在AI训练服务器朝着超高算力密度与能效比不断演进的今天,其内部为多GPU集群供电的功率管理系统已不再是简单的电源转换单元,而是直接决定了系统稳定性、训练效率与总拥有成本的核心。一条设计精良的功率链路,是服务器实现持续满负载运算、保障数据完整性并降低运维成本的关键物理基石。
然而,构建这样一条链路面临着多维度的挑战:如何在提升转换效率与控制散热成本之间取得平衡?如何确保功率器件在严苛的7x24小时满载工况下的长期可靠性?又如何将瞬态响应、热管理与功率密度无缝集成?这些问题的答案,深藏于从关键器件选型到系统级集成的每一个工程细节之中。
一、核心功率器件选型三维度:电压、电流与拓扑的协同考量
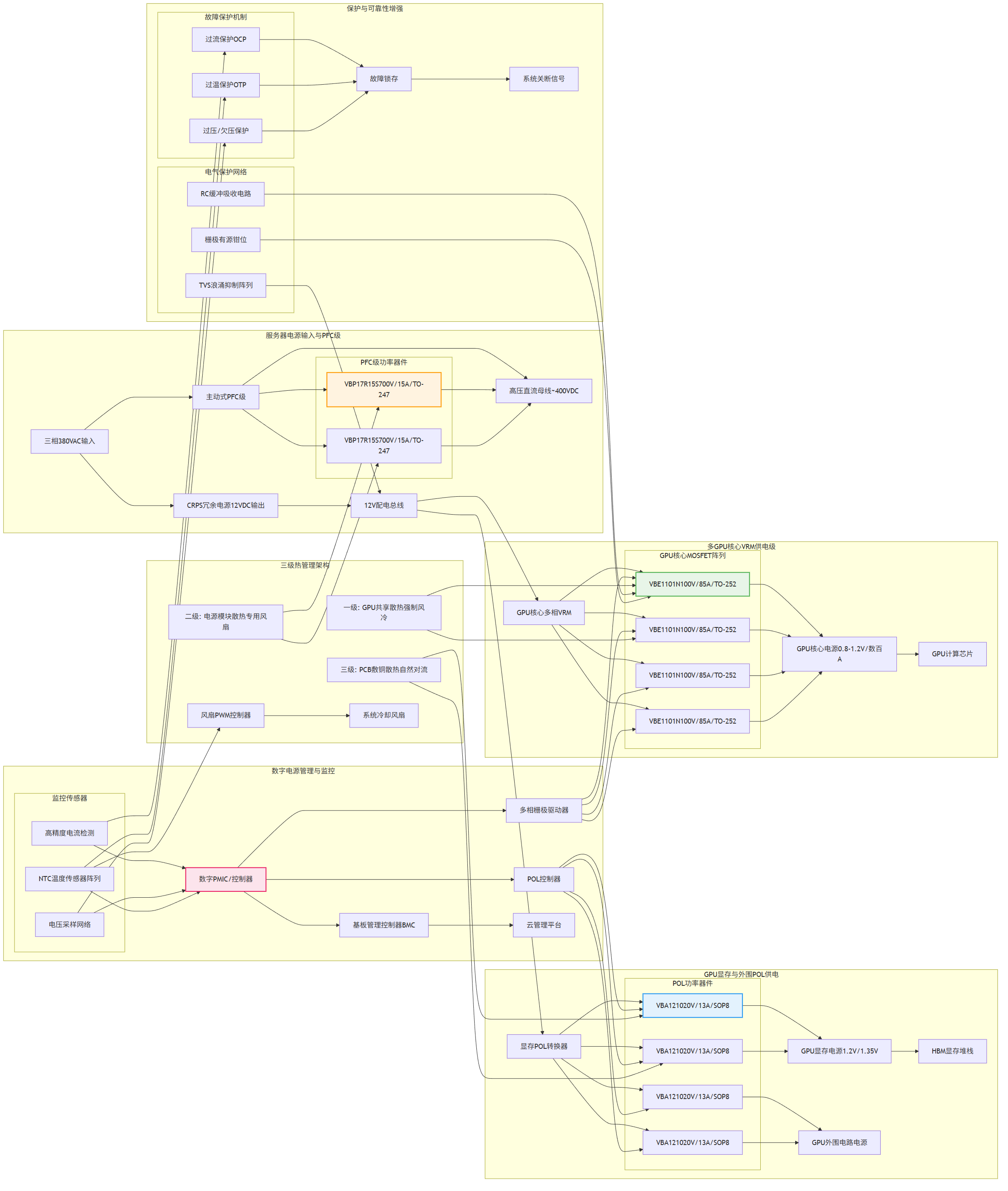
图1: AI 训练服务器 8GPU 方案与适用功率器件型号分析推荐VBE1101N与VBA1210与VBPB112MI40与VBP17R15S与产品应用拓扑图_01_total
- GPU核心供电MOSFET:效率与功率密度的决定性因素
关键器件为VBE1101N (100V/85A/TO-252),其选型需要进行深层技术解析。在电压应力分析方面,考虑到为高端GPU(如H100/A100)核心供电的多相VRM,其输入电压通常为12V,输出低至1V以下,因此MOSFET承受的应力主要来自开关节点振铃,100V耐压为应对3-5倍于输入电压的尖峰提供了充足裕量。在动态特性优化上,极低的导通电阻(Rds(on)@10V=8.5mΩ)是降低导通损耗的关键。