ComfyUI + SVD 系列(二):最小工作流实现图片生成视频(24 帧 + mp4 合成)
1. 写在前面
上一篇已经把 ComfyUI + SVD 的环境装好了,目标是:
- ComfyUI 能正常启动
svd_xt.safetensors能被识别- 前端界面能打开
- 图片生视频所需的基础节点能正常使用
这一篇就不再讲安装,直接进入最核心的实战部分:
用一张图片,实际跑通一个最小的图生视频工作流。
这次只做一件事:
输入一张图片,输出 24 帧图片序列,再合成 mp4。
不追求复杂动作,不追求剧情,不追求多人物。
先把最小闭环跑通,这才是最有价值的第一步。
B站查看视频(帮忙点赞呗 ):https://www.bilibili.com/video/BV1ayQ4BZECy/?vd_source=3a9dd7a328acafb09dd1b8d05f3e2bf7
2. 本文目标
本文完成以下事情:
- 用 ComfyUI 搭建一个最小 SVD 图生视频工作流
- 输入一张图片
- 输出 24 帧图片序列
- 用 ffmpeg 合成 mp4
- 保存前端工作流和 API 工作流,便于后续复用
也就是说,这一篇主要解决的是:
一张图,如何实际生成一段短视频。
3. 先看最终工作流
本次实际跑通的最小工作流如下图所示:
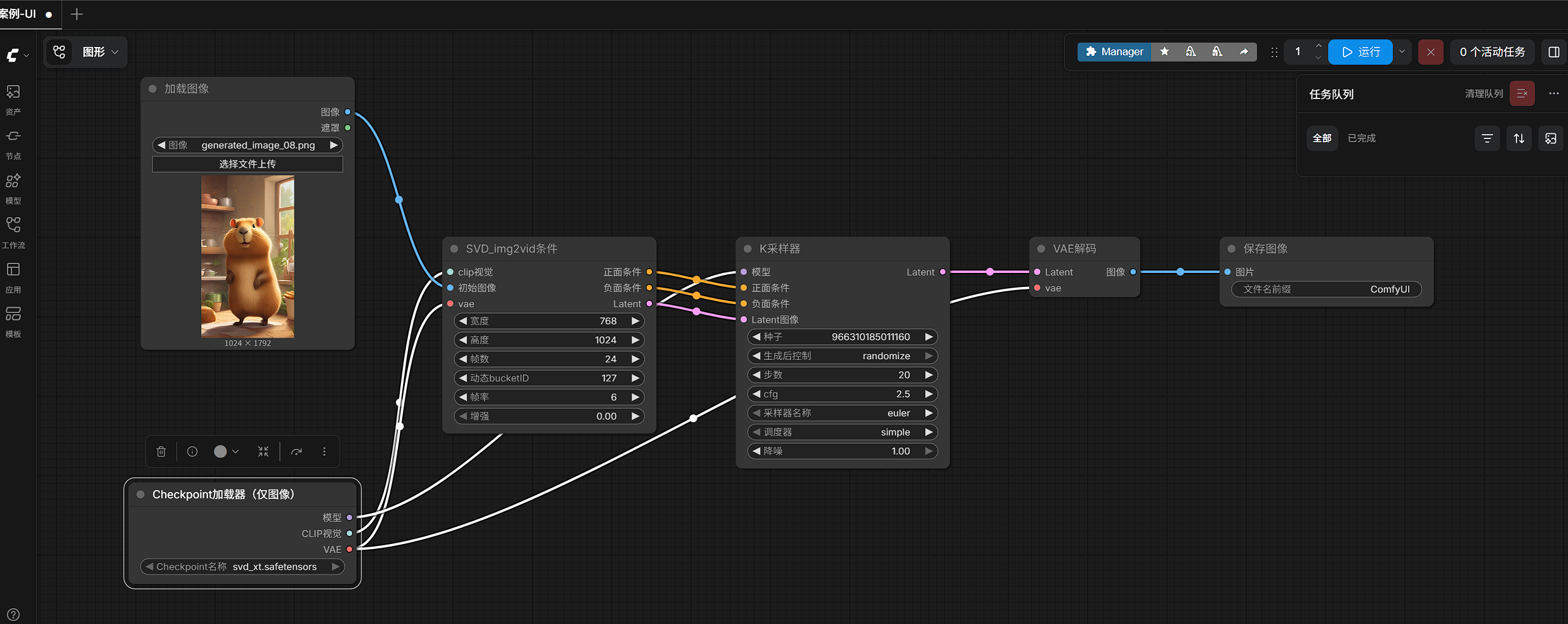
这条链路非常清晰,核心就是:
- 加载图像
- 加载 SVD 模型
- 构造图生视频条件
- K 采样
- VAE 解码
- 保存图片
4. 这套工作流到底做了什么
工作流中的核心节点如下:
LoadImageImageOnlyCheckpointLoaderSVD_img2vid_ConditioningKSamplerVAEDecodeSaveImage
它们之间的逻辑关系是:
4.1 加载输入图像
LoadImage 节点负责读取输入图片。
当前工作流中使用的输入图像是:
text
generated_image_08.png对应 API 工作流中的配置如下 :
json
"1": {
"inputs": {
"image": "generated_image_08.png"
},
"class_type": "LoadImage"
}4.2 加载 SVD 模型
ImageOnlyCheckpointLoader 节点负责加载图片生视频模型。
当前使用的模型是:
text
svd_xt.safetensors对应 API 工作流中的配置如下 :
json
"2": {
"inputs": {
"ckpt_name": "svd_xt.safetensors"
},
"class_type": "ImageOnlyCheckpointLoader"
}4.3 构造图生视频条件
SVD_img2vid_Conditioning 节点是整个工作流的核心。
它接收:
clip_visioninit_imagevae
然后生成:
positivenegativelatent
这一步决定了图生视频的基本参数 。
4.4 K 采样
KSampler 节点负责真正执行采样生成 latent 序列 。
4.5 VAE 解码
VAEDecode 节点把 latent 解码成图片帧 。
