为什么 Karpathy 的「LLM Wiki」突然火了?
2026 年 4 月 4 日,Andrej Karpathy 发布了《LLM Wiki》这篇 gist。它不是一篇在炫新模型参数的文章,而是在讨论一种新的知识工作方式:别再把大模型只当作"临时回答问题的机器",而要把它变成一个持续整理、维护、进化知识库的助手。
这篇文章最近之所以迅速传播,不是因为它提出了一个陌生术语,而是因为它把很多人正在模糊感受到的问题,讲得非常清楚:今天的大模型很会回答,但还不太会积累。
第一部分:速读版 / 核心要点
发生了什么
Karpathy 提出了一种叫"LLM Wiki"的思路:让大模型把论文、网页、会议记录、数据和笔记,逐步整理成一个持续存在、可以不断更新的 wiki,而不是每次等人提问时再临时去检索原始资料、拼一个答案出来。
它火的原因很直接,因为这套想法切中了当前 AI 使用中的一个真实痛点:我们已经很擅长用模型"问一次、答一次",但还不擅长让模型"越用越懂、越用越会整理"。
一句话理解
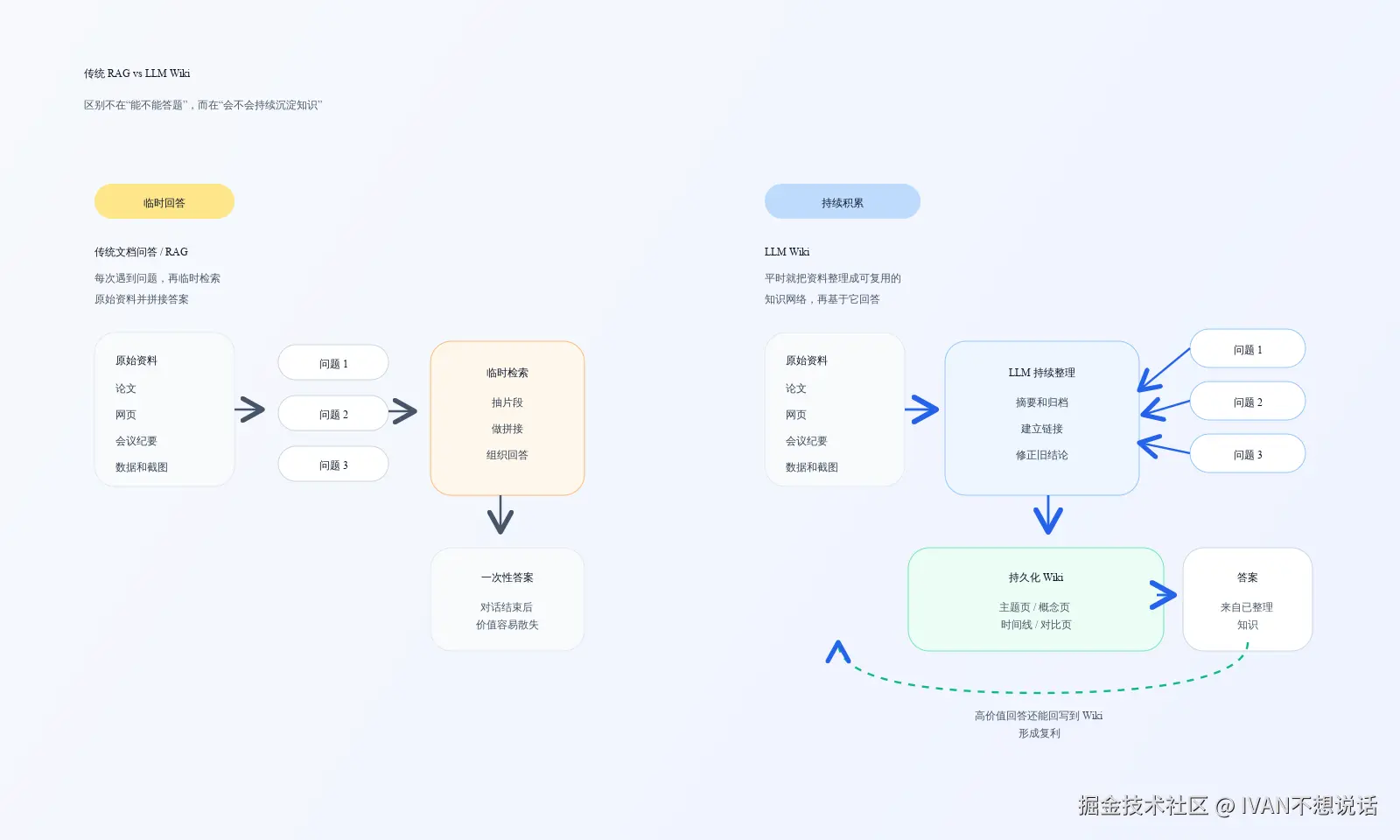
传统 RAG 更像"每次提问都重新开卷搜索";LLM Wiki 更像"让模型平时就把知识整理成一套可复用的百科,再基于这套百科回答问题"。
核心观点
- 这件事的重点不是"回答一个问题",而是"建设一层会持续生长的知识结构"。
- 它和传统文档问答的最大区别,不在于有没有检索,而在于有没有长期沉淀。
- Karpathy 想解决的根本问题是:为什么 AI 给过很多好答案,但这些答案很难沉淀为以后还能复用的知识。
- 在这套思路里,模型不只是聊天工具,更像一个持续维护 wiki 的知识库编辑。
- 这件事之所以重要,是因为它可能代表了 AI 进入知识工作后的下一种主流形态。