以单相80A峰值电流、占空比10%为例,采用此器件相较于常规30mΩ方案,单相导通损耗可降低约70%,这对于高达数十相的GPU供电系统意义重大。其Trench技术确保了在低栅极电压(如4.5V)下仍具备优异导通特性(10.5mΩ),有利于兼容先进数字PWM控制器的驱动能力。热设计关联紧密,TO-252封装需紧密贴装在多层PCB的铜平面上,利用服务器强制风冷将热阻降至最低。
- 12V至GPU显存/外围电路DC-DC MOSFET:高频率与高可靠性的保障
关键器件选用VBA1210 (20V/13A/SOP8),其系统级影响可进行量化分析。在功率密度提升方面,其为GPU板载的多个POL(负载点)电源提供了理想选择。其超低导通电阻(Rds(on)@10V=8mΩ)和SOP8封装,允许在极小的布板面积内实现高达10A以上的连续电流输出,显著提升PCB空间利用率。在可靠性层面,其20V的耐压针对12V输入总线具有高安全裕度,能有效抵御热插拔或负载阶跃产生的电压过冲。驱动设计要点包括:可直接由现代电源管理IC驱动,无需额外的驱动级,简化设计;其低栅极电荷(由低Rds(on)及Trench技术推断)有助于实现高达1-2MHz的开关频率,从而大幅减小滤波电感和电容的尺寸。
- PFC/高压母线开关MOSFET:系统能效与稳健性的基石
关键器件是VBP17R15S (700V/15A/TO-247),它能够胜任服务器CRPS电源或整机PFC级的高压侧应用。在效率与可靠性协同设计上,其700V耐压完美适配400V直流母线架构,并为雷击浪涌和开关尖峰预留充足空间。