导读
让VLM(Vision-Language Model)用视觉工具辅助推理,听起来是个好主意------先高亮表格中的关键行列,再基于处理后的图像回答问题。但现实是,直接提示未经训练的VLM使用工具,性能不升反降:3B模型在图表任务上从51.8%暴跌到24.6%,几乎腰斩。问题出在哪?开源VLM根本不知道"什么时候该用工具、怎么用工具"。
UIUC团队提出的VTool-R1给出了一个干净的解法:用强化学习(GRPO)训练VLM自主决定是否调用视觉编辑工具,奖励信号只看最终答案对不对。训练后,7B模型在图表问答上达到80.7%,接近GPT-4o的82.9%,同时大幅超越同类RL方法R1-VL(63.8%)和Deepeyes(60.0%)。更有意思的是,训练过程中工具调用频率并非单调上升------模型学会了"选择性"使用工具,不需要时就不调。
论文信息
- 标题:VTool-R1: VLMs Learn to Think with Images via Reinforcement Learning on Multimodal Tool Use
- 作者:Mingyuan Wu, Jingcheng Yang, Jize Jiang, Meitang Li, Kaizhuo Yan, Hanchao Yu, Minjia Zhang, Chengxiang Zhai, Klara Nahrstedt
- 机构:University of Illinois Urbana-Champaign (UIUC), University of Michigan Ann Arbor
- 发表:ICLR 2026
- 代码 :github.com/VTOOL-R1/vt... (Apache 2.0)
一、为什么直接提示VLM用工具会"翻车"?
当前VLM在处理结构化图像(表格、图表)时,即使能"看到"图像,推理过程仍然高度依赖文本链。论文举了一个直观的例子:给模型看一张6根手指的图片问"有几根手指",模型很可能基于文本先验回答"五根"------因为"一只手五根手指"在文本推理路径中更"合理"。这说明纯文本Chain-of-Thought存在根本性的局限:模型并没有真正"看"图像中的细节。
一个自然的想法是给VLM配备视觉编辑工具------比如高亮表格中的特定行列、遮罩无关区域------让它先处理图像再推理。之前的ReFocus和Visual Sketchpad就是这个思路,但它们只在推理时使用工具,没有训练机制,依赖GPT-4o级别的商业模型才能产生有意义的视觉操作。
那如果直接给开源VLM提供工具呢?论文的实验数据给出了清晰的回答:
| 模型 | 任务 | Pure Run(不提供工具) | Tool Use(提示用工具,未经RL训练) | 性能变化 |
|---|---|---|---|---|
| Qwen2.5-VL 3B | Chart | 51.8% | 24.6% | -27.2pp |
| Qwen2.5-VL 3B | Table | 41.3% | 24.3% | -17.0pp |
| Qwen2.5-VL 7B | Chart | 76.2% | 53.4% | -22.8pp |
| Qwen2.5-VL 7B | Table | 64.7% | 41.1% | -23.6pp |
未经训练就提示使用工具,3B和7B模型的性能全面大幅下降。原因在于:这些模型从未被训练过工具使用能力,面对工具调用的prompt模板时,它们生成的工具调用代码质量极低,反而干扰了正常推理。
二、用强化学习教VLM什么时候该用工具
