
长对话/多资料场景下的信息"找回"难题
作为火山方舟面向 AI 开发者推出的专属订阅套餐包,方舟 Coding Plan 一直以高性价比的模型调用额度、丰富的 Agent 开发工具支持受到大家的欢迎。
开发者一次订阅 即可在 Doubao-Seed-2.0-Code、Doubao-Seed-2.0-pro、Doubao-Seed-2.0-lite、Doubao-Seed-Code、MiniMax-M2.5、Kimi-K2.5、GLM-4.7、DeepSeek-V3.2 等模型按需切换 ,此外,方舟 Coding Plan 还兼容主流 AI 编码工具,如 Claude Code、OpenCode、OpenClaw、TRAE、Cline、Cursor、Roo Code、Kilo Code、Codex CLI 等,适配多种开发场景。
不过,我们注意到,几乎每个写代码的开发者,都在和"大模型失忆"斗争,开发者们经常会遇到一个高频需求:当 AI 助手需要基于历史对话、需求文档、任务信息去"找回相关内容"时,仅靠关键词匹配不够用------同义表达、口语描述、跨段落信息很容易漏;而把大量内容直接塞给大模型,又会带来 Token 成本上升与效果波动。
归根结底,这类问题的关键在于:系统能否在关键时刻"找回正确的上下文",并控制好成本。
本次升级:新增 Embedding 模型,提升 Agent 语义检索与长期记忆能力
为了解决"找得准、找得快、成本可控"的语义召回需求,**方舟 Coding Plan 迎来能力升级:新增支持 Embedding 模型。**开发者在集成龙虾助手/各类工具时,可以通过 Coding Plan 直接调用 Embedding 能力,将内容向量化,基于语义相似度完成检索与召回。
这意味着,开发者现在可以轻松地将代码、文档、对话、PR 记录等任意信息,转化为高维度的语义向量,让信息检索从"关键词匹配"升级为"语义理解",从而让后续的大模型推理更聚焦、更稳定。
**简单来说:**有了 Embedding,你的 AI Agent 就装上了一颗"数字海马体",能够真正理解并记住你的项目上下文,实现跨文件、跨任务、跨周期的长期可检索记忆。
效果提升:找得准、忘得慢、花钱少、上手快
火山方舟 Coding Plan 将 Embedding 能力集成到日常开发流中,进一步提升开发者编码效率:
1. 更精准的语义召回 🎯
相比传统关键词匹配,Embedding 检索在信息量大、对话长、资料分散的场景下,更准确召回相关内容,降低遗漏与误判。
2. 更持久的跨轮次记忆 🧠
在多轮对话或复杂的编码任务中,Agent 能持续追踪上下文,记住关键变量、函数定义和开发者的编程偏好,实现更持久的跨轮次记忆。
3. 更低的 Token 成本 💰
Embedding 为记忆检索、知识库问答与工具调用提供统一的语义检索层,帮助工具在不增加主模型推理成本的前提下,提升跨轮次上下文追踪能力与整体效果。
4. 更低的集成门槛🔌
我们提供兼容 OpenAI 的接口协议和专属 Base URL,并与 OpenClaw、OpenViking 等主流 AI 编码工具开箱集成,让用户以最低的成本,快速为自己的 Agent 赋能。
多场景适配:轻松应对信息量大、对话长、资料分散难题
Embedding 模型能把代码、文档、对话等信息向量化并按语义检索召回,例如,在代码理解、PRD 问答、Bug 溯源、知识库检索与 Agent 长期记忆等场景里,都能帮助使用者"先找对上下文,再写对代码/做对决策"。

方舟 Coding Plan 新增 Embedding 模型,
信息图由 vaka 知识助手生成
极简配置,快速上手
Coding Plan 提供的 Embedding 服务完全兼容 OpenAI 接口协议,最大程度降低开发者迁移成本,提升配置效率。
核心配置信息:
-
Embedding 模型名: doubao-embedding-vision
Doubao-embedding-vision 是多模态向量化模型,它能将文本、图片以及视频等混合输入内容转换为统一的向量表示,从而帮助您更高效地处理跨模态数据,实现精准的文搜图、图搜图和图文混合搜索。
当前模型支持以下几种向量输出类型:
-
**稠密向量 (Dense Embedding):**所有版本均默认支持。
-
**稀疏向量 (Sparse Embedding):**从 doubao-embedding-vision-250615 版本起支持,支持文本输入。
与主流工具集成:
为了帮助开发者免除从零搭建 RAG(检索增强生成)系统的繁琐,我们提供了与 OpenClaw 和 OpenViking 等开源框架开箱即用的集成方案。只需简单配置,将 Coding Plan 的底层向量化能力注入到这些专为 AI 智能体设计的上下文中,即可快速为你的 AI 编码助手建立起长时记忆和精准的代码库检索能力。
👉 在 OpenClaw 中配置 Embedding 模型:对话记忆精准找回,让 AI 助手更会找、更会记
OpenClaw 是一款开源、自托管的个人 AI 助手,支持配置 Embedding 模型,以解决大模型原生记忆有限、易产生幻觉、无法适配私有数据的问题,从而提升模型在处理复杂任务时的准确性和可靠性。
-
前提条件:已完成 OpenClaw 的安装与配置,(步骤请见)。
-
选择以下任一方式配置 Embedding 模型。
(一)Web UI 方式
a. 执行以下命令打开 Web UI。
openclaw dashboardb. 在左侧菜单栏选择配置 - All Settings - Raw,在agents.defaults节点下增加 memorySearch 相关配置信息,增加的配置信息如下。其中需要将 <ARK_API_KEY> 替换为您自己的 API Key (https://console.volcengine.com/ark/region:ark+cn-beijing/apikey)。
{
...