采用SJ_Multi-EPI(超结多外延)技术,实现了低导通电阻(350mΩ)与低栅极电荷的良好平衡,这对于提升PFC级在满载下的效率(目标>98%)至关重要。在热设计方面,TO-247封装便于安装大型散热器,结合服务器系统级强力散热,可确保在高温环境下长期稳定工作。其15A的电流能力为千瓦级电源模块提供了可靠的单管或并联方案。
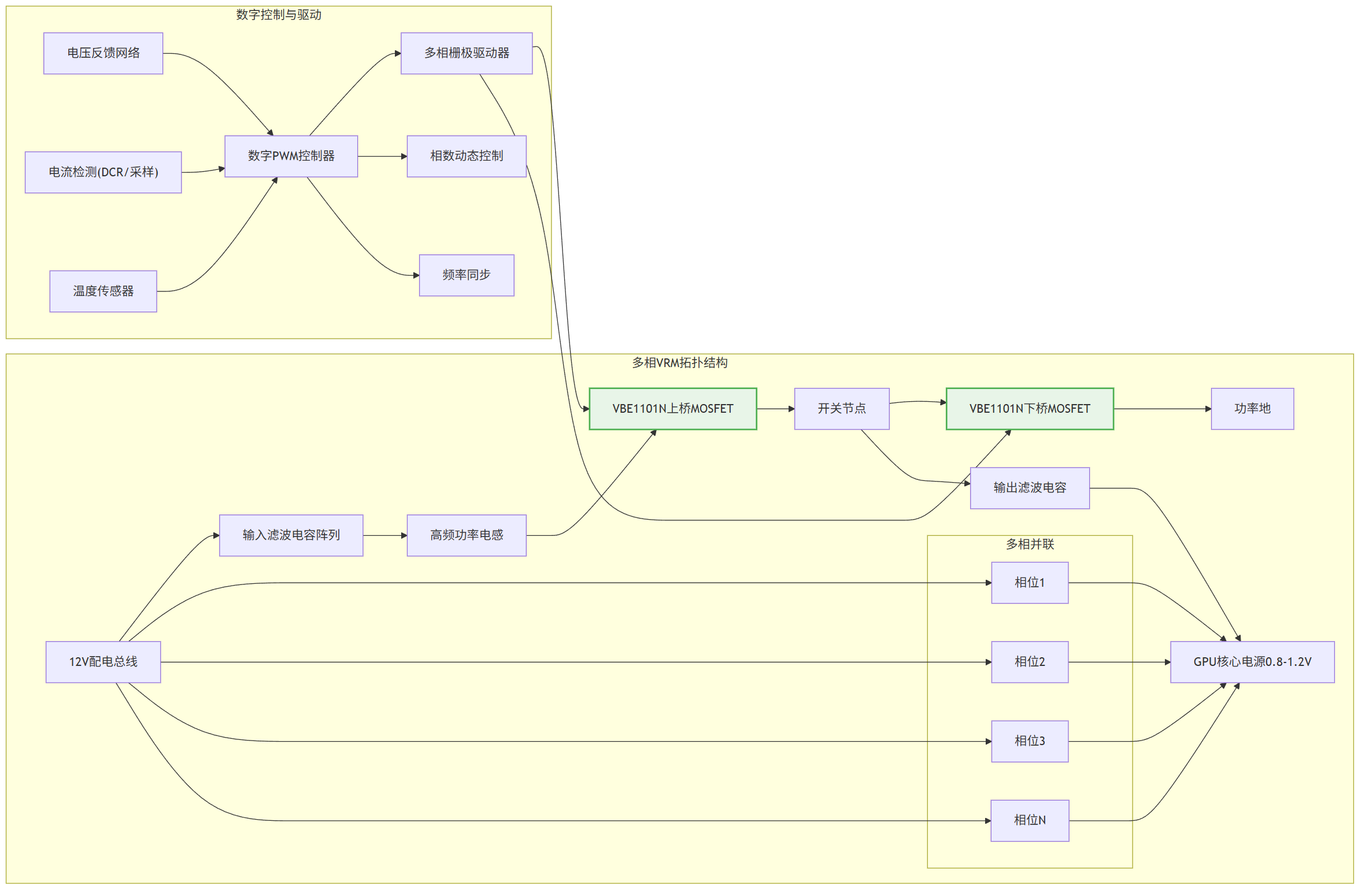
图2: AI 训练服务器 8GPU 方案与适用功率器件型号分析推荐VBE1101N与VBA1210与VBPB112MI40与VBP17R15S与产品应用拓扑图_02_gpu-vrm
二、系统集成工程化实现
- 多层级热管理架构
我们设计了一个三级散热系统。一级强化散热针对VBE1101N这类GPU核心供电MOSFET,采用直接焊接在多层厚铜PCB(如6层,2oz+)上,并配合GPU散热模组的共享风道进行强制散热,目标是将壳温控制在85℃以下。二级主动散热面向VBP17R15S这样的PFC/高压MOSFET,在电源模块内为其单独配备散热片和专用风扇,目标温升低于50℃。三级板载散热则用于VBA1210等板载POL开关管,依靠PCB内部铜层和表面气流,目标温升小于30℃。
具体实施方法包括:将GPU供电MOSFET以多相阵列形式布局在GPU插槽周围,背面使用热导率高的导热垫片与机箱中板或散热器接触;为高压MOSFET选择低热阻的绝缘垫片和散热器;在所有大电流路径上使用实心铜块或嵌入铜层技术,并密集布置散热过孔阵列。