为什么值得关注
如果这个方向成立,人与 AI 的关系就会发生变化。人不再需要一遍遍从零提问,模型也不再一遍遍从零作答;两者是在共同维护一个会不断完善的"外部大脑"。
对普通读者来说,最值得记住的一点是:LLM Wiki 不是在教模型记住更多,而是在教模型把零散信息整理成可积累、可导航、可更新的知识系统。
第二部分:详细版 / 完整解读
1. 背景问题:为什么现有 AI 文档问答还不够好
大多数人现在处理"文档 + 大模型"的方式,本质上都接近 RAG。你上传一些论文、网页、会议记录或报告,等你提问时,模型再从里面找相关片段,临时拼出一个回答。
这种方式当然有用,但问题也很明显:它每次都像重新开卷考试。
你今天问一次,它去翻资料、提取片段、组织语言。你明天换个角度再问一次,它又得再来一遍。即便这两个问题高度相关,模型也不会自动沉淀出一套越来越完整的知识结构。
换句话说,传统文档问答的重点是"回答当前问题";而 Karpathy 想推动的是另一件事:能不能让模型先把知识整理好,再来回答问题。
2. 核心定义:LLM Wiki 到底是什么
Karpathy 的核心想法是:让大模型把原始资料逐步"编译"成一个持续存在的 wiki。
这里的 wiki,不是指维基百科那样的公共网站,而是你自己的知识仓库。它通常由一组 Markdown 文件组成,可能放在 Obsidian 或 Git 仓库里。里面有主题页、人物页、概念页、对比页、时间线,以及索引页与日志页。
重点不在于"把资料存进去",而在于让模型持续维护这些页面之间的关系。例如你新加入一篇行业报告,模型不是只把它扔进检索库里等以后来搜,而是会读这篇报告、提炼关键信息、更新已有主题页、修正旧结论、标记与旧资料冲突的地方、补充交叉链接。
于是知识不再只是"查出来的",而是"平时就已经整理好了"。
