作为 Java 后端开发者,MyBatis 几乎是我们每天都在使用的持久层框架。它封装了 JDBC 的繁琐操作,让我们只需要关注 SQL 本身,大大提高了开发效率。但很多人用了很多年 MyBatis,却始终没有搞懂它的底层原理:
- Mapper 接口没有实现类,为什么能执行 SQL?
- 一个 SQL 查询从调用到返回结果,中间经历了什么?
- SqlSessionFactory 和 SqlSession 有什么区别?
- #{} 和 ${} 到底有什么不同?为什么 #{} 能防止 SQL 注入?
这些问题不仅是日常开发中排查问题的关键,更是面试中 100% 会被深挖的核心考点。很多人能写出 Mapper 接口和 XML 文件,却不知道为什么会出现 SQL 执行异常、缓存失效、参数绑定失败等问题。
这篇文章,我们就从核心架构→初始化流程→SQL 执行全流程→底层原理→面试重点五个维度,彻底搞懂 MyBatis。不仅会讲清楚理论,更会结合源码和实战,让你看完既能轻松应对面试,又能解决实际项目中的问题。
一、先搞懂:MyBatis 解决了什么问题?
在开始之前,我们先回顾一下传统 JDBC 开发的痛点,这样就能明白 MyBatis 的价值所在。
传统 JDBC 开发的痛点
java
public User getUserById(Long id) {
Connection conn = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
try {
// 1. 加载驱动
Class.forName("com.mysql.cj.jdbc.Driver");
// 2. 获取连接
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root", "password");
// 3. 创建PreparedStatement
String sql = "SELECT * FROM user WHERE id = ?";
pstmt = conn.prepareStatement(sql);
// 4. 设置参数
pstmt.setLong(1, id);
// 5. 执行查询
rs = pstmt.executeQuery();
// 6. 处理结果集
if (rs.next()) {
User user = new User();
user.setId(rs.getLong("id"));
user.setName(rs.getString("name"));
user.setAge(rs.getInt("age"));
return user;
}
return null;
} catch (Exception e) {
e.printStackTrace();
} finally {
// 7. 关闭资源
try {
if (rs != null) rs.close();
if (pstmt != null) pstmt.close();
