note
- 这篇论文介绍了LLaDA,一种从头开始训练的大规模扩散语言模型。LLaDA展示了强大的可扩展性、上下文学习能力和指令跟随能力,达到了与领先的LLMs相当的性能。此外,LLaDA提供了双向建模和增强的鲁棒性,有效解决了现有LLMs的一些局限性。
- LLaDA不是像 GPT/LLaMA 那样 从左到右一个 token 一个 token 生成,而是:先把句子里的 token 随机 mask 掉,模型去预测这些 mask 的 token,推理时从"全 mask"开始,逐步把句子补出来
- LLM 的 in-context learning、instruction following、scaling,这些能力是不是天然只能靠自回归模型得到?
- 作者的答案是:不一定。
- LLaDA预训练时对整句按随机比例 mask;SFT 时只 mask response;生成时从全 mask 的 response 一步步还原。
- LLaDA 在 general、math、code、Chinese 等 benchmark 上,整体能做到和他们自己训练的 ARM baseline 差不多;8B base 还和 LLaMA3 8B Base 接近。SFT 后也能做多轮对话和指令跟随。
- AR 模型很擅长顺着生成,但对"反着来"的任务天然不舒服。论文拿中文诗句补全举例:给下句推上句,LLaDA 因为是双向 mask 预测,没有左到右偏置,所以在 reversal task 上明显更稳,甚至在这个任务上超过 GPT-4o。
文章目录
- note
- 一、研究背景
- 二、LLaDA
-