3. 架构解释:它为什么说起来新,搭起来却不一定重
Karpathy 在 gist 里把这个模式概括成三层,这也是整套方案的核心骨架:
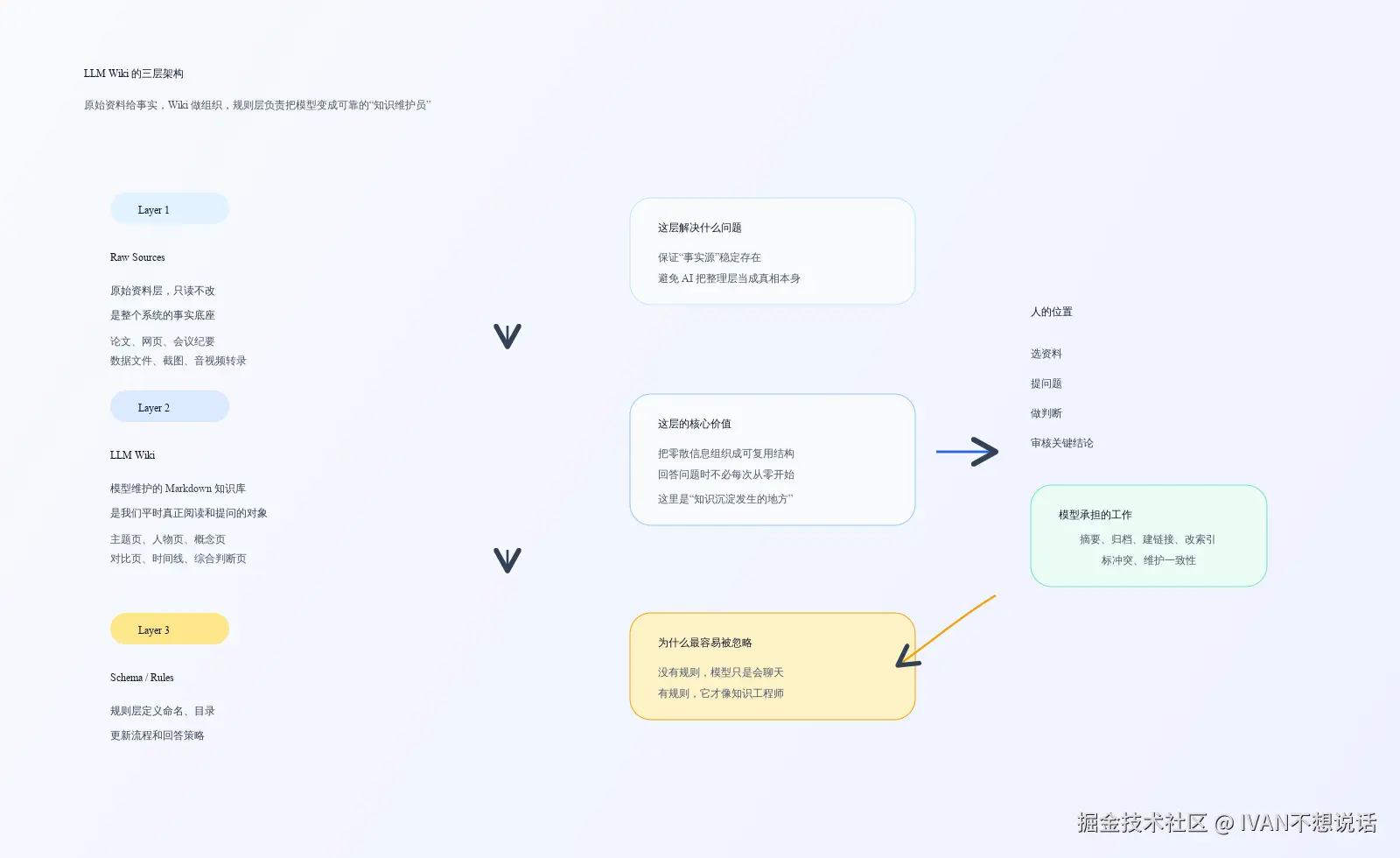
第一层是原始资料层。论文还是论文,网页还是网页,原始记录不应该被模型随意改写。它们是整个知识系统的事实底座。
第二层是 wiki 层。这一层才是 LLM 真正施展能力的地方。模型把零散信息整理成结构化页面,并维护页面之间的链接关系。你读的是这一层,模型写的也是这一层。
第三层是规则层。它决定了模型什么时候新建页面、什么时候更新已有页面、如何命名、如何写索引、如何记录冲突,也决定了它到底是"聊天机器人",还是"知识库维护员"。
这也是为什么很多人看完会觉得它既新颖又现实。新颖在于它重新定义了模型在知识工作里的角色;现实在于它未必依赖很重的基础设施,很多时候 Markdown、Obsidian、Git 再加一套明确规则,就已经能搭出雏形。
4. 运行机制:为什么关键是 Ingest、Query、Lint 三个动作
Karpathy 在原文里强调了三个操作:Ingest、Query、Lint。翻成更容易理解的话,就是:摄入、查询、体检。
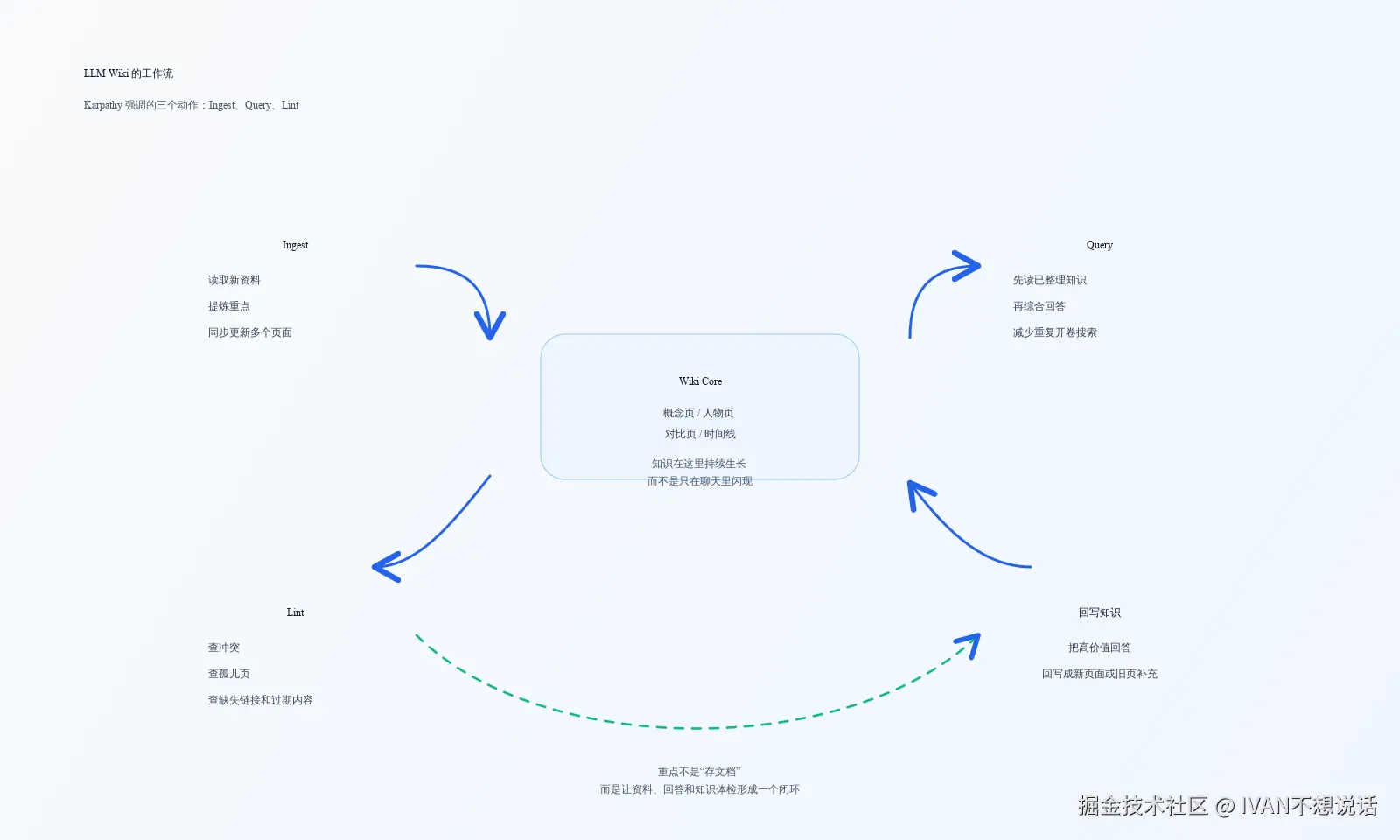
Ingest 的重点,是把新资料真正"吃进去"。你放进来一篇新文章,模型可能会同时更新 10 到 15 个页面。这体现了它和普通笔记最大的区别:你不是在新增一条笔记,而是在更新整个知识网络。
Query 的重点,是基于整理后的知识来回答。你提问时,模型不必每次从原始资料重新摸索,而是先读 wiki 里已经整理好的页面,再进行综合分析。这样回答会更稳定,也更像"长期研究之后得出的看法"。