- 电磁兼容性与信号完整性设计
对于高频噪声抑制,在GPU核心供电的每相电路中使用紧耦合的功率回路布局,将开关节点面积控制在1cm²以内;输入输出采用多层陶瓷电容阵列进行去耦。针对VBA1210所在的高频POL电路,采用屏蔽电感并确保反馈走线远离噪声源。
针对大电流瞬态响应,采用多相并联与交错技术以降低输入输出纹波;优化驱动电阻以平衡开关速度与EMI;对VBE1101N的栅极驱动路径实施Kelvin连接,避免地噪声影响。
- 可靠性增强设计
电气应力保护通过网络化设计来实现。在12V输入端口部署TVS和电解电容缓冲网络以吸收浪涌。在每相GPU VRM的开关节点设置RC缓冲或栅极有源钳位,以抑制Vds电压过冲。
故障诊断与保护机制涵盖多个方面:每相电流通过精密采样电阻或电感DCR采样进行监控,实现精确的过流保护和均流控制;通过安装在MOSFET附近的NTC或集成温度传感器实现过温保护;电源管理IC具备相数动态增减、频率同步等功能,以优化不同负载下的效率和热分布。
三、性能验证与测试方案
- 关键测试项目及标准
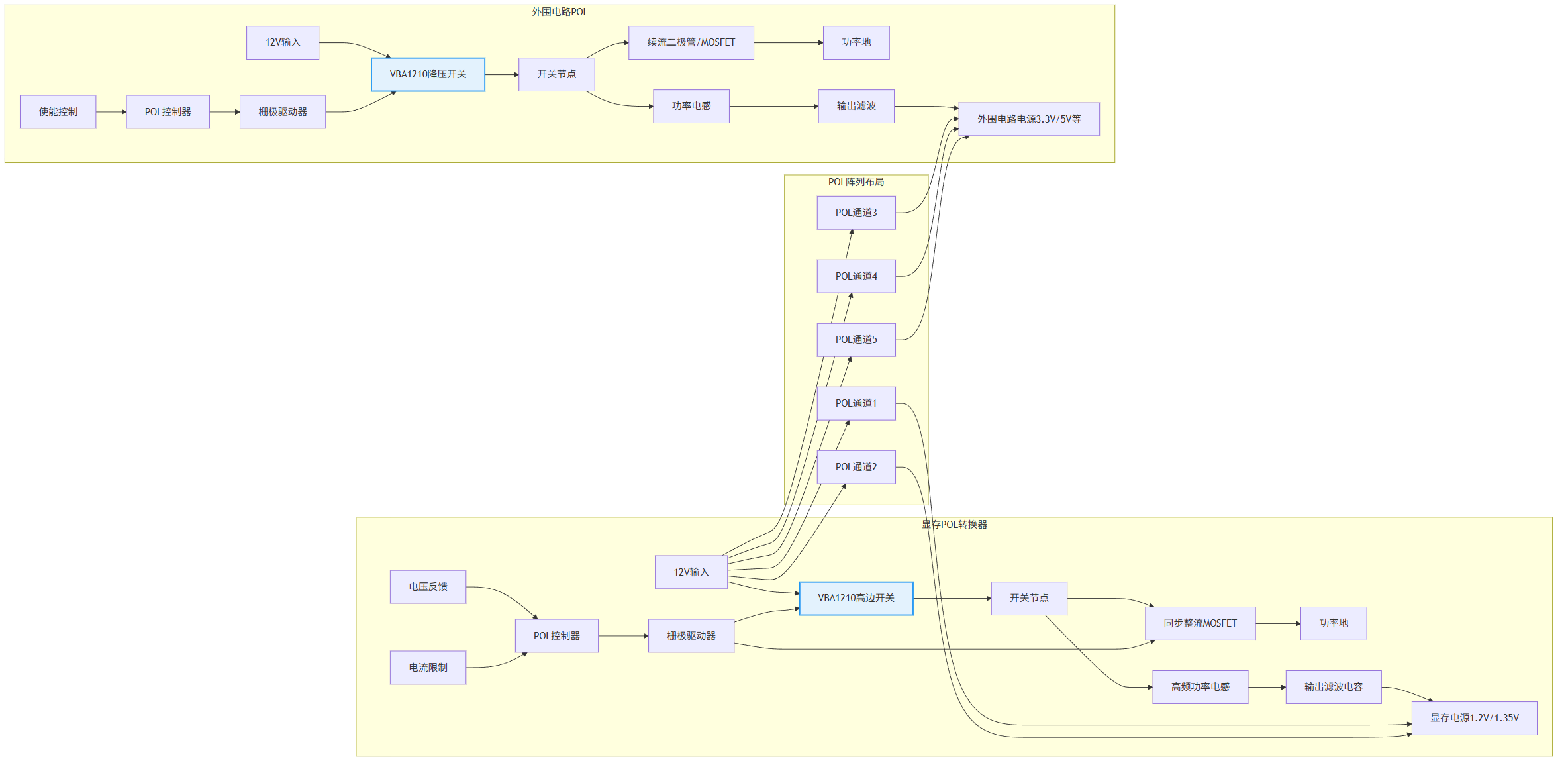
图3: AI 训练服务器 8GPU 方案与适用功率器件型号分析推荐VBE1101N与VBA1210与VBPB112MI40与VBP17R15S与产品应用拓扑图_03_mem-pol