if (conn != null) conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
return null;
}可以看到,传统 JDBC 开发存在以下致命问题:
- 代码冗余:每次执行 SQL 都要重复编写获取连接、创建 Statement、关闭资源的代码
- 参数绑定繁琐:需要手动设置每个参数的类型和值
- 结果集处理麻烦:需要手动遍历 ResultSet,将数据映射到 Java 对象
- 连接管理困难:频繁创建和关闭连接会严重影响性能
- SQL 硬编码:SQL 写在 Java 代码中,修改 SQL 需要重新编译
MyBatis 的解决方案
MyBatis 是一个半自动化的 ORM 框架,它在 JDBC 的基础上进行了轻量级封装,解决了传统 JDBC 的所有痛点:
- 消除了 JDBC 的冗余代码:自动管理连接、Statement 和资源的关闭
- 自动参数绑定:支持多种参数类型,自动将 Java 对象映射到 SQL 参数
- 自动结果集映射:支持将 ResultSet 自动映射到 Java 对象,支持复杂的关联映射
- 连接池管理:内置连接池,避免频繁创建和关闭连接
- SQL 与代码分离:SQL 写在 XML 文件中,便于维护和优化
- 缓存机制:支持一级缓存和二级缓存,提高查询性能
ORM 即对象关系映射(Object-Relational Mapping),是一种为了解决面向对象编程与关系型数据库数据模型不匹配问题的技术。它通过建立程序对象与数据库表之间的映射关系,实现对象数据与数据库记录的自动转换,让开发者可以用面向对象的方式来操作数据库,无需频繁编写原生 SQL 语句,从而减少数据访问层的重复代码、提升开发效率;像 MyBatis 这类半自动化 ORM 框架,虽仍需手动编写 SQL,但能自动完成结果集到对象的映射,兼顾了 SQL 优化的灵活性与对象操作的便捷性。
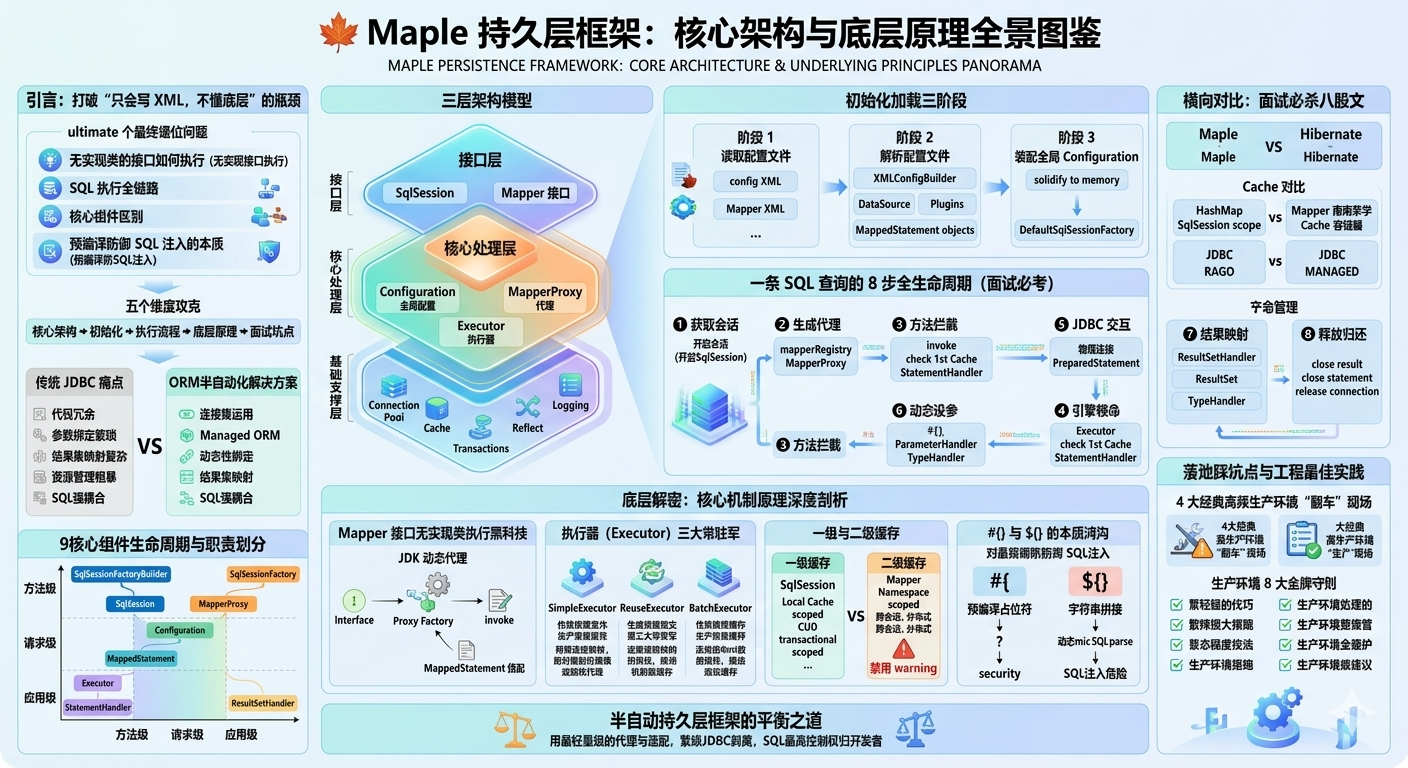
二、MyBatis 核心架构与组件
MyBatis 的架构非常清晰,分为三层:接口层 、核心处理层 和基础支撑层。
整体架构图
┌─────────────────────────────────────────────────────────┐
│ 接口层 │
│ SqlSessionFactoryBuilder → SqlSessionFactory → SqlSession │
└─────────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────┐
│ 核心处理层 │
│ Configuration → MapperProxy → Executor → StatementHandler │
│ ↓ │
│ ResultSetHandler → TypeHandler │
└─────────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────┐