- [1. 前向数据掩码过程](#1. 前向数据掩码过程)
- [2. 反向生成过程](#2. 反向生成过程)
- [3. 模型分布定义](#3. 模型分布定义)
- 三、实验设计
- 四、结果分析
- Reference
一、研究背景
- 研究问题:这篇文章要解决的问题是大语言模型(LLMs)是否只能依赖于自回归模型(ARMs)来实现其核心能力,如可扩展性、上下文学习和指令跟随。
- 研究难点:该问题的研究难点包括:如何在不使用自回归模型的情况下,通过生成模型原则实现LLMs的核心能力;如何在有限的计算预算下实现大规模语言模型的扩展。
- 相关工作:该问题的研究相关工作有:自回归模型在LLMs中的广泛应用和成功;扩散模型在视觉数据上的成功应用;以及对现有扩散模型在语言建模中的潜在扩展的研究。
二、LLaDA
这篇论文提出了LLaDA(Large Language Diffusion with mAsking),一种从预训练和监督微调(SFT)范式下从头开始训练的扩散模型。
预训练时对整句按随机比例 mask;SFT 时只 mask response;生成时从全 mask 的 response 一步步还原。
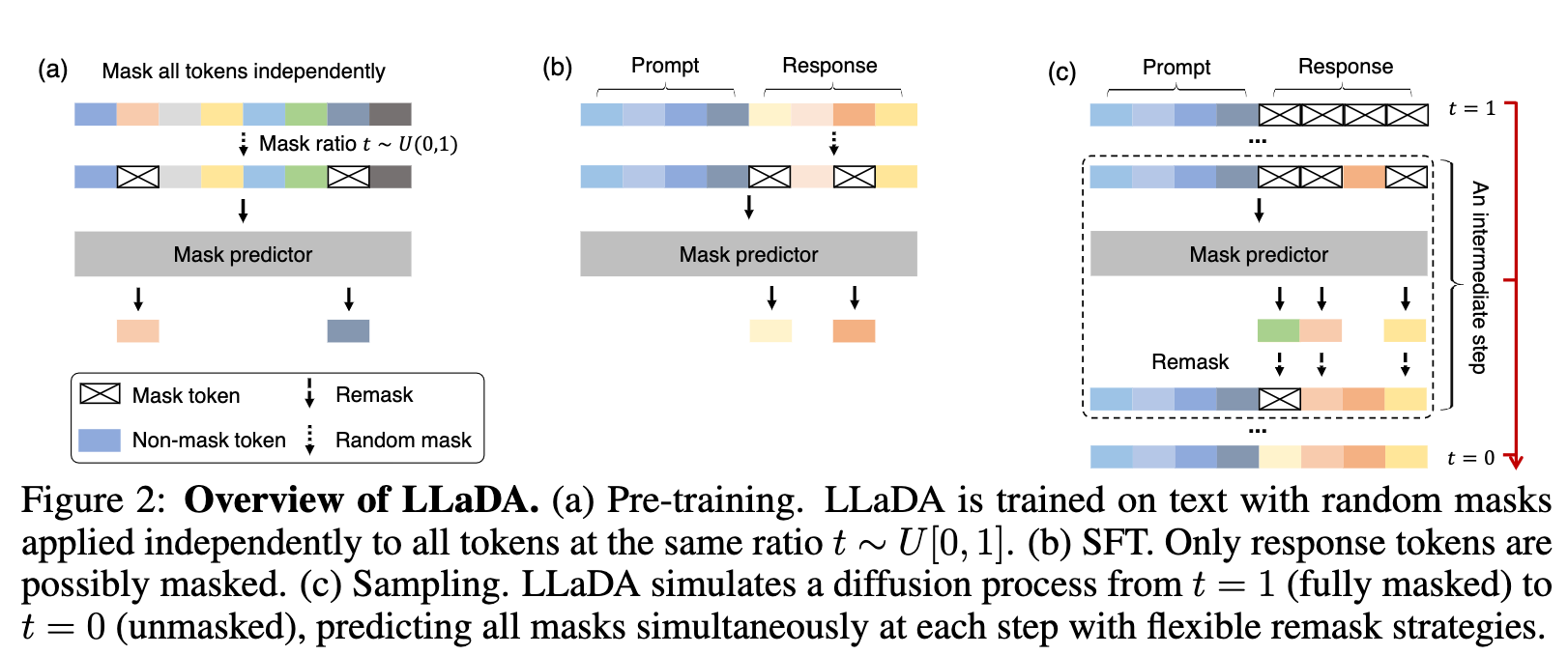
1. 前向数据掩码过程
首先,LLaDA通过逐步独立地掩码序列中的令牌来生成一个部分掩码的序列。对于时间 t ∈ ( 0 , 1 ) t \in (0, 1) t∈(0,1),序列 x t x_t xt是部分掩码的,每个令牌被掩码的概率是 t t t,未被掩码的概率是 1 − t 1 - t 1−t。
2. 反向生成过程