为确保设计质量,需要执行一系列关键测试。单相VRM效率测试在12V输入、满载输出条件下进行,采用功率分析仪测量,合格标准为峰值效率不低于92%。瞬态响应测试使用电子负载进行大幅值阶跃(如50A/μs),要求输出电压偏差不超过±3%。热成像测试在40℃环境、服务器满载运行1小时后进行,关键器件MOSFET的壳温必须低于规格书最大值。开关波形测试在满载条件下用示波器观察,要求Vds电压过冲不超过25%,需使用高频电流探头和差分电压探头。长期可靠性测试则在55℃环境温度下进行1000小时满载老化,要求无故障。
- 设计验证实例
以一台8-GPU服务器的单GPU板卡供电链路测试数据为例(输入电压:12VDC,环境温度:25℃),结果显示:GPU核心多相VRM(使用VBE1101N)峰值效率达到94.5%;显存POL(使用VBA1210)效率在5V/10A输出时为91.2%。关键点温升方面,GPU核心供电MOSFET(壳温)为72℃,PFC高压MOSFET(在电源模块内)为58℃。
四、方案拓展
- 不同功率等级的方案调整
针对不同GPU配置的服务器,方案需要相应调整。4-GPU中端训练服务器可减少GPU VRM的相数,PFC级可采用单管或双管交错。8-GPU高端服务器(如本文基准)采用全规格多相设计,PFC级可能需并联使用。未来16-GPU或集群级机柜,GPU供电需考虑使用功率模块或更先进的封装(如DrMOS),高压侧可能采用VBPB112MI40 (1200V IGBT) 用于更高功率的三相PFC或隔离DC-DC拓扑。
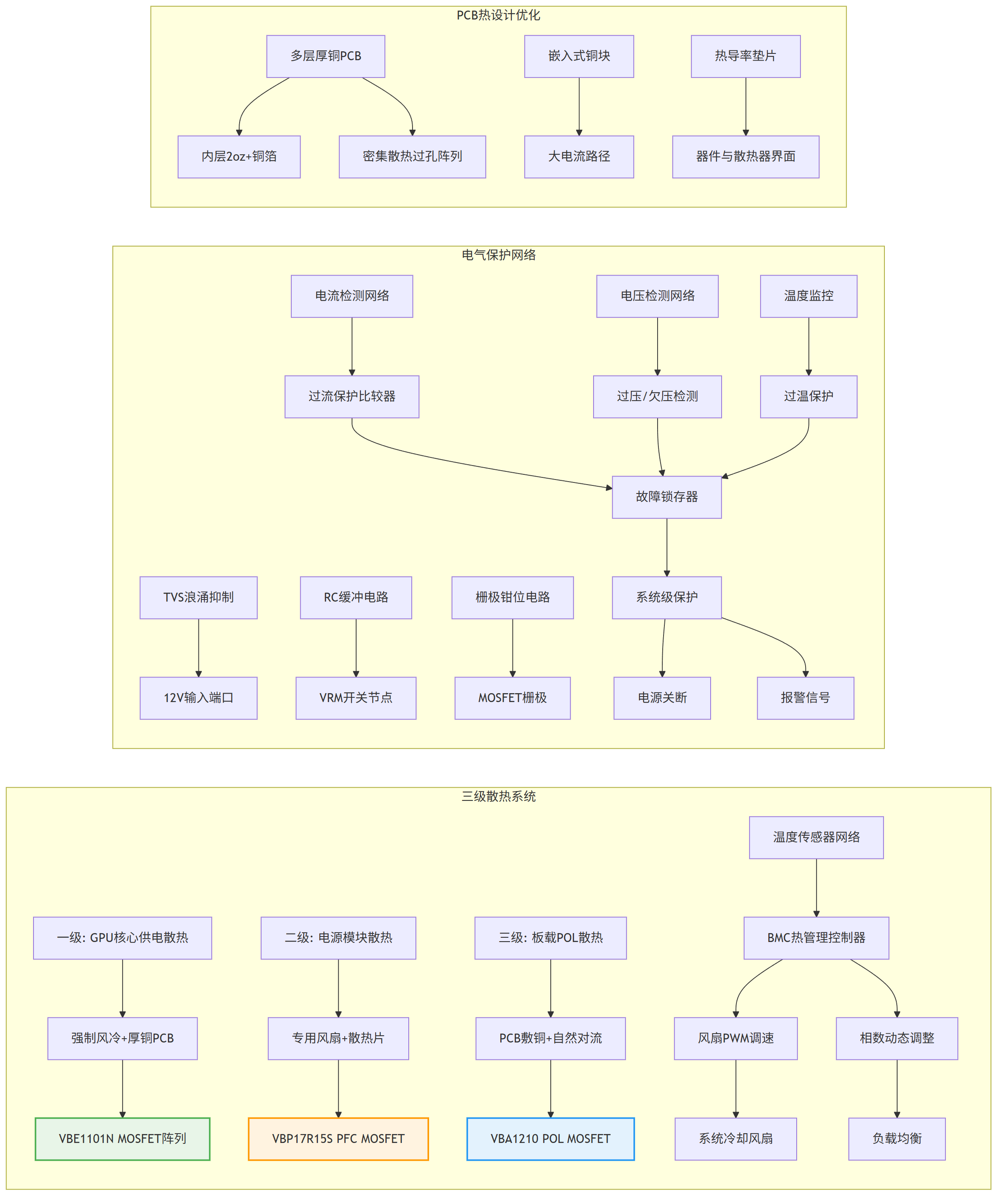
图4: AI 训练服务器 8GPU 方案与适用功率器件型号分析推荐VBE1101N与VBA1210与VBPB112MI40与VBP17R15S与产品应用拓扑图_04_thermal-mgmt