│ 基础支撑层 │
│ 连接池、事务管理、缓存、日志、反射、数据源 │
└─────────────────────────────────────────────────────────┘9 大核心组件详解
这 9 个组件是 MyBatis 的核心,每个组件各司其职,共同完成 SQL 的执行。其中SqlSessionFactory、SqlSession、MapperProxy、Executor、StatementHandler是面试最常考的五个,必须重点掌握。
| 组件 | 作用 | 生命周期 |
|---|---|---|
| SqlSessionFactoryBuilder | 构建 SqlSessionFactory,负责解析配置文件 | 方法级,用完即销毁 |
| SqlSessionFactory | 创建 SqlSession 的工厂,是 MyBatis 的核心对象 | 应用级,整个应用生命周期内只有一个 |
| SqlSession | 与数据库交互的会话,提供了 CRUD 方法 | 请求 / 线程级,每次请求创建一个,用完即关闭 |
| MapperProxy | Mapper 接口的代理对象,负责将接口方法调用转换为 SQL 执行 | 方法级,每个 Mapper 方法调用创建一个 |
| Configuration | MyBatis 的全局配置对象,保存了所有配置信息 | 应用级,与 SqlSessionFactory 同生命周期 |
| MappedStatement | 保存了一个 SQL 语句的所有信息(SQL、参数、结果映射等) | 应用级,启动时创建,永久保存 |
| Executor | 负责执行 SQL 语句,管理事务和缓存 | SqlSession 级,每个 SqlSession 对应一个 Executor |
| StatementHandler | 负责与 JDBC 的 Statement 交互,设置参数、执行 SQL | 方法级,每次 SQL 执行创建一个 |
| ResultSetHandler | 负责处理结果集,将 ResultSet 映射到 Java 对象 | 方法级,每次 SQL 执行创建一个 |
三、MyBatis 初始化流程
MyBatis 的初始化过程,本质上就是解析配置文件,创建 SqlSessionFactory 的过程。整个过程可以分为三个阶段:
阶段 1:读取配置文件
MyBatis 的配置文件分为两种:
- 全局配置文件 :通常是
mybatis-config.xml,配置了数据源、事务、插件、Mapper 映射等全局信息 - Mapper 映射文件 :通常是
XxxMapper.xml,配置了 SQL 语句、参数映射、结果映射等
java
// 读取全局配置文件
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
// 构建SqlSessionFactory