"agents": {
"defaults": {
...
"memorySearch": {
"provider": "openai",
"model": "doubao-embedding-vision",
"remote": {
"baseUrl": "https://ark.cn-beijing.volces.com/api/coding/v3",
"apiKey": "<ARK_API_KEY>"
}
}
...
}
}
...
}c. 配置完成后,先单击右上角 Save 保存,保存完成后单击 Update 更新配置。
(二)终端方式
a. 在终端执行以下命令打开 OpenClaw 配置文件。
nano ~/.openclaw/openclaw.jsonb. 在 agents.defaults 节点下增加 memorySearch 相关配置信息,增加的配置信息如下。其中需要将 <ARK_API_KEY> 替换为您自己的 API Key (https://console.volcengine.com/ark/region:ark+cn-beijing/apikey)。
{
...
"agents": {
"defaults": {
...
"memorySearch": {
"provider": "openai",
"model": "doubao-embedding-vision",
"remote": {
"baseUrl": "https://ark.cn-beijing.volces.com/api/coding/v3",
"apiKey": "<ARK_API_KEY>"
}
}
...
}
}
...
}c. 配置完成后,重启网关使配置生效。
openclaw gateway restart👉 在 OpenViking 中配置 Embedding 模型:为 Agent 构建上下文数据库,让资料沉淀可复用
OpenViking 是专为 AI 智能体(Agent)打造的上下文数据库,主要适用于多 Agent 协同、长期记忆管理、复杂任务执行等场景。
该数据库采用 viking:// 文件系统范式,将智能体的记忆、资源与技能 进行统一组织管理,依托分层加载机制按需供给上下文,在减少 Token 消耗的同时提升运行效率,结合目录式检索优化信息召回效果。功能上,OpenViking 支持多租户、多用户及多 Agent 隔离,且能在会话结束后自动沉淀长期记忆,实现智能体能力的持续积累与自我优化,既有效降低开发者的上下文管理成本,也能显著提升 OpenClaw 等智能体的整体运行表现。
OpenViking 支持多模态 Embedding 模型的集成与接入,实现非结构化数据的向量化转换,并提供高效的语义相似度检索能力。
-
前提条件:已完成 OpenViking 的安装与基础配置,(步骤请见:https://www.volcengine.com/docs/82379/2288685?lang=zh)。
-
在配置文件 ~/.openviking/ov.conf 中新增 embedding 相关配置。其中需要将 <ARK_API_KEY> 替换为您自己的 API Key (https://console.volcengine.com/ark/region:ark+cn-beijing/apikey)。
{
...
"embedding": {
"dense": {
"api_base" : "https://ark.cn-beijing.volces.com/api/coding/v3",
"api_key" : "<ARK_API_KEY>",
"provider" : "volcengine",
"dimension": 1024,
"model" : "doubao-embedding-vision"
},
"max_concurrent": 10
}
...
}
如何订阅方舟 Coding Plan?
方舟 Coding Plan 提供 Lite 与 Pro 套餐,适应轻量与大规模编程场景。
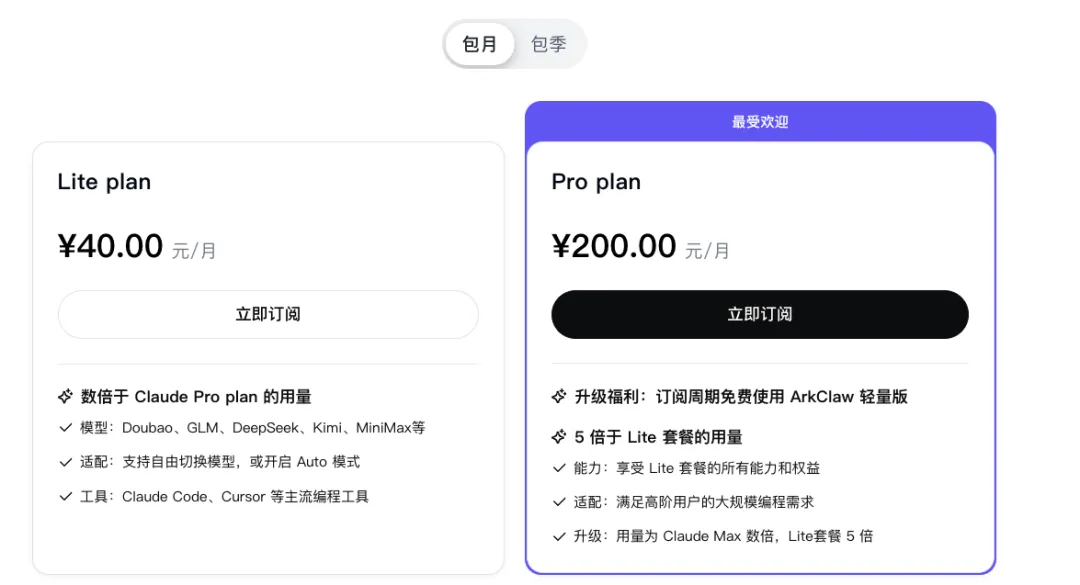
邀请好友更划算,立享 9 折优惠!

现在,就为你的 Coding Plan 装备上这颗强大的"数字海马体"吧!我们相信,真正的 AI Native 开发体验,始于模型能够真正"理解"并"记住"你的工作。
欢迎各位开发者试用与反馈,与我们共同定义下一代的 AI 编程范式。