- 前沿技术融合
数字电源与智能管理是未来的发展方向。通过数字PWM控制器,实现对每相VBE1101N的驱动时序、死区时间的动态优化,并基于实时温度数据调整开关频率或相数,实现效率与散热的最佳平衡。
宽禁带半导体应用路线图可规划为:第一阶段是当前主流的优化硅基MOS方案(如本文所选);第二阶段在高效12V-1.xV的VRM中引入GaN FET,以追求MHz级开关频率和极致功率密度;第三阶段在高压PFC/隔离级探索SiC MOSFET的应用,进一步提升系统整体能效。
AI训练服务器的GPU功率链路设计是一个追求极致功率密度、效率与可靠性的系统工程,需要在电气性能、热管理、瞬态响应和成本等多个约束条件之间取得平衡。本文提出的分级优化方案------GPU核心供电追求极低损耗与高电流能力、板载POL供电追求高功率密度与高频特性、高压PFC级追求高耐压与稳健性------为高性能计算服务器的电源设计提供了清晰的实施路径。
随着AI模型规模指数级增长,未来的服务器功率管理将朝着更高密度、全链路智能化监控的方向发展。建议工程师在采纳本方案基础框架的同时,重点考虑散热系统的兼容性与数字控制接口的开放性,为应对未来更高功耗的GPU和更复杂的集群管理做好充分准备。
最终,卓越的功率设计是隐形的,它不直接呈现给用户,却通过更稳定的满载运算、更低的PUE值、更高的训练可用性和更长的硬件寿命,为AI计算提供持久而可靠的基础动力。这正是支撑人工智能前沿突破的底层工程智慧。