Lint 的重点,是定期给知识库做体检。模型会检查不同页面之间是否互相矛盾、哪些结论已经被新资料推翻、哪些页面没有被其他页面链接、哪些地方还缺少关键资料。它做的已经不只是"存储知识",而是维护知识结构的健康度。
5. 关键细节:为什么 index.md 和 log.md 很重要
Karpathy 提到,在中等规模下,一个维护良好的 index.md 再加一个按时间记录变化的 log.md,就已经很有用了。
index.md 像地图,帮助模型知道"有哪些页面""该先读什么""主题在哪"。log.md 像时间轴,帮助模型理解最近发生了什么、哪些内容刚刚更新过。
这两个文件看起来不起眼,但它们非常关键,因为它们让系统从"零散页面堆积"变成"可导航、可维护的知识库"。这也是 LLM Wiki 看起来朴素、却很容易真正落地的原因之一。
6. 为什么这个想法一下子打动了很多人
因为它解决的不是"AI 会不会答题",而是"AI 能不能帮人长期做知识工作"。
过去,很多高质量的 AI 输出都会消失在对话框里。你问了一个很好的问题,模型也给了一个很好的分析,但聊天结束后,这些价值常常就散掉了。LLM Wiki 提醒了大家一件事:好的回答不应该只是对话,它应该变成知识库的一部分。
一旦这件事成立,整个工作方式就会改变。你不再是一次次从零开始问,模型也不再一次次从零开始答。你们是在一起维护一个会越长越完整的"外部大脑"。
7. 为什么它看起来比很多人想象中更现实
一个很有意思的点是,这个方案并不一定依赖重型基础设施。它未必一开始就需要复杂向量数据库或高门槛工程系统。Markdown、Obsidian、Git、索引页、日志页,这些现成工具加上 LLM 的整理能力,就已经足够搭出最初的骨架。
所以它的吸引力不在于"更复杂",恰恰在于"更朴素"。它没有要求你先造一个超级系统,而是在提醒你:也许真正缺的不是更大的上下文,而是一层会被持续维护的知识组织层。