然后,LLaDA通过迭代预测掩码令牌来恢复数据分布。核心是一个掩码预测器,一个参数模型 p θ ( ⋅ ∣ x t ) p_\theta(\cdot|x_t) pθ(⋅∣xt),它接受 x t x_t xt作为输入并预测所有掩码令牌。该模型使用交叉熵损失进行训练:
L ( θ ) ≜ − E t , x 0 , x t 1 t ∑ i = 1 L 1 \[ x t i = M log p θ ( x 0 i ∣ x t ) ] \mathcal{L}(\theta) \triangleq - \mathbb{E}{t, x_0, x_t} \left \\frac{1}{t} \\sum_{i=1}\^L \\mathbb{1}\[x_t\^i = M \log p\theta(x_0^i|x_t) \right] L(θ)≜−Et,x0,xtt1i=1∑L1\[xti=Mlogpθ(x0i∣xt)]
其中:
- x 0 x_0 x0是训练样本
- t t t是从 0 , 1 0, 1 0,1均匀抽取的连续随机变量
- x t x_t xt是从前向过程中采样的
- L L L是序列长度
3. 模型分布定义
一旦训练完成,可以通过掩码预测器参数化的反向过程来模拟反向过程,并在 t = 0 t = 0 t=0时定义模型分布 p θ ( x 0 ) p_\theta(x_0) pθ(x0)作为边缘分布。损失函数在方程(4)中被证明是模型分布负对数似然的上界,使其成为生成建模的有力目标。
三、实验设计