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);阶段 2:解析配置文件
SqlSessionFactoryBuilder会调用XMLConfigBuilder来解析全局配置文件:
- 解析
<properties>标签,加载属性文件 - 解析
<settings>标签,设置全局配置参数 - 解析
<environments>标签,配置数据源和事务管理器 - 解析
<mappers>标签,加载所有 Mapper 映射文件 - 解析每个 Mapper 映射文件,生成
MappedStatement对象 - 将所有配置信息封装到
Configuration对象中
阶段 3:创建 SqlSessionFactory
解析完成后,SqlSessionFactoryBuilder会根据Configuration对象创建一个DefaultSqlSessionFactory实例。
核心结论 :MyBatis 的初始化过程就是将所有配置信息加载到内存中,生成一个Configuration对象,然后基于这个对象创建SqlSessionFactory。整个应用生命周期内,只需要初始化一次。
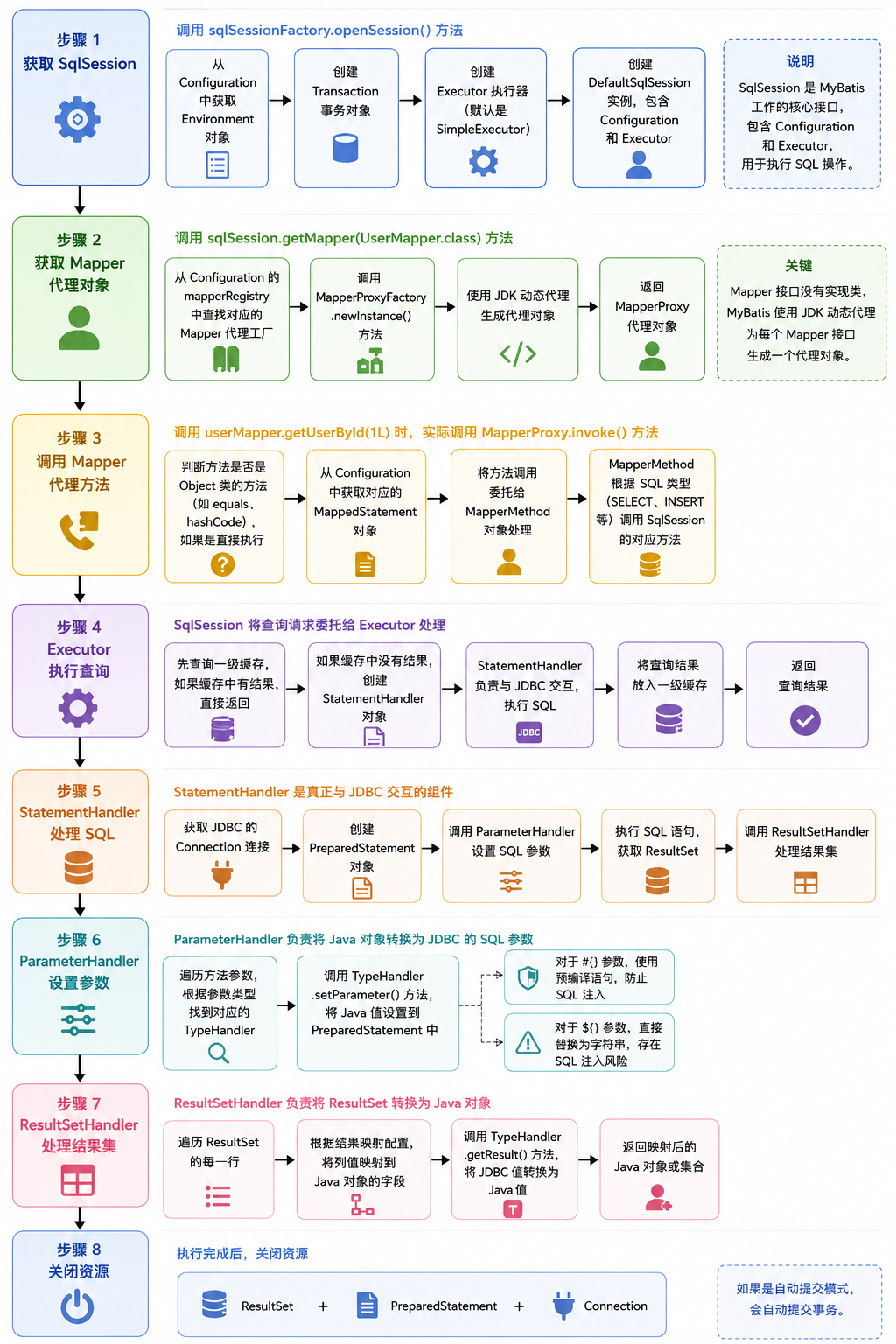
四、SQL 执行的完整流程(面试必背)
这是 MyBatis 最核心的内容,也是面试 100% 会问的问题。我把整个流程拆解成 8 个步骤,每个步骤都讲清楚做了什么,由哪个组件负责。
我们以一个最简单的查询为例,来拆解整个执行流程:
java
// 1. 获取SqlSession
SqlSession sqlSession = sqlSessionFactory.openSession();
// 2. 获取Mapper代理对象
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
// 3. 执行查询
User user = userMapper.getUserById(1L);
// 4. 关闭SqlSession
sqlSession.close();完整执行流程
步骤 1:获取 SqlSession
调用sqlSessionFactory.openSession()方法,创建一个 SqlSession 实例:
- 从
Configuration中获取Environment对象 - 创建
Transaction事务对象 - 创建
Executor执行器(默认是SimpleExecutor) - 创建
DefaultSqlSession实例,包含Configuration和Executor
步骤 2:获取 Mapper 代理对象
调用sqlSession.getMapper(UserMapper.class)方法,获取 Mapper 接口的代理对象:
- 从
Configuration的mapperRegistry中查找对应的 Mapper 代理工厂 - 调用
MapperProxyFactory.newInstance()方法,使用 JDK 动态代理生成代理对象 - 返回