8. 本质上,它是在重新定义"人机分工"
LLM Wiki 真正聪明的地方,不是让 AI 替代人,而是把分工切得很合理。
- 人负责选资料
- 人负责判断方向
- 人负责提出好问题
- 人负责审核关键结论
- 模型负责摘要、归档、建链接、改索引、标冲突、维护一致性
这也是它最像"下一代知识工作流"的地方。因为知识工作的真正瓶颈,很多时候不是"不会想",而是"维护太累"。人擅长判断和提问,但不擅长长期做那些细碎、重复、必须又枯燥的维护工作;模型恰好在这方面很有潜力。
9. 边界与限制:它不是万能答案
LLM Wiki 也不是没有边界。它不意味着原始资料不重要,恰恰相反,原始资料越扎实,这个系统越可靠。它也不意味着模型不会犯错。模型依然可能误读、过度概括、错误链接,或者把猜测写得像事实。
所以更准确地说,它不是"让 AI 替你思考",而是让 AI 替你维护思考成果。在重要问题上,人仍然要负责判断、抽查和定稿。
10. 结论:它为什么值得被当作一个方向来认真看待
《LLM Wiki》之所以火,不是因为它展示了一个炫目的 demo,而是因为它提出了一种很多人一看就懂、而且马上想试的未来工作方式:
人不再一次次从零提问,模型也不再一次次从零作答;两者共同维护一套会持续生长的知识系统。
这可能才是大模型真正深入知识工作的关键一步。它的价值不只是"更快找到答案",而是"更持续地建设理解"。
参考来源
- Karpathy 原始 gist:gist.github.com/karpathy/44...
- 本文解读依据其原文中关于三层架构、
ingest/query/lint操作,以及index.md/log.md设计的描述:gist.githubusercontent.com/karpathy/44...