VTool-R1的核心设计是一个两阶段迭代推理框架,配合GRPO强化学习训练:
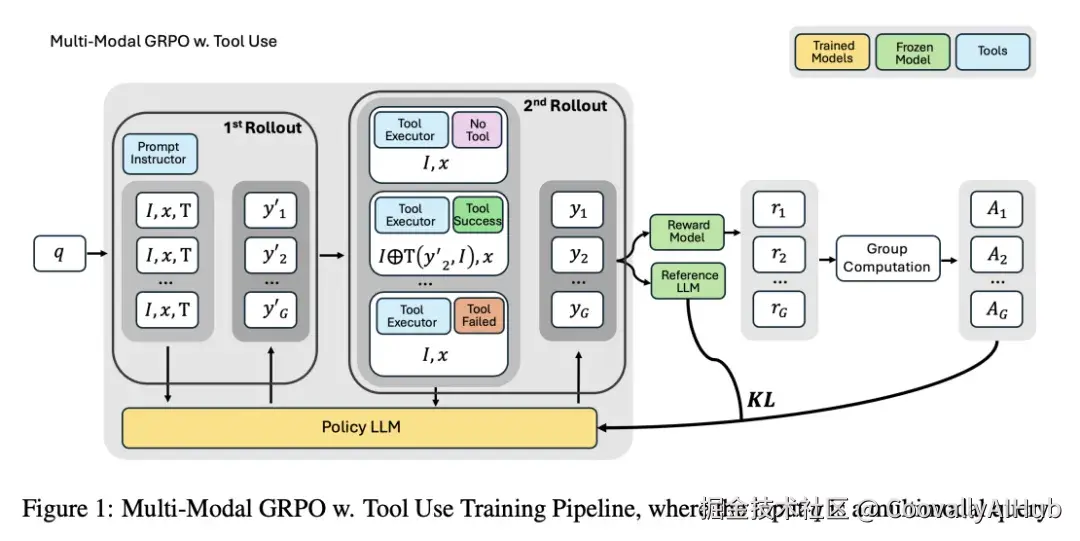
图片来源于原论文
推理流程分两轮:
- 第一轮Rollout:VLM接收原始图像和问题,在思考阶段(Thought 0)分析问题并决定是否需要视觉工具。如果需要,在Action 0中生成Python代码调用工具;如果不需要,直接回答。
- 工具执行:Python代码在外部环境中运行,生成编辑后的图像(如高亮了关键列的表格图片)。
- 第二轮Rollout:VLM同时接收原始图像和编辑后图像,基于两张图进行推理(Thought 1),给出最终答案。
当前版本聚焦单轮工具使用------模型最多调用一次工具,多轮迭代编辑留作未来工作。
视觉工具集包含6种基于OpenCV的Python编辑工具,按操作方式和目标维度组合:
| 操作方式 | 按列操作 | 按行操作 |
|---|---|---|
| 高亮(半透明红色) | focus_on_columns_with_highlight | focus_on_rows_with_highlight |
| 遮罩(白色覆盖无关区域) | focus_on_columns_with_mask | focus_on_rows_with_mask |
| 画框(红色边框) | focus_on_columns_with_draw | focus_on_rows_with_draw |
对图表任务,类似工具基于x轴或y轴位置对柱状图条形进行操作。模型可在一次Action中并行调用多个工具。
训练策略 采用GRPO(Group Relative Policy Optimization),基础模型为Qwen2.5-VL(3B/7B/32B)。训练的关键设计在于奖励信号:
- 纯结果导向(Outcome-based):用Qwen2.5-7B-Instruct作为轻量判官,只看最终答案是否正确------正确得1分,错误得0分。
- 不使用格式奖励,也不对工具调用过程本身做奖励或惩罚。
论文探索了两种过程奖励(Process-based Reward)方案,均失败:
- 惩罚失败工具调用:模型迅速学会完全不使用工具,工具调用率降为零。
- 奖励成功工具使用:模型出现Reward Hacking,生成表面"成功"但实际不辅助推理的工具调用。
训练效率方面,约50-100步即可收敛,在8-16张H100 GPU上不到1-2天完成。
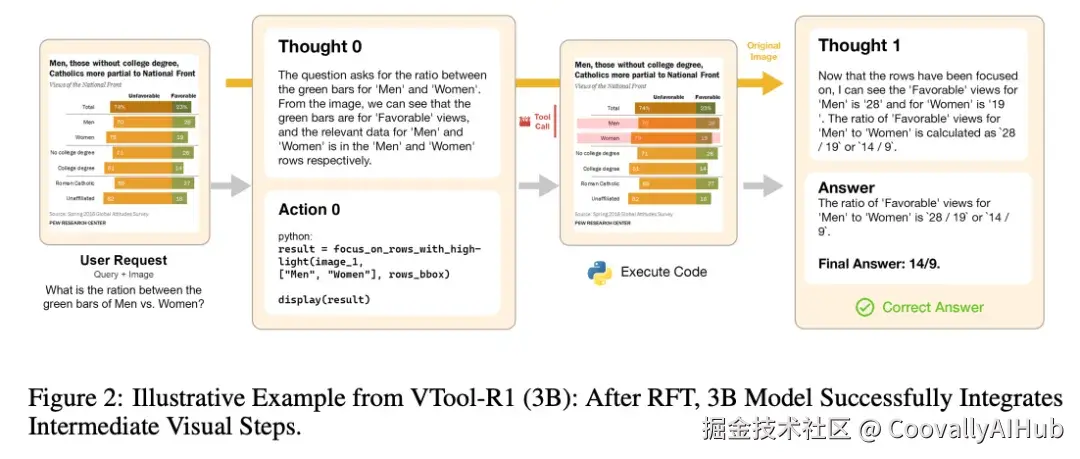
图片来源于原论文
三、实验结果:7B模型接近GPT-4o
主实验
VTool-R1训练后,各尺寸模型在图表和表格任务上的表现:
| 模型规模 | 任务 | Pure Run | Tool Use(未训练) | VTool-R1 | VTool-R1 vs Pure Run |
|---|---|---|---|---|---|
| 3B | Chart | 51.8% | 24.6% | 64.0% | +12.2pp |
| 3B | Table | 41.3% | 24.3% | 57.9% | +16.6pp |
| 7B | Chart | 76.2% | 53.4% | 80.7% | +4.5pp |
| 7B | Table | 64.7% | 41.1% | 71.7% | +7.0pp |
| 32B | Chart | 88.0% | 85.0% | 86.7% | -1.3pp |
| 32B | Table | 86.2% | 76.0% | 84.5% | -1.7pp |