4.6 保存输出
SaveImage 节点负责把生成结果保存为图片序列,当前文件名前缀为:
text
ComfyUI对应配置如下 :
json
"124": {
"inputs": {
"filename_prefix": "ComfyUI"
},
"class_type": "SaveImage"
}5. 节点连接关系
如果你要手工搭工作流,按下面这个顺序连就可以:
5.1 输入图像连接到 SVD 条件节点
LoadImage.image
->SVD_img2vid_Conditioning.init_image
5.2 模型节点连接到 SVD 条件节点
-
ImageOnlyCheckpointLoader.clip_vision->
-
SVD_img2vid_Conditioning.clip_vision -
ImageOnlyCheckpointLoader.vae->
-
SVD_img2vid_Conditioning.vae
5.3 模型节点连接到 KSampler
ImageOnlyCheckpointLoader.model
->KSampler.model
5.4 SVD 条件节点连接到 KSampler
-
SVD_img2vid_Conditioning.positive->
-
KSampler.positive -
SVD_img2vid_Conditioning.negative->
-
KSampler.negative -
SVD_img2vid_Conditioning.latent->
-
KSampler.latent_image
5.5 KSampler 输出连接到解码与保存
-
KSampler.LATENT->
-
VAEDecode.samples -
ImageOnlyCheckpointLoader.vae->
-
VAEDecode.vae -
VAEDecode.images->
-
SaveImage.images
6. 本次实际使用的参数
这次工作流不是随便填的,而是已经实际跑通的那一组。
6.1 输入图片
当前输入图片为:
text
generated_image_08.png6.2 模型
当前模型为:
text
svd_xt.safetensors6.3 SVD 条件参数
SVD_img2vid_Conditioning 的参数如下 :
width = 768height = 1024video_frames = 24motion_bucket_id = 127fps = 6augmentation_level = 0
也就是说,这次生成的是:
24 帧、6 fps、纵向 768×1024 的短视频帧序列。
6.4 KSampler 参数
KSampler 的参数如下 :
seed = 966310185011160steps = 20cfg = 2.5sampler_name = eulerscheduler = simpledenoise = 1
6.5 输出参数
输出通过 SaveImage 节点保存,前缀是:
text
ComfyUI7. 为什么宽高设置成 768 × 1024
很多人第一次做图生视频时会问一个问题:
输入图多大,工作流里的宽高就一定要一样吗?