MapperProxy代理对象
关键:Mapper 接口没有实现类,MyBatis 使用 JDK 动态代理为每个 Mapper 接口生成一个代理对象。
步骤 3:调用 Mapper 代理方法
当调用userMapper.getUserById(1L)时,实际上调用的是MapperProxy.invoke()方法:
- 判断方法是否是 Object 类的方法(如 equals、hashCode),如果是直接执行
- 从
Configuration中获取对应的MappedStatement对象 - 将方法调用委托给
MapperMethod对象处理 MapperMethod根据 SQL 类型(SELECT、INSERT 等)调用 SqlSession 的对应方法
步骤 4:Executor 执行查询
SqlSession 将查询请求委托给Executor处理:
- 先查询一级缓存,如果缓存中有结果,直接返回
- 如果缓存中没有结果,创建
StatementHandler对象 StatementHandler负责与 JDBC 交互,执行 SQL- 将查询结果放入一级缓存
- 返回查询结果
步骤 5:StatementHandler 处理 SQL
StatementHandler是真正与 JDBC 交互的组件,它会做以下事情:
- 获取 JDBC 的
Connection连接 - 创建
PreparedStatement对象 - 调用
ParameterHandler设置 SQL 参数 - 执行 SQL 语句,获取
ResultSet - 调用
ResultSetHandler处理结果集
步骤 6:ParameterHandler 设置参数
ParameterHandler负责将 Java 对象转换为 JDBC 的 SQL 参数:
- 遍历方法参数,根据参数类型找到对应的
TypeHandler - 调用
TypeHandler.setParameter()方法,将 Java 值设置到 PreparedStatement 中 - 对于
#{}参数,使用预编译语句,防止 SQL 注入 - 对于
${}参数,直接替换为字符串,存在 SQL 注入风险
步骤 7:ResultSetHandler 处理结果集
ResultSetHandler负责将ResultSet转换为 Java 对象:
- 遍历 ResultSet 的每一行
- 根据结果映射配置,将列值映射到 Java 对象的字段
- 调用
TypeHandler.getResult()方法,将 JDBC 值转换为 Java 值 - 返回映射后的 Java 对象或集合
步骤 8:关闭资源
执行完成后,关闭ResultSet、PreparedStatement和Connection(如果是自动提交模式,会自动提交事务)。
执行流程图
五、核心原理深入解析
1. Mapper 代理的实现原理
这是面试最常问的问题:Mapper 接口没有实现类,为什么能执行 SQL?