3B和7B模型经VTool-R1训练后均获得显著提升,其中3B模型在Table任务上提升达+16.6pp。值得注意的是,32B模型的VTool-R1略低于Pure Run------大模型本身的推理能力已足够强,额外的工具步骤反而引入少量噪声。
与其他方法对比
| 方法 | Chart | Table |
|---|---|---|
| VTool-R1 7B | 80.7% | 71.7% |
| R1-VL 7B | 63.8% | 45.4% |
| R1-VL 2B | 10.4% | 8.6% |
| GPT-4o Pure Run | 82.9% | 75.7% |
| GPT-4o Tool Use | 80.5% | 77.0% |
几个关键对比:
- VTool-R1 7B vs GPT-4o Pure Run:Chart任务80.7% vs 82.9%,差距仅2.2pp;Table任务71.7% vs 75.7%,差距4.0pp。一个7B开源模型达到了接近GPT-4o的水平。
- VTool-R1 7B vs R1-VL 7B:Chart任务80.7% vs 63.8%(+16.9pp),Table任务71.7% vs 45.4%(+26.3pp)。R1-VL是通用视觉RL模型,仅训练文本CoT,不包含视觉工具使用步骤,在结构化推理任务上表现明显不足。
- VTool-R1 7B vs Deepeyes:在ChartQA上80.7% vs 60.0%(+20.7pp),论文将差异归因于VTool-R1更优的工具设计和训练方案。
四、消融实验:模型学会了"选择性"使用工具
论文中最有意思的发现之一来自训练动态分析:工具调用频率不与准确率单调增长。
3B模型的训练曲线显示:
- 训练早期:模型因为prompt中暴露了工具相关信息,倾向于过度使用工具
- 训练中后期:随着RL优化推进,模型逐渐学会更选择性地调用工具------只在工具确实有帮助时才调用,不需要时则直接推理
这种"先多后少"的非单调变化说明,模型不是简单地学会"总是用工具",而是学会了判断何时该用、何时不该用。
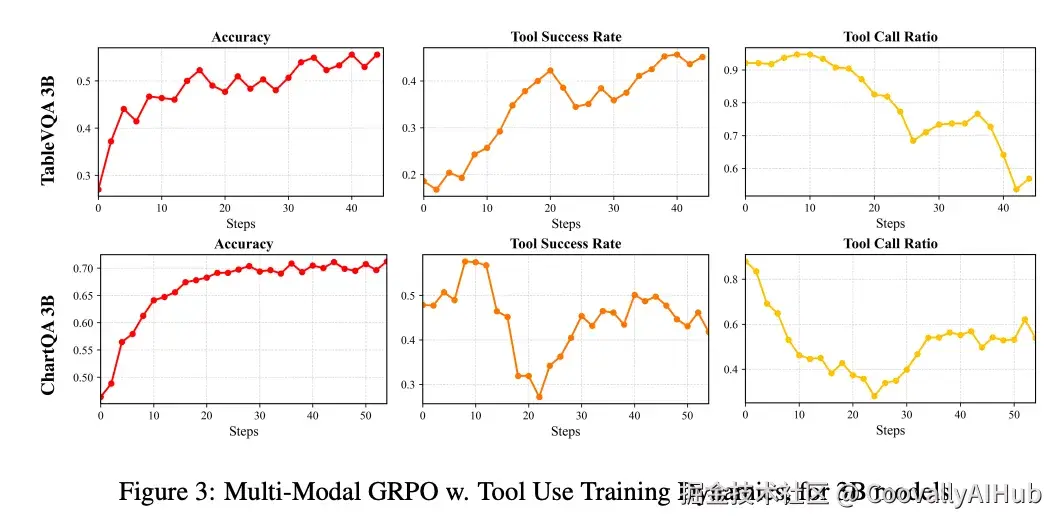
图片来源于原论文
32B模型的表现更直接地印证了这一点:VTool-R1 32B在Chart任务上为86.7%,略低于Pure Run的88.0%;在Table任务上为84.5%,略低于Pure Run的86.2%。对于已经足够强大的32B模型,工具使用带来的收益无法覆盖额外步骤引入的不确定性。
奖励设计消融进一步揭示了设计选择的关键性:
| 奖励方案 | 效果 |
|---|---|
| 纯结果导向(0/1匹配) | 模型学会有意义的工具使用,最可靠 |
| 惩罚失败工具调用 | 工具使用率降为零,模型完全回避工具 |
| 奖励成功工具使用 | Reward Hacking,生成无意义的"成功"调用 |
只有纯结果导向奖励能让模型在工具使用和推理质量之间找到平衡。
五、总结与思考
VTool-R1的核心贡献在于证明:纯结果导向的RL奖励足以让VLM自主学会何时、如何使用视觉工具,不需要对工具调用过程施加监督。过程奖励的两种失败模式(完全回避工具 / Reward Hacking)反而印证了端到端结果反馈的合理性。
两个值得关注的边界条件:一是32B模型训练后反而略低于Pure Run,说明工具辅助推理对能力足够强的大模型边际收益可能为负,更适合中小模型;二是当前仅支持单轮工具调用且限于结构化图像(表格/图表),向自然图像和多轮迭代编辑的迁移还需验证。