不一定。
当前输入图像文件是 generated_image_08.png ,
而工作流里实际生成时使用的是:
width = 768height = 1024
这样做的目的主要是:
- 保持竖图方向
- 控制显存占用
- 让第一轮验证更稳定
如果你一上来就用过大的分辨率,再叠加 24 帧,很容易显存压力上升。
所以第一轮最推荐的策略是:
先用相对稳妥的尺寸,把工作流跑通。
8. 为什么先输出图片,而不是直接输出 mp4
当前工作流最后接的是:
VAEDecodeSaveImage
也就是说,先输出的是一组图片,而不是直接输出视频 。
这样做有几个好处:
- 更容易排查问题
- 能确认到底生成了多少帧
- 能观察每一帧是否连续
- 即使视频插件有问题,也不影响核心验证
所以对于第一轮验证来说:
先输出图片序列,再合成视频,是最稳妥的路线。
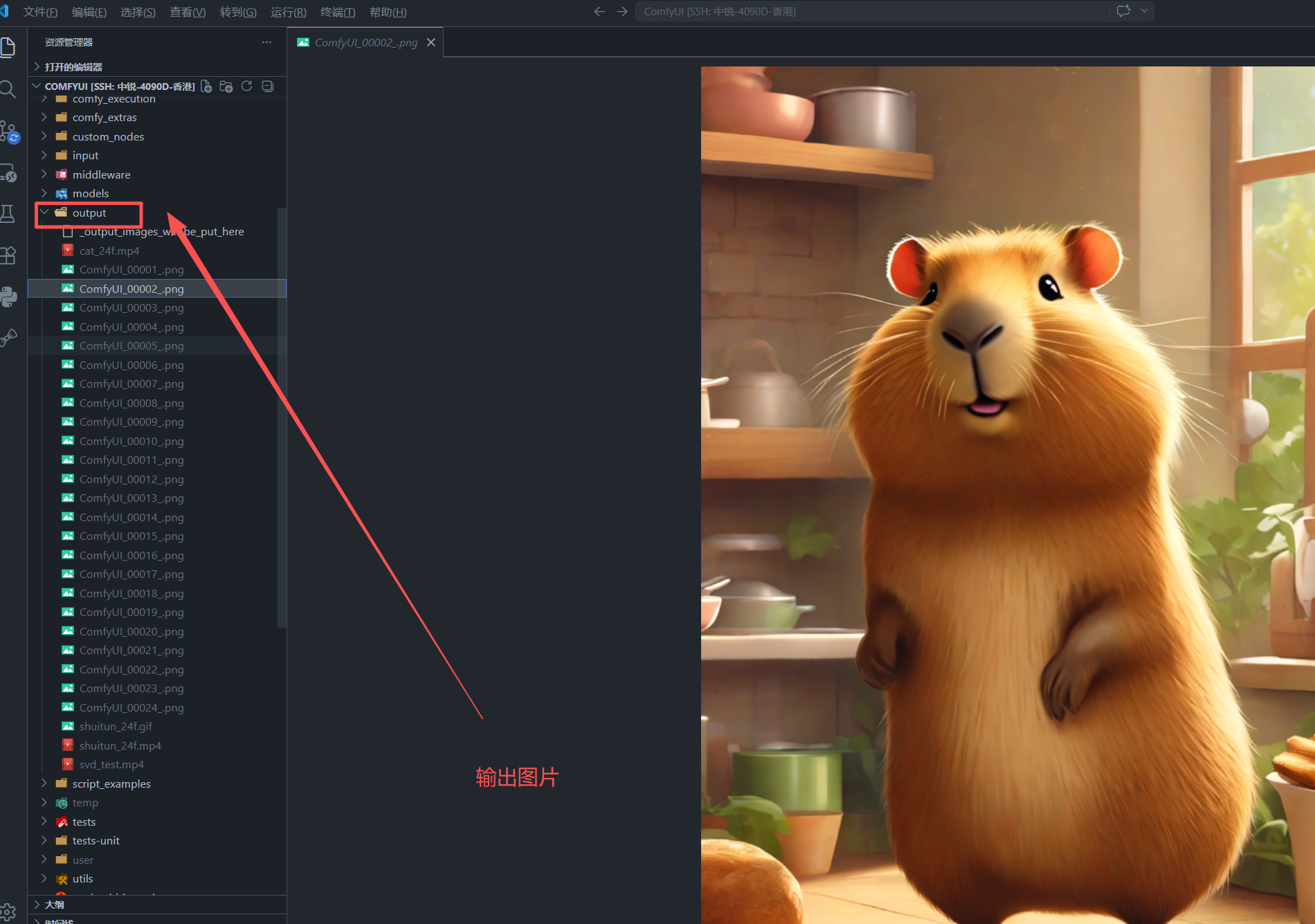
9. 运行后输出在哪里
运行成功后,图片通常会保存在 ComfyUI 的输出目录:
bash
/work/animateDiff/ComfyUI/output/而且因为 SaveImage 的前缀是 ComfyUI ,所以你会看到类似文件:
text
ComfyUI_00001_.png
ComfyUI_00002_.png
ComfyUI_00003_.png
...
ComfyUI_00024_.png这 24 张图就是后续合成视频的素材。
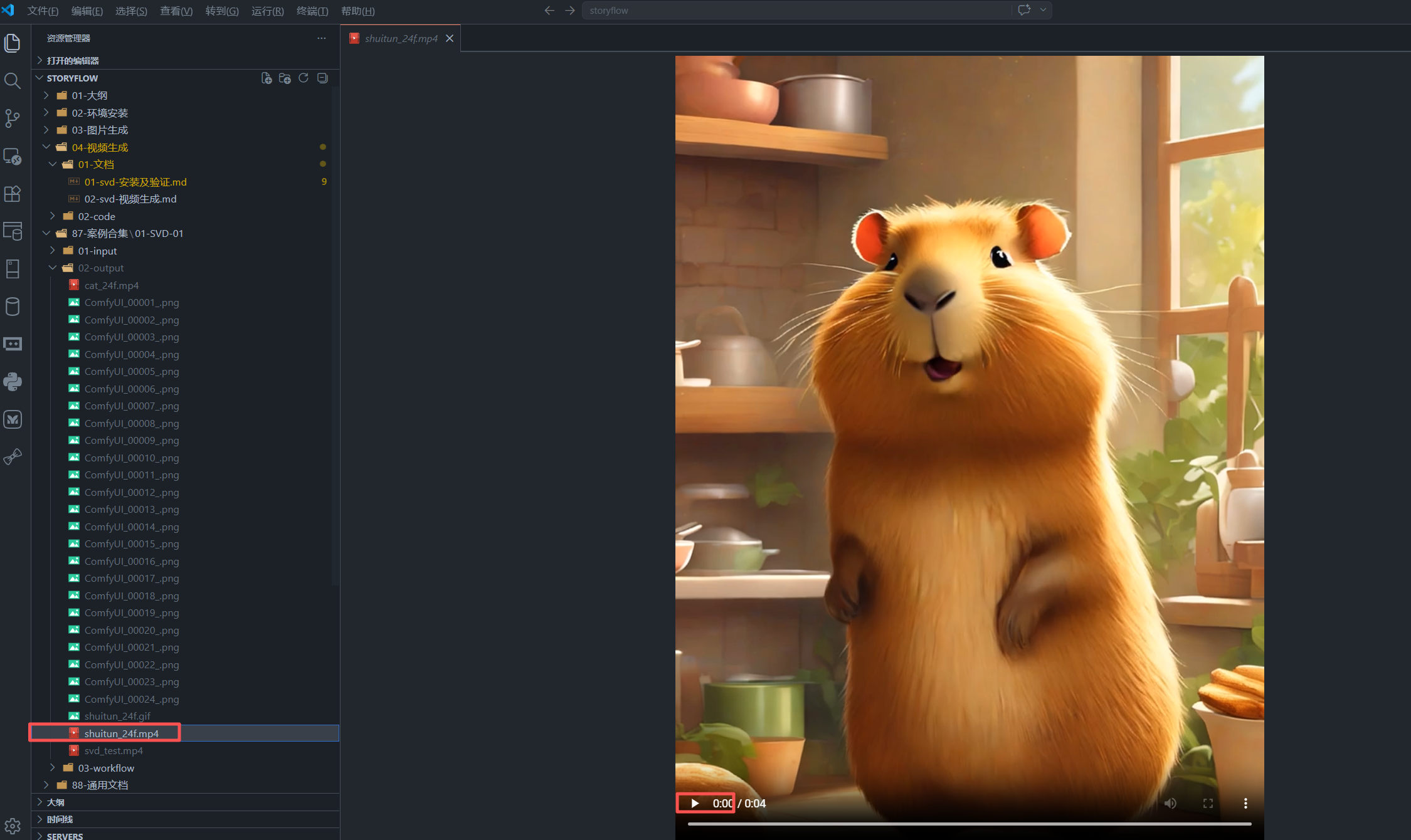
10. 如何把 24 帧图片合成 mp4
前一篇已经装过 ffmpeg,所以这里可以直接合成视频。
先进入输出目录:
bash
cd /work/animateDiff/ComfyUI/output然后执行:
bash
ffmpeg -framerate 6 -i ComfyUI_%05d_.png -c:v libx264 -pix_fmt yuv420p svd_24f.mp4这里参数的含义是:
-framerate 6:按 6 fps 读取图片ComfyUI_%05d_.png:匹配ComfyUI_00001_.png到ComfyUI_00024_.png-c:v libx264:使用 H.264 编码-pix_fmt yuv420p:保证兼容性更好svd_24f.mp4:输出视频文件名