答案是:MyBatis 使用 JDK 动态代理为每个 Mapper 接口生成了一个代理对象。
实现过程
- 当 MyBatis 初始化时,会扫描所有 Mapper 接口,为每个接口创建一个
MapperProxyFactory - 当调用
sqlSession.getMapper()时,MapperProxyFactory会使用 JDK 动态代理生成一个代理对象 - 代理对象的
invoke()方法会拦截所有接口方法的调用 - 根据方法的全限定名(接口名 + 方法名)找到对应的
MappedStatement - 调用 SqlSession 的对应方法执行 SQL
核心源码
java
// MapperProxyFactory生成代理对象
public T newInstance(SqlSession sqlSession) {
final MapperProxy<T> mapperProxy = new MapperProxy<>(sqlSession, mapperInterface, methodCache);
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}
// MapperProxy的invoke方法
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
}
final MapperMethod mapperMethod = cachedMapperMethod(method);
return mapperMethod.execute(sqlSession, args);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}2. Executor 的三种类型
MyBatis 提供了三种 Executor 实现,分别适用于不同的场景:
| Executor 类型 | 特点 | 适用场景 |
|---|---|---|
| SimpleExecutor | 默认实现,每次执行 SQL 都创建一个新的 Statement | 大多数场景 |
| ReuseExecutor | 重用 Statement 对象,避免重复创建 | 频繁执行相同 SQL 的场景 |
| BatchExecutor | 批量执行 SQL,将多个 SQL 批量提交到数据库 | 批量插入、更新场景 |
可以通过全局配置文件指定默认的 Executor 类型:
XML
<settings>
<setting name="defaultExecutorType" value="BATCH"/>
</settings>也可以在获取 SqlSession 时指定:
java
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH);3. 一级缓存与二级缓存
MyBatis 提供了两级缓存机制,用于提高查询性能。
一级缓存(本地缓存)
- 作用域:SqlSession 级,同一个 SqlSession 内的查询共享缓存
- 默认开启:不需要任何配置,默认开启
- 失效场景 :
- 执行了增删改操作
- 手动调用了
sqlSession.clearCache() - 提交或回滚了事务
- 关闭了 SqlSession
原理 :一级缓存本质上是一个 HashMap,存储在BaseExecutor中。每次查询时,先从缓存中查找,如果找到就直接返回,否则执行 SQL 查询并将结果放入缓存。
二级缓存(全局缓存)
- 作用域:Mapper 级,同一个 Mapper 的所有 SqlSession 共享缓存
- 默认关闭:需要手动开启
- 开启方式 :
-
在全局配置文件中开启二级缓存:
XML<settings> <setting name="cacheEnabled" value="true"/> </settings> -
在 Mapper 映射文件中添加
<cache/>标签:XML<mapper namespace="com.example.mapper.UserMapper"> <cache/> </mapper>
-
注意 :二级缓存存在很多坑,比如数据不一致问题、分布式环境下失效等,生产环境不推荐使用。
作用域相关:仅在同一 Mapper 的 SqlSession 共享,跨 Mapper 操作同表会导致逻辑失效 默认行为:执行增删改操作自动清空当前 Mapper 的二级缓存
失效场景:
- 执行了同 Mapper 下的 INSERT/UPDATE/DELETE 操作(无论是否提交事务,都会清空当前 Mapper 的二级缓存)
- 查询语句设置 flushCache="true"(执行该查询时会清空当前 Mapper 的二级缓存)
- 事务提交或回滚(若事务内包含增删改操作,会触发对应 Mapper 二级缓存的清空)
- 缓存达到 flushInterval 定时刷新间隔(按配置时间自动全量清空)
- 缓存数据超过 size 容量限制(按 LRU 策略淘汰旧数据)
- 未提交 SqlSession 的查询结果(不会写入二级缓存,相当于缓存未生效)
- 跨 Mapper 操作同一张表(如 UserMapper 和 UserExtMapper 都操作 user 表,一个 Mapper 执行增删改不会清空另一个 Mapper 的缓存,导致数据不一致)
- 实体类未实现 Serializable 接口(无法序列化存储,缓存失效)
**原理:**二级缓存默认使用 PerpetualCache 实现,通过 CacheKey(包含 statementId、参数、RowBounds 等)标识缓存条目,失效时会清空对应 Mapper 的缓存空间或淘汰指定条目。
4. #{} 和 ${} 的区别
这是面试必问的问题,也是最容易踩坑的地方。
| 特性 | #{} | ${} |
|---|---|---|
| 处理方式 | 预编译处理,替换为? | 字符串替换,直接替换为参数值 |
| SQL 注入 | 能防止 SQL 注入 | 不能防止 SQL 注入 |
| 适用场景 | 所有参数传递 | 动态表名、动态列名等需要直接替换 SQL 的场景 |
| 类型处理 | 会自动进行 Java 类型到 JDBC 类型的转换 | 不会进行类型转换,直接作为字符串处理 |
为什么 #{} 能防止 SQL 注入?