- 数据收集:预训练语料库由来自公共来源的多样化数据构成,包括网络数据、书籍、学术文章、社交媒体、百科全书、数学和代码,约11%是中文,61%是英文,28%是代码。SFT数据集包括100万个人工标注样本和350万个合成样本。
- 数据预处理:数据清理涉及PDF文本提取、去重和有害内容过滤。为了确保质量,使用BERT模型进行自动化数据质量注释,以选择更高质量的样本。
- 模型训练:LLaDA采用Transformer架构作为掩码预测器,并使用AdamW优化器和Warmup-Stable-Decay学习率调度器进行训练。预训练过程中,使用固定序列长度4096,计算成本为0.13百万H800 GPU小时。SFT过程中,使用动态序列长度策略,确保所有样本具有相同的长度。
四、结果分析
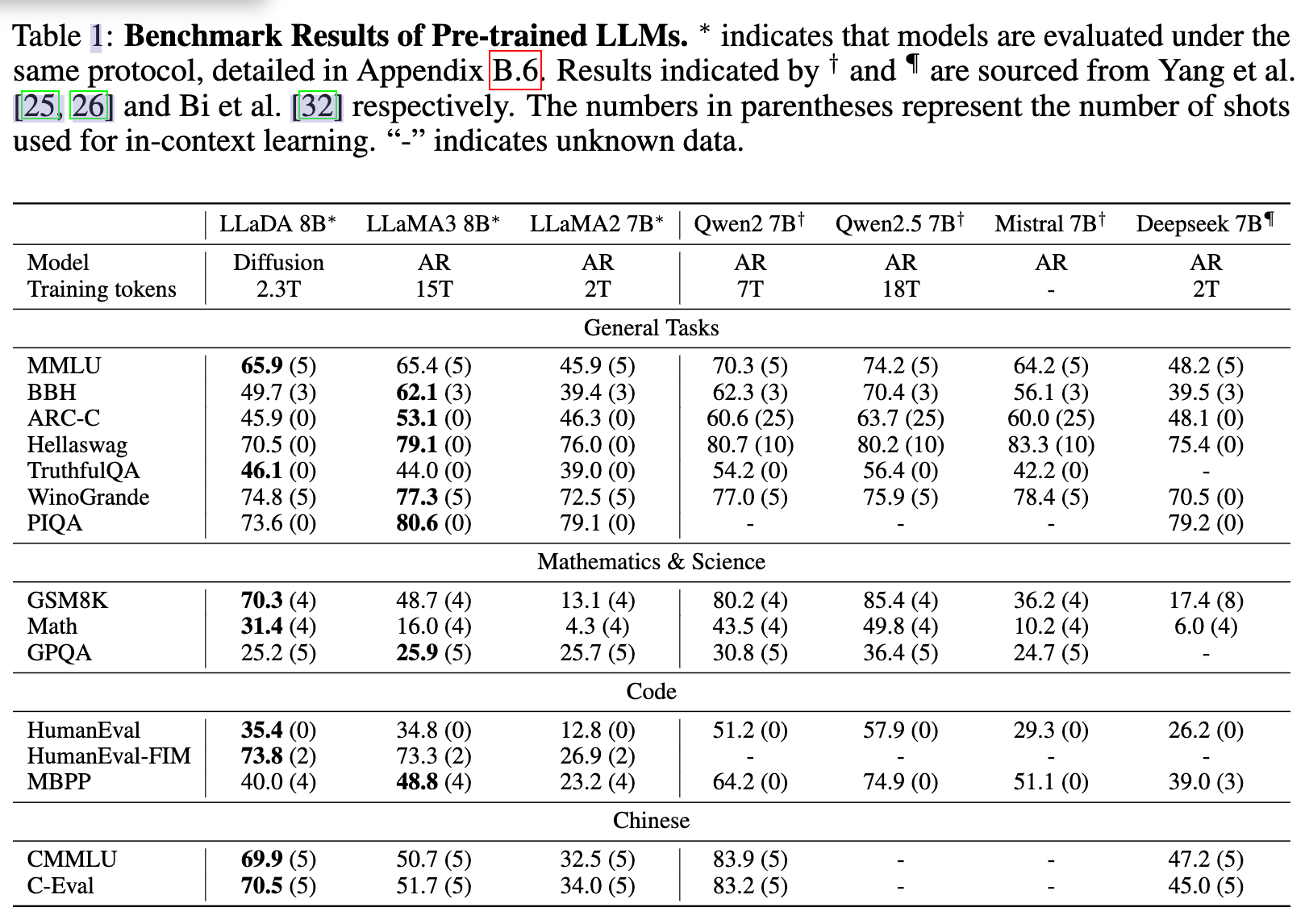
- 可扩展性:LLaDA在六个标准任务上展示了令人印象深刻的可扩展性,整体趋势与ARMs高度竞争。特别是在MMLU和GSM8K任务上,LLaDA表现出更强的可扩展性。
- 基准测试结果:在预训练2.3T令牌后,LLaDA 8B Base在几乎所有15个标准零样本/少样本学习任务上超越了LLaMA2 7B Base,并且在大多数任务上与LLaMA3 8B Base表现相当。
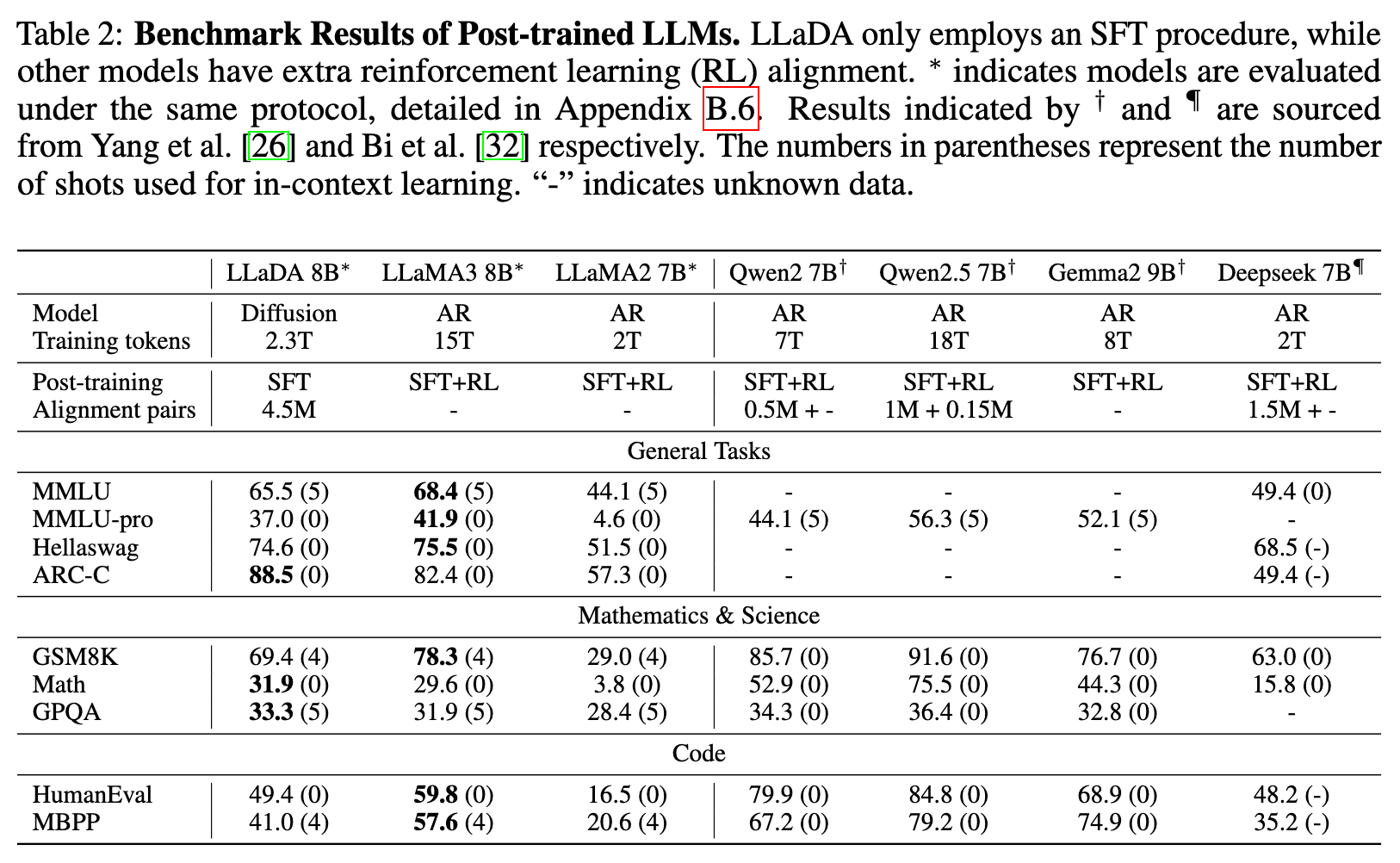
- 指令跟随能力:SFT显著增强了LLaDA的指令跟随能力,如多轮对话案例所示。
- 反转推理能力:LLaDA有效地打破了反转诅咒,在正向和反转任务上表现一致。特别是在反转诗歌完成任务中,LLaDA超越了GPT-4o。
Reference
1 Large Language Diffusion Models