因为当前工作流里 fps = 6 ,所以这里 ffmpeg 的 -framerate 也应该对应设置为 6。
11. 如何确认这次最小验证已经成功
这一轮验证成功的标准其实很简单:
- ComfyUI 能正常执行工作流
svd_xt.safetensors能被正确加载- 输入图片能正常读取
- 输出目录里成功生成 24 张图片
- 图片之间有连续变化
- 最终能顺利合成 mp4
只要满足这几点,就说明:
单图生成短视频的最小闭环已经跑通。
12. 这套工作流为什么适合作为"最小案例"
因为它足够简单,但链路完整。
当前工作流只包含 6 个关键节点:
LoadImageImageOnlyCheckpointLoaderSVD_img2vid_ConditioningKSamplerVAEDecodeSaveImage
这意味着它具备几个优势:
- 新手容易照着搭
- 出错点少
- 参数少,容易复现
- 后续方便导出 API JSON
- 方便改造成 Python 后端调用
这也是为什么我建议:
第一轮不要一上来追求复杂视频,而是先拿下这个最小闭环。
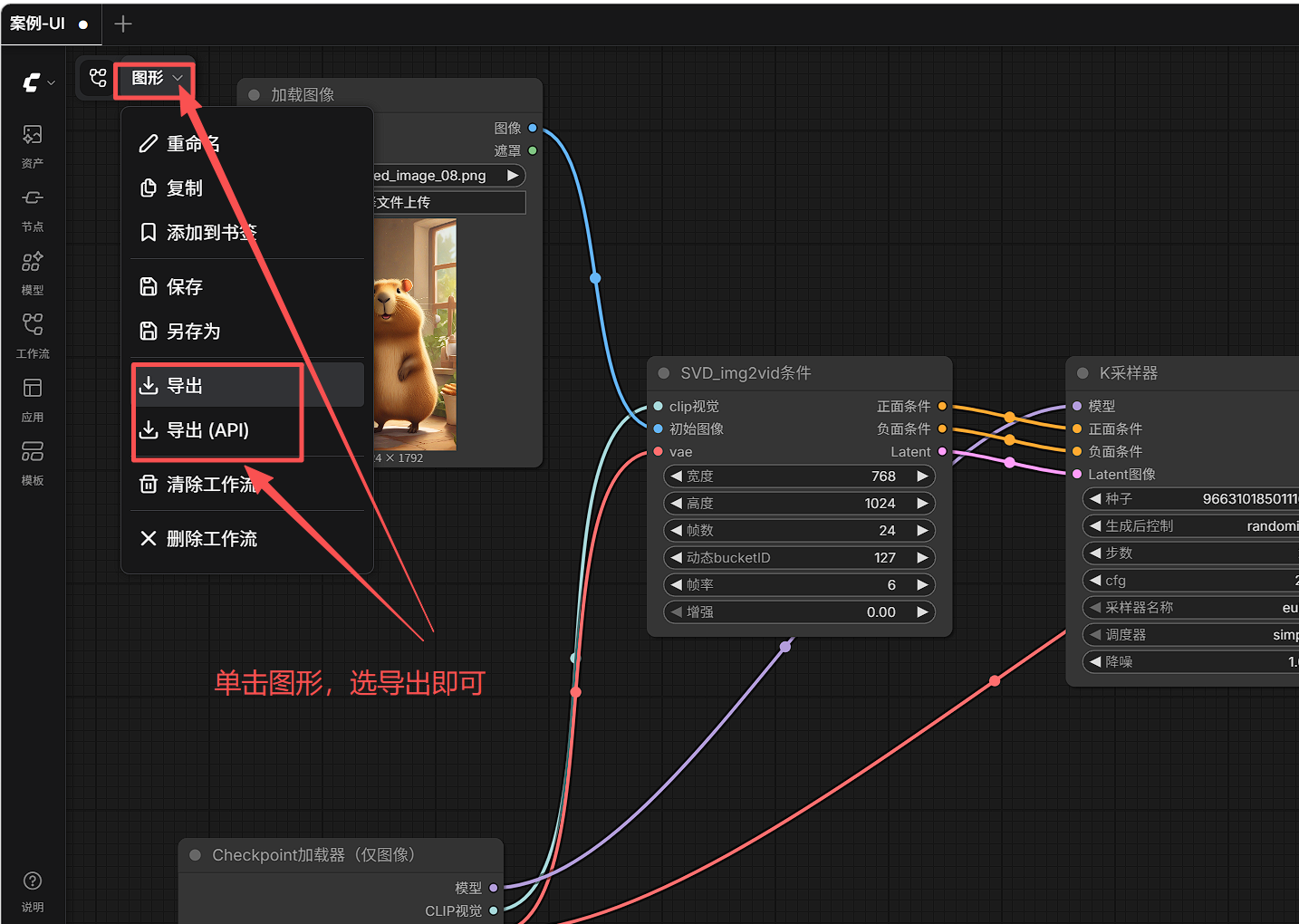
13. 建议顺手保存两份工作流
既然已经跑通了,建议你顺手保存两份:
13.1 前端工作流
用途:
- 下次直接在 ComfyUI 界面打开
- 保留节点位置、连线和参数
13.2 API 工作流
用途:
- 后续 Python 调用
- 自动提交任务
- 批量替换输入图和参数
这两份都很重要。
尤其是 API 工作流,后面如果要做后端调用,会非常方便。
14. 本文小结
这篇文章实际跑通了一个 ComfyUI + SVD 最小图生视频工作流,流程如下:
- 加载输入图
generated_image_08.png - 加载模型
svd_xt.safetensors - 设置
768×1024、24帧、6fps的 SVD 条件 - 使用
KSampler执行 20 步采样,CFG 为 2.5 - 解码并保存 24 张图片帧
- 最后通过
ffmpeg合成 mp4
如果你现在已经生成出了图片序列,并顺利合成视频,那么就说明:
ComfyUI + SVD 的最小图生视频案例已经成功跑通。