因为 #{} 使用预编译语句,SQL 语句在执行前已经编译完成,参数只是作为数据传入,不会改变 SQL 的结构。而 ${} 是直接将参数值替换到 SQL 语句中,如果参数值包含恶意 SQL 代码,就会导致 SQL 注入。
示例:
sql
-- 使用#{}
SELECT * FROM user WHERE name = #{name}
-- 编译后:SELECT * FROM user WHERE name = ?
-- 参数:"张三' OR '1'='1"
-- 执行结果:查询name为"张三' OR '1'='1"的用户,不会返回所有用户
-- 使用${}
SELECT * FROM user WHERE name = ${name}
-- 编译后:SELECT * FROM user WHERE name = '张三' OR '1'='1'
-- 执行结果:返回所有用户,发生SQL注入六、面试重点与常见问题
1. MyBatis 和 Hibernate 的区别
| 特性 | MyBatis | Hibernate |
|---|---|---|
| 自动化程度 | 半自动化,需要手写 SQL | 全自动化,不需要手写 SQL |
| SQL 控制 | 完全控制 SQL,便于优化 | SQL 由框架生成,优化困难 |
| 学习成本 | 低,容易上手 | 高,需要掌握复杂的映射规则 |
| 性能 | 高,接近原生 JDBC | 低,有一定的性能开销 |
| 适用场景 | 复杂查询、性能要求高的场景 | 简单 CRUD、快速开发的场景 |
2. 一级缓存和二级缓存的区别
| 特性 | 一级缓存 | 二级缓存 |
|---|---|---|
| 作用域 | SqlSession 级 | Mapper 级 |
| 默认状态 | 开启 | 关闭 |
| 存储位置 | BaseExecutor 中的 HashMap | Mapper 的 Cache 对象中 |
| 共享范围 | 同一个 SqlSession | 同一个 Mapper 的所有 SqlSession |
| 数据一致性 | 好 | 差,可能出现数据不一致 |
3. MyBatis 的事务管理
MyBatis 的事务管理分为两种:
- JDBC 事务 :使用 JDBC 的
Connection来管理事务,通过commit()和rollback()方法提交和回滚 - MANAGED 事务:将事务管理交给容器(如 Spring),MyBatis 不负责事务的提交和回滚
在 Spring 整合 MyBatis 的环境中,通常使用 Spring 的声明式事务管理,不需要手动管理事务。
七、常见坑点与最佳实践
1. 常见坑点
坑 1:一级缓存导致的数据不一致
问题:同一个 SqlSession 内,两次查询同一个数据,中间有其他事务修改了数据,第二次查询会返回缓存中的旧数据。
解决方案:
- 避免在同一个 SqlSession 内执行长时间的操作
- 执行增删改操作后,手动清除缓存
- 对于需要实时性的数据,禁用一级缓存
坑 2:${} 导致的 SQL 注入
问题:使用 ${} 传递参数,会导致 SQL 注入漏洞。
解决方案:
- 优先使用 #{} 传递参数
- 对于必须使用 ${} 的场景(如动态表名),要对参数进行严格的校验和过滤
坑 3:批量操作性能问题
问题:使用循环插入大量数据,每次插入都创建一个新的 Statement,性能极差。
解决方案:
- 使用 BatchExecutor 进行批量操作
- 使用 MyBatis 的 foreach 标签生成批量插入 SQL
- 控制批量操作的大小,避免一次性插入过多数据
坑 4:结果集映射失败
问题:数据库列名和 Java 对象字段名不匹配,导致结果集映射失败。
解决方案:
-
使用别名,将列名别名设置为 Java 对象的字段名
-
使用
@Result注解或<resultMap>标签配置映射关系 -
开启驼峰命名自动映射:
