止它不看文档就动手。Pre-Execution Gate 拦截模糊请求,Ralph 规划门禁验证 PRD 和测试规格的存在。
核心设计:从"信任 + 期望"转向"门禁 + 证据"。
法则二:数学化歧义管理
用加权歧义评分量化需求的清晰度,而不是靠主观判断"应该够清楚了"。每个维度有明确的权重,有明确的阈值,有强制的硬门。
核心设计:消歧不是可选步骤,是强制阶段。
法则三:三角色审议替代单人决策
Planner 提方案、Architect 挑战方案、Critic 验证方案。任何一方的非 APPROVE 都触发完整的重审循环。这比单个 Agent 自己想、自己做、自己验要可靠得多。
核心设计:内建对抗性思考,而不是依赖单一 Agent 的自我怀疑能力。
法则四:验证即证据,不是声称
"should work" 和 "looks good" 不是完成。新鲜的测试输出、构建输出、LSP 诊断结果才是完成。Ralph 的 9 项清单中有 6 项要求"新鲜证据"。
核心设计:Agent 必须"prove"而不是"claim"。
法则五:上下文窗口是最珍贵的资源
clawhip 的全部意义在于:把监控、通知、状态格式化推到 Agent 上下文窗口之外。Agent 的每个 Token 都应该花在实现上,而不是状态汇报上。
核心设计:通知路由和实现执行物理分离。
法则六:并行化是乘数效应
9 个车道同时推进,10 个 Claws 协同工作。关键在于任务分解的质量------每个车道必须足够独立,才能真正并行。
核心设计:投资时间在任务分解上,而不是在串行执行上。
法则七:持久化一切,恢复任何中断
.omx/ 目录体系确保了:计划、规格、上下文、状态、日志都持久化到磁盘。Agent 崩溃、会话中断、网络问题都不会导致进度丢失。
核心设计:Long-Running 意味着必须能从任何断点恢复。
十、反思:什么还缺失
10.1 当前体系的局限
- 依赖关系是叙事式的------没有形式化的 DAG 图或自动化的依赖解析。对于更大规模的项目,这可能成为瓶颈。
- OmX 依赖实验性 API ------如 Claude Code 的
CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1标志,随时可能 break。 - 法律灰区------clean-room 重写的法律边界仍有争议。
- Token 成本------250 亿+ Token 的消耗不是所有团队都能承受的。
10.2 对从业者的启示
作者的总结可能是最好的收尾:
"When coding intelligence gets cheaper and more available, the durable differentiators are not raw coding output. What still matters: product taste, direction, system design, human trust, operational stability, judgment about what to build next."
"In that world, the job of the human is not to out-type the machine. The job of the human is to decide what deserves to exist."
在 AI Agent 成为主力开发者的世界里,人类的价值不在于打字速度,而在于决定什么值得存在。
附录:关键资源索引
| 资源 | 链接 |
|---|---|
| claw-code 仓库 | github.com/ultraworker... |
| oh-my-codex (OmX) | github.com/Yeachan-Heo... |
| clawhip | github.com/Yeachan-Heo... |
| oh-my-openagent (OmO) | github.com/code-yeongy... |
| PHILOSOPHY.md | github.com/ultraworker... |
| PARITY.md | github.com/ultraworker... |
| ROADMAP.md | github.com/ultraworker... |
| claw-code 官网 | claw-code.codes/ |