XML<settings> <setting name="mapUnderscoreToCamelCase" value="true"/> </settings>
2. 最佳实践
- 优先使用 #{} 传递参数:防止 SQL 注入
- 开启驼峰命名自动映射:简化结果集映射
- 使用 BatchExecutor 进行批量操作:提高批量操作性能
- 避免使用二级缓存:防止数据不一致问题
- 合理使用分页插件:避免内存溢出
- SQL 不要写得太复杂:复杂 SQL 不利于维护和优化
- 使用参数别名:提高代码可读性
- 定期优化 SQL:使用 explain 分析 SQL 执行计划
八、高频面试题解答
-
问:MyBatis 的执行流程是什么? 答:MyBatis 的执行流程分为 8 个步骤:1. 获取 SqlSession;2. 获取 Mapper 代理对象;3. 调用 Mapper 代理方法;4. Executor 执行查询;5. StatementHandler 处理 SQL;6. ParameterHandler 设置参数;7. ResultSetHandler 处理结果集;8. 关闭资源。
-
问:Mapper 接口没有实现类,为什么能执行 SQL? 答:MyBatis 使用 JDK 动态代理为每个 Mapper 接口生成一个代理对象。当调用 Mapper 接口的方法时,实际上调用的是代理对象的 invoke () 方法,该方法会根据方法的全限定名找到对应的 MappedStatement,然后调用 SqlSession 的对应方法执行 SQL。
-
**问:#{} 和({}有什么区别?** 答:#{}是预编译处理,会将参数替换为?,能防止SQL注入;{} 是字符串替换,直接将参数值替换到 SQL 语句中,不能防止 SQL 注入。优先使用 #{},只有在需要动态表名、动态列名等场景下才使用 ${}。
-
问:MyBatis 的一级缓存和二级缓存有什么区别? 答:一级缓存是 SqlSession 级别的缓存,默认开启,同一个 SqlSession 内的查询共享缓存;二级缓存是 Mapper 级别的缓存,默认关闭,同一个 Mapper 的所有 SqlSession 共享缓存。一级缓存数据一致性好,二级缓存可能出现数据不一致问题,不推荐使用。
-
问:SqlSessionFactory 和 SqlSession 有什么区别? 答:SqlSessionFactory 是创建 SqlSession 的工厂,是 MyBatis 的核心对象,整个应用生命周期内只有一个;SqlSession 是与数据库交互的会话,提供了 CRUD 方法,每次请求创建一个,用完即关闭。
-
问:MyBatis 的 Executor 有哪几种类型? 答:MyBatis 提供了三种 Executor 类型:SimpleExecutor(默认,每次执行创建新的 Statement)、ReuseExecutor(重用 Statement)、BatchExecutor(批量执行 SQL)。
九、总结
MyBatis 是一个非常优秀的持久层框架,它的设计简洁优雅,既保留了 SQL 的灵活性,又消除了 JDBC 的繁琐操作。
回顾一下全文的核心内容:
- MyBatis 的初始化过程就是解析配置文件,创建 SqlSessionFactory 的过程
- SQL 执行的核心是 Mapper 代理,通过 JDK 动态代理将接口方法调用转换为 SQL 执行
- Executor 负责管理事务和缓存,StatementHandler 负责与 JDBC 交互
- #{} 使用预编译处理,能防止 SQL 注入,${} 是字符串替换,存在 SQL 注入风险
- 一级缓存是 SqlSession 级别的,默认开启;二级缓存是 Mapper 级别的,不推荐使用
理解了 MyBatis 的底层原理,你就能快速定位和解决开发中遇到的各种问题,比如 SQL 执行异常、参数绑定失败、缓存失效等。同时,这些内容也是面试中的高频考点,掌握了它们,你就能轻松应对所有 MyBatis 相关的面试题。